引言
在AI大模型风靡全球的今天,你是否好奇:为什么ChatGPT能告诉你今天的天气?为什么它能帮你查股票、发邮件,甚至操作数据库?这一切的核心秘密,就是Function Calling(函数调用)。
因为大模型的训练数据是静态的,知识截止于某个时间点,即无法感知实时数据(如天气、股价),也无法操作外部系统(如发邮件、查数据库)。


什么是 Function Call?
1.什么是 Function Call?
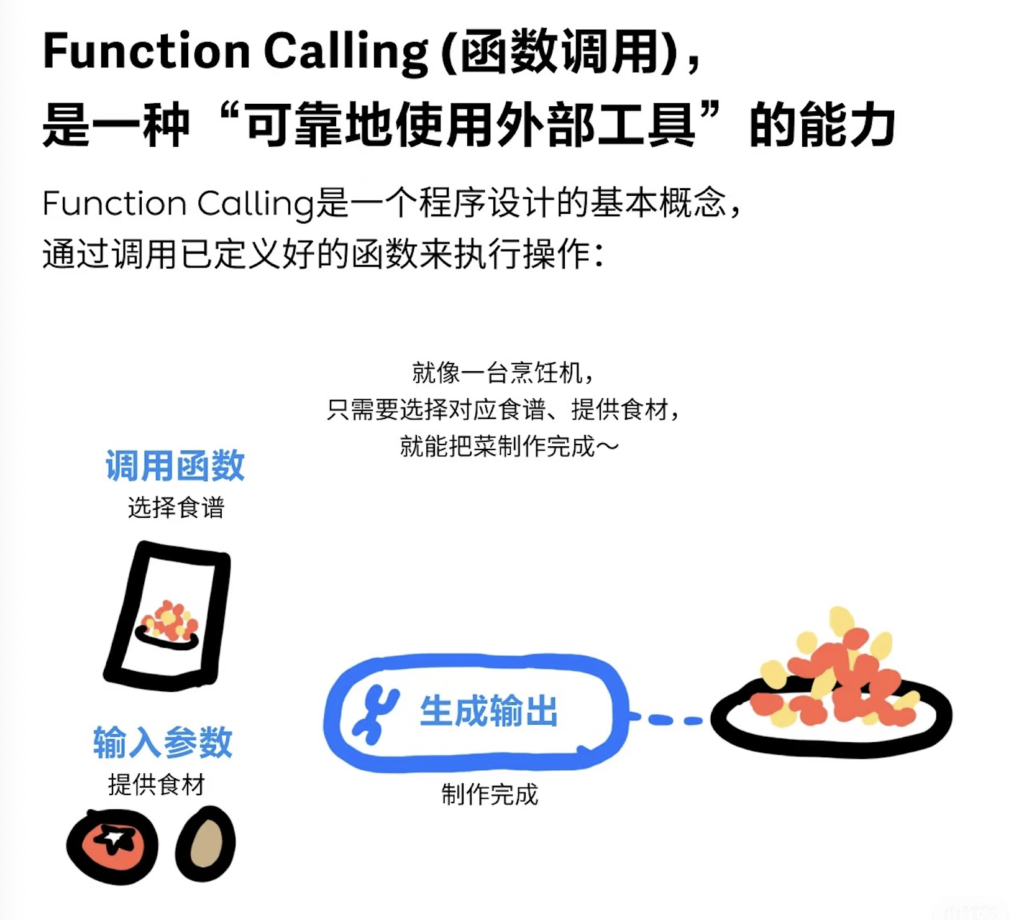
简单说:就是让大模型具备“调用外部工具” 的能力!
大模型平时只能靠训练时学到的知识回答问题。一旦你问它:
“现在空气质量怎么样?”? “我快递到哪了?” 它就懵了,因为这些都是实时、动态信息。
而 Function Calling 能让大模型:意识到“这问题我不会”,喊外部工具帮忙(比如查天气的API、计算器)拿到结果后再组织成答案
举个例子:
你问:“杭州今天天气怎么样?” 大模型会说:“我要调用查天气的函数,参数是: location=杭州,date=2025/07/23"
外部程序完成查询,把结果传回,然后大模型再告诉你:
“杭州今天 25°C,晴天~”
核心:让大模型从“只会说”变成“能做事”!
