转载:小红书 AI产品赵哥
前言🔖
上上周我们聊了聊 LangChain,我们把 LangChain 比作一个 “工具箱”,其中的核心组件 Chains(链),可以让我们像搭建流水线一样,把各种 AI 能力串联起来。这个模型很棒,对于很多任务简直是手到擒来。
但是,当 AI 开发者们想用它来做一个复杂的 AI 系统(比如一个能自我反思、多轮修正、协同工作的复杂 AI 智能体)时,他们发现,这条 “流水线” 好像有点…… 太直了。
今天,咱来聊聊 LangChain 的 “亲儿子”——LangGraph。它彻底打破了 “链” 的束缚,引入了 “图” 的结构,让构建复杂 AI 应用的可能性,从一条直线,变成了一张网。
伙计们,准备好了吗?咱们出发了!!!
一、回顾与反思,LangChain “链” 式结构的天花板在哪?🔖
在介绍 LangGraph 之前,我们必须先深刻理解,它到底解决了LangChain 的什么问题?我们先快速回顾一下 LangChain 的核心 ——Chain(链)和 Agent(智能体),并看看它们的 “阿喀琉斯之踵”。
🔹1. Chain:一条道走到黑的 “单行线”
我们上次说过,Chain 就像一条工作流水线。
原料进来 → 工位 A 处理 → 传给工位 B 处理 → …… → 最终产品出去
这个模式清晰且高效。比如 “先总结文本,再翻译成英文”,这种一步接一步的线性任务,用 Chain 简直完美。但是,现实世界是复杂的!很多任务不是一条直线。
想象一个真实的场景:你让一个实习生写一份市场分析报告。
他的工作流程可能是这样的:
- 上网搜索相关资料。
- 根据资料写出第一版草稿。
- 他自己审阅草稿,觉得 “哎呀,数据不够支撑论点”。
- 于是他返回第一步,进行新一轮的搜索,补充更多数据。
- 重写 / 修改草稿。
- 他又觉得 “嗯,结构有点乱”。
- 于是他不搜索了,而是直接对现有内容进行重新组织。
- 最后,他觉得 “OK,差不多了”,才把报告交给你。
大家看到了吧?这个过程充满了循环(loops)、判断(decisions)和分支(branches)。他会根据当前草稿的状态,来决定下一步是该 “重新搜索”、“重新组织” 还是 “提交工作”。
用 LangChain 的 Chain 来模拟这个过程,会变得极其痛苦!因为 Chain 天生就是一条单行线,它很难实现 “返回上一步” 或者 “根据条件跳转到某一步” 这种灵活的控制流。开发者需要写大量的、非常不优雅的 “胶水代码” 来强行实现循环,整个逻辑会变得一团糟。
🔹2. Agent:一个有想法但有点失控的 “黑箱”
LangChain 的 Agent 在某种程度上解决了这个问题。我们上次说,Agent 像一个有自主决策能力的 “项目经理”,它基于 ReAct (Reason + Act) 框架,可以自己决定调用什么工具来完成任务。
它确实能实现循环,比如发现信息不够,它会自己决定再次调用搜索工具。但 Agent 的最大问题在于,它是一个 “黑箱”!你给了它目标和工具,它就开始 “自言自语”(Reasoning)和 “手忙脚乱”(Acting)了。整个过程,你作为 “老板”,很难对它的工作流程进行精细化的控制和干预。
- 你没法强制它必须先写草稿再批判,它可能搜了半天,觉得信息够了直接就给你一个最终答案。
- 你没法在它犯错的时候把它拉回来,它可能在一个错误的思路上循环了十几次,浪费了大量的时间和 API 调用费用,最终告诉你 “我做不到”。
- 它的行为不够稳定,同样的问题,这次它可能是 A-B-C 的步骤,下次可能是 A-C-B,结果可能截然不同。
对于想开发一个可靠、可控、可预测的商业级 AI 应用的开发者来说,这种 “黑箱” 式的智能体,就像一个能力很强但野性难驯的员工,你不敢把真正核心的任务交给它。
二、LangGraph 登场:从 “链” 到 “网” 的革命🔖
LangGraph 到底是什么?
