转载:https://www.zhihu.com/question/561078975/answer/1956297309785658762
什么是Embedding?🔖
简单来说,Embedding就是把文字、图片或其他数据转换成数字的形式,让计算机能够理解和处理。就像我们给每个单词分配一个「数字身份证」,但这个身份证不是简单的编号,而是包含丰富信息的「多维特征向量」。
Embedding 模型的核心价值在于将非结构化文本转化为数值向量,解决语义理解与计算效率问题.
先举一个生动的栗子
想象一下,我们要给世界上所有食物编码:
汉堡:[-0.2, 0.8, 0.3] 沙拉:[0.5, -0.3, 0.1] 冰淇淋:[0.1, 0.9, -0.4]
数字的正负和大小代表了食物的特征(如甜度、健康程度、温度)。这样计算机就能通过数字计算发现「汉堡和冰淇淋都是高热量食物」。
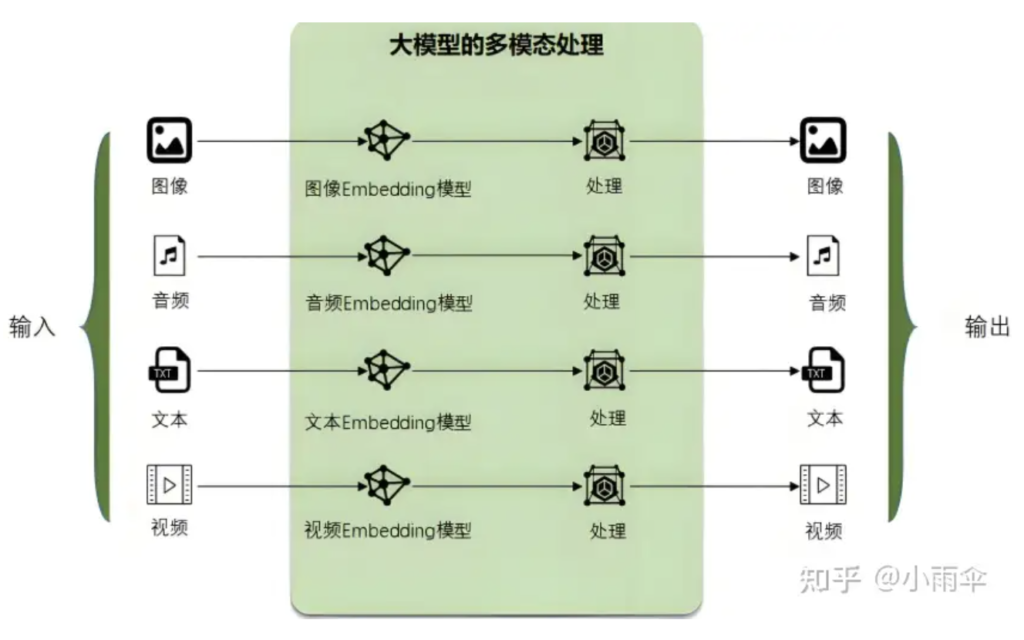
Embedding就是大模型自己的语言,任何需要跟大模型沟通的文字、图像、视频都需要转换为大模型所能理解的语言:Embedding,它才能处理。处理完成后,它再翻译成人类能理解的文字、图像等。这也是大模型最强大的核心能力之一,多模态处理能力.
Embedding的一些案例 🔖
🔹语义编码:通过向量空间捕捉上下文关联,区分多义词、同义词;如:
问题:用户搜索“苹果”,需区分“水果”还是“品牌”。
Embedding 作用:
"苹果手机"的向量 会接近 "iPhone"智能手机; 而"红苹果"的向量 会接近 "水果" "香蕉" "维生素"。
结果:搜索“苹果”时,优先展示手机或水果,取决于用户历史行为(如点击电子产品)。
🔹高效检索:支持近似最近邻(ANN)算法,降低海量数据匹配复杂度;
场景:某电商平台有 1 亿商品描述,需实时匹配用户查询“适合露营的轻便帐篷”。
传统方法:关键词匹配“露营+轻便+帐篷”,可能漏掉“户外超薄遮阳篷”。
Embedding 方案:
将查询和商品描述转为向量; 使用 ANN 库(如 FAISS )在毫秒级返回
Top100 相关商品,覆盖语义相似但关键词不匹配的结果。
🔹AI 基础设施:支撑 RAG 、多模态搜索、迁移学习等任务,替代传统关键词匹配与人工规则。
场景:客服机器人回答“如何清洁帐篷上的污渍?”
