前言 🔖
聊个让我非常兴奋的项目——mlx-tune
一句话概括:在你的 Mac 上,用 Unsloth 的 API 微调一切
LLM、视觉模型、TTS、STT、OCR、Embedding,全都能在 Apple Silicon 上本地微调
🔹Mac 用户的微调困境
做大模型微调的同学应该都有过这种体验:想在本地跑个小实验验证下 idea,结果发现 Unsloth 依赖 Triton,而 Triton 不支持 Mac
于是你只剩两条路:
- 1. 花钱开云 GPU —— 就跑个 100 条数据的实验,有必要吗?
- 2. 用 mlx-lm 原生 API —— 但代码和 unsloth 完全不兼容,到了云上还得重写一遍
mlx-tune(github.com/ARahim3/mlx-tune)的作者也遇到了一模一样的问题
他的解决思路非常简单粗暴:把 MLX 包装成 Unsloth 的 API
你在 Mac 上写的训练脚本,换个 import 就能直接在 CUDA 集群跑
mlx-tune 是一个专为 Apple Silicon 设计的机器学习微调项目。针对 Mac 用户难以使用依赖 Triton 的 Unsloth 库的问题,该项目通过将 MLX 框架封装为 Unsloth 的 API 接口,实现了代码在本地 Mac 与云端 CUDA 集群间的无缝切换。这一设计让开发者能够在本地进行想法验证,并在云端直接运行生产级代码,无需修改核心逻辑。
# Unsloth (CUDA) # MLX-Tune (Apple Silicon) from unsloth import FastLanguageModel from mlx_tune import FastLanguageModel from trl import SFTTrainer from mlx_tune import SFTTrainer # 后面的代码一模一样!
这才是真正解决问题的设计
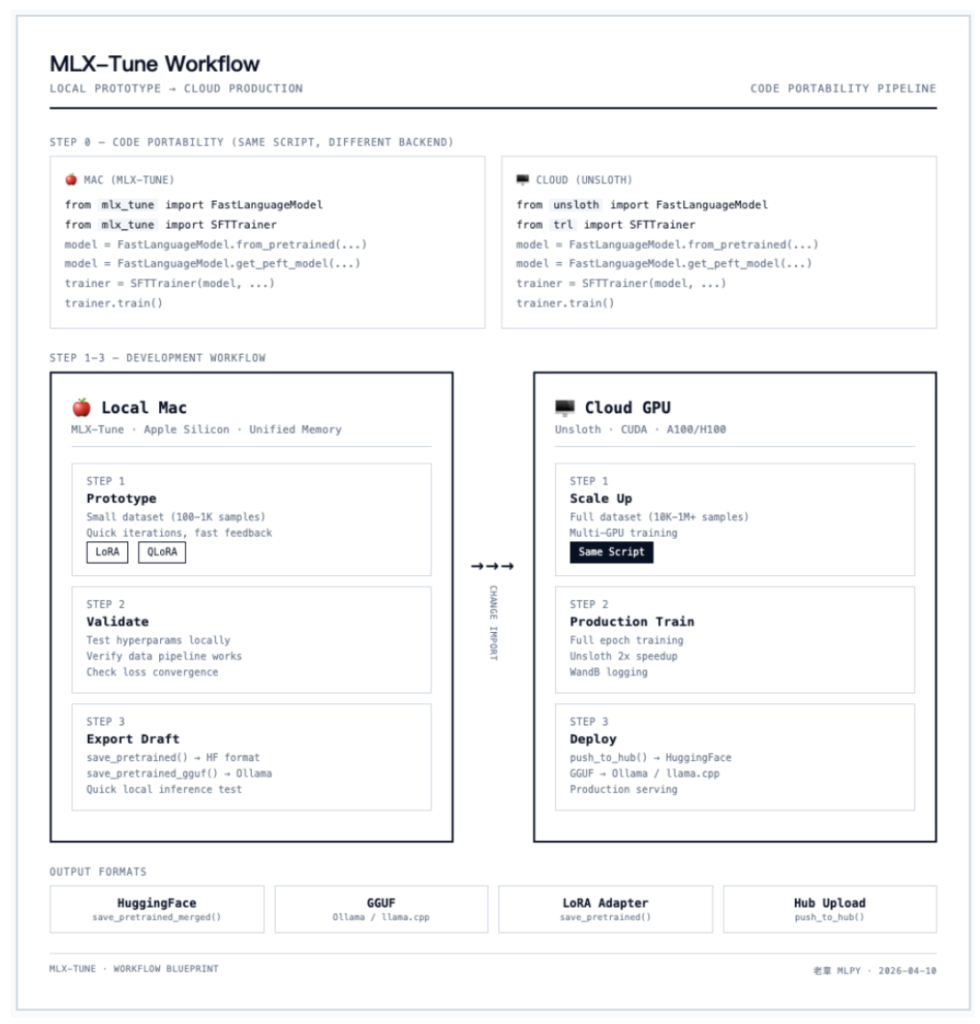
下面这张图清楚展示了 mlx-tune 的工作流——本地原型验证,改个 import 就能上云训练:
🔹核心机制与优势
mlx-tune 的核心价值在于其 API 兼容性。通过模拟 Unsloth 的接口,用户只需将代码中的导入语句从 from unsloth 修改为 from mlx_tune,即可将训练脚本迁移至 Mac 环境运行。这一机制不仅降低了多平台开发的成本,也填补了 Mac 端缺乏高效微调工具的空白。
| 特性 | Unsloth | mlx-tune |
|---|---|---|
| 运行环境 | CUDA (Linux/云端) | Apple Silicon (Mac 本地) |
| 依赖库 | Triton | MLX |
| API 接口 | 原生接口 | 兼容 Unsloth API |
| 硬件成本 | 需购买云 GPU | 利用现有 Mac 设备 |
| 主要用途 | 大规模生产训练 | 快速验证、小数据集实验 |
全模态功能支持🔖
功能有多全?看完吓一跳
它支持的训练方法比很多正经公司的内部工具都全:
语言模型训练:
- SFT:基础指令微调,这是最常用的
- DPO / ORPO / KTO / SimPO:各种偏好学习方法全覆盖
- GRPO:DeepSeek R1 风格的多生成 + 奖励训练
- CPT:持续预训练,支持解耦学习率
多模态训练:
- Vision:支持 Gemma 4、Qwen3.5、PaliGemma、LLaVA、Pixtral 等 VLM 微调
- TTS:Orpheus、OuteTTS、Spark-TTS、Sesame/CSM、Qwen3-TTS 五个 TTS 模型
- STT:Whisper、Moonshine、Qwen3-ASR、NVIDIA Canary、Voxtral 五个 STT 模型
- Embedding:BERT、ModernBERT、Qwen3-Embedding、Harrier,支持对比学习
