背景 🔖
假如我们有一个员工手册,做 RAG(检索增强生成),那么应该如何分块准备我们的文档,并更新到向量数据库中呢。

核心策略 🔖
🔹按“语义结构/标题”分割 (Structure-based Splitting)
Word文档是层级结构(章 -> 节)。这是最天然的分割边界。不要盲目使用固定字符数(如每块500字)切割,否则容易把一条完整的规定切成两半,导致上下文丢失。
建议方案:MarkdownHeaderTextSplitter (或类似逻辑)
如果你的源文件是 Word/PDF,先将其转换为 Markdown 格式,保留标题层级(# 第一章,## 1、公司简介)。利用 LangChain 或 LlamaIndex 的 MarkdownHeaderTextSplitter,以标题为界限进行切分。
🔹关键技巧:元数据增强 (Metadata Injection)
这是做规章制度 RAG 最重要的一点。
如果你只切分出一段文字:“迟到 30 分钟以上按旷工处理”,当用户问“考勤怎么算?”时,检索还能匹配。但如果文档里有两处“处罚规定”(一处在行政,一处在业务),LLM 就会混淆。
你应该将父级标题加入到每一个 Chunk 的元数据或开头中。
错误的 Chunk:
迟到30分钟扣除半天工资...
正确的 Chunk (包含上下文):
[第二章 人力资源管理 - 3、考勤管理制度]
迟到30分钟扣除半天工资...
建议: 在分割时,强制让每个切片都带上路径:第一章企业文化 > 3、员工守则。
🔹进阶策略:父文档检索 (Parent Document Retrieval)
对于规章制度,最怕“断章取义”。
- 做法:
- 切分(小): 将文档切得很细(比如按具体的每一条规则切分),用于检索。这样匹配精度极高。
- 存储(大): 每一个小切片都关联它的“父块”(比如整个“考勤管理制度”这一节)。
- 生成: 当检索到某条规则时,不只把这句话给 LLM,而是把整节内容给 LLM。
- 好处: 如果用户问“请总结一下考勤制度”,小块检索能定位到相关内容,而大块上下文能让 LLM 写出完整的总结,而不是只回答某一条规则。
🔹总结参数建议 (作为起步配置)
如果使用 LangChain/LlamaIndex,针对此类文档的起步配置建议如下:
- Chunk Size (块大小): 512 – 1000 Tokens (规章制度通常比较精炼,太大了容易混杂不同主题)。
- Chunk Overlap (重叠): 100 – 150 Tokens (防止一句话被切断)。
- Splitter: 优先
MarkdownHeaderTextSplitter(按 #, ## 分割),如果没法转 Markdown,则使用RecursiveCharacterTextSplitter。 - Embedding 模型: 推荐支持中文较好的模型(如 BGE-M3, OpenAI text-embedding-3-large)。
不要把它们当成纯文本,要当成树状数据库来处理。保留“章节-小节”的层级关系是回答准确的关键。
为什么要把word转成markdown 🔖
做 RAG 时,数据清洗和结构化(ETL) 往往比模型本身更重要。
我分两部分来回答:先解释为什么要这么折腾转成 Markdown,再手把手教你怎么用代码实现。
为什么要费劲把 Word 转成 Markdown?
