转载:小红书 AI产品赵哥
前言🔖
大家都用过 AI 作图软件吧:
- 输入一句 “大熊猫站在月球上,手里举着五星红旗,背景有是地球”,AI 就能给你画出来!
- 上传一张自己的照片,就能生成各种风格的艺术头像!

有没有想过这些事怎么实现出来的?这涉及到图像生成领域的一项关键技术 —— 扩散模型 (Diffusion Model)。
它与我们之前可能聊过的 **GAN(生成对抗网络)** 生成模型都不同。它用一种极其独特、甚至有点违反常态的方式,无中生有的完成图像生成。
今天咱们来聊聊这个很火的扩散模型。大家准备好了吗?我们发车了!!!
我们为啥要搞 Diffusion?🔖
在扩散模型成为香饽饽之前,AI 绘画界的老大是一个叫做 GAN(生成对抗网络) 的模型。GAN 非常有趣,你可以把它想象成一个伪造艺术品大师。它由两个部分组成:
- 生成器(Generator):G 先生,相当于伪造艺术品大师。他的任务是凭空造出越来越逼真的艺术品(在我们的场景里就是画画)。
- 判别器(Discriminator):D 先生,相当于鉴宝大师。他的任务是火眼金睛,分辨出哪些是真艺术品(真实的图片),哪些是生成器造的假艺术品(AI 画的画)。
这两个家伙是死对头,每天互相卷对方。
- 一开始,生成器画的画很烂,像小孩子涂鸦。判别器一眼就能看出来:“假的!”
- 生成器受到打击,回去苦练画技,下次画得稍微好了一点。
- 判别器也跟着升级,学习更精细的防伪特征,又把生成器给揪出来了。
- ……
就这样,在没日没夜的对抗和博弈中,生成器的画技越来越高超,直到有一天,它画出的画连判别器都分不出真假了。这时候,我们就得到了一个很牛的 AI 画师。
听起来很厉害,对吧?但 GAN 有几个很大的问题:
- 训练不稳定:这种对抗训练就像走钢丝,非常难平衡。一不小心,可能生成器就躺平不学了,或者判别器太强,导致生成器一直被吊打,学不到东西。整个训练过程很玄学。
- 模式崩溃(Mode Collapse):这是 GAN 最头疼的问题。比如你让它画人脸,它可能学会了画某一种风格的美女脸,然后就只会画这一种脸了。不管你让它画啥,它都给你交同一张网红脸作业。它记住了一条通往成功的捷径,失去了创造多样性的能力。
此时,天空一声炸雷,扩散模型诞生了。
扩散模型到底是个啥?🔖
扩散模型的思想,来源于物理学中的热力学。别怕,我们今天不聊物理学。我先看一个实验:
想象一下,你有一杯清澈见底的水,水里滴入了一滴浓郁的墨水。
- 发生了什么?这滴墨水会开始慢慢地、不受控制地向四周扩散(Diffusion)。墨水分子会从集中的地方,逐渐散布到整杯水中。
- 最终结果?经过一段时间,整杯水都变成了均匀的、淡淡的灰色。最初那滴纯黑的墨水已经看不见了,它的信息均匀地消散在了整杯水中。
这个过程,我们称之为加噪或前向过程。它是一个从有序(一滴纯墨水 + 一杯纯水)到无序(一杯均匀的灰水)的过程。这个过程是自然的、简单的、不可逆的(在宏观上)。
如果我能教会一个 AI,精确地学会这个过程的逆操作呢?
💡 也就是说,我给 AI 一杯均匀的灰水,它能不能一步步地、把那些散开的墨水分子重新聚集起来,最终还原出最开始那滴纯黑的墨水?
这就是扩散模型的核心思想:
- 先学会破坏:先通过一个简单、固定的数学过程,一步步地往一张清晰的图片上添加噪声(就像滴墨水),直到图片变成一片完全随机的、像电视雪花点一样的纯噪声(就像那杯灰水)。
- 再学会修复:然后,训练一个强大的神经网络,让它学习这个过程的逆向操作。你给它一张纯噪声图,它能一步步地去除噪声(就像把墨水分子捞回来),最终雕刻出一张清晰、有意义的图片。
这个思想的牛 X 之处在于:
- 破坏的过程是已知的、可控的。我们知道每一步加了多少噪声,怎么加的。
- 修复的任务是明确的。AI 的任务不再是凭空想象,而是根据噪声的模式,预测出原始信号。这是一个定义清晰的监督学习问题,比 GAN 那种玄学博弈要稳定得多!
