安装环境 🔖
在本地安装 LangChain 并不复杂,但因为 LangChain 是一个“胶水”框架,它通常需要配合大模型(LLM)才能工作。
LangChain 并非必须依赖 Python 环境,它提供了多语言支持,核心功能可在多种编程语言 / 运行时中使用,Python 只是其最主流、生态最完善的版本。以下是具体说明,帮你清晰了解不同场景下的选择:
| 语言 / 环境 | 支持程度 | 适用场景 |
|---|---|---|
| Python | 完全支持(官方核心版本) | 绝大多数场景(RAG、Agent、本地大模型集成、向量库联动),生态最丰富 |
| JavaScript/TypeScript | 官方支持(LangChain JS) | 前端 / Node.js 后端、全栈 AI 应用、轻量级检索场景 |
| Go | 社区维护(LangChain Go) | 高性能后端、Go 语言项目集成(功能略精简) |
| Java | 社区维护(LangChain4j) | 企业级 Java 项目、Spring 生态集成 |
| C#/.NET | 社区维护(LangChain .NET) | .NET 平台应用、Windows 开发场景 |
简单来说:只有想使用 LangChain 全部功能(尤其是最新特性、丰富的第三方集成),Python 是最优解;若你的技术栈是 JS/Go/Java 等,也能找到适配版本,只是功能覆盖度和生态完善度略低。
Python环境搭建(Windows) 🔖
🔹获取电脑处理器型号
按下Win+R键,运行cmd或直接在开始菜单搜索命令提示符后, 进入命令提示符界面,输入以下指令获取处理器型号.
echo %PROCESSOR_ARCHITECTURE%
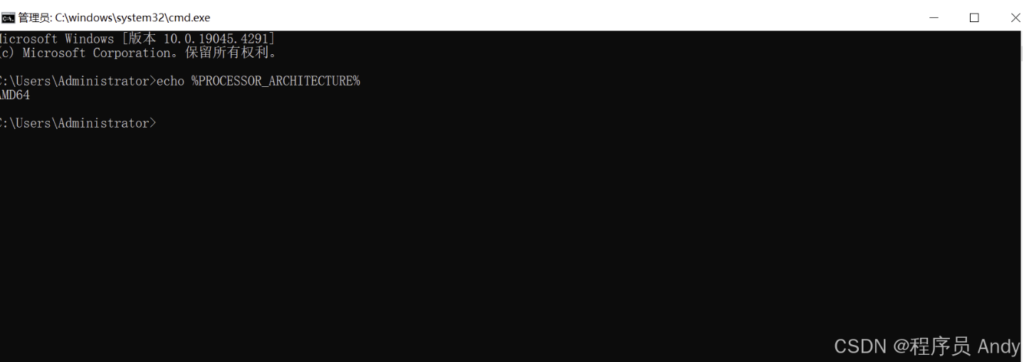
上图显示此电脑是AMD64处理器
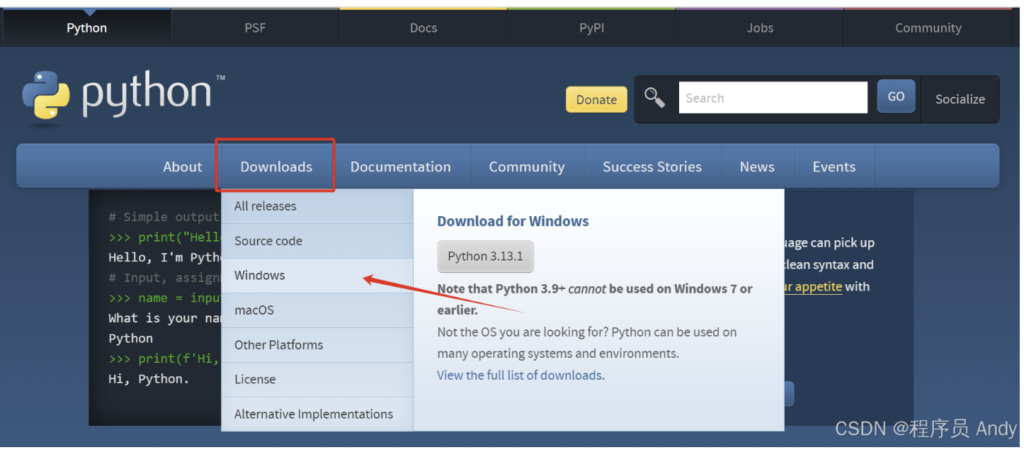
🔹安装python
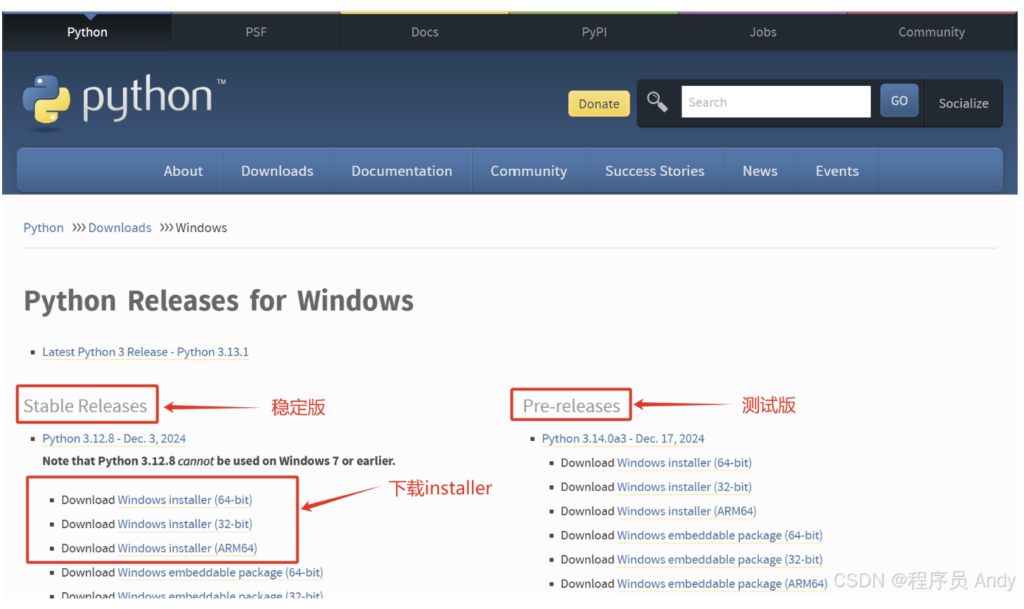
python官网网址: Welcome to Python.org
由于此电脑是AMD64处理器,因此在确认要下载的python版本后选择 Windows installer (64-bit) 或 Windows x86-64 executable installer ,如下图所示
安装可执行程序,勾选下面的选项。
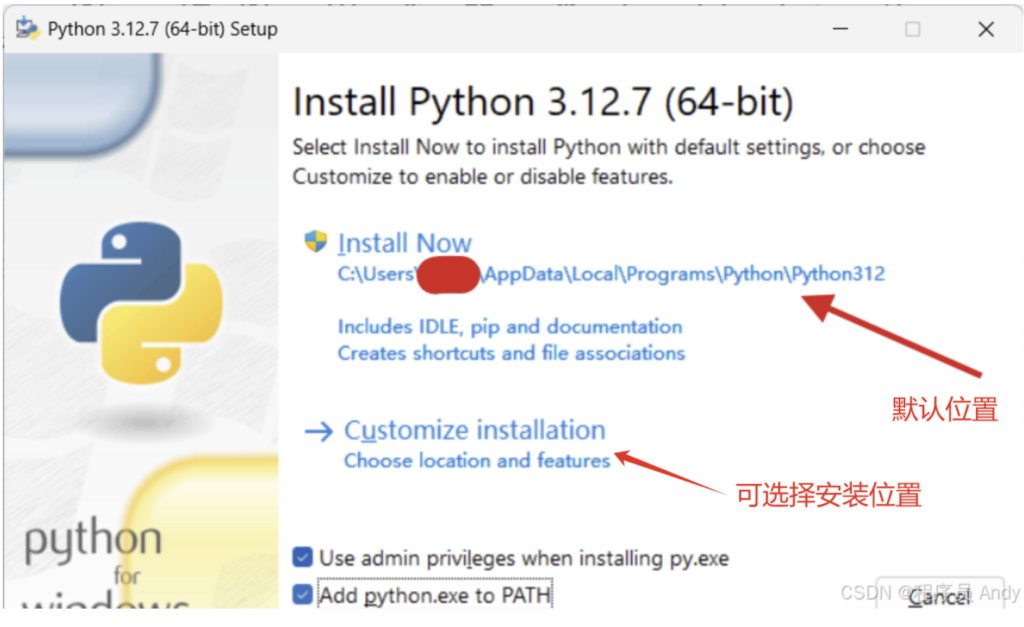
Use admin privileges when installing py.exeAdd python.exe to PATH
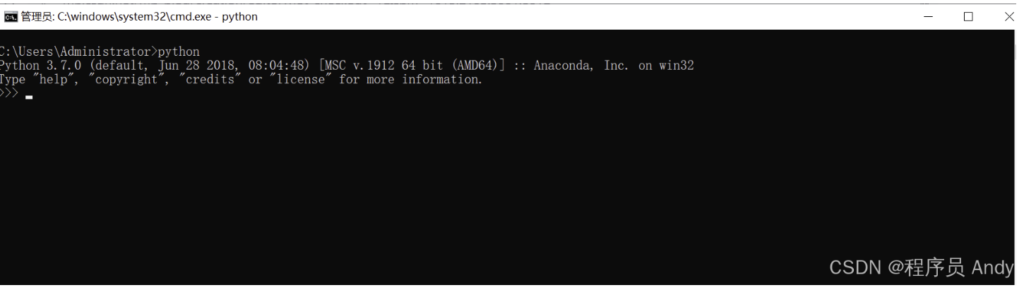
安装完成后按下Win+R键,运行cmd或直接在开始菜单搜索命令提示符后,进入命令提示符界面,输入以下指令,下图为安装成功的示例。

创建虚拟环境(强烈推荐) 🔖
为了避免依赖冲突,建议为 LangChain 创建一个独立的虚拟环境。
🔹Windows:
python -m venv langchain_env langchain_env\Scripts\activate
🔹Mac / Linux:
python3 -m venv langchain_env source langchain_env/bin/activate
安装 LangChain 核心库 🔖
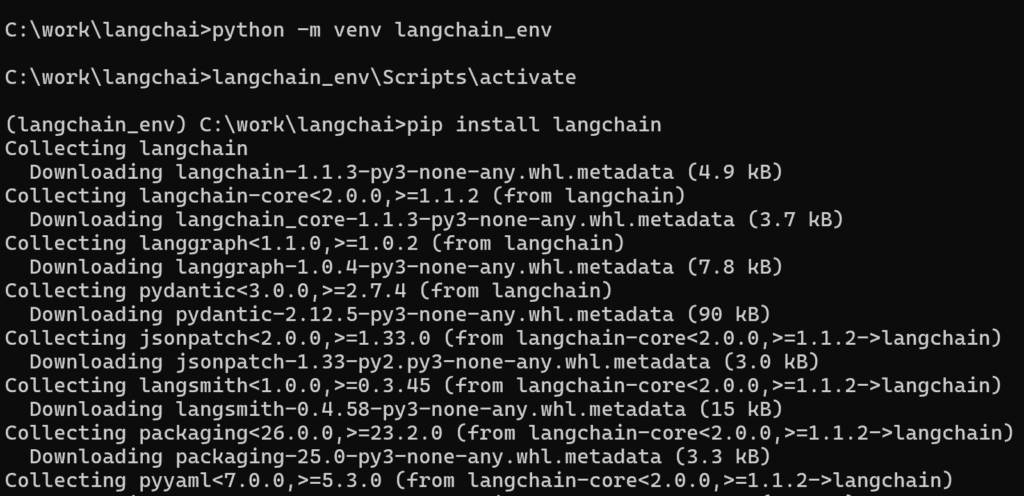
在激活的虚拟环境中,使用 pip 安装:
pip install langchain
