TCP/IP的协议概念
IP又叫网际协议,负责将数据包从一个地方传送到另一个地方。TCP又叫传输控制协议,提供一种可靠的、面向连接的服务,用于在不可靠的IP层之上进行数据传输。
TCP/IP把数据传输分成4层,像快递的配送流程:
- 1、应用层:“你要寄什么?”
比如你告诉顺丰客服你要寄口红。你用的微信、小红书、淘宝(不同app属于不同快递公司)都在这一层,比如你的需求是用微信给朋友发送消息「周末约饭」。
- 2、传输层:“分装包裹+保价服务〞
负责把大件拆成小包裹,贴上序号,确保对方收齐后能拼回原样。
- 3、网络层:〝规划快递路线〞
像快递单地址(设备的“门牌号”(比如192.168.1.1)),告诉快递员送到哪。
- 4、数据链路层:“送货的快递员”
通过W-Fi、网线等物理方式把数据包送到目的地,就像快递员开车送货。
举个真实例子:你给朋友发微信说“周末约饭”
- 应用层把文字转成代码
- 传输层把数据拆成数据包+编号(比如拆成#1包=“周”、#2包=“末”)
- 网络层导航到朋友的手机地址
- 数据链路层通过Wi-Fi/5G传输一朋友收到你发的信息
当你用微信发消息时,文字先被微信打包(应用层),加上发送和接收的端口号(传输层),写上你和朋友的IP地址(网络层),最后通过WiFi或流量发出去(网络接口层)。整个过程就像发快递:内容一快递单 ~ 地址> 实际运输。
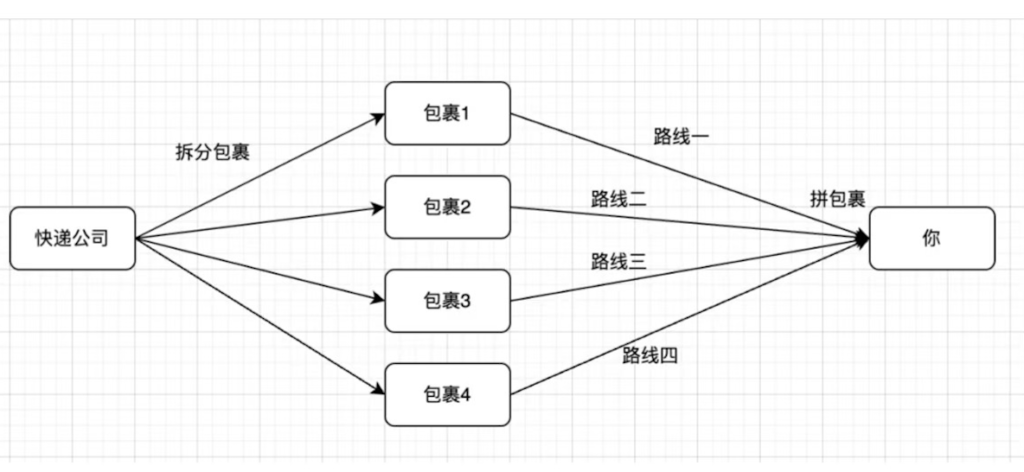
TCP/IP 就是互联网的“快递系统”,负责把数据(比如文字、图片、视频)从一台设备准确送到另一台设备。如果把互联网比作全球快递网,TCP/IP就是最牛的快递公司(顺丰),它会把你的所有大件拆成小包裹(数据分片),然后给每个小包裹贴快递单(IP地址),用多辆车派送走不同路线(路由器),后精准拼起来送到你家门口,收到后你再检查包裹是否完好(数据校验)。
HTTP和TCP之间的关系是怎样的呀?
HTTP在TCP之上,是应用层的协议,我们常用的小红书、微信就在这一层,也是我们程序员能直接看得到的协议。那HTTP是如何使用TCP的呢?