前向过程,是咋回事?🔖
我们来把上面那个比喻具体化。这个破坏的过程,在学术上叫做前向过程(Forward Process)或扩散过程(Diffusion Process)。
这个过程非常简单粗暴,甚至不需要 AI 参与。
- 准备素材:拿一张你手机里的高清美图,比如你家猫主子的照片。我们把这张初始图片叫做 X₀。
- 第一步加噪:我们给这张图加上一点点非常轻微的高斯噪声。你可以把高斯噪声想象成非常细密的、半透明的 “小麻点”。加完之后,图片看起来和原来差不多,只是没那么锐利了。我们把这张图叫做 X₁。
- 第二步加噪:在 X₁ 的基础上,再加一点点同样强度的高斯噪声。图片变得更模糊了一点。这张图叫做 X₂。
- 循环往复……:我们重复这个过程几百次,甚至上千次(这个总步数我们用 T 表示)。每一步,都在前一步的基础上再加一点点噪声。
- X₀ → X₁ → X₂ → … → X_t → …… → X_T
- 最终形态:当我们走到最后一步 X_T 时,原始的猫主子图片已经被噪声完全淹没了。你看到的,就是一张毫无规律、纯粹的、像电视没信号时那样的 “雪花图”。这张图里已经看不出任何关于猫的痕迹。
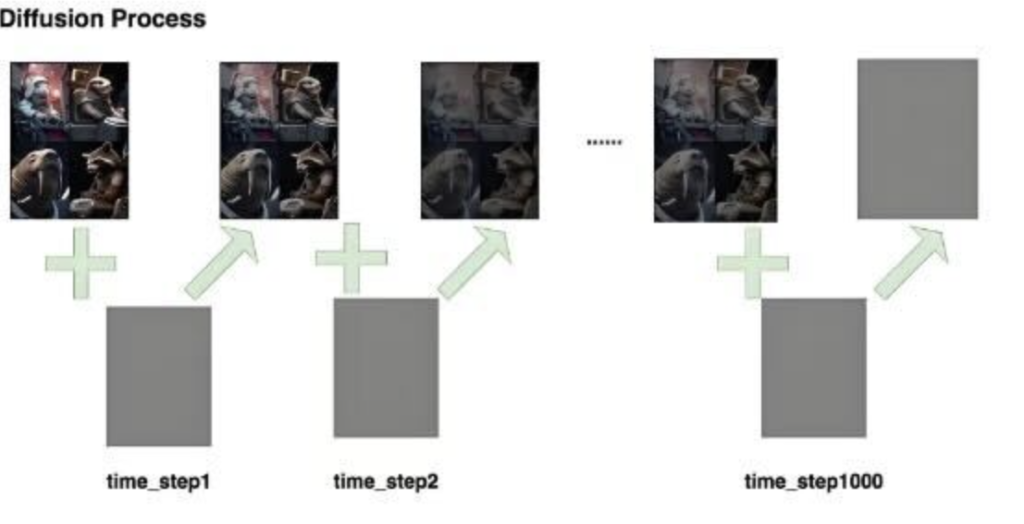
这个前向过程有几个关键特点:
- 它是固定的:每一步加多少噪声,是用一个预先设定的、简单的数学公式来控制的。我们完全掌握这个配方。
- 它是马尔可夫链:意思是,X_t 的状态只跟它的上一步 X_{t-1} 有关,跟更早的状态没关系。这大大简化了计算。
- 它是可数学表达的:由于整个过程是数学上精确定义的,我们可以写出一个公式,直接从最开始的清晰图片 X₀,一步到位地计算出任意中间步骤 X_t 的样子,而不需要真的去一步步模拟。这在训练时非常重要,能极大提高效率!
现在,艺术的毁灭完成了。这个过程的意义在于,我们收集了大量的毁灭证据:我们有从清晰到模糊的每一步的样本,以及我们知道每一步添加的噪声是什么。
逆向过程,是咋回事?🔖
下一步是最重要的部分:逆向过程(Reverse Process)或去噪过程(Denoising Process)。
我们的目标是训练一个 AI 模型,让它学会时间倒流:从纯噪声 X_T 一步步倒推回清晰的图片 X₀。
X_T → X_{T-1} → … → X₂ → X₁ → X₀
🔹AI 的任务是什么?