Funtion Call 本质:
让大模型根据用户指令,生成结构化参数调用预定义的外部函数(如API、数据库),再将结果转化为自然语言回答。
2.为啥非得有这个能力
因为大模型的知识是“静态”的,训练数据只到某个时间点,之后的变化(股价、新闻、天气)它都不知道。
Function Calling 相当于给它接上“外挂”:
- 能查实时信息(调用搜索引擎)
- 能做科学计算(调用计算器)
- 能执行代码(调用代码解释器)
- 能访问内部系统(如查库存)
- 甚至能控制设备( 如关灯、开空调)
没有这能力,大模型就是个“纸上谈兵的学霸”, 有了它,才能变成“能干活的打工人”
所以,Function Calling 也成为实现 Al Agent 的核心技术之一。
3.容易误解的地方
很多同学可能会以为大模型自己能“跑代码”“调用函数”?其实不然!
重点来了:大模型只负责“决定是否调用函数、调用哪个函数、传哪些参数”。
真正执行函数调用的是某个外部程序,比如可能是你写的大模型应用、某个脚本或 API 服务等。所以,Function Calling 本质上是一种提示词工程:你要在提示词里告诉大模型“嘿,你可以用这些函数:XXX”,它才知道有哪些选项,并生成格式正确的调用请求。
4.模型本身能力也很关键
当然,提示词设计再精妙,前提还是大模型本身要“具备函数调用能力”。
当下,函数调用已成为现代大模型的“标配技能”。
主流大模型(如 Llama、Qwen、GPT)在训练阶段就加入了专门的数据,让大模型学会:
- 看懂函数定义
- 能正确判断是否调用
- 能准确选出调用哪个函数
- 能合理决定如何传参
- 结构化地生成调用请求,方便程序解析
不同大模型在训练方式和训练数据格式上差别很大!
在使用 Function Calling 时,需要注意:
- 提示词结构设计:函数清单应该按什么格式写,如何拼接到提示词中
- 生成结果解析:如何从大模型输出中提取函数调用信息(如函数名、参数等)
这两点因模型而异,必须根据具体模型进行适配!
5.Function Calling和MCP的区别
它们完全不是一回事,可别搞混哈

简单来说:
- Function Calling:让“大模型”会思考:要不要调用函数(工具)、调用哪个、怎么传参。
- MCP:让“大模型和工具”能沟通顺畅:处理如何注
册、发现、调用外部工具等问题。
两者需要配合使用,才能实现稳定的、可扩展的工具调用闭环!
经典例子
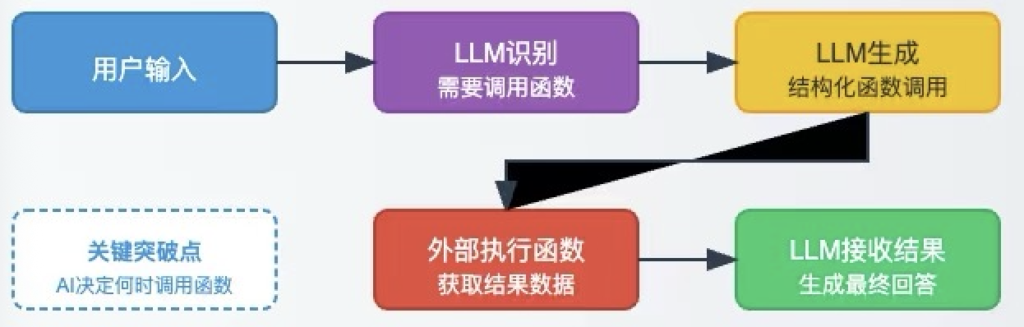
fuction call 功能可以识别用户意图,告诉我们要调用哪个接口(或工具)来响应用于的意图,并自动解析获取需要的入参。这样就能通过接口(或外部工具)的方式获取响应用户意图需要的信息或操作,让机器人给用户输出的内容更加贴合用户意图。

以一个经典场景为例:用户问“北京今天多少度?”
