序列化的含义
序列化的原本意图是希望对一个Java对象作一下“变换”,变成字节序列,这样一来方便持久化存储到磁盘,避免程序运行结束后对象就从内存里消失,另外变换成字节序列也更便于网络运输和传播,所以概念上很好理解:
- 序列化:把Java对象转换为字节序列。
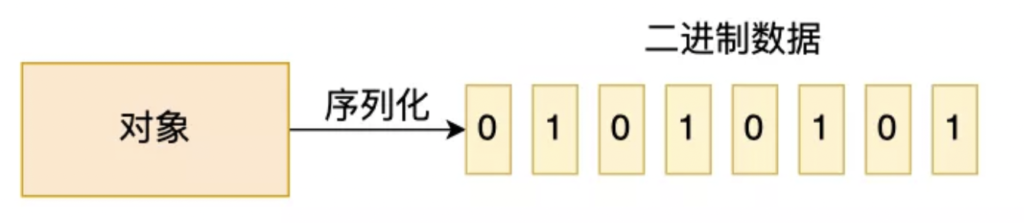
- 反序列化:把字节序列恢复为原先的Java对象。

而且序列化机制从某种意义上来说也弥补了平台化的一些差异,毕竟转换后的字节流可以在其他平台上进行反序列化来恢复对象。
简单说就是为了保存在内存中的各种对象的状态,并且可以把保存的对象状态再读出来。虽然你可以用你自己的各种各样的方法来保存Object States,但是Java给你提供一种应该比你自己好的保存对象状态的机制,那就是序列化。
总结来说,序列化就是将对象转换成二进制数据的过程,以方便传输或存储。而反序列就是将二进制转换为对象的过程。
什么情况下需要序列化
- 当你想把的内存中的对象保存到一个文件中或者数据库中时候;
- 当你想用序列化在网络上传送对象的时候;
- 当你想通过RMI传输对象的时候;
如何序列化
在介绍对象序列化的使用方法之前,先看看我们之前是怎么存储一个对象类型的数据的。
//简单定义一个Student类
public class Student {
private String name;
private int age;
public Student(){}
public Student(String name,int age){
this.name = name;
this.age=age;
}
public void setName(String name){
this.name = name;
}
public void setAge(int age){
this.age = age;
}
public String getName(){
return this.name;
}
public int getAge(){
return this.age;
}
//重写toString
@Override
public String toString(){
return ("my name is:"+this.name+" age is:"+this.age);
}
}
//main方法实现了将对象写入文件并读取出来
public static void main(String[] args) throws IOException{
DataOutputStream dot = new DataOutputStream(new FileOutputStream("hello.txt"));
Student stuW = new Student("walker",21);
//将此对象写入到文件中
dot.writeUTF(stuW.getName());
dot.writeInt(stuW.getAge());
dot.close();
//将对象从文件中读出
DataInputStream din = new DataInputStream(new FileInputStream("hello.txt"));
Student stuR = new Student();
stuR.setName(din.readUTF());
stuR.setAge(din.readInt());
din.close();
System.out.println(stuR);
}
输出结果:my name is:walker age is:21
显然这种代码书写是繁琐的,接下来我们看看,如何使用序列化来完成保存对象的信息。
public static void main(String[] args) throws IOException, ClassNotFoundException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("hello.txt"));
Student stuW = new Student("walker",21);
oos.writeObject(stuW);
oos.close();
//从文件中读取该对象返回
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("hello.txt"));
Student stuR = (Student)ois.readObject();
System.out.println(stuR);
}
写入文件时,只用了一条语句就是writeObject,读取时也是只用了一条语句readObject。并且Student中的那些set,get方法都用不到了。是不是很简洁呢?接下来介绍实现细节。
Serializable演示
然而Java目前并没有一个关键字可以直接去定义一个所谓的“可持久化”对象。
对象的持久化和反持久化需要靠程序员在代码里手动显式地进行序列化和反序列化还原的动作。
举个例子,假如我们要对Student类对象序列化到一个名为student.txt的文本文件中,然后再通过文本文件反序列化成Student类对象:
1、Student类定义
public class Student implements Serializable {
private String name;
private Integer age;
private Integer score;
@Override
public String toString() {
return "Student:" + '\n' +
"name = " + this.name + '\n' +
"age = " + this.age + '\n' +
"score = " + this.score + '\n'
;
}
// ... 其他省略 ...