你可能会想,AI 的任务是不是在第 t 步,输入一张带噪的图 X_t,然后直接预测出它上一步更清晰的图 X_{t-1}?可以这么想,但实践中,大家发现了一个更聪明的办法!回忆一下,我们从 X_{t-1} 到 X_t,是往里面加了一点噪声,我们把这部分噪声叫做 ε。
X_t = α * X_{t-1} + β * ε(α、β 是系数)
那么,如果我们知道了 X_t,又知道了在这一步被加进去的噪声 ε,我们是不是就能通过一个简单的数学反算,把 X_{t-1} 给求出来?答案是肯定的!
所以,AI 的任务被巧妙地转换成了:在任意给定的步骤 t,输入带噪的图片 X_t,AI 需要预测出在这一步被添加进去的噪声 ε 是什么样子的。
这就像一个高超的文物修复师,他看着一件混杂了泥土的古董,他思考的不是 “这古董原来长啥样”,而是 “我应该从哪些地方、去掉哪些泥土”。预测噪声,就是预测要 “去掉的泥土”。
承担这个预测噪声任务的神经网络,是一个叫 U-Net 的家伙。
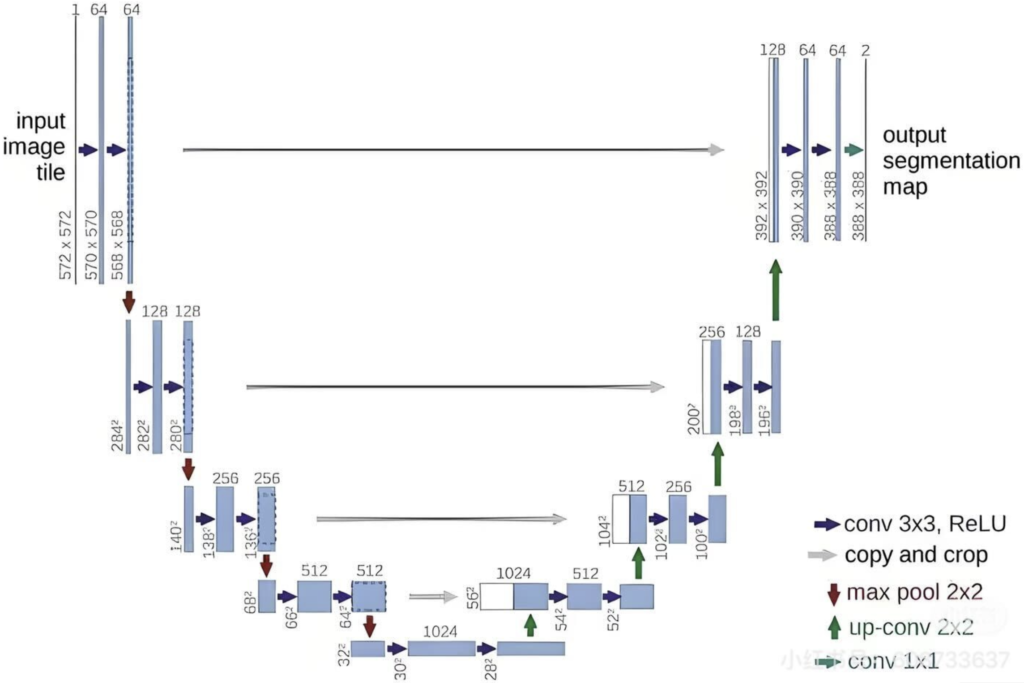
🔹它怎么工作?
a. 编码器(U 的左半边):当带噪图片 X_t 输入后,U-Net 会先像看缩略图一样,不断地对图片进行压缩和下采样。这个过程能帮助网络理解图片内容的宏观结构和语义。比如:“哦,这团噪声大概轮廓像个猫头”。
b. 瓶颈(U 的底部):在最底层,图片被压缩成了信息密度最高的 “特征精华”。
c. 解码器(U 的右半边):然后,网络再一步步地放大和上采样,逐渐恢复到原始图片的尺寸。在放大的过程中,它不仅利用底层的 “特征精华”,还会通过一种叫做 “跳跃连接(Skip Connection)” 的结构,把左边编码器在相应尺寸上提取到的细节信息也照抄过来。
- 跳跃连接是关键:这个抄作业的骚操作非常重要!它能确保在恢复细节时,不会忘记最开始输入图片里的高频信息(比如物体的边缘、纹理),让最终预测出的噪声图更精确。
- 最终输出:U-Net 的最终输出,就是一张和输入图片一样大小的噪声预测图 ε_pred。
训练过程就是不断地对答案:
- 随机抽一张训练图片 X₀。
- 随机选一个时间步 t(比如 t=250)。
- 通过前向过程的公式,直接从 X₀ 生成带噪图片 X_t,并记录下这一步实际添加的真实噪声 ε_true。
- 把 X_t 和时间步 t 一起喂给 U-Net。
- U-Net 输出一个它预测的噪声 ε_pred。
- 对比答案:比较 ε_pred 和 ε_true 之间的差距(计算损失)。
- 调整参数:根据这个差距,用梯度下降算法微调 U-Net 里所有的参数,让它下次预测得更准一点。
这个过程重复几亿、几十亿次,用海量的图片数据进行训练。最终,U-Net 就成了一个火眼金睛的噪声消除大师。你给它任何一张加了任意程度噪声的图片,它都能八九不离十地猜出当初是加入了什么样的噪声。
从 0 到 1 —— 看看 Diffusion 是怎么做的 🔖
好了,我们的雕琢大师 AI(训练好的 U-Net)已经出师了。现在,我们想让它画一张全新的画,该怎么做呢?