直接读取 Word 或 PDF 提取纯文本(Plain Text)然后切割,通常会有以下几个致命问题,而 Markdown 能完美解决:
🔹纯文本丢失了“层级结构”
- Word/纯文本的问题: 在 Word 里,你看到“第一章”是加粗放大的,但在机器眼里,那就是一串普通的字符。如果你按每 500 字切割,切片器根本不知道“考勤制度”是从哪行开始、哪行结束的。
- Markdown 的优势: Markdown 用
#、##、###显式地标记了层级。机器一看到#就能确定:“哦,这里是一个新章节的开始”,从而实现按语义边界精准切割,而不是傻傻地按字数切。
🔹RAG 最核心的痛点:丢失上下文(Context Lost)
- 场景: 假设文档里有两处提到“罚款 100 元”,一处在《考勤制度》,一处在《保密制度》。
- 普通切割: 切出来一段话:“违反规定者罚款 100 元”。
- 用户问:“迟到罚多少?” -> 检索到了这段话。
- LLM 回答:“罚 100。”(错! 也许迟到只罚 50,那段话其实是说泄密的)。
- MarkdownHeader 切割: 它会自动把标题“继承”下来。
- 切出来的块自带元数据:
{'Header 1': '保密制度', 'Content': '违反规定者罚款100元'}。 - LLM 就能根据元数据判断:“这段是保密制度的,跟考勤无关。”
- 切出来的块自带元数据:
🔹大模型(LLM)天生亲和 Markdown
GPT、Claude 等模型在训练时阅读了海量的 GitHub 代码和 Markdown 文档。相比于乱七八糟的纯文本,LLM 对 Markdown 的格式(列表、加粗、表格)理解能力极强,能更好地提取信息。
Chunk Overlap(块重叠)🔖
Chunk Overlap(块重叠) 是 RAG 文档分割中一个非常关键的参数。简单来说,就是让相邻的两个切片(Chunk)之间有一部分内容是重复的。
🔹形象的比喻
想象你在贴瓷砖或铺瓦片。如果你把瓦片边缘对得齐齐的(无重叠),一旦房子热胀冷缩,缝隙就会漏雨。
Chunk Overlap 就是让瓦片互相压住一部分,确保没有任何缝隙(信息)漏掉。
🔹为什么要用 Overlap?(解决“断章取义”的问题)
机器切分文档通常是很“傻”的,它可能会刚好在句子的中间、或者一个重要的关键词中间切了一刀。
举个具体的例子:假设你的员工手册里有一句话:
“严禁在办公区域吸烟,违者罚款500元。”
如果不设置 Overlap,机器可能刚好在第 10 个字切开了:
Chunk A (切片1): ...其他规定。严禁在办公区域吸
Chunk B (切片2): 烟,违者罚款500元。...
这时候会发生什么灾难?
语义丢失: Chunk A 只说了“吸”,没说是“吸烟”。Chunk B 说了“烟”,但没说“严禁”。
检索失效: 当用户问“吸烟怎么处罚?”时,向量数据库可能找不到这两个块,因为关键词“吸烟”被切断了,两个块的向量(Embedding)都跟“吸烟”这个概念相差甚远。
如果设置了 Overlap (比如重叠 5 个字):
Chunk A: ...其他规定。严禁在办公区域吸烟,违者
Chunk B: 吸烟,违者罚款500元。...
结果: 两个块里都完整保留了“吸烟”和“违者”这种关键连接词,保证了语义的连贯性。
🔹图解
假设 Chunk Size = 10,Overlap = 4:
原文: A B C D E F G H I J K L M N
Chunk 1: [ A B C D E F G H I J ]
|重叠部分|
Chunk 2: [ G H I J K L M N ... ]
你可以看到,G H I J 这部分内容在两个块里都出现了。
🔹设置多少比较合适?
