为什么需要开发框架
有人会说,Agent不就是自动调用几个工具?我手写几个Python函数就完了嘛。
当然可以这么做,但一旦Agent涉及以下任意一个维度,代码复杂度就会爆炸:
- 多轮对话、上下文管理(用户多次交互)
- 多工具组合调用(外部API、数据库、搜索引擎等)
- 多Agent协作(类组织结构,角色协同)
这些问题不是“调大模型”能解决的,而是一个真正的“系统工程”问题,需要解决:
- 如何组织模块?
- 如何保持状态?
- 如何让多个Agent协同工作,而不是互相捣乱?
所以,Agent框架的出现,就是为了结构化解决这些问题。
你可以把它理解成——
给AI Agent开发提供一个像“Spring Boot那样的工程架构”,从组件化、流程控制、状态管理,到接口定义、部署调试,一整套“编程范式”。
引言

AutoGen是一个由微软推出的框架,旨在简化和自动化大型语言模型(LLM)的工作流程编排、优化和自动化。它通过创建多个智能体(agents),这些智能体可以相互协作,以完成复杂的任务。开发人员可以使用自然语言和计算机代码为不同的应用程序编写灵活的对话模式,从而实现多代理之间的聊天和协作。
AutoGen的核心优势在于其多代理对话能力,能够让不同的代理互相沟通,以解决复杂的任务。这种框架不仅简化了复杂的大数据模型工作流程的编排和自动化,还支持多种对话和任务的执行。此外,AutoGen还提供了自动座席聊天集成大型语言模型(LLM)、工具和人类见解的功能,进一步提高了其性能。
AutoGen是一个强大的多代理对话框架,适用于构建基于大型语言模型的应用程序,并且在大数据模型工作流程中表现出色。
在人工智能技术日新月异的当下,多智能体协作与大型语言模型(LLM)的应用日益广泛。微软推出的 AutoGen 框架,犹如一颗璀璨的新星,为开发者们提供了一个强大的工具,以实现高效的多智能体对话和复杂任务的自动化处理。AutoGen 框架致力于简化多智能体系统的开发过程,使开发者能够轻松构建出智能体之间能够相互协作、交流并共同解决问题的应用程序。无论是在学术研究领域,推动人工智能理论的进一步发展,还是在实际的工业生产中,提高软件开发、数据分析等工作的效率,AutoGen 都展现出了巨大的潜力和应用价值。它的出现,无疑为 AI 领域的发展注入了新的活力,也为广大开发者带来了更多的创新机遇。接下来,就让我们深入了解一下 AutoGen 框架及其基础环境的安装方法。
AutoGen 是一个开源编程框架,用于构建 AI 代理并促进多个代理之间的合作以解决问题。AutoGen 旨在提供一个易于使用和灵活的框架,以加速代理型 AI 的开发和研究,就像 PyTorch 之于深度学习。它提供了诸如代理之间可以对话、LLM 和工具使用支持、自主和人机协作工作流以及多代理对话模式等功能。
项目地址:https://github.com/microsoft/autogen
官方文档:https://microsoft.github.io/autogen/stable
Autogen是什么?
AutoGen是微软公司开源的多智能体(Mutiple Agents)应用开发框架,多智能体应用让不同的Agent之间相互交流沟通来解决问题。
更大白话一些,在公司里,老板如果有一个事情要办,通常会让秘书组织一个会议,把相关的人拉到会议室里,然后告诉他们自己的目标,比如要半年实现一百倍的增长,下面的人就会相互扯皮讨论,但是最终还是琢磨出一个不靠谱的方法把事儿给办了。
你可能不是老板,但是可以通过AutoGen创建几个Agent,一起玩Cosplay。你扮演老板,给Agent分配不同的角色,比如项目经理,程序员,或者主管等。把你的目标告诉它们,让他们任意去想办法,你只要在一旁听汇报,如果觉得有意见或者它们做得不对的地方,就让它们改,直到满意为止。
如果要提供一个开发框架,让开发人员能够在这个框架的基础上开发出不同的应用,那么这个框架要实现哪些能力呢?把”大象放进冰箱”分三步:
- 能够创建一个Agent,就是单独创建不同的Agent,让他们担任不同的角色,分配必要的工具,负责具体的任务;
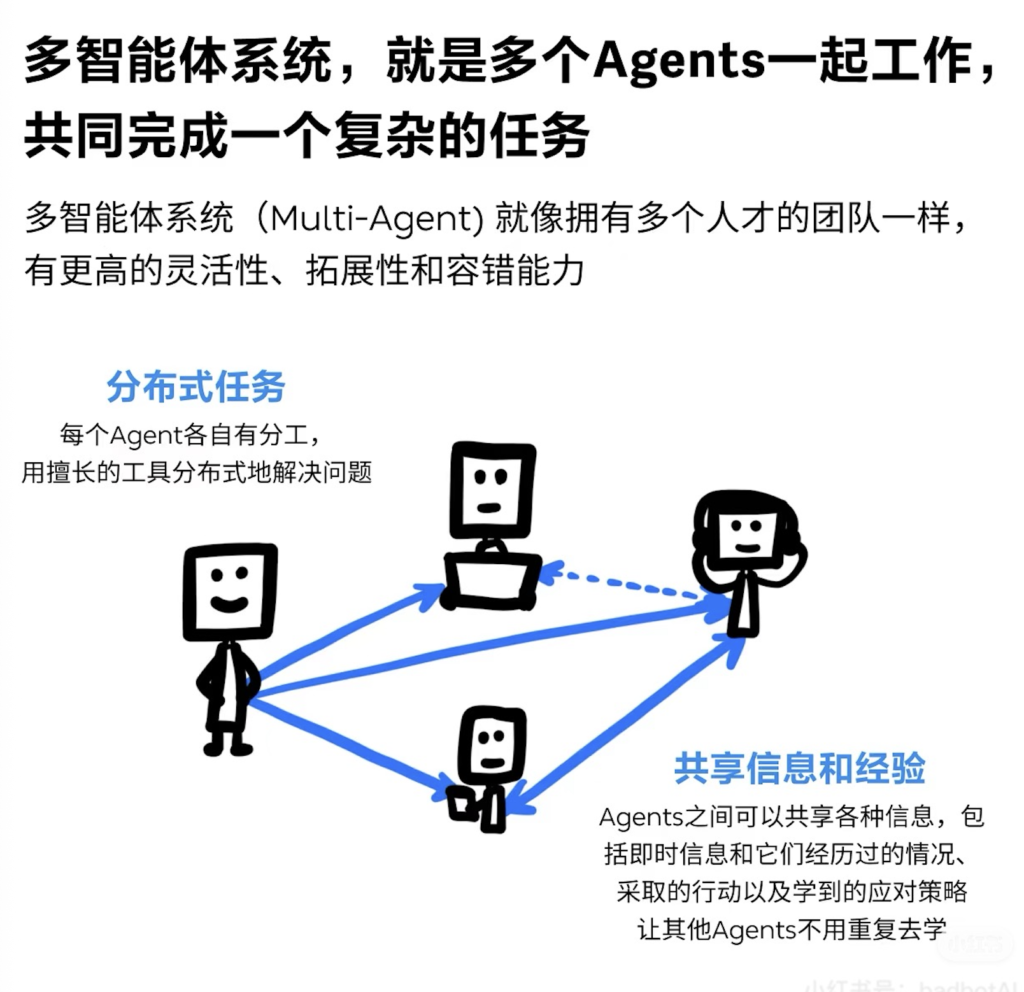
- 提供多个Agent对话的环境,将多个Agent放到一个”小黑屋”里,让他们之间能够相互对话,把对话记录下来;
- 对对话进行管理,比如发言顺序,什么时候会议结束,对话过程是不是跑偏。
基本上AutoGen就是预先把这些功能都实现了,开发人员要做的只是明确任务,创建Agent,把Agent拉到聊天室里,让他们开聊。
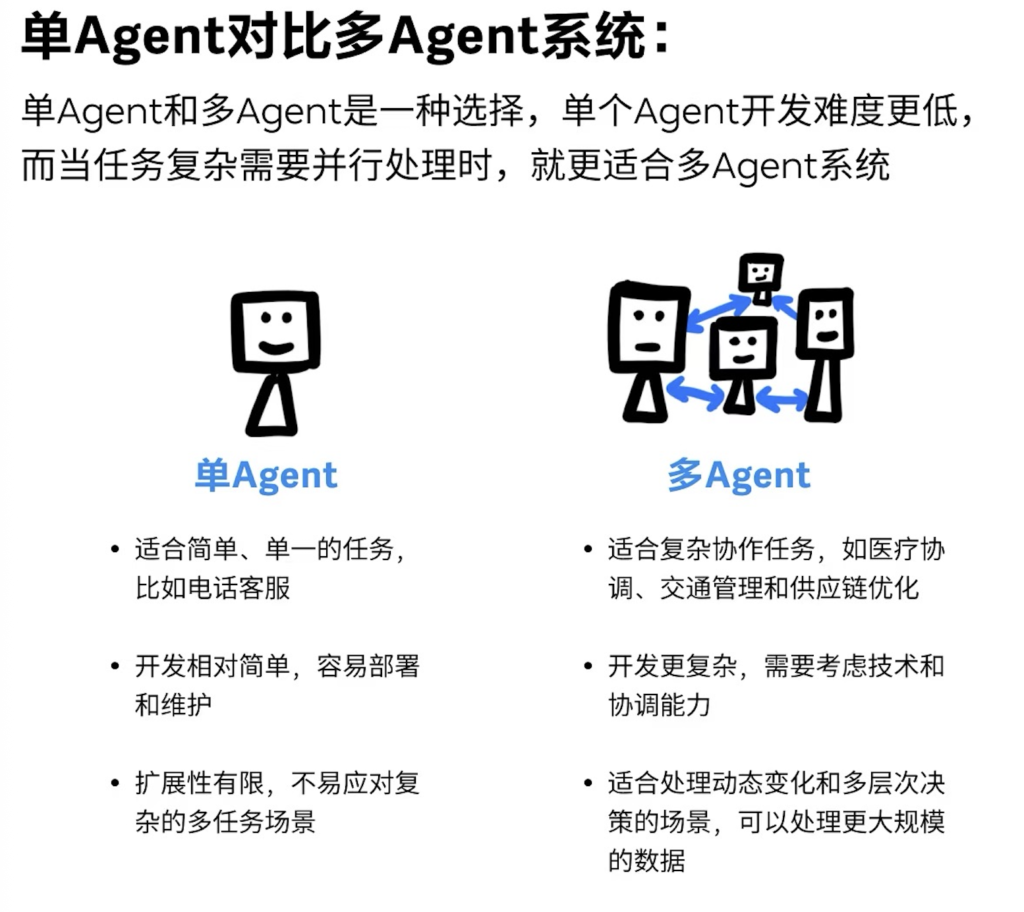
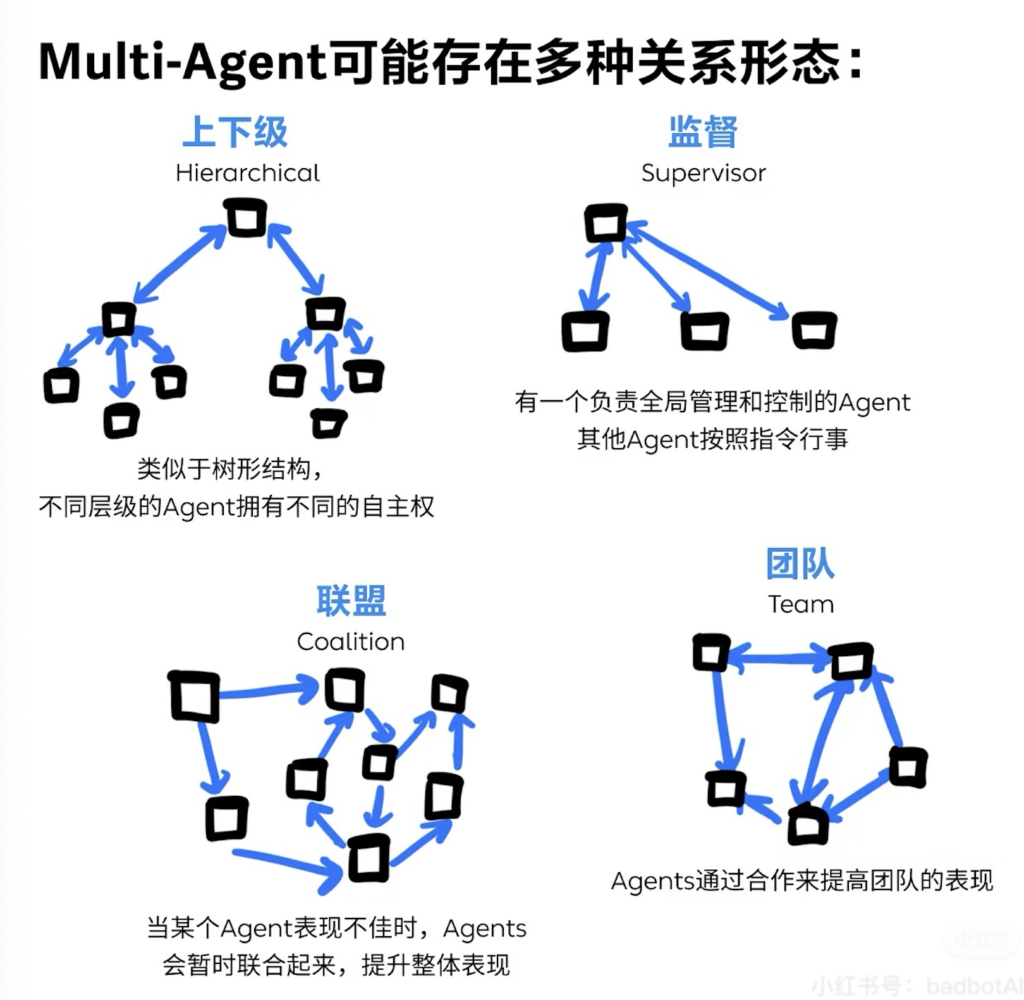
为什么需要Multi-Agent框架
现在一大堆开发框架都已经实现了Agent的能力,比如AutoGPT, Langchain Agent等,为什么会需要一个Multi-Agent框架?实际上Multi-Agent框架还不止AutoGen一家,BabyAGI、CAMEL、MetaGPT、ChatDev等等都是。业界这么热心投入Multi-Agent研究肯定是有一些道理的。
简单的说,人们的直觉是模仿人类分工协同的模式,能够更有效的解决问题。更底层的逻辑是为了突破单Agent的一些限制。例如上下文窗口大小。
Long Context是很多LLM追求的特性之一,单一的Agent也会受到Context 的限制,因为Agent一般都通过XoT (CoT、ToT、GoT) + React等方法来规划和思考,上下文会不断的加长,迟早会突破窗口限制。因此拆分Agent的功能避免超过上下文窗口限制是一个很有效的方法。
而且,Prompt是Agent工作的中很关键的因素,单一的Agent如果维护的大量的上下文,难免”脑子”会乱。如果只执行特定的任务,掌握特定技能,当然理论上表现会更好。
具体到开发应用的过程里,也需要不同的开发团队分工协同,那么势必要对应用功能进行拆分,每个开发团队负责一个Agent的模式也更有效。
AutoGen能做什么
AutoGen的论文里举了6种场景。
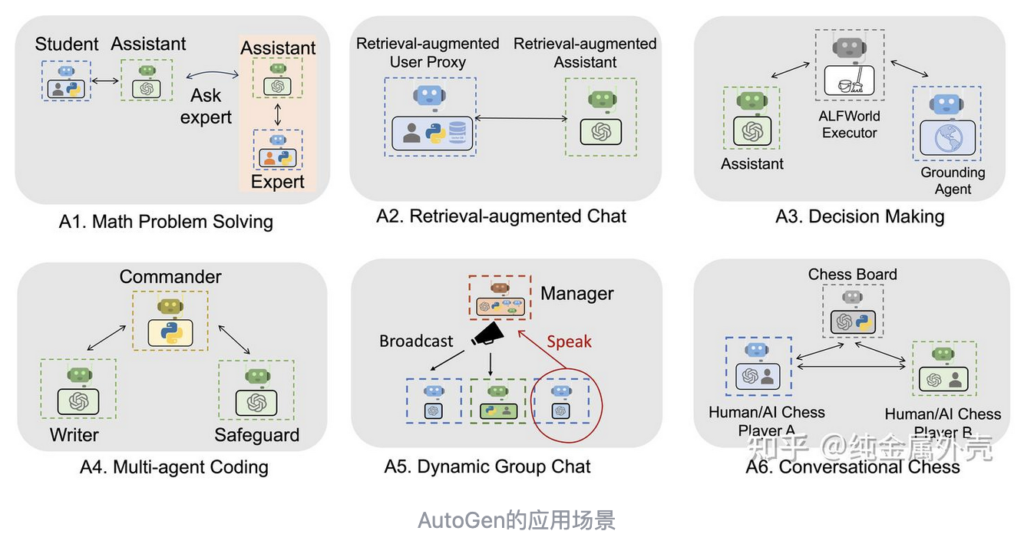
分别是解决数学问题,检索增强(RAG),决策制定,多Agent编程,动态群聊,下国际象棋。具体可以参见官网描述,这里不详细说明。
定义与概念阐述