这个过程,就是纯粹的逆向过程的应用,也就是推理(Inference)或采样(Sampling)。
1. 起点
- 纯粹的混沌。我们不是从一张已有的图片开始,而是从一张完全随机的高斯噪声图开始。这张图就是我们的 X_T。你可以把它想象成一块未经雕琢的、内部纹理随机的 “大理石”。这张随机噪声图,就是你最终画作的种子(Seed)。换一个种子,最终的画作就会完全不同。
2.第一步雕琢(T → T-1)
- 把这张纯噪声图 X_T 和当前的时间步 T,一起输入到我们训练好的 U-Net 里。
- U-Net 会输出它预测的噪声 εpred。
- 我们从 X_T 中减去(或者根据特定采样算法进行处理)这个预测出的噪声 ε_pred,就得到了一个稍微不那么 “噪” 的图 X{T-1}。
- 终于,混沌中诞生了第一丝秩序!虽然它看起来还是一片噪声,但里面已经隐藏了未来画作最模糊的轮廓。
3. 第二步雕琢(T-1 → T-2)
- 把刚刚得到的 X_{T-1} 和时间步 T-1,再次输入 U-Net。
- U-Net 再次预测出在这一步应该去掉的噪声。
- 我们再从 X_{T-1} 中减去这部分噪声,得到 X_{T-2}。
- 现在,图片里的轮廓可能更清晰了一点点。
4. 循环往复,百炼成钢:
- 我们重复这个 **“预测噪声 → 去除噪声”** 的过程 T 次。
- 每一步,图片都变得更清晰、更有结构、细节更丰富。

5. 终点:
- 艺术品诞生了!当我们走到最后一步,从 X₁ 生成 X₀ 时,一张清晰、完整、细节丰富的全新 AI 画作就诞生了!它不是从训练集里复制出来的,而是从一片混沌的噪声中,根据 U-Net 学会的世界规则,一步步从噪声里挖出来的。
这个过程,是不是很像一位雕塑家,从一块璞玉开始,一刀一刀,慢慢凿去多余的部分,最终让内藏的绝美雕像显现出来?我记得米开朗基罗说过一句话:
💡 米开朗基罗:雕像本来就在石头里,我只是把不要的部分去掉而已!
如何引导 AI 的创作方向? 🔖
到目前为止,我们的 AI 画师还是一个自由艺术家。它能从随机噪声画出精美的画,但画什么,完全是随机的,我们控制不了。
那 Midjourney 和 Stable Diffusion 是怎么做到让我们用文字(Prompt)来控制画面内容的呢?这就需要引入一个至关重要的概念:条件引导(Conditioning)。
这是实现听指挥最核心的技术。思路很简单:在去噪的每一步,都给模型提供一个额外的提示或条件。
- 做法:在训练和生成时,我们不仅给去噪网络输入带噪的图片 X_t 和时间步 t,还把我们想要的条件信息 c 也一起输进去。
- 这个条件 c 可以是什么?
