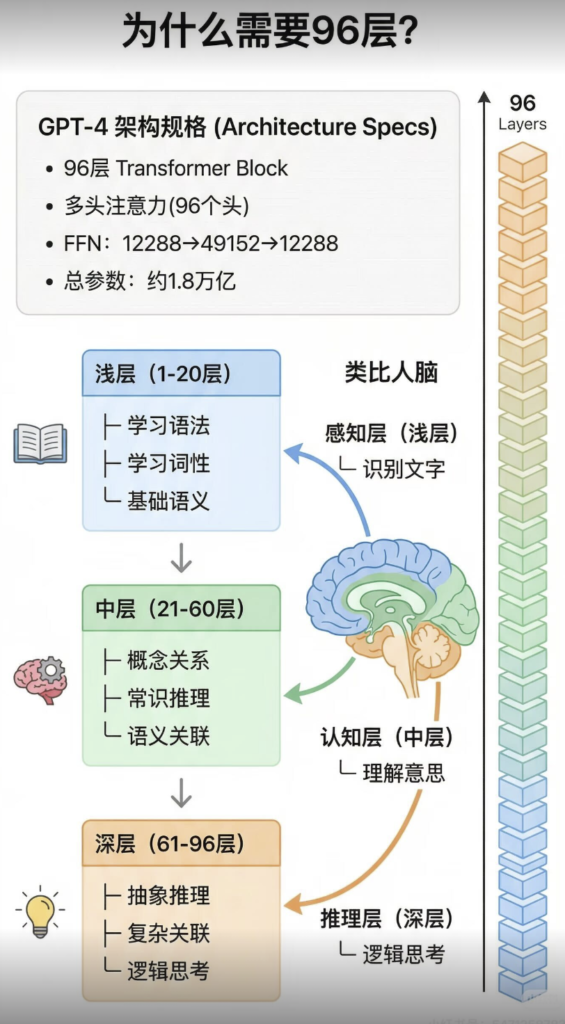
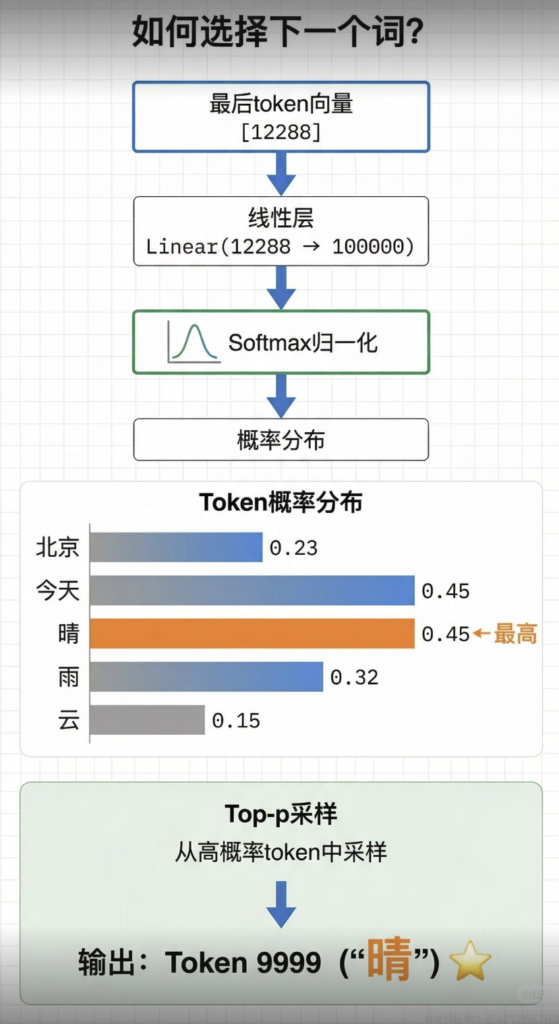
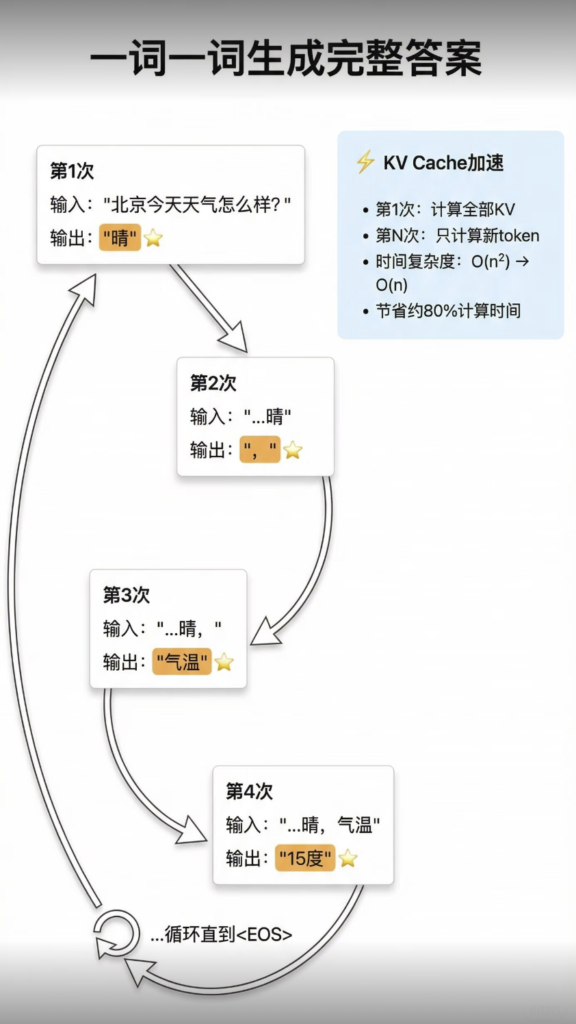
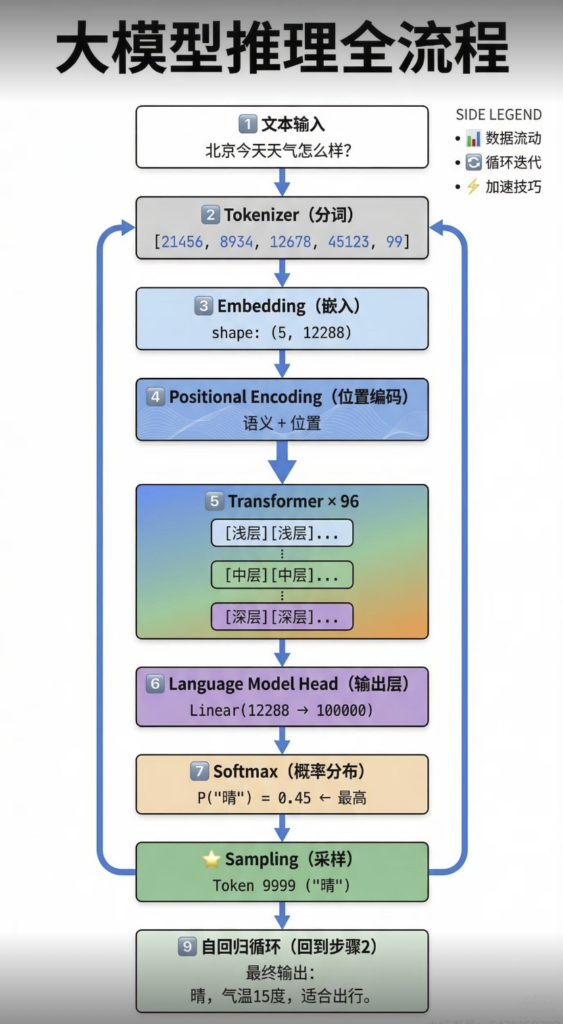
转载:小红书 AI产品赵哥
前言🔖
- 你是否惊叹于 ChatGPT 的对答如流、文采奕奕?
- 你是否好奇 AI 绘画(如 Midjourney, Stable Diffusion)是如何听懂人类要求(提示词)的?
- 你是否想知道支撑起这些应用的底层技术究竟是什么?
今天,我们就来聊聊这个 AI 时代的源头,它就是大名鼎鼎的 ——Transformer 模型。
2017 年,谷歌一篇名为《Attention Is All You Need》的论文横空出世,提出的 Transformer 模型彻底改变了自然语言处理(NLP)乃至整个 AI 领域的游戏规则。它就是我们熟知的 GPT 系列模型的祖先和核心架构。
闲言少叙,大家准备好,咱,出发了。。。
为什么我们需要 Transformer?🔖
在 Transformer 出现之前,处理序列数据(比如一句话、一段语音)主要是 RNN(循环神经网络)及其变体 LSTM 和 GRU,这些我们在前面的笔记里都讲过。
🔹看看 RNN/LSTM 是怎样循规蹈矩的
RNN 的工作方式:非常符合人类的直觉,一个一个地处理。就像我们阅读一样,从句子的第一个词读到最后一个词。
