转载:https://www.thebyte.com.cn/ServiceMesh/summary.html
计算机科学中的所有问题都可以通过增加一个间接层来解决。如果不够,那就再加一层。
Kubernetes 的崛起意味着虚拟化的基础设施,开始解决分布式系统软件层面的问题。Kubernetes 最早提供的应用副本管理、服务发现和分布式协同能力,实质上将构建分布式应用的核心需求,利用 Replication Controller、kube-proxy 和 etcd “下沉”到基础设施中。然而,Kubernetes 解决问题的粒度通常局限于容器层面,容器以下的服务间通信治理(如服务发现、负载均衡、限流、熔断和加密等问题)仍需业务工程师手动处理。
在传统分布式系统中,解决上述问题通常依赖于微服务治理框架(如 Spring Cloud 或 Apache Dubbo),这类框架将业务逻辑和技术方案紧密耦合。而在云原生时代,解决这些问题时,在 Pod 内注入代理型边车(Sidecar Proxy) ,业务对此完全无感知,显然是最“Kubernetes Native”的方式。边车代理将非业务逻辑从应用程序中剥离,服务间的通信治理由此开启了全新的进化,并最终演化出一层全新基础设施层 —— 服务网格(ServiceMesh)。
本章,我们将回顾服务间通信的演化历程,从中理解服务网格出现的背景、以及它所解决的问题。然后解读服务网格数据面和控制面的分离设计,了解服务网格领域的产品生态(主要介绍 Linkerd 和 Istio)。最后,我们直面服务网格的缺陷(网络延迟和资源占用问题),讨论如何解决,并展望服务网格的未来。本章内容组织如图 8-0 所示。
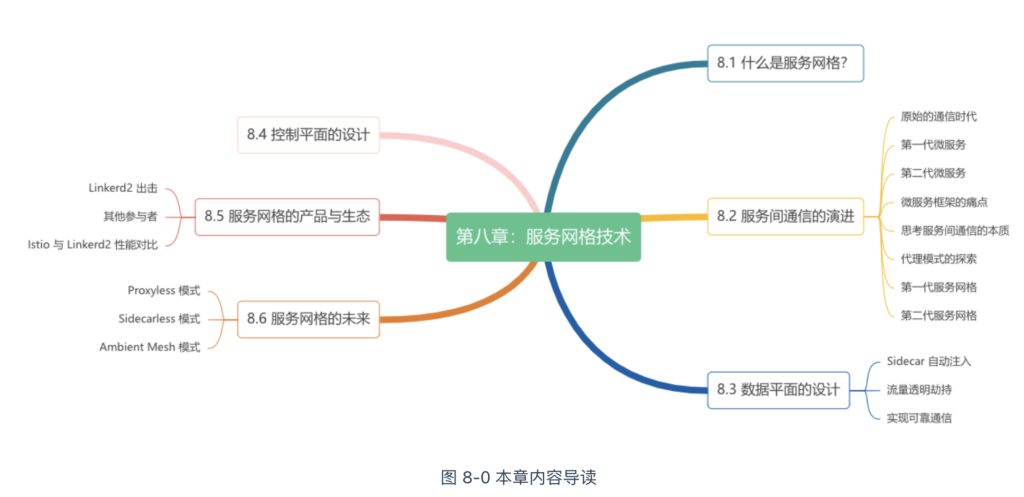
什么是服务网格
2016 年,William Morgan 离开 Twiiter,组建了一个小型技术公司 Buoyant。不久之后,他在 Github 上发布了创业项目 Linkerd,业界第一款服务网格诞生!
那么,服务网格(Service Mesh)到底是什么?服务网格的概念最早由 William Morgan 在其博文《What’s a service mesh? And why do I need one?》中提出。作为服务网格的创造者,引用他的定义无疑是最官方和权威的。
服务网格的定义
服务网格是一个处理服务通讯的专门的基础设施层。它的职责是在由云原生应用组成服务的复杂拓扑结构下进行可靠的请求传送。在实践中,它是一组和应用服务部署在一起的轻量级的网络代理,对应用服务透明。
—— What’s a service mesh?And why do I need one?,William Morgan
通过下述,感受服务网格从无到有、被社区接受、巨头入局、众人皆捧的发展历程:
- 2016 年 9 月:在 SF MicroServices 大会上,术语“服务网格”首次在公开场合提出,服务网格的概念从 Buoyant 公司内部走向社区。
- 2017 年 1 月:Linkerd 加入 CNCF,被归类到 CNCF 新设立的“Service Mesh”分类,这表明服务网格的设计理念得到了主流社区认可。
- 2017 年 4 月:Linkerd 发布 1.0 版本,服务网格实现了关键里程碑 —— 被客户接受,在生产环境中大规模应用。服务网格从“虚”转“实”。
- 2017 年 5 月:Google、IBM 和 Lyft 联合发布 Istio 0.1 版本,以 Istio 为代表的第二代服务网格登场。
- 2018 年 7 月:CNCF 发布了最新的云原生定义,将服务网格与微服务、容器、不可变基础设施等技术并列,服务网格的地位空前提升。