注意:从最近的版本开始,LangChain 将生态系统拆分成了不同的包。
- 如果你需要使用社区集成的功能(大多数情况都需要),建议同时安装:
pip install langchain-community
🔹langchain-core 和 langchain-community
- langchain-core (操作系统内核):
- 这是 LangChain 的大脑。它定义了什么是“链(Chain)”,什么是“提示词模板(Prompt)”,什么是“消息(Message)”。但它本身不包含连接外部世界的代码。它只是一套逻辑规则,就像 Windows 操作系统,如果没有驱动程序,它连不上打印机、显卡或网卡。
- langchain-community (驱动程序包):
- 这是 LangChain 的外设仓库。它包含了连接成千上万个第三方软件和服务的代码。
- 比如:你想连接 Qdrant 数据库?代码在这里。你想读取 PDF 文件?代码在这里。你想调用 HuggingFace 的模型?代码也在这里。
如果没有 langchain-community,LangChain 就只是一个空壳逻辑,无法与外界交互。以下是它包含的四大核心板块,也是你做项目必用的:
🔹文档加载器 (Document Loaders) —— RAG 的第一步
这是最常用的功能。如果你想做“知识库”,你需要把本地的文件读进程序里。
langchain-core 不懂怎么读 PDF 或 Word,这些功能全在 community 里。
- 读取 PDF: PyPDFLoader
- 读取 Markdown: UnstructuredMarkdownLoader
- 读取 Word: Docx2txtLoader
- 爬取网页: WebBaseLoader
# ❌ 核心包里没有这个,会报错 from langchain.document_loaders import PyPDFLoader # ✅ 必须从社区包导入 from langchain_community.document_loaders import PyPDFLoader
🔹向量数据库集成 (Vector Stores)
虽然 Qdrant 最近推出了独立的 langchain-qdrant 包,但在 LangChain 的生态中,绝大多数数据库的连接器都住在 community 里。
- 连接 Chroma: Chroma
- 连接 FAISS: FAISS
- 连接 Neo4j: Neo4jVector
如果你不装这个包,LangChain 就不知道如何把向量存进这些数据库,也无法从里面检索数据。
🔹模型集成 (LLMs & Embeddings)
除了 OpenAI、Anthropic 这种巨头有自己独立的包(如 langchain-openai)之外,成百上千的其他开源模型、小众模型的接口都在这里。
- HuggingFace: HuggingFaceHub, HuggingFaceEmbeddings (这是你做本地知识库必用的)
- LlamaCpp: 用于本地运行量化模型
- Ollama: 虽然现在有 langchain-ollama,但很多旧教程和辅助功能依然依赖 community 中的实现。
🔹工具 (Tools):让 AI 拥有“手”和“眼”。
- Google 搜索: GoogleSearchAPIWrapper
- 维基百科搜索: WikipediaAPIWrapper
- DuckDuckGo: DuckDuckGoSearchRun
🔹为什么要拆分?(背景知识)
在 LangChain 的早期版本(0.1.0 之前),所有这些东西都塞在一个包里。
结果就是:
包巨大无比:你只想用个 OpenAI,结果它让你下载了几百兆关于 AWS、Azure、Google 的依赖库。
维护困难:某个冷门的数据库更新了 API,导致整个 LangChain 都要发新版。
所以现在变成了:
- langchain-core: 轻量,稳定,很少变动。
- langchain-community: 庞大,更新快,依赖多。
- langchain-openai / langchain-qdrant: 官方认证的顶级合作伙伴,独立维护。
🔹总结: “社区集成的功能” 简单来说就是:LangChain 用来连接“别人家软件”的所有接口。
- 你想读 PDF 文件?需要它。
- 你想用 Ollama 或 HuggingFace?需要它。
- 你想存 向量数据库?需要它。
- 所以,除非你只是想纯粹地研究 LangChain 的源代码逻辑而不做任何实际应用,否则 pip install langchain-community 是 100% 必须的。
简单的Demo 🔖
🔹RAG Chain Demo
pip install langchain-openai pip install langchain-qdrant qdrant-client pip install langchain-huggingface pip install sentence-transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
import os
# 设置环境变量,切换到国内镜像源
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
# 导入 Qdrant 相关的库
from langchain_qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
from qdrant_client.http import models
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# ==========================================
# 0. 配置信息 (填入你的真实信息)
# ==========================================
# Qdrant 配置
QDRANT_URL = "http://xxxx:6333/" # 你的集群地址
QDRANT_API_KEY = "xxx" # 你的 API Key
COLLECTION_NAME = "LangChainTest" # 集合名称
# DeepSeek 配置
DEEPSEEK_API_KEY = "xxx"
DEEPSEEK_BASE_URL = "https://api.deepseek.com"
# ==========================================
# 1. 准备数据 & Embedding
# ==========================================
documents = [
"幻影科技公司成立于 2023 年,总部位于深圳南山区。",
"幻影科技的核心产品是 'ShadowAI',AI 助手。",
"公司的 CEO 叫李四,CTO 叫张三。",
"公司的企业文化是:'不加班,只摸鱼'。"
]
print("1. 加载 Embedding 模型...")
# 注意:如果你用的是 bge-small-zh,维度是 512
# 如果你用 bge-m3,维度是 1024。一定要记住这个数字!
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': 'cpu'}