流程:用 BGE-M3 将问题编码为向量;
从向量数据库检索《户外用品保养指南》中相关段落; 将检索结果输入大模型(如DeepSeek-R1),生成步骤清晰的回答。
优势:避免大模型虚构答案,提升可信度。
重点:代码实战 🔖
🔹好,接下来直接上代码,看Embedding如何工作
# 导入必要的库
from sentence_transformers import SentenceTransformer
# 加载模型
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
# 定义句子列表
sentences = [
'我喜欢吃苹果',
'苹果公司9月要发布新手机iPhone 17',
'今天的天气真好,蓝天白云',
"香蕉是一种热带水果"
]
# 生成Embedding向量
embeddings = model.encode(sentences)
print("生成的Embedding的向量维度:", embeddings.shape)
# 输出全部
# print("Embedding向量的具体内容:", embeddings)
# 输出上面句子的向量前10维
for i, sentence in enumerate(sentences):
print(f"'{sentence}': {embeddings[i][:10]} ...")
# 计算句子间的相似度
from sklearn.metrics.pairwise import cosine_similarity
# 计算余弦相似度
similarities = cosine_similarity(embeddings)
print("句子相似度矩阵:")
for i in range(len(sentences)):
for j in range(len(sentences)):
if i <= j: # 避免重复输出
sim = similarities[i][j]
print(f"'{sentences[i]}' vs '{sentences[j]}': {sim:.3f}")
输出如下:
生成的Embedding的向量维度: (4, 384) '我喜欢吃苹果': [-0.37381974 1.1482197 -0.10418612 0.09360497 -0.66173714 0.2802788 1.6347399 0.14204119 0.8921655 -0.16619411] ... '苹果公司9月要发布新手机iPhone 17': [-0.2590392 0.6924811 0.18627527 -0.5357205 -0.07483669 -0.19914986 0.8918247 0.05937493 0.6875115 0.24681543] ... '今天的天气真好,蓝天白云': [-0.3749065 0.74014777 0.16411266 -0.21965387 -0.48084465 -0.22723575 1.4115497 0.11568774 0.76047236 -0.31601837] ... '香蕉是一种热带水果': [-0.11292891 0.5817749 0.06361266 0.02144676 -0.511007 0.1269096 1.2333398 0.3227354 1.0315524 0.00547485] ... 句子相似度矩阵: '我喜欢吃苹果' vs '我喜欢吃苹果': 1.000 '我喜欢吃苹果' vs '苹果公司9月要发布新手机iPhone 17': 0.445 '我喜欢吃苹果' vs '今天的天气真好,蓝天白云': 0.782 '我喜欢吃苹果' vs '香蕉是一种热带水果': 0.823 '苹果公司9月要发布新手机iPhone 17' vs '苹果公司9月要发布新手机iPhone 17': 1.000 '苹果公司9月要发布新手机iPhone 17' vs '今天的天气真好,蓝天白云': 0.642 '苹果公司9月要发布新手机iPhone 17' vs '香蕉是一种热带水果': 0.544 '今天的天气真好,蓝天白云' vs '今天的天气真好,蓝天白云': 1.000 '今天的天气真好,蓝天白云' vs '香蕉是一种热带水果': 0.866 '香蕉是一种热带水果' vs '香蕉是一种热带水果': 1.000
注:上面的代码会默认从hugging face官方仓库下载模型,需要翻墙!!!!!
🔹接下来再用ModelScope的方式实现一遍:(ModelScope阿里云提供的一个中文版的HuggingFace)
from langchain_community.embeddings import ModelScopeEmbeddings
# 初始化句子嵌入pipeline
model_id = "damo/nlp_corom_sentence-embedding_chinese-base"
embedding_model = ModelScopeEmbeddings(model_id=model_id)
# 定义句子列表
sentences = [
'我喜欢吃苹果',
'苹果公司9月要发布新手机iPhone 17',
'今天的天气真好,蓝天白云',
"香蕉是一种热带水果"
]
embeddings = embedding_model.embed_documents(sentences)
# 输出全部
# print("Embedding向量的具体内容:", embeddings)
# 输出上面句子的向量前10维
for i, sentence in enumerate(sentences):
print(f"'{sentence}': {embeddings[i][:10]} ...")
