随着人工智能技术的不断发展,AI大模型在各个领域展现出强大的能力,也引起了广泛关注。
在了解这些模型时,我们经常会看到诸如「参数」、「Token」、「上下文窗口」、「上下文长度」和「温度」等术语。这些术语代表着什么意思?它们对AI大模型有何影响?
本文将深入浅出地为你解析这些概念,并结合实际案例和数据,帮助你理解 AI 大模型的运作机制。
Parameter 参数:模型的复杂度和性能指标
参数是 AI 模型在训练过程中学习和调整的变量。它们的数量决定了模型的复杂度和性能。参数越多,模型能够表示更复杂的关系,从而在任务上取得更好的效果,但也需要更多的训练数据和计算资源。
例如,GPT-3 拥有 1750亿个参数,而WuDao 2.0的参数数量则高达1.75万亿。这也就意味着WuDao 2.0能够学习更加复杂的数据模式,在自然语言处理、机器翻译等任务上展现出更强的能力。
然而,参数数量并不是衡量AI大模型性能的唯一指标。训练数据的质量、模型架构等因素也至关重要。
用一个例子解释就是,假设一个 LLM 模型包含1亿个参数,那么在训练过程中,模型需要调整1亿个可变值才能达到最佳性能。这需要大量的训练数据和计算资源。
Token:模型理解和处理的基本单位
在 AI领域,Token 是指模型处理的基本数据单位。它可以是单词、字符、短语甚至图像片段、声音片段等。例如,一句话会被分割成多个 Token,每个标点符号也会被视为单独的Token。
Token 的划分方式会影响模型对数据的理解和处理。例如,中英文的 Token划分方式就存在差异。对于中文,由于存在多音字和词组的情况,Token 的划分需要更加细致。为了更好地理解 Token的概念,让我们来看一个简单的例子。假设我们要将句子今天天气很好
进行 Token 化,那么,该句子的 Token 序列可能有以下几种情况,取决于大模型的分词规则、架构以及数据集:
基于空格的 Token 化:
['今天','天气','很好']
基于字的 Token 化:
['今','天','天','气',‘候',‘很',‘好']
上下文长度(Context Length)
也称为上下文窗口(Context Window),指的是大语言模型(LLM)在处理和生成文本时能够有效记忆和利用的信息范围。简单来说,就是模型一次能够“看到”和“记住”的文本序列的最大长度,通常以词元(token)的数量来衡量。一个词元可以是一个词、一个子词,甚至一个字符,具体取决于模型的分词策略。