)
# ==========================================
# 2. 连接 Qdrant (核心修改部分)
# ==========================================
print("2. 连接 Qdrant 数据库...")
# 步骤 A: 创建原生 Qdrant 客户端
client = QdrantClient(
url=QDRANT_URL,
api_key=QDRANT_API_KEY,
)
# 步骤 B: 检查集合是否存在,不存在则创建 (这一步很重要,防止报错)
# 注意:size 必须和你的 embedding 模型维度一致!
# bge-small-zh-v1.5 = 512
# bge-m3 = 1024
# nomic-embed-text = 768
if not client.collection_exists(collection_name=COLLECTION_NAME):
print(f"集合 {COLLECTION_NAME} 不存在,正在创建...")
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=models.VectorParams(size=512, distance=models.Distance.COSINE),
)
# 步骤 C: 实例化 LangChain 的 VectorStore
vectorstore = QdrantVectorStore(
client=client,
collection_name=COLLECTION_NAME,
embedding=embeddings,
)
# 步骤 D: 添加数据 (如果数据已经在库里了,这行可以注释掉,不然会重复添加)
print("正在写入数据...")
vectorstore.add_texts(documents)
# 创建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# ==========================================
# 3. 后续 RAG 流程 (和之前完全一样)
# ==========================================
print("3. 初始化 DeepSeek...")
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_key=DEEPSEEK_API_KEY,
openai_api_base=DEEPSEEK_BASE_URL,
temperature=0.1
)
template = """
使用以下上下文回答问题。如果不清楚,说不知道。
【上下文】:
{context}
【问题】:
{question}
"""
prompt = ChatPromptTemplate.from_template(template)
def format_docs(docs):
return "\n\n".join([d.page_content for d in docs])
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# ==========================================
# 4. 测试
# ==========================================
print("\n=== 测试结果 ===")
print(rag_chain.invoke("这家公司的CEO是谁?"))
