在电商的履约业务中,运营人员或财务人员需要在一张excel中导出关于履约单的具体信息,如履约单下单信息、履约商品信息、履约单送仓信息、履约单的物流信息等等,这些信息往往在同一个履约数据库的不同表中,如果要导出这些数据需要联表查询来获取数据。
假设在履约单的数据量很大的情况下,联表查询肯定是一个慢Sql,如果此时履约系统的并发量突增,此时极有可能由于慢Sql的原因将系统打崩溃。有没有什么办法来优化多表的联合查询问题呢?下面介绍几种优化方案。
1、字段冗余的宽表方案
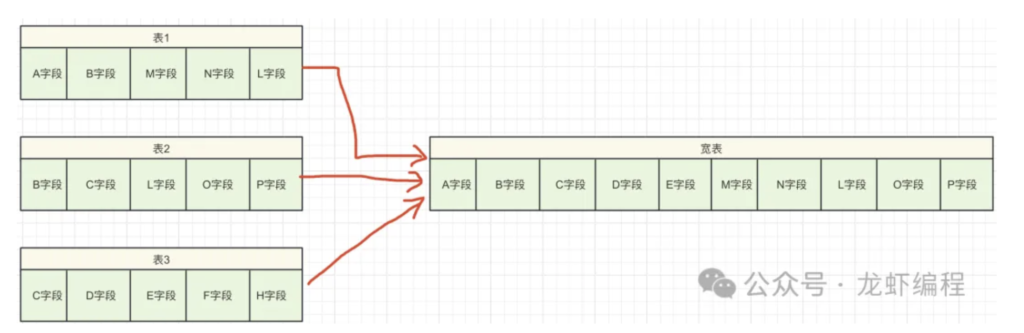
宽表是将业务需要的数据字段冗余到一张数据表中,在查询的时候往往就不需要在联表查询了,这种设计虽然符合了业务需求但是违反了Mysql数据表的设计原则。宽表有如下的缺点:
(1)在添加或者删除字段的时候可能需要锁住表,如果并发较大的情况下,锁表会带来较多的问题。
(2)宽表很难清晰地看出表与表之间的联系,维护上不方便。
2、Mysql的JSON格式字段方案
自Mysql5.7.8版本开始就提供了一种JSON格式字段,它会自动的验证存储在JSON列中的JSON文档是否有效,如果有效就允许存储,反之不可以存储;可以在存储的JSON文档中快速读取文档元素数据。
创建一个JSON格式字段如下:
CREATE TABLE `my_test` (
`id` INT UNSIGNED NOT NULL,
`data` JSON NOT NULL,
PRIMARY KEY (`id`)
);
存储JSON格式的数据:
insert into my_test values(1,'{"num": 1,"name": "abc","age": 20,"relation":{"borther": {"num": 1}, "sister": {"num": 2}}}');
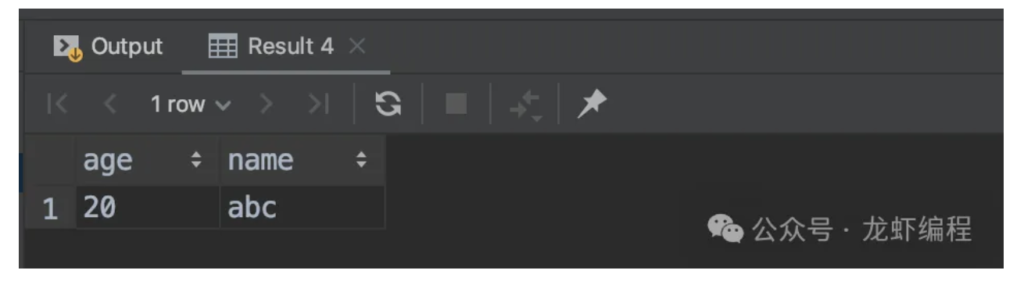
查询数据添加情况:

添加条件查询
select
json_unquote(data -> '$.age') as age,
json_unquote(data -> '$.name') as name
from my_test;
结果如下:
在数据量很大的时候,查询的时候依然是很慢的,原因是没有索引,如下的Sql语句解析:
explain select
json_unquote(data -> '$.age') as age,
json_unquote(data -> '$.num') as num
from my_test where data -> '$.name' = 'abc';
解析的效果:

那么为了提高查询效率,我们可以给JSON中的字段添加虚拟列,然后给虚拟列添加索引:
alter table my_test
add column name varchar(64) as (json_unquote(data-> '$.name')) virtual;
#添加索引
create index idx_name on my_test (name);
添加虚拟列后的效果:

现在再执行解析后发现之前添加索引生效了,效果如下:
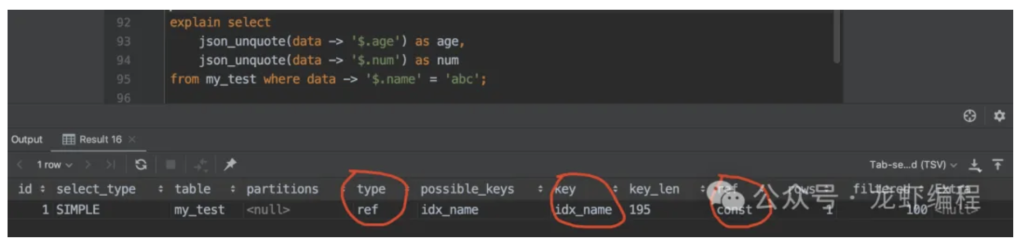
当前JSON格式的数据也可以很方便的修改,这块我们就不做过多的介绍了。根据以上的分析可以得出,业务需要的订单信息可以存放在到JSON格式的字段中存储,并且针对需要经常用来查询的字段我们通过虚拟列方法来添加索引,这样可以很好的实现业务需求。
JSON数据类型可以有效的解决多表多列场景下的数据查询性能问题,大大的简化了数据结构,便于数据的传输和管理。它特别适用于需要处理复杂数据结构的应用场景。
总结:
(1)简单的业务场景下,可以采用宽表的方式来满足业务需求,如果业务场景复杂的话建议使用JSON数据类型来做。
(2)宽表的字段也可以使用如Mongodb这样的中间件来帮助我们解决问题,我们都知道Mongodb其实是可以支持动态的增删字段列。