转载:https://www.thebyte.com.cn/Observability/summary.html
given enough eyeballs, all bugs are shallow.
足够多的眼睛,就可让所有问题浮现。
随着系统规模扩大、组件复杂化以及服务间依赖关系的增加,确保系统稳定性已超出绝大多数 IT 团队的能力极限。
复杂性失控问题在工业领域同样出现过。19 世纪末起,电气工程的细分领域迅速发展,尤其是 20 世纪 50 年代的航空领域,研发效率要求越来越高、运行环境越来越多样化,系统日益复杂对稳定性提出了巨大挑战。在这一背景下,匈牙利裔工程师 Rudolf Emil Kálmán 提出了“可观测性”概念,其理念的核心是“通过分析系统向外部输出的信号,判断工作状态并定位缺陷的根因”。
借鉴电气系统的观测理念,我们也可以通过系统输出各类信息,实现软件系统的可观测。2018 年,CNCF 率先将“可观测性”概念引入 IT 领域,强调它是云原生时代软件的必备能力!从生产所需到概念发声,加之 Google 在内的众多大厂一拥而上,“可观测性”逐渐取代“监控”,成为云原生领域最热门的话题之一。
什么是可观测性
什么是可观测性?观测的又是什么?
Google Cloud 在介绍可观测标准项目 OpenTelemetry 时提到一个概念 —— “遥测数据”(telemetry data)[1]。
遥测数据
遥测数据(telemetry data)是指采样和汇总有关软件系统性能和行为的数据,这些数据(接口的响应时间、请求错误率、服务资源消耗等)用于监控和了解系统的当前状态。
“遥测数据”看起来陌生,但你肯定无意间听过。观看火箭发射的直播时,你应该听到过类似的指令:“东风光学 USB 雷达跟踪正常,遥测信号正常” 。随着火箭升空,直播画面还会特意切换到一个看起来“高大上”仪表控制台。
实际上,软件领域的观测与上述火箭发射系统相似,都是通过全面收集系统运行数据(遥测数据),以了解内部状态。所以说,可观测性是指系统的内部状态能够通过外部输出(如日志、指标、追踪等)来进行观察和理解的能力。换句话说,系统的可观测性使得我们能够从系统的外部获取足够的信息,以便分析和解决可能存在的问题,预测系统行为,或者优化系统性能。
可观测性与传统监控
了解什么是可观测性后,接踵而来的问题是,它与传统监控有何区别?业内专家 Baron Schwartz 曾用一句简洁的话总结了两者的关系,不妨来看他的解释。
可观测性与监控的关系
监控告诉我们系统哪些部分是正常的,可观测性告诉我们系统为什么不正常了。
——by《高性能 MySQL》作者 Baron Schwartz
如图 9-1,我们把系统的理解程度、可收集信息之间的关系象限化分析,说明可观测性与传统监控的区别。

X 轴的右侧(Known Knows 和 Known Unknowns)表示确定性的已知和未知,图中给出了相应的例子。这类信息通常是系统上线前就能预见,并能够监控的基础性、普适性事实(如 CPU Load、内存、TPS、QPS 等指标)。传统的监控系统大部分围绕这些确定的因素展开。
但是很多情况下,上述信息很难全面描述和衡量系统的状态。比如坐标的左上角的 Unknown Knowns(未知的已知,通俗理解为假设),举个例子,通常会引入限流策略来保证服务可用性。假设请求量突然异常暴增,限流策略牺牲小部分用户、保证绝大部分用户的体验。但注意,这里的“假设”(请求量突然暴增)并未实际发生。因此,平常情况下的监控看不出任何异常。
但如果请求量突然暴增了,同时那些“假设”又未经过验证(如限流逻辑写错了),就会导致我们碰见最不愿见到的情况 —— Unknown Unknowns(未知的未知,毫无征兆且难以理解)。
经验丰富(翻了无数次车)的工程师根据以往经验,逐步缩小 Unknown Unknowns 的排查范围,从而缩短故障修复时间。但更合理的做法是,根据系统的细微输出(如 metrics、logs、traces,也就是遥测数据),以低门槛且直观的方式(如监控大盘、链路追踪拓扑等)描绘出系统的全面状态。如此,当发生 Unknown Unkowns 情况时,才能具象化的一步步定位到问题的根因。
遥测数据的分类与处理
业界将系统输出的数据总结为三种独立的类型,它们的含义与区别如下:
- 指标(metric):量化系统性能和状态的“数据点”,每个数据点包含度量对象(如接口请求数)、度量值(如 100 次/秒)和发生的时间,多个时间上连续的数据点便可以分析系统性能的趋势和变化规律。指标是发现问题的起点,例如你半夜收到一条告警:“12 点 22 分,接口请求成功率下降到 10%”,这表明系统出现了问题。接着,你挣扎起床,分析链路追踪和日志数据,找到问题的根本原因并进行修复。
- 日志(log):系统运行过程中,记录离散事件的文本数据。每条日志详细描述了事件操作对象、操作结果、操作时间等信息。例如下面的日志示例,包含了时间、日志级别(ERROR)以及事件描述。
[2024-12-27 14:35:22] ERROR: Failed to connect to database. Retry attempts exceeded.
日志为问题诊断提供了精准的上下文信息,与指标形成互补。当系统故障时,“指标”告诉你应用程序出现了问题,“日志”则解释了问题出现的原因。
- 链路追踪(trace):记录请求在多个服务之间的“调用链路”(Trace),以“追踪树”(Trace Tree)的形式呈现请求的“调用”(span)、耗时分布等信息。
// 追踪树
Trace ID: 12345
└── Span ID: 1 - API Gateway (Duration: 50ms)
└── Span ID: 2 - User Service (Duration: 30ms)
└── Span ID: 3 - Database Service (Duration: 20ms)