🔹RAG Server Demo
pip install "langserve[all]" uvicorn sse_starlette
import os
# 1. 解决下载报错 (可选)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from fastapi import FastAPI
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langserve import add_routes
# ==========================================
# 2. 全局初始化 (只执行一次,避免每次请求都重连)
# ==========================================
# 配置信息
QDRANT_URL = "http://xxx:6333/" # 替换你的
QDRANT_API_KEY = "xxx" # 替换你的
COLLECTION_NAME = "LangChainTest"
DEEPSEEK_API_KEY = "xxx"
DEEPSEEK_BASE_URL = "https://api.deepseek.com"
# 初始化 Embedding
print("正在加载模型...")
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': 'cpu'}
)
# 连接 Qdrant
client = QdrantClient(url=QDRANT_URL, api_key=QDRANT_API_KEY)
vectorstore = QdrantVectorStore(
client=client,
collection_name=COLLECTION_NAME,
embedding=embeddings,
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# 初始化 DeepSeek
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_key=DEEPSEEK_API_KEY,
openai_api_base=DEEPSEEK_BASE_URL,
temperature=0.1
)
# 定义 Prompt
template = """
使用以下上下文回答问题。如果不清楚,说不知道。
【上下文】:
{context}
【问题】:
{question}
"""
prompt = ChatPromptTemplate.from_template(template)
def format_docs(docs):
return "\n\n".join([d.page_content for d in docs])
# 定义链 (Chain)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# ==========================================
# 3. 创建 FastAPI 应用 (LangServe 核心)
# ==========================================
app = FastAPI(
title="LangChain RAG API",
version="1.0",
description="一个基于 DeepSeek + Qdrant 的知识库问答 API",
)
# 核心魔法:把 chain 挂载到 /rag 这个路径下
add_routes(
app,
rag_chain,
path="/rag",
)
if __name__ == "__main__":
import uvicorn
# 启动服务,监听 8000 端口
print("服务已启动: http://localhost:8000")