- 2022 年 7 月,Cilium 发布了“无边车模式”的服务网格,2 个月之后,Isito 发布了全新的数据平面模式 “Ambient Mesh”,服务网格的形态开始多元化。
服务间通信的演化
服务网格主要解决服务间通信治理问题。本节内容,我们从各个历史阶段的通信治理展开,探讨服务网格的起源与演变。
原始的通信时代
先回到计算机的“远古时代”。
大约 50 年前,初代工程师编写涉及网络的应用程序,需要在业务代码里“埋入”各类网络通信的逻辑。比如实现可靠连接、超时重传和拥塞控制等功能,这些功能与业务逻辑毫无关联,但不得不与业务代码混杂在一起实现。
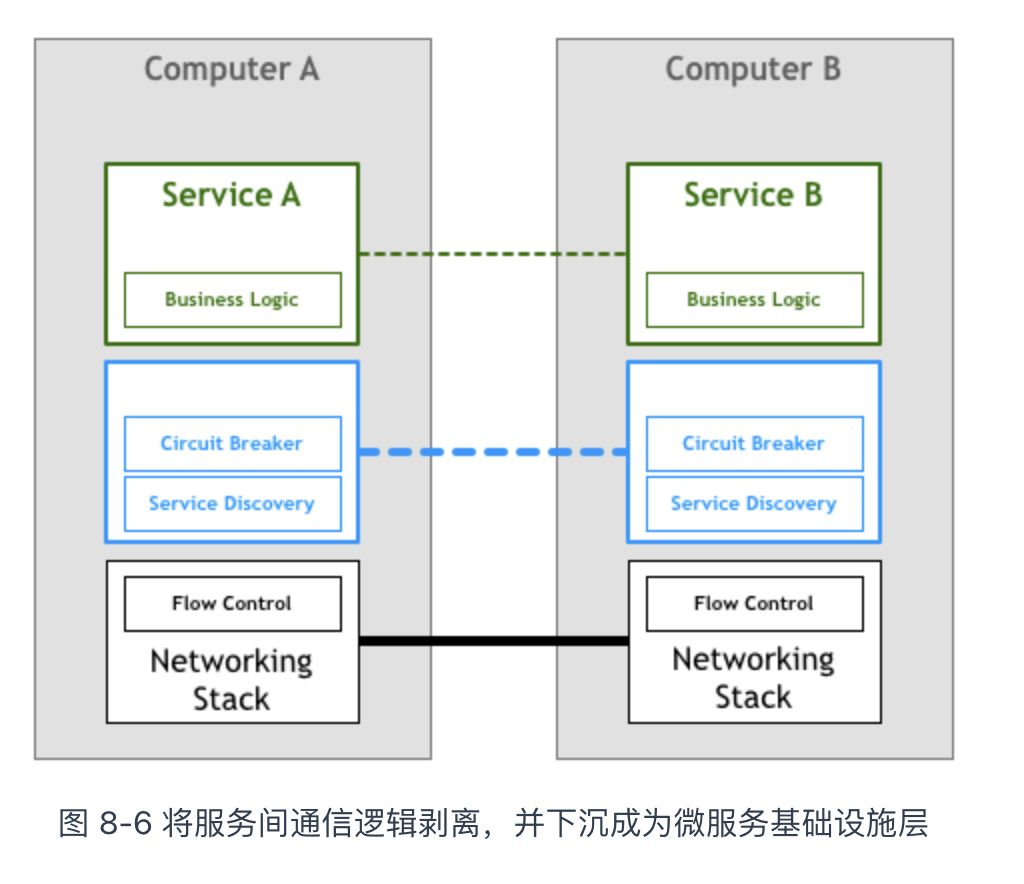
为了解决每个应用程序都要重复实现相似的通信控制逻辑问题,TCP/IP 协议应运而生,它把通信控制逻辑从应用程序中剥离,并将这部分逻辑下沉,成为操作系统网络层的一部分。
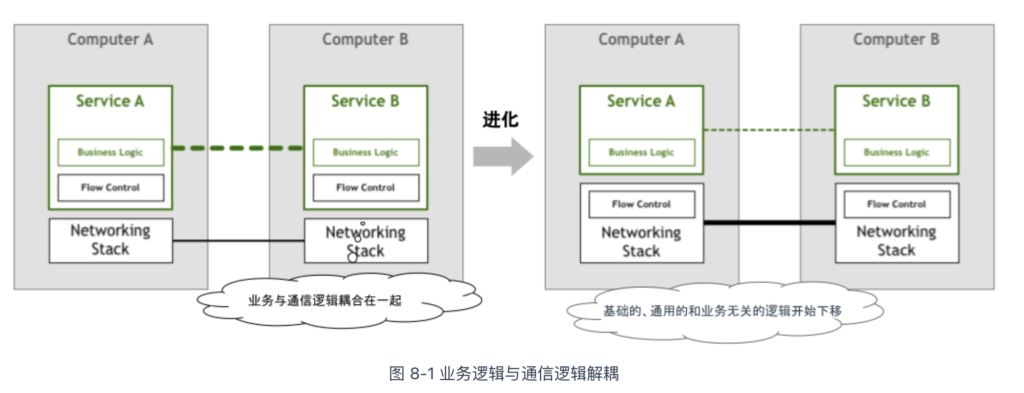
在原始的通信时代,TCP/IP 协议的出现让我们看到这样的变化:非业务逻辑从应用程序中剥离出来,剥离出来的通信逻辑下沉成为基础设施层。于是,工程师的生产力被解放,各类网络应用开始遍地开花。
第一代微服务
随着 TCP/IP 协议的出现,机器之间的网络通信不再是难题,分布式系统也由此迎来了蓬勃发展。此阶段,分布式系统特有的通信语义又出现了,比如熔断策略、负载均衡、服务发现、认证与授权、灰度发布以及蓝绿部署等。
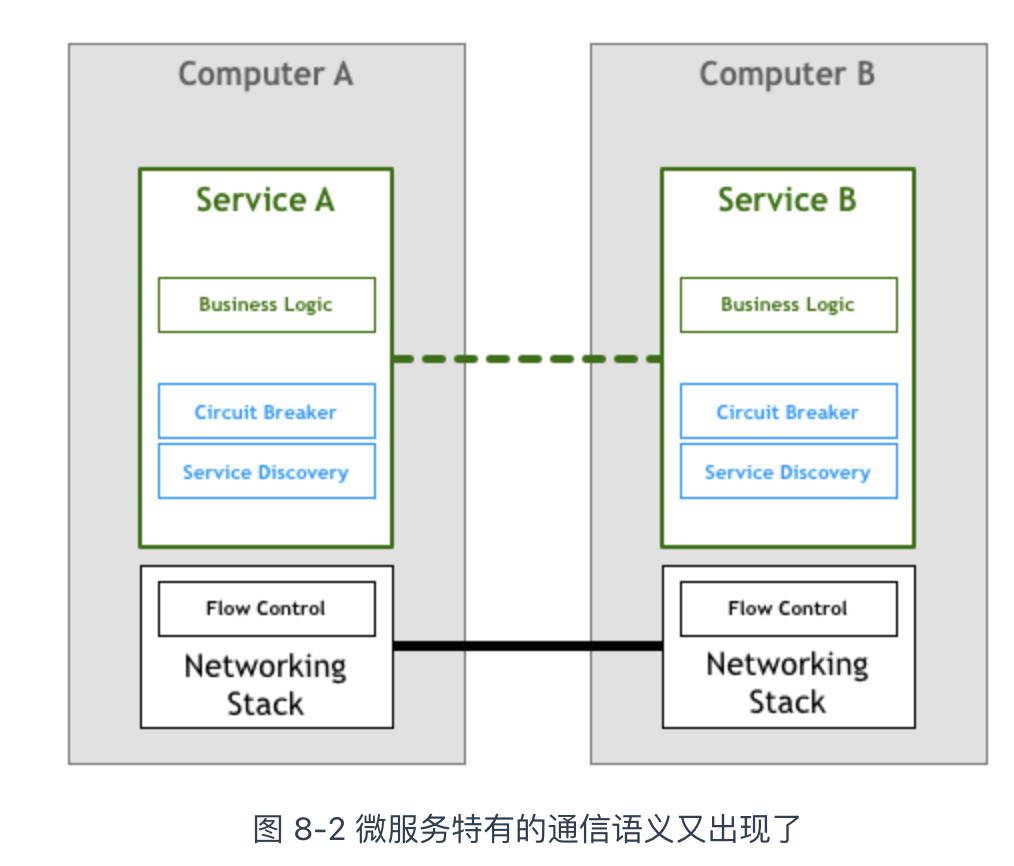
在这一阶段,工程师实现分布式系统时,不仅需要专注于业务逻辑,还需根据业务需求实现各种分布式系统的通信语义。随着系统规模的扩大,即使是最简单的服务发现功能,逻辑也变得愈发复杂。其次,使用相同开发语言的另一个应用,这些分布式系统功能仍需重复实现一遍。
此刻,你是否想到了计算机远古时代前辈们处理网络通信的情形?
第二代微服务
为了避免每个应用程序都要自己实现一套分布式系统的通信语义,一些面向分布式系统的微服务框架出现了,比如 Twitter 的 Finagle、Facebook 的 Proxygen,还有众所周知的 Spring Cloud。
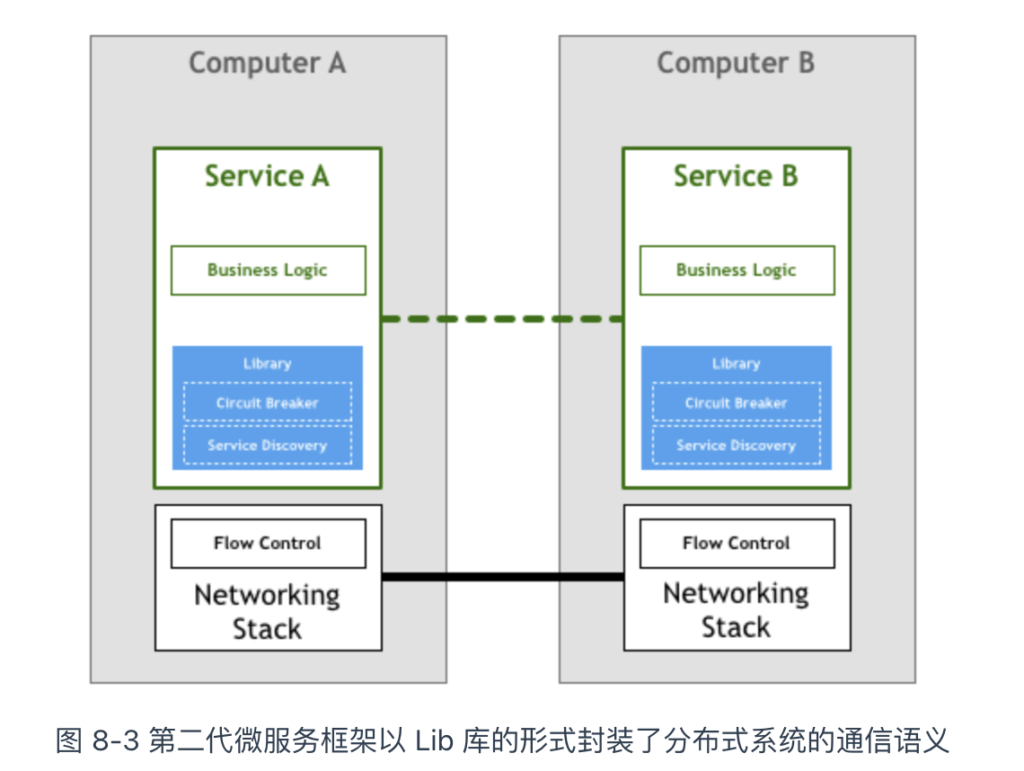
此类微服务框架实现了负载均衡、服务发现、流量治理等分布式通用功能。开发人员无需关注分布式系统底层细节,付出较小的精力就能开发出健壮的分布式应用。
微服务框架的痛点
使用微服务框架解决分布式问题看似完美,但开发人员很快发现它存在三个固有问题:
- 技术门槛高:虽然微服务框架屏蔽了分布式系统通用功能的实现细节,但开发者却要花很多精力去掌握和管理复杂的框架本身。以 SpringCloud 为例,如图 8-5 所示,它的官网用了满满一页介绍各类通信功能的技术组件。实践过程中,工程师们追踪、解决框架出现的问题绝非易事。
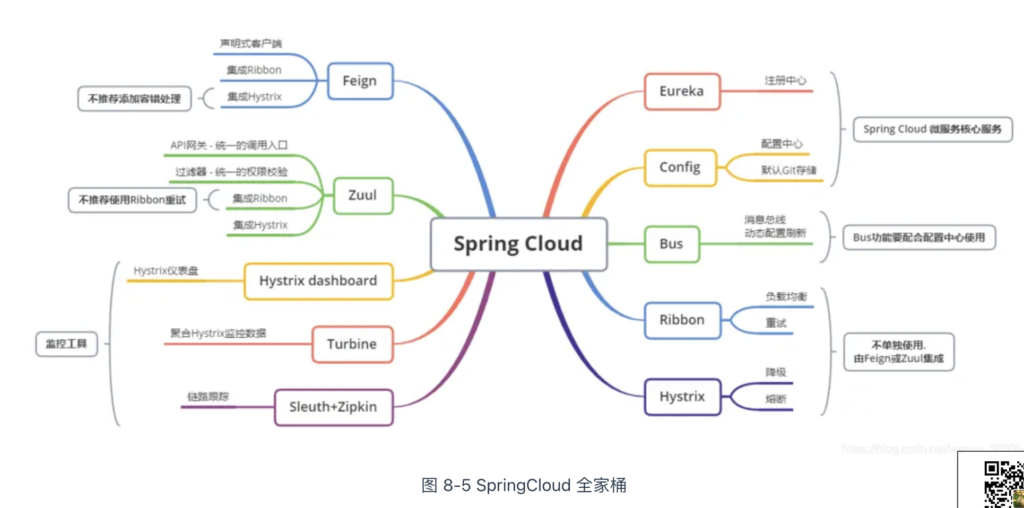
- 框架无法跨语言:微服务框架通常只支持一种或几种特定的编程语言,而微服务的关键特性是和编程语言无关。如果你使用的编程语言框架不支持,则很难融入这类微服务的架构体系。因此,微服务架构所提倡的:“因地制宜用多种编程语言实现不同模块”,也就成了空谈。
- 框架升级困难:微服务框架以 Lib 库的形式和服务联编,当项目非常复杂时,处理依赖库版本、版本兼容问题将非常棘手。同时,微服务框架的升级也无法对服务透明。服务稳定的情况下,工程师们普遍不愿意升级微服务框架。大部分的情况是,微服务框架某个版本出现 Bug 时,才被迫升级。
站在企业组织的角度思考,技术重要还是业务重要?每个工程师都是分布式专家固然好,但又不现实。因此,当企业实施微服务架构时,你会看到业务团队每天处理大量的非业务逻辑,相似的技术问题总在不停上演!