- 它在处理当前词时,会参考上一个词传递过来的记忆(隐藏状态)。
- 这个 “记忆” 理论上包含了前面所有词的信息。
这种串行处理的模式,带来了两个致命的问题:
- A. 计算效率低下,无法并行
- 想象一下,你有一条长长的队伍要过安检,每个人都必须等前面那个人检查完了才能轮到自己。RNN 就是这样,它必须处理完第
t个词,才能开始处理第t+1个词。在动辄需要处理成千上万个词的今天,这种龟速成了巨大的瓶颈。你无法把一句话切成几段,让几个处理器同时开工,因为后面的处理依赖于前面的结果。
- 想象一下,你有一条长长的队伍要过安检,每个人都必须等前面那个人检查完了才能轮到自己。RNN 就是这样,它必须处理完第
- B. 长期依赖问题(Long-Term Dependency Problem)
- RNN 的记忆力是有限的。当句子很长时,信息在传递过程中会不断被稀释或遗忘。
- 比如这句话:“我在法国长大,会说一口流利的……”。要预测最后一个词是 “法语”,模型需要记住最开头的 “法国”。但如果中间隔了几十个甚至上百个词,RNN 很可能已经忘了 “法国” 这回事了。
- LSTM 和 GRU 通过引入门控机制(像记忆的阀门)在一定程度上缓解了这个问题,但并未根治。
💡 小结:
RNN/LSTM 就像一个记忆力不太好、还必须按部就班工作的老学究。AI 需要一个既能看得远、记得牢,又能并行计算、速度飞快的天才少年。于是,Transformer 应运而生。
Transformer 的核心思想 —— Attention Is All You Need!🔖