上述 3 类数据各自侧重不同,但并非孤立存在,它们之间有着天然的交集与互补。比如指标监控(告警)帮助发现问题,日志和链路追踪则帮助定位根本原因。这三者之间的关系如图 9-2 的韦恩图所示。
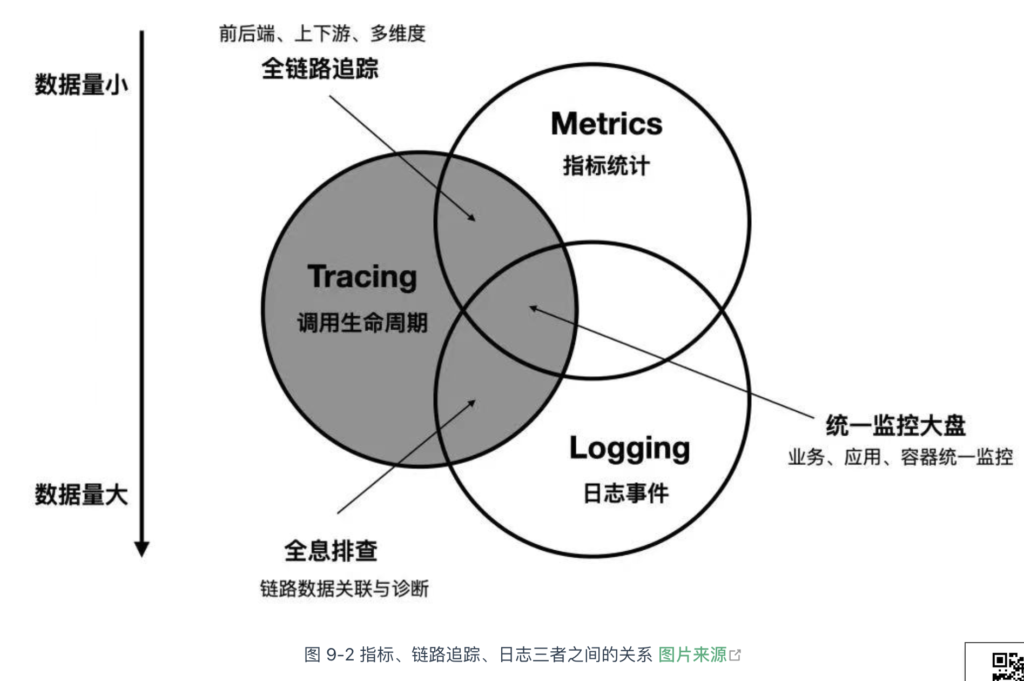
2021 年,CNCF 发布了可观测性白皮书[1],里面新增了性能剖析(Profiling)和核心转储(Core dump)2 种数据类型。接下来,笔者将详细介绍这 5 类遥测数据的采集、存储和分析原理。
指标的处理
提到指标,就不得不提 Prometheus 系统。Prometheus 是继 Kubernetes 之后,云原生计算基金会(CNCF)的第二个正式项目。该项目发展至今,已成为云原生系统中处理指标监控的事实标准。
额外知识
有趣的是,像 Kubernetes 一样,Prometheus 也源自 Google 的 Borg 体系,其原型是与 Borg 同期诞生的内部监控系统 BorgMon。Prometheus 的发起原因与 Kubernetes 类似,都是希望以更好的方式将 Google 内部系统的设计理念传递给外部开发者。
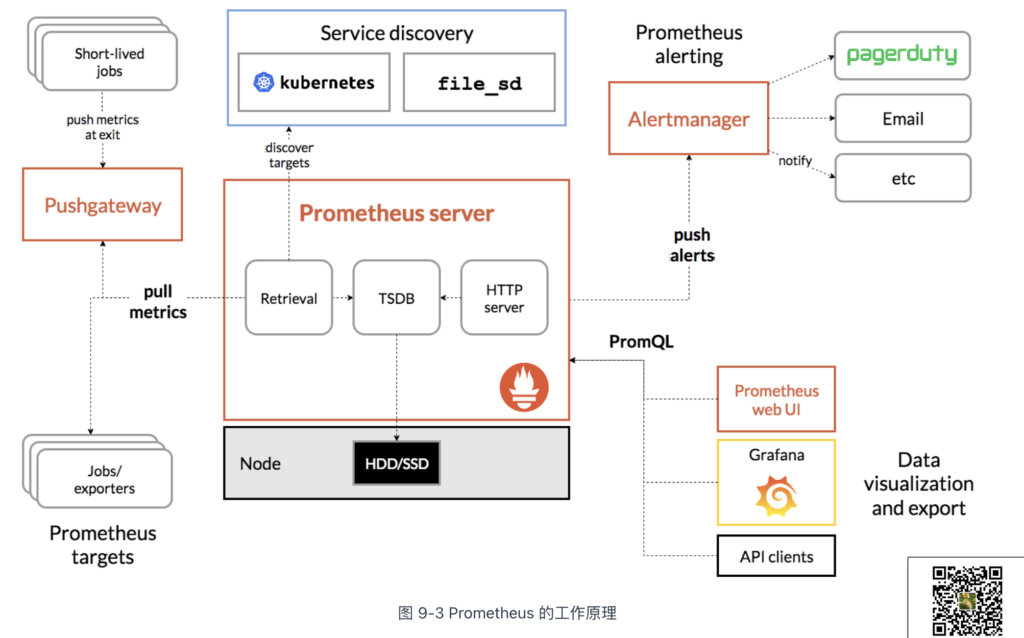
作为监控系统,Prometheus 的基本原理如图 9-3 所示,通过 pull(拉取)方式收集被监控对象的指标数据,并将其存储在 TSDB(时序数据库)中。其他组件(如 Grafana 和 Alertmanager)配合这一机制,实现指标数据可视化和预警功能。
定义指标的类型
为便于理解和使用不同类型的指标,Prometheus 定义了四种指标类型:
- 计数器(Counter):一种只增不减的指标类型,用于记录特定事件的发生次数。常用于统计请求次数、任务完成数量、错误发生次数等。在监控 Web 服务器时,可以使用 Counter 来记录 HTTP 请求的总数,通过观察这个指标的增长趋势,能了解系统的负载情况;
- 仪表盘(Gauge):一种可以任意变化的指标,用于表示某个时刻的瞬时值。常用于监控系统的当前状态,如内存使用量、CPU 利用率、当前在线用户数等;
- 直方图(Histogram):用于统计数据在不同区间的分布情况。它会将数据划分到多个预定义的桶(bucket)中,记录每个桶内数据的数量。常用于分析请求延迟、响应时间、数据大小等分布情况。比如监控服务响应时间时,Histogram 可以将响应时间划分到不同的桶中,如 0-100ms、100-200ms 等,通过观察各个桶中的数据分布,能快速定位响应时间的集中区间和异常情况;
- 摘要(Summary):和直方图类似,摘要也是用于统计数据的分布情况,但与直方图不同的是,Summary 不能提供数据在各个具体区间的详细分布情况,更侧重于单一实例(例如单个服务实例)的数据进行计算。

使用 Exporter 收集指标
收集指标看似简单,但实际上复杂得多:首先,应用程序、操作系统和硬件设备的指标获取方式各不相同;其次,它们通常不会以 Prometheus 格式直接暴露。例如:
- Linux 的许多指标信息存储在 /proc 目录下,如 /proc/meminfo 提供内存信息,/proc/stat 提供 CPU 信息;
- Redis 的监控数据通过执行 INFO 命令获取;
- 路由器等硬件设备的监控数据通常通过 SNMP 协议获取。
为了解决上述问题,Prometheus 设计了 Exporter 作为监控系统与被监控目标之间的“中介”,负责将不同来源的监控数据转换为 Prometheus 支持的格式。
Exporter 可以作为独立服务运行,也可以与应用程序共享同一进程,只需集成 Prometheus 客户端库即可。Exporter 通过 HTTP 协议返回符合 Prometheus 格式的文本数据,Prometheus 服务端会定期拉取这些数据。以下是一个 Exporter 示例,它返回名为 http_request_total 的 Counter 类型指标。
$ curl http://127.0.0.1:8080/metrics | grep http_request_total # HELP http_request_total The total number of processed http requests # TYPE http_request_total counter // 指标类型 类型为 Counter http_request_total 5
得益于 Prometheus 良好的社区生态,现在已有大量用于不同场景的 Exporter,涵盖了基础设施、中间件和网络等各个领域。如表 9-1 所示,这些 Exporter 扩展了 Prometheus 的监控范围,几乎覆盖了用户关心的所有监控目标。
表 常用的 Exporter
| 范围 | 常用 Exporter |
|---|---|
| 数据库 | MySQL Exporter、Redis Exporter、MongoDB Exporter、MSSQL Exporter 等 |
| 硬件 | Apcupsd Exporter、IoT Edison Exporter、IPMI Exporter、Node Exporter 等 |
| 消息队列 | Beanstalkd Exporter、Kafka Exporter、NSQ Exporter、RabbitMQ Exporter 等 |
| 存储 | Ceph Exporter、Gluster Exporter、HDFS Exporter、ScaleIO Exporter 等 |
| HTTP 服务 | Apache Exporter、HAProxy Exporter、Nginx Exporter 等 |