如果说 LangChain 的 Chain 是一条笔直的乡间小路,那么 LangGraph 就是一张布满了立交桥、环岛和交通信号灯的现代化城市交通网络!
最核心的一句话定义:LangGraph 是一个专门用于构建可循环、有状态的、类似 “图” 结构的多智能体应用的库。它是对 LangChain 核心思想的延伸和升级,但它把基础单元从 “链” 换成了 “图(Graph)”。
在 LangGraph 的世界里,你不再是设计一条 “流水线”,而是在设计一张 “流程图” 或者 “地图”。
这张 “地图” 由两个核心元素构成:
- 节点(Nodes):地图上的各个 “地点” 或 “站点”。每个站点都负责一项具体的工作,比如 “搜索站”、“写作站”、“审核站”、“计算站”。
- 边(Edges):连接这些站点的 “道路”。道路决定了从一个站点完成工作后,接下来应该去往哪个站点。
和 Chain 最大的区别在于,这些 “道路” 不再是唯一的、单向的!
- 你可以从 “审核站” 修一条路回到 “搜索站”(实现循环)。
- 你可以在 “审核站” 设置一个 “交通警察”(条件边),它会根据你的报告质量,指挥你 “直行,去终点站”、“掉头,回写作站重写” 或者 “左转,去搜索站补充材料”。
这种 “图” 结构,天然地就支持了循环和条件分支,完美地解决了 Chain 的死板问题。同时,因为整个网络是你自己亲手设计的,每个站点、每条道路、每个交通规则都清清楚楚,所以它又解决了 Agent 的 “黑箱” 问题,让整个应用变得完全可控和透明。
三、拆解 LangGraph 的四大模块(核心组件精讲)🔖
好了,概念我们懂了。现在,让我们庖丁解牛,深入 LangGraph 的内部,看看它的核心组件到底是怎么运作的。记住这四个词,你就掌握了 LangGraph 的灵魂:State(状态)、Nodes(节点)、Edges(边)、Graph(图)。
🔹1. State(状态对象):流淌在整个网络中的 “血液”
State 在 LangGraph 里最为重要,所以咱先聊聊 State:
State(状态)是一个共享的信息容器。你可以把它想象成一个在整个交通网络中不断流动的手推车。
- 当流程开始时,这个手推车里可能只装着最初的问题,比如
{"任务": "写一篇关于AIGC的报告"}。 - 手推车被推到 “搜索站”(第一个节点),这个站点的 “工人”(函数)从手推车里拿出任务,上网搜索,然后把搜索结果放回手推车里。现在手推车里的东西变成了
{"任务": "...", "搜索结果": [...]}。 - 手推车又被推到 “写作站”,工人拿出 “搜索结果”,写了一份草稿,然后把草稿也放进手推车。现在手推车里是
{"任务": "...", "搜索结果": [...], "报告草稿": "..."}。 - 手推车继续被推到 “审核站”……
看到了吗?State 这个 “手推车”,贯穿了整个流程,所有的节点都可以从里面读取信息,也可以把自己的工作成果更新回去。它就是整个图的单一事实来源(Single Source of Truth),是所有节点之间沟通的桥梁。
这种设计很是优雅!它让数据传递变得非常清晰,每个节点只需要关心如何与这个共享的 State 对象交互,而不需要关心数据具体是从哪个上游节点来的。这大大降低了系统的耦合度。
🔹2. Nodes(节点):各司其职的 “工作站”
Node(节点),就是一个接收当前 State,并对其进行某些操作,然后返回更新结果的 “函数” 或 “可调用对象”。
在 LangGraph 里,一个节点可以做任何事情:
- 调用一个 LLM:比如让 GPT-4 根据 State 里的 “搜索结果” 来写一份草稿。
- 调用一个工具:比如执行一次网络搜索、一次数据库查询、或者运行一段 Python 代码。
- 一个普通的 Python 函数:比如对 State 里的数据进行格式化、清洗、或者简单的逻辑判断。
