世界上有两个设计软件的方法,一种方法是设计的尽量简单,以至于明显没有什么缺陷,另外一种方式是使他尽量的复杂,以至于其缺陷不那么明显。
—— by 计算机科学家 C.A.R. Hoare
随着容器化架构大规模应用,手动管理大量容器的方式变得异常艰难。为了减轻管理容器的心智负担,实现容器调度、扩展、故障恢复等自动化机制,容器编排系统应运而生。
过去十年间,Kubernetes 发展成为容器编排系统的事实标准,也成为大数据分析、机器学习以及在线服务等领域广泛认可的最佳技术底座。然而,Kubernetes 在解决复杂问题的同时,本身也演变成当今最复杂的软件系统之一。目前,包括官方文档在内的大多数 Kubernetes 资料都聚焦于“怎么做”,鲜有解释“为什么这么做”。自 2015 年起,Google 陆续发布了《Borg, Omega, and Kubernetes》及《Large-scale cluster management at Google with Borg》等论文,分享了 Google 内部开发 Borg、Omega 和 Kubernetes 系统的经验与教训。本章,我们将从这几篇论文展开,讨论容器编排系统中关于网络通信、持久化存储、资源模型和编排调度等方面的设计原理和应用。
容器编排系统的演进
近几年,业界对容器技术兴趣越来越大,大量的公司开始逐步将虚拟机替换成容器。
实际上,早在十几年前,Google 内部就已开始大规模的实践容器技术了。Google 先后设计了三套不同的容器管理系统,Borg、Omega 和 Kubernetes,并向外界分享了大量的设计思想、论文和源码,直接促进了容器技术的普及和发展,对整个行业的技术演进产生了深远的影响。
Borg 系统
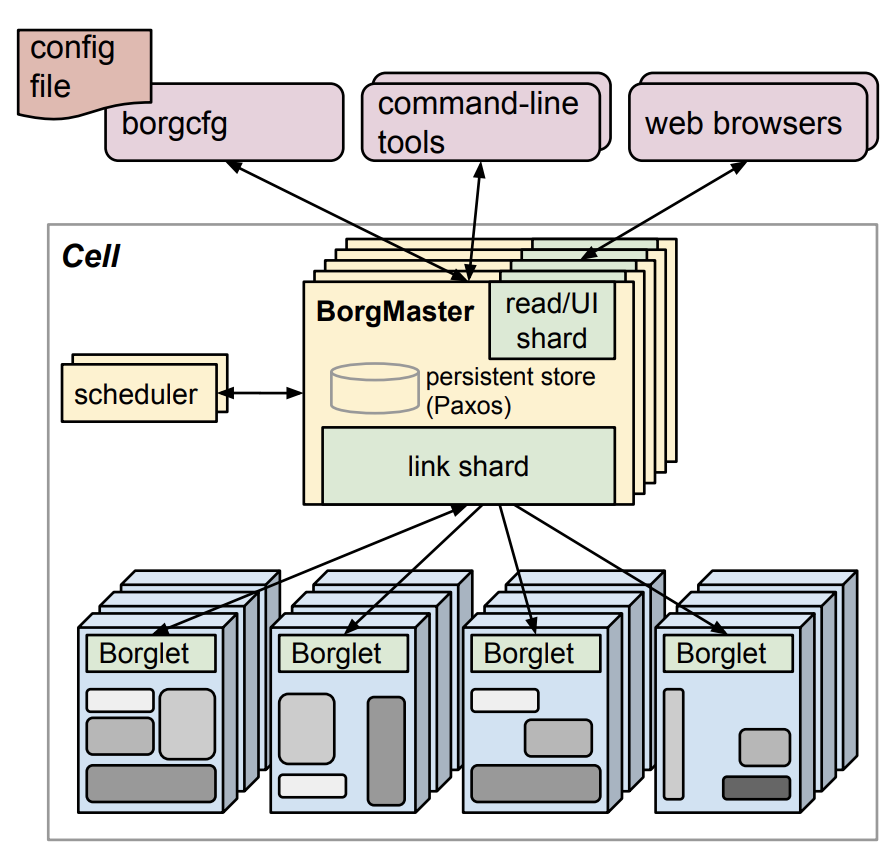
Google 内部第一代容器管理系统叫 Borg。
Borg 的架构如图 7-1 所示,是典型的 Master(图中 BorgMaster) + Agent(图中的 Borglet)架构。用户通过命令行或浏览器将任务提交给 BorgMaster,后者负责记录任务与节点的映射关系(如“任务 A 运行在节点 X 上”)。随后,节点中的 Borglet 与 BorgMaster 进行通信,获取分配给自己的任务,然后启动容器执行。
开发 Borg 的过程中,Google 的工程师为 Borg 设计了两种工作负载(workload):
- 长期运行服务(Long-Running Service):通常是对请求延迟敏感的在线业务,例如 Gmail、Google Docs 和 Web 搜索以及内部基础设施服务;
- 批处理任务(Batch Job):用于一次性处理大量数据、需要较长的运行时间和较多的计算资源的“批处理任务”(Batch Job)。典型如 Apache Hadoop 或 Spark 框架执行的各类离线计算任务。
区分 2 种不同类型工作负载的原因在于:
- 两者运行状态不同:长期运行服务存在“环境准备ok,但进程没有启动”、“健康检查失败”等状态,这些状态是批处理任务没有的。运行状态不同,决定了两类应用程序生命周期管理、监控、资源分配操作的机制不同;
- 关注点与优化方向不一样:一般而言,长期运行服务关注的是“可用性”,批处理任务关注的是“吞吐量”(Throughput),即单位时间内系统能够处理的任务数量或数据量。两者关注点不同,进一步导致内部实现机制的分化。
在 Borg 系统中,大多数长期运行的服务(Long-Running Service)被赋予高优先级(此类任务在 Borg 中称为 “prod”),而批处理任务(Batch Job)则被赋予低优先级(此类任务在 Borg 中称为 “non-prod”)。Borg 的任务优先级设计基于“资源抢占”模型,即高优先级的 prod 任务可以抢占低优先级的 non-prod 任务所占用的资源。
这一设计的底层技术由 Google 贡献给 Linux 内核的 cgroups 支撑。cgroups 是容器技术的基础之一,提供了对网络、计算、存储等各类资源的隔离(7.2 节,笔者将详细介绍 cgroups 技术)。Borg 通过 cgroups 技术,实现了不同类型工作负载的混合部署,共享主机资源同时互不干扰。
随着 Google 内部越来越多的应用程序被部署到 Borg 上,业务团队与基础架构团队开发了大量围绕 Borg 的管理工具和服务,如资源需求预测、自动扩缩容、服务发现与负载均衡、监控系统(Brogmon,Prometheus 的前身,笔者将在第九章详细介绍)等,并逐渐形成了基于 Borg 的内部生态系统。
Omega 系统
Borg 生态的发展由 Google 内部不同团队推动。从迭代结果来看,Borg 生态是一系列异构且自发形成的工具和系统,而不是一个精心设计的整体架构。
为使 Borg 生态更符合软件工程规范,Google 在汲取 Borg 设计与运维经验的基础上开发了 Omega 系统。相比 Borg,Omega 的最大改进是将 BorgMaster 的功能拆分为多个交互组件,而不再是一个单体、中心化的 Master。
此外,Omega 还显著提升了大规模集群的任务调度效率:
- Omega 基于 Paxos 算法实现了一套分布式一致性和高可用的键值存储(内部称为 Store),集群的所有状态都保存在 Store 中;
- 拆分后的组件(如容器编排调度器、中央控制器)可以直接访问 Store;
- 基于 Store,Omega 提出了一种共享状态的双循环调度策略,解决了大规模集群的任务调度效率问题。此设计反哺了 Borg 系统,又延续到了 Kubernetes 之中(笔者将在本章 7.7.3 节详细介绍)。
如图 7-2 所示,改进后的 Borg 和 Omega 系统成为 Google 整套基础设施最核心的依赖。
Kubernetes 系统
Google 开发的第三套容器管理系统是 Kubernetes,其背景如下:
- 全球越来越多的开发者开始对 Linux 容器产生兴趣(Linux 容器是 Google “家底”,但提到容器,开发者们首先想到的是 Docker。Google 并没有吃到容器技术的红利);
- 同时,Google 将公有云服务作为业务重点并实现持续增长(虽然 Google 提出了云计算的概念,但市场被 AWS 抢占先机。Google 起了大早赶了个晚集)。
2013 年夏,Google 的工程师们开始讨论借鉴 Borg 的经验开发新一代容器编排系统,希望通过十几年的技术积累影响云计算市场格局。Kubernetes 项目获批后, 2014 年 6 月,Google 在 DockerCon 大会上宣布将其开源。
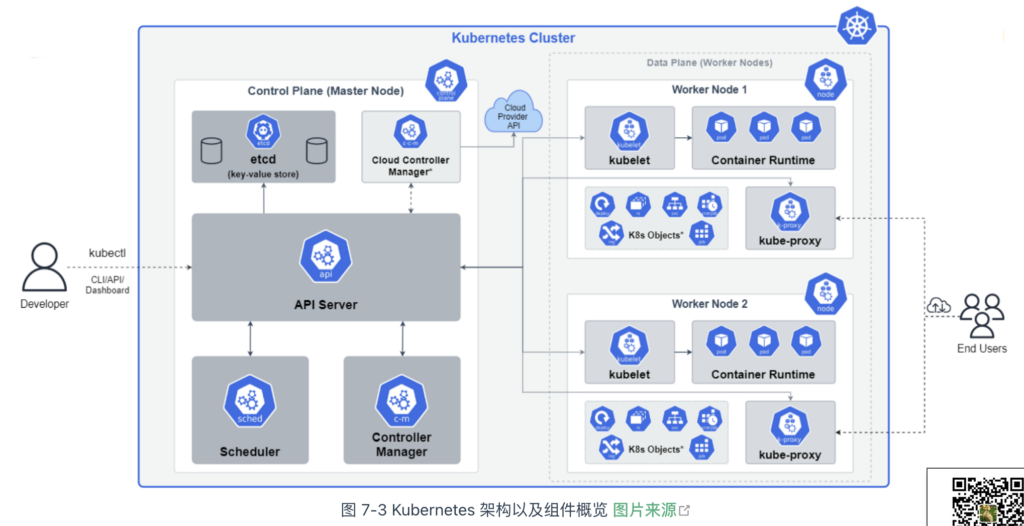
通过图 7-3 观察 Kubernetes 架构,能看出大量设计来源于 Borg/Omega 系统:
- Master 系统由多个分布式组件构成,包括 API Server、Scheduler、Controller Manager 和 Cloud Controller Manager;
- Kubernetes 的最小运行单元 Pod,其原型是 Borg 系统对物理资源的抽象 Alloc;
- 工作节点上的 kubelet 组件,其设计来源于 Borg 系统中各节点里面 Borglet 组件;
- 基于 Raft 算法实现的分布式一致性键值存储 Etcd,对应 Omega 系统中基于 Paxos 算法实现的 Store。
出于降低用户使用的门槛,并最终达成 Google 从底层进军云计算市场意图,Kubernetes 的设计目标是享受容器带来的资源利用率改善,同时让支撑分布式系统的基础设施标准化、操作更简单。
为了进一步理解基础设施的标准化,来看 Kubernetes 从一开始就提供的东西 —— 用于描述各种资源需求的 API:
- 描述 Pod、Container 等计算资源需求的 API;
- 描述 Service、Ingress 等网络功能的 API;
- 描述 Volumes 之类的持久存储的 API;
- 甚至还包括 Service Account 之类的服务身份的 API 等等。
各云厂商已经将 Kubernetes 结构和语义对接到它们各自的原生 API 上。所以,Kubernetes 描述资源需求的 API 是跨公有云、私有云和各家云厂商的,也就是说只要基于 Kubernetes 的规范管理应用程序,那么应用程序就能无缝迁移到任何云中。
提供一套跨厂商的标准结构和语义来声明核心基础设施是 Kubernetes 设计的关键。在此基础上,它又通过 CRD(Custom Resource Define,自定义资源定义)将这个设计扩展到几乎所有的基础设施资源。
有了 CRD,用户不仅能声明 Kubernetes API 预定义的计算、存储、网络服务,还能声明数据库、Task Runner、消息总线、数字证书等等任何云厂商能想到的东西!随着 Kubernetes 资源模型越来越广泛的传播,现在已经能够用一组 Kubernetes 资源来描述一整个软件定义计算环境。
就像用 docker run 可以启动单个程序一样,现在用 kubectl apply -f 就能部署和运行一个分布式应用程序,无需关心是在私有云、公有云或者具体哪家云厂商上。
以应用为中心的转变
从 Borg 到 Kubernetes,容器技术的价值早已超越了单纯提升资源利用率。更深远的影响在于,系统开发和运维的理念从“以机器为中心”转变为“以应用为中心”:
- 容器封装了应用程序的运行环境,屏蔽了操作系统和硬件的细节,使得业务开发者不再需要关注底层实现;
- 基础设施团队可以更灵活地引入新硬件或升级操作系统,最大限度减少对线上应用和开发者的影响;
- 每个设计良好的容器通常代表一个应用,因此管理容器就等于管理应用,而非管理机器;
- 将收集的性能指标(如 CPU 使用率、内存用量、QPS 等)与应用程序而非物理机器关联,显著提高了应用监控的精确度和可观测性。
容器技术的原理与演进
字面上,“容器”这一术语往往让人难以直观地理解其真正含义,Kubernetes 中最核心的概念“Pod”也是如此。
单纯的几句话解释并不足以帮助读者充分理解这些概念,甚至可能引起误解。例如,业内常将容器与轻量级虚拟机混为一谈。如果容器真的类似虚拟机,那我们应该能够有一种通用的方法,轻松将虚拟机中的应用迁移到容器中。但现实中并不存在这种方法,迁移过程仍然需要大量的改造工作。
本节内容将从文件系统隔离的起源出发,逐步讲解容器技术的发展历程,帮助你深入理解 Kubernetes 核心概念 Pod 的设计背景与应用。
文件系统隔离
容器的起源可以追溯到 1979 年。那个时候,UNIX 系统刚引入 chroot 命令[1]。
chroot 是“change root”的缩写,它允许管理员将进程的根目录锁定在特定位置,从而限制进程对文件系统的访问范围。chroot 的隔离功能对安全性至关重要。例如,它可以用于创建一个“蜜罐”,用于安全地运行和监控可疑代码或程序。由于它的隔离作用,chroot 环境也被形象地称为“jail”(监狱),从 chroot 逃逸的过程则被称为“越狱”。
即便时至今日,chroot 命令仍然活跃于主流的 Linux 系统中。在绝大部分 Linux 系统中,只需简单几步操作,就可以为进程创建一个基本的文件隔离环境:
$ mkdir -p new-root/{bin,lib64,root}
$ cp /bin/bash new-root/bin
$ cp /lib64/{ld-linux-x86-64.so*,libc.so*,libdl.so.2,libreadline.so*,libtinfo.so*} new-root/lib64
$ sudo chroot new-root
虽然这个隔离环境功能有限,仅提供了 bash 和一些内置函数,但足以说明其作用:运行在 new-root 根目录下的进程,其文件系统与宿主机隔离了。
bash-4.2# cd bin bash-4.2# pwd /bin
额外知识
除了 /bin 之外,如果我们将程序依赖的 /etc、/proc 等目录一同打包进去,实际上就得到了一个 rootfs 文件。因为 rootfs 包含的不仅是应用,还有整个操作系统的文件和目录,这意味着应用及其所有依赖都被封装在一起,这正是容器被广泛宣传为一致性解决方案的由来。
我们再运行一个 docker 容器,观察两者之间的区别。
$ docker run -t -i ubuntu:18.04 /bin/bash root@028f46a5b7db:/# cd bin root@028f46a5b7db:/bin# pwd /bin
虽然 chroot 看起来与容器相似,都是创建与宿主机隔离的文件系统环境,但这并不意味着 chroot 就是容器。
chroot 只是改变了进程的根目录,并未创建真正独立、安全的隔离环境。在 Linux 系统中,从低层次的资源(如网络、磁盘、内存、处理器)到操作系统控制的高层次资源(如 UNIX 分时、进程 ID、用户 ID、进程间通信),都存在大量非文件暴露的操作入口。
因此,无论是 chroot,还是针对 chroot 安全问题改进后的 pivot_root,都无法实现对资源的完美隔离。
资源全方位隔离
hroot 的最初目的是为了实现文件系统的隔离,并非专门为容器设计。
后来,Linux 吸收了 chroot 的设计理念,并在 2.4.19 版本中引入了 Mount 命名空间,使得文件系统挂载可以被隔离开来。随着容器技术的发展,发现进程间通信也需要隔离,因此引入了 IPC(Inter-Process Communication)命名空间。此外,容器还需要一个独立的主机名来在网络中标识自己,这便催生了 UTS(UNIX Time-Sharing)命名空间。有了独立的主机名,自然需要独立的 IP、端口、路由等,因此 Network 命名空间 也随之诞生。
从 Linux 内核 2.6.19 起,逐步引入了 UTS、IPC、PID、Network 和 User 等命名空间功能。到了 3.8 版本,Linux 实现了容器所需的六项最基本的资源隔离机制。
表 Linux 系统目前支持的八类命名空间(Linux 4.6 版本起,新增了 Cgroup 和 Time 命名空间)
| 命名空间 | 隔离的资源 | 内核版本 |
|---|---|---|
| Mount | 隔离文件系统挂载点,功能大致类似 chroot | 2.4.19 |
| IPC | 隔离进程间通信,使进程拥有独立消息队列、共享内存和信号量 | 2.6.19 |
| UTS | 隔离主机的 Hostname、Domain names,这样容器就可以拥有独立的主机名和域名,在网络中可以被视作一个独立的节点。 | 2.6.19 |
| PID | 隔离进程号,对进程 PID 重新编码,不同命名空间下的进程可以有相同的 PID | 2.6.24 |
| Network | 隔离网络资源,包括网络设备、协议栈(IPv4、IPv6)、IP 路由表、iptables、套接字(socket)等 | 2.6.29 |
| User | 隔离用户和用户组 | 3.8 |
| Cgroup | 使进程拥有一个独立的 cgroup 控制组。cgroup 非常重要,稍后笔者详细介绍。 | 4.6 |
| Time | 隔离系统时间,Linux 5.6 内核版本起支持进程独立设置系统时间 | 5.6 |
在 Linux 中,为进程设置各种命名空间非常简单,只需通过系统调用函数 clone 并指定相应的 flags 参数即可。clone 函数允许创建一个新的进程,并在创建时指定多个资源隔离的选项。clone 函数的声明如下:
int clone(int (*fn)(void *), void *child_stack,
int flags, void *arg, ...