上下文长度的影响:对于经常使用大模型的人来说,最大上下文长度无疑是一个至关重要的评价指标。这一点,在Kimi等大模型的宣传中也有所体现,它们声称能支持长达128K的上下文长度。那么,什么是上下文呢?简单来说,它就是大模型的“记忆”。大模型之所以能进行连续会话、文档解析以及按需提取内容,全赖于其强大的记忆能力,而这个记忆容量就由最大上下文长度来衡量。
在实际应用中,各大模型都会明确标示自己支持的最大上下文长度。例如,DeepSeek就宣称其最大上下文长度为64K。这里的64K指的是64乘以1024个token,而token作为大模型中的最小单位,可以理解为单个汉字或符号或单词的等价物(通常一个汉字约等于0.6个token)。这意味着,使用DeepSeek进行一次会话时,系统的提示词、用户的提问以及助手的回复等所有内容,都必须严格控制在10万字以内,否则就可能超出模型的处理能力。
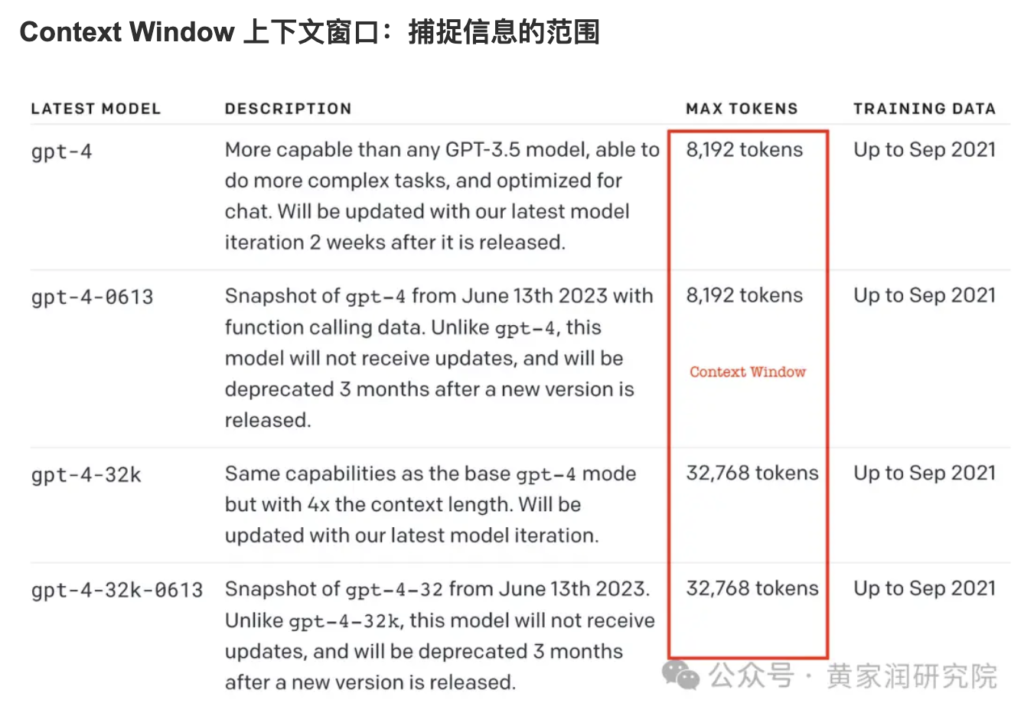
- 定义:指模型在单次交互中能够处理的最大 token 总量上限,是模型设计时就固定的参数(由模型架构、训练数据和硬件限制决定)。
- 特点:
- 是一个固定值,例如 “4k 窗口”“128k 窗口”,对应具体的 token 数量(4096、131072 等)。
- 包含模型在当前交互中需要处理的所有信息:用户的提问、历史对话记录、模型自身的回应(部分模型会将生成内容计入窗口)等。
- 决定了模型 “能记住多少信息” 的上限,超过这个上限的内容会被截断或无法处理。
- 示例:GPT-3.5 的默认窗口是 4k token,意味着它在一次对话中最多能 “看到” 4096 个 token 的内容(包括历史消息和当前提问);如果输入内容超过这个值,后面的部分会被忽略。
重要性:
- 理解复杂指令和对话: 更长的上下文使得模型能够理解包含多个步骤或依赖先前信息的复杂指令,并在多轮对话中保持连贯性和相关性。
- 处理长文档: 对于文档摘要、问答、信息提取等任务,模型需要能够处理整个文档或大部分内容才能给出准确的结果。例如,分析一份几万词元的法律合同。
- 提升生成质量: 更长的上下文有助于模型捕捉更广泛的语境信息,从而生成更相关、更一致、更有深度的文本。例如,在写故事或报告时,模型可以回顾数千词元前提到的细节。
- 减少信息丢失: 在处理长序列时,如果上下文长度不足,模型可能会丢失早期的重要信息,导致理解偏差或生成内容不连贯。
- 支持更复杂的应用: 许多高级应用,如代码生成与理解(可能涉及数万行代码)、法律文件分析、科学研究等,都依赖于模型处理和理解大规模文本的能力。
因此,扩展上下文长度一直是LLM研究领域的核心目标之一,它直接关系到模型的性能上限和应用场景的广度。
上下文长度的局限性:为什么LLM会受限于上下文长度?
