转载:小红书 AI产品赵哥
前言🔖
面的几件事情,不知道大家有没有想过背后的原理:
- 😲 刷短视频,APP 总能精准推送你爱看的?
- 😲 网上购物,首页总能猜中你想买的东西?
- 😲 你的 email,能自动把烦人的垃圾邮件丢进回收站?
好像系统能够读懂你的内心?其实系统的背后就是我们今天要聊的 ——机器学习(Machine Learning, ML)。
它不是某个具体的软件,也不是某种特定的算法,而是一种技术思想,它让计算机从数据中自动学习规律。它是构成人工智能大厦最基础的那块砖头。
什么是机器学习?🔖
我们得先看看传统的计算机程序是怎么工作的。
🔹1. 传统编程:你告诉计算机怎么做
在传统编程里,人是规则的制定者。我们必须把解决问题的每一步都想得清清楚楚,然后用代码的形式,一条条地喂给计算机。
- 举个例子:写一个判断垃圾邮件的程序。
- 你可能会写下这样的规则:如果邮件标题包含 “发票”、“中奖”、“免费”,那么它就是垃圾邮件。如果发件人不在我的联系人列表里,那么它也可能是垃圾邮件。
- 问题:这种方式非常僵化。骗子们很聪明,他们会不断变换说法(比如把 “发票” 写成 “发嘌”),你的规则库就得不断地手动更新,永无止境,累死个人。
💡 传统编程的本质是:我们给计算机输入规则和数据,它输出答案。
🔹2. 机器学习:让计算机自己学
机器学习彻底改变了这个模式。我们不再是手把手地教计算机规则,而是变成了一个 “数据投喂员” 和 “教练” 的角色。
还是那个垃圾邮件的例子,用机器学习来做:
- a. 收集数据:我们收集成千上万封邮件,并且手动给它们打上标签:“这是垃圾邮件”、“这是正常邮件”。
- b. 我们把这些打好标签的数据,一股脑地喂给一个机器学习模型。
- c. 然后我们告诉模型:“你自己看着办吧!去从这些数据里,自己总结出垃圾邮件到底都有哪些千奇百怪的特征。”
- d.结果:模型可能会学到比我们想象中更复杂的规律。比如,它可能发现:垃圾邮件通常在凌晨 3 点发送,用的字体颜色很奇怪,或者某个词的出现频率特别高。这些都是人类工程师很难凭空想出来的规则。
💡 机器学习的本质是:我们给计算机输入数据和期望的答案,它自己输出规则。
💡 小结:机器学习,就是一种让计算机拥有学习能力的技术。它不是通过我们编写的硬性规则来解决问题,而是通过分析海量数据,自动从中发现模式、总结规律,并利用这些规律来对未来的、未知的数据做出预测或判断。
机器学习的工作流一瞥🔖
那么,机器到底是咋学的?这个过程听起来很神奇,但它的核心流程其实非常有逻辑。我们可以把它拆解成四个核心组件。
我们用一个非常简单的任务来贯穿这个案例:预测房价。
🔹1. 数据(Data):教材和习题
数据:是机器学习的燃料,没有数据,一切都是空谈。对于预测房价任务,我们的数据可能长这样:
- (房子面积:80 平米,房价:300 万)
- (房子面积:120 平米,房价:500 万)
- (房子面积:60 平米,房价:250 万)
- …… 成千上万条这样的记录。
🔹2. 模型(Model):学生和公式
模型:你可以把它理解成一个待求解的函数或公式。它定义了输入和输出之间可能存在的关系。一开始,这个模型很笨,是傻白甜的(里面的参数都是随机的)。
- 对于房价预测,我们可以建立一个最简单的线性模型:
房价 = w * 面积 + b - 是不是像极了我们初中学的一次函数
y = kx + b?这里的w和b就是模型需要学习的参数(Parameters)。w代表了面积对房价的影响权重,即每增加一平米,房价大概增加多少。b代表了基础房价,就算面积是 0,房子也可能有个地价。
- 学习的目标,就是找到最合适的
w和b,让这个公式能最好地拟合我们所有的数据。
🔹3. 损失函数(Loss Function):评分标准
模型一开始瞎猜了一组 w 和 b,然后它会根据这个公式去做出预测。但它怎么知道自己猜得好不好呢?这就需要损失函数。
- 损失函数的唯一任务就是:衡量 “模型的预测值” 与 “真实的答案” 之间的差距有多大。这个差距,就叫做损失(Loss)。
- 大白话:
- a. 假设模型猜的公式是
房价 = 3 * 面积 + 50。 - b. 对于那套 80 平米的房子,它的预测价是
