索引:索引是帮助数据库高效获取数据的数据结构。
在 MySQL 中,索引(Index) 是一种特殊的数据结构,用于快速查询数据库表中的特定记录。它类似于书籍的目录,通过提前排序和存储关键信息,避免了全表扫描(逐行查找)的低效操作,从而大幅提升查询效率。
索引的核心作用
- 加速查询:通过索引可以直接定位到符合条件的记录位置,减少数据扫描范围。
- 优化排序:如果查询包含
ORDER BY或GROUP BY,索引可以避免额外的排序操作(利用索引本身的有序性)。
索引的工作原理
索引本质是对表中一列或多列的值进行排序,并存储这些值与对应记录物理位置(如磁盘地址)的映射关系。
- 当执行查询(如
WHERE 列名 = 值)时,MySQL 会先查询索引,找到符合条件的记录位置,再直接读取对应的数据。 - 没有索引时,MySQL 需要逐行扫描整个表(全表扫描),效率极低(尤其表数据量大时)。
关于索引的误解
- 索引并不是越多越好,索引太多,应用程序的性能可能会受到影响;索引太少,对查询性能又会产生影响。
- 索引最好是初始时添加,后续添加的话,会处理相当大的一部分数据。
- 初始时候让DBA添加,由于DBA往往不了解业务的数据流,往往添加得不够精确
索引的原理
索引的目的在于提高查询效率,本质是通过不断的缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的时间编程顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
b+树的查找过程
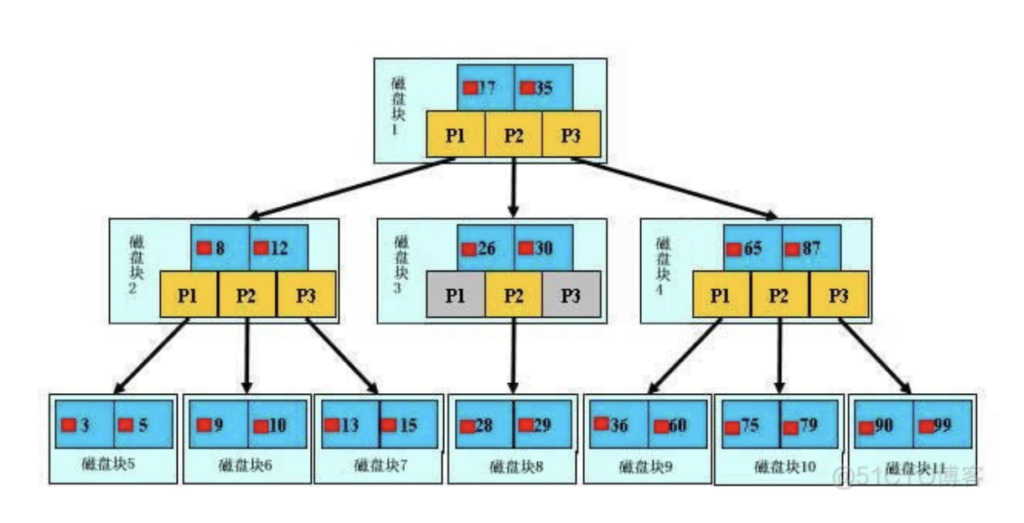
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。
3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
MySQL数据库中的索引并非建得越多越好。以下是一些理由说明为什么索引不是越多越有利:
- 1. 存储空间:索引需要占用额外的磁盘空间,每个索引都是对数据表的一部分数据进行排序后单独存储的结构。索引越多,占用的空间越大。
- 2. 写操作性能损耗:每当对表进行INSERT、UPDATE、DELETE操作时,如果涉及索引列,不仅要更新数据表本身,还需要更新相关索引,这会增加写操作的开销,降低写入速度。
- 3. 维护成本:随着数据的变化,索引需要不断地维护和更新以保持其正确性,这会消耗数据库服务器
- 的CPU和I/O资源。
- 4. 读取效率考虑:虽然索引可以提高查询效率,但不是所有查询都能从索引中受益。对于简单的查询或者数据量较小的表,全表扫描可能比使用索引更快。
- 5. 索引选择性:只有在查询中频繁使用,并且具有较高选择性的列上建立索引才有意义。选择性指索引列中不同值的数量与总行数的比例,选择性低的列(如性别字段,通常只有两个值)不适合做索引。
- 6. 过度索引:为不常使用的列或者已经在其他索引中覆盖到的列创建索引是没有必要的,这会导致不必要的资源浪费。
总结
综上所述,设计索引策略时应根据实际业务需求、查询模式、数据规模及更新频率等因素综合考虑,既要确保关键查询能得到有效加速,又要避免因过多索引带来的负面影响。因此,合理优化和选择性地创建索引才是最佳实践
不是,索引并不是越多越好,实际上索引数量过多,反而会导致一系列性能问题和系统负担。
1. 索引带来的好处
- ✅ 加速查询:索引可以极大提高 SELECT 查询的速度,减少数据扫描量。
- ✅ 加速关联(JOIN)查询:通过索引字段进行表关联,可以加速连接操作。
- ✅ 加速排序(ORDER BY)和分组(GROUP BY):索引可以避免额外的排序开销。
- ✅ 加速唯一性约束检查:如主键、唯一索引,插入/更新时可以快速验证数据是否重复。
2. 索引过多的坏处
- ❌ 增加写入和更新成本
每次 INSERT、UPDATE、DELETE 操作,除了更新数据本身,还需要同步更新所有涉及的索引。
索引越多,写入延迟越大,事务耗时越长。
- ❌ 占用更多磁盘空间
每个索引都会占用额外的存储空间。
尤其是复合索引(多个列组合索引)或冗余索引(功能重复的索引),容易造成空间浪费。
- ❌ 增加优化器决策开销
查询优化器在执行计划生成阶段,需要评估所有可用索引,索引越多,优化器的选择成本越大。
有时候优化器还可能选错索引,反而导致查询变慢。
- ❌ 可能导致索引失效
索引太多时,查询优化器为了省事,可能选择了并不最优的索引,尤其是在存在很多单列索引时。
3. 正确的索引策略
真正的高手会遵循:”索引应够用,不贪多。精准覆盖典型查询场景。“