思考服务间通信的本质
实施微服务架构时,需要解决问题(服务注册、服务发现、负载均衡、熔断、限流等)的本质是保证服务间请求的可靠传递。站在业务的角度来看,无论上述逻辑设计的多么复杂,都不会影响业务请求本身的业务语义与业务内容发生任何变化,实施微服务架构的技术挑战和业务逻辑没有任何关系。
回顾前面提到的 TCP/IP 协议案例,我们思考是否服务间的通信是否也能像 TCP 协议栈那样:“人们基于 HTTP 协议开发复杂的应用,无需关心底层 TCP 协议如何控制数据包”。如果能把服务间通信剥离、并下沉到微服务基础层,工程师将不再浪费时间编写基础设施层的代码,而是将充沛的精力聚焦在业务逻辑上。
代理模式的探索
最开始,探路者们尝试过使用“代理”(Proxy)的方案,比如使用 Nginx 代理配置上游、负载均衡的方式处理部分通信逻辑。
虽然这种方式和微服务关系不大,功能也简陋,但它们提供了一个新颖的思路:“在服务器端和客户端之间插入一个中间层,避免两者直接通讯,所有的流量经过中间层的代理,代理实现服务间通信的某些特性。”。
受限于传统代理软件功能不足,在参考代理模式的基础上,市场上开始陆陆续续出现“边车代理”(Sidecar)模式的产品,比如 Airbnb 的 Nerve & Synaps、Netflix 的 Prana。这些产品的功能对齐原侵入式框架的各类功能,实现上也大量重用了它们的代码、逻辑。
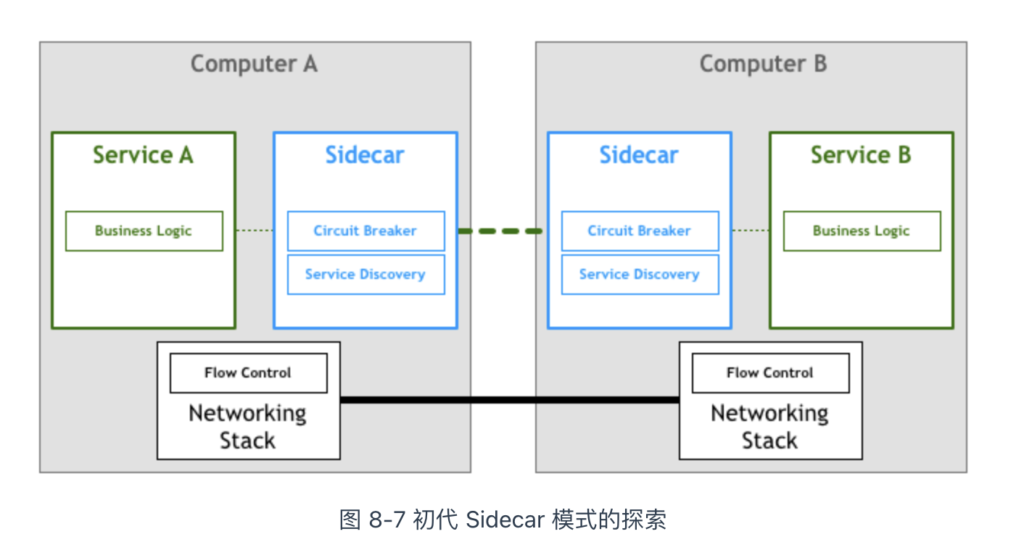
但是此类边车代理存在局限性:它们往往被设计成与特定的基础设施组件配合使用。比如 Airbnb 的 Nerve & Synapse,要求服务发现必须使用 Zookeeper,Prana 则限定使用 Netflix 自家的服务发现框架 Eureka。
因此,该阶段的边车代理局限在某些特定架构体系中,谈不上通用性。
第一代服务网格
2016 年 1 月,William Morgan 和 Oliver Gould 离开 twitter,开启了他们的创业项目 Linkerd。早期的 Linkerd 借鉴了 Twtter 开源的 Finagle 项目,并重用了大量的 Finagle 代码:
- 设计思路上:Linkerd 将分布式服务的通信逻辑抽象为单独一层,在这一层中实现负载均衡、服务发现、认证授权、监控追踪、流量控制等必要功能。
- 具体实现上:Linkerd 作为和服务对等的代理服务(Sidecar)和服务部署在一起,接管服务的流量。
Linkerd 开创先河的不绑定任何基础架构或某类技术体系,实现了通用性,成为业界第一个服务网格项目。同期的服务网格代表产品还有 Lyft(和 Uber 类似的打车软件)公司的 Envoy(Envoy 是 CNCF 内继 Kubernetes、Prometheus 第三个孵化成熟的项目)。

第二代服务网格
第一代服务网格由一系列独立运行的代理型服务(Sidecar)构成,但并没有思考如何系统化管理这些代理服务。为了提供统一的运维入口,服务网格继续演化出了集中式的控制面板(Control Plane)。
典型的第二代服务网格以 Google、IBM 和 Lyft 联合开发的 Istio 为代表。根据 Istio 的总体架构(见图 8-8),第二代服务网格由两大核心组成部分:一系列与微服务共同部署的边车代理(称为数据平面),以及用于管理这些代理的控制器(称为控制平面)。控制器向代理下发路由、熔断策略、服务发现等策略信息,代理根据这些策略处理服务间的请求。
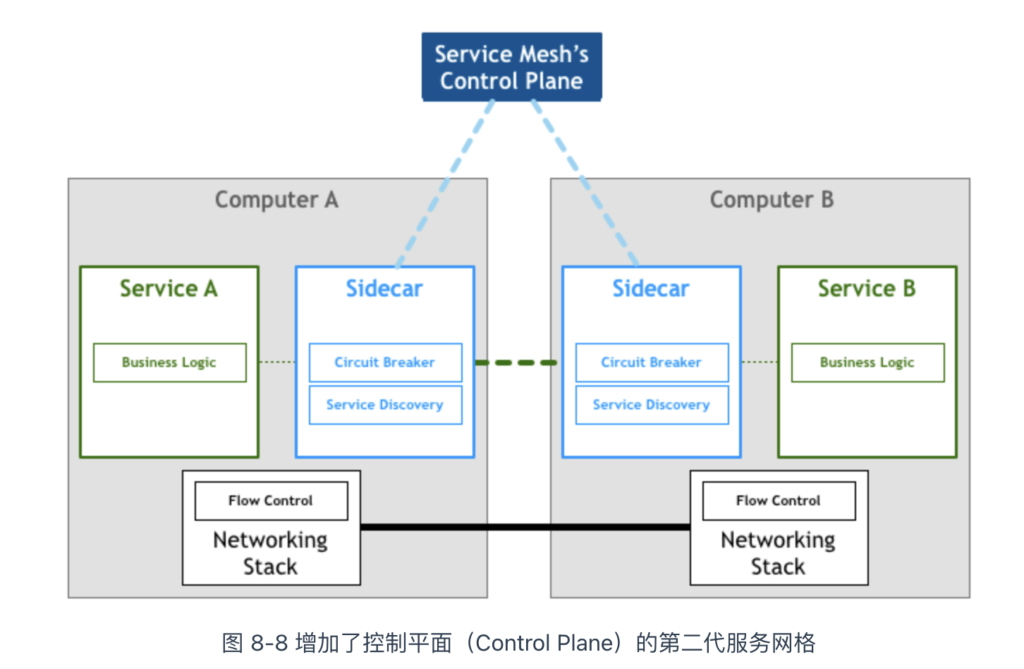
只看代理组件(下方浅蓝色的方块)和控制面板(顶部深蓝色的长方形),它们之间的关系形成如图 8-9 所示的网格形象状,这也是服务网格命名的由来。
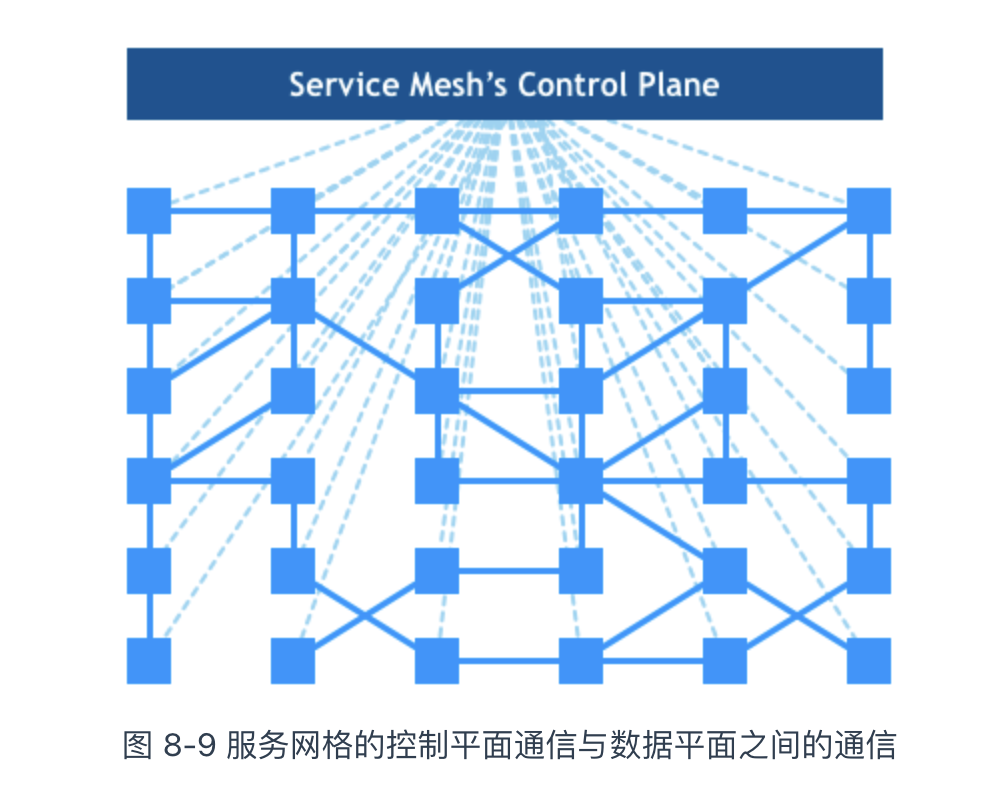
至此,我们见证了 5 个时代的变迁。大家一定清楚了服务网格技术到底是什么,以及是如何一步步演化成今天这样的形态。现在,我们回过头重新看 William Morgan 对服务网格的定义。
服务网格的定义
服务网格是一个基础设施层,用于处理服务间通信。云原生应用有着复杂的服务拓扑,服务网格保证请求在这些拓扑中可靠地穿梭。在实际应用当中,服务网格通常是由一系列轻量级的网络代理组成的,它们与应用程序部署在一起,但对应用程序透明。
再来理解定义中的 4 个关键词:
- 基础设施层+请求在这些拓扑中可靠穿梭:这两个词加起来描述了服务网格的定位和功能,是否似曾相识?没错,你一定想到了 TCP 协议。
- 网络代理:描述了服务网格的实现形态。
- 对应用透明:描述了服务网格的关键特点,正是由于这个特点,服务网格能够解决以 Spring Cloud 为代表的第二代微服务框架所面临的三个本质问题。
数据平面的设计
服务间通信治理并非复杂的技术,服务网格之所以备受追捧,正是因为它能够自动化实现这一过程,且对应用完全透明。接下来,笔者将从边车代理(Sidecar)自动注入、请求透明劫持和可靠通信实现三个方面,探讨数据平面的设计原理。
Sidecar 自动注入
使用过 Istio 的读者一定知道,在带有 istio-injection: enabled 标签的命名空间中创建 Pod 时,Kubernetes 会自动为其注入一个名为 istio-proxy 的边车容器。这套机制的核心在于 Kubernetes 的准入控制器。
Kubernetes 准入控制器
Kubernetes 准入控制器会拦截 Kubernetes API Server 接收到的请求,在资源对象被持久化到 etcd 之前,对其进行校验和修改。准入控制器分为两类:
Validating 类型准入控制器:用于校验请求,无法修改对象,但可以拒绝不符合特定策略的请求;
Mutating 类型准入控制器:在对象创建或更新时,可以修改资源对象。
Istio 预先在 Kubernetes 集群中注册了一个类型为 Mutating 类型的准入控制器,它包含以下内容:
- Webhook 服务地址:指向运行注入逻辑的 Webhook 服务,例如 Istio 的 istio-sidecar-injector;
- 匹配规则:定义哪些资源和操作会触发该 Webhook,比如针对 Pod 创建请求(operations: [“CREATE”]);
- 注入条件:通过 Label(istio-injection: enabled) 或 Annotation 决定是否注入某些 Pod。
apiVersion: admissionregistration.k8s.io/v1
kind: MutatingWebhookConfiguration
metadata:
name: sidecar-injector
webhooks:
- name: sidecar-injector.example.com
admissionReviewVersions: ["v1"]
clientConfig:
service:
name: sidecar-injector-service
namespace: istio-system
path: "/inject"
rules:
- apiGroups: [""]
apiVersions: ["v1"]
resources: ["pods"]
operations: ["CREATE"]
namespaceSelector:
matchLabels:
istio-injection: enabled
流量透明劫持
Isito 通过准入控制器,还会注入一个名为 istio-init 的初始化容器 ,它的配置如下:
initContainers:
- name: istio-init
image: docker.io/istio/proxyv2:1.13.1
args: ["istio-iptables", "-p", "15001", "-z", "15006", "-u", "1337", "-m", "REDIRECT", "-i", "*", "-x", "", "-b", "*", "-d", "15090,15021,15020"]
在上述配置中,istio-init 容器的入口命令为 istio-iptables,该命令配置了一系列 iptables 规则,用于拦截并重定向除特定端口(如 15090、15021、15020)外的流量到 Istio 的边车代理(Envoy):
- 对于入站(Inbound)流量,会被重定向到边车代理监听的端口(通常为 15006)。
- 对于出站(Outbound)流量,则会被重定向到边车代理监听的另一个端口(通常为 15001)。
通过 iptables -t nat -L -v 命令查看 istio-iptables 添加的 iptables 规则。
# 查看 NAT 表中规则配置的详细信息
$ iptables -t nat -L -v
# PREROUTING 链:用于目标地址转换(DNAT),将所有入站 TCP 流量跳转到 ISTIO_INBOUND 链上
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
2 120 ISTIO_INBOUND tcp -- any any anywhere anywhere
# INPUT 链:处理输入数据包,非 TCP 流量将继续 OUTPUT 链
Chain INPUT (policy ACCEPT 2 packets, 120 bytes)
pkts bytes target prot opt in out source destination
# OUTPUT 链:将所有出站数据包跳转到 ISTIO_OUTPUT 链上
Chain OUTPUT (policy ACCEPT 41146 packets, 3845K bytes)
pkts bytes target prot opt in out source destination
93 5580 ISTIO_OUTPUT tcp -- any any anywhere anywhere
# POSTROUTING 链:所有数据包流出网卡时都要先进入POSTROUTING 链,内核根据数据包目的地判断是否需要转发出去,我们看到此处未做任何处理
Chain POSTROUTING (policy ACCEPT 41199 packets, 3848K bytes)
pkts bytes target prot opt in out source destination
# ISTIO_INBOUND 链:将所有目的地为 9080 端口的入站流量重定向到 ISTIO_IN_REDIRECT 链上
Chain ISTIO_INBOUND (1 references)
pkts bytes target prot opt in out source destination
2 120 ISTIO_IN_REDIRECT tcp -- any any anywhere anywhere tcp dpt:9080
# ISTIO_IN_REDIRECT 链:将所有的入站流量跳转到本地的 15006 端口,至此成功的拦截了流量到 Envoy
Chain ISTIO_IN_REDIRECT (1 references)
pkts bytes target prot opt in out source destination
2 120 REDIRECT tcp -- any any anywhere anywhere redir ports 15006
# ISTIO_OUTPUT 链:选择需要重定向到 Envoy(即本地) 的出站流量,所有非 localhost 的流量全部转发到 ISTIO_REDIRECT。为了避免流量在该 Pod 中无限循环,所有到 istio-proxy 用户空间的流量都返回到它的调用点中的下一条规则,本例中即 OUTPUT 链,因为跳出 ISTIO_OUTPUT 规则之后就进入下一条链 POSTROUTING。如果目的地非 localhost 就跳转到 ISTIO_REDIRECT;如果流量是来自 istio-proxy 用户空间的,那么就跳出该链,返回它的调用链继续执行下一条规则(OUPT 的下一条规则,无需对流量进行处理);所有的非 istio-proxy 用户空间的目的地是 localhost 的流量就跳转到 ISTIO_REDIRECT
Chain ISTIO_OUTPUT (1 references)
pkts bytes target prot opt in out source destination
0 0 ISTIO_REDIRECT all -- any lo anywhere !localhost
40 2400 RETURN all -- any any anywhere anywhere owner UID match istio-proxy
0 0 RETURN all -- any any anywhere anywhere owner GID match istio-proxy
0 0 RETURN all -- any any anywhere localhost
53 3180 ISTIO_REDIRECT all -- any any anywhere anywhere
# ISTIO_REDIRECT 链:将所有流量重定向到 Envoy(即本地) 的 15001 端口
Chain ISTIO_REDIRECT (2 references)
pkts bytes target prot opt in out source destination
53 3180 REDIRECT tcp -- any any anywhere anywhere redir ports 15001
根据图 8-10 进一步理解上述 iptables 自定义链(以 ISTIO_开头)处理流量的逻辑。
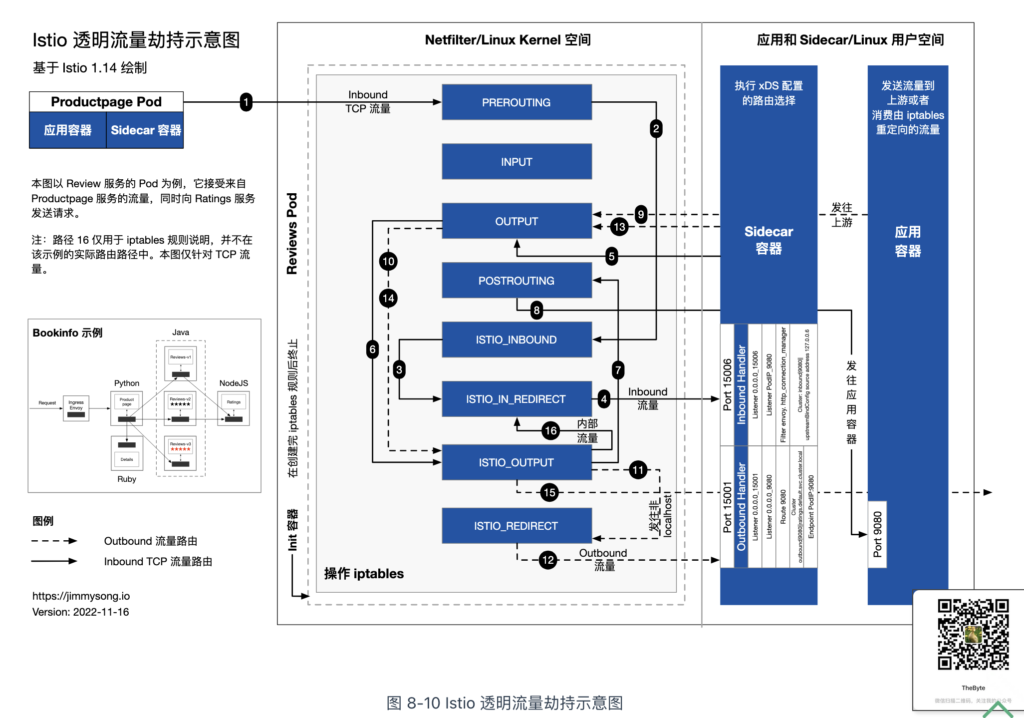
使用 iptables 实现流量劫持是最经典的方式。不过,客户端 Pod 和服务端 Pod 之间的网络数据路径需要至少经过三次 TCP/IP 堆栈(出站、客户端边车代理到服务端的边车代理、入站)。如何降低流量劫持的延迟和资源消耗,是服务网格未来的主要研究方向,笔者将在 8.5 节探讨这一问题。
实现可靠通信
通过 iptables 劫持流量,转发至边车代理后,边车代理根据配置接管应用程序之间的通信。
传统的代理(如 HAProxy 或 Nginx)依赖静态配置文件来定义资源和数据转发规则,而 Envoy 则几乎所有配置都可以动态获取。Envoy 将代理转发行为的配置抽象为三类资源:Listener、Cluster 和 Router,并基于这些资源定义了一系列标准数据面 API,用于发现和操作这些资源,这套标准数据面 API 被称为 xDS。
xDS 的全称是“x Discovery Service”,“x” 指的是表 8-1 中的协议族。
表 xDS v3.0 协议族
| 简写 | 全称 | 描述 |
|---|---|---|