- 文本描述(Text Prompt):这就是 AI 绘画的魔法来源!比如 “a cat wearing a spacesuit”。我们会用一个强大的文本编码器(比如 CLIP 的 Text Encoder)把这句话变成一个向量,然后把它喂给去噪网络。去噪网络在去噪的每一步,都会参考这个文本向量,确保自己最终生成的图片内容和文本描述是一致的。
- 类别标签(Class Label):比如,告诉模型 “我现在想生成第 5 类的图片”。
- 另一张图片:这就是图生图(Image-to-Image)应用的基础。比如输入一张草稿,让模型生成精美的插画。
大白话:这就像清洁工在打扫卫生时,你不仅给了他脏了的房间,还在旁边贴了一张最终效果图(条件 c)。清洁工每擦一块地方,都会抬头看一眼效果图,确保自己的打扫方向是正确的,最终能还原出效果图的样子。
为啥 Diffusion 能又快又好?🔖
如果你玩过早期的扩散模型,你会发现一个问题:** 慢!因为上面的所有操作,都是在像素空间(Pixel Space)** 里进行的。一张 512×512 的图片,就有几十万个像素点,每一步都要对这么大的数据进行运算,计算量巨大,对显存要求也高。
于是,Stable Diffusion 的作者们提出了一个天才的改进方案:潜空间扩散模型(Latent Diffusion Model, LDM)。
核心思想:别在像素世界里卷了,我们去一个更小的世界里搞事情!
🔹1. 引入两个新工具:编码器和解码器(VAE)
我们训练了一个叫做 ** 变分自编码器(VAE)** 的东西。它由两部分组成:
- 一个编码器(Encoder):它的任务是把一张高分辨率的像素图片(比如 512×512),压缩成一张尺寸小得多的 **“潜空间特征图”**(比如 64×64)。这张小图虽然我们人眼看不懂,但它蕴含了原始图片绝大部分的关键信息。就像把一部长篇小说压缩成一份精准的内容大纲。
- 一个解码器(Decoder):它的任务和编码器相反,能把那张小小的 “潜空间特征图” 解压缩,完美地还原成高分辨率的原始图片。
🔹2. 在潜空间里扩散和去噪:
- 前向过程:我们不再对原始大图加噪声了,而是先把大图用 VAE 编码器压缩成小小的潜空间图,然后在潜空间里对这张小图加噪声。
- 逆向过程:我们的 U-Net,也只需要在小小的潜空间里工作!它输入的是带噪的潜空间图,输出的是预测的潜空间噪声。
- 因为操作的尺寸大大减小(比如从 512×512 降到 64×64,计算量可能减少了十几倍甚至更多),所以整个去噪过程变快了很多!
🔹3. 最后一步:见证奇迹。
- 当 U-Net 在潜空间里完成了全部的去噪步骤,得到了一张干净的 “潜空间特征图” 后,我们再把它喂给 VAE 的解码器。
- 解码器把这张我们看不懂的小图,还原成了一张我们熟悉的、高分辨率的、精美的最终画作!
扩散模型的优缺点总结🔖
讲了这么多优点,我们也要客观地看看扩散模型的两面性。
优点:
- ✅ 训练稳定:相比 GAN,扩散模型的训练过程非常稳定,不容易 “翻车”,调参压力小很多。
- ✅ 生成质量高、多样性好:不容易出现 GAN 的 “模式崩溃” 问题,能生成风格多样、质量极高的图片。
- ✅ 可控性强:通过条件引导,可以灵活地控制生成内容,玩出各种花样(文生图、图生图、Inpainting 等)。
缺点:
- ❌ 推理速度仍然偏慢:虽然 LDM 加速了很多,但它本质上还是一个需要迭代几百上千步的顺序过程。相比 GAN 那种 “一步到位” 的生成方式,还是要慢一些。现在有很多研究在尝试减少采样步数,甚至一步出图。
- ❌ 需要引导:如果没有条件引导,它就是个 “自由艺术家”,画出来的东西是随机的。它的强大在于被引导,而不是凭空创造特定内容。
- ❌ 对 “世界知识” 的理解仍有局限:比如你让它画 “一个人有三只手”,它可能会画不好,因为它在训练数据里没见过。它对物理世界、逻辑关系的理解,完全来自于海量数据的统计规律,而不是真正的认知。
来来来,总结一下吧🔖
来吧,兄弟们(含姐妹们),咱们来总结一下今天都聊了啥:
- 扩散模型的核心,是一个 “先破坏,再修复” 的过程。
- 破坏(前向过程):不断往图片上加噪声,直到变成纯噪声。
- 修复(逆向过程):训练一个 U-Net,让它学会从纯噪声中,一步步预测并去除噪声,最终还原 / 创造出清晰图片。
- 为了听懂人话,我们用 “条件引导”(如交叉注意力)给 U-Net 传小抄。
- 为了跑得更快,我们用潜空间扩散(LDM+VAE)在压缩后的小世界里干活。