在与大语言模型交互时,许多用户都会遇到这样的困惑:当对话或文档输入过长时,模型会出现 “失忆” 现象,要么忽略早期信息,要么生成逻辑混乱的内容。这背后的核心原因并非技术缺陷,而是所有大语言模型都必须遵守的“上下文长度限制”。理解这一限制的产生逻辑,需要从模型架构、硬件条件、训练范式到商业需求逐层拆解。
首先,限制的根本落点在技术架构。当前主流大语言模型采用 Transformer 架构,其核心组件——自注意力机制——决定了计算量随长度呈平方级增长:输入序列每翻一倍,计算量就要翻四倍。当上下文从 1 000 tokens 扩张到 10 000 tokens 时,计算需求瞬间放大 100 倍;这种爆炸式膨胀让即便最先进的 GPU 集群也难以承受无限制的长度扩展。
然而,计算量只是第一道门槛,紧接着迎来的是内存瓶颈。Transformer 需要把每个 token 映射为高维向量并常驻显存。按常见的 16 位浮点精度估算,1 个 token 约占用 1 KB,若支持 10 万 token 的上下文,仅存储输入就要吃掉近 100 GB 显存。而当前顶级单卡显存普遍在 80–160 GB 之间,还得同时容纳模型参数与中间激活值,实际可分配给“历史对话”的空间被进一步压缩。
训练数据本身也提前给模型划好了“舒适区”。模型所见书籍、网页等自然文本,段落长度大多在数千 token 以内。超出这一范围的长距离依赖在训练集中极为稀疏,导致模型对超长上下文的理解缺乏统计支撑。一旦强行突破训练边界,就会触发“分布偏移”:早期 token 的语义信号被稀释,后期生成内容随之漂移,准确性和连贯性同步下降。
即便技术上能够强行拉高上下文长度,商业和体验层面也会迅速给出反作用力。更长的上下文意味着更高的延迟与成本——在按 token 计费的商业模式里,用户每多输入 1 000 tokens,就要为算力和显存多付一次钱;同时,分钟级的响应时间也直接削弱了对话产品的即时性。于是,技术、成本与体验三者之间形成了一张看不见的“张力网”,把上下文长度牢牢约束在平衡点之内。
LLM在上下文长度方面受到限制,主要源于以下几个核心技术挑战:
- 计算复杂度 (Computational Complexity):
Transformer的自注意力机制 (Self-Attention): 标准的Transformer模型采用自注意力机制,其计算复杂度与上下文长度 N 的平方成正比,即 O(N2⋅d),其中 d 是模型的隐藏层维度。当上下文长度 N 从例如1024词元增加到4096词元(4倍)时,计算量会增加约16倍。这使得在非常长的序列上训练和推理变得非常昂贵和缓慢。
- 内存消耗 (Memory Consumption):
注意力矩阵: 自注意力机制需要计算并存储一个 N×N 的注意力得分矩阵。这个矩阵的内存消耗同样是 O(N2)。对于一个有32768 (32K) 个词元的上下文,注意力矩阵就需要存储 327682≈109 个值,对内存是巨大的挑战。(大模型在持续推理的过程中,需要缓存一个叫做 KV Cache 的数据快,KV Cache 的大小也与序列长度成正比。以 Llama 2 13B 大模型为例,一个 4K 长的序列大约需要 3G 的显存去缓存 KV Cache,16K 的序列则需要 12G,128K 的序列则需要 100G 显存。)

- 训练数据的限制 (Limitations of Training Data):
长序列数据的稀缺性: 高质量、多样化的长序列训练数据(例如包含数十万词元的文档)相对短文本数据更为稀缺。模型需要接触足够多的长文本样本才能学会处理长程依赖和利用长上下文。