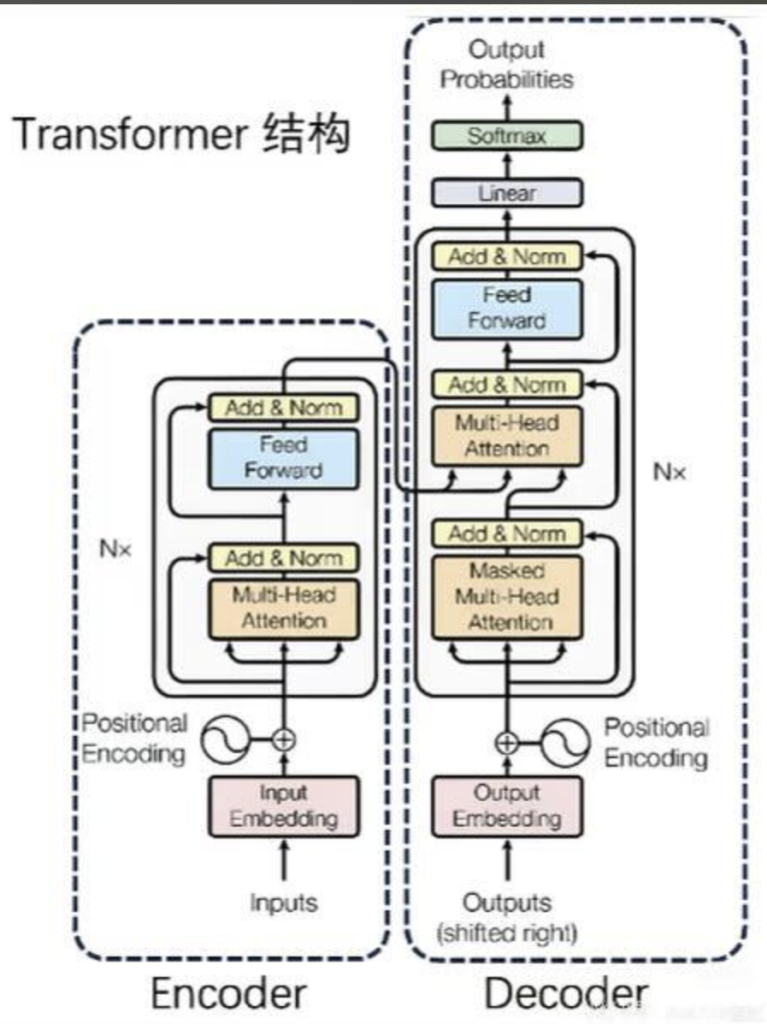
Transformer 扔掉了 RNN 的循环结构,另起炉灶。它的核心武器只有一个,就是论文标题所强调的 —— 注意力机制(Attention Mechanism),更准确地说,是自注意力机制(Self-Attention)。下面这个结构图很经典,直接上原图:
🔹 什么是自注意力机制?
自注意力机制,允许模型在处理一个词的时候,能够同时、直接地注意到句子中任何一个其他词,并根据相关性的大小,赋予不同的 “注意力权重”。
它彻底打破了 RNN 的顺序依赖,实现了一步到位、纵览全局。
我们看一个例子:
The old dog didn’t cross the street because it was too tired.
(那个老狗没有过马路,因为它太累了。)
这里的 it 指的是谁?是 dog 还是 street?
- 对于人类来说,这很简单,
it指的是animal。 - 对于模型来说,当它处理
it这个词时,自注意力机制会计算it和句子中所有其他词的相关性分数。它会发现it和animal的相关性分数最高,和street的相关性很低。 - 因此,在生成
it的新表示时,模型会把更多的 “注意力” 放在animal的信息上。
自注意力的高明之处在于:它让句子中任意两个词之间的距离都变成了 1。不管 “法国” 和 “法语” 隔了多远,模型都能瞬间建立起它们的直接联系。长期依赖问题,迎刃而解!