3 * 80 + 50 = 290万。 - c. 但真实价格是 300 万。
- d. 那么,这次预测的损失就是
(300 - 290)² = 100(用平方是为了避免负数)。
- a. 假设模型猜的公式是
- 我们会计算模型在所有数据上的总损失。总损失越大,说明模型现在越菜;总损失越小,说明模型越接近正确答案。
🔹4. 优化器(Optimizer):学习方法
现在,模型知道了自己错得有多离谱(损失很大)。它需要一个方法来调整自己的参数 w 和 b,从而让损失变小。这个方法,就是优化器。
- 最常用的优化器叫做梯度下降(Gradient Descent)。
- 大白话 ——“盲人下山”:
- a. 想象一下,损失函数是一个连绵起伏的山脉,我们的目标是走到山谷的最低点(损失最小的地方)。
- b. 我们自己(模型)被蒙上了眼睛,站在山上的某个随机位置。
- c. 我们该怎么办?最聪明的办法是:伸出脚,感受一下当前位置哪个方向是下坡最陡的,然后就朝那个方向迈一小步。
- d. 这个 “下坡最陡的方向”,在数学上就是 ** 梯度(Gradient)** 的负方向。
- e. 我们不断地重复 “感受最陡下坡 → 迈一小步” 这个过程,最终就能走到山谷的最低点。
- 在机器学习中,“迈出的那一步”,就是对参数
w和b的一次更新。模型通过梯度下降,不断微调w和b,每一次调整都确保总损失会比上一次更小一点。
整个机器学习的训练过程,就是这四个组件不断循环的过程:** 模型做出预测 → 损失函数评估好坏 → 优化器根据评估结果,指导模型调整参数 → 调整后的模型再做出新的预测……** 如此循环往复,直到损失小到一个我们可以接受的程度。
机器学习的三大流派🔖
根据我们投喂的数据类型和学习目标的不同,机器学习主要可以分为三大门派。
🔹1. 监督学习(Supervised Learning):有标准答案的教学
监督学习是最常见、应用最广泛的一类。它的特点是,我们提供给模型的数据是有明确标签或答案的。
- 就像一个学生在做有标准答案(标签)的习题集(训练数据)。
- 我们前面举的垃圾邮件分类(标签是 “垃圾” 或 “正常”)和房价预测(标签是具体的房价数值),都属于监督学习。
- 根据标签是离散的类别(如 “猫”、“狗”)还是连续的数值(如房价、气温),监督学习又可以细分为:
- 分类 (Classification):预测一个物体属于哪个类别。比如图像识别、人脸识别。
- 逻辑回归:二分类 / 多分类,基于线性模型 + Sigmoid 函数,适合二分类问题。
- 决策树:基于特征分裂构建树结构,直观易解释,适合中小规模数据。
- 随机森林:集成多个决策树,通过投票降低过拟合,鲁棒性强。
- 支持向量机(SVM):寻找最优超平面分类,适合高维数据(如文本、图像特征)。
- K 近邻(KNN):基于 “近邻投票” 分类,简单直观,适合小样本数据。
- 神经网络:如 CNN(卷积神经网络)、RNN(循环神经网络),适合图像、语音等复杂任务。
- 回归 (Regression):预测一个连续的数值。比如股票价格预测、销量预测。
- 线性回归:拟合线性关系,如房价预测、销量预测。
- 岭回归 / 套索回归:加入正则化项,解决过拟合问题。
- 决策树回归:基于决策树的回归模型,适合非线性关系。
- 梯度提升树(GBDT/XGBoost/LightGBM):集成多个弱回归树,提升预测精度。
🔹2. 无监督学习(Unsupervised Learning):没有答案,自己找规律
无监督学习的挑战更大。我们给模型的数据是没有任何标签的。
大白话:就像一个人类学家,被扔到一个从未接触过的原始部落里。没有人告诉他谁是首领、谁是祭司,他只能通过观察人们的行为、衣着、语言,自己去发现部落里的社会结构和潜在规则。
主要应用:
- 聚类 (Clustering):把相似的东西自动归为一类。比如,一个电商网站可以根据用户的购买行为,自动把用户分成 “高价值用户”、“价格敏感型用户”、“潜在流失用户” 等群体,从而进行精准营销。
- K 均值(K-Means):将数据分为 K 个簇,简单高效,适合球形分布数据。
- 层次聚类:构建聚类树,直观展示数据层级关系,适合小样本。