| API 服务 | AWS ECS Exporter、Docker Cloud Exporter、Docker Hub Exporter、GitHub Exporter 等 |
| 日志 | Fluentd Exporter、Grok Exporter 等 |
| 监控系统 | Collectd Exporter、Graphite Exporter、InfluxDB Exporter、Nagios Exporter、SNMP Exporter 等 |
| 其它 | Blockbox Exporter、JIRA Exporter、Jenkins Exporter、Confluence Exporter 等 |
使用时序数据库存储指标
存储数据本来是一项常规操作,但当面对存储指标类型的场景来说,必须换一种思路应对。
举一个例子,假设你负责管理一个小型集群,该集群有 10 个节点,运行着 30 个微服务系统。每个节点需要采集 CPU、内存、磁盘和网络等资源使用情况,而每个服务则需要采集业务相关和中间件相关的指标。假设这些加起来一共有 20 个指标,且按每 5 秒采集一次。那么,一天的数据规模将是:
10(节点)* 30(服务)* 20 (指标) * (86400/5) (秒) = 103,680,000(记录)
对于一个仅有 10 个节点的小规模业务来说,7*24 小时不间断生成的数据可能超过上亿条记录,占用 TB 级别的存储空间。虽然传统数据库也可以处理时序数据,但它们并未充分利用时序数据的特点。因此,使用这些数据库往往需要不断增加计算和存储资源,导致系统的运维成本急剧上升。
通过下面的例子,我们来分析指标数据的特征。可以发现,指标数据是纯数字型的、具有时间属性、旨在揭示某些事件的趋势和规律,它们不涉及关系嵌套、主键/外键,也不需要考虑事务处理。
{
"metric": "http_requests_total", // 指标名称,表示 HTTP 请求的总数
"labels": { // 标签,用于描述该指标的不同维度
"method": "GET", // HTTP 请求方法
"handler": "/api/v1/users", // 请求的处理端点
"status": "200", // HTTP 响应状态码
},
"value": 1458, // 该维度下的请求数量
},
针对时序数据特点,业界已发展出专门优化的数据库类型 —— 时序数据库(Time-Series Database,简称 TSDB)。与常规数据库(如关系型数据库或 NoSQL 数据库)相比,时序数据库在设计和用途上存在显著差异,比如:
- 数据结构: 时序数据库一般采用 LSM-Tree,这是一种专为写密集型场景设计的存储结构,其原理是将数据先写入内存,待积累一定量后批量合并并写入磁盘。因此,时序数据库在写入吞吐量方面,通常优于常规数据库(基于 B+Tree);
- 数据保留策略:时序数据具有明确的生命周期(监控数据只需要保留几天)。为防止存储空间无限膨胀,时序数据库通常支持自动化的数据保留策略。比如设置基于时间的保留规则,超过 7 天就会自动删除。
Prometheus 服务端内置了强大的时序数据库(与 Prometheus 同名),“强大”并非空洞的描述,它在 DB-Engines 排行榜中常年稳居前三[1]。该数据库提供了专为时序数据设计的查询语言 PromQL(Prometheus Query Language),可轻松实现指标的查询、聚合、过滤和计算等操作。掌握 PromQL 语法是指标可视化和告警处理的基础,笔者就不再详细介绍其语法细节了,具体可以参考 Prometheus 文档。
指标的图形化和预警
采集和存储指标的最终目的是分析数据的趋势变化,预测业务需求(图形化),以及持续监控数据波动变化,及时发现问题(预警)。
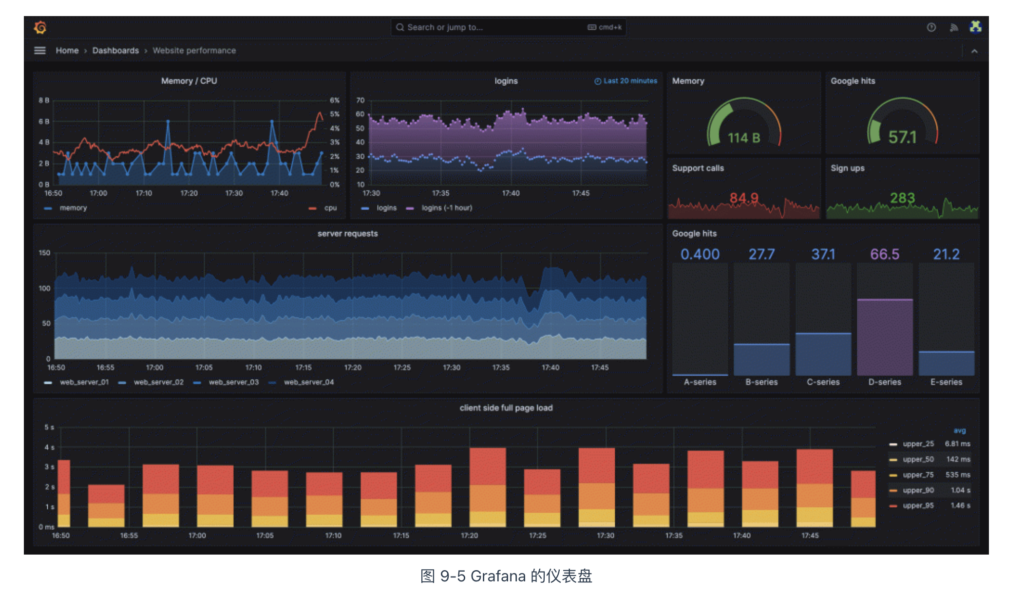
Prometheus 提供了基本的展示功能,但其图形界面相对简单,许多用户会将 Prometheus 与 Grafana 配合使用(这也是 Prometheus 官方推荐的组合方案)。图 9-5 展示了一个 Grafana 仪表板(Dashboard)。将指标数据可视化,能够更方便地从中发现规律。例如,趋势分析可以帮助判断服务 QPS 的增长趋势,从而预测何时需要扩容;对照分析则能对比新旧版本的 CPU、内存等资源消耗,评估性能差异;在故障分析方面,服务性能的波动、瓶颈或潜在问题也更加容易识别。
除了图形化展示外,指标的另一个主要用途是预警。例如,当某个服务的 QPS 超过设定的阈值时,系统自动发送一封邮件通知工程师及时处理,这就是一种预警。Prometheus 提供了专门的 Alertmanager 组件,用来管理和通知 Prometheus 生成的预警信息。
如下面的例子所示,Prometheus 根据预设的条件定期检查数据,一旦满足预警条件,Prometheus 触发预警并将其发送到 Alertmanager。
// 定期使用 PromQL 语法检查过去 5 分钟内,某个被监控目标(instance)中指定服务(job)的 QPS 是否超过 1000。
groups:
- name: example-alerts
rules:
- alert: HighQPS
expr: sum(rate(http_requests_total[5m])) by (instance, job) > 1000
for: 5m
labels:
severity: critical
annotations:
summary: "High QPS detected on instance {{ $labels.instance }}"
description: "Instance {{ $labels.instance }} (job {{ $labels.job }}) has had a QPS greater than 1000 for more than 5 minutes."