更重要的是,这些注意力的计算,对于所有词来说都是可以并行进行的!这就解决了 RNN 的效率瓶颈。
🔹 自注意力的实现:Q、K、V 三位一体
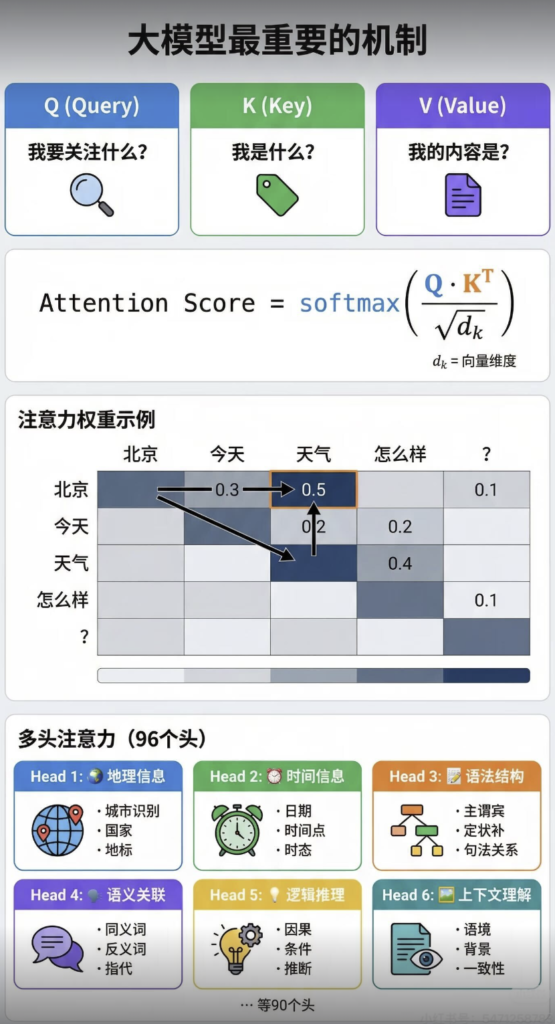
那么,这个相关性是怎么计算出来的呢?这里就要引入 Transformer 里最核心的三个概念:Query(查询)、Key(键)、Value(值)。
这是整个 Transformer 最难理解但也是最关键的部分,我会讲得非常细。自注意力的公式如下:
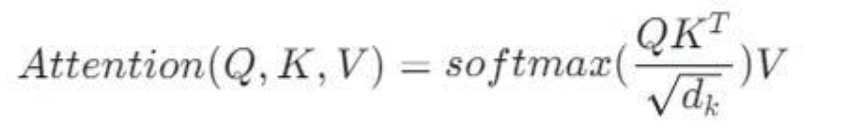
是不是看懵了?先忘掉公式,假设你在一个图书馆查资料:
- Query (Q):你脑子里的问题。(比如:“我想找关于人工智能历史的书。”)
- Key (K):书架上每本书的书名或标签。(比如:《AI 简史》、《机器学习》、《烹饪大全》)
- Value (V):每本书的实际内容。
自注意力的过程就是:
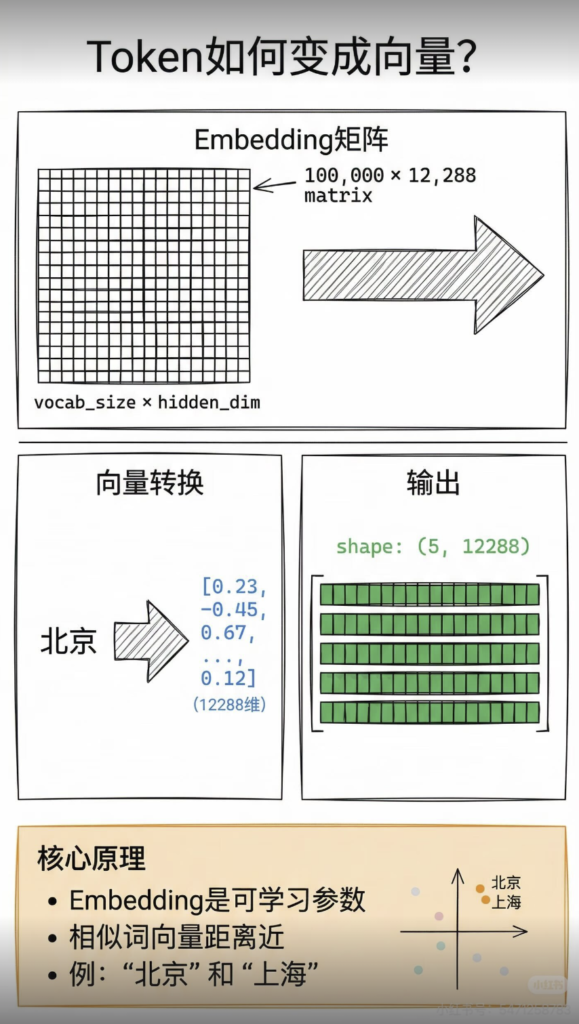
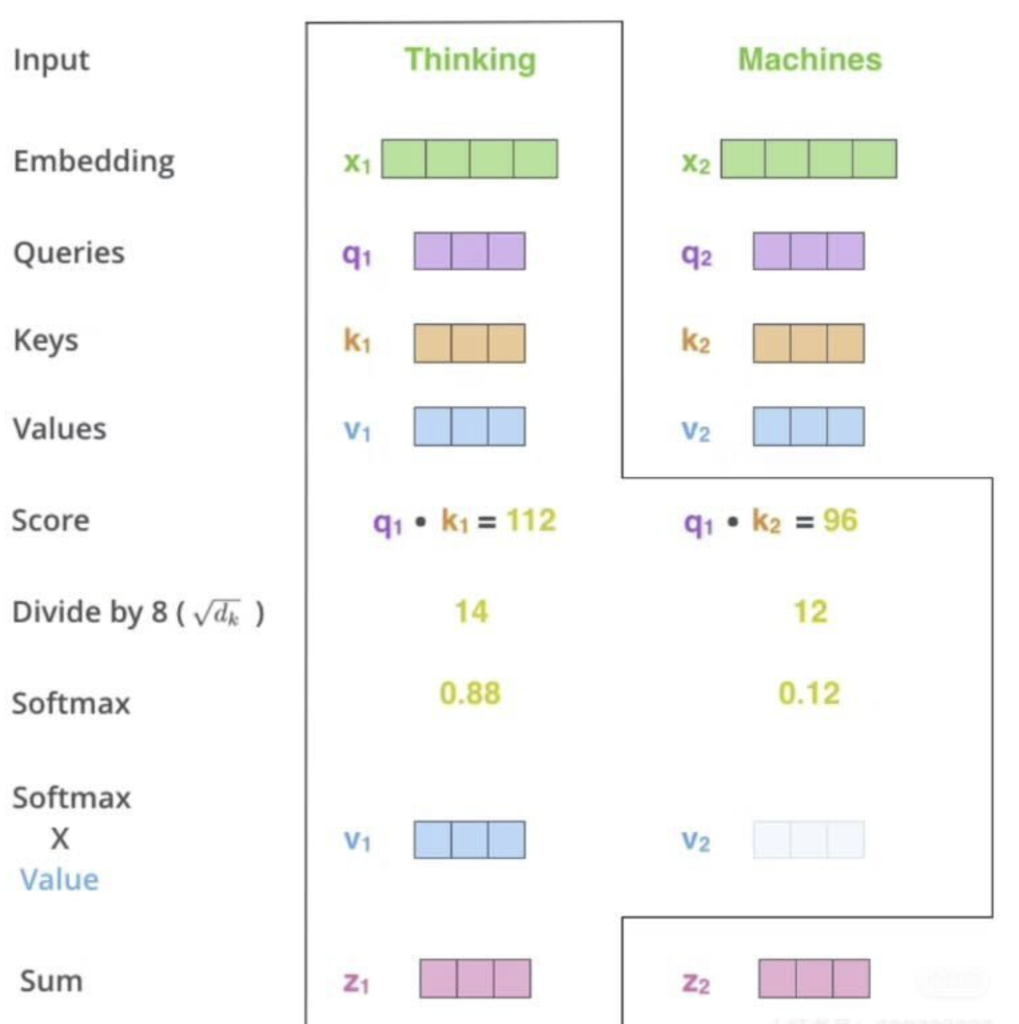
- 准备工作:对于输入句子中的每一个词,我们都通过三个不同的权重矩阵(W_Q、W_K、W_V)把它从原始的词嵌入(Word Embedding)向量,分别变换成三个新的向量:Query 向量、Key 向量、Value 向量。也就是说,每个词现在都身兼三职:它既是一个提问者 (Q),也是一个被检索的标签 (K),还是信息本身的承载者 (V)。
- 计算注意力分数(打分):当我们要计算 A 词的新表示时,我们用 A 词的Query 向量(Q_A),去和句子里所有词(包括 A 自己)的Key 向量(K_A,K_B,K_C …)进行点积运算。这个点积的结果,就代表了 “A 词对其他每个词的关注程度”,即注意力分数。
- Score(A,B)=Q_A*K_B
- 分数归一化(权重分配):得到的分数有高有低,我们需要把它们转换成一个总和为 1 的概率分布,这样才好分配注意力预算。
- 首先,将分数除以一个缩放因子(通常是 Key 向量维度的平方根)。这一步是为了在训练时梯度更稳定,可以先理解为一个技术处理。