/* pid_t *ptid, struct user_desc *tls, pid_t *ctid */ );
例如,下面的代码展示了如何通过调用 clone 函数并指定多个 CLONE_NEW 标志来创建一个子进程,该进程将“看到”一个全新的系统环境。所有的资源,包括进程挂载的文件目录、进程 PID、进程间通信资源、网络设备、主机名等,都将与宿主机进行隔离。
int flags = CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWNET | CLONE_NEWUTS; int pid = clone(main_function, stack_size, flags | SIGCHLD, NULL);
资源全方位限制
进程的资源隔离已经完成,如果再对使用资源进行额度限制,就能对进程的运行环境实现“进乎完美”的隔离。这就要用 Linux 内核的第二项技术 —— Linux Control Cgroup(Linux 控制组群,简称 cgroups)。
cgroups 是 Linux 内核用于隔离、分配并限制进程组使用资源配额的机制。例如,它可以控制进程的 CPU 占用时间、内存大小、磁盘 I/O 速度等。该项目最初由 Google 工程师 Paul Menage 和 Rohit Seth 于 2000 年发起,当时称之为“进程容器”(Process Container)。由于“容器”这一名词在 Linux 内核中有不同含义,为避免混淆,最终将其重命名为 cgroups。
2008 年,cgroups 被合并到 Linux 内核 2.6.24 版本中,标志着第一代 cgroups 的发布。2016 年 3 月,Linux 内核 4.5 引入了由 Facebook 工程师 Tejun Heo 重写的第二代 cgroups。相比第一代,第二代提供了更加统一的资源控制接口,使得对 CPU、内存、I/O 等资源的限制更加一致。不过,考虑兼容性和稳定性,大多数容器运行时(container runtime)目前仍默认使用第一代 cgroups。
在 Linux 系统中,cgroups 通过文件系统向用户暴露其操作接口。这些接口以文件和目录的形式组织在 /sys/fs/cgroup 路径下。
在 Linux 中执行 ls /sys/fs/cgroup 命令,可以看到在该路径下有许多子目录,如 blkio、cpu、memory 等。
$ ll /sys/fs/cgroup 总用量 0 drwxr-xr-x 2 root root 0 2月 17 2023 blkio lrwxrwxrwx 1 root root 11 2月 17 2023 cpu -> cpu,cpuacct lrwxrwxrwx 1 root root 11 2月 17 2023 cpuacct -> cpu,cpuacct drwxr-xr-x 3 root root 0 2月 17 2023 memory ...
在 cgroups 中,每个子目录被称为“控制组子系统”(control group subsystems),它们对应于不同类型的资源限制。每个子系统有多个配置文件,比如内存子系统:
$ ls /sys/fs/cgroup/memory cgroup.clone_children memory.memsw.failcnt cgroup.event_control memory.memsw.limit_in_bytes cgroup.procs memory.memsw.max_usage_in_bytes cgroup.sane_behavior memory.memsw.usage_in_bytes
这些文件各自用于不同的功能。例如,memory.kmem.limit_in_bytes 用于限制应用程序的总内存使用;memory.stat 用于统计内存使用情况;memory.failcnt 文件报告内存使用达到了 memory.limit_in_bytes 限制值的次数等。
目前,主流的 Linux 系统支持的控制组子系统如表 7-2 所示。
| 控制组群子系统 | 功能 |
|---|---|
| blkio | 控制并监控 cgroup 中的任务对块设备(例如磁盘、USB 等) I/O 的存取 |
| cpu | 控制 cgroups 中进程的 CPU 占用率 |
| cpuacct | 自动生成报告来显示 cgroup 中的进程所使用的 CPU 资源 |
| cpuset | 可以为 cgroups 中的进程分配独立 CPU 和内存节点 |
| devices | 控制 cgroups 中进程对某个设备的访问权限 |
| freezer | 暂停或者恢复 cgroup 中的任务 |
| memory | 自动生成 cgroup 任务使用内存资源的报告,并限定这些任务所用内存的大小 |
| net_cls | 使用等级识别符(classid)标记网络数据包,这让 Linux 流量管控器(tc)可以识别从特定 cgroup 中生成的数据包 ,可配置流量管控器,让其为不同 cgroup 中的数据包设定不同的优先级 |
| net_prio | 可以为各个 cgroup 中的应用程序动态配置每个网络接口的流量优先级 |
| perf_event | 允许使用 perf 工具对 crgoups 中的进程和线程监控 |
Linux cgroups 的设计简洁易用。在 Docker 等容器系统中,只需为每个容器在每个子系统下创建一个控制组(通过创建目录),然后在容器进程启动后,将进程的 PID 写入相应子系统的 tasks 文件。
如下面的代码所示,我们创建了一个内存控制组子系统(目录名为 $hostname),并将 PID 为 3892 的进程的内存限制为 1 GB,同时限制其 CPU 使用时间为 1/4。
/sys/fs/cgroup/memory/$hostname/memory.limit_in_bytes=1GB // 容器进程及其子进程使用的总内存不超过 1GB /sys/fs/cgroup/cpu/$hostname/cpu.shares=256 // CPU 时间总数为 1024,设置 256 后,限制进程最多只能占用 1/4 CPU 时间 echo 3892 > /sys/fs/cgroup/cpu/$hostname/tasks
值得补充的是,cgroups 在资源限制方面仍有不完善之处。例如,/proc 文件系统记录了进程对 CPU、内存等资源的占用情况,这些数据是 top 命令查看系统信息的主要来源。然而,/proc 文件系统并未关联 cgroups 对进程的限制。因此,当在容器内部执行 top 命令时,显示的是宿主机的资源占用状态,而不是容器内的状态。为了解决这个问题,业内通常采用 LXCFS(LXC 用的 FUSE 文件系统)技术,维护一套专门用于容器的 /proc 文件系统,从而准确反映容器内的资源使用情况。
至此,相信读者已经理解容器的概念。容器并不是轻量化的虚拟机,也不是一个完全的沙盒(容器共享宿主机内核,实现的是一种“软隔离”)。本质上,容器是通过命名空间、cgroups 等技术实现资源隔离和限制,并拥有独立根目录(rootfs)的特殊进程。
设计容器协作的方式
既然容器是个特殊的进程,那联想到真正的操作系统内大部分进程也并非独自运行,而是以进程组的形式被有序地组织和协作,完成特定任务。
例如,登录到 Linux 机器后,执行 pstree -g 命令可以查看当前系统中的进程树状结构。
$ pstree -g
|-rsyslogd(1089)-+-{in:imklog}(1089)
| |-{in:imuxsock) S 1(1089)
| `-{rs:main Q:Reg}(1089)
如命令输出所示,rsyslogd 程序的进程树结构展示了其主程序 main 和内核日志模块 imklog 都属于进程组 1089。它们共享资源,共同完成 rsyslogd 的任务。对于操作系统而言,这种进程组管理更加方便。比如,Linux 操作系统可以通过向一个进程组发送信号(如 SIGKILL),使该进程组中的所有进程同时终止运行。
现在,假设我们要将上述进程用容器改造,该如何设计呢?如果使用 Docker,通常会想到在容器内运行两个进程:
- rsyslogd 负责业务逻辑;
- imklog 处理日志。
但这种设计会遇到一个问题:容器中的 PID=1 进程应该是谁?在 Linux 系统中,PID 为 1 的进程是 init,它作为所有其他进程的祖先进程,负责监控进程状态,并处理孤儿进程。因此,容器中的第一个进程也需要具备类似的功能,能够处理 SIGTERM、SIGINT 等信号,优雅地终止容器内的其他进程。
Docker 的设计核心在于采用的是“单进程”模型。Docker 通过监控 PID 为 1 的进程的状态来判断容器的健康状态(在 Dockerfile 中用 ENTRYPOINT 指定启动的进程)。如果确实需要在一个 Docker 容器中运行多个进程,首个启动的进程应该具备资源监控和管理能力,例如,使用专为容器开发的 tinit 程序。
虽然通过 Docker 可以勉强实现容器内运行多个进程,但进程间的协作远不止于资源回收那么简单。要让容器像操作系统中的进程组一样进行协作,下一步的演进是找到类似“进程组”的概念。这是实现容器从“隔离”到“协作”的第一步。
超亲密容器组 Pod
在 Kubernetes 中,与“进程组”对应的设计概念是 Pod。Pod 是一组紧密关联的容器集合,它们共享 IPC、Network 和 UTS 等命名空间,是 Kubernetes 管理的最基本单位。
容器之间原本通过命名空间和 cgroups 进行隔离,Pod 的设计目标是打破这种隔离,使 Pod 内的容器能够像进程组一样共享资源和数据。为实现这一点,Kubernetes 引入了一个特殊容器 —— Infra Container。
Infra Container 是 Pod 内第一个启动的容器,体积非常小(约 300 KB)。它主要负责为 Pod 内的容器申请共享的 UTS、IPC 和网络等命名空间。Pod 内的其他容器通过 setns(Linux 系统调用,用于将进程加入指定命名空间)来共享 Infra Container 的命名空间。此外,Infra Container 也可以作为 init 进程,管理子进程和回收资源。
额外知识
Infra Container 启动后,执行一个永远循环的 pause() 方法,因此又被称为“pause 容器”。
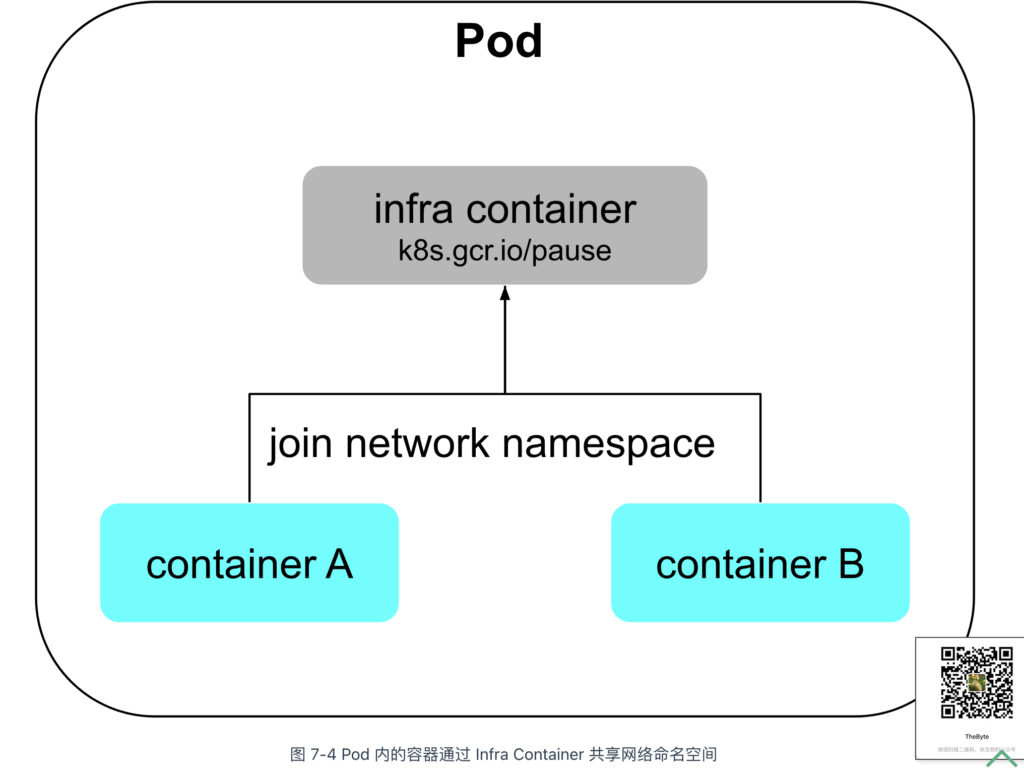
通过 Infra Container,Pod 内的容器可以共享 UTS、Network、IPC 和 Time 命名空间。不过,PID 命名空间和文件系统命名空间默认依然是隔离的,原因如下:
- 文件系统隔离:容器需要独立的文件系统,以避免冲突。如果容器之间需要共享文件,Kubernetes 提供了 Volume 支持(将在本章 7.5 节中介绍);
- PID 隔离:PID 命名空间隔离是为了避免某些容器进程没有 PID=1 的问题,这可能导致容器启动失败(例如,使用 systemd 的容器)。
如果需要共享 PID 命名空间,可以在 Pod 声明中设置 shareProcessNamespace: true。Pod 的 YAML 配置如下所示:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
shareProcessNamespace: true
containers:
- name: container1
image: myimage1
...
在共享 PID 命名空间的 Pod 中,Infra Container 将承担 PID=1 进程的职责,负责处理信号和回收子进程资源等操作。
Pod 是 Kubernetes 的基本单位
解决了容器的资源隔离、限制以及容器间协作问题,Kubernetes 的功能开始围绕容器和 Pod 不断向实际应用的场景扩展。
由于一个 Pod 不会仅有一个实例,Kubernetes 引入了更高层次的抽象来管理多个 Pod 实例。例如:
- Deployment:用于管理无状态应用,支持滚动更新和扩缩容;
- StatefulSet:用于管理有状态应用,确保 Pods 的顺序和持久性;
- DaemonSet:确保每个节点上运行一个 Pod,常用于集群管理或监控;
- ReplicaSet:确保指定数量的 Pod 副本处于运行状态;
- Job/CronJob:管理一次性任务或定期任务。
鉴于 Pod 的 IP 地址是动态分配的,Kubernetes 引入了 Service 来提供稳定的网络访问入口并实现负载均衡。此外,Ingress 作为反向代理,根据定义的规则将流量路由至后端的 Service 或 Pod,从而实现基于域名或路径的细粒度路由和更复杂的流量管理。围绕 Pod 的设计不断衍生,最终绘制出图 7-5 所示的 Kubernetes 核心功能全景图。
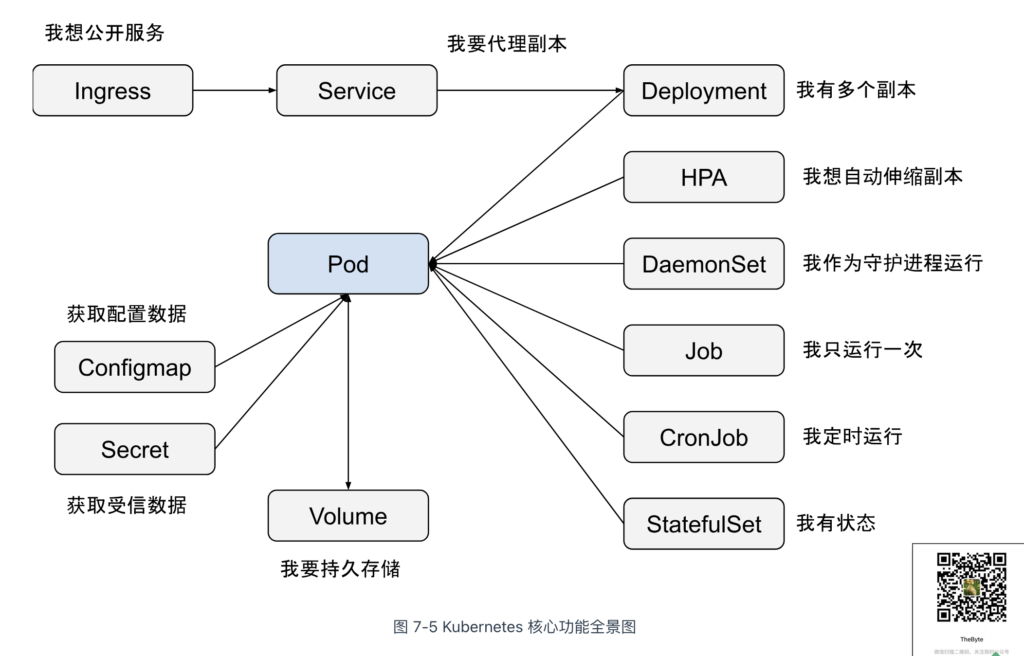
Pod 是调度的原子单元
Pod 还承担着作为调度单元的关键职责。
调度(特别是协同调度)是非常麻烦的事情。举个例子,假设有两个具有亲和性的容器:
- Nginx(资源需求:1GB 内存),负责接收请求并将其写入主机的日志文件;
- LogCollector(资源需求:0.5GB 内存),负责读取日志并将其转发到 Elasticsearch 集群。
假设当前集群的资源情况如下:
- Node1:1.25G 可用内存;
- Node2:2G 可用内存。
如果这两个容器必须协作并在同一台机器上运行,调度器可能会将 Nginx 调度到 Node1。然而,Node1 上只有 1.25GB 内存,而 Nginx 占用了 1GB,导致 LogCollector 无法在该节点上运行,从而阻塞了调度。尽管重新调度可以解决这个问题,但如果需要协调数以万计的容器呢?以下是两种典型的解决方案:
- 成组调度:集群等到足够的资源满足容器需求后,统一调度。这种方法可能导致调度效率降低、资源利用不足,并可能出现互相等待而导致死锁的问题;
- 提高单个调度效率: 通过提升单任务调度效率解决。像 Google 的 Omega 系统采用了基于共享状态的乐观绑定(Optimistic Binding)来优化大规模调度效率。但这种方案实现起来较为复杂,笔者将在第 7.7.3 节“调度器及扩展设计”中详细探讨。
在 Pod 上直接声明资源需求,并以 Pod 作为原子单元来实现调度,Pod 与 Pod 之间不存在超亲密的关系,如果有关系,就通过网络通信实现关联。复杂的协同调度问题在 Kubernetes 中直接消失了!