Alertmanager 接收到预警后,根据配置对预警进行分组(将相似标签的预警合并)、抑制(防止预警风暴发生)、静默(在维护期间,屏蔽预警)和路由(发送到短信、邮件、微信)处理。
日志的索引与存储
处理日志本来是件稀松平常的事情,但随着数据规模的增长,量变引发质变,高吞吐写入(GB/s)、低成本海量存储(PB 级别)以及亿级数据的实时检索(1 秒内),已成为软件工程领域最具挑战性的难题之一。
本节将从日志索引和存储的角度出发,介绍三种业内应对海量数据挑战的方案。
全文索引 Elastic Stack
在讨论如何构建完整的日志系统时,ELK、ELKB 或 Elastic Stack 是工程师们非常熟悉的术语。它们实际上指的是同一套由 Elastic 公司[1]开发的开源工具,旨在处理海量数据的收集、搜索、分析和可视化。
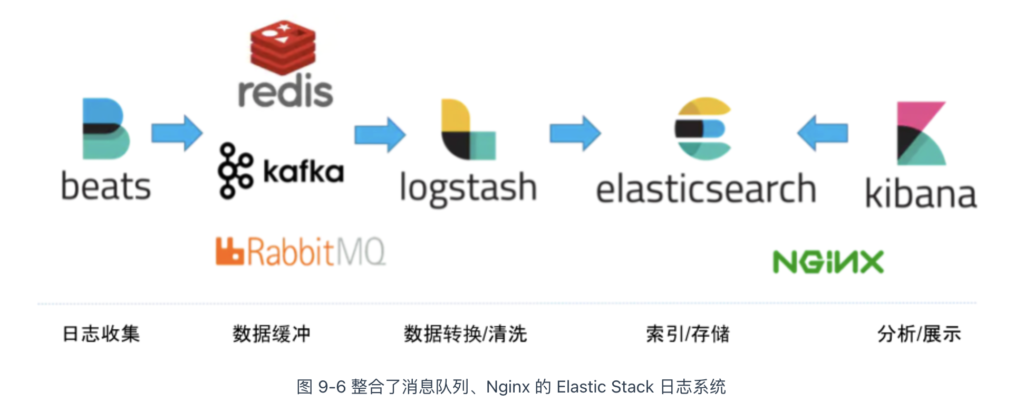
图 9-6 展示了一套基于 Elastic Stack 的日志处理方案:
- 数据收集:Beats 组件部署在业务所在节点,负责收集原始的日志数据;
- 数据缓冲:使用 RabbitMQ 消息队列缓冲数据,提高数据吞吐量;
- 数据清洗:数据通过 Logstash 进行清洗。
- 数据存储:清洗后的数据存储在 Elasticsearch 集群中,它负责索引日志数据、查询聚合等核心功能;
- 数据可视化:Kibana 负责数据检索、分析与可视化,必要时可部署 Nginx 实现访问控制。
Elastic Stack 中最核心的组件是 Elasticsearch —— 基于 Apache Lucene 构建的开源的搜索与分析引擎。值得一提的是,Lucene 的作者就是大名鼎鼎的 Doug Cutting,如果你不知道他是谁是?那你一定听过他儿子玩具的名字 —— Hadoop。
Elasticsearch 能够在海量数据中迅速检索关键词,其关键技术之一就是 Lucene 提供的“反向索引”(Inverted Index)。与反向索引相对的是正向索引,二者的区别如下:
- 正向索引(Forward Index):传统的索引方法,将文档集合中的每个单词作为键,值为包含该单词的文档列表。正向索引适用于快速检索特定标识符的文档,常见于数据库中的主键索引。
- 反向索引(Inverted Index):反向索引通过将文本分割成词条并构建“<词条->文档编号>”的映射,快速定位某个词出现在什么文档中。值得注意的是,反向索引常被译为“倒排索引”,但“倒排”容易让人误以为与排序有关,实际上它与排序无关。
举一个具体的例子,以下是三个待索引的英文句子:
- T0 = “it is what it is”
- T1 = “what is it”
- T2 = “it is a banana”
通过反向索引,得到下面的匹配关系:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
在检索时,条件“what”、“is” 和 “it” 将对应集合:{0,1}∩{0,1,2}∩{0,1,2}={0,1}{0,1}∩{0,1,2}∩{0,1,2}={0,1}。可以看出,反向索引能够快速定位包含特定关键词的文档,而无需逐个扫描所有文档。
Elasticsearch 的另一项关键技术是“分片”(sharding)。每个分片相当于一个独立的 Lucene 实例,类似于一个完整的数据库。在文档(Elasticsearch 数据的基本单位)写入时,Elasticsearch 会根据哈希函数(通常基于文档 ID)计算出文档所属的分片,从而将文档均匀分配到不同的分片;查询时,多个分片并行计算,Elasticsearch 将结果聚合后再返回给客户端。
为了追求极致的查询性能,Elasticsearch 也付出了以下代价:
- 写入吞吐量下降:文档写入需要进行分词、构建排序表等操作,这些都是 CPU 和内存密集型的,会导致写入性能下降;
- 存储空间占用高:Elasticsearch 不仅存储原始数据和反向索引,为了加速分析能力,可能还额外存储一份列式数据(Column-oriented Data);其次,为了避免单点故障,Elasticsearch 会为每个分片创建一个或多个副本副本(Replica),这导致 Elasticsearch 会占用极大的存储空间。
轻量化 Loki
Grafana Loki 是由 Grafana Labs 开发的一款日志聚合系统,其设计灵感来源于 Prometheus,目标是成为“日志领域的 Prometheus”。与 Elastic Stack 相比,Loki 具有轻量、低成本和与 Kubernetes 高度集成等特点。
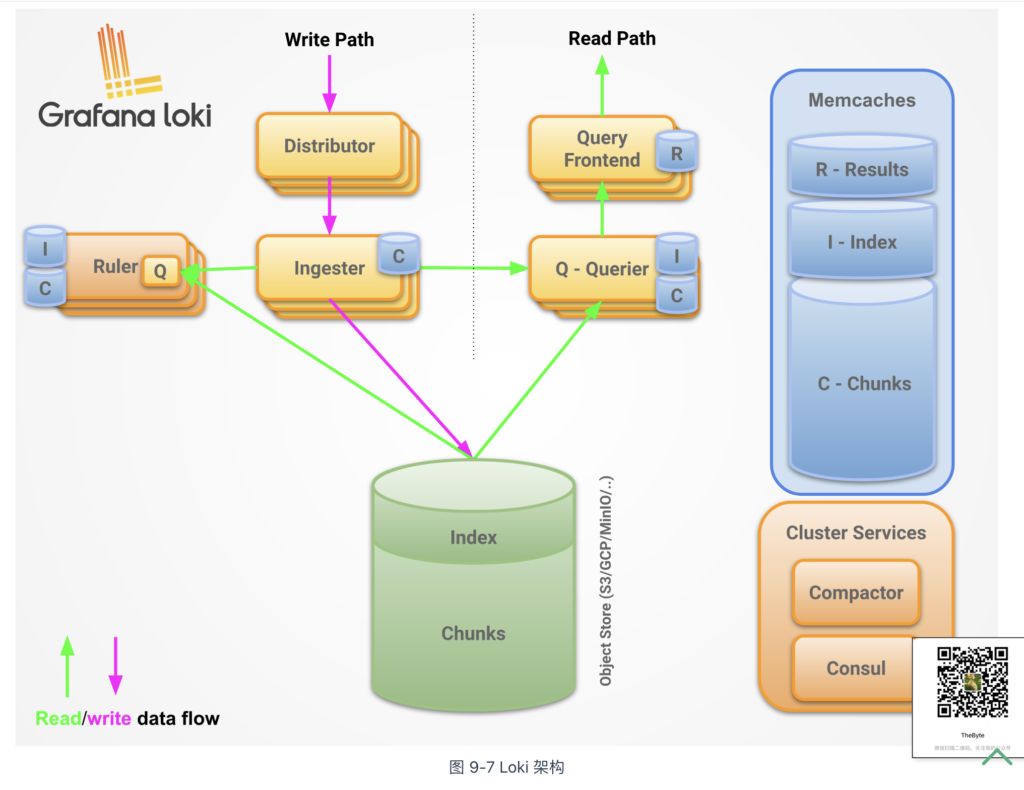
Loki 的架构如图 9-7 所示,其组件以及作用如下:
- 日志代理(Promtail):负责从多种来源(如文件系统、云日志服务)收集日志,并将其格式化后发送至 Loki 系统;
- 分发器(Distributor):接收 Promtail 或其他来源发送的日志,验证日志的完整性,并根据分片规则将日志分发到合适的 Ingester 节点;
- 写入器(Ingester):负责日志的临时存储和索引,将日志数据分段存储,并定期将数据持久化到长久存储(如对象存储);
- 查询器(Querier):执行用户的日志查询请求,从存储中提取所需数据并返回结果;
- 查询前端(Query Frontend):用于优化查询性能,负责分解复杂查询、管理缓存以及合并查询结果,提高查询效率和用户体验;
- 规则处理器(Ruler):处理监控和告警规则,对日志数据执行周期性评估,并根据预定义规则触发告警或生成报告。
Loki 的主要特点是,只对日志的元数据(如标签、时间戳)建立索引,而不对原始日志数据进行索引。在 Loki 的存储模型中,数据有以下两种类型:
- 索引(Indexes):Loki 的索引仅包含日志标签(如日志的来源、应用名、主机名等)和时间戳。索引与相应的块关联;
- 块(Chunks):用来存储原始日志数据的基本单元。原始日志数据会被压缩成“块”,存储在持久化存储介质中,如对象存储(例如 Amazon S3、GCP、MinIO)或本地文件系统。
不难看出,Loki 通过仅索引元数据、以及索引和块的分离存储设计,让其在处理大规模日志数据时具有明显的成本优势。