- 然后,将缩放后的分数输入到一个Softmax 函数中。Softmax 会把一组任意数值,变成一组总和为 1 的百分比,即注意力权重。分数越高的词,得到的百分比(权重)就越高。
- 加权求和(信息汇总)最后,用上一步得到的注意力权重,去乘以每个词的Value 向量,然后把它们全部加起来。
- New_A=weight_A∗V_A+weight_B∗V_B+weight_C∗V_C+…
- 这个最终得到的 New_A 向量,就是 A 词经过自注意力机制洗礼后的新表示。它不再是 A 词自己的信息,而是整个句子所有词信息的加权融合,其中与 A 词最相关的词贡献了最多的信息。
这个从 Q,K,V 到新表示的完整过程,被称为一个 注意力头(Attention Head)。
Transformer 的完整架构剖析🔖
理解了自注意力的核心原理,我们就可以来拼装完整的 Transformer 积木了。一个标准的 Transformer 由 *编码器(Encoder)和解码器(Decoder) 两大部分组成。
🔹多头注意力机制 (Multi-Head Attention)
一个注意力头,只相当于从一个角度去审视句子中词与词的关系。但这种关系是复杂的。
- 比如,“The old dog didn’t cross the street……”,
it和dog的关系是指代关系。 - 在 “make up a story” 中,
make和up是短语搭配关系。
为了让模型能从不同角度理解这些复杂关系,Transformer 引入了多头注意力机制。
- 做法:它不是只做一次 Q,K,V 的变换和计算,而是并行地做多次(比如 8 次)。每次都用不同的权重矩阵(W_Q,W_K,W_V),生成不同的 Q,K,V “三件套”,这就形成了 8 个独立的注意力头。
- 效果:每个头都可以学到一种不同的注意力模式。比如,一个头可能专注于句法结构,另一个头可能专注于语义关联。
- 最后:将 8 个头得到的 8 个输出向量拼接起来,再通过一个线性变换,整合成一个最终的输出向量。
多头注意力:就像请了多个不同领域的专家,同时对一句话进行分析,然后汇总他们的意见,得到一个更全面、更深刻的理解。
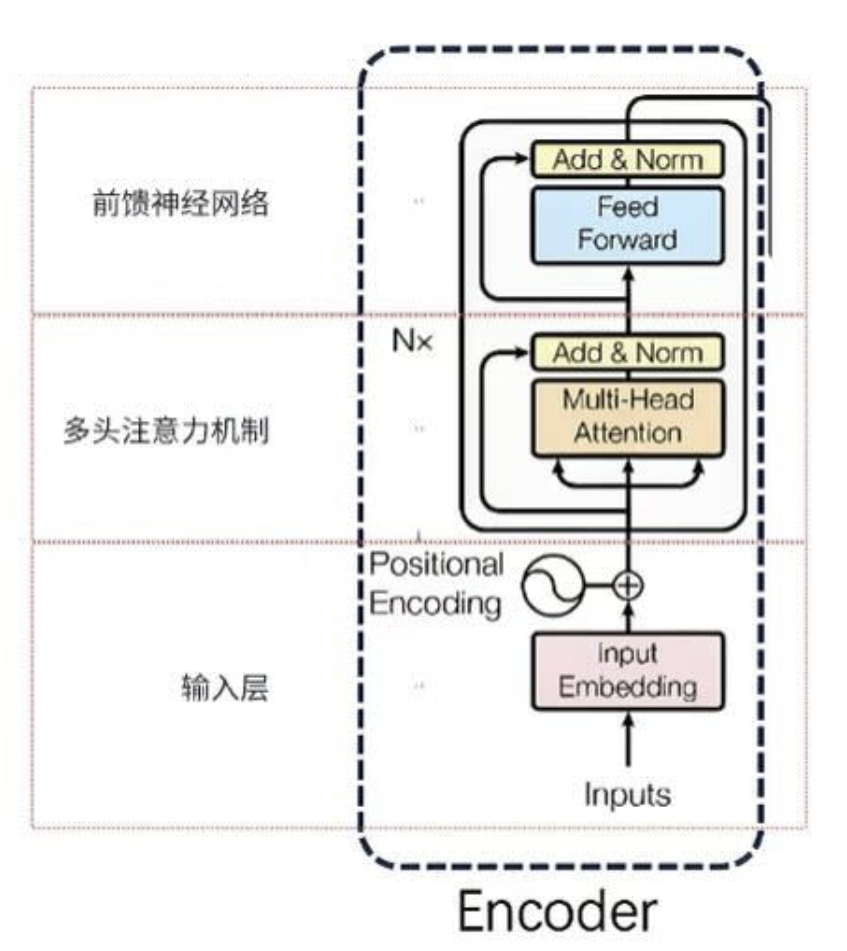
🔹编码器 (Encoder):理解你输入的句子