下面通过一个例子来详细解释:假设你在浏览器地址栏访问example网站,下面是浏览器和服务器的通信流程:
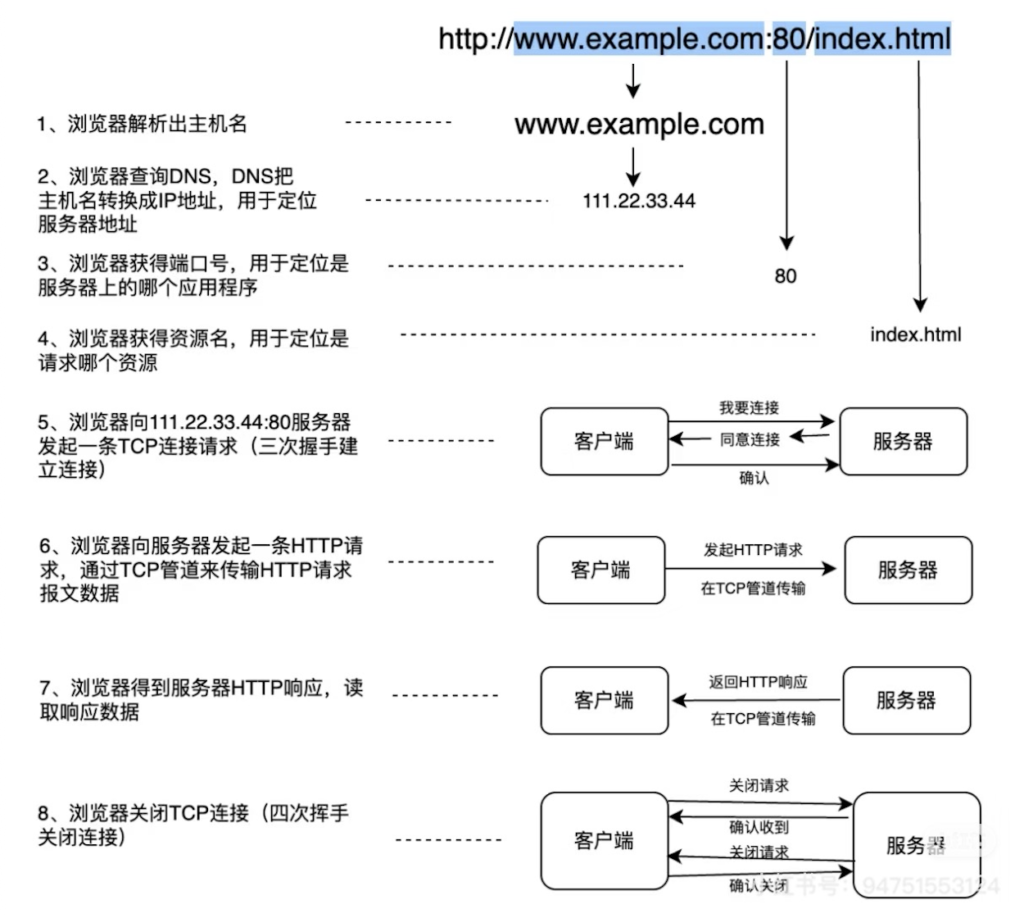
哦,所以说HTTP只关心发送的内容,TCP来负责传输HTTP数据。你的例子讲的是发起一个HTTP请求的情况,那如果同时发起多个HTTP请求呢,浏览器是怎么处理的?