通常建议 Overlap 设置为 Chunk Size 的 10% 到 20%。
针对你的员工手册/规章制度场景:
如果你的 Chunk Size 是 500 字符:
建议 Overlap = 50 到 100 字符。
规章制度通常句子比较短,50 个字符通常能覆盖半个句子,足够起到“承上启下”的作用。
如果你的 Chunk Size 是 1000 字符:
建议 Overlap = 150 - 200 字符。
Chunk Overlap 的作用就是给切分后的文档买一份“保险”,防止机器在切分时把重要的上下文联系(比如主语和谓语、条件和结果)给切断了。虽然这会稍微增加一点点数据库的存储空间(因为有重复内容),但为了检索的准确性,这是绝对值得的。
Word 转 Markdown🔖
MarkItDown 是微软(Microsoft)最近开源的一个 Python 库,它的设计目标就是极其简单地把各种乱七八糟的文件(Word, PDF, Excel, PPT)统统转成标准的 Markdown。
这就好比给 RAG 系统装了一个“万能翻译器”,把所有文件都变成大模型最爱读的格式。
首先在你的 Python 环境中安装它:
pip install markitdown
最简单的用法(处理 Word/PDF)
假设你有一个文件叫 员工手册.docx 或者 员工手册.pdf。
from markitdown import MarkItDown
# 1. 初始化转换器
md = MarkItDown()
# 2. 转换文件 (支持 .pptx, .docx, .xlsx, .pdf 等)
# 只要把文件路径传进去,它会自动识别格式
result = md.convert("员工手册.docx")
# 3. 打印结果
# result.text_content 就是转换好的 Markdown 文本
print(result.text_content)
# 4. (可选) 保存成 .md 文件,方便后续查看或给 Splitter 使用
with open("员工手册_converted.md", "w", encoding="utf-8") as f:
f.write(result.text_content)
print("转换完成,已保存为 md 文件")
它会发生什么?
- Word 里的一级标题会被转成
# 标题 - Word 里的二级标题会被转成
## 标题 - Word 里的表格会被转成 Markdown 的表格格式
| 列1 | 列2 | - Word 里的图片通常会被忽略或保留占位符(除非使用高级的多模态功能)。
转完以后,发现是md文件这样的。

**第一章 企业文化** <-- 机器:这是普通文本,跳过。 内容内容... **1、公司简介** <-- 机器:这是普通文本,跳过。 内容内容...
机器找不到任何 #,认为整篇文章就是一大坨没有结构的文字。所以它只能放弃结构切割,导致你只得到了 1 个巨大的块,元数据是 {}。
🔹解决方案1:修改原始word文件
- 在 Word 顶部工具栏,点击 “标题 1” (Heading 1)。
- 选中“1、公司简介”,点击 “标题 2” (Heading 2)。
- 保存,重新运行 MarkItDown 转换,再运行分割代码。这样转出来的就是标准的 # 和 ##,分割器立马就能识别,元数据也就有了。
🔹解决方案2:把word变成一张张图片,扔给大模型生成markdown。
这是一个非常暴力但有效的方案,业内称为 “Visual ETL” (基于视觉的数据清洗)。
对于包含复杂排版、流程图(如你的组织架构图)、手写签名或表格的 Word 文档,这种方法的效果远好于传统的 Python 解析库。但它的成本较高(Token 消耗大)。
核心策略:Word -> PDF -> 图片 -> LLM -> Markdown
Prompt 模板 (建议直接复制):
Role: 你是一个专业的文档数字化专家。
Task: 我会给你一张企业文档的图片(第 {page_num} 页)。请将其内容精准转换为 Markdown 格式。
Rules:
保留层级: 根据视觉上的字体大小和加粗,严格判断标题层级(使用 #, ##, ###)。不要把普通加粗文本误判为标题。
图表转译: 如果遇到“组织架构图”、“流程图”,不要忽略,也不要只写“图片”。必须将其转化为 Markdown 列表或文字描述,详细说明层级和关系(例如:CEO下设...)。
表格处理: 遇到表格,必须还原为 Markdown Table。
原样输出: 不要写“这是文档的第几页”这种废话,直接输出文档内容。
跨页处理: 如果页面末尾句子没写完,不要强行补全,保留原样,我会在后期拼接。