容器边车模式
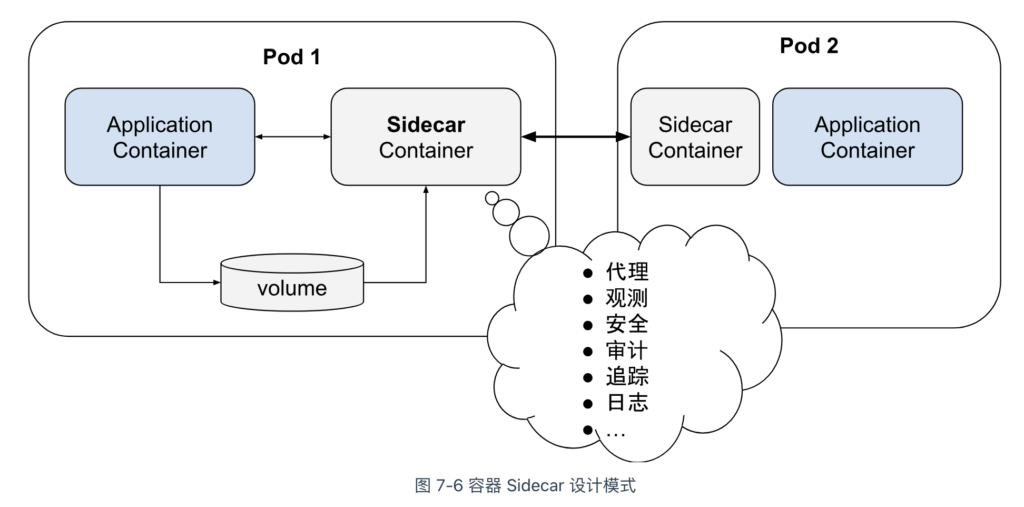
组合多种不同角色的容器,共享资源并统一调度编排,在 Kubernetes 中是一种经典的容器设计模式 —— 边车(Sidecar)模式。
如图 7-6 所示,在边车模式下,一个主容器(负责业务逻辑处理)与一个或多个边车容器共同运行在同一个 Pod 内。边车容器负责处理非业务逻辑的任务,如日志记录、监控、安全保障或数据同步。边车容器将这些职能从主业务容器中分离,使得开发更加高内聚、低耦合的软件变得更加容易。
容器镜像的原理与应用
容器镜像是 Docker 革命性的创新,它在短短几年就迅速改变了整个云计算领域的发展历程。在本节中,我们将深入分析镜像技术原理,并探讨其在下载加速、启动加速、存储优化等场景中的最佳实践。
什么是容器镜像
所谓的“容器镜像”,其实就是一个“特殊的压缩包”,它将应用及其依赖(包括操作系统中的库和配置)打包在一起,形成一个自包含的环境。
很多开发者通常将应用依赖局限于编程语言层面。例如,某个 Java 应用依赖特定版本的 JDK,或者 Python 应用依赖 Python 2.7。但一个常被忽视的事实是:“操作系统本身才是应用运行所需的最完整依赖环境”。制作容器镜像的过程,实际上就是创建一个符合特定要求的操作系统快照。Docker 中,这个操作是:
$ docker build 镜像名称
一旦镜像创建完成,用户便可通过 Docker 创建一个“沙盒”,解压镜像并将其作为根文件系统(rootfs)挂载,容器内的应用程序和依赖就可以顺利运行。Docker 中,这个操作是:
$ docker run 镜像名称
上述的“沙盒”,其实就是上一篇介绍的 namespace 和 cgroups 技术创建出来的隔离环境。
由于镜像打包的是“整个操作系统”,应用程序与运行依赖全部封装在了一起,从而赋予了容器最核心的一致性能力。无论是在本地,还是在云端某个虚拟机,只要解压打包好的容器镜像,应用程序运行所依赖的环境就能完美重现。
注意
严格讲,rootfs 只是操作系统的一部分,是按规则组织的一些文件和目录,并不包括操作系统内核。如果容器内的进程与内核交互,将影响宿主机,这是容器相比虚拟机的主要缺陷之一(不安全)。
容器镜像分层设计原理
rootfs 解决了应用程序运行环境的一致性问题,但并未解决所有问题。
例如,当应用程序升级或运行环境发生变动时,是否需要重新制作一次 rootfs?将整个 rootfs 直接打包不仅无法复用,还会浪费大量存储空间。举例来说,笔者基于 CentOS ISO 制作了一个 rootfs,配置了 Java 运行环境。那么,笔者的同事发布 Java 应用时,肯定想复用之前安装过 Java 运行环境的 rootfs,而不是重新制作一个。此外,如果每个人都重新制作 rootfs,考虑到一台主机通常运行几十个容器,将会占用巨大的存储空间。
分析上述 Java 应用对 rootfs 的需求,发现底层的 rootfs(例如 CentOS + JDK)其实是固定的。那么,是否可以通过增量修改的方式来支持不同应用的依赖?比如,维护一个共同的“基础 rootfs”,然后根据应用的不同依赖制作不同的镜像。例如,CentOS + JDK + app-1、CentOS + JDK + app-2 和 CentOS + Python + app-3 等等。
增量修改的思路当然可行,这也是 Docker 镜像设计的核心。与传统的 rootfs 制作流程不同,Docker 引入了“层”(layer)的概念,每次创建镜像时,都会生成一个新的层,即一个增量式的 rootfs。
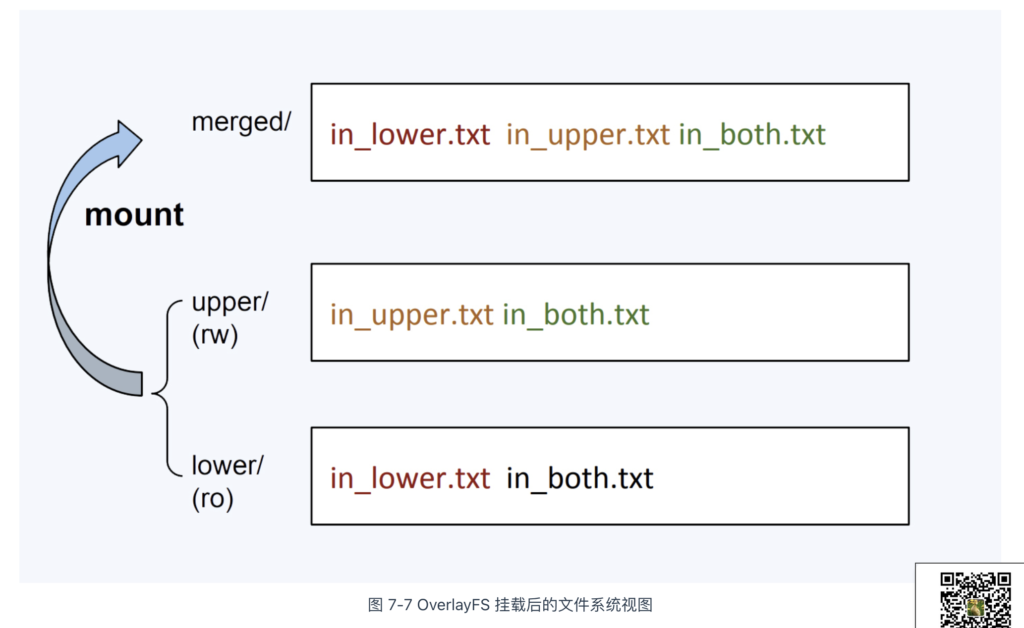
Docker 镜像的分层设计依赖于 UnionFS(联合文件系统)技术,UnionFS 允许将多个目录联合挂载到同一目录下,呈现给用户的是一个统一的文件系统视图,而非多个分散的目录。
UnionFS 有多种实现,例如 OverlayFS、Btrfs 和 AUFS 等。在 Linux 内核 3.18 版本中,OverlayFS 被合并进主分支,并逐渐成为各大主流 Linux 发行版的默认联合文件系统。OverlayFS 的使用非常简便,只需通过 mount 命令,指定文件系统类型为 overlay,并配置以下相关参数:
- lowerdir:OverlayFS 的只读层,通常用于提供基础文件系统,可以指定多个目录;
- upperdir:OverlayFS 的读写层,用于存储用户的增量修改;
- merged:挂载完成后,展示给用户的统一文件系统视图。
笔者举一个具体的例子供你参考,代码如下所示:
#!/bin/bash umount ./merged rm upper lower merged work -r mkdir upper lower merged work echo "I'm from lower!" > lower/in_lower.txt echo "I'm from upper!" > upper/in_upper.txt # `in_both` is in both directories echo "I'm from lower!" > lower/in_both.txt echo "I'm from upper!" > upper/in_both.txt // 使用 mount 命令即将 lower、upper 挂载到 merged。 $ sudo mount -t overlay overlay \ -o lowerdir=./lower,upperdir=./upper,workdir=./work \ ./merged
使用 mount 命令,指定文件系统类型为 overlay,挂载后的文件系统如图 7-7 所示。
当在 merged 目录中执行增删改操作时,OverlayFS 文件系统会触发写时复制(CoW,Copy-On-Write)策略。下面通过一系列操作来解释 CoW 的基本原理:
- 新建文件时:文件会被写入到 upper 目录中;
- 删除文件时:
- 如果删除 in_upper.txt,该文件会从 upper 目录中移除;
- 如果删除 in_lower.txt,lower 目录中的 in_lower.txt 文件保持不变,但 upper 目录会新增一个特殊文件,标记 in_lower.txt 在 merged 目录中已被删除。
- 修改文件时:如果修改 in_lower.txt,upper 目录会创建一个新的 in_lower.txt 文件,包含更新后的内容,而 lower 目录中的原始文件保持不变。
再来看 Docker 镜像利用联合文件系统的分层设计。如图 7-8 所示,整个镜像从下往上由 6 个层组成:
- 最底层是基础镜像 Debian Stretch,相当于“base rootfs”,所有容器可以共享这一层;
- 接下来的 3 层是通过 Dockerfile 中的 ADD、ENV、CMD 等指令生成的只读层;
- Init Layer 位于只读层和可写层之间,存放可能会被修改的文件,如 /etc/hosts、/etc/resolv.conf 等。这些文件原本属于 Debian 镜像,但容器启动时,用户往往会写入一些指定的配置,因此 Docker 为其单独创建了这一层;
- 最上层是通过 CoW(写时复制)技术创建的可写层(Read/Write Layer)。容器内的所有增、删、改操作都发生在此层。但该层的数据不具备持久性,容器销毁时,所有写入的数据也会丢失。容器镜像内无法写入任何数据,是不可变基础设施的思想的体现,无论容器重启多少次或在任何机器上运行,只要使用相同的镜像,启动的服务始终保持一致。
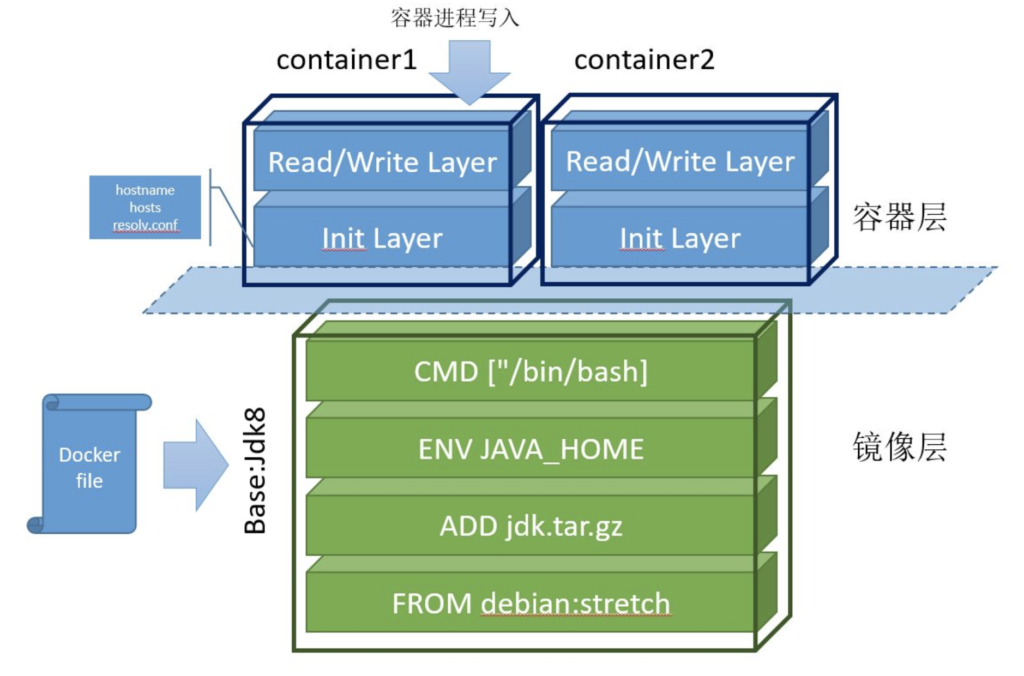
最终,这 6 个层被联合挂载到 /var/lib/docker/overlay/mnt 目录。容器系统通过系统调用 chroot 和 pivot_root 切换根目录,使得容器内的进程仿佛独占一个带有 Java 环境的 Debian 操作系统。
通过镜像分层设计,以 Docker 镜像为核心,不同公司和团队的开发人员可以紧密协作。每个人不仅可以发布基础镜像,还可以基于他人的基础镜像构建和发布自己的软件。镜像的增量操作使得拉取和推送内容也是增量的,这远比操作虚拟机动辄数 GB 的 ISO 镜像要更敏捷。更重要的是,容器镜像一旦发布,全球任何地方的用户都能下载并复现应用所需的完整环境,打通了“开发-测试-部署”流程中的每个环节。
构建足够小的容器镜像
容器镜像的一大挑战是尽量减小镜像体积。较小的镜像在部署、故障转移和存储成本等方面具有显著优势。构建足够小镜像的方法如下:
- 选用精简的基础镜像:基础镜像应只包含运行应用程序所必需的最小系统环境和依赖。选择 Alpine Linux 这样的轻量级发行版作为基础镜像,镜像体积会比 CentOS 这样的大而全的基础镜像要小得多;
- 使用多阶段构建镜像:在构建过程中,编译缓存、临时文件和工具等不必要的内容可能被包含在镜像中。通过多阶段构建,可以只打包编译后的可执行文件,从而得到更加精简的镜像。
以下是通过多阶段构建一个精简 Nginx 镜像的示例,供读者参考:
# 第 1 阶段 FROM skillfir/alpine:gcc AS builder01 RUN wget https://nginx.org/download/nginx-1.24.0.tar.gz -O nginx.tar.gz && \ tar -zxf nginx.tar.gz && \ rm -f nginx.tar.gz && \ cd /usr/src/nginx-1.24.0 && \ ./configure --prefix=/app/nginx --sbin-path=/app/nginx/sbin/nginx && \ make && make install # 第 2 阶段 只打包最终可执行文件 FROM skillfir/alpine:glibc RUN apk update && apk upgrade && apk add pcre openssl-dev pcre-dev zlib-dev COPY --from=builder01 /app/nginx /app/nginx WORKDIR /app/nginx EXPOSE 80 CMD ["./sbin/nginx","-g","daemon off;"]
使用 docker build 命令构建镜像并查看生成的镜像,最终大小为 23.4 MB。
$ docker build -t alpine:nginx . $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE alpine nginx ca338a969cf7 17 seconds ago 23.4MB
加速容器镜像下载
当容器启动时,如果本地没有镜像文件,它将从远程仓库(Repository)下载。镜像下载效率受限于网络带宽和仓库服务质量,镜像越大,下载时间越长,容器启动也因此变慢。
为了解决镜像拉取速度慢和带宽浪费的问题,阿里巴巴技术团队在 2018 年开源了 Dragonfly 项目。
Dragonfly 的工作原理如图 7-9 所示。首先,Dragonfly 在多个节点上启动 Peer 服务(类似 P2P 节点)。当容器系统下载镜像时,下载请求通过 Peer 转发到 Scheduler(类似 P2P 调度器),Scheduler 判断该镜像是否为首次下载:
- 首次下载:Scheduler 启动回源操作,从源服务器获取镜像文件,并将镜像文件切割成多个“块”(Piece)。每个块会缓存到不同节点,相关配置信息上报给 Scheduler,供后续调度决策使用;
- 非首次下载:Scheduler 根据配置,生成一个包含所有镜像块的下载调度指令。
最终,Peer 根据调度策略从集群中的不同节点下载所有块,并将它们拼接成完整的镜像文件。
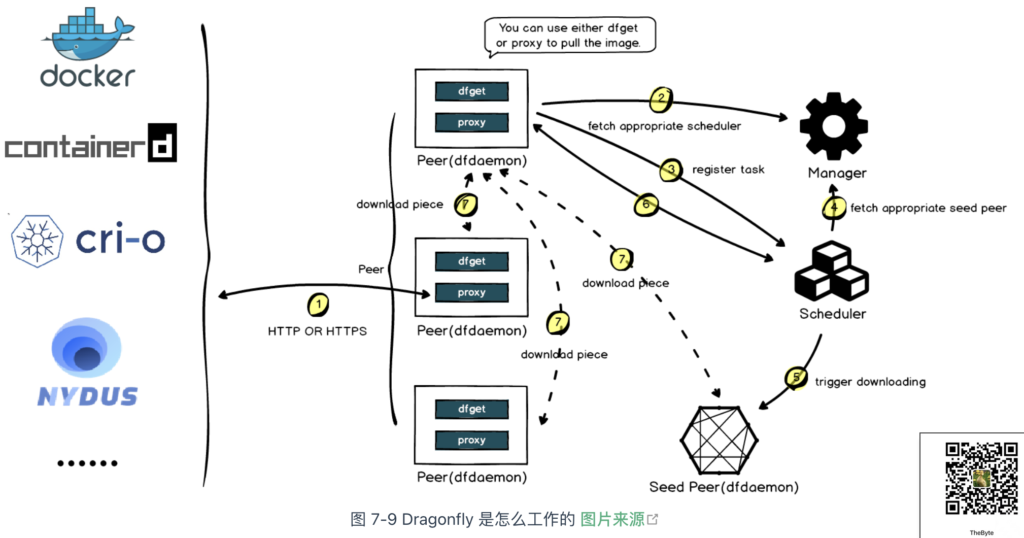
可以看出,Dragonfly 的镜像下载加速流程与 P2P 下载加速非常相似,二者都是通过分布式节点和智能调度来加速大文件的传输与重组。
加速容器镜像启动
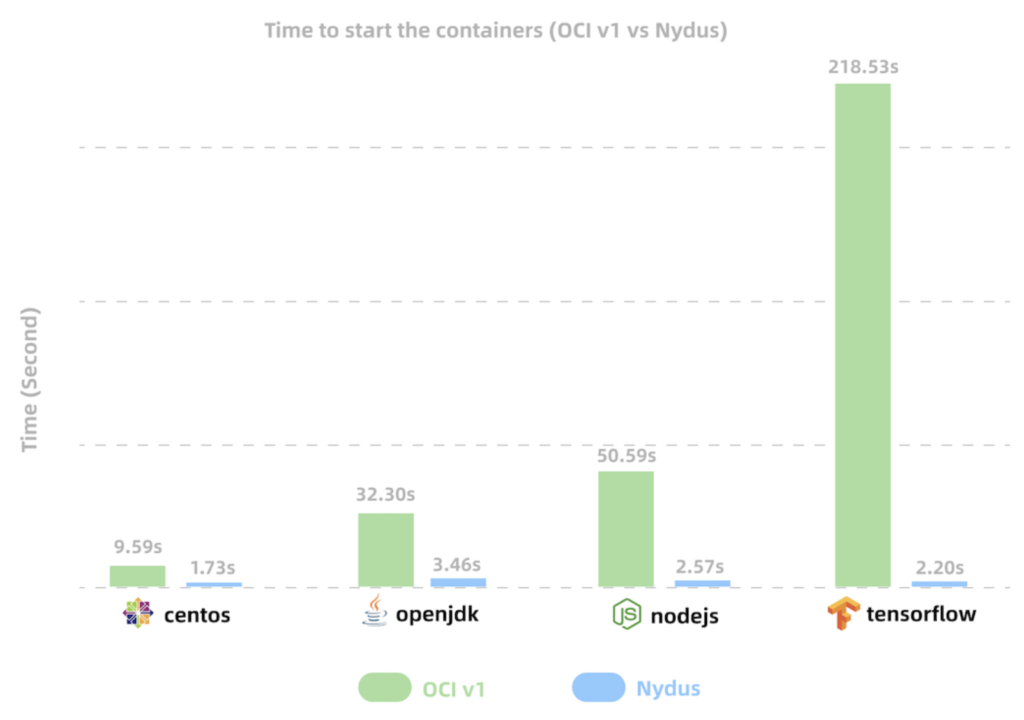
容器镜像的大小直接影响启动时间,一些大型软件的镜像可能超过数 GB。例如,机器学习框架 TensorFlow 的镜像大小为 1.83 GB,冷启动时至少需要 3 分钟。大型镜像不仅启动缓慢、镜像内的文件往往未被充分利用(业内研究表明,通常镜像中只有 6% 的内容被实际使用)[1]。
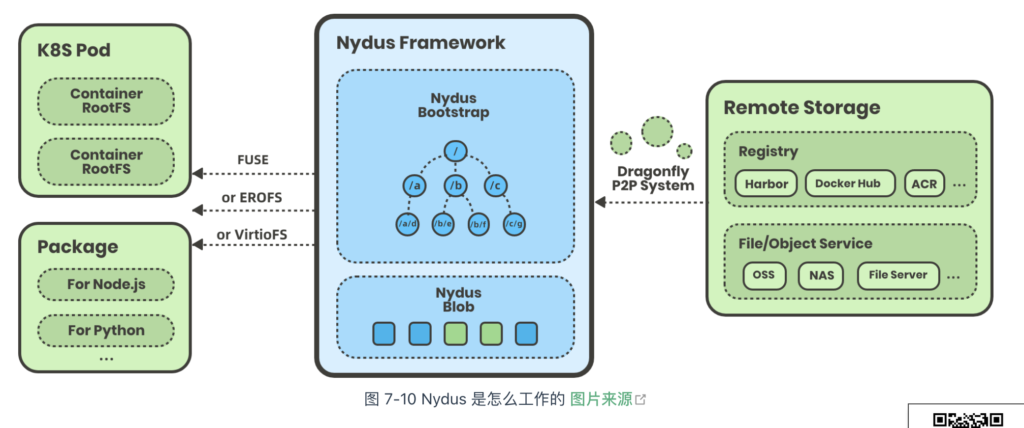
2020 年,阿里巴巴技术团队发布了 Nydus 项目,它将镜像层的数据(blobs)与元数据(bootstrap)分离,容器第一次启动时,首先拉取元数据,再按需拉取 blobs 数据。相较于拉取整个镜像层,Nydus 下载的数据量大大减少。值得一提的是,Nydus 还使用 FUSE 技术(Filesystem in Userspace,用户态文件系统)重构文件系统,用户几乎无需任何特殊配置(感知不到 Nydus 的存在),即可按需从远程镜像中心拉取数据,加速容器镜像启动。
如图 7-11 所示,传统镜像格式(OCIv1)与 Nydus 镜像格式的启动时间对比。Nydus 将常见应用镜像的启动时间从几分钟缩短至仅几秒钟。
综合来讲,上述优化措施对于大规模集群,或对扩容延迟有严格要求的场景(如大促扩容、游戏服务器扩容等)来说,不仅能显著降低容器启动时间,还能大幅节省网络和存储成本。值得一提的是,这些技术调整对业务工程师完全透明,不会影响原有的业务流程。
容器运行时与 CRI 接口
Docker 在诞生十多年后,未曾料到仍会重新成为舆论焦点。事件的起因是 Kubernetes 宣布将进入废弃 dockershim 支持的倒计时,随后讹传讹被人误以为 Docker 不能再用了。
虽说此次事件有众多标题党的推波助澜,但也从侧面说明了 Kubernetes 与 Docker 的关系十分微妙。本节,我们把握这两者关系的变化,从中理解 Kubernetes 容器运行时接口的演变。
Docker 与 Kubernetes
由于 Docker 太流行了,Kubernetes 没有考虑支持其他容器引擎的可能性,完全依赖并绑定于 Docker。那时,Kubernetes 通过内部的 DockerManager 组件调用 Docker API 来创建和管理容器。
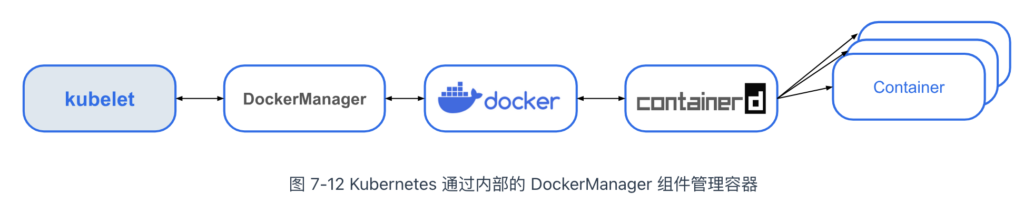
随着市场上出现越来越多的容器运行时,比如 CoreOS 推出的开源容器引擎 Rocket(简称 rkt),Kubernetes 在 rkt 发布后采用类似强绑定 Docker 的方式,添加了对 rkt 的支持。随着容器技术的快速发展,如果继续采用与 Docker 类似的强绑定方式,Kubernetes 的维护工作将变得无比庞大。
Kubernetes 需要重新审视与各种容器运行时的适配问题了。
容器运行时接口 CRI
从 Kubernetes 1.5 版本开始,Kubernetes 在遵循 OCI 标准的基础上,将容器管理操作抽象为一系列接口。这些接口作为 Kubelet(Kubernetes 节点代理)与容器运行时之间的桥梁,使 Kubelet 能通过发送接口请求来管理容器。
管理容器的接口称为“CRI 接口”(Container Runtime Interface,容器运行时接口)。如下面的代码所示,CRI 接口其实是一套通过 Protocol Buffer 定义的 API。
// https://github.com/kubernetes/cri-api/blob/master/pkg/apis/services.go
// RuntimeService 定义了管理容器的 API
service RuntimeService {
// CreateContainer 在指定的 PodSandbox 中创建一个新的容器
rpc CreateContainer(CreateContainerRequest) returns (CreateContainerResponse) {}
// StartContainer 启动容器
rpc StartContainer(StartContainerRequest) returns (StartContainerResponse) {}
// StopContainer 停止正在运行的容器。
rpc StopContainer(StopContainerRequest) returns (StopContainerResponse) {}
...
}
// ImageService 定义了管理镜像的 API。
service ImageService {
// ListImages 列出现有的镜像。
rpc ListImages(ListImagesRequest) returns (ListImagesResponse) {}
// PullImage 使用认证配置拉取镜像。
rpc PullImage(PullImageRequest) returns (PullImageResponse) {}
// RemoveImage 删除镜像。
rpc RemoveImage(RemoveImageRequest) returns (RemoveImageResponse) {}
...
}
根据图 7-13,CRI 的实现由三个主要组件协作完成:gRPC Client、gRPC Server 和具体的容器运行时。具体来说:
- Kubelet 充当 gRPC Client,调用 CRI 接口;
- CRI shim 作为 gRPC Server,响应 CRI 请求,并将其转换为具体的容器运行时管理操作。
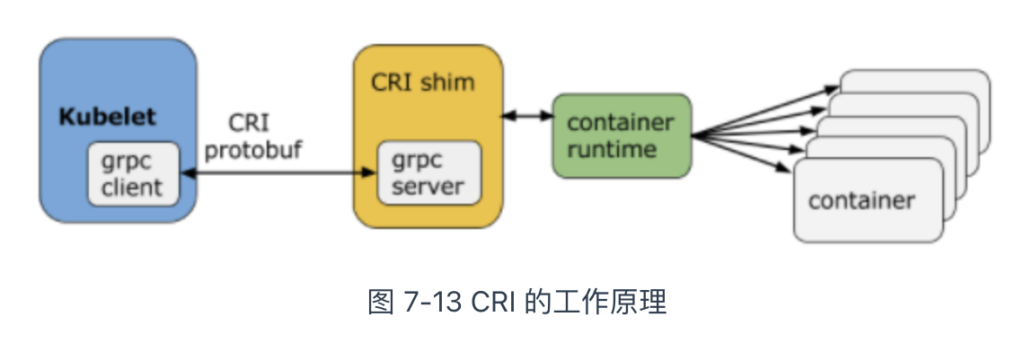
由此,市场上的各类容器运行时,只需按照规范实现 CRI 接口,就可以无缝接入 Kubernetes 生态。
Kubernetes 专用容器运行时
2017 年,Google、RedHat、Intel、SUSE 和 IBM 一众大厂联合发布了 CRI-O(Container Runtime Interface Orchestrator)项目。从名称可以看出,CRI-O 的目标是兼容 CRI 和 OCI,使 Kubernetes 能在不依赖传统容器引擎(如 Docker)的情况下,仍能有效管理容器。

Google 推出 CRI-O 的意图明显,即削弱 Docker 在容器编排领域的主导地位。但彼时 Docker 在容器生态中的市场份额仍占绝对优势。对于普通用户而言,如果没有明确的收益,并没么动力把 Docker 换成别的容器引擎。
不过,我们也可以想象,Docker 当时的内心一定充满了被抛弃的焦虑。
Containerd 与 CRI
Docker 并没有“坐以待毙”,开始主动进行革新。回顾本书第一章 1.5.1 节关于 Docker 演进的内容,Docker 从 1.1 版本起开始重构,并拆分出了 Containerd。
早期,Containerd 单独开源,并未捐赠给 CNCF,还适配了其他容器编排系统,如 Swarm,因此并未直接实现 CRI 接口。出于诸多原因的考虑,Docker 对外部开放的接口也依然保持不变。在这种背景下,Kubernetes 中出现了两种调用链(如图 7-15 所示):
- 通过适配器 dockershim 调用:首先 dockershim 调用 Docker,然后 Docker 调用 Containerd,最后 Containerd 操作容器;;
- 通过适配器 CRI-containerd 调用:首先 CRI-containerd 调用 Containerd,随后 Containerd 操作容器。
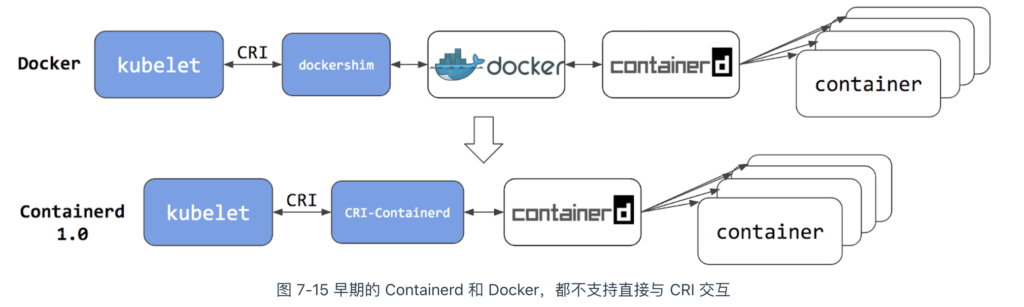
在这一阶段,Kubelet 和 dockershim 的代码都托管在同一个仓库中,意味着 dockershim 由 Kubernetes 负责组织、开发和维护。因此,每当 Docker 发布新版本时,Kubernetes 必须集中精力快速更新 dockershim。此外,Docker 作为容器运行时显得过于庞大。Kubernetes 弃用 dockershim 有了充分的理由和动力。
再来看 Docker。2018 年,Docker 将 Containerd 捐赠给 CNCF,并在 CNCF 的支持下发布了 1.1 版。与 1.0 版相比,1.1 版的最大变化在于完全支持 CRI 标准,这意味着原本作为 CRI 适配器的 CRI-Containerd 也不再需要。
Kubernetes v1.24 版本正式移除 dockershim,实质上是废弃了内置的 dockershim 功能,转而直接对接 Containerd。此时,再观察 Kubernetes 与容器运行时之间的调用链,你会发现,与 DockerShim 和 CRI-containerd 的交互相比,调用步骤最多减少了两步:
- 用户只需抛弃 Docker 的情怀,容器编排至少可以省略一次调用,获得性能上的收益;
- 对 Kubernetes 而言,选择 Containerd 作为容器运行时,调用链更短、更稳定、占用的资源更少。
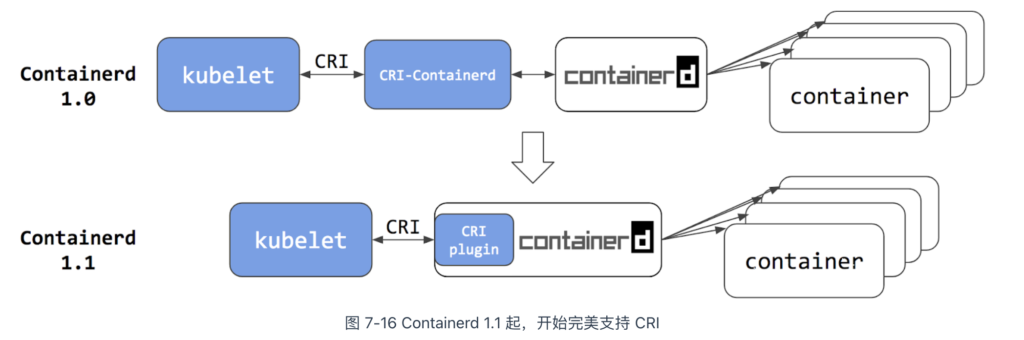
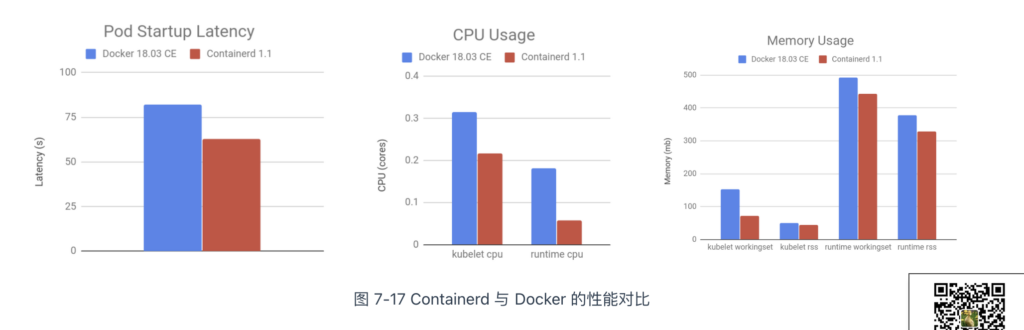
根据 Kubernetes 官方提供的性能测试数据[1],Containerd 1.1 相比 Docker 18.03,Pod 的启动延迟降低了 20%、CPU 使用率降低了 68%、内存使用率降低了 12%。这是一个相当显著的性能改善。
安全容器运行时
事实上,虽然容器提供一个与系统中的其它进程资源相隔离的执行环境,但是与宿主机系统是共享内核的。如果有一个容器进程被恶意程序攻击,就有可能造成容器逃逸,轻则破坏当前的容器,重则造成 Linux 内核崩溃,导致整个机器宕机。
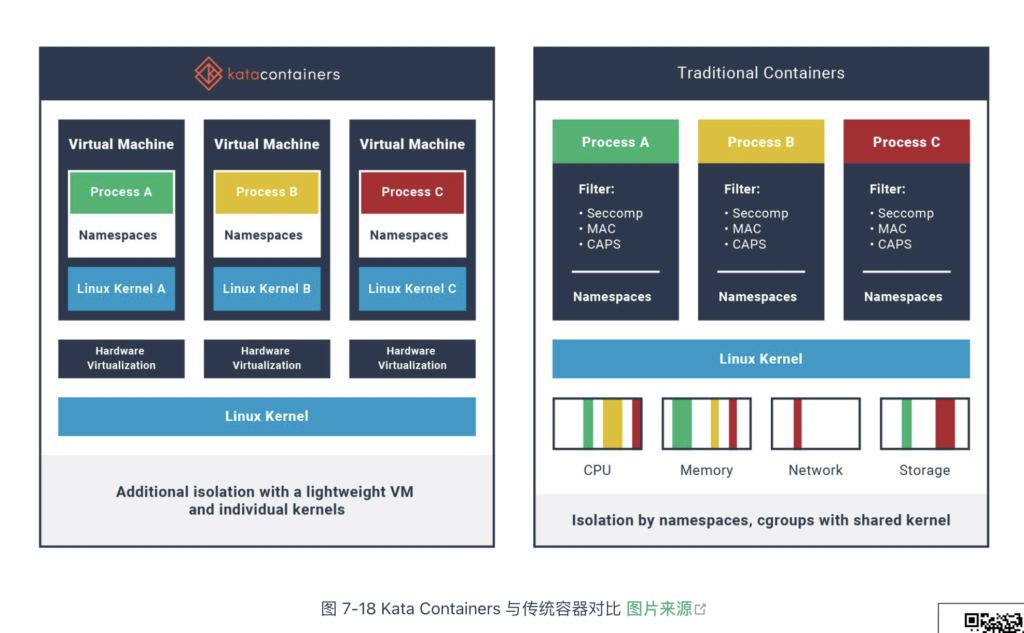
为了提高安全性,很多运维人员会将容器“嵌套”在虚拟机中,将容器与同一主机上的其他进程完全隔离。但在虚拟机中运行容器会丧失容器的速度和敏捷性优势。为了解决这个问题,Intel 和 Hyper.sh(现为蚂蚁集团的一部分)在 2016 年,几乎同时发布了各自的解决方案,分别是 Intel Clear Containers 和 runV 项目。
2017 年,Intel 和 Hyper.sh 两家公司将各自的项目合并,互补优势,创建了开源项目 Kata Containers。该项目的原理如图 7-18 所示,本质上是通过硬件虚拟化技术(如 QEMU/KVM)为每个容器/Pod 分配独立的内核,将其运行在一个精简的轻量级虚拟机中。因此,它“像容器一样敏捷,像虚机一样安全”(The speed of containers, the security of VMs)。