这里有个发展历史,从HTTP1.0-> HTTP1.1->HTTP2,浏览器的处理方式都不一样,下面我将详细解释:
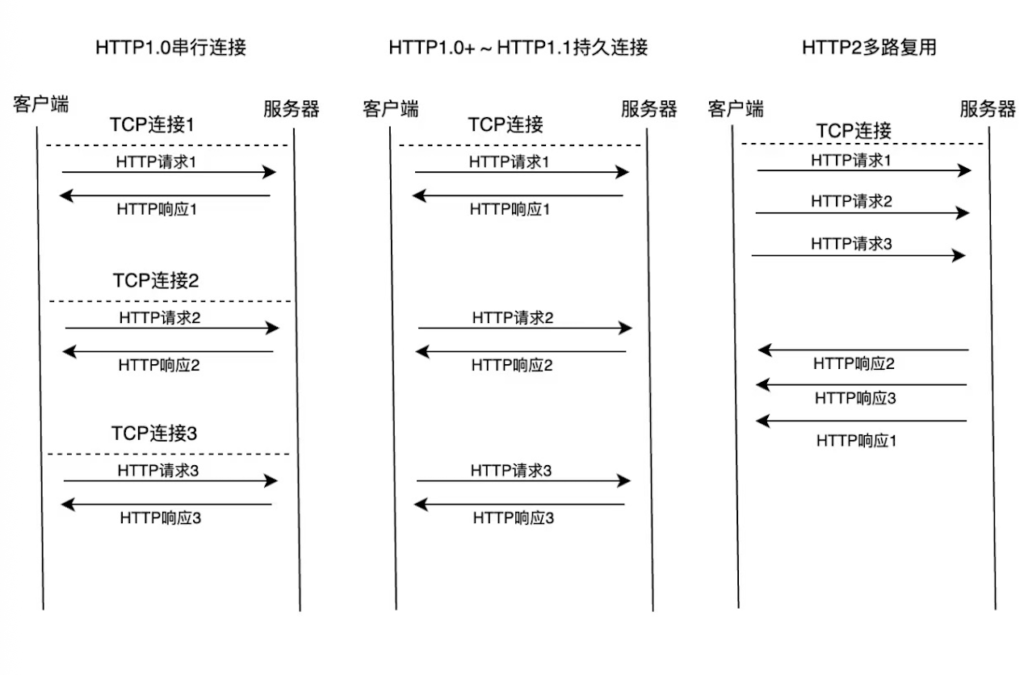
- 1、串行连接
最早期的时候(HTTP1.0),浏览器每发起一个HTTP请求,都会新建立一个TCP连接,并且必须等上一个HTTP请求回来,下一个HTTP请求才开始传输。由于建立一个TCP连接比较耗时(三次握手和慢启动机制),并且是串行处理HTTP请求,TCP延时就叠加了起来,当网页同时发起多个HTTP请求时,整体耗时较长,性能较差,所以这种机制就慢慢被淘汰了。
- 2、持久连接+顺序处理
从HTTP 1.0+到 HTTP1.1,持久连接是主流机制,基本所有浏览器和服务器都支持。那么什么是持久连接呢?即重用TCP连接,通过一个 TCP 连接按顺序处理多个请求,避免频繁建立连接的时间和资源开销。一般浏览器规定,同个域名下,可并行打开6~8个TCP连接,其中每个TCP连接都是可重用的,但是一个TCP连接上面的HTTP请求是按顺序处理的,必须等上一个请求响应回来,才能传输下一个请求。因为浏览器限制了TCP的最大连接数,所以当HTTP请求个数超过6个时,就要开始排队了,为了提高页面加载速度,所以很多程序员会在HTTP层面做优化,通过合并请求来减少并发请求个数。
这种方式确实减少了TCP连接,但是如果同一个TCP连接上面的某一个HTTP请求卡住了,后面在排队的HTTP请求也全部卡住,容易造成队头拥塞,所以就出现了http2的多路复用机制,继续往下看。
- 3、单连接多路复用+并行处理
HTTP2的多路复用机制,所有的HTTP请求和响应通过单条TCP连接来并发传输(一般来说同个域名下,只会建立一个TCP连接)。它具体是怎么实现的呢?它将每个HTTP请求数据和响应数据拆分为二进制帧,通过唯一的流 ID标记每个二进制帧,然后乱序发送,数据到达后再重新组装起来。
在单一连接上并发传输多个请求/响应,解决了队头阻塞问题。而且HTTP2以前,数据都是通过纯文本来传输的,HTTP2通过二进制传输,大大提高了传输效率~单一TCP连接上可同时处理数百个请求,这种方式解决了同一域名下请求数量的问题。
小结:下面通过一个图来总结下三种处理方式:
认识IP地址、域名和DNS
什么是IP地址呀?
