前言🔖
llama.cpp是以一个开源项目,也是本地化部署LLM模型的方式之一,除了自身能够作为工具直接运行模型文件,也能够被其他软件或框架进行调用进行集成。
llama.cpp 是纯C++实现的大模型推理框架,极致轻量化,适合对性能有极致要求的场景,可直接运行GGUF格式的量化模型。
github地址:https://github.com/ggml-org/llama.cpp
llama.cpp 是纯 C/C++ 写的开源 LLM 推理框架,2023 年由 Georgi Gerganov 开发,核心目标是让大模型在普通电脑(CPU / 苹果 M 芯片)上高效跑起来,几乎零外部依赖。
核心特点
- 极致性能:底层汇编 / 硬件指令优化,苹果 M 系列(Metal)优化拉满,支持 GGUF 量化(Q4_K_M 等),内存占用极低。
- 高度灵活:全参数可定制(上下文
-c、GPU 层-ngl、Flash Attention 等),支持多模态(mmproj)、自定义停止词、关闭思考过程。 - 无依赖:纯 C/C++,编译后单文件,可直接用
llama-server启 API / 网页服务。 - 你的用法:你现在用的命令(
./llama-server -m ...)就是直接调用原生 llama.cpp,性能最强、可控性最高。
Mac 安装 llama.cpp🔖
🔹1. 下载llama代码
git clone https://github.com/ggerganov/llama.cpp.git
🔹2.编译llama.cpp
官网build说明:https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md#metal-build
cd llama.cpp // cd到工程目录 cmake -B build // 准备编译环境 cmake --build build --config Release // 正式编译出可执行文件
因为编译需要cmake,如果出现下面的错误,请先安装cmake