from sklearn.metrics.pairwise import cosine_similarity
# 计算余弦相似度矩阵
similarity_matrix = cosine_similarity(embeddings)
print("句子之间的余弦相似度矩阵:")
for i in range(len(sentences)):
for j in range(len(sentences)):
if i <= j: # 避免重复输出
print(f"'{sentences[i]}' vs '{sentences[j]}' 的相似度: {similarity_matrix[i][j]:.4f}")
输出如下:
'我喜欢吃苹果': [0.32604819536209106, -0.24579137563705444, 0.14939190447330475, -0.18595966696739197, -0.2441755086183548, -0.5086973309516907, -0.4876851439476013, -0.01850845105946064, 0.44076400995254517, -0.019114553928375244] ... '苹果公司9月要发布新手机iPhone 17': [0.1550225019454956, -0.2128225564956665, 0.2851581275463104, -0.8280717730522156, 0.5369096994400024, -0.7610117793083191, -0.14223024249076843, -0.8344448208808899, -0.31277164816856384, -0.0666898638010025] ... '今天的天气真好,蓝天白云': [0.6082981824874878, 0.3789174258708954, 0.004537384957075119, -0.027960695326328278, 0.46887874603271484, -0.5822398662567139, -0.4064663350582123, -1.11110520362854, 0.24349763989448547, 0.1817186176776886] ... '香蕉是一种热带水果': [0.38078010082244873, -0.6754599213600159, 0.1290031373500824, -0.14763924479484558, -0.011951431632041931, -0.23197220265865326, -0.3167392313480377, -1.2026702165603638, -0.014405147172510624, 0.2859038710594177] ... 