编码器的任务是读懂并理解输入的整个句子。一个标准的 Transformer 编码器由 N 个(原论文中是 6 个)相同的编码器层堆叠而成。
每个编码器层(Encoder Layer)包含两个核心子层:
- 输入层:主要包括 Embedding 和位置编码
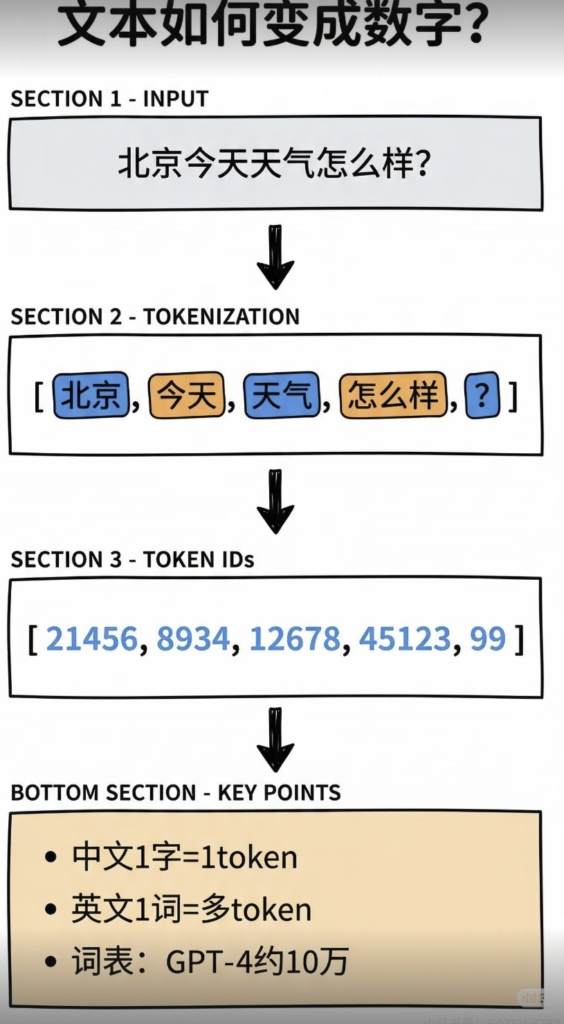
- a. Embedding:主要是将 token 映射为词向量
- b. 位置编码:为了让 Transformer 感知词语在句子中的位置信息,我们需要对词语的位置进行编码。比如说:“我爱吃苹果” 和 “苹果爱吃我” 这两句话对于 Transformer 的自注意力机制是一样的。位置编码我们在 3.4 里展开聊。
- 多头自注意力层:就是我们刚刚详述的部分。它负责在输入句子内部建立词与词之间的关联。
- 前馈神经网络层(FFN):这是一个简单的、由两个线性变换和一个 ReLU 激活函数组成的全连接网络。你可以把它理解成一个加工厂,对注意力层输出的信息进行进一步的非线性变换和提炼。
此外,每个子层外面都包裹着两个重要的 “辅助件”:
- 残差连接(Residual Connection):将子层的输入直接加到子层的输出上(Output=Layer(x)+x)。这就像在信息流动的过程中开了一条绿色通道,保证了原始信息不会在深层网络中丢失,极大地缓解了梯度消失问题,让训练更深的网络成为可能。
- 层归一化 (Layer Normalization):对每个样本的特征进行归一化,使得数据分布更加稳定,加速模型收敛。
所以,一个编码器层的完整流程是:输入 → 多头自注意力 → Add & Norm → 前馈网络 → Add & Norm → 输出。
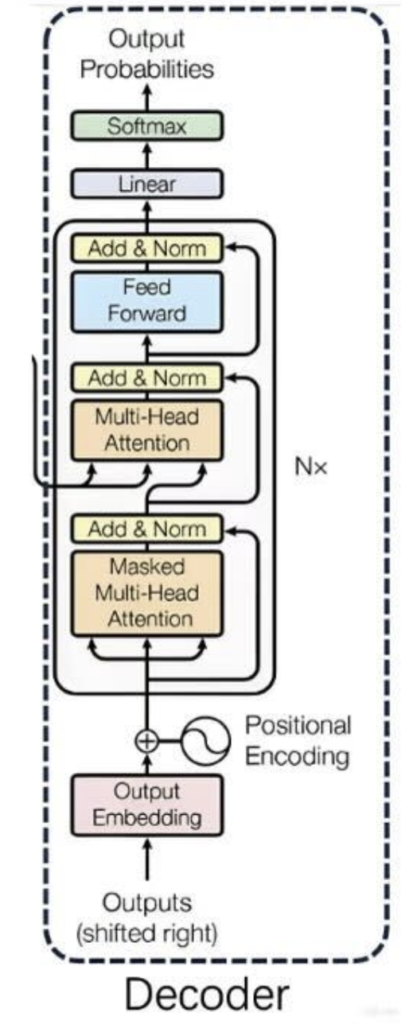
🔹3.3 解码器 (Decoder):创作并输出新的句子
解码器的任务是根据编码器对原文的理解,生成目标句子。它同样由 N 个解码器层堆叠而成。
解码器层比编码器层要复杂一点,它有三个核心子层:
- 1. 带掩码的多头自注意力层 (Masked Multi-Head Self-Attention Layer)
- 这个层的作用和编码器里的自注意力层类似,都是让解码器在生成当前词时,关注它已经生成的前面那些词。