每个节点都像一个专才,它只负责自己的那一亩三分地儿。这种设计让我们可以把一个复杂的任务,拆解成一个个简单、独立、可测试的小单元,极大地提高了代码的可维护性。
🔹3. Edges(边):决定流程走向的 “交通规则” 🚦
Edges(边),定义了节点之间的连接关系,也就是流程的走向。这是 LangGraph 灵活性和控制力的核心体现。
LangGraph 主要有三种类型的边:
- 起始边(Starting Edge):定义了整个流程从哪个节点开始。相当于 “机场入口”。
- 普通边(Normal Edges):定义了一个节点完成后,无条件地流向下一个节点。这就像一条没有岔路口的高速公路。比如,在我们的例子中,“搜索站” 完成之后,必然是去 “写作站”,这就可以用一条普通边连接。
- 条件边(Conditional Edges):这是 LangGraph 的撒手锏!它允许你根据当前 State 中的某些值,来动态地决定下一步要去哪个节点。这就像一个繁忙的交通环岛,中间站着一个聪明的 “交通警察”。 我们来详细说说这个 “交通警察” 是怎么工作的:
- 你先定义一个 “路由函数”(Routing Function)。这个函数会接收当前的 State 作为输入。在函数内部,你可以编写逻辑来检查 State。比如,检查 State 里的 “审核意见” 这个字段。根据检查结果,函数返回一个字符串,这个字符串就是下一个节点的名字。
route_after_critique的路由函数。这个函数内部的逻辑可能是:
# 路由函数(交通警察)
def route_after_critique(state):
critique = state["审核意见"]
if "完美" in critique:
return "end_node" # 直接去终点
elif "信息不足" in critique:
return "search_node" # 返回搜索站
else: # 其他情况,比如结构不好
return "rewrite_node" # 去重写站
大家看到了吗?通过这个简单的路由函数,我们就实现了一个极其灵活的、基于状态的流程控制!这就是把 Agent 的 “黑箱” 决策过程,变成了我们自己定义的、清晰可控的 “白箱” 逻辑。
🔹4. Graph(图):组装一切的 “总工程师”
最后,你需要一个 **Graph(图)** 对象。它就像一个总工程师,负责把上面定义好的所有 State、Nodes 和 Edges 组装成一个完整的、可执行的工作流。
你的工作流程是这样的:
- 实例化一个 Graph,并定义 State 长什么样。
- 向 Graph 中添加节点:
graph.add_node("节点名", 节点函数)。 - 向 Graph 中添加边:
- 设置起始点:
graph.set_entry_point("起始节点名")。 - 添加普通边:
graph.add_edge("节点A", "节点B")。 - 添加条件边:
graph.add_conditional_edges("来源节点", 路由函数, {"返回值A": "去节点X", "返回值B": "去节点Y"})。
- 设置起始点:
- 编译 Graph:
app = graph.compile()。
编译完成后,你就得到了一个可以执行的 AI 应用。你只需要调用app.stream({"初始输入": "..."}),这个复杂的、可循环的、有状态的流程就会自动运转起来,而且每一步的状态变化你都可以清晰地看到!
四、实战演练:用 LangGraph 打造一个 “自我修正” 的研究助理🔖
理论说了万万千,不如实战看一看,咱们一起来感受 LangGraph 的能力。让我们来设计一个比之前更强大的 “AI 研究助理”,它的任务是:根据用户提问,撰写一份高质量的研究报告。这个助理必须具备搜索、写作、反思、修正的能力,而且整个过程要像一个专业的团队在协作。
🔹第一步:设计 “状态”(State)—— 我们的 “手推车”
我们的手推车(State)里需要装点儿啥?