MacBook-Air llama.cpp % make Makefile:6: *** Build system changed: The Makefile build has been replaced by CMake. For build instructions see: https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md . Stop.
可以用下面的命令安装 cmake
brew install cmake
🔹3.下载gguf模型
然后我们就可以愉快的去 huggingface 网站下载gguf LLM模型了。比如下面的是qwen3.5模型
https://huggingface.co/HauhauCS/Qwen3.5-4B-Uncensored-HauhauCS-Aggressive/tree/main
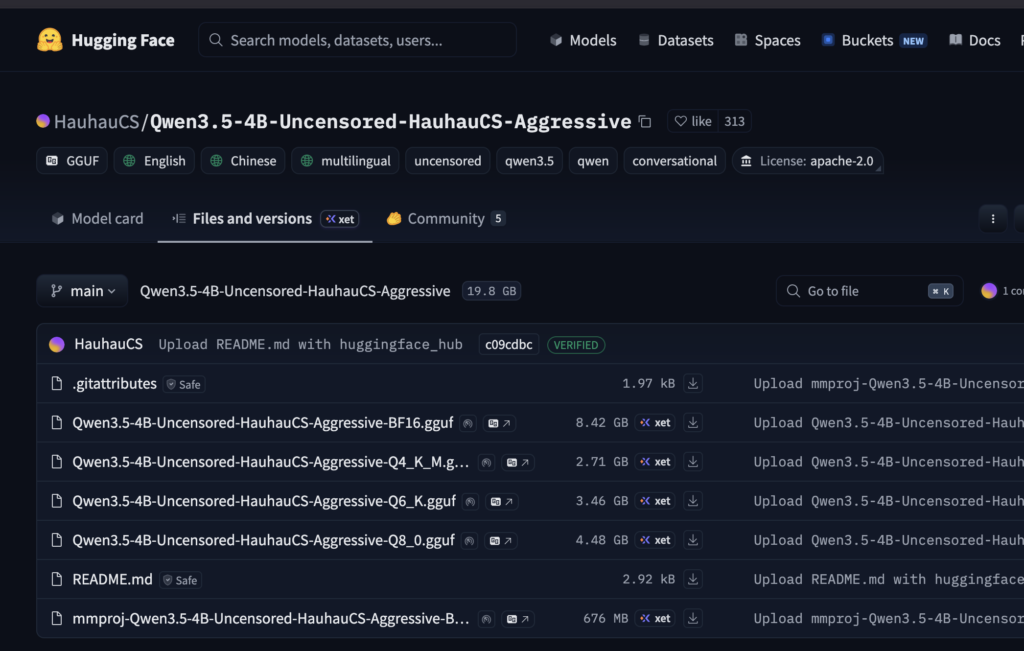
因为是多模态模型,有mmproj文件。
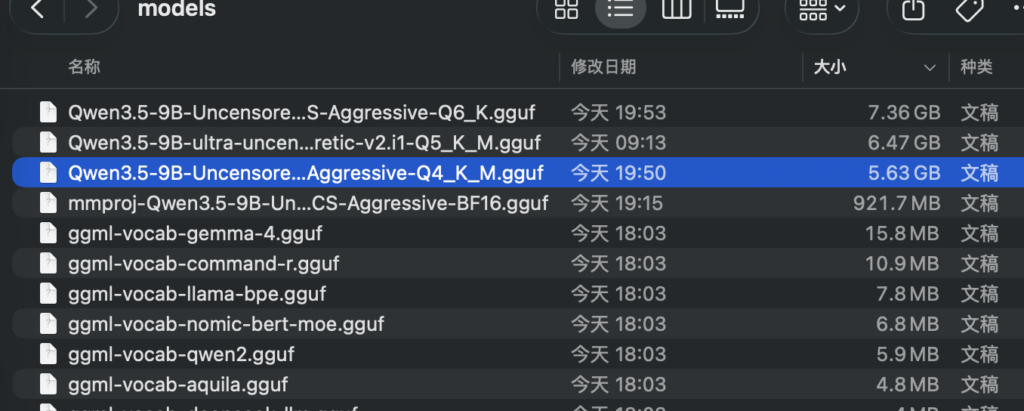
我们可以把下载的模型都放在下面的路径中
llama/llama.cpp/models/
启动 llama.cpp🔖
🔹llama.cpp 可以以web server的模式启动
cd llama/llama.cpp/build/bin \\切换到llama bin目录下
./llama-server \
-m ../../models/Qwen3.5-9B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf \
--mmproj ../../models/mmproj-Qwen3.5-9B-Uncensored-HauhauCS-Aggressive-BF16.gguf \
--port 8080 \
-c 16384 \
--n-gpu-layers 35 \
--chat-template-kwargs '{"enable_thinking":false}'
--api-key "MySecret123"
浏览器打开 http://127.0.0.1:8080/ 网页会提示输入API Key
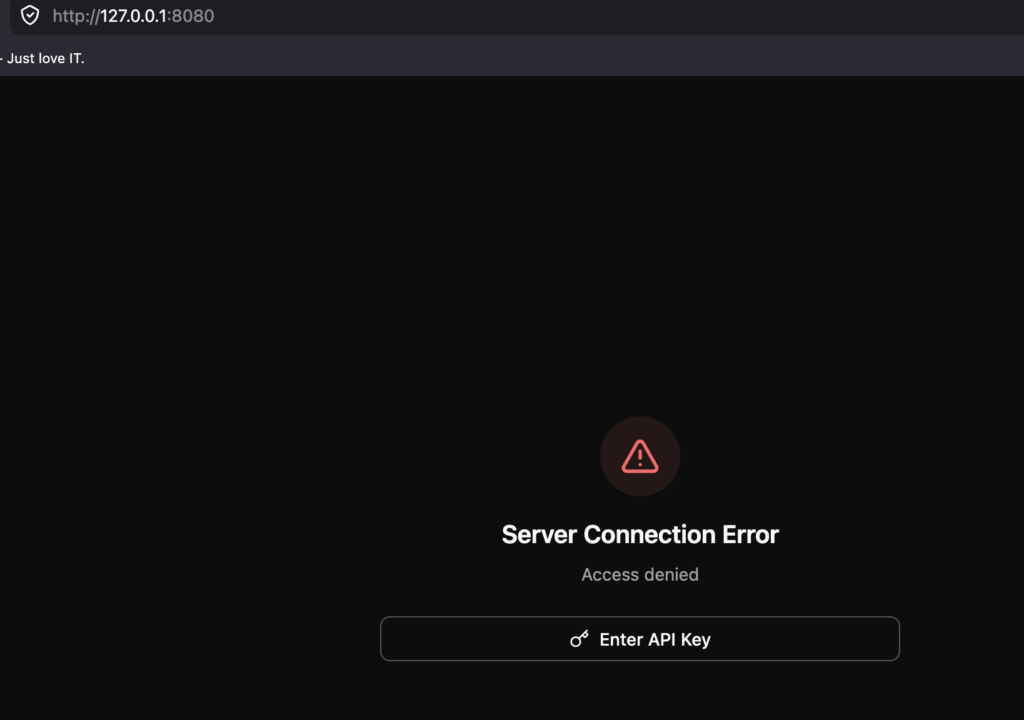
输入正确的key以后,就可以愉快的聊天了