AutoGen 是微软推出的一个开源的多代理对话框架,其核心目的是助力开发者创建基于大型语言模型(LLM)的智能应用 。在这个框架中,代理(Agent)是具有特定功能和角色的实体,它们能够通过自然语言进行交流和协作,共同完成复杂的任务。简单来说,就像是组建了一个虚拟的团队,团队中的每个成员(代理)都有自己的专长,通过相互沟通和配合,实现诸如问题解答、任务执行、项目管理等各类目标。比如在一个内容创作项目中,有的代理负责收集资料,有的代理负责撰写文案,还有的代理负责审核和修改,它们通过对话协作,最终产出高质量的内容。
核心特性剖析
多代理对话
AutoGen 允许开发者创建多个自主代理,这些代理可以在一个对话环境中相互交流、协作,以完成复杂的任务。每个代理都有其独特的角色和功能,它们通过发送和接收消息来进行互动。例如,在一个数据分析项目中,可以创建一个数据收集代理,负责从各种数据源获取数据;一个数据分析代理,对收集到的数据进行分析和建模;以及一个报告生成代理,根据分析结果生成详细的报告。这三个代理通过多轮对话,逐步推进项目,从数据获取到分析再到报告生成,最终完成整个数据分析任务。这种多代理对话机制,极大地提高了任务处理的效率和灵活性,能够应对各种复杂的业务场景。
简化工作流
该框架简化了 LLM 工作流的编排、自动化和优化过程。以往,开发者在使用 LLM 构建应用时,需要手动处理大量繁琐的流程,如模型调用、参数设置、对话管理等。而 AutoGen 通过提供一系列的工具和接口,将这些复杂的操作进行了封装和自动化处理。开发者只需关注业务逻辑和任务需求,通过简单的配置和代码编写,就可以实现高效的 LLM 应用开发。例如,在一个智能客服系统中,开发者可以利用 AutoGen 快速搭建起对话流程,使客服代理能够自动识别用户问题,并调用合适的模型进行回答,无需手动编写复杂的对话管理逻辑。这不仅减少了开发时间和工作量,还提高了应用的稳定性和可维护性。
模块化设计
AutoGen 采用模块化的架构设计,使得开发者可以轻松地创建自定义代理,并根据具体需求进行灵活组合。每个模块都具有独立的功能,如代理模块负责与其他代理进行对话和交互,模型模块负责提供语言模型支持,工具模块负责调用外部工具等。这种模块化设计使得框架具有很高的可扩展性和可定制性。开发者可以根据自己的业务需求,选择合适的模块进行组合,或者开发新的模块来满足特定的功能要求。例如,在一个电商智能推荐系统中,开发者可以基于 AutoGen 的模块化设计,创建一个商品推荐代理,该代理可以结合用户行为数据、商品信息等,利用语言模型进行分析和推理,最终为用户提供个性化的商品推荐。同时,开发者还可以根据实际情况,对代理的功能进行扩展和优化,如增加实时数据更新功能、优化推荐算法等。
与其他框架对比优势
与其他类似框架如 LangGraph、CrewAI 相比,AutoGen 具有显著的优势。在灵活性方面,AutoGen 的多代理对话模式和模块化设计使其能够适应各种复杂的任务和场景,开发者可以根据实际需求自由组合和定制代理 。而 LangGraph 虽然在构建有状态的多代理应用方面有一定优势,但在代理的灵活性和自定义程度上相对较弱。CrewAI 则更侧重于模拟真实团队协作,在任务处理的灵活性上不如 AutoGen。在社区支持方面,微软强大的技术实力和广泛的用户基础为 AutoGen 提供了丰富的社区资源,开发者可以在社区中获取到大量的文档、教程、代码示例以及技术支持,这对于开发者快速上手和解决问题非常有帮助 。相比之下,LangGraph 和 CrewAI 的社区规模相对较小,资源相对有限,开发者在遇到问题时可能较难快速找到解决方案。此外,AutoGen 在与 LLM 的集成方面也表现出色,能够更好地发挥 LLM 的强大功能,为开发者提供更高效、更智能的开发体验。
AutoGen 框架基础环境安装
准备工作
在开始安装 AutoGen 框架之前,需要确保你的系统满足以下基本要求:操作系统方面,建议使用 Windows 10 及以上版本、Linux(如 Ubuntu 18.04 及以上)或 macOS 10.15 及以上版本 。这些操作系统能够为后续的软件安装和运行提供稳定的环境支持。硬件方面,确保计算机具备至少 8GB 的内存,以保证在安装过程中以及后续使用 AutoGen 框架时,系统能够流畅运行。如果你的计算机内存较小,可能会导致安装过程缓慢甚至失败,在运行相关应用时也可能出现卡顿现象。此外,还需要有一定的磁盘空间,至少预留 10GB 以上的可用空间,用于存储 Python、AutoGen 及其依赖库等相关文件。网络连接也至关重要,需保证网络稳定且速度较快,因为在安装过程中需要从互联网下载大量的软件包和依赖项。若网络不稳定或速度过慢,可能会导致下载中断或安装时间过长。
Python 环境搭建
安装 Python
AutoGen 框架需要 Python 3.10 及以上版本的支持。首先,访问 Python 官方网站(Download Python | Python.org),在下载页面中,根据你的操作系统选择对应的 Python 安装包。例如,若使用 Windows 系统,点击下载 Windows x86-64 executable installer(64 位系统)或 Windows x86 executable installer(32 位系统)。下载完成后,双击安装包进行安装。在安装向导中,务必勾选 “Add Python to PATH” 选项,这样可以将 Python 添加到系统的环境变量中,方便后续在命令行中直接调用 Python 命令。接着,选择 “Customize installation”(自定义安装),在接下来的安装选项中,可以根据个人需求选择安装的组件,一般保持默认设置即可,然后点击 “Next”。在安装路径选择界面,你可以选择默认路径,也可以根据自己的喜好更改安装路径,完成设置后点击 “Install” 开始安装。安装完成后,打开命令行工具(Windows 系统为 CMD 或 PowerShell,Linux 和 macOS 系统为终端),输入 “python –version”,若显示出安装的 Python 版本号,如 “Python 3.10.x”,则说明 Python 安装成功 。
安装虚拟环境
为了避免不同项目之间的依赖冲突,建议使用虚拟环境来安装 AutoGen 及其相关依赖。Python 自带的 venv 模块或 conda 工具都可以用来创建虚拟环境。