训练成本与效率: 使用长序列进行训练本身就非常耗时耗资源,这限制了研究者和开发者在超长上下文模型上的迭代速度。
这些因素共同构成了LLM上下文长度的主要瓶颈。为了突破这些限制,研究者们在注意力机制、模型架构、位置编码和训练策略等多个方面进行了大量的探索和创新。
- 资源限制:更高的数值可能需要更多的计算资源和更长的处理时间。需要平衡性能和资源的可用性。
- 模型性能:某些模型在处理长文本时可能表现更好,而其他模型可能在较短的文本上效果更佳。
- 输出质量:较高的max tokens值可能导致更详细的输出,但也可能增加语句偏离主题的风险。同时,较长的context length有助于模型理解更多的上下文信息,但如果上下文中包含无关信息,可能会降低输出的相关性。
Temperature 温度:控制创造性和确定性之间的平衡
温度是控制 AI模型生成输出随机性的参数。它决定了模型在生成输出时更倾向于创造性还是保守和确定性。
温度值越高,模型越倾向于生成随机的、意想不到的输出,但也可能导致语法错误或无意义的文本。温度值越低,模型越倾向于生成符合逻辑和常识的输出,但也可能缺乏创造性和趣味性。
例如,在设置较低温度时,语言模型可能会生成以下句子:“今天天气晴朗,适合户外活动。”而设置较高温度时,模型可能会生成以下句子:“天空像一块巨大的蓝宝石,点缀着棉花糖般的白云。鸟儿在枝头歌唱,微风拂过脸庞,一切都是那么美好。”
像豆包这种AI, 每次聊天都会把历史对话信息,发给大模型吗?
是的,像豆包这样的对话式 AI,在与你持续聊天的过程中,每次生成回复时,通常会将历史对话信息(包括你的提问和之前的回复)作为上下文一起发送给背后的大语言模型(LLM)。
这是因为大语言模型本身是 “无状态” 的,它不会主动存储之前的对话内容,每次调用都是独立的。为了让回复符合对话的连贯性和语境,系统需要在每次请求时,把历史对话打包成上下文,和你当前的提问一起传递给模型,这样模型才能 “理解” 之前聊过什么,从而生成贴合语境的回应。
不过,传递的历史对话总量会受到模型上下文窗口大小的限制。如果对话过长,超出窗口范围,系统可能会通过一定的策略(比如保留近期关键内容、压缩早期信息等)来确保核心上下文被保留,以维持对话的有效性。
杂乱主题可能导致的问题:“噪音干扰”
如果历史对话中无关信息过多(尤其是与当前问题语义相似但不相关的内容),可能会产生 “噪音干扰”,表现为:
- 回复偏离重点:例如,历史中聊过 “如何养猫” 和 “如何修车”,当前问 “养宠物需要注意什么”,模型可能错误关联到 “修车” 中的 “定期检查”,导致回复混入无关建议。
- 对早期关键信息的 “遗忘”:当杂乱信息挤占了上下文窗口,模型可能对更早的、真正相关的内容关注度下降(比如前 50 轮聊过 “科幻电影推荐”,中间插入 100 轮无关话题后,模型可能难以准确回忆早期推荐)。
多智能体对于长记忆能力的优势
多智能体系统之所以不需要像单智能体那样依赖超长上下文窗口(如 100K、200K)的长记忆能力,核心原因在于其通过 “分布式协作” 替代了 “单一体记忆”,将复杂任务的记忆压力拆解、分散到多个智能体中,同时借助交互机制实现信息的动态流转与整合。具体可从以下几个关键机制理解:
任务拆解:将 “长记忆需求” 转化为 “分工协作需求”
单智能体面对复杂任务时,需要记住所有细节(如任务目标、中间步骤、历史反馈等),因为所有决策和执行都由它独立完成,超长上下文本质是为了 “容纳” 这些庞杂信息。