- DBSCAN:基于密度的聚类,可识别异常值,适合非球形分布数据。
- 高斯混合模型(GMM):基于概率模型的聚类,适合多模态数据。
- 降维 (Dimensionality Reduction):在保留核心信息的前提下,减少数据的复杂度。
- 主成分分析(PCA):将高维数据映射到低维空间,保留最大方差。
- t-SNE:将高维数据降维到 2-3 维,适合可视化(如图像特征)。
- 自编码器(AutoEncoder):通过神经网络实现降维,适合复杂数据。
🔹3. 强化学习(Reinforcement Learning):在试错中学习
强化学习的模式又不一样。它没有现成的数据集,而是让一个智能体(Agent)在一个环境(Environment)中自己去探索。
- 举个例子:就像训练一只小狗。你不会给它看 “如何坐下” 的教学视频。你会在它碰巧做对 “坐下” 这个动作时,给它一块零食(奖励,Reward);在它做错时(比如乱叫),不给零食或轻轻拍它一下(惩罚,Punishment)。
- 通过不断的 “尝试 – 反馈” 循环,智能体自己会学到一套策略(Policy),知道在什么状态(State)下,采取什么行动(Action),才能获得最大的长期累计奖励。
- 经典案例:大名鼎鼎的 AlphaGo 下围棋,就是强化学习的杰作。它通过无数次的自我对弈,最终学会了超越人类的棋艺。自动驾驶中的路径规划、机器人的行走控制等,也大量用到强化学习的思想。
主要应用:
- Q-Learning:基于 Q 值(动作价值)的离线学习,适合离散动作空间。
- SARSA:与 Q-Learning 类似,但更新 Q 值时依赖下一个状态,适合在线学习。
- 策略梯度(Policy Gradient):直接优化策略函数,适合连续动作空间(如自动驾驶)。
- 深度强化学习(DRL):结合深度学习,如 DQN(深度 Q 网络)、PPO(近端策略优化),适合复杂任务(如游戏、机器人控制)。
- 马尔可夫决策过程(MDP):强化学习的数学框架,定义状态、动作、奖励的关系。
当然,强化学习在端到端自动驾驶领域,也大放异彩,这个我在相关笔记中也有涉及。
一个完整的例子 —— 一起训练一个房价预测模型🔖
理论讲了这么多,我们来把整个流程串一遍,看看一个最简单的机器学习项目是如何落地的。
目标:训练一个模型,能根据房屋面积预测房价。
第一步:收集数据(教材)
我们拿到了一个包含 10000 套房产交易记录的数据集,每一条记录都包含了<面积, 总价>。
第二步:选择模型(公式)
作为初学者,我们选择最简单的线性回归模型:
预测房价 = w * 面积 + b
第三步:初始化模型(瞎猜一次)
在训练开始前,w 和 b 是随机给定的。比如,计算机一通瞎猜,w=1.5,b=80。
第四步:正向传播与计算损失(做题与对答案)
- 我们拿出第一条数据:(面积 80 平米,真实房价 300 万)。
- 模型的预测是:
1.5 * 80 + 80 = 200万。 - 计算损失:真实值是 300 万,预测值是 200 万。差距太大了!损失函数算出来一个巨大的损失值。
第五步:反向传播与优化(反思与改正)
- 优化器(梯度下降)上场了。它根据巨大的损失值,计算出梯度,发现 “为了让损失变小,
w应该再大一点,b也应该再大一点”。 - 于是,它对参数进行了一次微小的更新。比如,
w从 1.5 变成了 1.6,b从 80 变成了 82。
第六步:循环往复,天荒地老
然后,模型拿着新的参数(w=1.6,b=82),去处理第二条、第三条…… 直到所有的数据。每处理一批数据,就重复一遍 “预测 → 算损失 → 更新参数” 的过程。
- 这个过程会重复很多轮(我们叫它 Epoch)。一开始,损失会飞快地下降;慢慢地,损失下降得越来越慢,最终稳定在一个很小的值。
- 大白话:这个 “炼丹” 的过程,可能需要几分钟,也可能需要几天几夜。最终,我们可能会得到一组最优的参数组合,比如
w=4.2,b=65。
第七步:部署与预测(上考场)
现在,我们有了一个训练好的模型:预测房价 = 4.2 * 面积 + 65。
当一个新客户来问:“我有一套 95 平米的房子,大概能卖多少钱?”
