转载:小白必看:大模型内部结构揭秘——从Token到Transformer的完整指南!
前言🔖
在 ChatGPT 席卷世界之后,很多人都听过「大语言模型(LLM)」这个词。
但当我们问自己:“LLM 的内部结构究竟是什么?” 时,往往只有模糊的印象。
它似乎是某种“巨大的黑箱”,能理解人类语言、生成回答、甚至推理创作。
然而,打开那层黑箱,你会发现——它其实是一个层层构建的语言“思考机器”。
今天,我们从结构角度,带你看清 LLM 的核心组成:
分词(Tokenization) → 词嵌入(Embedding) → 位置编码 → N 层 Transformer架构 → 输出概率。
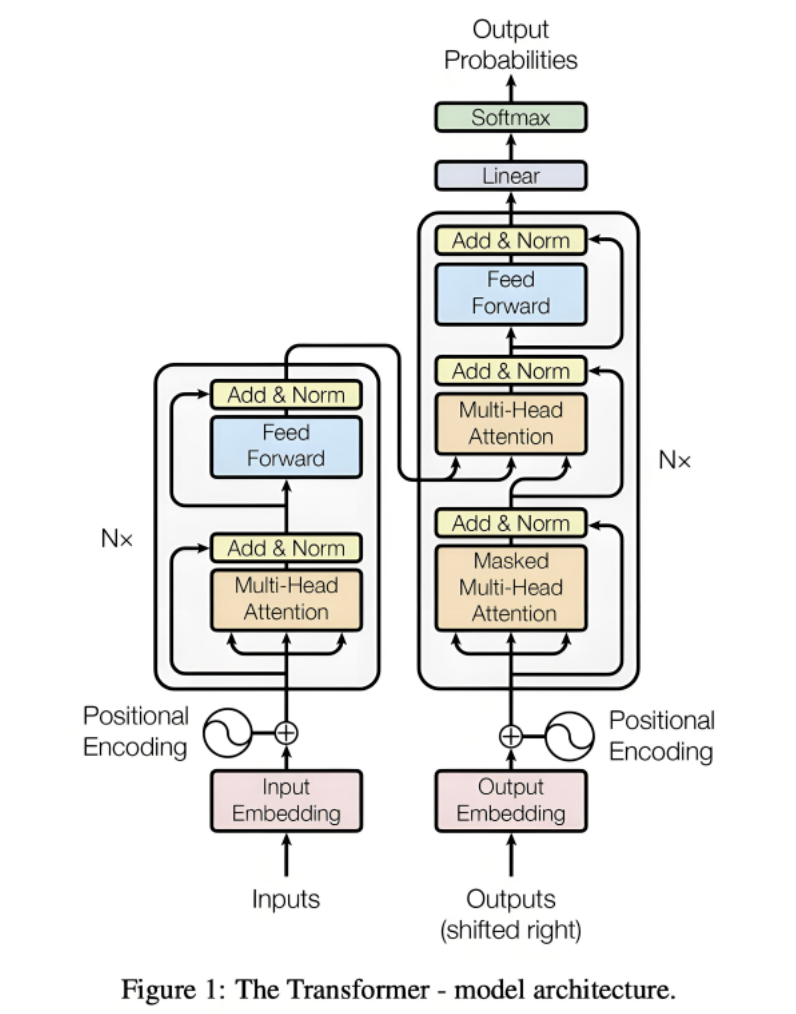
上图是经典的 Transformer 整体框架结构,它的原始出处是发表于 2017 年的开创性论文”Attention Is All You Need”,读完整篇文章您就可以理解
粗浅理解 大模型就是一个函数是吗? 提示词是调用的参数?🔖
大模型本质就是一个 “输入→计算→输出” 的数学函数,提示词就是调用这个函数的核心输入参数。
我们可以用更通俗的方式拆解这个类比:
函数的基本形式是:
输出 = 模型函数(输入, 推理参数)
↑
由两部分共同构成:
1. 架构代码 → 函数的“计算规则”(比如注意力怎么算、向量怎么映射)
2. 权重文件 → 函数的“系数参数”(比如Q矩阵的0.0123、词嵌入矩阵的数值)
- 函数的 “计算规则”:由训练好的权重参数决定(就是那些你下载的.bin/.safetensors文件里的浮点数)。这些权重是函数的 “固定逻辑”,训练完就不会变,相当于函数里的系数。
- 函数的 “输入”:主要就是提示词(Prompt),比如 “写一首春天的诗”“把这张图变成动态视频”。
- 函数的 “控制参数”:就是你之前了解的temperature、top_k、max_new_tokens等推理参数,用来调节函数输出的风格(比如严谨 / 创意)和长度。
- 函数的 “输出”:就是模型生成的文本、视频、代码等结果。
用更精准的方式拆解这个函数的构成:
- 架构代码 = 函数的 “计算规则”