# 注:这不是真实代码,只是一个结构示意
state = {
"question": "", # 用户的原始问题
"documents": [], # 搜索到的文档列表
"draft": "", # 报告的草稿
"critique": "", # 对草稿的评价
"revision_number": 0 # 记录修改次数,防止无限循环
}
🔹第二步:设计 “节点”(Nodes)—— 我们的 “专家团队”
我们需要一个团队,每个成员都是一个节点:
search_node(搜索专家):- 输入:State 中的
question。 - 工作:调用搜索引擎(比如 Tavily Search API),找到相关的网页和资料。
- 输出:将找到的文档(
documents)更新到 State 中。
- 输入:State 中的
draft_node(写作专家):- 输入:State 中的
question和documents。 - 工作:调用一个 LLM(比如 GPT-5.1),让它根据搜索到的文档,撰写一份报告草稿。
- 输出:将生成的
draft更新到 State 中。
- 输入:State 中的
critique_node(审核专家):- 输入:State 中的
question和draft。 - 工作:调用另一个 LLM(是的,可以有多个 LLM!),扮演一个挑剔的 “审稿人”,对草稿进行批判性评估。评估它是否回答了问题?论据是否充分?结构是否清晰?
- 输出:将
critique(审核意见)更新到 State 中。
- 输入:State 中的
rewrite_node(修改专家):- 输入:State 中的
question、draft和critique。 - 工作:调用 LLM,告诉它:“这是原始问题,这是第一版草稿,这是对草稿的修改意见,请你根据修改意见重写一份更好的。”
- 输出:将新的
draft更新回 State 中。
- 输入:State 中的
🔹第三步:设计 “边”(Edges)—— 设计我们的 “工作流程图”
这是最关键的一步,我们要画出这张复杂的地图!
- 起始点:
- 流程从
search_node开始。graph.set_entry_point("search_node")
- 流程从
- 普通边:
search_node完成后,必然要去draft_node。graph.add_edge("search_node", "draft_node")draft_node完成后,必然要去critique_node进行审核。graph.add_edge("draft_node", "critique_node")rewrite_node完成后,也要去critique_node重新审核。graph.add_edge("rewrite_node", "critique_node")
- 条件边(重要):
critique_node完成后,就是我们的大型交通枢纽了!我们需要一个路由函数decide_next_step。
def decide_next_step(state):
revision_number = state["revision_number"]
if revision_number > 3: # 防止无限循环,最多修改3次
return "end"
critique = state["critique"]
if "报告质量很高" in critique: # 假设LLM会输出类似的话
return "end" # 审核通过,结束
else:
# 审核不通过,需要修改
return "rewrite_node" # 去重写节点
然后把这个路由逻辑添加到图中:
graph.add_conditional_edges(
"critique_node",
decide_next_step,
{"end": END, "rewrite_node": "rewrite_node"}
)
(END 是 LangGraph 中表示流程结束的特殊节点)
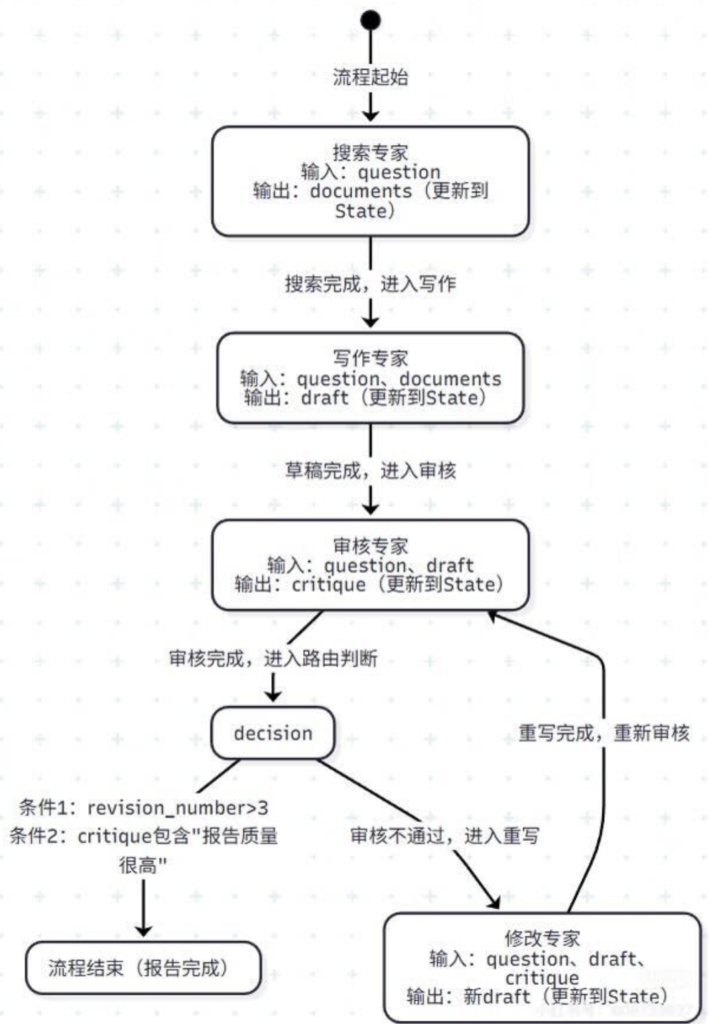
🔹第四步:组装并运行!