如果选择使用 venv 模块,打开命令行工具,进入你希望创建虚拟环境的目录,例如 “cd C:\Projects”。然后执行命令 “python -m venv myenv”,其中 “myenv” 是你为虚拟环境指定的名称,可根据实际情况进行修改。这将在当前目录下创建一个名为 “myenv” 的虚拟环境。创建完成后,在 Windows 系统中,进入虚拟环境的 Scripts 目录,执行 “myenv\Scripts\activate.bat” 来激活虚拟环境;在 Linux 或 macOS 系统中,执行 “source myenv/bin/activate” 激活虚拟环境。激活后,命令行提示符会显示虚拟环境的名称,例如 “(myenv) C:\Projects”,表示已成功进入虚拟环境。
创建一个Python虚拟环境:
python -m venv myenv
激活虚拟环境:
myenv\Scripts\activate
若使用 conda 工具创建虚拟环境,首先需要确保你已经安装了 Anaconda 或 Miniconda。打开 Anaconda Prompt(Windows 系统)或终端(Linux 和 macOS 系统),执行命令 “conda create -n myenv python=3.10”,这里同样以 “myenv” 作为虚拟环境的名称,你可以按需修改。该命令会创建一个名为 “myenv” 且基于 Python 3.10 版本的虚拟环境。创建完成后,执行 “conda activate myenv” 激活虚拟环境。当不再使用虚拟环境时,可以在命令行中执行 “deactivate” 命令退出虚拟环境。
安装 AutoGen
我们直接使用pip 安装即可
pip install pyautogen
在激活的虚拟环境中,使用 pip 命令来安装 AutoGen。在命令行中输入 “pip install autogen”,pip 会自动从 Python Package Index(PyPI)下载并安装 AutoGen 及其默认的依赖项。在安装过程中,请确保网络连接稳定,以免下载中断导致安装失败。
安装过程中可能会遇到一些问题。例如,如果网络连接较慢,下载时间可能会较长,甚至出现超时错误。此时,可以尝试更换网络环境,或者使用国内的镜像源来加速下载。
安装相关依赖
除了 AutoGen 本身,根据具体的应用场景,可能还需要安装一些其他的依赖库。例如,如果要使用 OpenAI 的语言模型,需要安装 “openai” 库。在命令行中执行 “pip install openai” 即可完成安装 。若涉及到数据分析和处理任务,可能需要安装 “pandas”“numpy” 等库,分别执行 “pip install pandas” 和 “pip install numpy” 进行安装。如果要进行绘图展示,如绘制数据可视化图表,“matplotlib” 库是不错的选择,使用 “pip install matplotlib” 进行安装。安装这些依赖库的方法与安装 AutoGen 类似,都是通过 pip 命令在虚拟环境中进行安装。在安装过程中,同样要注意网络连接情况和可能出现的依赖项冲突问题,按照前面提到的方法进行相应处理,以确保所有依赖库都能成功安装,为后续使用 AutoGen 框架进行开发工作做好充分准备。
AutoGen的可视化界面AutoGen Studio
AutoGen也提供了一个可视化的界面,让你无需编码也可以进行构建多Agent系统。按照官方的说明就可以安装。
AutoGen 框架的应用场景
软件开发
在软件开发过程中,AutoGen 框架展现出了强大的助力作用。例如,在一个 Web 应用开发项目中,开发者可以利用 AutoGen 创建不同的代理 。创建一个需求分析代理,该代理负责与产品经理沟通,深入理解项目需求,并将需求转化为详细的功能规格说明。当产品经理提出 “开发一个具有用户注册、登录、商品浏览和购买功能的电商 Web 应用” 的需求时,需求分析代理能够与产品经理进行多轮对话,明确诸如用户注册需要填写哪些信息、登录的验证方式、商品浏览的展示形式以及购买流程中的支付方式等细节。接着,代码生成代理登场,它根据需求分析代理提供的功能规格说明,调用合适的语言模型,自动生成前端和后端的代码框架。对于前端部分,可能会生成包含 HTML、CSS 和 JavaScript 的代码,构建出用户界面的基本结构和交互逻辑;对于后端,可能会生成基于 Python Flask 或 Django 框架的代码,搭建起服务器端的路由、数据库连接和业务逻辑处理模块。测试代理也不可或缺,它可以根据代码生成代理生成的代码,自动生成测试用例,并执行测试,检查代码是否存在漏洞和错误。在这个过程中,各个代理之间通过自然语言对话进行协作,大大提高了软件开发的效率和质量,减少了人工编写代码的工作量和出错的可能性。
数据分析
在数据分析领域,AutoGen 框架同样能发挥重要作用。以一个市场调研数据分析项目为例,数据收集代理可以从各种数据源,如数据库、网页、文件等,收集相关的数据。它能够与数据源进行交互,根据设定的规则和条件,筛选并提取出符合项目需求的数据。例如,从公司的销售数据库中提取过去一年的销售数据,包括产品名称、销售数量、销售金额、销售地区等字段。数据清洗代理负责对收集到的数据进行清洗和预处理,去除重复数据、处理缺失值和异常值。比如,当发现销售金额字段中存在一些明显不合理的负数时,数据清洗代理可以通过与其他代理或开发者的对话,确定这些数据是错误录入还是有特殊原因,然后采取相应的处理措施,如删除错误数据或进行合理修正。数据分析代理则利用各种数据分析工具和算法,对清洗后的数据进行深入分析。它可以根据数据特点和分析目标,选择合适的分析方法,如统计分析、相关性分析、聚类分析等。例如,通过相关性分析,找出销售数量与销售地区之间是否存在某种关联,为市场策略的制定提供依据。最后,报告生成代理根据数据分析代理的分析结果,生成详细的数据分析报告,以清晰易懂的方式呈现数据洞察和结论。
智能客服