uvicorn.run(app, host="localhost", port=8000)
当你运行 python server.py 时:
- uvicorn 启动,站在门口(端口 8000)开始接客。
- 用户发来一个请求:“CEO 是谁?”
- uvicorn 把请求交给 langserve。
- langserve 运行你的 RAG 链,生成答案。
- sse_starlette 负责把答案建立成一条管道,“李…四…是…”,一个字一个字推回去。
所以这三个缺一不可:一个是大脑(LangServe),一个是身体(Uvicorn),一个是嘴巴(SSE)。
LangChain 和 LangFuse 结合 Demo🔖
🔹什么是Langfuse
Langfuse是一个开源的可观测性平台,专为大语言模型(LLM)应用而设计。它提供了一套全面的工具,帮助开发者深入了解LLM应用的运行状况,从而实现对LLM请求的跟踪、调试和优化。无论使用的是LangChain、LlamaIndex等主流框架,还是自定义的RAG(检索增强生成)管道,Langfuse都能以最小的配置成本无缝集成,并揭示LLM应用内部的复杂性。
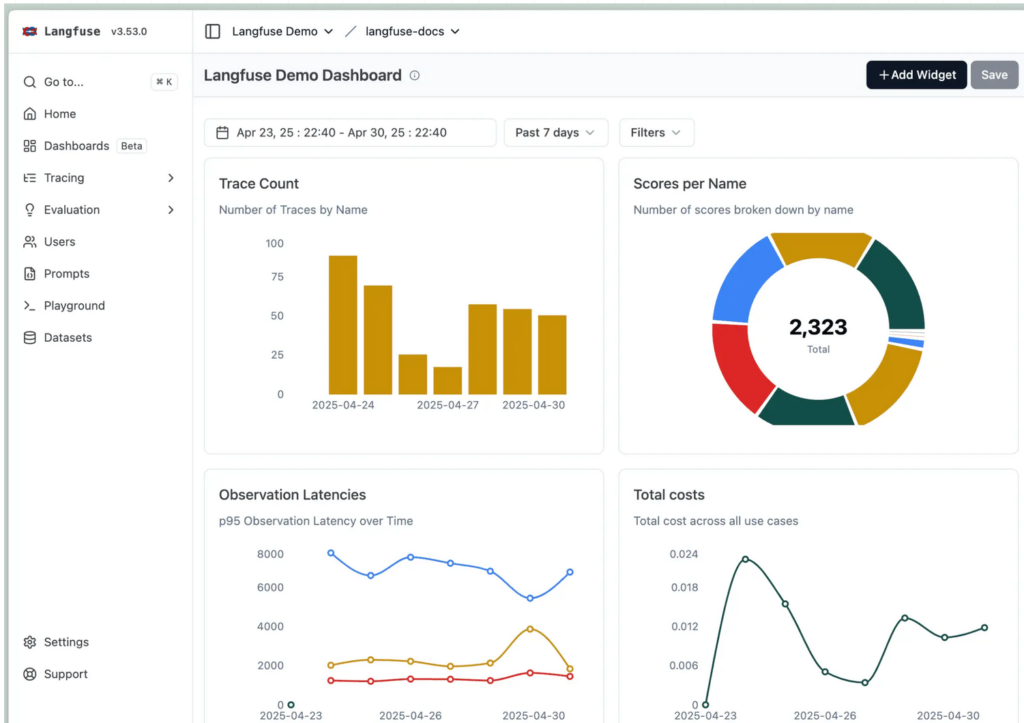
Langfuse的核心价值在于其对LLM应用全生命周期的详细可见性,主要体现在以下几个方面:
- 追踪(Traces): 记录LLM应用中完整的请求生命周期,从用户查询到最终响应的每一个步骤,包括API调用、上下文、提示、并行处理等。这对于理解多跳推理、工具使用和检索调用的行为至关重要。
- 指标(Metrics): 提供关键的性能、成本和质量指标。可以监控模型延迟、API调用成本(例如OpenAI的token使用)、错误率和重试次数等,从而量化应用的运行效率和经济效益。
- 评估(Assessments): 支持对LLM响应质量进行自动化评估和人工评估。Langfuse可以与“LLM即裁判”的评估方法集成,并支持基于LLM的自动评分,评估指标包括准确性、有毒性和连贯性等。此外,它也提供了手动评估界面,方便人工审核和反馈。
- 实验跟踪(Experiment Tracking): 允许开发者对不同配置进行A/B测试,并比较它们在性能、成本和质量方面的表现,从而实现数据驱动的优化。
简而言之,Langfuse填补了传统监控工具在LLM应用领域留下的空白,它为开发者提供了一个清晰的“窗口”,可以透视AI工作流的内部,帮助我们发现问题、衡量关键指标,并充满信心地进行扩展。
传统的软件开发中,我们习惯于使用日志和应用性能监控(APM)工具来追踪系统行为。然而,LLM应用的特性使得这些传统方法显得力不从心。LLM应用并非简单的确定性逻辑,其内部运作充满了复杂性和不确定性。例如,一个看似简单的客户支持聊天机器人,在幕后可能涉及:
- 从向量数据库中检索相关文档
- 构建包含上下文的复杂提示
- 对不同推理步骤进行多次LLM调用
- 通过各种过滤器处理响应
- 生成最终答案
每一个步骤都可能引入不可控的变量,如token使用量、响应质量、延迟以及因提示复杂度和模型行为而波动的成本。当聊天机器人给出不佳的响应时,我们很难直接判断是检索到的文档不相关、提示构建不当,还是模型产生了幻觉。缺乏适当的可观测性,调试LLM应用就像在盲目摸索,不仅效率低下,还可能导致成本失控。
Langfuse正是为了解决这些挑战而生。它作为一个可观测性层,能够捕捉语言模型应用的完整执行上下文,从而提供传统工具无法比拟的深度洞察:
- 1. 成本透明化与优化
LLM的API调用成本是许多开发者面临的痛点。Langfuse能够自动计算支持模型的成本(如OpenAI、Anthropic),并允许按用户、会话、特定模型版本、不同功能或工作流程,甚至地理区域来细分成本。这意味着可以精确地找出哪些提示、用户或功能正在驱动你的开支,从而有针对性地进行优化。例如,通过Langfuse,可以发现某些公司报告触发了极长的提示(12,000+ token),导致成本飙升,进而优化分块策略,将平均提示长度减少40%,实现显著的成本节约。