- 关键在于掩码(Masked)。在训练时,我们虽然一次性把整个目标句子都喂给了解码器,但在预测第 i 个词时,模型是不允许偷看第 i 个词之后的内容的。这个掩码操作,就是把未来的信息给遮挡起来,模拟真实预测时一步一步生成的情景。
- 2. 编码器 – 解码器注意力层 (Encoder-Decoder Attention Layer)
- 这是连接编码器和解码器的桥梁,是整个翻译 / 生成任务的关键。
- 在这一层里,Query(Q)来自于解码器前一层的输出,而Key(K)和 Value(V)则来自于编码器的最终输出。
- 这意味着:解码器在决定下一步要生成什么词时,会用自己的当前状态(Q)去查询编码器对整个源句的理解(K 和 V),看看原文的哪个部分最值得关注。
- 比如翻译 “Je suis étudiant” → “I am a student”。当解码器准备生成
student时,这一层的注意力会高度集中在编码器输出的、对应于étudiant的向量上。
- 3. 前馈神经网络层 (Feed-Forward Network, FFN)
- 与编码器中的一样,负责对信息进行加工。
- 同样,解码器的每个子层也都包裹着残差连接和层归一化。
🔹3.4 位置编码 (Positional Encoding)
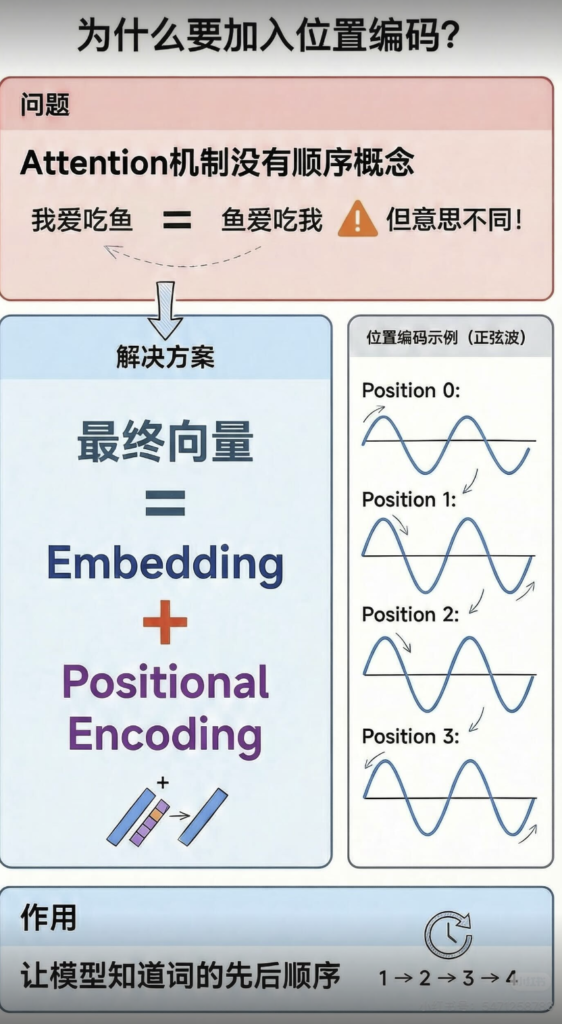
我们前面提到,Transformer 抛弃了 RNN 的循环结构,所有词都是并行处理的。这带来了一个新问题:模型不知道词的顺序了!“你爱我” 和 “我爱你” 在 Transformer 看来可能是一样的,因为它们都只是一个词的集合。
为了解决这个问题,Transformer 引入了位置编码(Positional Encoding)。
- 做法:在将词嵌入输入到模型之前,给每个词的嵌入向量加上一个特殊的位置向量。这个位置向量是根据词在句子中的绝对位置(第 1 个、第 2 个……)通过正弦和余弦函数生成的(见下图)。
- 效果:这个位置向量为每个词注入了其独一无二的位置信息。由于三角函数的周期性,模型还能学到词与词之间的相对位置关系。
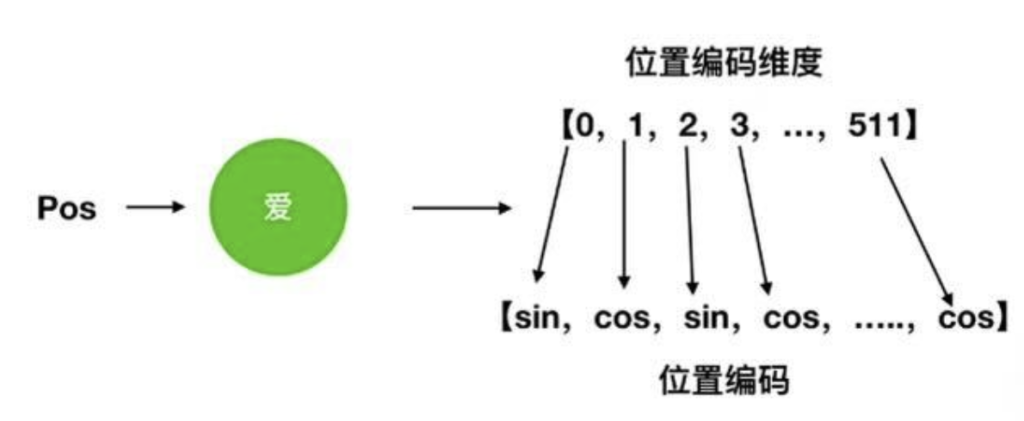
- 所以,模型的最终输入 = 词嵌入 + 位置编码。
Transformer 的深远影响🔖
Transformer 不仅是一个模型,更是一种范式,它对 AI 领域的改变可以说是翻天覆地的。