| LDS | Listener Discovery Service | 监听器发现服务 |
| RDS | Route Discovery Service | 路由发现服务 |
| CDS | Cluster Discovery Service | 集群发现服务 |
| EDS | Endpoint Discovery Service | 集群成员发现服务 |
| ADS | Aggregated Discovery Service | 聚合发现服务 |
| HDS | Health Discovery Service | 健康度发现服务 |
| SDS | Secret Discovery Service | 密钥发现服务 |
| MS | Metric Service | 指标服务 |
| RLS | Rate Limit Service | 限流发现服务 |
| LRS | Load Reporting service | 负载报告服务 |
| RTDS | Runtime Discovery Service | 运行时发现服务 |
| CSDS | Client Status Discovery Service | 客户端状态发现服务 |
| ECDS | Extension Config Discovery Service | 扩展配置发现服务 |
| xDS | X Discovery Service | 以上诸多API的统称 |
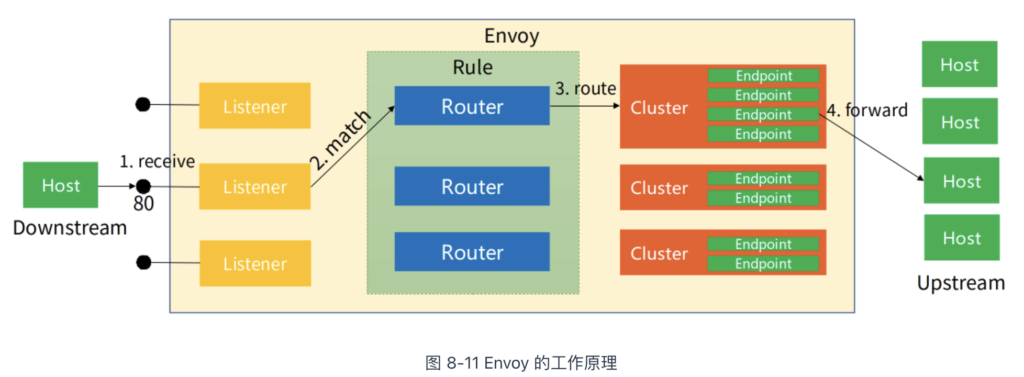
具体到每个 xDS 协议都包含大量的内容,笔者无法一一详述。但通过这些协议操作的资源,再结合图 8-11 理解,可大致说清楚它们的工作原理。
- Listener:Listener 可以理解为 Envoy 打开的一个监听端口,用于接收来自 Downstream(下游服务,即客户端)连接。每个 Listener 配置中核心包括监听地址、插件(Filter)等。Envoy 支持多个 Listener,不同 Listener 之间几乎所有的配置都是隔离的。Listener 对应发现服务称之为 LDS。LDS 是 Envoy 正常工作的基础,没有 LDS,Envoy 就不能实现端口监听,其他所有 xDS 服务也失去了作用。
- Cluster:在 Envoy 中,每个 Upstream(上游服务,即业务后端,具体到 Kubernetes,则对应某个 Service)被抽象成一个 Cluster。Cluster 包含该服务的连接池、超时时间端口、类型等等。Cluster 对应的发现服务称之为 CDS。一般情况下,CDS 服务会将其发现的所有可访问服务全量推送给 Envoy。与 CDS 紧密相关的另一种服务称之为 EDS。CDS 服务负责 Cluster 资源的推送。当该 Cluster 类型为 EDS 时,说明该 Cluster 的所有 endpoints 需要由 xDS 服务下发,而不使用 DNS 等去解析。下发 endpoints 的服务就称之为 EDS;
- Router:Listener 接收来自下游的连接,Cluster 将流量发送给具体的上游服务,而 Router 定义了数据分发的规则,决定 Listener 在接收到下游连接和数据之后,应该将数据交给哪一个 Cluster 处理。虽然说 Router 大部分时候都可以默认理解为 HTTP 路由,但是 Envoy 支持多种协议,如 Dubbo、Redis 等,所以此处 Router 泛指所有用于桥接 Listener 和后端服务(不限定 HTTP)的规则与资源集合。Route 对应的发现服务称之为 RDS。Router 中最核心配置包含匹配规则和目标 Cluster。此外,也可能包含重试、分流、限流等等。
Envoy 的另一项重要设计是其可扩展的 Filter 机制,通俗地讲就是 Envoy 的插件系统。
Envoy 的插件机制允许开发者通过基于 xDS 的数据流管道,插入自定义逻辑,从而扩展和定制 Envoy 的功能。Envoy 的很多核心功能是通过 Filter 实现的。例如,HTTP 流量的处理和服务治理依赖于两个关键插件 HttpConnectionManager(网络 Filter,负责协议解析)和 Router(负责流量分发)。通过 Filter 机制,Envoy 理论上能够支持任意协议,并对请求流量进行全面的修改和定制。
控制平面的设计
本节,笔者继续以 Istio 的架构为例,探讨控制平面的设计。
Istio 自发布首个版本以来,有着一套“堪称优雅”的架构设计,它的架构由数据面和控制面两部分组成,前者通过代理组件 Envoy 负责流量处理;后者根据功能职责不同,由多个微服务(如 Pilot、Galley、Citadel、Mixer)组成。
Istio 控制面组件的拆分设计看似充分体现了微服务架构的优点,如职责分离、独立部署和伸缩能力,但在实际场景中,并未实现预期的效果。
Isito 控制平面的问题
当业务调用出现异常时,由于接入了服务网格,工程师首先需要排查控制面内各个组件的健康状态:首先检查 Pilot 是否正常工作,配置是否正确下发至 Sidecar;然后检查 Galley 是否正常同步服务实例信息;同时,还需要确认 Sidecar 是否成功注入。
一方面,控制面组件的数量越多,排查问题时需要检查的故障点也就越多。另一方面,过多的组件设计也会增加部署、维护的复杂性。
服务网格被誉为下一代微服务架构,用来解决微服务间的运维管理问题。但在服务网格的设计过程中,又引入了一套新的微服务架构,这岂不是用一种微服务架构设计的系统来解决另一种微服务架构的治理问题。那么,谁来解决 Istio 系统本身的微服务架构问题呢?
在 Istio 推出三年后,即 Istio 1.5 版本,开发团队对控制面架构进行了重大调整,摒弃了之前的设计,转而采用了“复古”的单体架构。组件 istiod 整合了 Pilot、Citadel 和 Galley 的功能,以单个二进制文件的形式部署,承担起之前组件的所有职责:
- 服务发现与配置分发:从 Kubernetes 等平台获取服务信息,将路由规则和策略转换为 xDS 协议下发至 Envoy 代理;
- 流量管理:管理流量路由规则,包括负载均衡、分流、镜像、熔断、超时与重试等功能;
- 安全管理:生成、分发和轮换服务间的身份认证证书,确保双向 TLS 加密通信、基于角色的访问控制(RBAC)和细粒度的授权策略,限制服务间的访问权限;
- 可观测性支持:协助 Envoy 采集系统输出的遥测数据(日志、指标、追踪),并将数据发送到外部监控系统(如 Prometheus、Jaeger、OpenTelemetry 等);
- 配置验证与管理:验证用户提交的网格配置,并将其分发到数据平面,确保一致性和正确性;
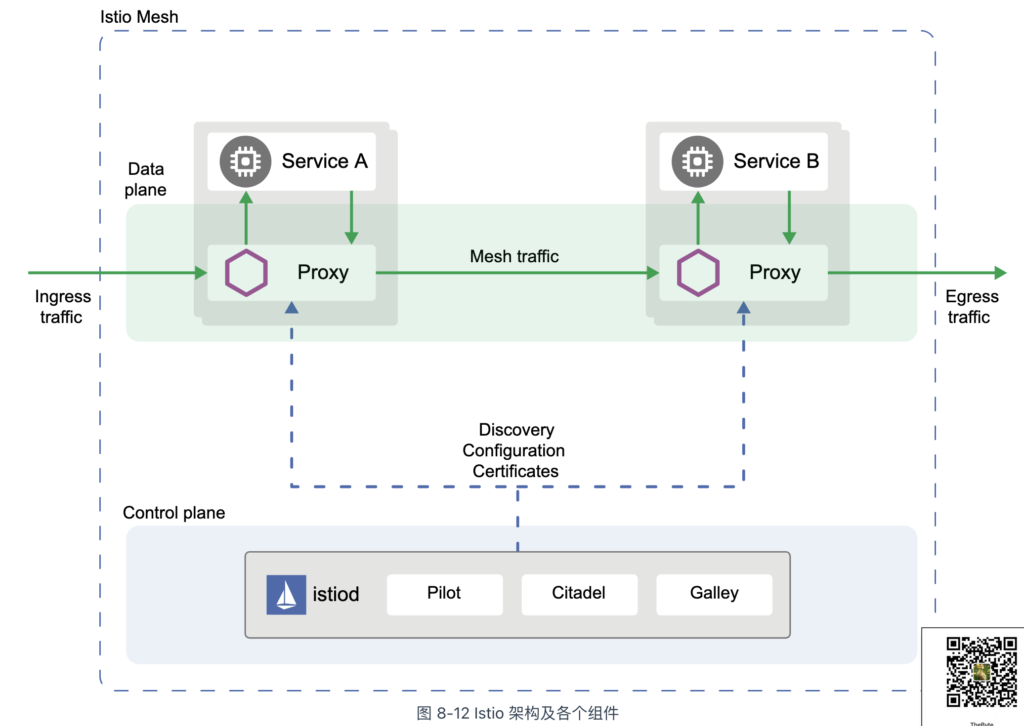
Istio 1.5 版本的架构变化,实际上是将原有的多进程设计转换为单进程模式,以最小的成本实现最高的运维收益。
- 运维配置变得更加简单,用户只需要部署或升级一个单独的服务组件。
- 更加容易排查错误,因为不需要再横跨多个组件去排查各种错误。
- 更加利于做灰度发布,因为是单一组件,可以非常灵活切换至不同的控制面。
- 避免了组件间的网络开销,因为组件内部可直接共享缓存、配置等,也会降低资源开销。
通过以上分析,你是否对 Istio 控制平面的拆分架构有了新的理解?看似优雅的架构设计,落地过程中往往给工程师带来意料之外的困难。正如一句老话,没有完美的架构,只有最合适的架构!