- 2. 性能瓶颈识别
LLM应用的响应速度直接影响用户体验。Langfuse捕获了从数据检索、提示创建到LLM分析的每一个阶段,使得延迟测量和细粒度的性能调优成为可能。当的应用感觉缓慢时,Langfuse可以准确地显示时间花费在哪里,是向量搜索、提示构建,还是LLM推理本身?通过识别并优化最慢的组件,可以显著提升应用的整体性能。
- 3. 大规模质量监控
确保LLM输出的质量是构建可靠AI应用的关键。Langfuse允许运行基于模型的评估,LLM可以根据准确性、有毒性或幻觉等因素对特定会话、追踪或LLM调用进行评分。这意味着可以设置自动化质量评分,在生产环境中持续运行,而不是依赖手动审查。这不仅提高了效率,还能在用户发现问题之前及时捕获并解决问题。
- 4. 提示词工程优化
提示词(Prompt)的微小改动都可能对LLM的输出质量和成本产生巨大影响。Langfuse能够追踪哪些提示在不同场景中表现最佳,并支持对提示变体进行A/B测试,衡量它们对质量和成本的影响。通过系统地测试和优化提示,可以找到每个用例的最佳版本,从而提升模型表现并控制成本。
- 5. 用户体验洞察
Langfuse允许实时监控成本和延迟指标,并按用户、会话、地理位置和模型版本进行分类。通过了解不同用户群体如何与AI互动,可以优先考虑改进方向,并识别个性化的机会。例如,可以为高频用户和普通用户制定不同的优化策略,以提供更优质的服务。
总之,Langfuse为LLM应用开发者提供了一个强大的工具集,将AI开发从“成本高昂的猜测游戏”转变为“数据驱动的优化机器”。它让LLM应用的可观测性不再是可选项,而是构建可靠、高效和可解释AI系统的必需品。
安装langfuse sdk(版本>3.0)
pip install --upgrade langfuse -i https://mirrors.aliyun.com/pypi/simple/
Python代码 LangChain 结合 Langfuse, 连接Langfuse Cloud
import os
# 解决下载报错 (可选)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from fastapi import FastAPI
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langserve import add_routes
from langfuse import Langfuse
from langfuse.langchain import CallbackHandler
# ==========================================
# Langfuse 配置
# ==========================================
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-xx" # 替换你的公钥
os.environ["LANGFUSE_SECRET_KEY"] = "sk-xx" # 替换你的私钥
os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 如果是云端版不用改,私有化部署改这里
# ==========================================
# 全局初始化
# ==========================================
# [新增] 初始化 Langfuse Handler
# 这个 handler 会自动捕获 LangChain 的所有动作
langfuse_handler = CallbackHandler()
# 配置信息
QDRANT_URL = "http://xxx:6333/" # 替换你的