接入互联网的每一台计算机会被分配一个逻辑唯一的IP地址,
一个IP地址由两部分组成:网络部分(标识子网络)和主机部分(标识设备)。
例如在192.168.1.198中,子网是192.168.1,主机是198。
IP地址有什么作用呢?
IP地址就像一套“分层的邮政编码”,前段用于定位城市(子网),后段用于定位街道(主机);
邮局(路由器)根据城市代号规划干线运输,到达后再按街道派送。IP地址的主要作用是确定计算机所在的子网络。比如你的电脑想要访问example.com网站时,路由器会通过IP地址找到目标网站的子网,
到达子网后,再通过ARP协议将目标IP解析为物理地址(MAC地址),通过物理地址,两台计算机就可以找到对方,就可以通信了。
那么计算机的IP地址是固定不变的吗?
不一定,IP地址又分为静态IP和动态IP。静态IP需要手动配置并且长期固定,适用于需要稳定公网问的服务器,但成本较高且需要专业管理。动态IP指的是在计算机开机后会被动态分配到的一个IP地址,因为动态IP能有效的利用地址资源,现在大多数都是动态IP上网。
IP地址、域名和DNS是什么关系呀
域名是IP地址的别名,因为IP地址不好记忆(比如192.168.1.1),而域名可读性更强,比如
example.com,所以人们通常就用域名来记忆一个网站的地址。DNS负责维护域名和IP地址之间的映射关系,它可以通过域名找IP地址,也可以反过来通过IP地址找域名,就像手机通讯录,通讯录助手可以把手机号码和人名映射起来。
一个域名可以映射多个IP地址吗?
可以呀。可以为同个域名配置多个IP地址,比如:
www.example.com 192.168.1.2
www.example.com 192.168.1.3
这种策略主要为了提高服务器性能,将用户的请求分散到多台服务器,避免单台服务器过载。
一个域名的层级结构是怎样的呀
一般来说,一个域名由至少三部分组成。
- 顶级域名:如.com、.cn,位于最右侧,代表域名类别或国家
- 二级域名:顶级域名的直接下级(如example.com ),是用户可注册的最高级域名
- 子域名(三级及以下):二级域名的左侧延伸(如news.example.com 中的 news),用于划分更细的子服务或部门
- 主机名:域名最左侧的部分(如www.example.com中的www),标识特定服务器或服务类型一般我们购买域名,购买的是一个二级域名的管理权,然后我们就可以在二级域名基础上去设置三级、四级域名等等。
什么是HTTP呀?
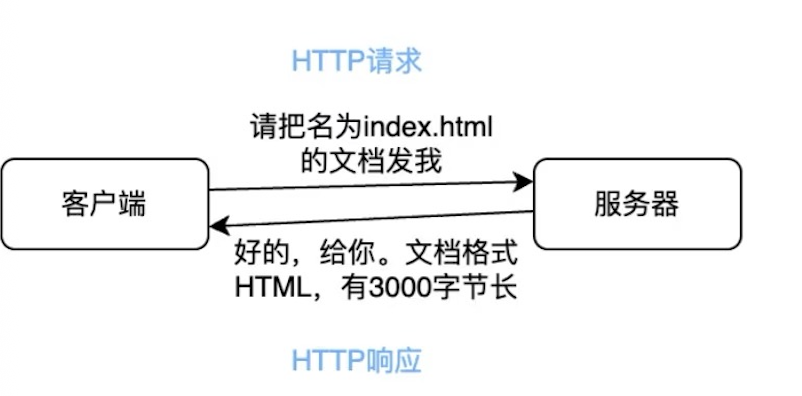
HTTP是–种「超文本传输协议」,说白了就是web客户端和服务器之间通信的一套规则。
其中超文本就是不止文本,即它不仅能支持传输文本,还支持图片、音频、视频等等。
web客户端具体指的什么呢?