1.意图识别
大模型分析问题,发现需要实时天气数据,决定调用预定义的get_weather函数
2.生成参数
模型输出结构化JSON参数,精准匹配函数要求:
var = {
"name": "get_weather",
"arguments": {
"Location":"北京"
"unit": "celsius"
}
3.执行函数
开发者代码解析参数,并调用命中的天气API,返回数据:
result = {
"Location":“北京",
"temperature": 25,
"cond
4.生成回答
模型将API返回的数据和用户提问整合为自然语言回复:
“北京今日晴,气温25°C,适宜外出。”
原理和实现
大模型通过接口对外提供Function Call功能,接口如何调用,不同模型厂商有些差别,具体可以查阅模型厂商的文档。具有的大致的共性如下:
使用Function Call功能时,你需要先定义一些function。然后,在发送给模型的信息中描述这些function(需要指定函数名,函数用途的描述,参数名,参数描述),并传给LLM。注意是发送函数描述,不是定义函数本身的代码。当用户输入问题时,大模型理解用户的意图,通过文本分析是否需要调用某一个function,当需要调用但缺少参数值时,会与用户沟通获取更多的信息,以从用户语义中提取出函数参数。然后,LLM返回一个json,json包括需要调用的function名,需要输入到function的参数名,以及参数值。
下一步,开发者使用接收到的函数参数调用对应函数就可以了。如果需要,还可以将函数执行的结果返回给模型,以进行更多的操作。
总而言之,function cal|帮我们做了两件事情:
- 1.判断是否要调用某个预定义的函数。
- 2.如果要调用,从用户输入的文本里提取出函数所需要的函数值
流程示意图
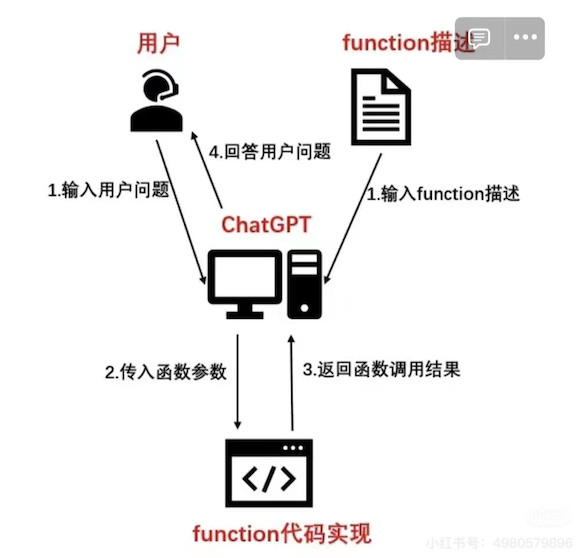
目前,很多模型会自动检测,判断什么时候进行Function Calling
大模型通过 JSON 调用工具函数的过程
大模型通过 JSON 调用工具函数的过程,本质是模型与外部工具之间的 “标准化对话”,具体细节可拆解为以下步骤:
1. 模型生成符合格式的 JSON 指令
当大模型判断需要调用工具时,会根据提前学习的函数描述(如函数名、参数要求),生成一段严格遵循预设格式的 JSON。
- 格式约定:通常需要包含
function_name(函数名)、parameters(参数键值对)等核心字段,有时会加上id(用于多轮调用时匹配结果)。
示例:
{
"function_name": "get_weather",
"parameters": {
"city": "上海",
"date": "2024-05-20"
}
}
- 模型的 “自律性”:训练时会通过大量样本(如 “用户问天气→生成天气函数 JSON”)让模型学会 “什么时候输出这样的 JSON”“参数是否完整”,避免格式错误(如少括号、参数缺失)。
2. 外部程序 “捕获” 并解析 JSON
大模型不会直接执行 JSON,而是由外部系统(如开发者搭建的后端服务)负责处理:
- 提取指令:外部程序监听模型的输出,当检测到符合格式的 JSON(通常用特殊标记包裹,如
<function_call>{...}</function_call>),就会提取这段内容。 - 校验合法性:检查 JSON 格式是否正确、函数名是否存在、参数是否符合要求(如 “city” 是否为字符串、“date” 是否符合日期格式)。若有错误,可能返回给模型要求修正(比如 “缺少参数 date,请补充”)。
3. 调用工具并获取结果
外部程序解析 JSON 后,执行实际的工具调用:
- 映射到具体工具:根据
function_name找到对应的工具(如 API 接口、本地函数),并将parameters中的参数传入。
例如,若function_name是get_weather,外部程序可能用 curl 调用天气 API:
curl -X POST https://api.weather.com/get \
-d '{"city":"上海", "date":"2024-05-20"}'
- 获取返回结果:工具执行后,返回结构化数据(如 JSON 格式的天气信息:
{"temperature": "25℃", "condition": "sunny"})。
4. 将结果反馈给模型,完成闭环
外部程序把工具返回的结果整理成自然语言或结构化数据,“喂” 回给大模型,作为下一轮生成的上下文:
- 模型结合用户原始问题和工具结果,生成最终回答(如 “上海 2024 年 5 月 20 日天气晴朗,气温 25℃”)。
- 若结果不完整(如天气 API 未返回风力信息),模型可能再次生成 JSON 调用工具补充查询。
核心关键点
- 大模型的角色是 “生成指令”,不涉及实际调用;外部系统是 “执行者”,负责解析、调用和反馈。
- JSON 的作用是 “标准化接口”,让模型和工具之间的信息传递清晰、无歧义,就像两人用同一种语言对话。
- 整个过程的顺畅性,依赖模型对格式的严格遵循(训练保障)和外部程序的高效解析(工程实现)。
大模型function call是怎么调用工具的、怎么知道工具在哪呢?