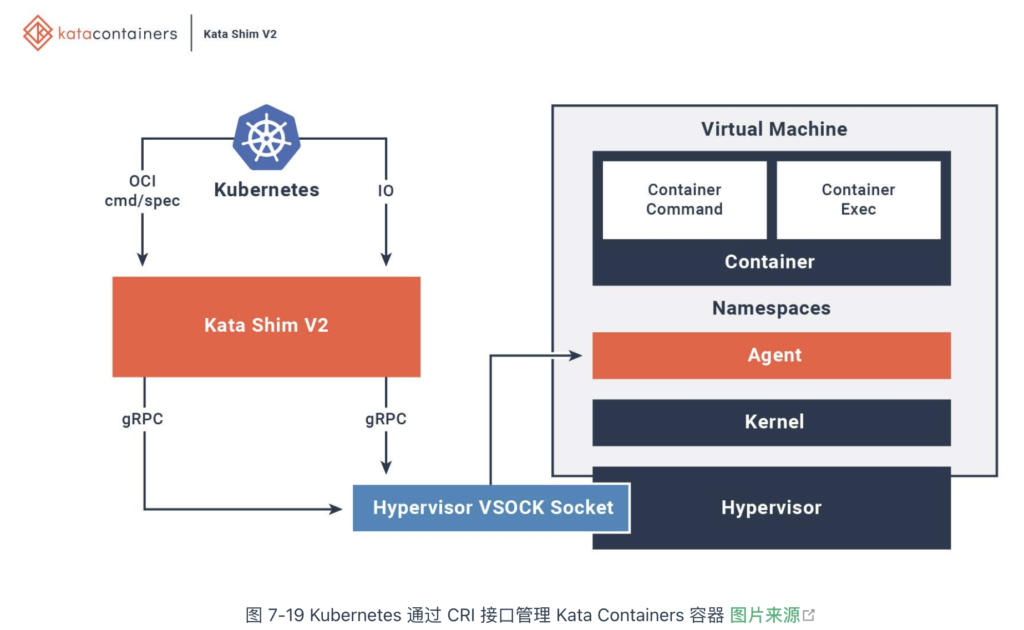
为了与上层容器编排系统对接,Kata Containers 会启动一个进程(shimv2)来负责容器的生命周期管理。shimv2 相当于 Kata Containers 与容器运行时之间的兼容层,支持标准的容器接口,如 CRI(容器运行时接口)或 Docker API。这使得容器编排系统能够像操作普通容器一样管理容器,而不需要意识到容器实际上是运行在一个虚拟机中。
除了 Kata Containers,2018 年底,AWS 发布了安全容器项目 Firecracker。其核心是一个用 Rust 编写的虚拟化管理器,利用 Linux 内核虚拟机(KVM)来创建和运行轻量级虚拟机。不难看出,无论是 Kata Containers 还是 Firecracker,它们实现安全容器的方法殊途同归,都是为每个进程分配独立的操作系统内核,从而有效防止容器进程“逃逸”或夺取宿主机控制权的问题。
容器运行时生态
如图 7-20 所示,目前已有十几种容器运行时实现了 CRI 接口,具体选择哪一种取决于 Kubernetes 安装时宿主机的容器运行时环境。但对于云计算厂商而言,除非出于安全性需要(如必须实现内核级别的隔离),大多数情况都会选择 Containerd 作为容器运行时。毕竟对于它们而言,性能与稳定才是核心的生产力与竞争力。

容器持久化存储设计
镜像作为不可变的基础设施,要求在任何环境下能复制出完全一致的容器实例。这意味着,容器内部写入的数据与镜像无关,一旦容器重启,所有写入的数据都会丢失。那容器系统怎么实现数据持久化存储呢?本节,我们由浅入深,先从 Docker 开始,逐步了解容器持久化存储的原理、不同存储类型的特点及其适用场景。
Docker 的存储设计
Docker 通过将宿主机目录挂载到容器内部的方式,实现数据持久化存储。如图 7-21 所示,目前它支持三种挂载方式:bind mount、volume 和 tmpfs mount。
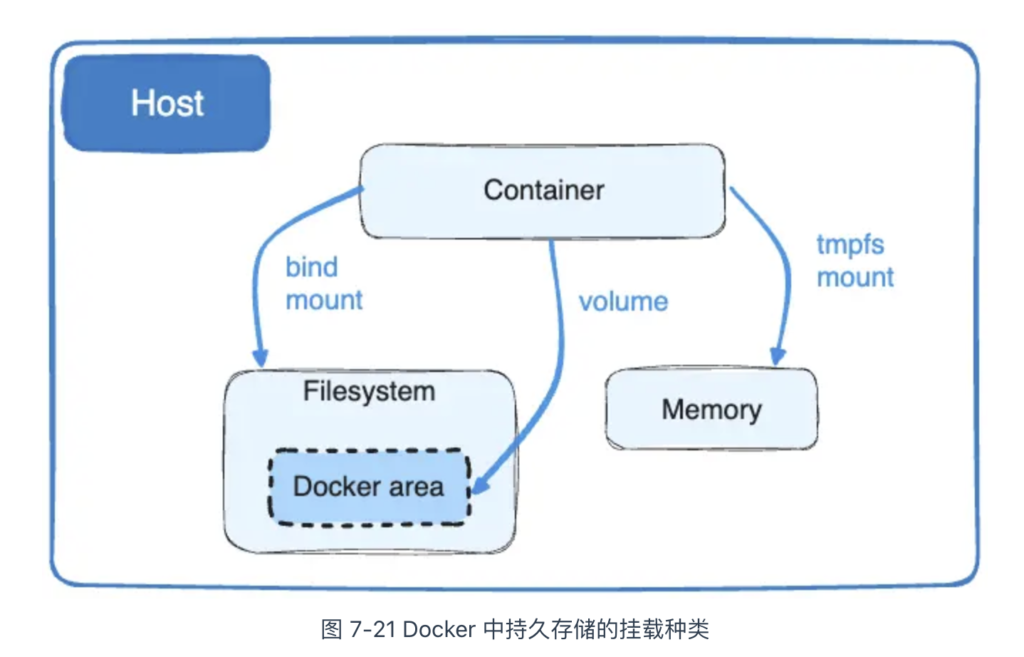
bind mount 是 Docker 最早支持的挂载类型,也是我们最熟悉的挂载方式。如下命令所示,启动一个 Nginx 容器,并将宿主机的 /usr/share/nginx/html 目录挂载到容器内 /data 目录:
$ docker run -v /usr/share/nginx/html:/data nginx:lastest
上面的挂载,实际上是通过 mount 系统调用实现的。如下代码所示:
// 将宿主机中的 /usr/share/nginx/html 挂载到容器根文件系统的 /data 路径
mount("/usr/share/nginx/html", "rootfs/data", "none", MS_BIND, NULL);
通过 mount 系统调用实现的持久化存储存在以下缺陷:
- 与操作系统的强耦合:容器内的目录通过 mount 挂载到宿主机的绝对路径,这使得容器的运行环境与操作系统紧密绑定。一方面,bind mount 方式无法写入 Dockerfile,否则镜像在其他环境中可能无法启动。另一方面,宿主机中被挂载的目录与 Docker 并无直接关联,其他进程可能会误操作,存在潜在的安全风险;
- 难以满足多样化的存储需求:随着容器广泛应用,存储需求也变得更加复杂。存储位置不仅限于宿主机,还可能涉及外部网络存储;存储介质不仅是磁盘,还可能是内存文件系统(如 tmpfs);存储类型也不局限于文件系统,还包括块设备或对象存储;
- 低效的网络存储处理,对于网络存储,实在没必要先将其挂载到操作系统再挂载到容器内某个目录。Docker 完全可以直接对接 iSCSI、NFS 网络存储协议,绕过操作系统,降低资源占用和访问延迟。
为了解决上述问题,Docker 从 1.7 版本起引入了全新的挂载类型 —— Volume(存储卷):
- 独立的存储空间:Volume 会在宿主机中开辟一个专属于 Docker 的空间(通常在 Linux 中为 /var/lib/docker/volumes/ 目录),这样就避免了 bind mount 对宿主机绝对路径的依赖;
- 支持多种存储系统:考虑到存储类型的多样性,仅依赖 Docker 本身来实现所有存储需求并不现实。因此,Docker 在 1.10 版本中又引入了 Volume Driver 机制,借助社区的力量扩展存储驱动,支持更多存储系统和协议。。
经过一系列的设计,现在 Docker 用户只要通过 docker plugin install 安装额外的第三方卷驱动,就能使用想要的存储方案。
举个具体的例子,请看使用阿里云文件存储(NAS)的示例:
- 先安装阿里云 NAS Volume 插件:
docker plugin install aliyun/aliyun-volume-plugin:latest --alias aliyun-nas --grant-all-permissions
- 接着,使用 docker volume create 命令创建一个挂载到阿里云 NAS 的存储卷,指定 NAS 文件系统的地址:
docker volume create \ --driver aliyun-nas \ --opt nasAddr=<Your_NAS_Address> \ --opt mountDir=/myvolume \ my-aliyun-nas-volume
- 最后,启动容器时,将创建的阿里云 NAS 卷挂载到容器中的目录:
docker run -d -v my-aliyun-nas-volume:/mnt/nas nginx:latest
Kubernetes 的存储设计
我们从 Docker 返回到 Kubernetes 中,同 Docker 类似的是:
- Kubernetes 也抽象出了 Volume 的概念来解决持久化存储;
- 在宿主机中,也开辟了属于 Kubernetes 的空间(该目录是 /var/lib/kubelet/pods/[pod uid]/volumes);
- 也设计了存储驱动(在 Kubernetes 中称 Volume Plugin)扩展支持出众多的存储类型,如本地存储、网络存储(如 NFS、iSCSI)、云厂商的存储服务(如 AWS EBS、GCE PD、阿里云 NAS 等)。
不同的是,作为一个工业级的容器编排系统,Kubernetes 的 Volume 机制比 Docker 更复杂、支持的存储类型更丰富。Kubernetes 支持的存储类型,如图 7-22 所示。

乍一看,这么多 Volume 类型实在难以下手。然而,总结起来就 3 类:
- 普通 Volume:主要用于临时数据存储,包括 emptyDir 和 hostPath 等类型;
- emptyDir:在 Pod 删除时数据会被清空;
- hostPath:数据存储在节点本地路径上,如果 Pod 被调度到其他节点,则无法访问原有数据。
- 持久化的 Volume:通过 PersistentVolume(PV)和 PersistentVolumeClaim(PVC)机制实现,支持长期存储且与 Pod 的生命周期解耦。常见的类型包括 NFS、云存储(如 AWS EBS、GCE PD)等;
- 特殊的 Volume:用于管理配置和敏感数据,例如 Secret 和 ConfigMap。严格来说,这类 Volume 并非传统意义上的存储类型,而是通过实现标准的 POSIX(可移植操作系统接口)接口,提供对 Kubernetes 集群中配置信息的便捷访问。这部分内容,笔者就不再展开讨论了。
普通的 Volume
Kubernetes 设计普通 Volume 的初衷并非为了持久化存储数据,而是为了实现容器间的数据共享。请看两个典型示例:
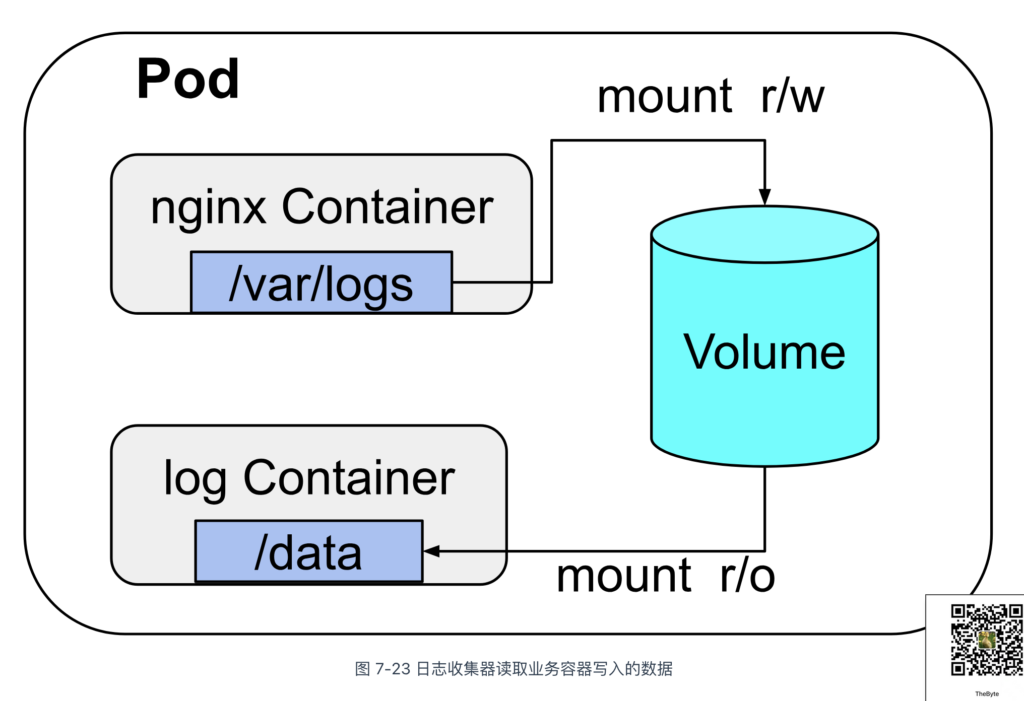
- EmptyDir:这种 Volume 类型常用于 Sidecar 模式。例如,日志收集容器通过 EmptyDir 访问业务容器的日志文件;
- HostPath:与 EmptyDir 不同,HostPath 允许同一节点上的所有容器共享宿主机的本地存储。例如,在 Loki 日志系统中,Pod 挂载宿主机的 HostPath Volume 后,Loki 可以收集并读取宿主机上所有 Pod 生成的日志。
如图 7-23 所示,EmptyDir 类型的 Volume 随 Pod 生命周期而存在。当 Pod 被销毁时,EmptyDir Volume 也会被删除。对于 HostPath,当 Pod 被调度到其他节点时,数据也相当于丢失了。
持久化的 Volume
由于 Pod 随时可能被调度到其他节点,如果要实现数据的持久化存储,就得依赖网络存储解决方案。这就是引入 PV(PersistentVolume,持久卷)的原因。
以下是一个 PV 资源的 YAML 配置示例。其 spec 部分定义了关键配置项,包括:存储容量(5Gi)、访问模式(ReadWriteOnce,表示允许单个节点进行读写)、远程存储类型(如 NFS),以及数据回收策略(Recycle,表示在 PV 释放后自动清除数据以供重用)。
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity: #容量
storage: 5Gi
accessModes: #访问模式
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle #回收策略
storageClassName: manual
nfs:
path: /
server: 172.17.0.2
直接使用 PV 时,需要详细描述存储的配置信息,这对业务工程师并不友好。业务工程师只想知道我有多大的空间、I/O 是否满足要求,肯定不关心存储底层的配置细节。
为了简化存储的使用,Kubernetes 将存储服务再次抽象,把业务工程师关心的逻辑再抽象一层,于是有了 PVC(Persistent Volume Claim,持久卷声明),这种设计很像软件开发中的“面向对象”思想:
- PVC 可以理解为持久化存储的“接口”,它提供了对某种持久化存储的描述,但不提供具体的实现;
- 而持久化存储的实现部分则由 PV 负责完成。
这样设计的好处是,作为业务开发者,我们只需要与 PVC 这个“接口”进行交互,而不必关心存储的具体的实现是 NFS 还是 Ceph。请看下面 PVC 资源的 YAML 配置示例。可以看到,其中没有任何与存储实现相关的细节。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
现在,还有个问题,PV 和 PVC 两者之间并没有明确相关的绑定参数,它们之间是如何绑定的?PV 和 PVC 的绑定是自动的,依赖以下两个匹配条件:
- Spec 参数匹配:Kubernetes 会根据 PVC 中声明的规格自动寻找符合条件的 PV。这包括存储容量、所需的访问模式(如 ReadWriteOnce、ReadOnlyMany 或 ReadWriteMany),以及存储类型(如文件系统或块存储);
- 存储类匹配:PV 和 PVC 必须具有相同的 storageClassName,它定义了存储类型和特性,确保 PVC 请求的存储资源与 PV 提供的资源一致。