web客户端指的是发起HTTP请求的载体,最常见的有浏览器、app,还有一些命令行工具
CURL、weget,还有开发者工具postman等等。当我们需要模拟请求的时候,可以使用CURL、postman这些工具哟~
web服务器又是啥?
从广义上来说,web服务器指的是web服务器软件和硬件,硬件部分指的是物理服务器(电脑主机+网络设备),存放网站文件和联网。这里的软件指的是Nginx、Apache等,它们主要职责是接收HTTP请求、调用后端应用程序、返回HTTP响应等等。
那HTTP有什么特征吗?
1、HTTP是一个没有状态的协议
指的是服务器不会登记和你的聊天记录(请求记录),你的上一次请求和下一次请求,服务器不知道是同一个人。
就好像你去线下奶茶店口头向店员点奶茶:
第一天:
你:“我要一杯芋泥波波”
店员:好的。
第二天:
你:"我要一杯杨枝甘露〞
店员:“你是哪位呀,之前点过奶茶吗”(服务器不记得你)
服务器默认是不会存和你的聊天记录的,除非你主动带“身份证”(Cookie/Token),它才能通过身份证来识别你哦。
2、必须是客户端主动向服务器发起请求,服务器才能响应(单向传输)
如果想实现服务器主动向客户端推送消息,可以使用“伪推送” 技术,比如长轮询,客户端定时向服务器发请求询问。或者使用全双工通信协议WebSocket,双方可随时主动发送数据。
但是在HTTP2中,可以说实现了半双工通信,服务器能“预判你的需求”,当浏览器请求主资源(如
HTML)时,服务器会主动推送相关资源(CSS/JS/图片)给浏览器,不需要浏览器再次请求CSS/JS/图片等资源了,减少了请求次数,页面加载更快了。
3、明文传输
HTTP报文数据就像明信片一样,在运输过程中可能会被偷看,因为它没有对数据加密(HTTPS才会加密,所以后期出现了HTTPS)。
一条HTTP请求或者响应的数据结构是怎样的呢?有哪些部分组成?
HTTP协议是由三部分组成的,分别是:
- 1、起始行:描述http基础信息,比如版本号,请求方法。
- 2、头部字段:key-value形式比如content-type: text/plain,是客户端和服务器之间通信的额外辅助信息,可以提高沟通效率。比如比如请求头Referer:XX,服务器就知道你是从哪个页面过来的。响应头content-type: application/json,客户端就知道你传的请求数据是json格式的。
- 3、消息正文:传送的主体消息。

一般会把起始行和头部字段合并起来叫请求头/响应头,在HTTP报文中叫Header。消息正文在HTTP报文中叫body。每条HTTP请求都需要带有Header,可以没有body。因为Header是客户端和服务器之间通信的辅助信息,可以提高沟通效率。
我看HTTP有好几个版本,有1.0、1.1、2.0等,目前看到用的比较多的是HTTP1.1和HTTP2.0,使用HTTP哪个版本,需要什么条件吗?
需要呀。必须要客户端(Chrome/Android/IOS等)和服务器(Nginx/Apache等)都支持HTTP xX版本,才能使用哦。
如果服务器支持HTTP2,但是客户端不支持HTTP2,那用户还能访问吗?
可以的,不支持2.0的客户端会自动降级为1.1,不需要额外配置。
认识cookie和session
上一期讲到HTTP是没有状态的,不会登记你和服务端的聊天记录,那么服务端是如何识别某个用户的呢?