🔹 奠定大语言模型的基石
几乎所有你听过的现代大语言模型,都是基于 Transformer 架构的变体:
- BERT (Bidirectional Encoder Representations from Transformers):主要使用了 Transformer 的编码器(Encoder)部分。它通过 “完形填空” 和 “下一句预测” 任务进行预训练,成为了一个极强的语言理解模型,在各种 NLP 下游任务(如分类、问答)上屠榜。
- GPT (Generative Pre-trained Transformer):主要使用了 Transformer 的解码器(Decoder)部分。它通过预测下一个词的任务进行预训练,天生就是一个强大的文本生成模型,ChatGPT 就是其登峰造极的代表。
🔹跨界征服,不止于 NLP
Transformer 的成功思想很快被迁移到了其他领域,最著名的就是计算机视觉(CV)。
- Vision Transformer (ViT):将一张图片切成一个个小图块(Patches),把每个图块看作一个词,然后把这些 “词” 序列输入到标准的 Transformer 编码器中进行图像分类。ViT 证明了,在有足够数据的情况下,Transformer 架构同样可以在 CV 领域媲美甚至超越传统的卷积神经网络(CNN)。
来,总结一下吧🔖
- Transformer 的诞生是为了解决 RNN/LSTM 的并行计算瓶颈和长期依赖问题。
- 其核心是自注意力机制,通过 Q, K, V 的计算,让模型能一步到位地捕捉句子中任意两个词之间的依赖关系,且可以并行计算。
- 多头注意力允许模型从不同角度理解句子。
- 位置编码解决了 Transformer 本身无法感知词序的问题。
- 完整的 Transformer 由编码器(理解输入)和解码器(生成输出)组成。解码器比编码器多了一个编码器 – 解码器注意力层,用于 “参考” 原文。
- Transformer 架构是 **BERT(编码器派)和GPT(解码器派)** 等所有现代大语言模型的共同基石,并成功跨界到 CV 等领域。
Transformer 用一种看似简单粗暴但又极其深刻的方式,重塑了 AI 模型处理信息的方式。理解了它,你对于 AI 及大语言模型才算是真正入门。