AutoGen 框架在构建智能客服系统方面具有显著优势。在一个电商智能客服场景中,当用户向客服咨询问题时,如 “我购买的商品什么时候能发货?”,智能客服系统中的问题分类代理首先对用户的问题进行分类,判断该问题属于订单处理类问题。然后,知识检索代理根据问题分类结果,从知识库中检索相关的答案信息。知识库中存储了各种常见问题的解答、商品信息、物流信息等。如果知识库中存在直接匹配的答案,如 “一般情况下,商品会在下单后的 24 小时内发货”,则由回复生成代理将该答案以友好、恰当的语言形式回复给用户。若知识库中没有直接匹配的答案,智能客服系统可以通过与用户进一步对话,获取更多信息,如订单编号等,然后由查询代理向订单管理系统或物流系统发起查询,获取准确的发货时间信息,再由回复生成代理将结果反馈给用户。在这个过程中,AutoGen 框架使得各个代理能够协同工作,快速、准确地响应用户的咨询,提高客户服务的效率和质量,为用户提供更好的购物体验 。
AutoGen的基本原理
跟Langchain等框架比起来,AutoGen还是相对比较简单的框架。前面已经提过,AutoGen所做的就是如下几件事情:
- 能够创建一个Agent,AutoGen定义了一些Agent的类,用于定义和实例化特定的Agent。这些Agent具有基本的对话能力,能够根据接收到的消息,生成回复。最简单的,创建两个Agent,就能够让他们一对一的闲聊起来。
- 提供多个Agent对话的环境,通过GroupChat类来管理一个具有多个Agent参与的群聊环境,在这个GroupChat中来维护管理聊天记录、发言者选择/转换规则、谁是下一个发言者、什么时候群聊终止等;
- 对群聊进行管理,群聊的实际管理是由一个GroupChatManager来实现的,GroupChatManager也是一个Agent,GroupChat提供了一个环境,交给GroupChatManager来实际管理这个环境。
单个Agent
一个最简单的AutoGen helloworld 应用就是下面的样子:
from autogen import UserProxyAgent, ConversableAgent, config_list_from_json
def main():
# Load LLM inference endpoints from an env variable or a file
# 从文件或者环境变量中加载LLM的推理端点
# 具体参看https://microsoft.github.io/autogen/docs/FAQ#set-your-api-endpoints
# 以及 OAI_CONFIG_LIST_sample.
# 例如,如果你在当前工作目录下创建了一个 OAI_CONFIG_LIST 的文件,那么这个文件就会被用来作为配置文件
config_list = config_list_from_json(env_or_file="OAI_CONFIG_LIST")
#利用LLM来创建一个Assistant Agent,这个LLM是在上面的配置文件里指定的。
assistant = ConversableAgent("agent", llm_config={"config_list": config_list})
#创建一个用户代理,这个用户代理就代表你,你可以随时加入对话中
user_proxy = UserProxyAgent("user", code_execution_config=False)
#让assistant来开始这个对话,如果用户输入 exit,那么对话就会被终止。
assistant.initiate_chat(user_proxy, message="How can I help you today?")
if __name__ == "__main__":
main()
在上面的简单的程序里,定义了两个Agent,一个叫assistant,一个是user_proxy,然后让assistant初始化了一个对话,这个对话的对象是user_proxy,初始的消息是”How can I help you today?”。运行代码后,你会接收到这条消息,然后可以任意输入回复,直到你输入exit,对话结束。
所以单个Agent的行为模式很简单,就是收发消息而已,输入输出都是文本。和人一样,有人跟你说话,你可以回复,或者选择不回复。
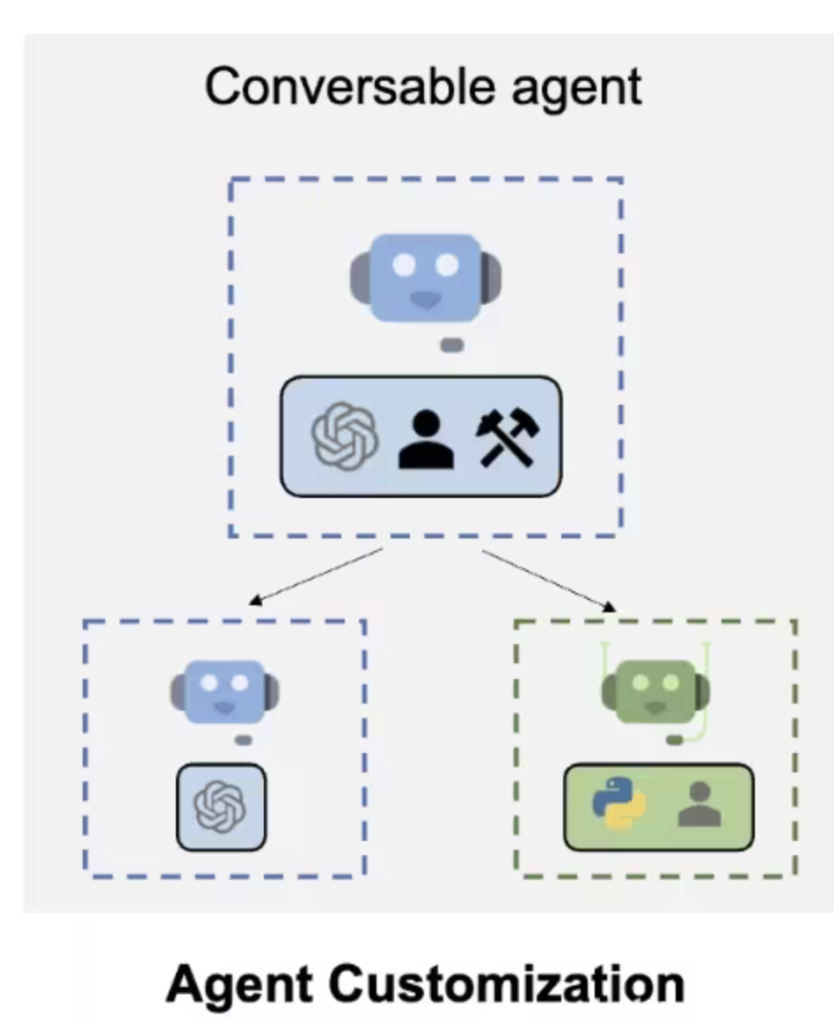
在上面的代码示例中,assistant这个Agent实例是一个ConversableAgent,而user_proxy是一个UserProxyAgent的实例。实际上在AutoGen中,Agent是如下图构造的:
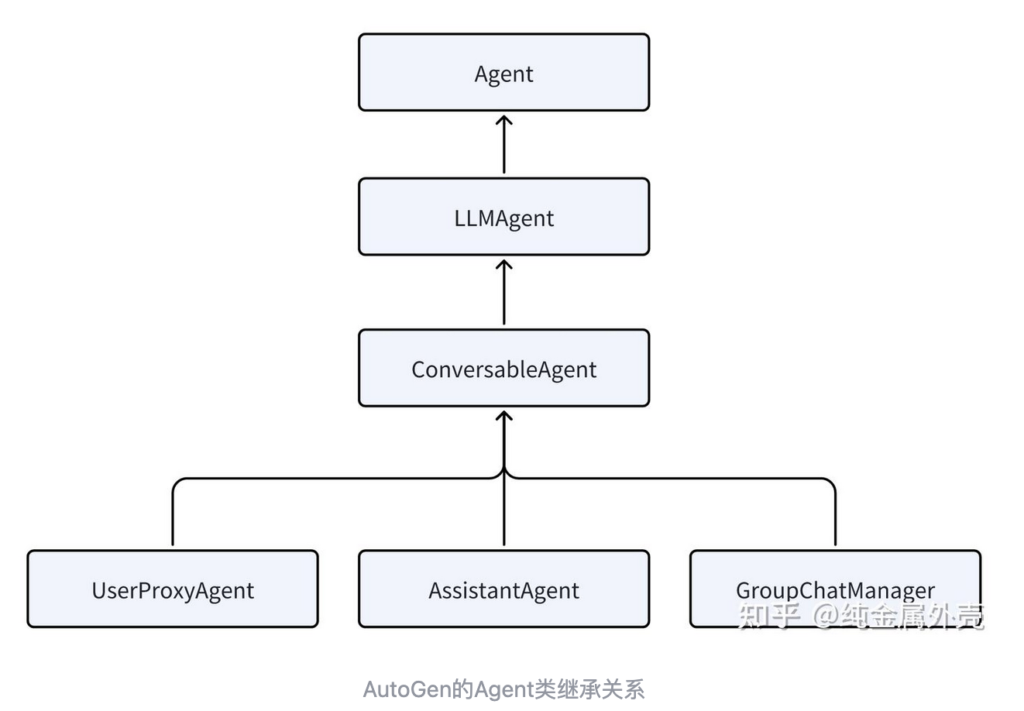
AutoGen先声明了一个Agent的protocol,规定了作为一个Agent基本属性和行为:
name属性:每个Agent必须有一个属性。description属性:每个Agent必须有个自我介绍,描述自己的能干啥和一些行为模式。send方法:发送消息给另一个Agent。receive方法:接收来自另一个代理的消息Agent。generate_reply方法:基于接收到的消息生成回复,也可以同步或异步执行。
只要具有这些能力,那么在AutoGen中就会被认为是一个Agent。
如果你定义了一个Agent,无论其他人说什么它都固定回复”好的”,也可以认为是一个Agent,并不需要有LLM。这也是为什么在Agent之后又定义了一个LLMAgent的封装,它在Agent的基础上增加给LLM用的system message。
然后在ConversableAgent中具体实现了Agent规定的各种方法。核心是receive,当ConversableAgent收到一个消息之后,它会调用generate_reply去生成回复,然后调用send把消息回复给指定的接收方。同时ConversableAgent还负责实现对话消息的记录,一般都记录在ChatResult里,还可以生成摘要等。
最后,AutoGen在ConversableAgent的基础上实现了AssistantAgent,UserProxyAgent和GroupChatAgent三个比较常用的Agent类,这三个类在ConversableAgent的基础上添加了特定的system_message和description。其实就是添加了一些基本的prompt而已。
你可能也留意到了,好像这些Agent没有工具,那么它是如何使用工具呢?其实具体的实现是在ConversableAgent中。你可以通过类似如下的方法来给Agent提供工具:
def my_tool_function(param1, param2):
# 实现工具的功能
return result
agent = ConversableAgent(...)