句子之间的余弦相似度矩阵: '我喜欢吃苹果' vs '我喜欢吃苹果' 的相似度: 1.0000 '我喜欢吃苹果' vs '苹果公司9月要发布新手机iPhone 17' 的相似度: 0.4424 '我喜欢吃苹果' vs '今天的天气真好,蓝天白云' 的相似度: 0.4736 '我喜欢吃苹果' vs '香蕉是一种热带水果' 的相似度: 0.6298 '苹果公司9月要发布新手机iPhone 17' vs '苹果公司9月要发布新手机iPhone 17' 的相似度: 1.0000 '苹果公司9月要发布新手机iPhone 17' vs '今天的天气真好,蓝天白云' 的相似度: 0.4052 '苹果公司9月要发布新手机iPhone 17' vs '香蕉是一种热带水果' 的相似度: 0.4137 '今天的天气真好,蓝天白云' vs '今天的天气真好,蓝天白云' 的相似度: 1.0000 '今天的天气真好,蓝天白云' vs '香蕉是一种热带水果' 的相似度: 0.4308 '香蕉是一种热带水果' vs '香蕉是一种热带水果' 的相似度: 1.0000
两种实现方式大体上结果是一样的,因为是不同的模型,所以向量值会有差异。(上面两种实现方式三方依赖可能会存在冲突,建议使用不同的环境尝试喔!)
是不是很神奇!计算机通过Embedding发现:
- 1、「我喜欢吃苹果」和「香蕉是一种热带水果」相似度很高(都是水果)
- 2、但与「苹果公司」相似度很低(虽然都有”苹果”二字)
- 3、和「天气」基本不相关
这就是Embedding的魔力——理解语义而不仅仅是字面!
🔹为什么Embedding如此重要?
- 1、让计算机理解语言:不再是简单的关键词匹配,而是真正的语义理解
- 2、赋能推荐系统:Netflix、淘宝都在用Embedding理解你的喜好
- 3、驱动搜索引擎:Google搜索背后的核心科技之一
- 4、聊天机器人:ChatGPT等AI对话系统的基石
目前流行的Embedding模型 🔖
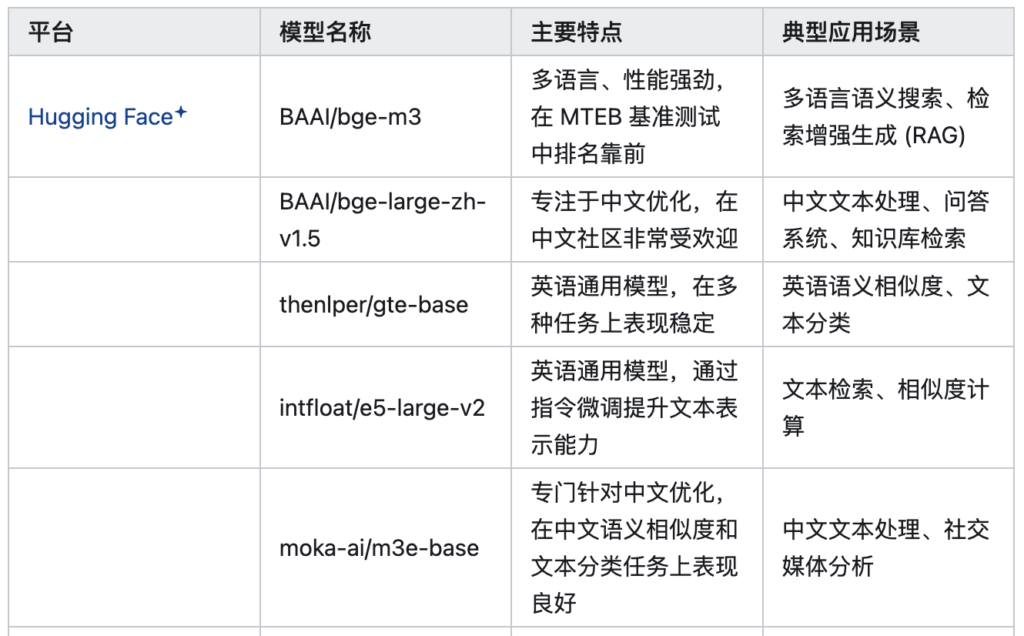
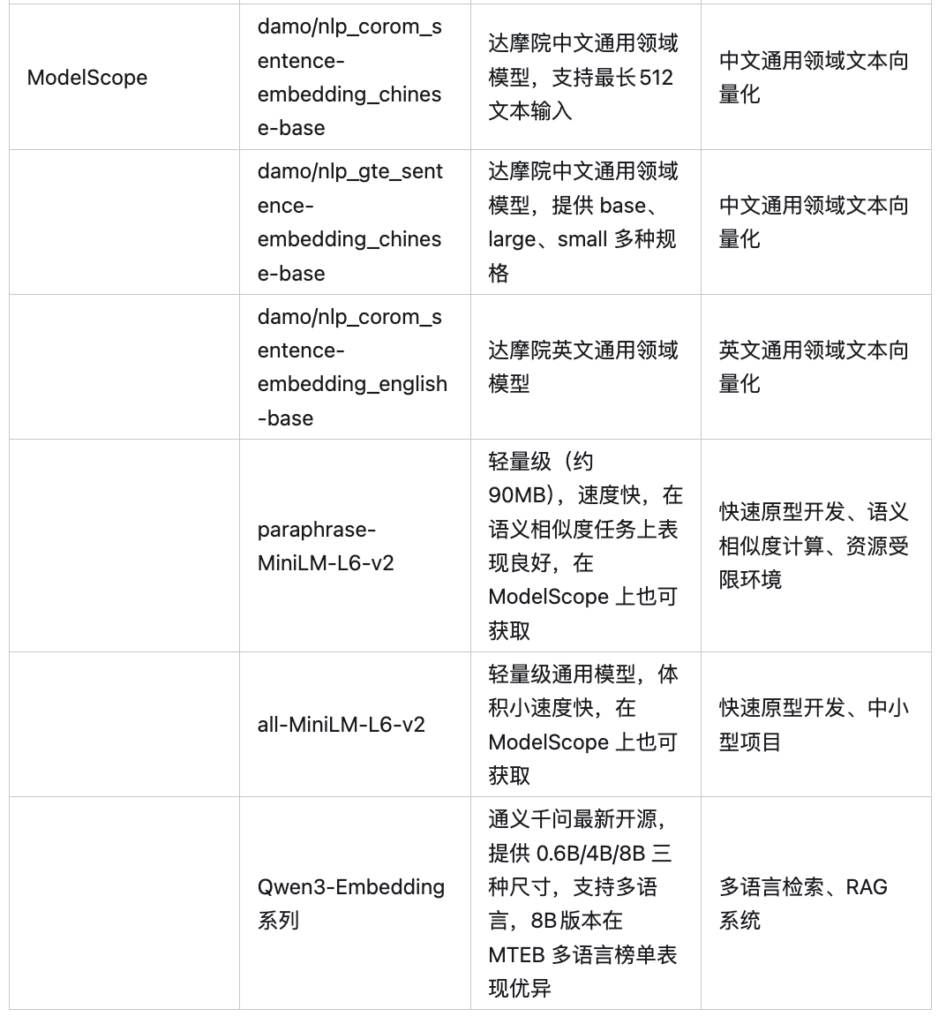
说在最后:Embedding就像是一座桥梁,连接了人类语言和计算机数字世界。它通过将文字转换为富含语义的数字向量,让机器能够真正「理解」我们的语言。下次当你使用智能搜索、推荐系统或与AI对话时,就知道背后是Embedding技术在默默工作啦!