服务网格的产品与生态
2016 年,Buoyant 公司发布了 Linkerd。Matt Klein 离开 Twitter 并加入 Lyft,启动了 Envoy 项目。第一代服务网格稳步发展时,世界另一角落,Google 和 IBM 两个巨头联手,与 Lyft 一起启动了第二代服务网格 Istio。
- 以 Linkerd 为代表的第一代服务网格,通过边车代理控制微服务间的流量;
- 以 Istio 为代表的第二代服务网格,新增控制平面,管理了所有边车代理。于是,Istio 对微服务系统掌握了前所未有的控制力。
依托行业巨头的背书与创新的控制平面设计理念,让 Istio 得到极大关注和发展,并迅速成为业界落地服务网格的主流选择。
Linkerd2 出击
在 Istio 受到广泛追捧的同时,服务网格概念的创造者 William Morgan 自然不甘心出局。William Morgan 瞄准 Istio 的缺陷(过于复杂)、借鉴 Istio 的设计理念(新增控制平面),开始重新设计他们的服务网格产品。
Buoyant 公司的第二代服务网格使用 Rust 构建数据平面 linkerd2-proxy ,使用 Go 开发了控制平面 Conduit,主打轻量化,目标是世界上最轻、最简单、最安全的 Kubernetes 专用服务网格。该产品最初以 Conduit 命名,Conduit 加入 CNCF 后不久,宣布与原有的 Linkerd 项目合并,被重新命名为 Linkerd 2[1]。
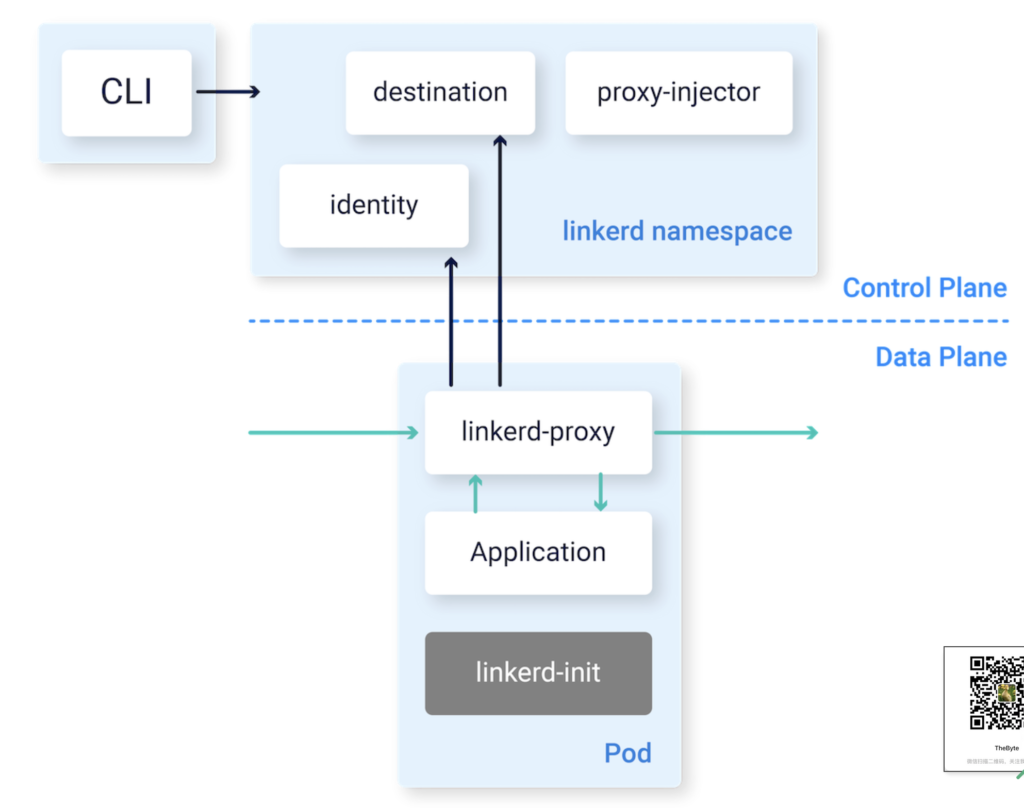
Linkerd2 的架构如图 8-13 所示,增加了控制平面,但整体相对简单:
- 控制层面组件只有 destination(类似 Istio 中的 Pilot 组件)、identity(类似 Istio 中的 Citadel)和 proxy injector(代理注入器);
- 数据平面中 linkerd-init 设置 iptables 规则拦截 Pod 中的 TCP 连接,linkerd-proxy 实现对所有的流量管控(负载均衡、熔断..)。
- 图 Linkerd2 架构及各个组件
其他参与者
能明显影响微服务格局的新兴领域,除了头部的 Linkerd2、Istio 玩家外,又怎少得了传统的 Proxy 玩家。
先是远古玩家 Nginx 祭出自己新一代的产品 Nginx ServiceMesh,理念是简化版的服务网格。接着,F5 Networks 公司顺势推出商业化产品 Aspen Mesh,定位企业级服务网格。随后,API 网关独角兽 Kong 推出了 Kuma,主打通用型服务网格。有意思的是,Kong 选择了 Envoy 作为数据平面,而非它自己内核 OpenResty。
与 William Morgan 死磕 Istio 策略不同,绝大部分在 Proxy 领域根基深厚玩家,从一开始就没有想过做一套完整服务网格,而是选择实现 xDS 协议或基于 Istio 扩展,作为 Istio 的数据平面出现。
至 2023 年,经过 8 年的发展,服务网格的产品生态如图 8-14 所示。虽然有众多的选手,但就社区活跃度而言,Istio 和 Linkerd 还是牢牢占据了头部地位。

Istio 与 Linkerd2 性能对比
2019 年,云原生技术公司 Kinvolk 发布了一份 Linkerd2 与 Istio 的性能对比报告。报告显示,Linkerd 在延迟和资源消耗方面明显优于 Istio[2]。
两年之后,Linkerd 与 Istio 都发布了多个更成熟的版本,两者的性能表现如何?笔者引用 William Morgan 文章《Benchmarking Linkerd and Istio》[3]中的数据,向读者介绍 Linkerd v2.11.1、Istio v1.12.0 两个项目之间延迟与资源消耗的表现。
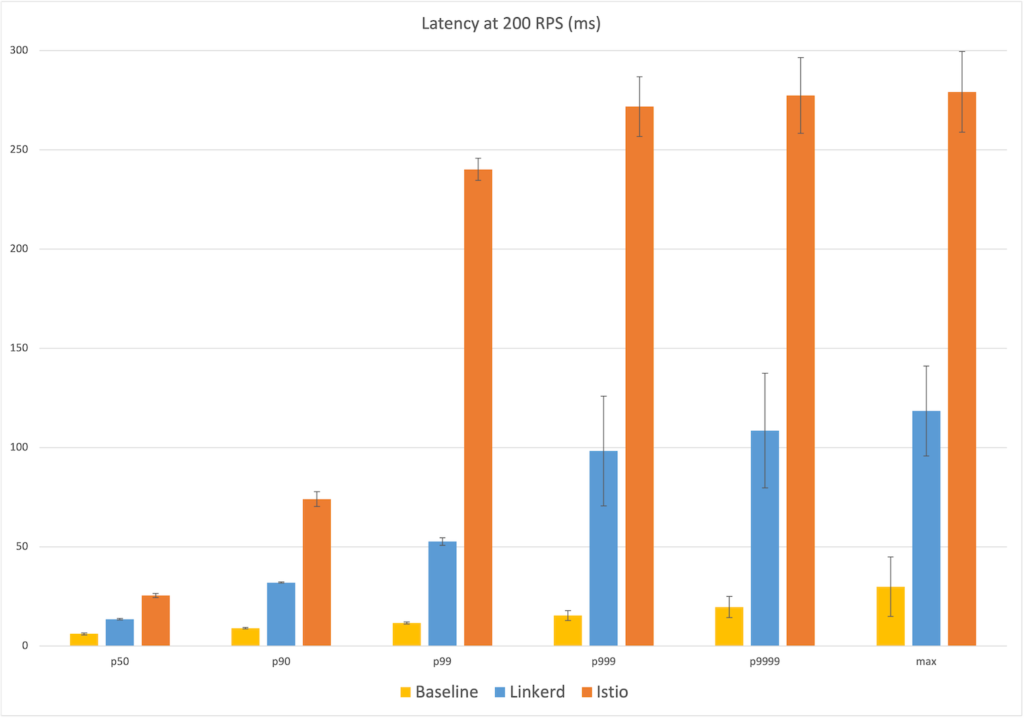
首先是网络延迟的对比。如图 8-15 所示,在中位数(P50)延迟上,Linkerd 在 6ms 的基准延迟基础上增加了 6ms,而 Istio 增加了 15ms。值得注意的是,从 P90 开始,两者的差异明显扩大。在最极端的 Max 数据上,Linkerd 在 25ms 的基准延迟上增加了 25ms,而 Istio 则增加了 5 倍,达到 253ms 的额外延迟。
图 Linkerd 与 Istio 的延迟对比
接下来是资源消耗的对比。如图 8-16 所示,Linkerd 代理的最大内存消耗为 26MB,而 Istio 的 Envoy 代理则为 156.2MB,是 Linkerd 的 6 倍。此外,Linkerd 的最大代理 CPU 时间为 36ms,而 Istio 的代理 CPU 时间为 67ms,比前者多出 85%。