把以上所有都组装到 Graph 对象里,然后编译。现在,让我们看看当用户提问 “LangGraph 是什么?” 时,整个流程是如何运转的:
- [启动] ->
State = {"question": "LangGraph是什么?", ...} - 🔵
search_node:搜索关于 LangGraph 的文章,把结果放进documents。 - 🔵
draft_node:根据documents写出第一版草稿,更新draft。 - 🔵
critique_node:审稿人 LLM 看了草稿,觉得 “定义不够清晰,缺少例子”,把这个意见更新到critique。 - 🚦
decide_next_step(条件边):路由函数检查critique,发现不通过 -> 决定去rewrite_node。 - 🔄
rewrite_node:修改专家 LLM 看到了草稿和修改意见,重写了一版更清晰的,更新了draft。 - 🔵
critique_node:审稿人再次审核新草稿,觉得 “好多了,但可以再加一个对比 LangChain 的表格”,更新critique。 - 🚦
decide_next_step(条件边):路由函数再次检查,还是不通过 -> 再次决定去rewrite_node。 - 🔄
rewrite_node:再次修改草稿…
- …… 这个 “重写 – 审核” 的循环可能会持续几次…
- 🔵
critique_node:这一次,审稿人 LLM 说:“报告质量很高,阐述清晰,例子生动。” - 🚦
decide_next_step(条件边):路由函数检查到 “质量很高” -> 决定去end。 - ✅ [结束]:流程结束,最终的
draft就是高质量的成品。
这里,通过 LangGraph,我们构建了一个拥有 “自我反思” 和 “迭代改进” 能力的 AI 系统。它不再是一条道走到黑,而是像人类专家团队一样,通过协作、评审和修正,来逐步提升工作成果的质量。整个过程清晰、可控,越来越像一个真正的 team 了!
五、最后再来总结一下🔖
其实,LangGraph 的概念比 LangChain 要抽象和复杂得多。你可能会问:我一个产品经理,理解这么底层的架构有什么用?它的用处,是思维层面的升华:
- 洞察顶级 AI 应用的底层框架:当你再看到那些能与你进行多轮深度对话、能帮你写论文、能帮你分析数据的顶尖 AI 应用时,你脑海里浮现的将不再是一个 “聊天框”,而是一张复杂的、由节点和边构成的 “图”。你知道它内部可能正在进行着 “搜索 – 草拟 – 批判 – 重写” 的循环。这种洞察力对于产品经理而言,实属可贵。
- 理解智能的本质:LangGraph 揭示了,高级的 “智能” 行为,很多时候可以被拆解为:一个共享的状态 + 一系列专业化的技能模块 + 一套灵活的决策规则。这不仅是构建 AI 的范式,甚至可以用来反思我们人类自己的学习和工作方式。我们是如何通过 “试错 – 反思 – 修正” 的循环来掌握一项新技能的?
- 理解 AI 的未来:未来,我们与 AI 的关系,将不再是简单的 “你问我答”。我们会成为 AI 工作流的设计者和指挥者。我们会像使用 LangGraph 一样,去编排多个 AI 智能体,让它们协同工作,去解决我们单凭人力或单个 AI 无法解决的宏大问题。理解 LangGraph,你离未来的 AI 时代就更近了一步。