而多智能体系统会先将复杂任务拆解为子任务,每个智能体专注于一个或几个子任务,仅需记忆与自身职责相关的信息:
- 例如,完成 “策划一场跨国会议” 的任务:
- 子任务 1(智能体 A):负责确定会议主题、议程,只需记忆用户需求、行业热点等信息;
- 子任务 2(智能体 B):负责预订场地、设备,只需记忆时间、地点、供应商信息等;
- 子任务 3(智能体 C):负责邀请嘉宾、发送通知,只需记忆嘉宾名单、联系方式等。
- 每个智能体的 “记忆负载” 被大幅降低,无需记住其他子任务的细节,自然不需要超长上下文窗口。
信息交互:用 “动态沟通” 替代 “静态记忆”
单智能体必须通过 “记忆” 留存所有历史信息,否则会丢失上下文(例如,前 100 轮提到的细节,第 200 轮可能因窗口限制被遗忘)。
多智能体则通过实时交互共享信息,无需某一个体记住所有内容:
- 当智能体 A 需要智能体 B 的子任务结果(如 A 确定议程后,需要 B 的场地时间来匹配),两者可直接 “沟通”(如 A 向 B 发送 “请提供可用场地的时间范围”),B 返回结果即可,A 无需记住 B 的所有操作过程。
- 这种 “按需索取” 的信息传递模式,替代了 “全量记忆” 的需求 —— 信息分散在各个智能体中,通过交互临时调用,而非集中存储在某一个体的上下文里。
角色专业化:减少 “无关信息干扰”,降低记忆冗余
单智能体的超长上下文窗口中,往往混杂着与当前步骤无关的信息(如前序任务的细节、用户闲聊内容),需要消耗算力筛选有用信息。
多智能体的角色专业化天然隔离了无关信息:
- 每个智能体的 “关注范围” 被严格限定在其职责内(如 “财务智能体” 只处理预算相关信息,“法务智能体” 只处理合规相关信息),其他领域的信息即使存在,也无需进入其处理流程。
- 例如,财务智能体无需关心会议的具体议程(由内容智能体负责),只需接收 “总预算上限” 和 “场地 / 嘉宾费用清单” 即可,记忆内容高度聚焦,无需冗余存储。
外部存储依赖:用 “共享数据库” 替代 “个体记忆”
单智能体的记忆完全依赖自身上下文窗口,超出窗口的信息会丢失(除非额外接入外部工具,但本质仍是单一体在调用)。
多智能体系统可共享外部数据库 / 知识库,将需要长期留存的信息(如历史任务记录、用户偏好)存储在外部,而非个体的上下文:
- 当某智能体需要查询历史数据(如 “用户去年会议的场地偏好”),可直接从共享数据库中调取,无需记住所有过往细节。
- 外部存储相当于 “集体记忆库”,个体只需记住 “如何查询”,而非 “具体内容”,进一步降低了对超长上下文的依赖。
多智能体的 “分布式优势” vs 单智能体的 “集中式压力”
单智能体像一个 “全能选手”,必须一个人记住所有细节、处理所有步骤,因此需要超长上下文窗口来承载信息;多智能体则像一个 “团队”,通过分工拆解任务、交互共享信息、专业化隔离干扰、外部存储兜底,将 “个体记忆压力” 转化为 “系统协作效率”,自然无需依赖某一个体的超长记忆能力。
这种架构设计的核心优势在于:用 “协作的复杂度” 替代了 “个体的记忆复杂度”,在处理复杂任务时,更符合人类社会的分工逻辑,也更高效地利用了资源。
总结
参数、Token、上下文窗口、上下文长度和温度是AI 大模型中重要的概念,它们决定了模型的复杂度、性能和能力。通过理解这些概念,我们可以更好地了解AI 大模型的工作原理,并评估它们的潜力。
随着 AI技术的不断发展,AI 大模型的参数量、上下文窗口和上下文长度都在不断增长,温度控制也更加精细。这使得 AI大模型能够在更多领域展现出更强大的能力,为我们带来更大的价值。