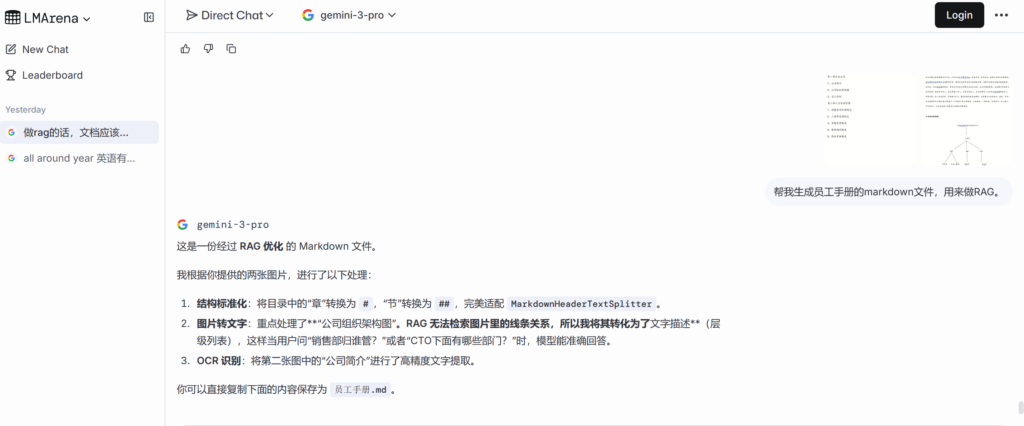
# 第一章 企业文化
## 1、公司简介
上海斯俊慕智能科技有限公司,成立于 2015 年 1 月 9 日,坐落于上海浦东。互联魔方致力于打造企业消费全程管理数字化中台。中台系统分为费控系统、商旅系统、采购系统、结算及对账系统等模块。
通过费控系统掌握和发起费用资源、商旅和采购系统参与管理供应商、结算和对账系统提供数据管理、收付款、供应链金融等服务,实现大中型企业消费支出的全过程、全生命周期管理。互联魔方深度参与这些管理,获取软件收入、供应商接入收入、交易分成收入、支付结算收入以及供应链金融服务收入,场景丰富,收入来源多样,市场潜力巨大。
通过前期系统实施耕耘,互联魔方已经在银行、保险、信托、企业集团等行业拥有 40 多家客户(代表客户有太保集团、大地保险、人保养老、包商银行、长沙银行、中信信托),正在这些客户拓展企业消费全场景服务。
## 2、公司组织架构图
公司的组织架构层级如下:
1. **顶层结构**:上海斯俊慕智能科技有限公司 -> 总经办
2. **核心管理层**:下设 CEO、COO、CTO 三大核心职位。
3. **各职能部门划分**:
* **CEO (首席执行官) 管辖**:
* 财务部
* 行政人事部
* **COO (首席运营官) 管辖**:
* 销售部(下设两个大区):
* 南方大区
* 北方大区
* **CTO (首席技术官) 管辖**:
* 技术部(下设三个中心):
* 研发中心
* 运维中心
* 项目中心
把md文件chunks分块 🔖
把分割好的md文件合并成一个整体total.md,review一下,看到不合适的地方调整一下。

然后用下面的方法分割块,并生成chunks文件
import os
from langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
# 定义文件路径 (记得加 r 防止转义)
file_path = r"C:\work\langchai\RAG\md\total.md"
# 读取本地 Markdown 文件
if not os.path.exists(file_path):
print(f"❌ 错误:找不到文件 {file_path}")
else:
try:
# 【关键】encoding="utf-8" 不能少,否则中文会乱码
with open(file_path, "r", encoding="utf-8") as f:
markdown_text = f.read()
print(f"✅ 成功读取文件,共 {len(markdown_text)} 个字符")
# 按标题结构切分
headers_to_split_on = [
("#", "Chapter"),
("##", "Section"),
("###", "Subsection"), # 如果有三级标题
]
md_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_docs = md_splitter.split_text(markdown_text)
print(f"✅ (结构分割)完成,共 {len(md_docs)} 个章节块")
# 按长度 + Overlap 二次切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每块约500字
chunk_overlap=50, # 重叠50字
separators=["\n\n", "\n", "。", "!", ","]
)
final_docs = text_splitter.split_documents(md_docs)
print(f"✅ (长度分割)完成,共 {len(final_docs)} 个最终切片\n")
output_path = r"C:\work\langchai\RAG\md\chunks_preview.txt"
with open(output_path, "w", encoding="utf-8") as f:
for i, doc in enumerate(final_docs, start=1):
f.write(f"--- Chunk {i}/{len(final_docs)} ---\n")
f.write(f"【元数据】: {doc.metadata}\n")
f.write("【内容】:\n")
f.write(doc.page_content + "\n")
f.write("-" * 80 + "\n\n")
print("✅ 已将所有 Chunk 写入:", output_path)
except Exception as e:
print(f"❌ 处理出错: {e}")
检查下生成好的chunks_preview.txt

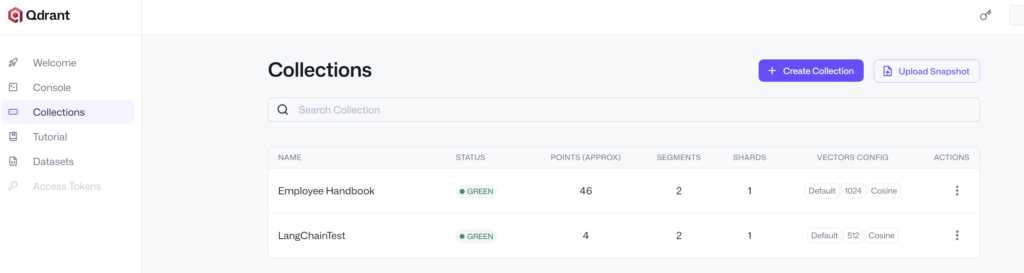
把chunks块登录到Qdrant向量数据库中 🔖
如果chunks块没问题的话,可以进一步登录到Qdrant向量数据库。
用下面的代码执行就可以了。
import os
from langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
# ========== 新增:写入 Qdrant ==========
from qdrant_client import QdrantClient
from langchain_qdrant import QdrantVectorStore
from langchain_huggingface import HuggingFaceEmbeddings
# 定义文件路径 (记得加 r 防止转义)
file_path = r"C:\work\langchai\RAG\md\total.md"
# Qdrant 配置
QDRANT_URL = "http://xxx:6333/" # 你的集群地址
QDRANT_API_KEY = "xxx" # 你的 API Key
COLLECTION_NAME = "Employee Handbook" # 集合名称
# 对应维度1024
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-m3",
model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
# 创建 Qdrant 客户端
client = QdrantClient(
url=QDRANT_URL,
api_key=QDRANT_API_KEY,
)
# 读取本地 Markdown 文件
if not os.path.exists(file_path):
print(f"❌ 错误:找不到文件 {file_path}")
else:
try:
# 【关键】encoding="utf-8" 不能少,否则中文会乱码
with open(file_path, "r", encoding="utf-8") as f:
markdown_text = f.read()
print(f"✅ 成功读取文件,共 {len(markdown_text)} 个字符")
# 按标题结构切分
headers_to_split_on = [
("#", "Chapter"),
("##", "Section"),
("###", "Subsection"), # 如果有三级标题
]
md_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_docs = md_splitter.split_text(markdown_text)
print(f"✅ (结构分割)完成,共 {len(md_docs)} 个章节块")
# 按长度 + Overlap 二次切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每块约500字
chunk_overlap=50, # 重叠50字
separators=["\n\n", "\n", "。", "!", ","]
)
final_docs = text_splitter.split_documents(md_docs)
print(f"✅ (长度分割)完成,共 {len(final_docs)} 个最终切片\n")
# 先创建向量库对象
vectorstore = QdrantVectorStore(
client=client,
collection_name=COLLECTION_NAME,
embedding=embeddings,
)
# 把文档写进去
vectorstore.add_documents(final_docs)
print("✅ 已将切片写入 Qdrant")
except Exception as e:
print(f"❌ 处理出错: {e}")
可以看到都正常登录到Qdrant向量数据库中了,件数和chunks数量是一样的,都是46

RAG为什么要分块呢? 整个文本扔到向量数据库中呢? 🔖
🔹向量检索的“粒度”问题
Embedding 是对“一段文本”做压缩,变成一个向量。
- 如果你把整本员工手册(几万字)做成一个向量:
- 这个向量里混着“公司简介 + 架构图 + 考勤 + 薪酬 + 离职……”
- 用户问“迟到怎么罚?”