相当于数学里的f(x) = ax² + bx + c这个公式本身:
它定义了 “输入 x 要先平方、再乘 a、再加 bx、最后加 c” 的步骤;
对应 LLM 的架构代码,就是定义了 “输入提示词要先分词、再做词嵌入、再跑 Transformer、最后算概率” 的步骤。
- 权重文件 = 函数的 “系数(a/b/c)”
相当于f(x) = 2x² + 3x + 5里的2/3/5这些具体数值:
没有这些数值,公式只是空架子(比如f(x)=ax²+bx+c算不出任何结果);
对应 LLM 的权重文件,就是.safetensors里的浮点数 —— 没有这些数值,架构代码的 “注意力计算”“词嵌入” 都只是空的数学公式,无法生成任何有意义的输出。
- 关键补充:
当你加载一个大模型时,本质是把权重文件的数值 “填充” 到架构代码的公式里,让空的 “模型函数” 变成有具体计算能力的 “可用函数”;
推理参数(temperature/top_k 等)是这个函数的可选参数—— 不改变函数的核心计算逻辑,只调整输出的风格(比如更随机 / 更确定)。
- 总结
“模型函数” 确实同时包含了:
架构代码(函数的计算逻辑 / 公式);
权重文件(函数的系数 / 具体数值)。
这也是为什么 “只给权重文件用不了”—— 就像只给你2/3/5,却不给你f(x)=ax²+bx+c这个公式,你永远不知道该怎么用这些数字计算。
分词(Tokenization):把文字拆成模型能懂的「语言颗粒」🔖
人类用“字”或“词”交流,但计算机只懂数字。
Tokenization(分词) 的任务,就是把自然语言切成一个个模型能理解的最小单位——Token。
举个例子:
句子:我喜欢学习AI
可能会被切分成:
["我", "喜欢", "学习", "A", "I"]
每个 token 都会被映射成一个唯一编号(比如 104、2075、…)。模型之后处理的,其实就是这些编号,而非汉字本身。
为什么要分词?🔖
因为这样能把语言“离散化”为数字序列,方便输入神经网络,同时控制计算量。
LLM 不能把整句话直接当参数,必须分词,本质是为了 “降低计算复杂度 + 实现语言的复用与泛化”,我们用通俗的逻辑拆解清楚。
🔹先想清楚:为什么不能把 “整句话” 当参数?