agent.register_function({"my_tool_function": my_tool_function})
那么决定Agent的行为模式就有几点关键:
- 提示词,system_message,就是这个Agent的基本提示词
- 能调用的工具,取决于给Agent提供了哪些工具,在AssistantAgent默认没有配置任何工具,但是提示它可以生成python代码,交给UserProxyAgent来执行获得返回,相当于变相的拥有了工具
- 回复逻辑,如果你希望在过程中掺入一点私货而不是完全交给LLM来决定,那么可以在
generate_reply的方法中加入一点其他逻辑来控制Agent返回回复的逻辑,例如在生成回复前去查询知识库,参考知识库的内容来生成回复。
两个Agent之间对话
你可以创建两个Agent,然后让它们进行对话。这是比较简单的一种方式。
如下图所示:
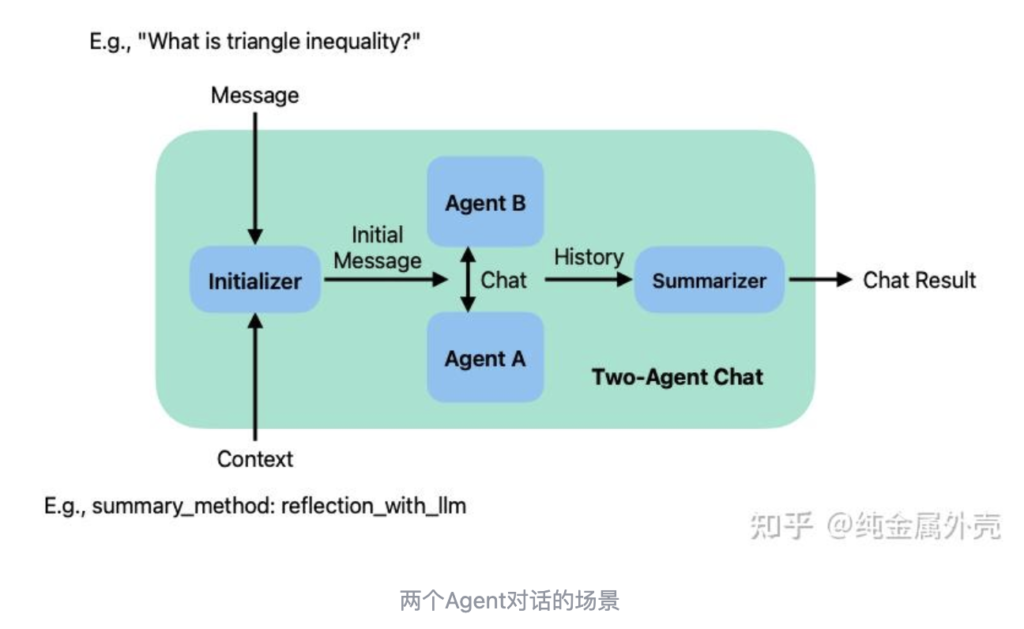
实际的代码是:
import os
from autogen import ConversableAgent
#构造student_agent实例
student_agent = ConversableAgent(
name="Student_Agent",
system_message="You are a student willing to learn.",
llm_config={"config_list": [{"model": "gpt-4", "api_key": os.environ["OPENAI_API_KEY"]}]},
)
#构造teacher_agent实例
teacher_agent = ConversableAgent(
name="Teacher_Agent",
system_message="You are a math teacher.",
llm_config={"config_list": [{"model": "gpt-4", "api_key": os.environ["OPENAI_API_KEY"]}]},
)
#初始化一个聊天,由student_agent发出,接收方式teacher_agent
chat_result = student_agent.initiate_chat(
teacher_agent,
message="What is triangle inequality?",
summary_method="reflection_with_llm",
max_turns=2,
)
由student_agent通过调用initiate_chat()的方法,问teacher_agent()什么是三角不等式,并且规定了最大对话轮次为两轮,最后的对话摘要是通过reflection_with_llm的方法生成。整个对话结果保存在chat_result中。
如果一个对话需要跟多个Agent一对一顺序交流完成,可以通过下面的方法将对话串在一起。上一次对话的摘要会被作为参数一起传递到下一个对话环节。
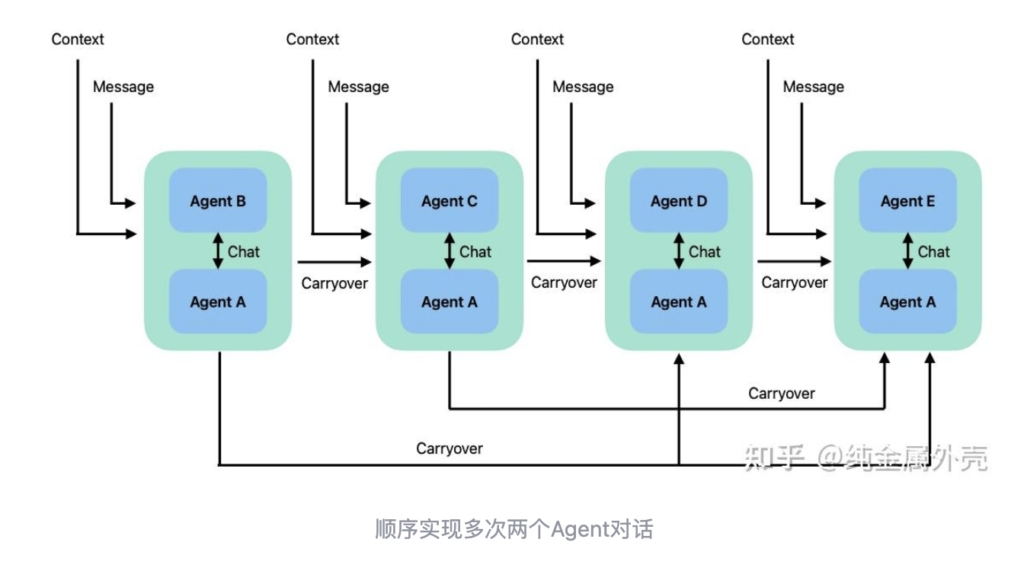
代码是:
# Start a sequence of two-agent chats.
# Each element in the list is a dictionary that specifies the arguments
# for the initiate_chat method.
chat_results = AgentA.initiate_chats(
[
{
"recipient": AgentB,
"message": "初始的message",
"max_turns": 2,
"summary_method": "last_msg",
},
{
"recipient": AgentC,
"message": "需要给AgentC的message",
"max_turns": 2,
"summary_method": "last_msg",
},
{
"recipient": AgentD,
"message": "需要给AgentD的message",
"max_turns": 2,
"summary_method": "last_msg",
},
{
"recipient": AgentE,
"message": "需要给AgentE的message",
"max_turns": 2,
"summary_method": "last_msg",
},
]
)
多个Agent的群聊
如果有超过两个Agent,那么就需要把它们加入一个聊天室(GroupChat)。然后考虑这个聊天室怎么管理和控制。例如谁应该在什么时候发言,哪些Agent之间才可以相互对话。
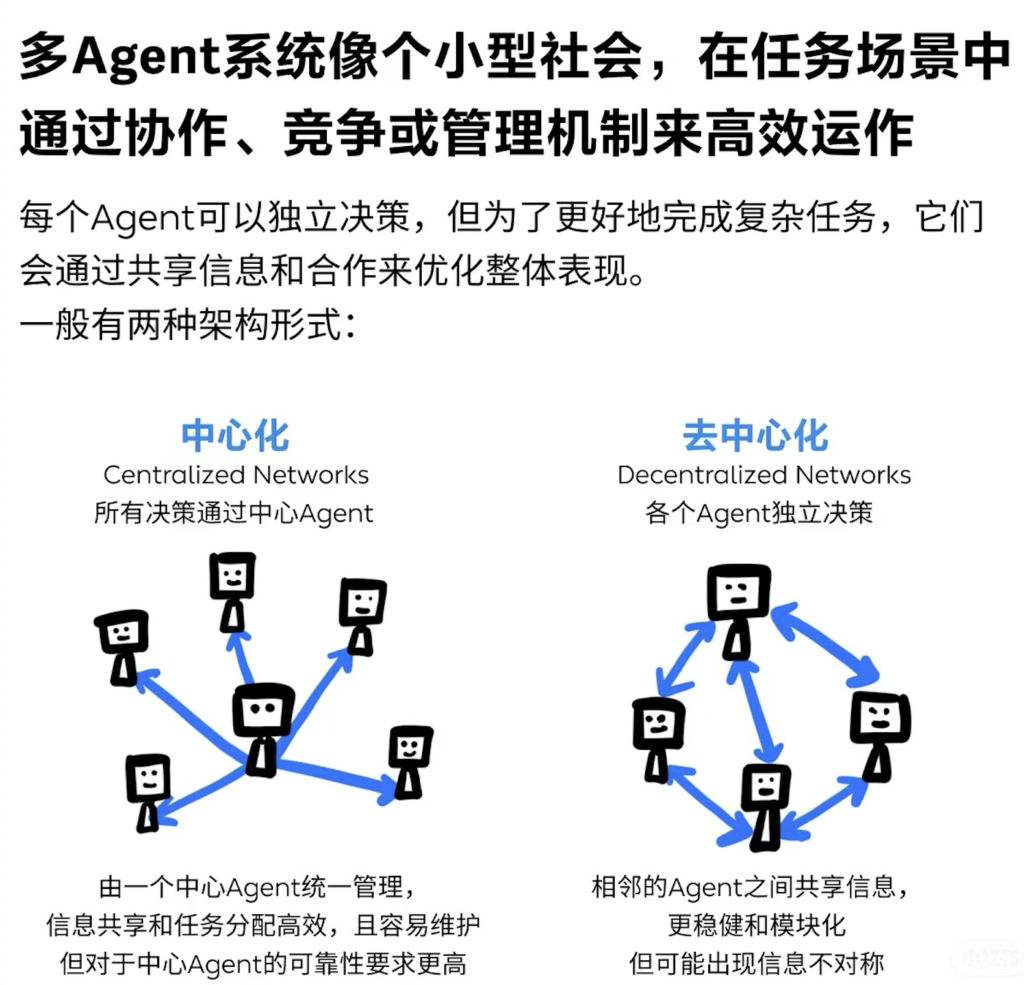
聊天室的管理是由GroupChatManager来进行的,GroupChatManager也是一个ConversableAgent的子类。它首选选择一个发言的Agent,然后发言Agent会返回它的响应,然后GroupChatManager会把收到的响应广播给聊天室内的其他Agent,然后再选择下一个发言者。直到对话终止的条件被满足。GroupChatManager选择下一个发言者的方法有:
- 自动选择: “auto”下一个发言者由LLM来自动选择;
- 手动选择:”manual”由用户输入来决定下一个发言者;
- 随机选择:”random”随机选择下一个发言者;
- 顺序发言:”round_robin” :根据Agent顺序轮流发言
- 自定义的函数:通过调用函数来决定下一个发言者;
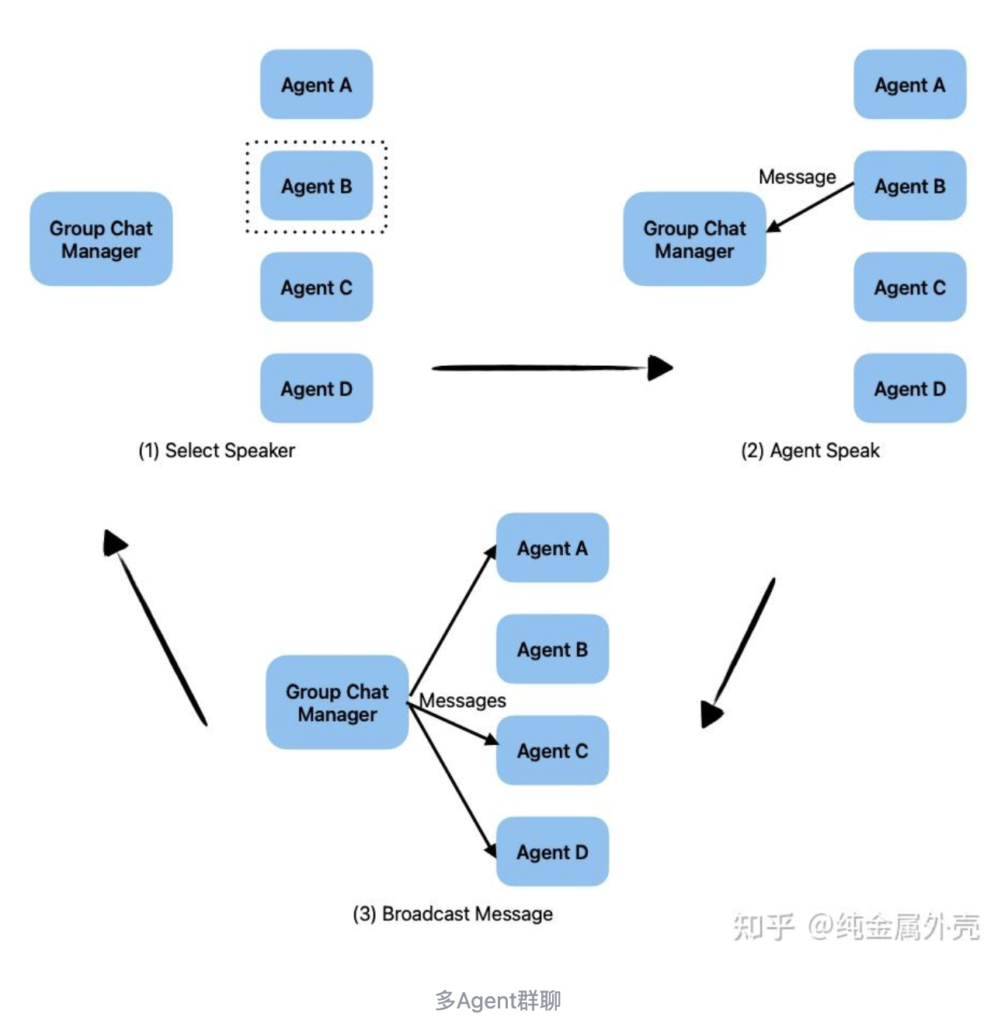
如果聊天室里Agent比较多,还可以通过设置GroupChat类中设置allowed_or_disallowed_speaker_transitions参数来规定当特定的Agent发言时,下一个候选的Agent都有哪些。例如可以规定AgentB发言时,只有AgentC才可以响应。
通过这些发言控制的方法,可以将Agent组成各种不同的拓扑。例如层级化、扁平化。甚至可以通过传入一个图形状来控制发言的顺序。
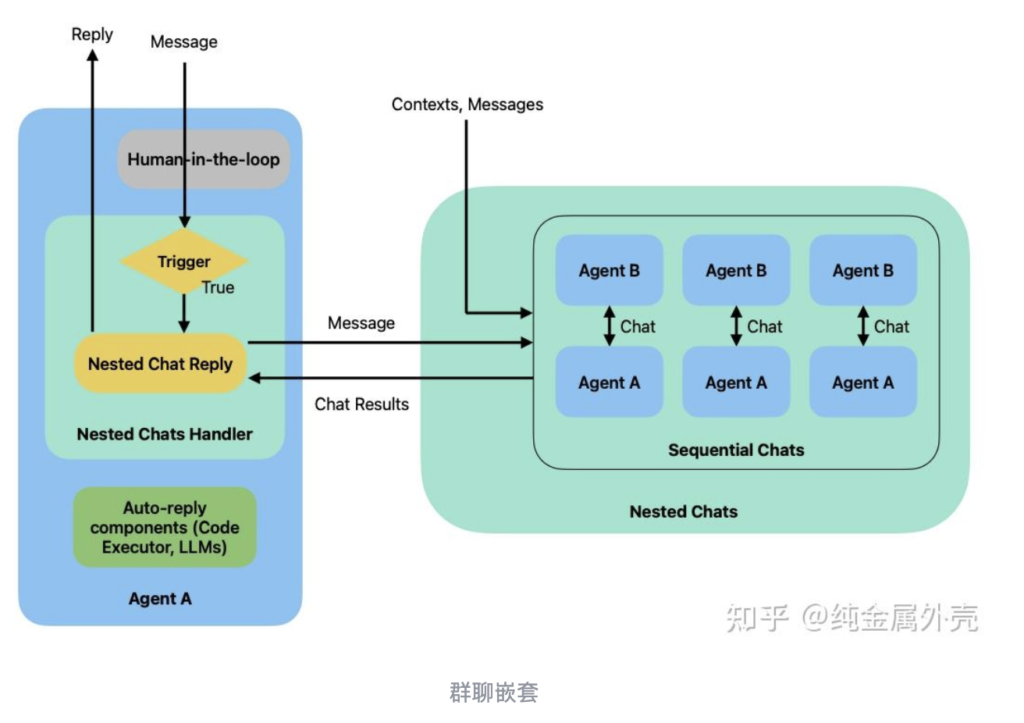
群聊嵌套
AutoGen允许在一个群聊中,调用另外一个Agent群聊来执行对话(嵌套对话Nested Chats)。这样做可以把一个群聊封装成单一的Agent,从而实现更加复杂的工作流。
具体实现方法是先利用上面的方法定义一个群聊,然后将这个群聊在另外一个群聊中,注册成为nested chat,并且设定一个trigger的表达式,当trigger表达式为”真”时,就会调用nested chat包装好的群聊来解决问题,将结果返回。
入门的例子
创建一个AI团队,一个当任务执行者,一个当评判者,当评判者觉得可以了,就停止对话,完成任务。
Python代码如下:
import asyncio
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.base import TaskResult
from autogen_agentchat.conditions import ExternalTermination, TextMentionTermination
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_agentchat.ui import Console
from autogen_core import CancellationToken
from autogen_ext.models.openai import OpenAIChatCompletionClient
async def main():
# Create an OpenAI model client.
model_client = OpenAIChatCompletionClient(
model="gpt-4o-2024-08-06",
api_key="", # Optional if you have an OPENAI_API_KEY env variable set.