}
2、序列化
public static void serialize( ) throws IOException {
Student student = new Student();
student.setName("CodeSheep");
student.setAge( 18 );
student.setScore( 1000 );
ObjectOutputStream objectOutputStream =
new ObjectOutputStream( new FileOutputStream( new File("student.txt") ) );
objectOutputStream.writeObject( student );
objectOutputStream.close();
System.out.println("序列化成功!已经生成student.txt文件");
System.out.println("==============================================");
}
3、反序列化
public static void deserialize( ) throws IOException, ClassNotFoundException {
ObjectInputStream objectInputStream =
new ObjectInputStream( new FileInputStream( new File("student.txt") ) );
Student student = (Student) objectInputStream.readObject();
objectInputStream.close();
System.out.println("反序列化结果为:");
System.out.println( student );
}
4、运行结果
控制台打印:
序列化成功!已经生成student.txt文件 ============================================== 反序列化结果为: Student: name = CodeSheep age = 18 score = 1000
Serializable接口有何用?
上面在定义Student类时,实现了一个Serializable接口,然而当我们点进Serializable接口内部查看,发现它竟然是一个空接口,并没有包含任何方法!
试想,如果上面在定义Student类时忘了加implements Serializable时会发生什么呢?
实验结果是:此时的程序运行会报错,并抛出NotSerializableException异常:
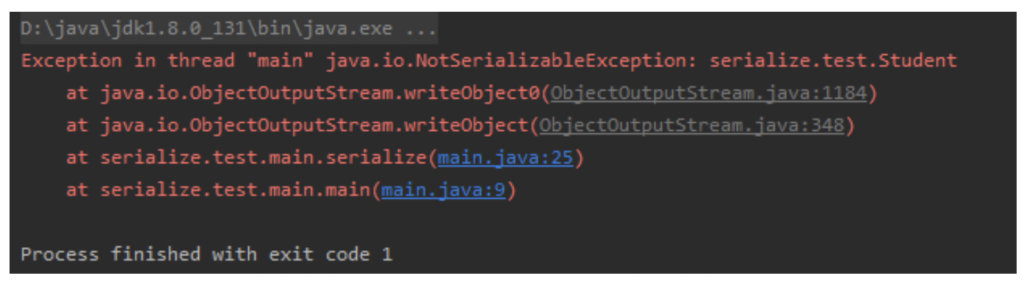
我们按照错误提示,由源码一直跟到ObjectOutputStream的writeObject0()方法底层一看,才恍然大悟:
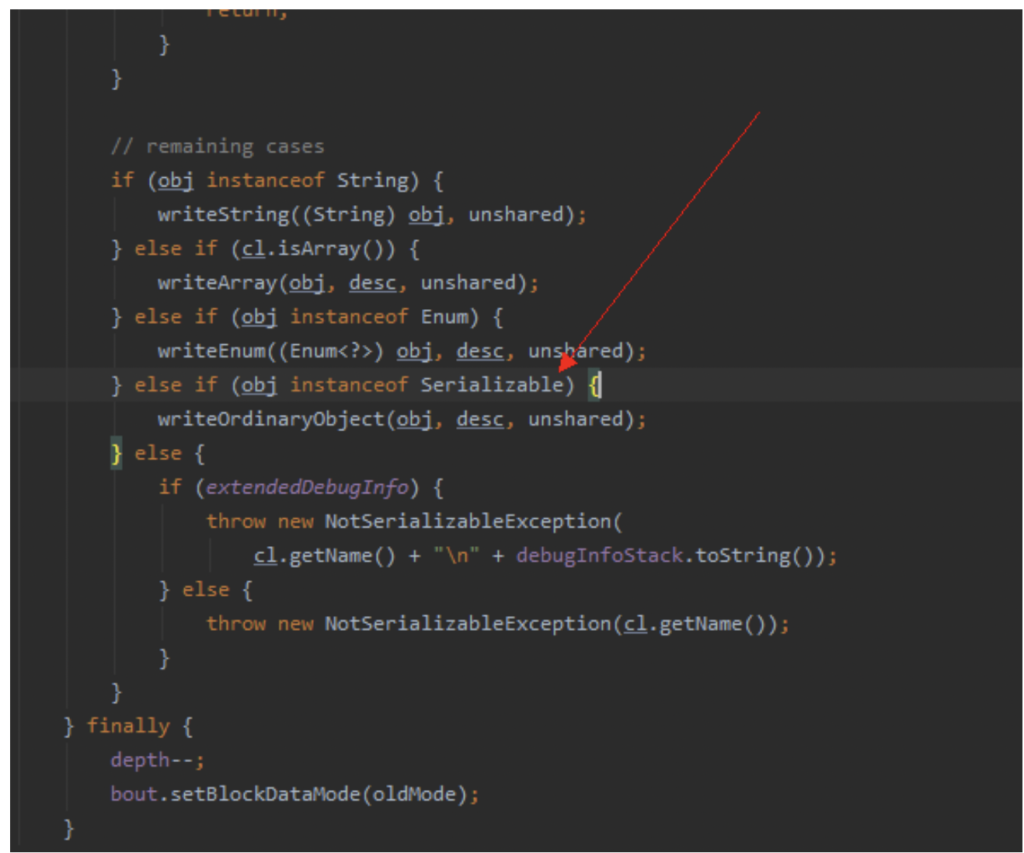
如果一个对象既不是字符串、数组、枚举,而且也没有实现Serializable接口的话,在序列化时就会抛出NotSerializableException异常!