假设你输入 “写一首春天的诗” 这句话,如果直接把它当一个 “整体参数” 喂给模型:
- 参数数量会爆炸:人类的语言组合是无限的 ——“写一首春天的诗”“写两首春天的诗”“写一首夏天的诗”…… 光是和 “写诗” 相关的句子就有上亿种,模型不可能为每一句话都单独分配一个 “参数向量”(相当于要记住上亿个独立的数字组合),7B 模型的参数都不够用。
- 无法泛化:如果模型只认识 “写一首春天的诗” 这个整句,当你输入 “写一首春天的歌”,模型会完全不认识 —— 因为这是一个 “新整句”,没有对应的参数,就像字典里没有这个词,根本查不到。
- 计算效率极低:整句话没有 “结构”,模型无法拆解语义(比如分不清 “春天” 是核心、“诗” 是目标),只能像背答案一样死记硬背,既耗显存又慢,完全不具备实用价值。
🔹分词的核心价值:把 “无限句子” 变成 “有限组件”
分词(Tokenization)本质是把无限的自然语言句子,拆解成有限的基础组件(Token),就像搭乐高:
- 乐高的核心:用 “方块、长板、轮子” 这几百种基础零件,能拼出无限种造型(汽车、房子、机器人);
- LLM 的核心:用 “你、好、春、天、的、诗” 这几万种基础 Token(比如 Llama 2 的词表是 32000 个),能组合出无限种句子。
🔹具体来说,分词带来 3 个关键好处:
1. 降低计算成本(核心原因)
模型只需要为3-5 万个 Token 分别训练词嵌入向量(比如 “春” 对应一个 4096 维的向量,“天” 对应另一个),而不是为无限句子训练向量。
- 举例:Llama 2-7B 的词嵌入矩阵是
32000×4096(约 1.3 亿参数),如果为整句话训练,这个矩阵会变成 “无限 ×4096”,完全不可能实现。
2. 实现语义泛化
Token 是 “语义最小单元”,模型能通过 Token 的组合理解新句子:
- 模型学过 “春”“天”“的”“诗” 这些 Token 的语义,当它第一次看到 “写一首春天的诗”,能通过 Token 的组合(“春 + 天 = 春天”“春天 + 的 + 诗 = 春天的诗”)理解整句话的意思;
- 哪怕你输入 “春天的诗很美” 这个新句子,模型也能靠已学的 Token 组合出语义,不用重新训练。
3. 适配模型的计算逻辑
Transformer 的注意力机制是按 Token 维度计算的 —— 模型需要为每个 Token 计算和其他 Token 的关联(比如 “它” 关注 “猫” 还是 “狗”),如果没有分词,注意力机制就没有 “计算单元”,无法完成语义关联分析。
🔹通俗类比:分词 = 把文章拆成 “字 / 词”
你可以把 LLM 的分词类比成我们读书时的 “识字过程”:
- 婴儿学说话:先认 “爸、妈、水、饭” 这些单字(Token),再学 “爸爸、妈妈、喝水、吃饭” 这些词,最后才能组合出 “爸爸喝水”“妈妈吃饭” 这些句子;
- LLM 学语言:先学每个 Token 的语义(“春”= 温暖、花开,“诗”= 韵律、文字),再学 Token 的组合规则,最后才能生成 “写一首春天的诗”。
如果跳过分词直接学整句,就像婴儿直接学 “爸爸喝水” 这个整句,却不认识 “爸、爸、喝、水”—— 换一句 “妈妈喝水” 就完全不懂了。
🔹总结
- ❌ 整句话当参数:无限组合、无法泛化、计算爆炸,完全不可行;
- ✅ 分词当参数:把无限句子拆解成有限 Token,降低计算成本,让模型能理解、泛化、生成无限的自然语言。
简单说:分词是 LLM 能 “用有限的参数,处理无限的语言” 的核心前提。
词嵌入(Embedding):让符号拥有「语义温度」🔖
在语言模型中,计算机最初看到的只是一个个离散的符号(token),例如“猫”“银行”“run”。
这些符号对计算机来说是没有意义的,它们只是数字 ID。而 Embedding 层 的作用,就是让这些冰冷的符号拥有“语义温度”——也就是,把它们映射到一个可以计算语义距离的向量空间中。
🔹从符号到向量
Embedding 可以理解为一个“词典矩阵”:
每个词(token)都被表示为一个固定长度的向量(如 1024 维)。
模型在训练过程中,会不断调整这些向量,使得语义相近的词在空间中靠得更近。
例如:
• “猫(cat)”和“狗(dog)”的向量距离会非常接近;
• 而“猫(cat)”和“金融(finance)”的距离则会很远。
于是,模型不仅“看到”了词本身,还能“感知”它与其他词的语义关系。
这为后续的注意力机制(Self-Attention)提供了基础的“语义几何空间”。
🔹向量空间的语义规律
在这个高维空间中,语义关系会以几何结构的方式自然显现。
比如经典例子:
king - man + woman ≈ queen
这说明模型“理解”了性别、角色等抽象语义差异。

🔹谁来训练这些向量?