- OCR:DeepSeek-OCR、GLM-OCR、olmOCR、Qwen-VL,内置 CER/WER 指标
进阶能力:
- MoE 微调:支持 39+ 种 MoE 架构,包括 Qwen3.5-35B、Mixtral、DeepSeek 系列
- Gemma 4 Audio:12 层 Conformer 音频塔,原生处理 16kHz 音频
- LFM2:Liquid AI 的混合卷积+GQA 架构
说真的,一个社区项目做到这个程度,相当离谱
全景架构一览——从 API 到硬件的五层设计:

快速上手🔖
🔹基本思路
安装环境
通过 pip install mlx-tune 命令安装项目库。
配置模型
加载模型并配置 LoRA (Low-Rank Adaptation) 参数。
执行训练
运行训练脚本,在本地完成微调过程。
导出部署
将训练完成的模型直接导出为 GGUF 格式,即可导入 Ollama 进行推理应用。
安装很简单,推荐用 uv:
# 标准安装 uv pip install mlx-tune # 带音频支持 uv pip install 'mlx-tune' brew install ffmpeg
来个最基础的 SFT 微调示例:
from mlx_tune import FastLanguageModel, SFTTrainer, SFTConfig
from datasets import load_dataset
# 加载模型(4bit 量化,省显存)
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="mlx-community/Llama-3.2-1B-Instruct-4bit",
max_seq_length=2048,
load_in_4bit=True,
)
# 加 LoRA
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_alpha=16,
)
# 加载数据集
dataset = load_dataset("yahma/alpaca-cleaned", split="train[:100]")
# 训练
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
tokenizer=tokenizer,
args=SFTConfig(
output_dir="outputs",
per_device_train_batch_size=2,
learning_rate=2e-4,
max_steps=50,
),
)
trainer.train()
# 保存:三种格式随你选
model.save_pretrained("lora_model") # LoRA 适配器
model.save_pretrained_merged("merged", tokenizer) # 合并后的完整模型
model.save_pretrained_gguf("model", tokenizer) # GGUF 格式,直接给 Ollama 用
如果你用过 Unsloth,这代码看着是不是特别眼熟?对,就是同一套 API
🔹视觉模型微调
VLM 微调也是同样简洁的体验:
from mlx_tune import FastVisionModel, UnslothVisionDataCollator, VLMSFTTrainer
from mlx_tune.vlm import VLMSFTConfig
model, processor = FastVisionModel.from_pretrained(
"mlx-community/Qwen3.5-0.8B-bf16",
)
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers=True, # 视觉层也微调
finetune_language_layers=True,
r=16, lora_alpha=16,
)