图 Istio 与 Linkerd 资源消耗对比
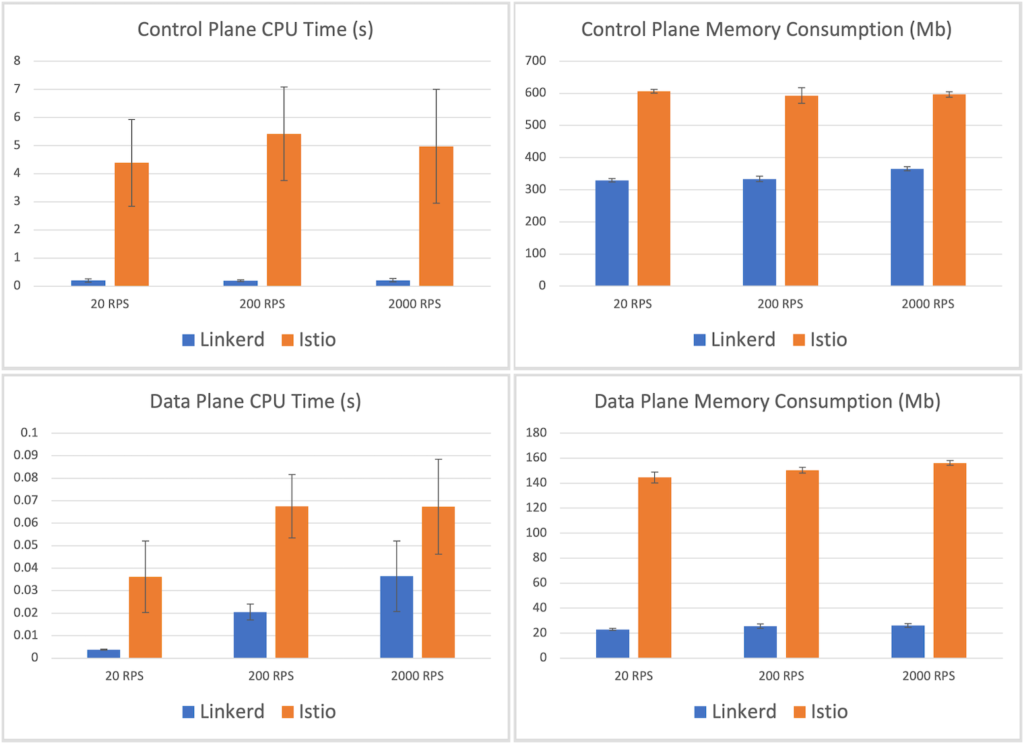
Linkerd 和 Istio 在性能和资源成本上的显著差异,要归因于 Linkerd2-proxy,该代理为 Linkerd 的整个数据平面提供动力。因此。上述基准测试很大程度上反映了 Linkerd2-proxy 与 Envoy 之间的性能和资源消耗对比。
虽然 Linkerd2-proxy 性能卓越,但使用的编程语言 Rust 相对小众,开源社区的贡献者数量稀少。截至 2024 年 6 月,Linkerd2-proxy 的贡献者仅有 53 人,而 Envoy 的贡献者则高达 1,104 人。此外,Linkerd2-proxy 不支持服务网格领域的 xDS 控制协议,其未来发展将高度依赖于 Linkerd 本身的进展。
服务网格的未来
随着服务网格的逐步落地,边车代理的缺点也逐渐显现:
- 网络延迟问题:服务网格通过 iptables 拦截服务间的请求,将原本的 A->B 通信改为 A->(iptables+Sidecar)-> (iptables+Sidecar)->B,调用链的增加导致了额外的性能损耗。尽管边车代理通常只会增加毫秒级(个位数)的延迟,但对性能要求极高的业务来说,额外的延迟是放弃服务网格的主要原因;
- 资源占用问题:边车代理作为一个独立的容器必然占用一定的系统资源,对于超大规模集群(如有数万个 Pod)来说,巨大的基数使边车代理占用资源总量变得相当可观。
为了解决上述问题,开发者们开始思考:“是否应该将服务网格与边车代理划等号?”,并开始探索服务网格形态上的其他可能性。
Proxyless 模式
既然问题出自代理,那就把代理去掉,这就是 Proxyless(无代理)模式。
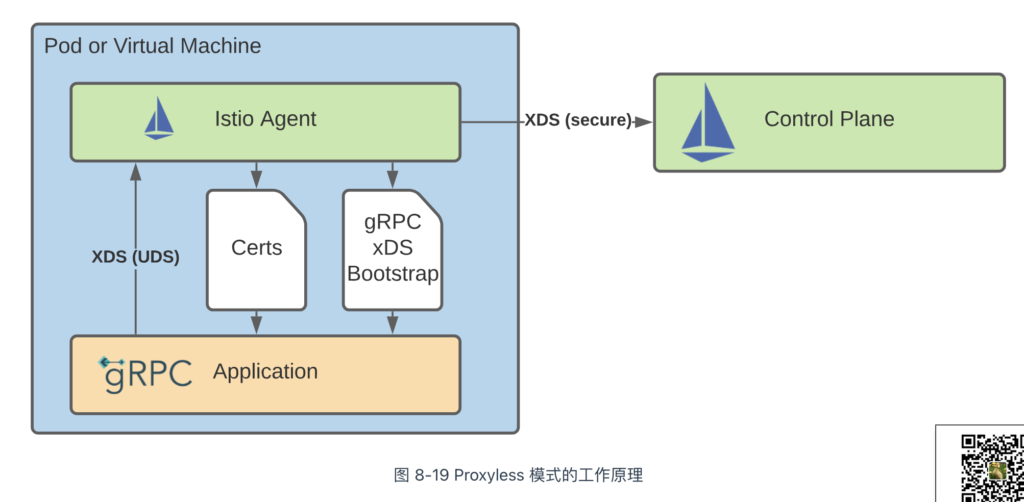
Proxyless 模式的思想是,服务间通信总依赖某种协议,那么将协议的实现(SDK)扩展,增加通信治理能力,不就能代替边车代理了吗?且 SDK 和应用封装在一起,不仅有更优异的性能,还能彻底解决边车代理引发的延迟问题。
2021 年,Istio 发表文章《基于 gRPC 的无代理服务网格》[1],介绍了一种基于 gRPC 实现的 Proxyless 模式的服务网格。它的工作原理如图 8-19 所示,服务间通信治理不再依赖边车代理,而是采用原始的方式在 gRPC SDK 中实现。此外,该模式额外需要一个代理(Istio Agent)与控制平面(Control Plane)交互,告知 gRPC SDK 如何连接到 istiod、如何获取证书、处理流量的策略等。
相比边车代理模式,Proxyless 模式在性能、稳定性、资源消耗低等方面具有明显的优势。根据官方公布的性能测试报告来看,该模式的延迟接近“基准”(baseline)、资源消耗也相对较低。
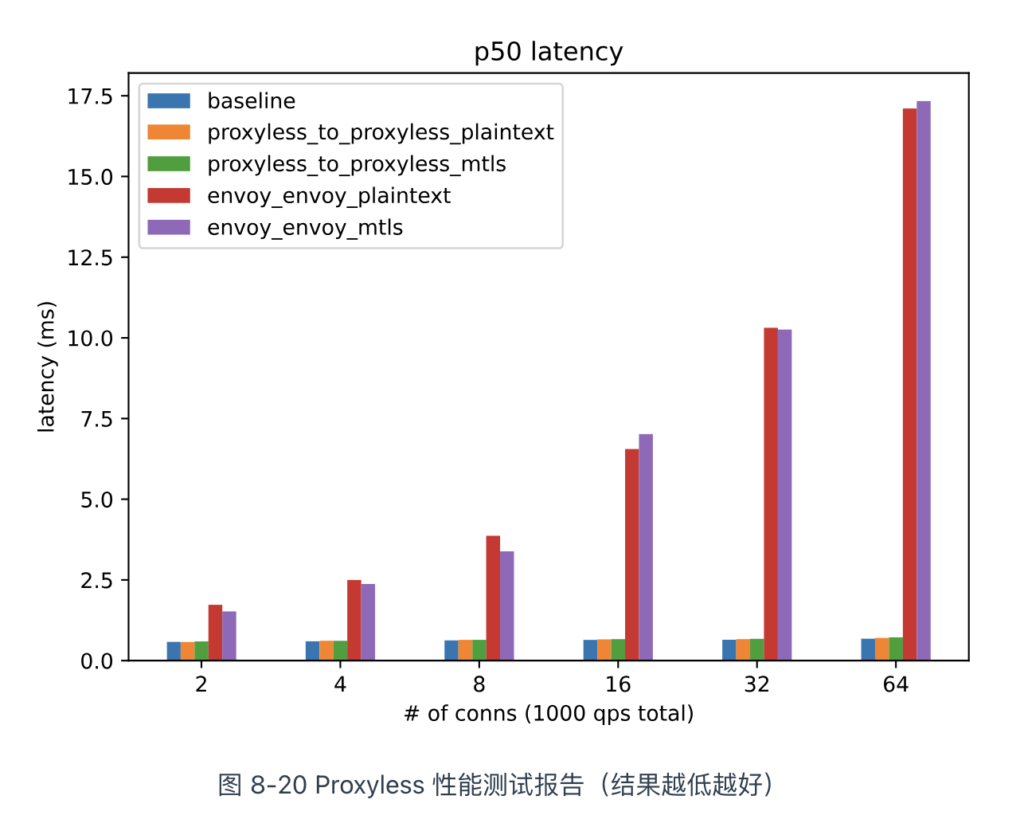
回过头来看,所谓的 Proxyless 模式与传统 SDK 并无本质区别,只是在库中内嵌了通信治理逻辑,也继承了传统 SDK 服务框架的固有缺陷。因此,许多人认为 Proxyless 模式实际上是一种倒退,是以传统方式重新解决服务间通信的问题。
Sidecarless 模式
既然有了 Proxyless 模式,也不妨再多个 Sidecarless 模式(无边车模式)。
2022 年 7 月,专注于容器网络领域的开源软件 Cilium 发布了 v1.12 版本。该版本最大的亮点是实现了一种无边车模式的服务网格。
Cilium 无边车模式的服务网格工作原理如图 8-21 所示。在这种模式下,Cilium 在节点中运行一个共享的 Envoy 实例,作为所有容器的代理,从而避免了每个 Pod 配置独立边车代理的需求。通过 Cilium CNI 提供的底层网络能力,当业务容器的数据包经过内核时,它们与节点中的共享代理进行连接,进而构建出一种全新的服务网格形态。
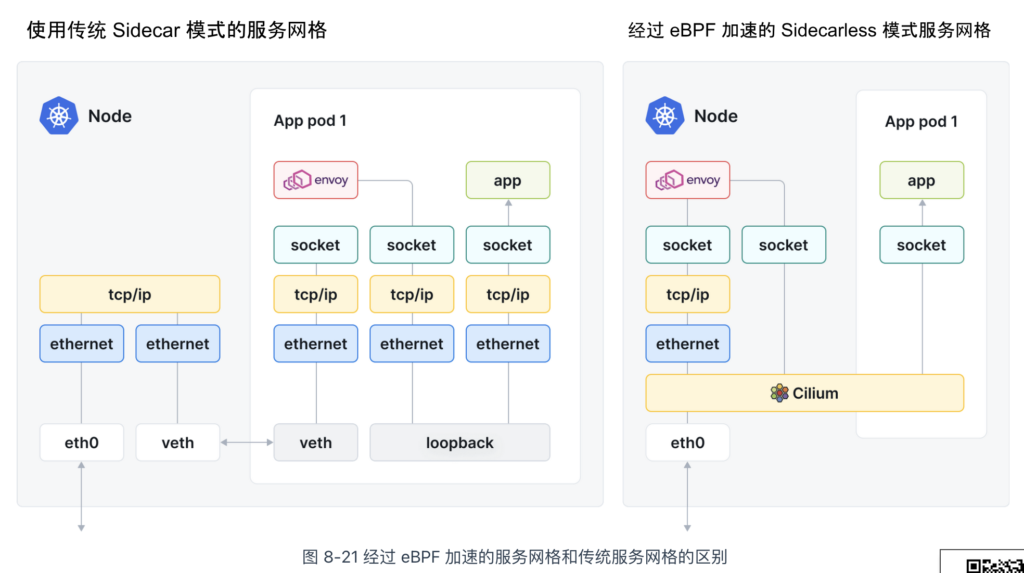
传统的服务网格(如 Linkerd 和 Istio),通常依赖 Linux 内核网络协议栈(如 iptables)来处理请求。而 Cilium 的无边车模式则基于 eBPF 技术在内核层面进行扩展,从而实现了天然的网络加速效果。如图 8-22 所示,基于 eBPF 加速的 Envoy 在性能上明显优于使用 iptables 的 Istio。