以下 YAML 配置展示了如何在 Pod 中使用 PVC。当 PVC 成功绑定到 PV 后,NFS 远程存储将被挂载到 Pod 内指定的目录,比如 nginx 容器中的 /data 目录。这样,Pod 内的应用就可以像使用本地存储一样,使用远程存储资源了。
apiVersion: v1
kind: Pod
metadata:
name: test-nfs
spec:
containers:
- image: nginx:alpine
imagePullPolicy: IfNotPresent
name: nginx
volumeMounts:
- mountPath: /data
name: nfs-volume
volumes:
- name: nfs-volume
persistentVolumeClaim:
claimName: pv-claim
PV 的使用:从手动到自动
在 Kubernetes 中,如果没有现成的 PV 满足 PVC 的需求,PVC 会保持在 Pending 状态,直到找到合适的 PV。在此期间,Pod 无法正常启动。对于小规模集群,可以提前手动创建多个 PV 以匹配 PVC,但在大规模集群中,Pod 数量可能达到成千上万,显然无法依靠人工方式提前创建如此多的 PV。
为此,Kubernetes 提供了一套自动创建 PV 的机制 —— 动态供给(Dynamic Provisioning)。相对而言,前面通过人工创建 PV 的方式被称为“静态供给”(Static Provisioning)。
动态供给的关键在于 Kubernetes 的 StorageClass 资源,它充当了 PV 模板的角色,使得 PV 可以根据需要自动生成。声明 StorageClass 时,必须明确两类信息:
- PV 的属性:定义 PV 的特性,包括存储空间的大小、读写模式(如 ReadWriteOnce、ReadOnlyMany 或 ReadWriteMany),以及回收策略(如 Retain、Recycle 或 Delete)等;
- Provisioner 的属性:确定存储供应商(即 Volume Plugin)及其相关参数。Kubernetes 支持两种类型的存储插件:
- In-Tree 插件:这些插件是 Kubernetes 源码的一部分,通常以前缀“kubernetes.io”命名,如 kubernetes.io/aws、kubernetes.io/azure 等。它们直接集成在 Kubernetes 项目中,为特定的存储服务提供支持;
- Out-of-Tree 插件:这些插件根据 Kubernetes 提供的存储接口由第三方存储供应商实现,代码独立于 Kubernetes 核心代码。Out-of-Tree 插件允许更灵活地集成各种存储解决方案,以适应不同的存储需求。
以下是一个 Kubernetes StorageClass 配置示例。该 StorageClass 使用 AWS Elastic Block Store(aws-ebs)作为存储供应商,并通过 type 属性设置为 gp2,表示使用 AWS 的通用型 SSD 卷。
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: standard provisioner: kubernetes.io/aws-ebs parameters: type: gp2 reclaimPolicy: Retain allowVolumeExpansion: true mountOptions: - debug volumeBindingMode: Immediate
当 StorageClass 资源提交到 Kubernetes 集群后,Kubernetes 会根据 StorageClass 定义的模板以及 PVC 的请求规格,自动创建一个新的 PV 实例。创建完成后,PV 会自动与 PVC 绑定,PVC 的状态从 Pending 转变为 Bound,表示存储资源已准备好。随后,Pod 就能使用 StorageClass 定义的存储类型了。
Kubernetes 存储系统设计
相信大部分读者对如何使用 Volume 已经没有疑问了。接下来,我们将继续探讨存储系统与 Kubernetes 的集成,以及它们是如何与 Pod 相关联的。
在深入这个高级主题之前,我们需要先掌握一些关于操作存储设备的基础知识。Kubernetes 继承了操作系统接入外置存储的设计,将新增或卸载存储设备分解为以下三个操作:
- 准备(Provision):首先,需要确定哪种设备进行 Provision。这一步类似于给操作系统准备一块新的硬盘,确定接入存储设备的类型、容量等基本参数。其逆向操作为 delete(移除)设备。
- 附加(Attach):接下来,将准备好的存储附加到系统中。Attach 可类比为将存储设备接入操作系统,此时尽管设备还不能使用,但你可以用操作系统的 fdisk -l 命令查看到设备。这一步确定存储设备的名称、驱动方式等面向系统的信息,其逆向操作为 Detach(分离)设备。
- 挂载(Mount):最后,将附加好的存储挂载到系统中。Mount 可类比为将设备挂载到系统的指定位置,这就是操作系统中 mount 命令的作用,其逆向操作为卸载(Unmount)存储设备。
注意
如果 Pod 中使用的是 EmptyDir、HostPath 这类 Volume,并不会经历附加/分离的操作,它们只会被挂载/卸载到某一个 Pod 中。
Kubernetes 中的 Volume 创建和管理主要由 VolumeManager(卷管理器)、AttachDetachController(挂载控制器)和 PVController(PV 生命周期管理器)负责。前面提到的 Provision、Delete、Attach、Detach、Mount 和 Unmount 操作由具体的 VolumePlugin(第三方存储插件,也称 CSI 插件)实现。
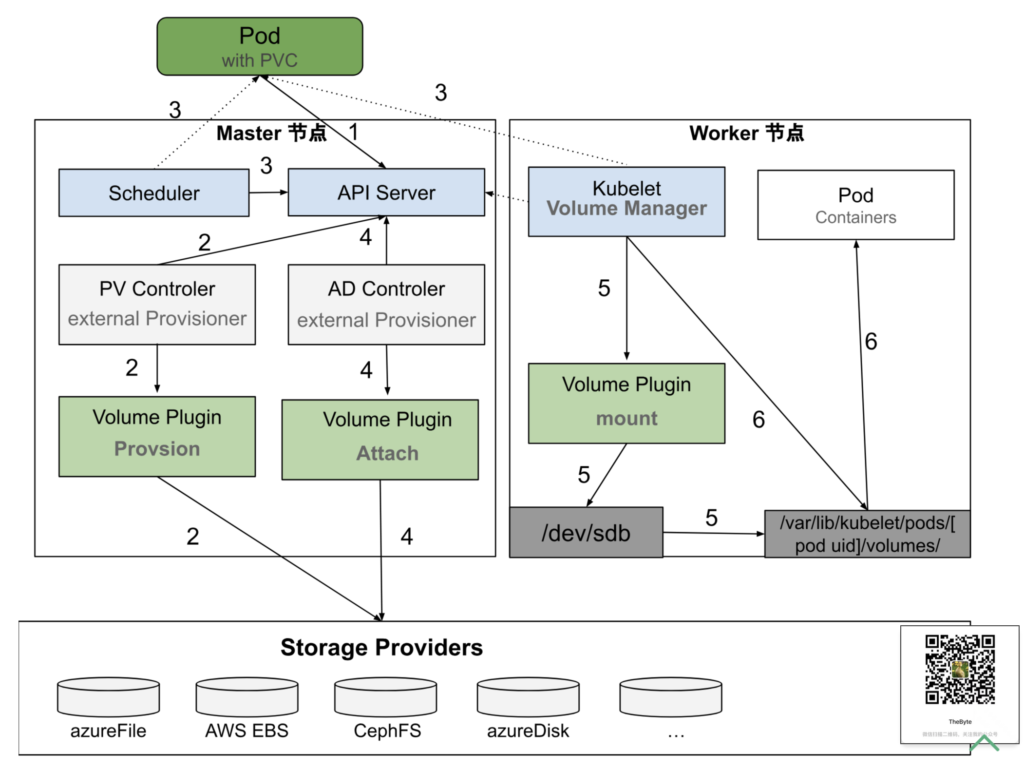
图 7-24 展示了一个带有 PVC 的 Pod 创建过程:
- 首先,用户创建一个包含 PVC 的 Pod,该 PVC 要求使用动态存储卷;
- 默认调度器 kube-scheduler 根据 Pod 配置、节点状态、PV 配置等信息,将 Pod 调度到一个合适的节点中;
- PVController 会持续监测 ApiServer,当发现一个 PVC 已创建但仍处于未绑定状态时,它会尝试将一个 PV 与该 PVC 进行绑定。首先,PVController 会在集群内查找适合的 PV;如果找不到相应的 PV,它会调用 Volume Plugin 中的接口执行 Provision 操作。Provision 过程包括从远程存储介质创建一个 Volume,并在集群中创建一个 PV 对象,然后将此 PV 与 PVC 绑定;
- 如果一个 Pod 被调度到某个节点后,它所定义的 PV 还没有被挂载,AttachDetachController 就会调用 Volume Plugin 中的接口,把远端的 Volume 挂载到目标节点中的设备上(例如:/dev/vdb);
- 在节点中,当 VolumeManager 发现一个 Pod 已调度到自己的节点上并且 Volume 已经完成挂载时,它会执行 mount 操作,将本地设备(即刚才得到的 /dev/vdb)挂载到 Pod 在节点上的一个子目录
/var/lib/kubelet/pods/[pod uid]/volumes/kubernetes.io~iscsi/[PV name](以 iSCSI 类型的存储为例); - 最后,Kubelet 启动 Pod,并使用 bind mount 方式将已挂载到本地目录的卷映射到 Pod 容器内。
图 Pod 挂载持久化 Volume 的过程
上述流程中第三方存储供应商实现 Volume Plugin 即 CSI(Container Storage Interface,容器存储接口)插件。CSI 是一个开放性的标准,目标是为容器编排系统(不仅仅是 Kubernetes,还包括 Docker Swarm 和 Mesos 等)提供统一的存储接口。
CSI 插件在实现上是一个可执行的二进制文件,它以 gRPC 的方式对外提供了三个主要的 gRPC 服务:Identity Service、Controller Service、Node Service 用于卷的管理、挂载和卸载等操作。笔者介绍如下:
其中,Identity Service 用于对外暴露插件本身的信息,它的接口定义如下:
service Identity {
// 返回插件的名称、版本和其他元数据。
rpc GetPluginInfo(GetPluginInfoRequest)
returns (GetPluginInfoResponse) {}
// 返回插件支持的功能,例如是否支持卷的快照等。
rpc GetPluginCapabilities(GetPluginCapabilitiesRequest)
returns (GetPluginCapabilitiesResponse) {}
rpc Probe (ProbeRequest)
returns (ProbeResponse) {}
}
Controller Service 管理卷的生命周期,包括创建、删除和获取卷的信息,它的接口定义如下所示。可以看出,接口中定义的操作就是图 7-24 Master 节点中 准备(Provision)和 附加(Attach)的逻辑。
service Controller {
// 创建一个新卷,并返回该卷的详细信息。
rpc CreateVolume (CreateVolumeRequest)
returns (CreateVolumeResponse) {}
// 删除指定的卷。
rpc DeleteVolume (DeleteVolumeRequest)
returns (DeleteVolumeResponse) {}
// 将卷绑定到特定的节点,准备后续的挂载操作。
rpc ControllerPublishVolume (ControllerPublishVolumeRequest)
returns (ControllerPublishVolumeResponse) {}
// 从节点解绑卷,准备进行删除或其他操作。
rpc ControllerUnpublishVolume (ControllerUnpublishVolumeRequest)
returns (ControllerUnpublishVolumeResponse) {}
...
Node Service 主要由 Kubelet 调用处理卷在节点上的挂载和卸载操作。它的接口定义如下:
service Node {
// 将卷挂载到节点的设备上,使其准备好被 Pod 使用。
rpc NodeStageVolume (NodeStageVolumeRequest)
returns (NodeStageVolumeResponse) {}
// 将卷从节点的设备中卸载。
rpc NodeUnstageVolume (NodeUnstageVolumeRequest)
returns (NodeUnstageVolumeResponse) {}
// 在指定的 Pod 中将卷挂载到容器的文件系统上。
rpc NodePublishVolume (NodePublishVolumeRequest)
returns (NodePublishVolumeResponse) {}
...