列式存储 ClickHouse
ClickHouse 是由俄罗斯 Yandex 公司[2]于 2008 年开发的开源列式数据库管理系统。它支持高并发查询,能够高效处理数百亿到数万亿条记录的数据,且具备极快的查询速度,广泛应用于实时数据分析、日志处理、指标监控等领域。
在大规模数据处理过程中,提升查询速度的最有效方法是减少数据扫描范围,这其中的关键在于数据的组织和存储方式。
我们先来看传统的行式数据库是如何存储数据的,以 MySQL 或 PostgreSQL 数据库为例,它们的数据组织如表 9-2 所示,是按行存储的。
表 行式数据库存储结构
| ow | ProductId | sales | Title | GoodEvent | CreateTime |
|---|---|---|---|---|---|
| #0 | 89354350662 | 120 | Investor Relations | 1 | 2016-05-18 05:19:20 |
| #1 | 90329509958 | 10 | Contact us | 1 | 2016-05-18 08:10:20 |
| #2 | 89953706054 | 78 | Mission | 1 | 2016-05-18 07:38:00 |
| #N | … | … | … | … | … |
在行式数据库中,一行数据会在物理存储介质中紧密相邻。
如果要执行下面的 SQL 来统计某个产品的销售额,行式数据库需要加载整个表的所有行到内存,进行扫描和过滤(检查是否符合 WHERE 条件)。过滤出目标行后,若有聚合函数(如 SUM、MAX、MIN),还需要进行相应的计算和排序,最后才会过滤掉不必要的列,整个过程可能非常耗时。
// 统计销售额 SELECT sum(sales) AS count FROM 表 WHERE ProductId=90329509958
接下来,我们来看列式数据库,ClickHouse 的数据组织如表 9-3 所示,数据按列而非按行存储,一列数据在物理存储介质中紧密相邻。我们继续以上面的统计销售额的 SQL 为例,列式数据库只读取与查询相关的列(如 sales 列),不会读取不相关列,从而减少不必要的磁盘 I/O 操作。
表 列式数据库存储结构
| Row: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| ProductId: | 89354350662 | 90329509958 | 89953706054 | … |
| sales: | 120 | 22 | 12 | … |
| Title: | Investor Relations | Contact us | Mission | … |
| GoodEvent: | 1 | 1 | 1 | … |
| CreateTime: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
此外,列式存储通常与数据压缩伴生。数据压缩的本质是通过一定步长对数据进行匹配扫描,发现重复部分后进行编码转换。面向列式的存储,同一列的数据类型和语义相同,重复项的可能性更高,因此自然有着更高的压缩率。
ClickHouse 更进一步的允许用户根据每列数据的特性选择最适合的压缩算法。如下 SQL 示例,创建 MergeTree 类型 example 表,其中:
- id 列使用的 LZ4 算法,主要用于需要快速压缩和解压缩的场景;
- name 列使用的 ZSTD 算法,主要用于日志、文本、二进制数据数据,该算法在压缩效率、速度和压缩比之间有良好的平衡;
- createTime 列使用的 Double-Delta 算法,主要用于压缩具有递增或相邻值差异较小的数据,特别适用于时间戳或计数类数据。
CREATE TABLE example (
id UInt64 CODEC(ZSTD), -- 为整数列设置 LZ4 压缩
name String CODEC(LZ4), -- 为字符串列设置 ZSTD 压缩
age UInt8 CODEC(NONE), -- 不压缩
score Float32 CODEC(Gorilla) -- 为浮点数设置 Gorilla 压缩
createTime DateTime CODEC(Delta, ZSTD), -- 为时间戳设置 Delta 编码加 ZSTD 压缩
) ENGINE = MergeTree()
ORDER BY id;
作为一款分布式数据系统,ClickHouse 自然支持“分片”(Sharding)技术。
ClickHouse 将数据切分成多个部分,并分布到不同的物理节点。也就是说,只要有足够多的硬件资源,ClickHouse 就能处理数万亿条记录、PB 级别规模的数据量。根据 Yandex 公布的测试结果来看(图 9-9),ClickHouse 性能表现遥遥领先对手,比 Vertica(一款商业 OLAP 软件)快约 5 倍、比 Hive 快 279 倍、比 InfiniDB 快 31 倍。
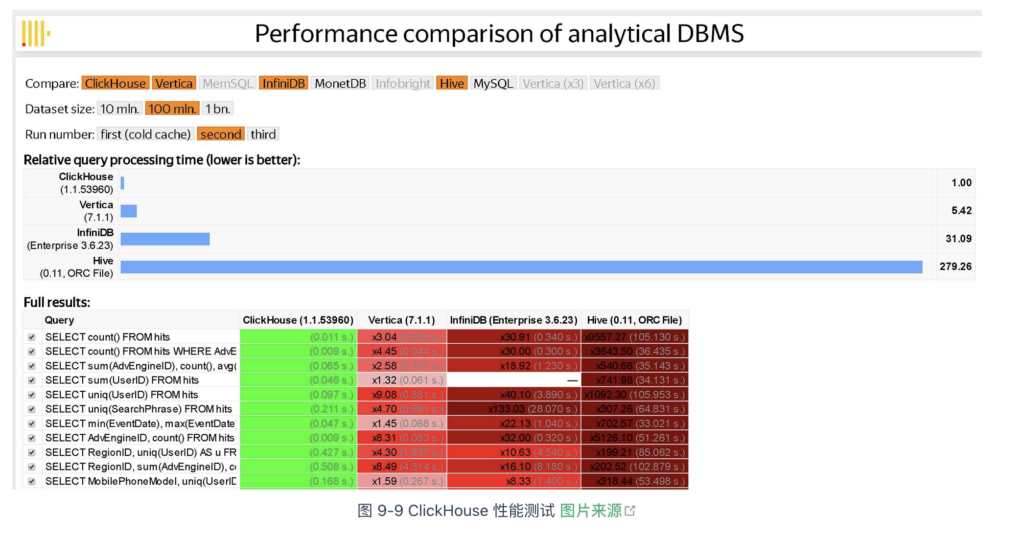
正如 ClickHouse 的宣传所言,其他的开源系统太慢,商用的又太贵。只有 ClickHouse 在存储成本与查询性能之间做到了良好平衡,不仅快且还开源。
分布式链路追踪
Uber 是实施微服务架构的先驱,他们曾经撰写博客介绍过它们的打车系统,该系统约由 2,200 个相互依赖的微服务组成。引用资料中的配图,直观感受铺面而来的复杂性。
图 Uber 使用 Jaeger 生成的追踪链路拓扑 图片来源

上述微服务由不同团队使用不同编程语言开发,部署在数千台服务器上,横跨多个数据中心。这种规模使系统行为变得难以全面掌控,且故障排查路径异常复杂。因此,理解复杂系统的行为状态,并析性能问题的需求显得尤为迫切。
2010 年 4 月,Google 工程师发表了论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》[1],论文总结了他们治理分布式系统的经验,并详细介绍了 Google 内部分布式链路追踪系统 Dapper 的架构设计和实现方法。
Dapper 论文的发布,让治理复杂分布式系统迎来了转机,链路追踪技术开始在业内备受推崇!