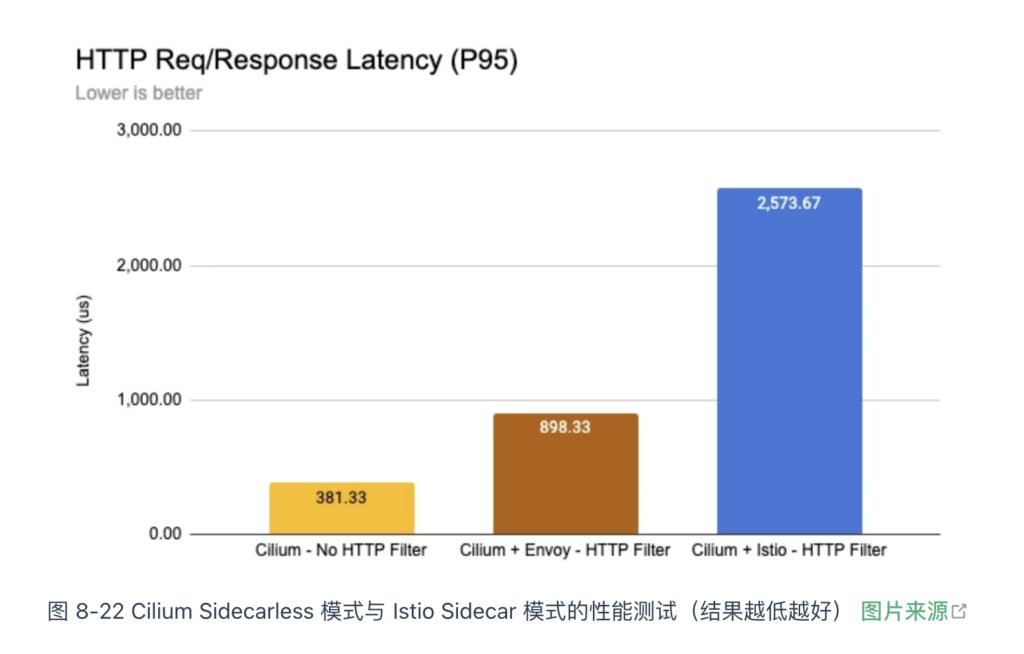
回过头来看,Cilium Sidecarless 模式的设计思路与 Proxyless 模式非常相似,都是通过非边车代理的方式实现流量控制。两者的区别在于:
- Proxyless 基于通信协议库;
- Cilium Sidecarless 则通过共享代理,利用 eBPF 技术在 Linux 内核层面实现。
但同样,软件领域没有银弹,eBPF 不是万能钥匙,它存在 Linux 内核版本要求高、代码编写难度大和容易造成系统安全隐患等问题。
Ambient Mesh 模式
2022 年 9 月,服务网格 Istio 发布了一种全新的数据平面模式 “Ambient Mesh”[2]。
在以往的 Istio 设计中,边车代理实现了从基本加密到高级 L7 策略的所有数据平面功能。这种设计使得边车代理成为一个“全有或全无”的方案,即使服务对传输安全性要求较低,工程师仍需承担部署和维护完整边车代理的额外成本。
Ambient Mesh 的设计理念是,将数据平面分为“安全覆盖层”(ztunnel)和七层处理层(waypoint 代理)。安全覆盖层用于基础通信处理,特点是低资源、高效率。它的功能包括:
- 通信管理:TCP 路由;
- 安全:面向四层的简单授权策略、双向 TLS(即 mTLS);
- 观测:TCP 监控指标及日志。
七层处理层用于高级通信处理,特点是功能丰富(当然也需要更多的资源),它的功能包括:
- 通信管理: HTTP 路由、负载均衡、熔断、限流、故障容错、重试、超时等;
- 安全:面向七层的精细化授权策略;
- 观测:HTTP 监控指标、访问日志、链路追踪;
在数据平面分层解耦的模式下,安全覆盖层的功能被转移至 ztunnel 组件,它以 DaemonSet 形式运行在 Kubernetes 集群的每个节点上。这意味着,ztunnel 是为节点内所有 Pod 提供服务的基础共享组件。另一方面,七层处理层不再以边车模式存在,而是按需为命名空间创建的 Waypoint 组件。Waypoint 组件以 Deployment 形式部署在 Kubernetes 集群中,从 Kubernetes 的角度来看,Waypoint 只是一个普通的 Pod,可以根据负载动态伸缩。业务 Pod 不再需要额外的边车代理即可参与网格,因此 Ambient 模式也被称为“无边车网格”。
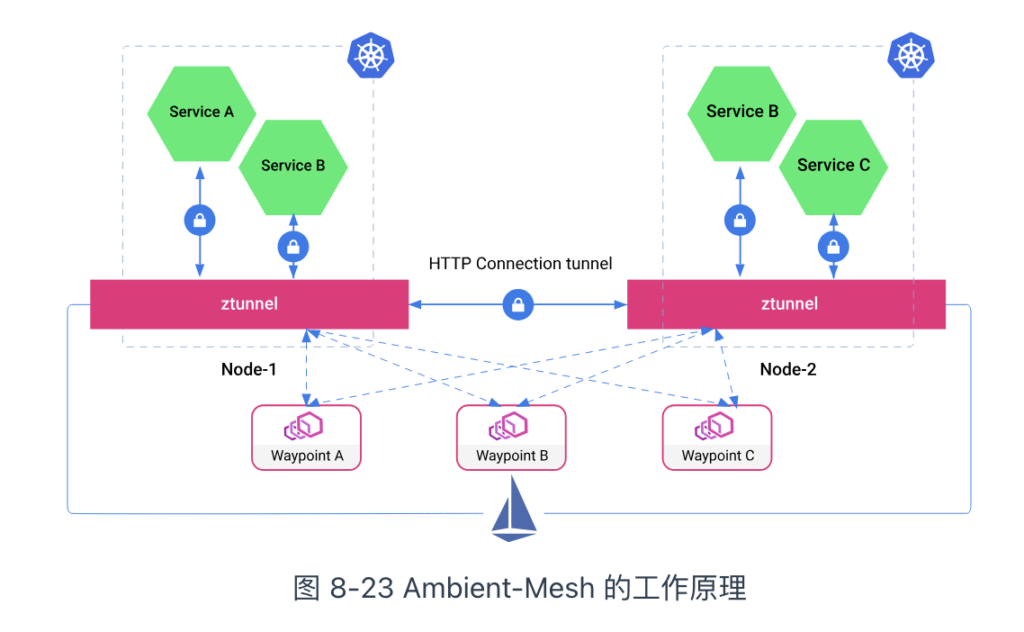
Ambient 分层模式允许你以逐步递进的方式采用 Istio,你可以按需从无网格平滑过渡到安全的 L4 覆盖,再到完整的 L7 处理和策略。根据 Istio 公开的信息,Istio 一直在推进 Ambient Mesh 的开发,并在 2023 年 2 月将其合并到了 Istio 的主分支。这个举措在一定程度上表明,Ambient Mesh 并非实验性质的“玩具”,而是 Istio 未来发展的重要方向之一。
最后,无论是 Sidecarless 还是 Ambient Mesh,它们本质上都是通过中心化代理替代位于业务容器旁边的代理容器。这在一定程度上解决了传统边车代理模式带来的资源消耗、网络延迟问题。但它们的缺陷也无法回避,服务网格的设计理念本来就很抽象,引入 Proxyless、Sidecarless、Ambient Mesh 等模式,进一步加剧了服务网格的复杂性和理解难度。
小结
在本章第二节,我们回顾了服务间通信的演变,并阐述了服务网格出现的背景。相信你已经理解,服务网格之所以备受推崇,关键不在于它提供了多少功能(这些功能传统 SDK 框架也有),而在于其将非业务逻辑从应用程序中剥离的设计思想。
从最初 TCP/IP 协议的出现,我们看到网络传输相关的逻辑从应用层剥离,下沉至操作系统,成为操作系统的网络层。分布式系统的崛起,又带来了特有的分布式通信语义(服务发现、负载均衡、限流、熔断、加密…)。为了降低治理分布式通信的心智负担,面向微服务的 SDK 框架出现了,但这类框架与业务逻辑耦合在一起,带来门槛高、无法跨语言、升级困难三个固有问题。
而服务网格的出现为分布式通信治理带来了全新的解决思路:通信治理逻辑从应用程序内部剥离至边车代理,下沉至 Kubernetes、下沉至各个云平台。沿着上述“分离/下沉”的设计理念,服务网格的形态不再局限于边车代理,开始多元化,陆续出现了 Proxyless、Sidecarless、Ambient Mesh 等多种模式。
无论通信治理逻辑下沉至哪里、服务网格以何种形态存在,核心都是把非业务逻辑从应用程序中剥离,让业务开发更简单。这正是业内常提到的“以应用为中心”设计理念的体现。