词嵌入的生成并不是手工设定的,而是通过大规模无监督学习自动获得的。
最早的模型如 word2vec、GloVe 专门用来训练词向量;
而在现代大语言模型(如 GPT、Qwen、DeepSeek)中,Embedding 层的参数与模型一同训练,并在更庞大的语料中持续更新。
例如,Qwen-1.5 系列在预训练阶段就包含了上百亿条语料,Embedding 层会随着模型学习语义关系而不断演化,使其能精细地捕捉不同语言、领域、风格的语义细节。
换句话说:
词嵌入是语言模型的「语义地基」,
它将离散的语言符号转化为连续的语义坐标,
为 Transformer 理解、推理和生成语言打下基础。
位置编码:赋予语言「顺序感」🔖
到这里,模型知道每个词“是什么”,但还不知道它“在句子里的位置”。
例如:
“猫追狗” vs “狗追猫”
词相同,但顺序颠倒,意义完全不同。
Transformer 结构没有像 RNN 那样的“时间记忆”,所以必须显式告诉它词语的顺序。这就是 Position Encoding(位置编码) 的作用。
它会为每个 token 增加一个位置向量,比如第一个词加 [sin(1), cos(1)],第二个加 [sin(2), cos(2)]……
这样模型在学习时能区分出:
“前后顺序不同 → 含义也不同”。
现在,模型拥有了语义(Embedding)+ 顺序(Position)两种基础信息。接下来,我们进入真正的核心——Transformer Block。
Transformer Block:语言理解的「心脏」🔖
我们希望 LLM 不仅是简单的词语拼接机器,而是具备强大的推理和语义理解能力的“语言大脑”。 为了实现这一目标,仅仅堆叠神经元是不够的。Transformer Block 作为 LLM 的基本计算单元,必须包含一套精巧的协作机制,才能有效地完成以下关键任务:
- 捕捉上下文的动态关系(解决多义词歧义)。
- 同时从多个维度解析语言(解决复杂性和多重含义)。
- 确保生成过程的逻辑和时间正确性(解决自回归生成问题)。
- 对抽象特征进行深度加工和提炼(解决高层语义理解)。
接下来的各个组件(自注意力、多头、掩码、前馈网络等),正是为了协同完成上述复杂任务而设计,它们共同构成了真正加工语言的“车间”的内部流程。
一个 LLM 通常由几十上百层(比如 GPT-4 约 120 层)这样的 Block 堆叠而成。每一层都负责对语言的理解更进一步。
🔹自注意力机制(Self-Attention):理解上下文的灵魂机制
核心思想是:
“一个词的意义,取决于它与上下文的关系。”
例如这句话:
“她把卡里的钱存到了A行。”
这里的“A行”,到底指的是银行还是公司分行?模型不能凭“行”这个词本身去判断,它要根据上下文的线索——“卡里的钱”“存到”——去理解语义。
Self-Attention 就是让模型学会这样“环顾四周”。
每个词在这一层都会生成三个向量:
- Query(查询):表示“我现在想找和我有关的信息”;
- Key(键):表示“我能被别人关联到哪些信息”;
- Value(值):表示“如果别人找到我,我能提供什么信息”。
你可以把它想象成一个会议场景:
每个词(与会者)都有一个提问卡(Query),一张名片(Key),和一份资料(Value)。
当“行”这个词想弄清自己是什么意思时,它会把自己的 Query 拿去和所有词的 Key 对比。
相似度越高,说明对方提供的信息越相关,就会给予更高的“注意力权重”。
最后,“行”会根据这些权重,把别人的 Value 按比例整合起来,
于是它对自己的理解变得更清晰——在这个语境下,它就是“银行”的“行”。

🔹多头注意力机制(Multi-Head Attention):从多个视角理解语言
仅靠一个注意力通道是不够的。语言中的联系是多维的——有的词在语法上相关,有的在语义上呼应。为了同时捕捉这些不同层面的信息,Transformer 引入了 多头注意力机制(Multi-Head Attention)。
模型会并行地建立多个独立的注意力通道,每个“头”都专注于不同的语言关系。
可以把它想象成一个讨论组:每个成员从自己的角度阅读句子,最后再综合意见。
例如:
- 第一个头关注主语和动词之间的关系
- 第二个头关注时间副词和动作之间的联系
- 第三个头可能专门捕捉情感色彩或语气变化
所有这些“视角”最后被融合在一起,形成了对整句话更立体、更全面的理解。这就是多头注意力的意义所在。