链路追踪的基本原理
如今的链路追踪系统大多以 Dapper 为原型设计,因为它们也统一继承了 Dapper 的核心概念:
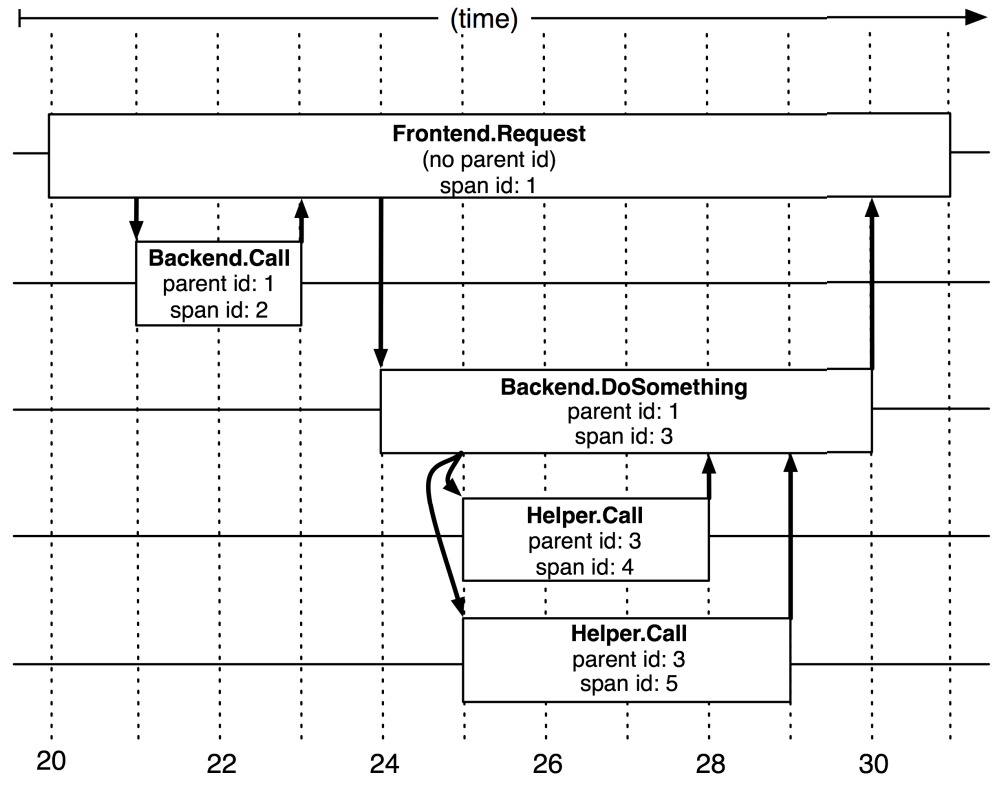
- 追踪(trace):Trace 表示一次完整的分布式请求生命周期,它是一个全局上下文,包含了整个调用链所有经过的服务节点和调用路径。例如,用户发起一个请求,从前端服务到后端数据库的多次跨服务调用构成一个 Trace。
- 跨度(Span):Span 是 Trace 中的一个基本单元,表示一次具体的操作或调用。一个 Trace 由多个 Span 组成,按时间和因果关系连接在一起。Span 内有描述操作的名称 span name、记录操作的开始时间和持续时间、Trace ID、当前 Span ID、父 Span ID(构建调用层级关系)等信息。
总结链路追踪系统的基本原理是,为每个操作或调用记录一个跨度,一个请求内的所有跨度共享一个 trace id。通过 trace id,便可重建分布式系统服务间调用的因果关系。换言之,链路追踪(Trace)是由若干具有顺序、层级关系的跨度组成一棵追踪树(Trace Tree),如图 9-1 所示。
图 由不同跨度组成的追踪树
从链路追踪系统的实现来看,核心是在服务调用过程中收集 trace 和 span 信息,并汇总生成追踪树结构。接下来,笔者将从数据采集、数据展示(分析)两个方面展开,解析主流链路追踪系统的设计原理。
数据采集
目前,追踪系统的主流实现有三种,具体如下:
- 基于日志的追踪(Log-Based Tracing):直接将 Trace、Span 等信息输出到应用日志中,然后采集所有节点的日志汇聚到一起,再根据全局日志重建完整的调用链拓扑。这种方式的优点是没有网络开销、应用侵入性小、性能影响低;但其缺点是,业务调用与日志归集不是同时完成的,有可能业务调用已经结束,但日志归集不及时,导致追踪失真。
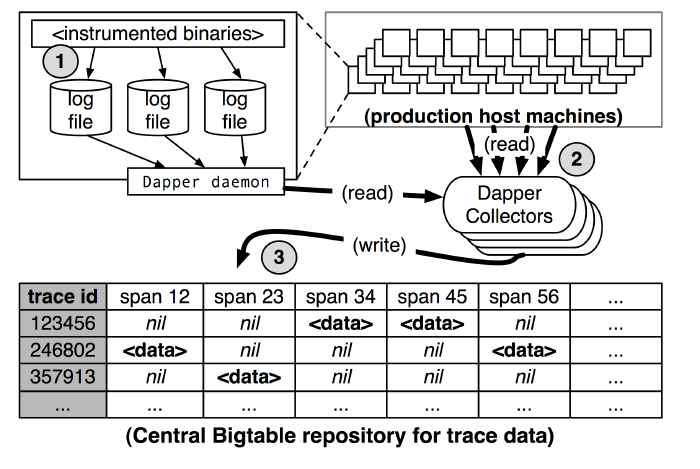
根据图 9-13,总结 Dapper 基于日志实现的追踪如下:
- 将 Span 数据写入本地日志文件。
- Dapper 守护进程(Dapper Daemon)和采集器(Dapper Collectors)从主机节点读取日志。
- 将日志写入 Bigtable 仓库,每行代表一个 Trace,每列代表一个 Span。
- 图 9-13 基于日志实现的追踪
图 基于日志实现的追踪
- 基于服务的追踪(Service-Based Tracing):通过某些手段给目标应用注入追踪探针(Probe),然后通过探针收集服务调用信息并发送给链路追踪系统。探针通常被视为一个嵌入目标服务的小型微服务系统,具备服务注册、心跳检测等功能,并使用专用的协议将监控到的调用信息通过独立的 HTTP 或 RPC 请求发送给追踪系统。以 SkyWalking 的 Java 追踪探针为例,它实现的原理是将需要注入的类文件(追踪逻辑代码)转换成字节码,然后通过拦截器注入到正在运行的应用程序中。比起基于日志实现的追踪,基于服务的追踪在资源消耗和侵入性(但对业务工程师基本无感知)上有所增加,但其精确性和稳定性更高。现在,基于服务的追踪是目前最为常见的实现方式,被 Zipkin、Pinpoint、SkyWalking 等主流链路追踪系统广泛采用。
- 基于边车代理的追踪(Sidecar-Based Tracing):这是服务网格中的专属方案,基于边车代理的模式无需修改业务代码,也没有额外的开销,是最理想的分布式追踪模型。总结它的特点如下:
- 对应用完全透明:有自己独立数据通道,追踪数据通过控制平面上报,不会有任何依赖或干扰;