)
# Create the primary agent.
primary_agent = AssistantAgent(
"primary",
model_client=model_client,
system_message="You are a helpful AI assistant.",
)
# Create the critic agent.
critic_agent = AssistantAgent(
"critic",
model_client=model_client,
system_message="Provide constructive feedback. Respond with 'APPROVE' to when your feedbacks are addressed.",
)
# Define a termination condition that stops the task if the critic approves.
text_termination = TextMentionTermination("APPROVE")
team = RoundRobinGroupChat(
[primary_agent, critic_agent],
termination_condition=text_termination, # Use the bitwise OR operator to combine conditions.
)
await Console(team.run_stream(task="写一首关于秋天的短诗"))
if __name__ == "__main__":
asyncio.run(main())
运行效果:
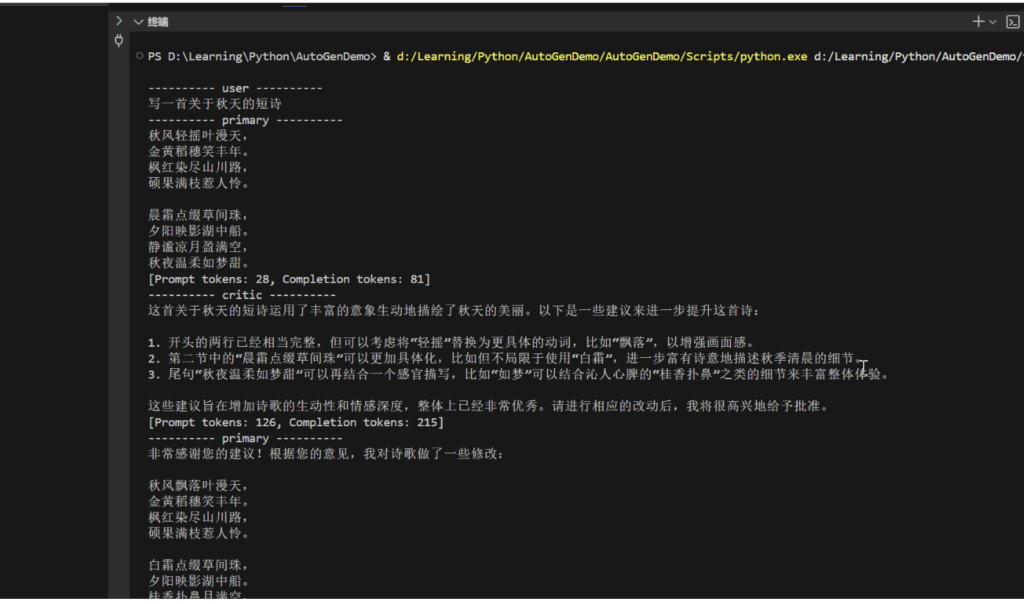
代码案例一:简单的多代理对话
功能描述
本案例创建两个代理,一个是用户代理,另一个是助手代理,模拟用户与助手之间的简单对话交互,用户提出问题,助手给出回答。
代码实现
import autogen
# 创建用户代理
user_proxy = autogen.UserProxyAgent(
name="User_proxy",
system_message="A human admin. Interact with the planner to discuss the plan. Plan execution needs to be approved by this admin."
)
# 创建助手代理
assistant = autogen.AssistantAgent(
name="Assistant",
llm_config={
"model": "gpt-3.5-turbo",
"api_key": "your_openai_api_key"
}
)
# 用户提出问题
user_proxy.initiate_chat(assistant, message="帮我总结一下Python语言的特点")
代码解释
- 导入 autogen 库:为使用 AutoGen 框架的功能做准备。
- 创建用户代理:
UserProxyAgent类用于创建用户代理,通过system_message描述用户代理的角色和职责。 - 创建助手代理:
AssistantAgent类创建助手代理,llm_config配置使用的语言模型(这里是gpt-3.5-turbo)以及对应的 API 密钥。 - 发起对话:用户代理通过
initiate_chat方法向助手代理发送消息,消息内容为 “帮我总结一下 Python 语言的特点”,助手代理会根据配置的语言模型生成回答。
代码案例二:任务协作
功能描述
该案例包含三个代理:用户代理、规划代理和执行代理。用户提出一个复杂任务,规划代理负责制定任务执行计划,执行代理根据计划执行任务,最后将结果反馈给用户。
代码实现
import autogen
# 创建用户代理
user = autogen.UserProxyAgent(
name="User",
system_message="提出任务需求的用户"
)
# 创建规划代理
planner = autogen.AssistantAgent(
name="Planner",
llm_config={
"model": "gpt-3.5-turbo",
"api_key": "your_openai_api_key"
}
)
# 创建执行代理
executor = autogen.AssistantAgent(
name="Executor",
llm_config={
"model": "gpt-3.5-turbo",
"api_key": "your_openai_api_key"
}
)
groupchat = autogen.GroupChat(agents=[user, planner, executor], messages=[], max_round=12)
manager = autogen.GroupChatManager(groupchat=groupchat)
user.initiate_chat(
manager,
message="我需要分析一份销售数据,数据文件名为sales_data.csv,告诉我分析步骤并执行分析"
)
代码解释
- 创建代理:分别创建了用户代理、规划代理和执行代理,每个代理都有其特定的角色和职责。
- 创建群聊和管理器:使用
GroupChat类创建一个包含三个代理的群聊环境,GroupChatManager用于管理群聊中的对话流程。 - 发起对话:用户代理向管理器发起聊天,提出分析销售数据的任务需求。规划代理接收到消息后,会制定分析步骤的计划,执行代理根据计划对
sales_data.csv文件进行数据分析,并将结果通过群聊反馈给用户。
代码案例三:代码生成与执行
功能描述
用户提出一个需要编写代码实现的功能,由代码生成代理生成 Python 代码,然后通过代码执行代理运行生成的代码,并将结果返回给用户。
代码实现
import autogen
import subprocess
# 创建用户代理
user_agent = autogen.UserProxyAgent(
name="User",
system_message="需求提出者"
)
# 创建代码生成代理
code_generator = autogen.AssistantAgent(
name="CodeGenerator",
llm_config={
"model": "gpt-3.5-turbo",
"api_key": "your_openai_api_key"
}
)
# 创建代码执行代理
code_executor = autogen.UserProxyAgent(
name="CodeExecutor",
system_message="执行生成的代码并返回结果"
)
def execute_code(code):
try:
result = subprocess.run(['python', '-c', code], capture_output=True, text=True)
return result.stdout
except subprocess.CalledProcessError as e:
return f"执行错误: {e.stderr}"
user_agent.initiate_chat(
code_generator,
message="写一个计算1到100累加和的Python代码"
)
generated_code = code_generator.last_message()['content']
code_executor.initiate_chat(
user_agent,
message=f"执行这段代码:\n{generated_code}"
)
result = execute_code(generated_code)
print(f"代码执行结果: {result}")
代码解释
- 创建代理:创建了用户代理、代码生成代理和代码执行代理。
- 生成代码:用户代理向代码生成代理提出编写计算 1 到 100 累加和的 Python 代码需求,代码生成代理根据语言模型生成相应代码。
- 执行代码:代码执行代理获取生成的代码,并调用
execute_code函数执行代码。execute_code函数使用subprocess.run方法运行 Python 代码,并捕获输出结果。如果代码执行出错,会返回错误信息。最后将代码执行结果打印输出。
AutoGen 框架以其独特的多代理对话机制、简化工作流的特性以及模块化设计,为多智能体系统的开发带来了极大的便利 。通过本文的介绍,我们深入了解了 AutoGen 框架的核心概念、显著特性以及与其他框架相比所具备的优势。在基础环境安装方面,我们详细阐述了从准备工作到 Python 环境搭建,再到 AutoGen 及其相关依赖安装的每一个步骤,确保开发者能够顺利搭建起运行 AutoGen 框架的基础环境。
展望未来,随着人工智能技术的不断发展,AutoGen 框架有望在更多领域得到广泛应用,并持续推动各行业的智能化变革。相信广大开发者在深入学习和应用 AutoGen 框架的过程中,能够充分发挥其潜力,创造出更多具有创新性和实用价值的应用程序,为人工智能领域的发展贡献自己的力量。
代码案例三:和 ollama 模型 结合使用
这里我们需要2个模型,模型我们使用ollama 在本地环境中部署。
ollama run qwen2:1.5b

ollama run llama3-Chinese:8B

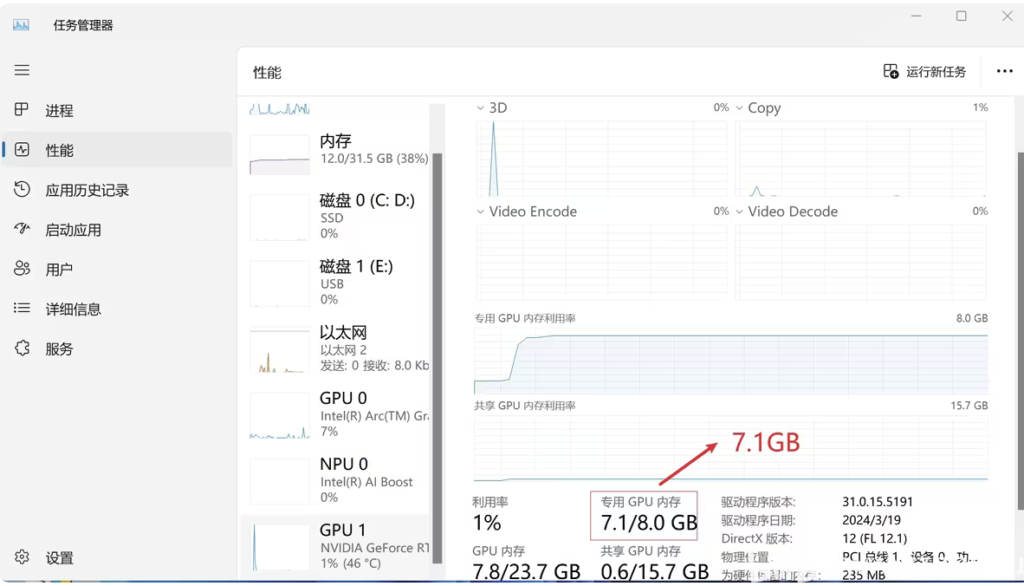
关于ollama 安装和部署在这里我们就不做详细展开。这里需要注意的是默认情况下ollama 启动模型是单个模型,我们需要启动增加OLLAMA_MAX_LOADED_MODELS来实现同时加载多个模型,这个在v0.1.33 增加此功能。
2个模型同时启动后,显存占用情况
下面我们之间给出代码
llama3 = {
"config_list": [
{
"model": "llama3-Chinese:8B",
"base_url": "http://localhost:11434/v1",
"api_key": "lm-studio",
},
],
"cache_seed": None, # Disable caching.