原来Serializable接口也仅仅只是做一个标记用!!!它告诉代码只要是实现了Serializable接口的类都是可以被序列化的!然而真正的序列化动作不需要靠它完成。
serialVersionUID号有何用?
相信你一定经常看到有些类中定义了如下代码行,即定义了一个名为serialVersionUID的字段:
private static final long serialVersionUID = -4392658638228508589L;
你知道这句声明的含义吗?为什么要搞一个名为serialVersionUID的序列号?
继续来做一个简单实验,还拿上面的Student类为例,我们并没有人为在里面显式地声明一个serialVersionUID字段。
我们首先还是调用上面的serialize()方法,将一个Student对象序列化到本地磁盘上的student.txt文件:
接下来我们在Student类里面动点手脚,比如在里面再增加一个名为id的字段,表示学生学号:
public class Student implements Serializable {
private String name;
private Integer age;
private Integer score;
private Integer id;
这时候,我们拿刚才已经序列化到本地的student.txt文件,还用如下代码进行反序列化,试图还原出刚才那个Student对象:
运行发现报错了,并且抛出了InvalidClassException异常

这地方提示的信息非常明确了:序列化前后的serialVersionUID号码不兼容!
从这地方最起码可以得出两个重要信息:
- 1、serialVersionUID是序列化前后的唯一标识符
- 2、默认如果没有人为显式定义过serialVersionUID,那编译器会为它自动声明一个!
第1个问题: serialVersionUID序列化ID,可以看成是序列化和反序列化过程中的“暗号”,在反序列化时,JVM会把字节流中的序列号ID和被序列化类中的序列号ID做比对,只有两者一致,才能重新反序列化,否则就会报异常来终止反序列化的过程。
第2个问题: 如果在定义一个可序列化的类时,没有人为显式地给它定义一个serialVersionUID的话,则Java运行时环境会根据该类的各方面信息自动地为它生成一个默认的serialVersionUID,一旦像上面一样更改了类的结构或者信息,则类的serialVersionUID也会跟着变化!
所以,为了serialVersionUID的确定性,写代码时还是建议,凡是implements Serializable的类,都最好人为显式地为它声明一个serialVersionUID明确值
当然,如果不想手动赋值,你也可以借助IDE的自动添加功能,比如我使用的IntelliJ IDEA,按alt + enter就可以为类自动生成和添加serialVersionUID字段,十分方便
两种特殊情况
1、凡是被static修饰的字段是不会被序列化的
2、凡是被transient修饰符修饰的字段也是不会被序列化的
对于第一点,因为序列化保存的是对象的状态而非类的状态,所以会忽略static静态域也是理所应当的。
对于第二点,就需要了解一下transient修饰符的作用了。
如果在序列化某个类的对象时,就是不希望某个字段被序列化(比如这个字段存放的是隐私值,如:密码等),那这时就可以用transient修饰符来修饰该字段。
比如在之前定义的Student类中,加入一个密码字段,但是不希望序列化到txt文本,则可以:
public class Student implements Serializable {
private static final long serialVersionUID = -4392658638228508589L;
private transient String name;
private Integer age;
private Integer score;
private transient String passwd;
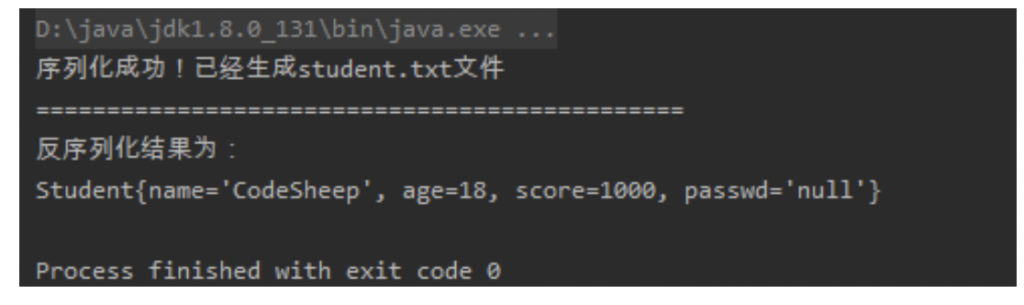
这样在序列化Student类对象时,password字段会设置为默认值null,这一点可以从反序列化所得到的结果来看出:
public static void serialize() throws IOException {
Student student = new Student();
student.setName("CodeSheep");
student.setAge(18);
student.setScore(1000);
student.setPasswd("123");
何时需要实现Serializable接口?