CSI 插件机制为存储供应商和容器编排系统之间的交互提供了标准化的接口。云存储厂商只需根据这一标准接口实现自己的云存储插件,即可无缝衔接 Kubernetes 的底层编排系统,Kubernetes 也由此具备了多样化的云存储、备份和快照等能力。
存储分类:块存储、文件存储和对象存储
得益 Kubernetes 的开放性设计,通过图 7-25 感受提供了 CSI 插件支持的存储生态,基本上包含了市面上所有的存储供应商。

上述众多的存储系统无法一一展开,但作为业务开发工程师而言,直面的问题是,我应该选择哪种存储类型?无论是内置的存储插件还是第三方的 CSI 存储插件,总结提供的存储服务类型就 3 种:块存储(Block Storage)、文件存储(File Storage)和对象存储(Object Storage)。这三种存储类型特点与区别,笔者介绍如下:
- 块存储:块存储是最接近物理介质的一种存储方式,常见的硬盘就属于块设备。块存储不关心数据的组织方式和结构,只是简单地将所有数据按固定大小分块,每块赋予一个用于寻址的编号。数据的读写通过与块设备匹配的协议(如 SCSI、SATA、SAS、FCP、FCoE、iSCSI 等)进行。块存储处于整个存储软件栈的底层,不经过操作系统,因此具有超低时延和超高吞吐。但缺点是每个块是独立的,缺乏集中控制机制来解决数据冲突和同步问题。因此,块存储设备通常不能共享,无法被多个客户端(节点)同时挂载。在 Kubernetes 中,块存储类型的 Volume 的访问模式必须是 RWO(ReadWriteOnce),即可读可写,但只能被单个节点挂载。由于块存储不关心数据的组织方式或内容,接口简单朴素,因此主要用于文件系统、专业备份管理软件、分区软件以及数据库,而非直接提供给普通用户。
- 文件存储:块设备存储的是最原始的二进制数据(0 和 1),对于人类用户来说,这样的数据既难以使用也难以管理。因此,我们使用“文件”这一概念来组织这些数据。所有用于同一用途的数据按照不同应用程序要求的结构方式组成不同类型的文件,并用不同的后缀来指代这些类型。每个文件有一个便于理解和记忆的名称。当文件数量较多时,通过某种划分方式对这些文件分组,所有文件和目录形成一个树状结构。再补充权限、文件名称、创建时间、所有者、修改者等元数据信息。这种定义文件分配、实现方式、存储信息和提供功能的标准被称为“文件系统”(File System)。常见的文件系统有 FAT32、NTFS、exFAT、ext2/3/4、XFS、BTRFS 等等。如果文件存储在网络服务器中,客户端用类似访问本地文件系统的方式访问远程服务器上的文件,这样的系统称为“网络文件系统”。常见的网络文件系统有 Windows 网络的 CIFS(Common Internet File System,也称 SMB)和类 Unix 系统的 NFS(Network File System)。
- 对象存储:文件存储的树状结构和路径访问方式便于人类理解、记忆和访问,但计算机需要逐级分解路径并查找,最终定位到所需文件,这对于应用程序而言既不必要,也浪费性能。块存储则性能出色,但难以理解且无法共享。选择困难症出现的同时,人们思考:“是否可以有一种既具备高性能、实现共享、又能满足大规模扩展需求的新型存储系统?”。于是,对象存储应运而生。对象存储中的“对象”可以理解为元数据与逻辑数据块的组合:
- 元数据提供了对象的上下文信息,如数据类型、大小、权限、创建人、创建时间等;
- 数据块则存储了对象的具体内容。
容器间通信的原理
要理解容器网络的工作原理,一定要从 Flannel 项目入手。Flannel 是 CoreOS 推出的容器网络解决方案,是业界公认是“最简单”的容器网络解决方案。接下来,笔者将以 Flannel 为例,介绍容器间通信的三种模式、容器网络接口(CNI)的设计及生态。
Overlay 覆盖网络模式
本书第三章 5.4 节已详细介绍了 Overlay 网络的设计思想。简而言之,它在现有三层网络之上“叠加”了一层由内核 VXLAN 模块管理的虚拟二层网络。
为在宿主机网络上构建虚拟二层通信网络(即建立隧道网络),VXLAN 模块会在通信双方配置特殊的网络设备作为隧道端点,称为 VTEP(VXLAN Tunnel Endpoints,VXLAN 隧道端点)。VTEP 是虚拟网络设备,具备 IP 地址和 MAC 地址。它根据 VXLAN 通信规范,负责将分布在不同节点和子网的“主机”(如容器或虚拟机)发送的数据包进行封装和解封,从而使它们能够像在同一局域网内一样进行通信。
上述基于 VTEP 设备构建“隧道”通信的流程,可以总结为图 7-26。
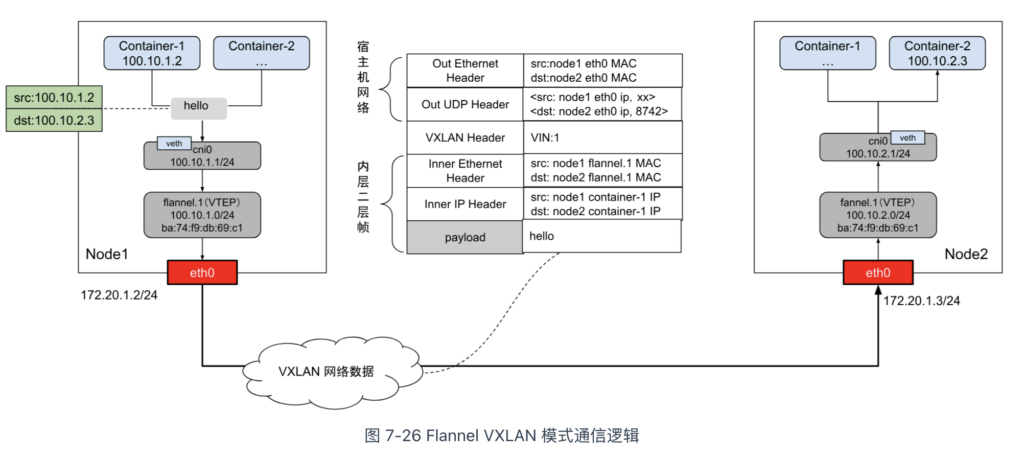
从图 7-26 可以看到,宿主机内的容器通过 veth-pair(虚拟网卡)桥接到名为 cni0 的 Linux Bridge。同时,每个宿主机都有一个名为 flannel.1 的设备,作为 VXLAN 所需的 VTEP 设备。当容器接收或发送数据包时,它们通过 flannel.1 设备进行封装和解封。
在 VXLAN 规范中,数据包由两层构成:
- 内层帧(Inner Ethernet Header),属于 VXLAN 逻辑网络;
- 外层帧(Outer Ethernet Header),属于宿主机网络。
当 Kubernetes 节点加入 Flannel 网络后,Flannel 会启动名为 flanneld 的服务,作为 DaemonSet 在集群中运行。flanneld 负责为每个节点内的容器分配子网,并同步集群内的网络配置信息,以确保各节点之间的网络连通性和一致性。
接下来,我们来分析当 Node1 中的 Container-1 与 Node2 中的 Container-2 通信时,Flannel 是如何进行封包和解包的。
首先,当 Container-1 发出请求时,目标地址为 100.10.2.3 的 IP 数据包会通过 cni0 Linux 网桥。由于该地址不在 cni0 网桥的转发范围内,数据包将被送入 Linux 内核协议栈,进一步路由到 flannel.1 设备进行处理。
Node1 中的路由信息由 flanneld 添加,规则大致如下:
[root@Node1 ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 100.10.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0 100.10.2.0 100.10.2.0 255.255.255.0 UG 0 0 0 flannel.1
上面两条路由的意思是:
- 凡是发往 100.10.1.0/24 网段的 IP 报文,都需要经过接口 cni0。
- 凡是发往 100.10.2.0/24 网段的 IP 报文,都需要经过接口 flannel.1,并且最后一跳的网关地址是 10.224.1.0(也就是 Node2 中 VTEP 的设备)。
根据上述路由规则,Container-1 发出的数据包会交由 flannel.1 设备处理,即数据包进入了隧道的“起始端点”。当“起始端点”接收到原始的 IP 数据包后,它会构造 VXLAN 网络的内层以太网帧,并将其发送到隧道网络的“目的端点”,即 Node2 中的 VTEP 设备。这样,虚拟二层网络就成功建立,容器可以跨节点进行通信。
构造 VXLAN 网络内层以太网帧的前提是,Node1 节点的 flannel.1 设备需要知道 Node2 中 flannel.1 设备的 IP 地址和 MAC 地址。当前,我们已经通过 Node1 的路由表获得了 VTEP 设备的 IP 地址(100.10.2.0)。那么,如何获取 flannel.1 设备的 MAC 地址呢?
实际上,Node2 中 VTEP 设备的 MAC 地址已由 flanneld 自动添加到 Node1 的 ARP 表中。在 Node1 中执行下面的命令:
[root@Node1 ~]# ip n | grep flannel.1 100.10.2.0 dev flannel.1 lladdr ba:74:f9:db:69:c1 PERMANENT # PERMANENT 表示永不过期
上面记录的意思是,IP 地址 10.10.2.0(也就是 Node2 flannel.1 设备的 IP)对应的 MAC 地址是 ba:74:f9:db:69:c1。
注意
这里 ARP 表记录并不是通过 ARP 协议学习得到的,而是 flanneld 预先为每个节点设置好的,没有过期时间。
现在,内层以太网帧已完成封装。接下来,Linux 内核将内层帧封装至宿主机 UDP 报文内,以“搭便车”的方式发送到宿主机的二层网络中。
为了实现“搭便车”机制,Linux 内核会在内层数据帧前添加一个特殊的 VXLAN Header,用于标识“乘客” 要转发给 VXLAN 模块处理。VXLAN Header 中有一个重要的标志 —— VNI(VXLAN Network Identifier),这是 VTEP 设备判断数据包是否属于自己处理的依据。在 Flannel 的 VXLAN 模式下,所有节点的 VNI 默认为 1,这也是 VTEP 设备命名为 flannel.1 的原因。
接下来,Linux 内核会将二层数据帧封装进宿主机的 UDP 报文。
在进行 UDP 封装时,首先需要确定四元组信息,即目的 IP 和目的端口。默认情况下,Linux 内核为 VXLAN 分配的 UDP 端口为 4789,因此目的端口为 4789。而目的 IP 地址则通过转发表(forwarding database,fdb)获取,fdb 表中的信息也由 flanneld 提前配置。在 Node1 中执行下面的命令:
[root@Node1 ~]# bridge fdb show | grep flannel.1 ba:74:f9:db:69:c1 dev flannel.1 dst 192.168.50.3 self permanent
上面记录的意思是,目的 MAC 地址为 ba:74:f9:db:69:c1( Node2 VTEP 设备的 MAC 地址)的数据帧封装后,应该发往哪个目的IP(192.168.50.3)。
至此,VTEP 设备已收集到所有封装所需的信息,并调用宿主机网络的 UDP 协议发送函数将数据包发出。接下来的过程与本机 UDP 程序发送数据包类似,就不再赘述了。
接下来,我们来看 Node2 收到数据包后的处理流程。
当数据包到达 Node2 的 8472 端口时,内核中的 VXLAN 模块会检查以下两个条件:
- VNI 比较:VXLAN 模块会检查 VXLAN Header 中的 VNI 是否与本机的 VXLAN 网络的 VNI 一致;
- MAC 地址比较:接着,比较内层数据帧中的目的 MAC 地址与本机的 flannel.1 设备的 MAC 地址是否匹配。
如果上述两个条件都满足,VXLAN 模块会去除数据包中的 VXLAN Header 和内层以太网帧 Header,恢复出 Container-1 原始发送的数据包。随后,根据 Node2 节点的路由规则(由 flanneld 提前配置),继续进行路由处理。
[root@Node2 ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface ... 100.10.2.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
从上面的路由规则可以看出,目标地址属于 100.10.2.0/24 网段的数据包会被交给 cni0 接口处理。接下来,数据包将按照 Linux 网桥的处理流程转发至对应的 Pod。
至此,Flannel VXLAN 模式的整个工作流程宣告结束。
三层路由模式
Flannel 的 host-gw 模式是“host gateway”的缩写。从名称可以看出,host-gw 工作模式通过宿主机路由表实现容器间通信。
该模式的工作原理简单明了,如图 7-27 所示。
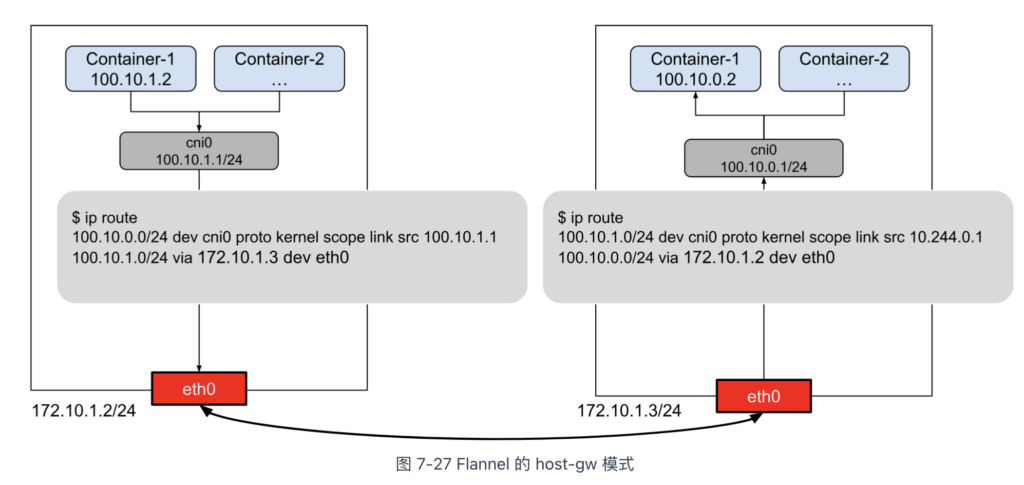
现在,假设 Node1 中的 container-1 与 Node2 中的 container-2 通信,我们来看 host-gw 模式是如何工作的。
首先,当 Kubernetes 节点加入 Flannel 网络后,flanneld 会在上面创建以下路由规则:
$ ip route 100.96.2.0/24 via 10.244.1.0 dev eth0
这条路由的含义是,目的地为 100.96.2.0/24 的 IP 包应通过 eth0 接口发送,其下一跳地址为 10.244.1.0(via 10.244.1.0)。
什么是下一跳
所谓“下一跳”是指 IP 数据包发送时需要经过某个路由设备的中转,下一跳的地址就是该中转路由设备的 IP 地址。例如,如果你个人电脑中配置的网关地址为 192.168.0.1,那么本机发出的所有 IP 包都需要经过 192.168.0.1 进行中转。
一旦确定了下一跳地址,Node1 中的 container-1 发出的 IP 包将被宿主机网络路由至下一跳地址,即 Node2 节点。
同样,Node2 中也有 flanneld 提前创建的路由规则。如下所示:
$ ip route 100.10.0.0/24 dev cni0 proto kernel scope link src 100.10.0.1
这条路由规则的含义是,目的地属于 100.10.0.0/24 网段的 IP 包应被送往 cni0 网桥。接下来的处理过程笔者就不再赘述了。
由此可见,Flannel 的 host-gw 模式实际上将每个容器子网(如 Node1 中的 100.10.1.0/24)的下一跳设置为目标主机的 IP 地址,利用宿主机的路由功能充当容器间通信的“路由网关”,这也是“host-gw”名称的由来。
host-gw 模式没有封包/解包的额外消耗,在性能表现上肯定优于前面介绍的 Overlay 模式。但由于它依赖于下一跳路由,因此它肯定无法用于宿主机跨子网的通信。
三层路由模式除了 Flannel 的 host-gw 模式外,还有一个更具代表性的项目 —— Calico。