- 与编程语言无关:无论应用采用什么编程语言,只要它通过网络(如 HTTP 或 gRPC)访问服务,就可以被追踪到。
数据展示
追踪数据通常以两种形式呈现:调用链路图和调用拓扑图,具体如下:
- 调用链路图:主要突出调用的深度、每一次调用的延迟。调用链路图通常用来定位故障。例如,当某次请求失败时,通过调用链路图可以追踪调用经过的各个环节,定位是哪一层调用失败。

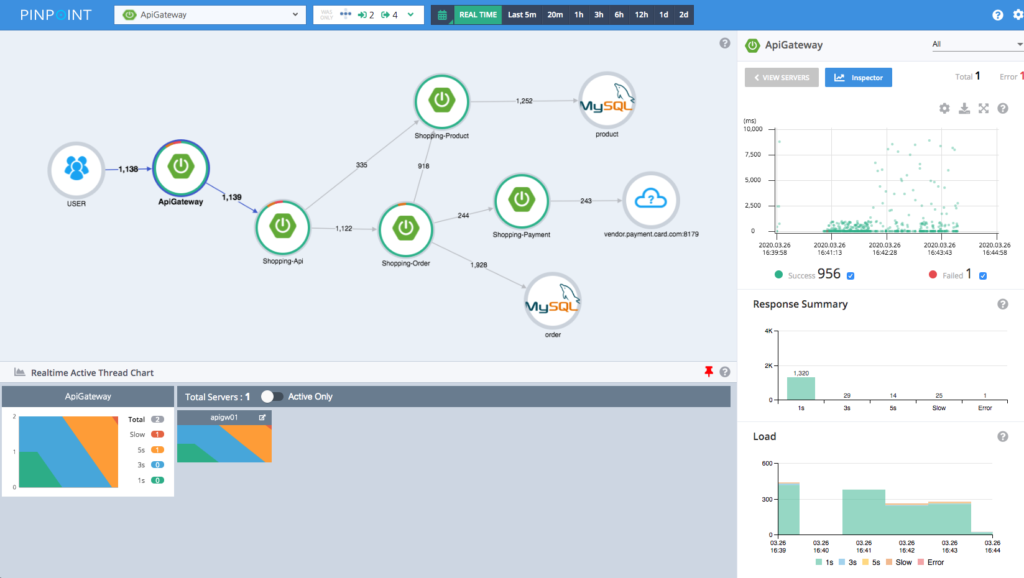
- 调用拓扑图:主要突出系统内各个子服务的全局关系、调用依赖关系。作为全局视角图,它帮助工程师理解全局系统、并识别瓶颈。例如,若某服务压力过高,调用拓扑图的拓展区(右侧)会显示该服务详细情况(延迟、load、QPS 等)。
图 Pinpoint 的调用拓扑图
性能剖析
可观测性领域的性能剖析(Profiling)的目标是分析运行中的应用,生成详细的性能数据(Profiles),帮助工程师全面了解应用的运行行为和资源使用情况,从而识别代码中的性能瓶颈。
性能数据通常以火焰图或堆栈图的形式呈现,分析这些数据是从“是什么”到“为什么”过程中的关键环节。例如,通过链路追踪识别延迟源(是什么),然后根据火焰图进一步分析,定位到具体的代码行(为什么)。2021 年,某网站发生崩溃事件,工程师通过分析火焰图发现 Lua 代码存在异常,最终定位到问题源头。[1]。

火焰图分析说明
纵轴:表示函数调用的堆栈深度(或层级)。纵向越高表示调用链越深,底部通常是程序的入口函数(如 main 函数),上层是被下层函数调用的函数。
横轴:表示函数在特定时间段内所占用的 CPU 时间或内存空间,条形的宽度越大,表示该函数消耗的时间或资源越多。
分析火焰图的关键是观察横向条形的宽度,宽度越大,函数占用的时间越多。如果某个函数的条形图出现“平顶”现象,表示该函数的执行时间过长,可能成为性能瓶颈。
性能数据有多种类型,每种类型由不同的分析器(Profiler)生成,常见的分析器包括:
- CPU 分析器:跟踪程序中每个函数或代码块的运行时间,记录函数调用堆栈信息,生成调用图,并展示函数之间的调用关系和时间分布;
- 堆分析器(Heap Profiler):监控程序的内存使用情况,帮助定位内存泄漏或不必要的内存分配。例如,Java 工程师通过堆分析器定位导致内存溢出的具体对象;
- GPU 分析器:分析 GPU 的使用情况,主要用于图形密集型应用(如游戏开发),优化渲染性能;
- 互斥锁分析器:检测程序中互斥锁的竞争情况,帮助优化线程间的并发性能,减少锁争用引发的性能瓶颈;
- I/O 分析器:评估 I/O 操作的性能,包括文件读写延迟和网络请求耗时,帮助识别数据传输瓶颈并提高效率;
- 特定编程语言分析器:例如 JVM Profiler,用于分析在 Java 虚拟机上运行的应用程序,挖掘与编程语言特性相关的性能问题。
过去,由于分析器资源消耗较高,通常仅在紧急情况下启用。随着低开销分析技术的发展,如编程语言层面的 Java Flight Recorder 和 Async Profiler 技术、操作系统层面的 systemTap 和 eBPF 技术的出现,让在生产环境进行持续性能分析(Continuous Profiling)成为可能,解决线上“疑难杂症”也变得更加容易。
核心转储
核心转储(Core dump)中的 “core” 代表程序的关键运行状态,“dump” 的意思是导出。
核心转储历史悠久,很早就在各类 Unix 系统中出现。在任何安装了《Linux man 手册》的 Linux 发行版中,都可以运行 man core 命令查阅相关信息。
$ man core
...