# 训练(数据集格式和 Unsloth 一致)
FastVisionModel.for_training(model)
trainer = VLMSFTTrainer(
model=model,
tokenizer=processor,
data_collator=UnslothVisionDataCollator(model, processor),
train_dataset=dataset,
args=VLMSFTConfig(max_steps=30, learning_rate=2e-4),
)
trainer.train()
Gemma 4、Qwen3.5、PaliGemma、LLaVA、Pixtral 都支持
你甚至可以用 Vision GRPO 来训练视觉推理能力
🔹TTS 微调:在 Mac 上克隆声音
这个功能我觉得特别有意思——在 Mac 上本地微调 TTS 模型:
from mlx_tune import FastTTSModel, TTSSFTTrainer, TTSSFTConfig, TTSDataCollator
from datasets import load_dataset, Audio
# 自动检测模型类型、编码器和 token 格式
model, tokenizer = FastTTSModel.from_pretrained(
"mlx-community/orpheus-3b-0.1-ft-bf16"
)
model = FastTTSModel.get_peft_model(model, r=16, lora_alpha=16)
dataset = load_dataset("MrDragonFox/Elise", split="train[:100]")
dataset = dataset.cast_column("audio", Audio(sampling_rate=24000))
trainer = TTSSFTTrainer(
model=model, tokenizer=tokenizer,
data_collator=TTSDataCollator(model, tokenizer),
train_dataset=dataset,
args=TTSSFTConfig(output_dir="./tts_output", max_steps=60),
)
trainer.train()
Orpheus、OuteTTS、Spark-TTS、Sesame/CSM、Qwen3-TTS 都支持
想做声音克隆或者风格化 TTS,再也不用租 GPU 了
🔹工作流全景
mlx-tune 的定位非常清晰:本地原型 → 云端量产。
本地 Mac (mlx-tune) 云端 GPU (Unsloth) ├── 快速实验 ├── 大规模训练 ├── 小数据集验证 ├── 完整数据集 ├── 秒级迭代 ├── 生产级优化 └── 同一套代码 ─────────────────── └── 同一套代码
训练完还能直接导出:
- HuggingFace 格式:标准保存
- GGUF:直接丢给 Ollama / llama.cpp
- push_to_hub:一键推到 HuggingFace Hub
它适合谁?
我觉得 mlx-tune 最适合这几类人:
- 1. Mac 用户 + 微调需求:你有 M1/M2/M3/M4/M5,想在本地跑微调实验,这是最佳选择
- 2. 混合工作流用户:本地调试、云端训练,代码无缝迁移
- 3. 多模态探索者:想同时玩 LLM、Vision、TTS、STT、OCR 微调的人
- 4. 学习者:想理解微调原理,在本地快速迭代比去 Colab 排队强太多
局限性也得说清楚:
- • 训练速度肯定比不上 A100 + Unsloth,这是物理定律决定的
- • GGUF 导出对量化模型有限制,建议用非量化基座模型
- • 内存受限于 Mac 的统一内存(不过 Mac Studio 最高 512GB,够用了)
如果你是 Mac 用户,又对微调大模型感兴趣,强烈建议试试。