可以通过cookie(不是唯一方法哈)来记录用户状态。cookie技术是通过在http请求头和响应头中写入cookie信息来控制用户状态的机制。
下面通过一个例子来解释:
我们思考一个问题,假设想对已经登录的用户进行状态管理,已经登录过的用户就不再跳转登录页,那我们怎么识别这个用户是已登录用户?
我们看一个简单的登录流程,
1、当用户第一次登录时,服务端会创建一个id来唯一识别这个用户(这个id叫 session id),
然后把id存在服务器内存(比如redis)或数据库中。
2、服务端创建完id后,就把这个id塞到一个叫set-cookie的响应头中,
告诉浏览器要存储这个cookie,当然cookie中不仅有session id,还有一些别的值。
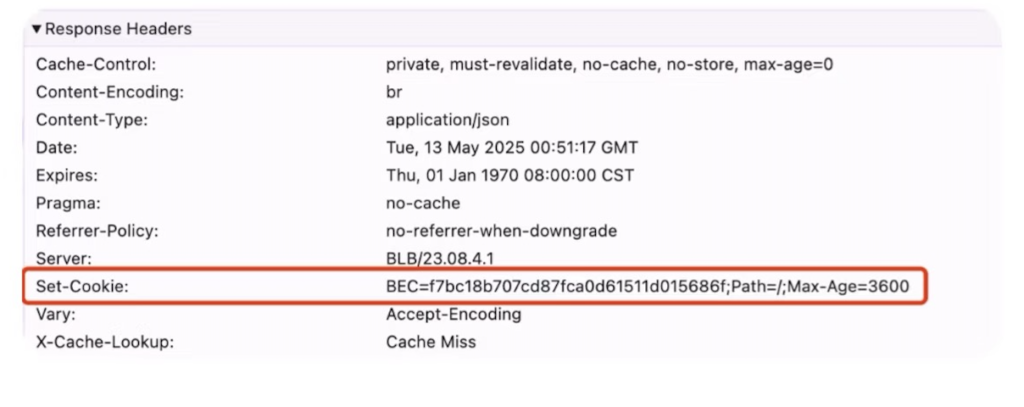
3、浏览器把cookie存储在浏览器内存后,在以后每次的http请求中,都带上这个cookie。
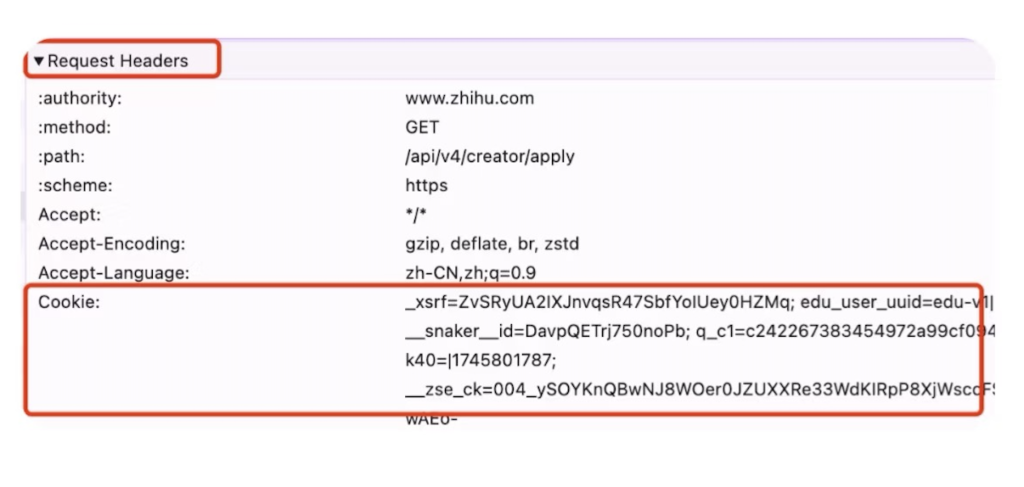
4、在以后每次的http请求中,服务端会把浏览器发送过来的cookie中的session id和后台里存的id 对比是否一致,如果一致则正常返回数据,如果不一致则返回未登录的状态给到浏览器,这时浏览器就会跳转到登录页。服务端把session id存储在缓存中后,session id还可以作为一个key值,下面可以存储一些当前用户的数据,比如用户id、名字、性别、城市等信息,当某个请求过来时,通过session id就可以拿到当前用户的id,就可以知道是哪个用户了。
那cookie中除了有sessionid,还有其他属性吗?