🔹带掩码的多头注意力(Masked Multi-Head Attention):防止“偷看未来”
在语言生成(Decoder)阶段,模型必须一边生成、一边预测下一个词。它不能“偷看”未来还没生成的部分。
为此,引入了 Mask(掩码)机制:
对当前位置之后的词,模型会自动屏蔽,不去计算它们的注意力。
这样,模型在生成句子时,只能参考已经生成的内容,就像人类写作时一边想一边写,保证语言的时间顺序是正确的。
在Transformer 模型的Decoder 中出现在Masked Multi-Head Attention。为什么需要masked,“掩码”的目的是在计算注意力时,阻止模型“看到”某些不应该看到的信息。在给出第一个词的基础上,去猜测下一个词是什么。不添加掩码,可以说是看着答案结论的一个操作。
这是生成式模型(如GPT)的关键。在训练或生成时,解码器应该只能“看到”当前词及之前的词,而不能“偷看”未来的词。这确保了自回归生成的特性。
以翻译为例:

Decoder 的输入矩阵和 Mask 矩阵, 输入矩阵包含 “ I have a cat” (0, 1, 2, 3, 4) 五个单词的表示向量, Mask 是一个 5×5 的矩阵. 在 Mask 可以发现单词 0 只能使用单词 0 的信息, 而单词 1 可以使用单词 0, 1 的信息, 即只能使用之前的信息。

🔹前馈神经网络(Feed Forward):提取更高层语义
Self-Attention 帮模型理解了词与词之间的关系,但每个词自身的特征也需要进一步加工。这时就轮到 前馈网络(Feed Forward Network) 出场了。
它相当于给每个词单独配备一段小型的“思考回路”,帮助模型进一步提炼和重组语义。
经过这一步,模型能捕捉到更深层次、更抽象的特征,让语言理解更加细腻。
🔹残差连接与层归一化:让学习更稳定
Transformer 的每一层还包含两项关键设计:
残差连接(Residual Connection) 和 层归一化(Layer Normalization)。
- 残差连接让输入信息能够绕过当前层直接传递下去,防止网络太深导致“记不住”原始信息。
- 层归一化则让每层的数值保持稳定,避免训练过程发散或震荡。通过这两个机制,Transformer 可以稳定地堆叠几十层甚至上百层,仍然保持信息流动顺畅。
🔹小结
Transformer Block 的内部结构,就像一台“语言理解引擎”:
- Self-Attention:理解上下文,建立词与词的关系;
- Multi-Head:多角度并行思考;
- Mask:保证生成时不“偷看未来”;
- Feed Forward:提炼更高层语义;
- 残差与归一化:保证深层网络稳定训练。
当这样的 Block 层层堆叠时,模型就能从浅层语法、到深层语义、再到逻辑推理,一步步构建出对语言的深度理解。
输出层:预测下一个 Token 的概率🔖
所有 Transformer 层的输出最终汇总成一个隐藏向量,这个向量会被投影(Linear Projection)回到词表维度,得到每个可能词的概率分布:
“我今天很 ——”
→ 高概率输出:“开心”、“累”、“忙”……
→ 低概率输出:“香蕉”、“汽车”。
模型通过 Softmax 将这些分数转成概率,从中采样或选取最高值,就生成下一个词。
这就是语言生成的基本过程。
模型的参数:哪些会被迭代?🔖
在整个模型结构中,以下部分的参数会在训练中不断更新:
| 模块 | 参数类型 |
|---|---|
| Embedding 层 | 每个 token 的词向量矩阵 |
| Attention 层 | Q, K, V, O 四个投影矩阵 |
| Feed Forward 层 | 两层线性权重矩阵 |
| 层归一化 | 缩放和偏移参数 |
这些参数的数量往往以 百亿甚至万亿 计,
训练的过程,就是通过梯度下降不断微调这些参数,让模型“更懂语言”。
总结:语言的机器心脏🔖
我们可以用一句话概括整个逻辑:
- Tokenization 让文字被看见
- Embedding 让文字有意义
- Position 让语言有顺序
- Transformer 让语义被理解
- Output 让思想得以表达
这,就是一个 LLM 的完整生命线。它并非魔法,而是数学与结构的奇迹。在无数层矩阵计算的背后,是人类让语言自我理解的壮举。