检索只能命中“这本书整体”,然后你还要自己在这几万字里再全文搜索一遍,等于又回到了传统检索。 - 向量相似度在“太大一坨文本”上其实不敏感:很多不同问题都会命中同一个大块。
🔹大模型上下文长度有限
即便你不做检索,只想“把整本手册一次性塞给模型”:
- GPT-4o / Claude 3.5 上下文是几万 token,但:
- 你的库不止一份手册,将来有更多文档;
- 检索时通常会取 top-3 / top-5 个 chunk,一拼容易超限;
- 即使勉强塞得下,模型在超长上下文里会“丢中间内容”(长文本遗忘问题,Lost in the Middle)。
让“每次送进模型的文本”控制在一个合理范围(比如 2k–4k token 以内),既不超上下文,也不淹没重点。
🔹不分块会牺牲“定位能力”
想象两种极端:
A. 全文一个向量
- 检索结果:永远只返回同一个文档。
- 模型要在一大坨里自己找“哪一段说了迟到罚款 50 元”,等于让它自己做全文检索,容易漏、容易幻觉。
B. 合理粒度的分块(比如每 400~800 字,一个条款或几条高度相关的条款)
- 检索:问“离职流程”,能直接命中“离职管理”的几块,而不会命中“公司简介”。
- 模型:直接基于几块相关内容组织答案,错误率和幻觉都会下降很多。
🔹为什么不是“越小越好”?
你可能会问:那我按“每一句话一个向量”是不是最好?
也不行:
- 句子太短,embedding 信息量不足,“这句”和“那句”在向量空间里特别像,容易召回噪声。
- 例如:“公司有权解除劳动合同。”
这类句子单独拿出来,跟很多别的制度句子在向量上非常接近。 - 另外,回答问题通常需要前后几句一起看,只给模型一句话,它也无法判断上下文。
所以分块的目标是:“足够长来表达完整语义,又足够短来精确定位”。
大模型能理解大文档的全部内容吗? 🔖
能“部分理解”,但做不到像人那样完全、精确地掌握一整本长文档的所有细节,主要受两类限制:
🔹硬限制:上下文长度(context length)
每个模型都有最大“可看”的 token 数:
- GPT‑4o / Claude 3.5 Sonnet:几十 K~上百 K token
- 你的一本员工手册:几万字以内,一般可以一次性塞进去
但有两个现实问题:
- 一旦超出窗口,多余的内容直接看不到
塞进去的东西太多,模型就像“只读了前面 N 页,后面根本没翻到”。 - 即使没超,模型对很长上下文的记忆是“有偏的”
研究里有个现象叫 Lost in the Middle:- 开头和结尾的信息保留得比较好
- 中间的内容容易被忽略、权重变低
所以“能放进去 ≠ 能同等重视每一段”。
🔹软限制:推理注意力和指令
就算你把整本文档完整塞进模型,效果也高度依赖于你问的问题和提示词:
- 问:“总结一下公司所有制度”
→ 模型会挑重要的、显眼的内容概括,细节大量丢失,很难穷举全部条款。 - 问:“试用期最长多久、结算工资怎么发?”
→ 如果相关段落本身还在上下文范围内,它通常能准确找到那几条来回答。
🔹为什么还要 RAG + 分块
正是因为模型对“超长全文”的理解有以上问题,才有了 RAG:
- 先用向量检索,在大文档里锁定几段最相关的内容
→ 减少无关噪声,避免把整本书都丢给模型。 - 给模型看的只是若干块高相关片段
→ 每块几百 token,模型能“精读”,回答细节更准,幻觉更少。 - 分块+元数据,让模型既知道“这句话怎么说”,也知道“它属于哪一章哪一节”,
→ 回答时既具体又有上下文。