}
qwen = {
"config_list": [
{
"model": "qwen2:1.5b",
"base_url": "http://localhost:11434/v1",
"api_key": "lm-studio",
},
],
"cache_seed": None, # Disable caching.
}
# 以上代码定义2个模型请求地址,我这里使用ollama运行的。当然你也可以使用gpt4 或者其他付费模型API KEY .
from autogen import ConversableAgent
qwen1 = ConversableAgent(
"qwen",
llm_config=qwen,
#system_message="Your name is Jack and you are a comedian in a two-person comedy show.",
system_message="你的名字叫qwen,你是一个参考高考学生。你的角色是根据指定主题创作引人入胜且信息丰富的文章,并且根据你的同事llama3的建议来修改和完善你创作的文章,每当你收到llama3的建议时,都要根据llama3的建议给出修改和完善后的完整文章。",
)
llama31 = ConversableAgent(
"llama3",
llm_config=llama3,
#system_message="Your name is Emma and you are a comedian in two-person comedy show.",
system_message="你的名字叫llama3,你的角色是一个高考作文阅卷老师。你的任务是针对你的同事qwen所写的文章评估并提出改进建议,每次对话你都要对文章作出评估并给出修改建议。",
)
chat_result = llama31.initiate_chat(qwen1, message="qwen,随着互联网的普及、人工智能的应用,越来越多的问题能很快得到答案。那么,我们的问题是否会越来越少?以上材料引发了你怎样的联想和思考?请写一篇文章。要求:选准角度,确定立意,明确文体,自拟标题;不要套作,不得抄袭;不得泄露个人信息;不少于800字", max_turns=2)
# 这段代码定义2个角色,最后通过lama31.initiate_chat 方法执行2轮对话 完成 2个模型的互相交换。实现一个简单高考阅卷的场景。
将以上代码保存到电脑任意盘符下面
// 运行代码 python autogentest.py
运行结果
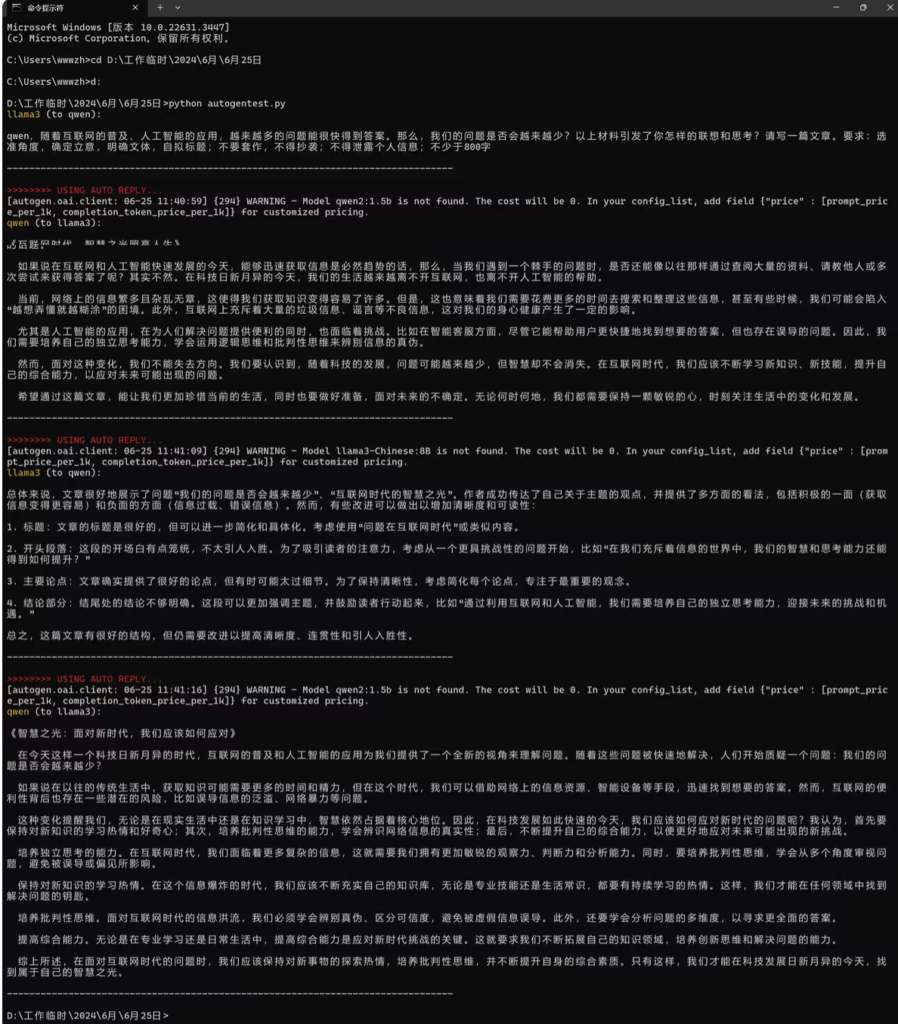
通过以上截图我们可以看到 2个模型之间进行了对话。
qwen 这个角色负责编写一个高考作为题目。 llama3 这个角色是一个高考监考老师。当qwen 第一次编写好高考昨天题目发给llama3 ,llama3 根据这个高考昨天题目实现了自动批改,并给出修改意见。

接下来qwen 这个角色收到llama3 批改昨天的修改意见进行第二次编写,然后在发给llama3。后面程序执行完成。
是不是非常简单就实现2个agent 代理功能呢。
通过简单2个agent 聊天对话方式实现。AutoGen是一个强大的框架,能够帮助开发者利用LLM的强大功能,创建复杂且高效的多代理对话系统,从而解决各种复杂问题并优化用户交互。
更高阶一点的玩法
可能已经有人会想到,前面无论是单个Agent或者是多个Agent,都是人类预先创建好的。针对某个具体的问题,又怎么知道应该创建多少个Agent?什么样的Agent才合适呢?在特定的任务里,是不是可以临时创建一个Agent?能不能只给一个”第一推动力”,后面的事儿全交给AI去干了?
这个也有人想过了,两位中国留学生Linxin Song和Jieyu Zhang搞了一个Agent AutoBuild的项目,就是解决这个问题。他们的方法是:设计一个名为AgentBuilder的类,它将在用户提供构建任务和执行任务的描述后,自动完成参与者专家Agent的生成和群聊的构建。
大概的代码如下:
from autogen.agentchat.contrib.agent_builder import AgentBuilder #步骤1,创建AgentBuilder的实例 builder = AgentBuilder(config_file_or_env=config_file_or_env, builder_model='gpt-4-1106-preview', agent_model='gpt-4-1106-preview') #步骤2,指定创建的任务 building_task = "Find a paper on arxiv by programming, and analyze its application in some domain. For example, find a latest paper about gpt-4 on arxiv and find its potential applications in software." #步骤3,创建群聊的Agent,这一步会返回一个agent_list和agent的配置 agent_list, agent_configs = builder.build(building_task, default_llm_config, coding=True) #步骤4,利用返回的agent_list和agent_configs构建群聊,并且将任务交给群聊去执行。
这就讲Agent的构建也交给AI去决策了,你需要的只是指定任务而已。
在官网的Blog还有一些其他也挺有的意思的试验性项目,例如让Agent更新自己的技能等等。可以自己参阅。
关于应用开发的一些想法
Agent和过去程序代码不一样的地方就是它或多或少是有一些智能的,和过去一个函数或者应用写好之后就处于不可改动的情况不同。也就是意味着,利用Agent或者Multi-Agent实现的应用程序是有可能实现进化的。传统的应用程序不过是为Agent提供了一个基本的”环境”,Agent可以通过与人(“用户”)的交互以及环境的互动过程中,通过数据和反馈来感知外部,并且不断生成代码和使用工具来优化应用。例如,过去人们购买的应用软件都需要等待厂家的升级来进行版本的改动和调整,但是基于Agent的应用程序就有可能通过自然语言来构筑新的功能,而无需等待版本的更新。也就是说,应用应该是”成长”出来。
如果将来LLM能够收集数据来更新自己,那么人类就真的变成了超级智能的引导程序。