我们就可以把 95 代入公式:4.2 * 95 + 65 = 464 万。模型给出了一个相当靠谱的预测!
这就是机器学习的一次完整生命周期。
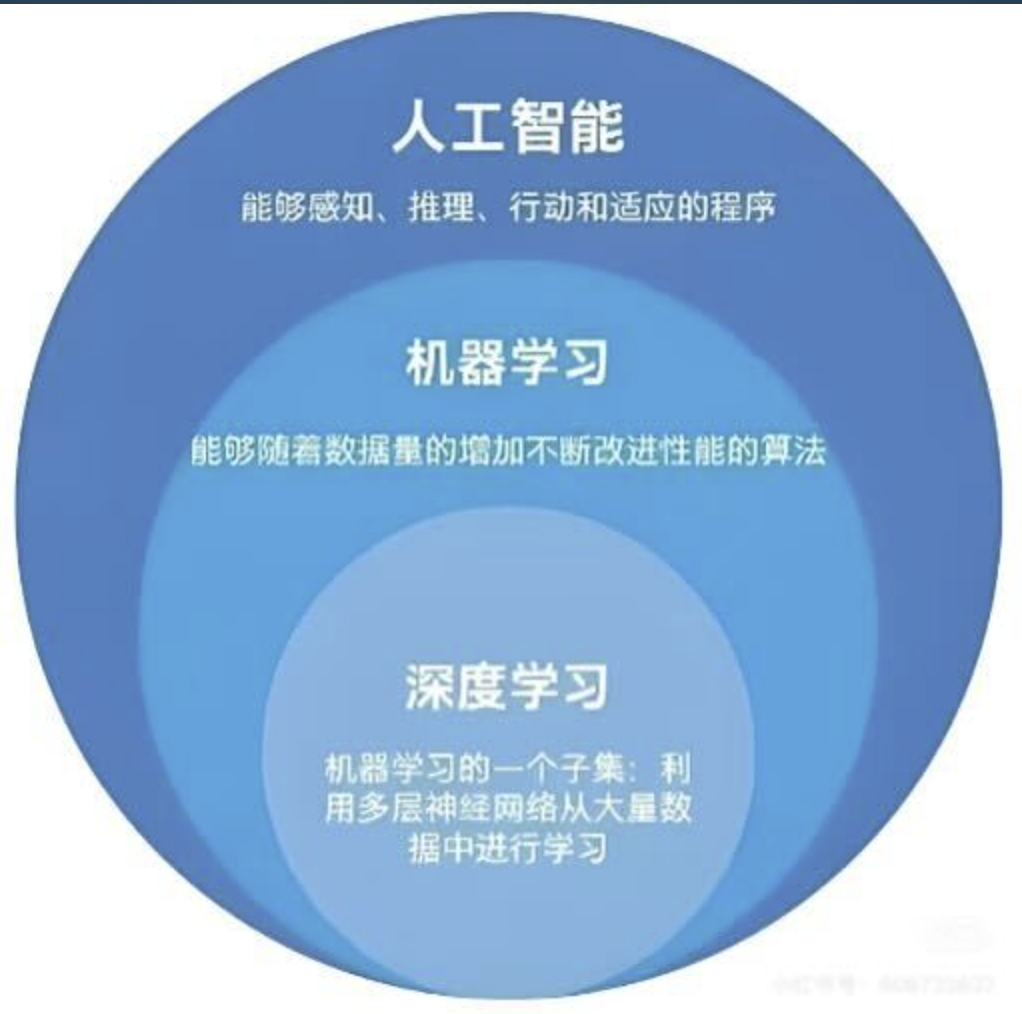
理清关系 —— AI、机器学习、深度学习的关系🔖
这是初学者最容易混淆的地方,我们用一张图就能说清楚。