有呀。cookie是有大小限制的,一般是4KB左右,cookie中还有好几个属性,下面讲下我认为比较重要的几个:
- 1、expires属性
用于设置cookie的有效期,就是平时我们说的登录态有效期。假设你设置登录态有效期是1天,过了一天之后浏览器就不会发送该cookie给服务端了,这时候就会跳到登录页。
- 2、domain属性
domain属性用于指定cookie的有效域名,比如你把cookie指定到www.a.com,那浏览器只会在这个域名下的请求才会发送cookie。该属性可用于多域名登录态共享的场景。cookie可以指定在二级域名、三级域名下面,比如如果把域名指定在.a.com下面,那么 x.a.com、y.a.com的登录态(cookie)是共享的。
- 3、HttpOnly
为了确保Cookie的安全,一般会设置HttpOnly:true,即禁止 JavaScript 读取 Cookie。
- 4、Secure
因为HTTP是明文传输的,为了确保安全,一般会设置Secure:true,即仅在 HTTPS 连接下传输Cookie。
cooke和session之间是相互协作的关系。在服务端创建好session id响应浏览器后,cookie就被存储在浏览器。cookie和session id有着—一对应的关系。
认识跨域
什么是跨域呀?
为了保证网站安全,浏览器有一种安全策略,叫做同源策略(咱们经常会喊跨域)
同源策略是指浏览器阻止网页从一个源向另一个源:
- 1、发起网络请求(AJAX/Fetch)
- 2、访问页面DOM元素
- 3、读写其他源的本地存储( localStorage/IndexedDB)
- 4、共享cookie
这里的源指的是什么呢?
一个源由三部分组成:
- 协议(Protocol):http, https
- 主机名(Host ):www.example.com
- 端口号(Port):80、8080
只要有一个不同,就是不同源。比如http://a.com和http://b.com不同,a.com:80和b.com:8080不同。
那一个服务端向另一个服务端发起请求会有跨域问题吗?
跨域问题只存在于浏览器中,那是浏览器的安全策略,服务端向服务端发起请求是没有跨域问题的。
那么跨域请求问题就没法解决了吗?假设同个公司里面,当前网站的页面域名和请求的服务域名不同,该怎么办?当然,跨域请求问题也是可以解决的。下面介绍常用的两种办法:
- 1、反向代理
反向代理利用的是服务端向服务端发起请求不会跨域这个原理,把客户端发起的请求转发到代理服务器,然后代理服务器再把请求转发给目标服务器。
- 2、跨域资源共享(CORS)
这是一种HTTP标头机制。服务端控制好允许访问的客户端域名,当服务端收到客户端的请求时,
服务端会校验当前客户端的域名是否在白名单内,如果在的话,HTTP响应头里面会返回一些标记:
Access-Control-Allow-Origin:*(允许所有域名)、Access-Control-Allow-Origin:http://example.com(允许特定域名),:告诉浏览器允许跨域请求,浏览器检测到这些标记后,就会通过,不会拦截报错跨域了。
那跨域访问页面元素、跨域携带cookie、跨域获取localst orage怎么解决?