Java中有一个接口是java.io.Serializable,实现这个接口,不用实现任何方法,这个接口就是一个标识作用,jvm在做序列化操作的时候,会去检查目标类有没有实现java.io.Serializable接口,没有实现的话,根据情况抛出异常:java.io.NotSerializableException。
这里我们需要明确的是哪些操作会去检查是否实现java.io.Serializable接口,一般而言,在将对象转换成流时,会去检查。比如转换成流进行网络传输,转换成流持久化到磁盘。
实际应用时,比如我们服务对外提供的接口时,返回的DTO对象需要实现java.io.Serializable接口吗?答案是一般不需要。我们返回给前端的数据,通常是JSON和XML,但是实际上这是一个String,String是实现了java.io.Serializable的,所以我们的DTO是不需要实现java.io.Serializable接口的。
除非你要将一个对象写入文件,此时就需要继承Serializable。
用不用指定serialVersionUID?
如果你不在对象中定义serialVersionUID,Java会隐式定义serialVersionUID,并根据规则设置值,这是一个危险的行为。serialVersionUID对象的版本号,因为一旦对象序列化到存储介质上,就相当于有了副本,就要考虑数据一致性,如果将对象序列化分发出去了,而对象又被修改,增加属性或改变属性,此时如果没有版本号做控制,是很难察觉这些变化的,所以,理论上serialVersionUID的使用方式就是,每当对象的field做了变更就应该将serialVersionUID改变,通常是递增,这样的话,当进行反序列化时,Java就可以得知序列化文件和对象的serialVersionUID是否匹配,如果不匹配,就会抛出异常:java.io.InvalidClassException,告知应用。所以我们实现Serializable接口后,应该定义serialVersionUID变量。
@Data
public class B implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
}
服务器与浏览器交互时真的没有用到 Serializable 接口吗?
当我们只在本地 JVM 里运行下 Java 实例, 这个时候是不需要什么序列化和反序列化的, 但当我们需要将内存中的对象持久化到磁盘, 数据库中时, 当我们需要与浏览器进行交互时, 当我们需要实现 RPC 时, 这个时候就需要序列化和反序列化了.
前两个需要用到序列化和反序列化的场景, 是不是让我们有一个很大的疑问? 我们在与浏览器交互时, 还有将内存中的对象持久化到数据库中时, 好像都没有去进行序列化和反序列化, 因为我们都没有实现 Serializable 接口, 但一直正常运行.
下面先给出结论:
只要我们对内存中的对象进行持久化或网络传输, 这个时候都需要序列化和反序列化.
理由:
服务器与浏览器交互时真的没有用到 Serializable 接口吗?
网络传输中使用字符串进行交互,JSON是一种特殊规范的字符串,有自己的格式规定,与String的显示形式一样,但本质不是String!各端都支持JSON串的格式,将JSON容易转化为String进行网络传输。
JSON格式实际上就是将一个对象转化为字符串, 所以服务器与浏览器交互时的数据格式其实是字符串, String 类型实现了 Serializable 接口, 并显示指定 serialVersionUID 的值。
// Json对象转换成字符串 String string = JSON.toJSONString(person); // 字符串转成JSon对象 JSONObject jsonObject = JSON.parseObject(string);
所谓序列化指 对象——->JSONString,反序列化指 JSONString——>JSONObject或对象。