A small number of signals which cause abnormal termination of a process
also cause a record of the process's in-core state to be written to disk
for later examination by one of the available debuggers. (See
sigaction(2).)
...
上面的大致意思是,当程序异常终止时,Linux 系统会将程序的关键运行状态(如程序计数器、内存映像、堆栈跟踪等)导出到一个“核心文件”(core file)中。工程师通过调试器(如 gdb)打开核心文件,查看程序崩溃时的运行状态,从而帮助定位问题。
注意
复杂应用程序崩溃时,可能会生成几十 GB 大小的核心文件。默认情况下,Linux 系统会限制核心文件的大小。如果你想解除限制,可通过命令 ulimit -c unlimited,告诉操作系统不要限制核心文件的大小。
值得一提的是,虽然 CNCF 发布的可观测性白皮书仅提到了 core dump。实际上,重要的 dumps 还有 Heap dump(Java 堆栈在特定时刻的快照)、Thread dump(特定时刻的 Java 线程快照)和 Memory dump(内存快照)等等。
最后,尽管 CNCF 将 dumps 纳入了可观测性体系,但仍有许多技术难题,如容器配置与操作系统全局配置的冲突、数据持久化的挑战(Pod 重启前将数 Gb 的 core 文件写入持久卷)等等,导致处理 dumps 数据还得依靠传统手段。
可观测标准的演进
Dapper 论文发布后,市场上涌现出大量追踪系统,如 Jaeger、Pinpoint、Zipkin 等。这些系统都基于 Dapper 论文实现,功能上无本质差异,但实现方式和技术栈不同,导致它们难以兼容或协同使用。
为解决追踪系统各自为政的乱象,一些老牌应用性能监控(APM)厂商(如 Uber、LightStep 和 Red Hat)联合定义了一套跨语言的、平台无关分布式追踪标准协议 —— OpenTracing。
开发者只需按照 OpenTracing 规范实现追踪接口,便可灵活替换、组合探针、存储和界面组件。2016 年,CNCF 将 OpenTracing 收录为其第三个项目,前两个分别是大名鼎鼎的 Kubernetes 和 Prometheus。这一举措标志着 OpenTracing 作为分布式系统可观测性领域的标准之一,获得了业界的广泛认可。
OpenTracing 推出后不久,Google 和微软联合推出了 OpenCensus 项目。OpenCensus 起初是 Google 内部的监控工具,开源的目的并非与 OpenTracing 竞争,而是希望为分布式系统提供一个统一的、跨语言的、开箱即用的可观测性框架,不仅仅处理链路追踪(tracing)、还要具备处理指标(metrics)的能力。
虽说 OpenTracing 和 OpenCensus 推动了可观测性系统的发展,但它们作为协议标准,彼此之间的竞争和分裂不可避免地消耗了大量社区资源。对于普通开发者而言,一边是老牌 APM 厂商,另一边是拥有强大影响力的 Google 和微软。选择困难症发作时,一个新的设想不断被讨论:“能否有一个标准方案,同时支持指标、追踪和日志等各类遥测数据?”。
2019 年,OpenTracing 和 OpenCensus 的维护者决定将两个项目整合在一起,形成了现在的 OpenTelemetry 项目。OpenTelemetry 做的事情是,提供各类遥测数据统一采集解决方案。
如图 9-17 所示,集成了 OpenTelemetry 的可观测系统:
- 应用程序只需要一种 SDK 就可以实现所有类型遥测数据的生产;
- 集群只需要部署一个 OpenTelemetry Collector 便可以采集所有的遥测数据。
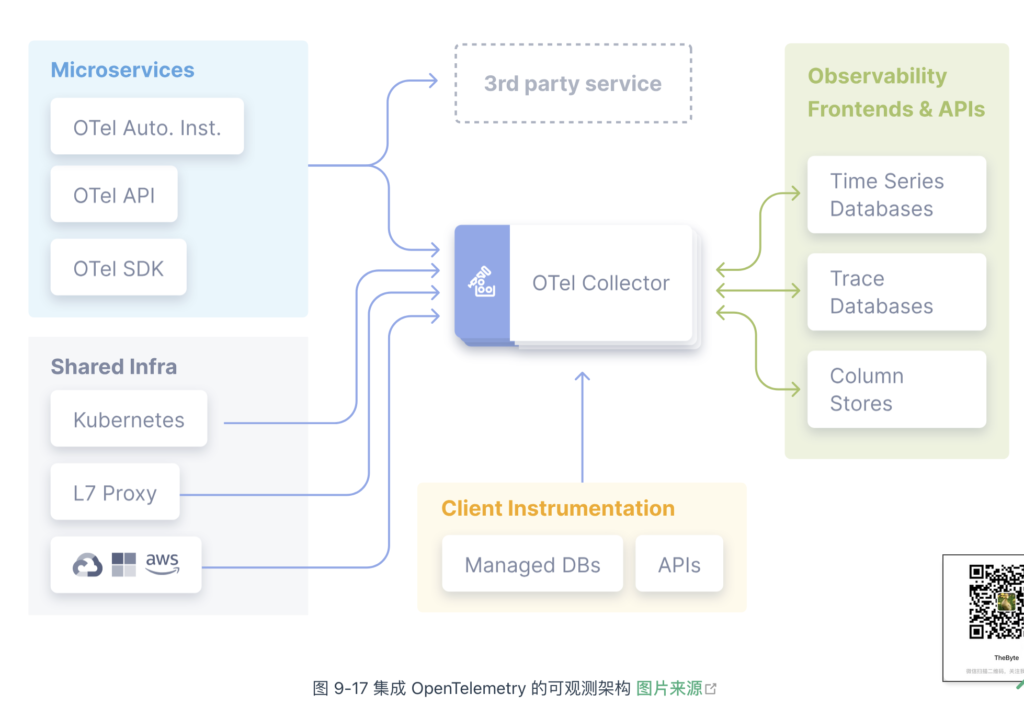
至于遥测数据采集后如何存储、展示、使用,OpenTelemetry 并不涉及。你可以使用 Prometheus + Grafana 做指标的存储和展示,也可以使用 Jaeger 做链路追踪的存储和展示。这使得 OpenTelemetry 既不会因动了“数据的蛋糕”,引起生态抵制,也保存了精力,专注实现兼容“所有的语言、所有的系统”的“遥测数据采集器”(OpenTelemetry Collector)。
自 2019 年发布,OpenTelemetry 便得到了社区的广泛支持。绝大部分云服务商,如 AWS、Google Cloud、Azure、阿里云等均已支持和推广 OpenTelemetry,各种第三方工具(如 Jaeger、Prometheus、Zipkin)也逐步集成 OpenTelemetry,共同构建了丰富的可观测性生态系统。
小结
通过本章的内容,相信你已经理解了什么是可观测性?简单来说,就是通过系统的外部输出推断其内部状态的能力。
系统的外部输出称为“遥测数据”,主要包括日志、指标和追踪数据。建立良好的可观测性机制,实质上是对这些数据进行统一收集、关联和分析。这其中还有两个关键:首先,要低开销。可观测性的一大目的就是发现性能问题,因此不应对业务造成明显的性能负担。对于对延迟敏感的业务,任何微小的性能损耗都可能产生明显的影响。其次,业务透明性至关重要。观测能力通常是在运维阶段加入的,因此应以非侵入或最小侵入的方式实现,尽量避免对业务开发造成干扰。