- 1、跨域访问页面元素
可以用iframe内嵌不同源网站,两个网站之间通过post message来通信,A网站发送页面元素信息给
B网站。
- 2、跨域携带cookie
跨域携带cookie一般有两种解决方式:
2.1、子域名共享
可以通过设置子域名共享cookie的方式来解决。可以利用domain属性,指定cookie在二级域名、三级域名(更多)下面,比如把域名指定在.a.com下面,那么b.a.com、c.a.com的cookie是共享的。
2.2、CORS凭证模式
对于不同源的网站,cookie默认是不会携带到服务端的。但是可以通过CORS设置服务端
Access-Control-Allow-Credentials'true, 客户端credentials: 'include' 来允许跨域携带cookie。
- 3、跨域获取/设置localstorage
浏览器是禁止跨域访问和设置localstorage的。
但是可以通过间接方案解决。可以用iframe来内嵌不同源网站,然后把iframe设置成透明不可见。
再让2个网站通过postmessage来通信获取或设置localstorage.
什么是端口号?
端口号(Port Number)是一个16位的整数(范围从0到65535),用于标识同一台设备上的不同网络服务或应用程序。
主要功能:
◎ 在同一IP地址上区分不同的应用程序或服务
© 使多个网络应用可以同时使用网络
◎ 帮助数据包正确路由到目标应用程序
IP地址 就像一栋大楼的地址,而端口号 就像大楼内的房间号。数据包通过IP地址找到大楼,通过端口号找到具体的房间(应用程序)

IP地址 与端口号 的结合
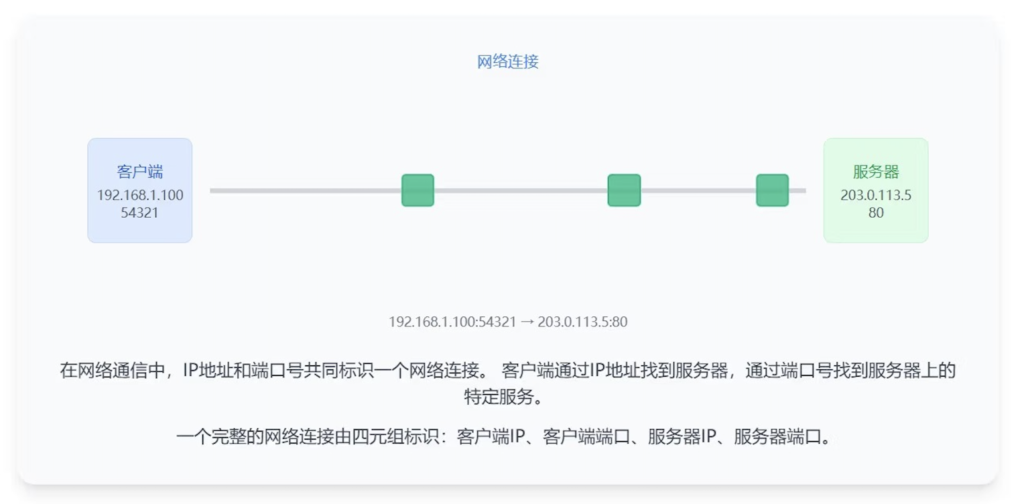
客户端-服务器通信流程
- 1.客户端选择一个未使用的本地端口(如54321)
- 2.客户端向服务器IP(如203.0.113.5)和端口(如80)发送连接请求服务器接收请求,
- 3.服务器接收请求,分配一个临时端口处理该连接
- 4.双方建立TCP连接(如果使用TCP协议)
- 5.数据通过已建立的连接传输
- 6.通信结束后,连接关闭
URL中的IP和端口
在URL中,端口号通常是可选的。如果省略,将使用协议的默认端口:
- http://example.com 一使用默认端口80
- https://example.com 一使用默认端口443
- http://example.com:8080 一使用指定端口8080
- ttp://example.com 一使用默认端口21
- ssh://example.com 一使用默认端口22