大模型的 Function Call 调用工具的过程,简单来说是 “识别需求→生成调用指令→对接工具→获取结果→整理输出” 的流程,而工具的位置则通过预设的 “接口信息” 来确定。
1. 如何调用工具?
- 识别调用需求:大模型接收用户问题后,判断是否需要调用工具(比如计算、查实时数据、调用 API 等)。例如,用户问 “今天北京的天气如何”,模型会识别出需要调用天气查询工具。
- 生成规范调用指令:如果需要调用工具,模型会按照预设的格式(通常是 JSON)生成调用指令,包含工具名称、所需参数(如 “城市 = 北京”“日期 = 今天”)。
- 对接工具执行:大模型将生成的指令发送给对应的工具接口,工具接收后执行操作(比如调用天气 API 获取数据)。
- 处理返回结果:工具将结果返回给大模型,模型再把结果整理成自然语言回答用户。
2. 怎么知道工具在哪?
工具的位置是通过预设的接口信息提前告知大模型的,包括:
- 工具的唯一标识(如工具名称、ID);
- 工具的调用地址(如 API 接口 URL、本地函数路径);
- 调用所需的参数格式(必填项、数据类型等)。
这些信息会在大模型部署时配置好,就像给模型一张 “工具地图”,让它知道该找谁、怎么联系。当模型需要调用工具时,就会根据这张 “地图” 找到对应的工具并发起请求。
大模型 function call 都需要有个 外部程序 “捕获” 大模型结果 、并且调用函数吗?
在大模型的Function Call(函数调用) 流程中,通常需要一个外部程序或中间层来 “捕获” 大模型的输出结果,并执行实际的函数调用。这是因为大模型本身并不直接具备执行外部函数的能力,它的核心作用是根据用户需求和上下文,判断是否需要调用函数、调用哪个函数,以及生成符合格式的函数调用指令(如参数、函数名等)。
具体流程可拆解为以下步骤:
1. 大模型生成函数调用指令
- 当用户的问题需要调用外部工具(如查询天气、调用 API、操作数据库等)时,大模型会按照预设格式(通常是 JSON)生成函数调用的描述,例如:
{"name": "get_weather", "parameters": {"city": "北京", "date": "2024-05-01"}}
此时,大模型仅输出指令,并不执行函数。
2.外部程序捕获并解析指令
- 外部程序(可以是开发者编写的后端服务、Agent 框架中的协调模块等)会监听大模型的输出,识别出其中的函数调用指令,并解析出函数名、参数等关键信息。
3.外部程序执行函数调用
- 外部程序根据解析结果,调用对应的实际函数(可能是本地函数、第三方 API、数据库操作等),并获取函数的返回结果。
4.将结果反馈给大模型
- 外部程序将函数的返回结果整理后,再传递回大模型,大模型基于此结果继续处理(如生成自然语言回答、决定是否需要进一步调用函数等)。
为什么需要外部程序?
- 大模型的局限性:大模型本质是语言模型,没有直接访问外部系统、执行代码或调用 API 的能力,无法直接与外部环境交互。
- 安全性与可控性:通过外部程序中转,可以对函数调用进行权限校验、参数过滤、日志记录等,避免大模型直接操作外部系统带来的风险(如误操作、安全漏洞)。
- 兼容性:外部程序可以适配不同的函数接口、工具类型,将大模型的标准化指令转换为各种外部系统可识别的格式。
例外情况?
某些集成了 Function Call 能力的Agent 框架或平台(如 LangChain、AutoGPT 等)会将 “捕获指令 – 调用函数” 的逻辑封装为内部模块,开发者无需手动编写外部程序,但本质上仍是框架内部的中间层在执行 “捕获 – 调用” 的工作,并非大模型自身直接执行。
综上,外部程序(或中间层)是 Function Call 流程中不可或缺的一环,它负责连接大模型与外部函数,实现 “指令生成 – 执行 – 结果反馈” 的闭环。