QDRANT_API_KEY = "xxx" # 替换你的
COLLECTION_NAME = "Employee Handbook"
DEEPSEEK_API_KEY = "sk-xxx"
DEEPSEEK_BASE_URL = "https://api.deepseek.com"
# 初始化 Embedding
print("正在加载模型...")
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-m3",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
# 连接 Qdrant
client = QdrantClient(url=QDRANT_URL, api_key=QDRANT_API_KEY)
vectorstore = QdrantVectorStore(
client=client,
collection_name=COLLECTION_NAME,
embedding=embeddings,
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# 初始化 DeepSeek
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_key=DEEPSEEK_API_KEY,
openai_api_base=DEEPSEEK_BASE_URL,
temperature=0.1
)
# 定义 Prompt
template = """
使用以下上下文回答问题。如果不清楚,说不知道。
【上下文】:
{context}
【问题】:
{question}
"""
prompt = ChatPromptTemplate.from_template(template)
def format_docs(docs):
return "\n\n".join([d.page_content for d in docs])
# 定义链 (Chain)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# ==========================================
# 创建 FastAPI 应用 (LangServe 核心)
# ==========================================
app = FastAPI(
title="LangChain RAG API",
version="1.0",
description="一个基于 DeepSeek + Qdrant 的知识库问答 API",
)
# 在这里注入 Langfuse
# 使用 .with_config() 将 callbacks 绑定到链上
# 这样通过 API 请求的每一次调用都会自动发送到 Langfuse
add_routes(
app,
rag_chain.with_config({"callbacks": [langfuse_handler]}), # <--- [重点修改]
path="/rag",
)
if __name__ == "__main__":
import uvicorn
# 启动服务,监听 8000 端口
print("服务已启动: http://localhost:8000")
uvicorn.run(app, host="localhost", port=8000)
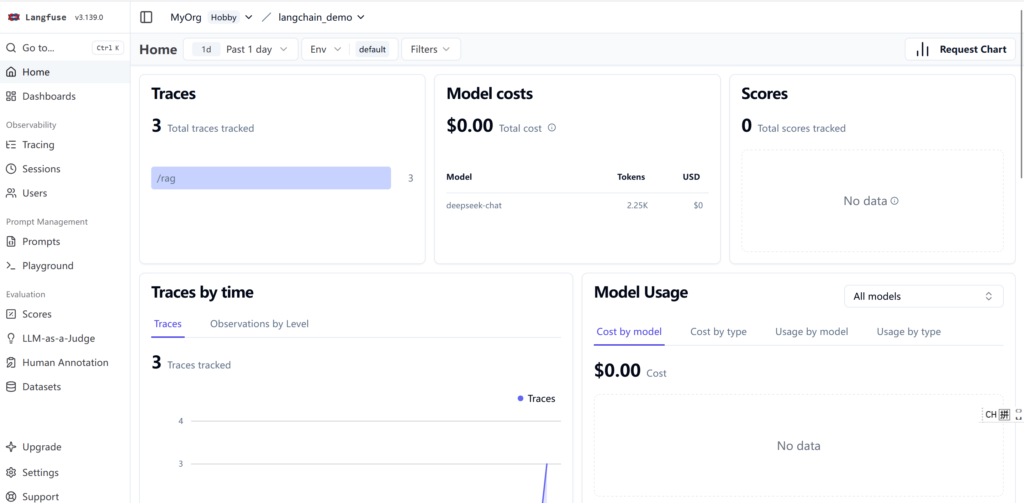
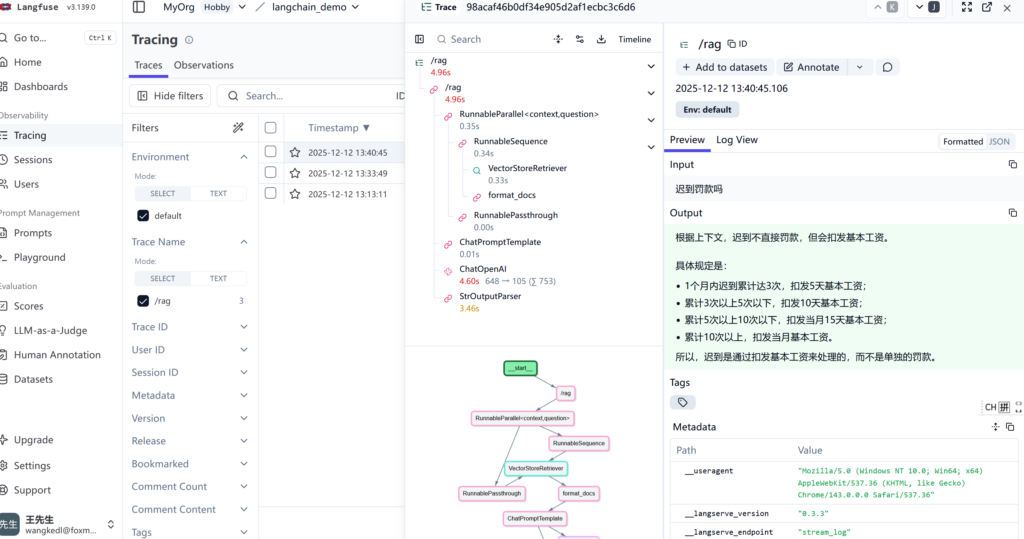
在画面调用RAG提问问题
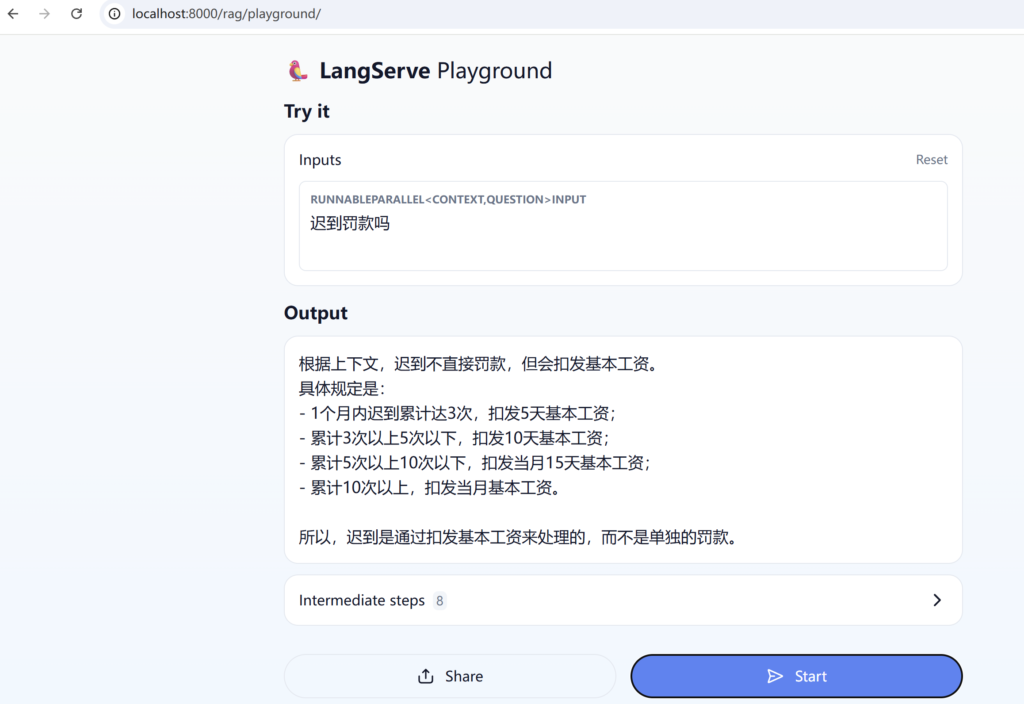
登录LangFuse网页可以看到细节被LangFuse监控到了。
https://us.cloud.langfuse.com/