Calico 和 Flannel 的原理都是直接利用宿主机的路由功能实现容器间通信,但不同之处在于Calico 通过 BGP 协议实现路由规则的自动化分发。因此 Calico 的灵活性更强,更适合大规模容器组网。
什么是 BGP
BGP(Border Gateway Protocol,边界网关协议)使用 TCP 作为传输层的路由协议,用于交互 AS(Autonomous System,自治域)之间的路由规则。每个 BGP 服务实例一般称为“BGP Router”,与 BGP Router 连接的对端称为“BGP Peer”。每个 BGP Router 收到 Peer 传来的路由信息后,经过校验判断后,将其存储在路由表中。
了解 BGP 协议之后,再看 Calico 的架构(图 7-28 ),就能理解它各个组件的作用了:
- Felix:负责在宿主机上插入路由规则,相当于 BGP Router;
- BGP Client:BGP 的客户端,负责在集群内分发路由规则,相当于 BGP Peer。
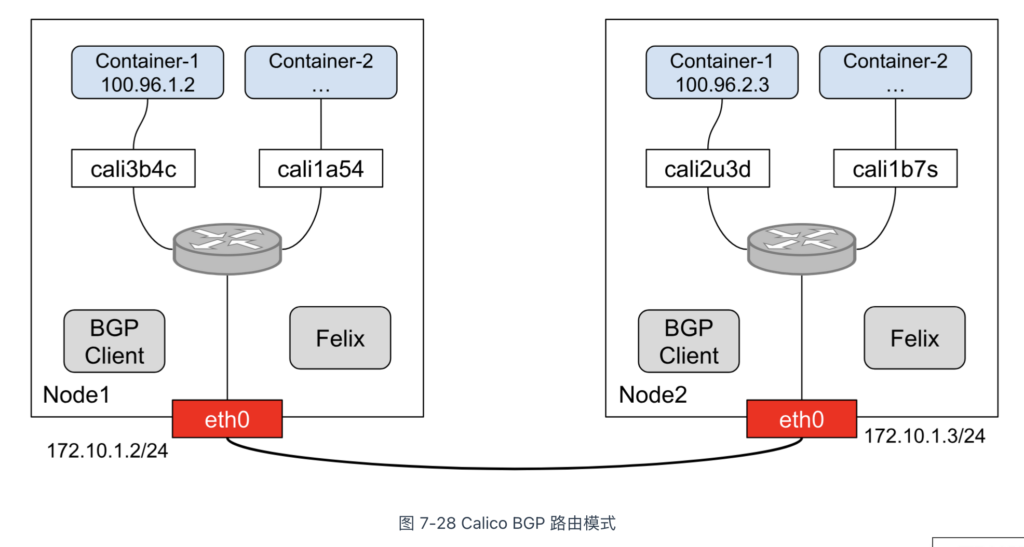
除了对路由信息的维护的区别外,Calico 与 Flannel 的另一个不同之处在于,它不会设置任何虚拟网桥设备。观察图 7-28,Calico 并未创建 Linux Bridge,而是将每个 Veth-Pair 设备的另一端放置在宿主机中(名称以 cali 为前缀),然后根据路由规则进行转发。例如,Node2 中 container-1 的路由规则如下:
$ ip route 10.223.2.3 dev cali2u3d scope link
这条路由规则的含义是,发往 10.223.2.3 的数据包应进入与 container-1 连接的 cali2u3d 设备(也就是 Veth-Pair 设备的另一端)。
由此可见,Calico 实际上将集群中每个节点的容器视为一个 AS(Autonomous System,自治域),并将节点视为边界路由器,节点之间相互交互路由规则,从而构建出容器间的三层路由网络。
Underlay 底层网络模式
接下来介绍的是最后一种容器间通信模式 —— Underlay 底层网络模式。
Underlay 模式本质上是直接利用宿主机的二层网络进行通信。在这种模式下,容器通常依赖于 MACVLAN 技术来组网。
MAC 地址通常是网卡接口的唯一标识,保持一对一关系。而 MACVLAN 技术打破了这一规则,它借鉴 VLAN 子接口的概念,在物理设备之上、内核网络栈之下创建多个“虚拟以太网卡”,每个虚拟网卡都有独立的 MAC 地址。
通过 MACVLAN 技术虚拟出的副本网卡在功能上与真实网卡完全对等。在接收到数据包后,物理网卡承担类似交换机的职责,它根据目标 MAC 地址判断该数据包应转发至哪块副本网卡处理(如图 7-29 所示)。
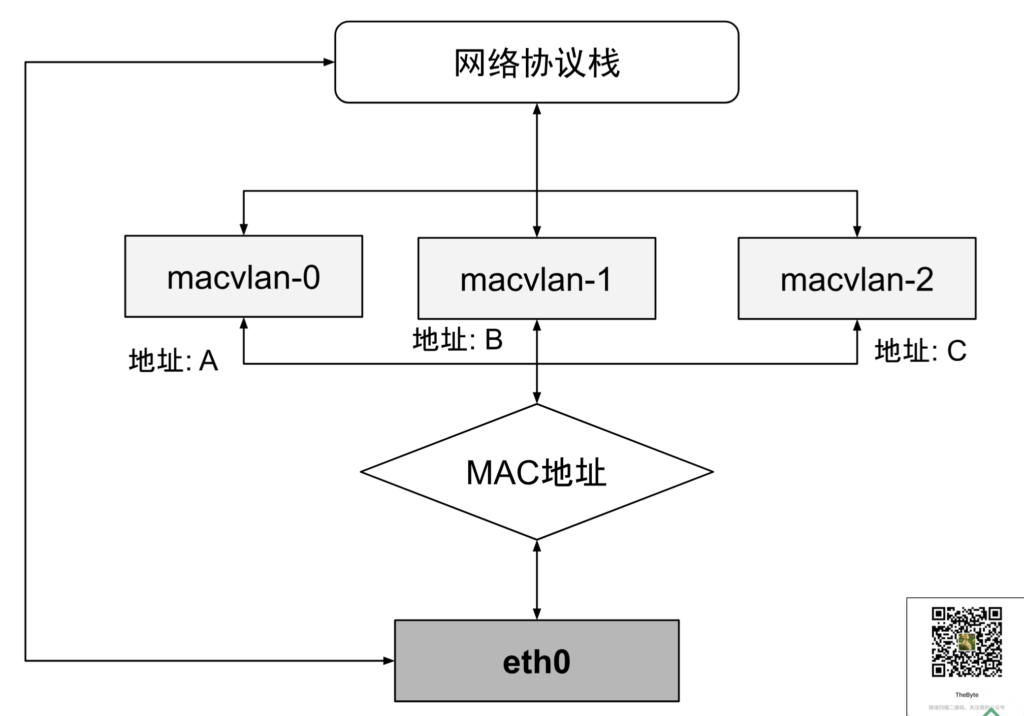
由于同一物理网卡虚拟出的副网卡天然位于同一子网(VLAN)内,因此它们可以直接在宿主机的二层网络中进行通信。
Docker 的网络模型中的 Macvlan 模式,正是利用上述“子设备”实现组网。Docker 使用 Macvlan 模式配置网络的命令如下:
$ docker network create -d macvlan \ --subnet=192.168.1.0/24 \ --gateway=192.168.1.1 \ -o parent=eth0 macvlan_network
可以看出,Underlay 底层网络模式直接利用物理网络资源,绕过了容器网络桥接和 NAT,因此具有最佳的性能表现。不过,由于依赖硬件和底层网络环境,部署时需要根据具体的软硬件条件进行调整,缺乏 Overlay 网络那样的开箱即用的灵活性。
CNI 插件及生态
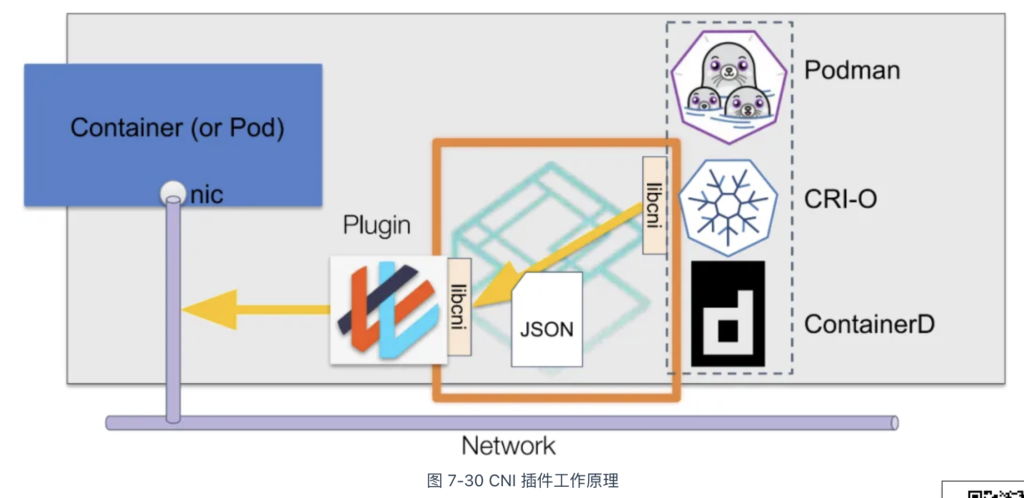
设计一个容器网络模型是一个很复杂的事情,Kubernetes 本身并不直接实现网络模型,而是通过 CNI(Container Network Interface,容器网络接口)把网络变成外部可扩展的功能。
CNI 接口最初由 CoreOS 为 rkt 容器创建,如今已成为容器网络的事实标准,广泛应用于 Kubernetes、Mesos 和 OpenShift 等容器平台。需要注意的是,CNI 接口并非类似于 CSI、CRI 那样的 gRPC 接口,而是指调用符合 CNI 规范的可执行程序,这些程序被称为“CNI 插件”。
以 Kubernetes 为例,Kubernetes 节点默认的 CNI 插件路径为 /opt/cni/bin。在该路径下,可以查看到可用的 CNI 插件,这些插件有的是内置的,有些是安装容器网络方案时自动下载的。
$ ls /opt/cni/bin/ bandwidth bridge dhcp firewall flannel calico-ipam cilium...
CNI 插件的大致工作流程如图 7-30 所示。在创建 Pod 时,容器运行时根据 CNI 配置规范(如设置 VXLAN 网络、配置节点容器子网等),通过标准输入(stdin)向 CNI 插件传递网络配置信息。待 CNI 插件完成网络配置后,容器运行时通过标准输出(stdout)接收配置结果。
举个具体例子,使用 Flannel 配置 VXLAN 网络,来帮助你理解 CNI 插件的工作流程。
首先,当在宿主机安装 flanneld 时,flanneld 启动会在每台宿主机生成对应的 CNI 配置文件,告诉 Kubernetes:该集群使用 flannel 容器网络方案。 CNI 配置文件通常位于 /etc/cni/net.d/ 目录下。它的配置如下所示:
{
"cniVersion": "0.4.0",
"name": "container-cni-list",
"plugins": [
{
"type": "flannel",
"delegate": {
"isDefaultGateway": true,
"hairpinMode": true,
"ipMasq": true,
"kubeconfig": "/etc/kube-flannel/kubeconfig"
}
}
]
}
接下来,容器运行时(如 CRI-O 或 containerd)会加载上述 CNI 配置文件,将 plugins 列表中的第一个插件(Flannel)设置为默认插件。在 Kubernetes 启动容器之前(即在创建 Infra 容器时),kubelet 调用 CNI 插件,传入下面两类参数,来为 Infra 容器配置网络。
- Pod 信息:如容器的唯一标识符、Pod 所在的命名空间、Pod 的名称等,这些信息一般组织成 JSON 对象;
- CNI 插件要执行的操作:
- add 操作:用于分配 IP 地址、创建 veth pair 设备等,并将容器添加到 Flannel 网络中;
- del 操作:用于清除容器的网络配置,将容器从 Flannel 网络中删除。
接下来,容器运行时会通过标准输入将上述参数传递给 CNI 插件。后续的逻辑则是 CNI 插件的具体操作,具体细节就不再赘述了。
echo '{
"cniVersion": "0.4.0",
"name": "flannel",
"type": "flannel",
"containerID": "abc123def456",
"namespace": "default",
"podName": "my-pod",
"netns": "/var/run/netns/abc123def456",
"ifname": "eth0",
"args": {
"isDefaultGateway": true
}
}' | /opt/cni/bin/flannel add abc123def456
最后,CNI 插件执行完毕后,会将容器的 IP 地址等信息返回给容器运行时,并由 kubelet 更新到 Pod 的状态字段中,整个容器网络配置就宣告结束了。
通过 CNI 这种开放性的设计,需要接入什么样的网络,设计一个对应的网络插件即可。这样一来节省了开发资源集中精力到 Kubernetes 本身,二来可以利用开源社区的力量打造一整个丰富的生态。现如今,如图 7-31 所示,支持 CNI 规范的网络插件多达几十种。这些网络插件笔者无法逐一解释,但就实现的容器通信模式而言,总结就上面三种类型:Overlay 覆盖网络模式、三层路由模式 和 Underlay 底层网络模式。

需要补充的是,对于容器编排系统而言,网络并非孤立的功能模块,还要配套各类的网络访问策略能力支持。例如,用来限制 Pod 出入站规则网络策略(NetworkPolicy),对网络流量数据进行分析监控等等额外功能。这些需求明显不属于 CNI 规范内的范畴,因此并不是每个 CNI 插件都会支持这些额外功能。如果你选择 Flannel 插件,必须配套其他插件(如 Calico 或 Cilium)才能启用网络策略。因此,有这方面需求的,应该考虑功能更全面的网络插件。
资源模型及编排调度
过去的集群管理平台(如 Mesos、Swarm)擅长的是,通过特定规则将容器调度到最佳节点上,这一功能称为“调度”。而 Kubernetes 擅长的,是根据系统规则和用户需求,自动化地处理好容器间的各种关系,这个功能就是我们常听到的 “编排”。
资源模型
在 Kubernetes 中,Pod 是最小的调度单元。因此,所有与调度和资源管理相关的属性都应包含在 Pod 对象中。
与调度密切相关的主要是 CPU 和内存的配置,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-5
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr-5
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
像 CPU 这类的资源被称作可压缩资源。这类资源不足时,Pod 内的进程变得卡顿,但 Pod 不会因此被杀掉。
Kubernetes 中的 CPU 资源计量单位为“个数”。例如,CPU=1 表示 Pod 的 CPU 限额为 1 个 CPU。具体的“1 个 CPU”定义取决于宿主机的硬件配置,它可能对应多核处理器中的一个核心、一个超线程(Hyper-Threading)或虚拟机中的一个虚拟处理器(vCPU)。对于不同硬件环境构建的 Kubernetes 集群,1 个 CPU 的实际算力可能有所不同,但 Kubernetes 只保证 Pod 能够使用到“1 个 CPU”这一逻辑单位的算力。
实际上,Kubernetes 中常用的 CPU 计量单位是毫核(Millcores,缩写 m)。1 个 CPU 等于 1000m。这样可以更精确地度量和分配 CPU 资源。例如,分配给某个容器 500m CPU,相当于 0.5 个 CPU。
像内存这样的资源被称作不可压缩资源。这类资源不足时,可能会杀死 Pod 中的进程,甚至驱逐整个 Pod。 对于内存资源来说,最基本的计量单位是字节。如果没有明确指定单位,默认以字节为计量单位。为了方便使用,Kubernetes 支持以 Ki、Mi、Gi、Ti、Pi、Ei 或 K、M、G、T、P、E 为单位来表示内存大小。例如,下面是一些相同内存值的不同表示方式:
128974848, 129e6, 129M, 123Mi
注意区分 Mi 和 M,1Mi=1024×1024,1M=1000×1000。随着数值的增加,Mi 和 M 计算的差异会越来越大,因此使用带小 i 的更准确。
资源分配
Kubernetes 使用以下两个属性来描述 Pod 的资源分配和限制:
- requests:表示容器请求的资源量,Kubernetes 会确保 Pod 获得这些资源。requests 是调度的依据,调度器只有在节点上有足够可用资源时,才会将 Pod 调度到该节点。
- limits:表示容器可使用的资源上限,防止容器过度消耗资源,导致节点过载。limits 会配置到 cgroups 中相应任务的 /sys/fs/cgroup 文件中。
Pod 是由一个或多个容器组成的,因此资源需求是在容器级别进行描述的。如图 7-32 所示,每个容器都可以通过 resources 属性单独设定相应的 requests 和 limits。例如,container-1 指定其容器进程需要 500m(即 0.5 个 CPU)才能被调度,并且允许最多使用 1000m(即 1 个 CPU)。
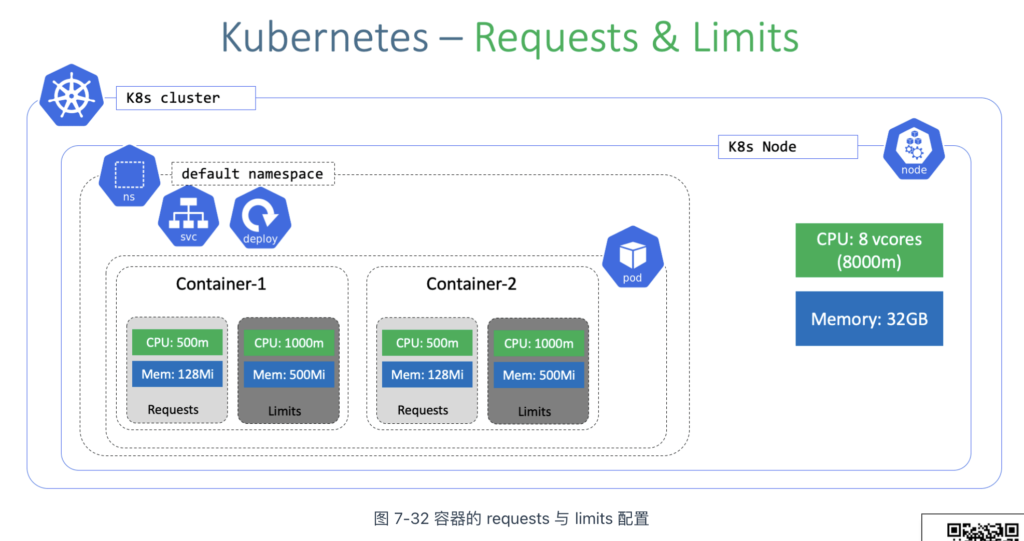
requests 和 limits 除了用于表明资源需求和限制资源使用之外,还有一个隐含功能,它决定了 Pod 的 QoS(Quality of Service,服务质量)等级。
服务质量等级
Kubernetes 根据每个 Pod 中容器资源配置情况,为 Pod 设置不同的服务质量(QoS,Quality of Service)等级。不同的 QoS 等级决定了当节点资源紧张时,Kubernetes 该如何处理节点上的 Pod,也就是接下来要讨论的驱逐(eviction)机制。
图 7-33 展示了 Pod 的 QoS 级别与资源配置之间的对应关系,具体名称及含义如下:
- Guaranteed:Pod 中每个容器必须配置相等的 CPU 和内存 requests 与 limits。此类 Pod 通常用于需要稳定资源的应用(如数据库)。在节点资源紧张时,Guaranteed 类型的 Pod 最不容易被驱逐。
- Burstable:Pod 中至少有一个容器设置了 requests 或 limits,但并非所有容器的请求和限制都相等。Burstable 类型的 Pod 在资源使用上有一定灵活性,但优先级低于 Guaranteed 类型。在节点资源紧张时,可能会被驱逐。
- Best Effort:Pod 中的容器没有设置 CPU 或内存的 requests 和 limits。Best Effort 类型的 Pod 通常用于临时或非关键任务,会尽可能使用可用资源,但在资源紧张时最容易被驱逐。
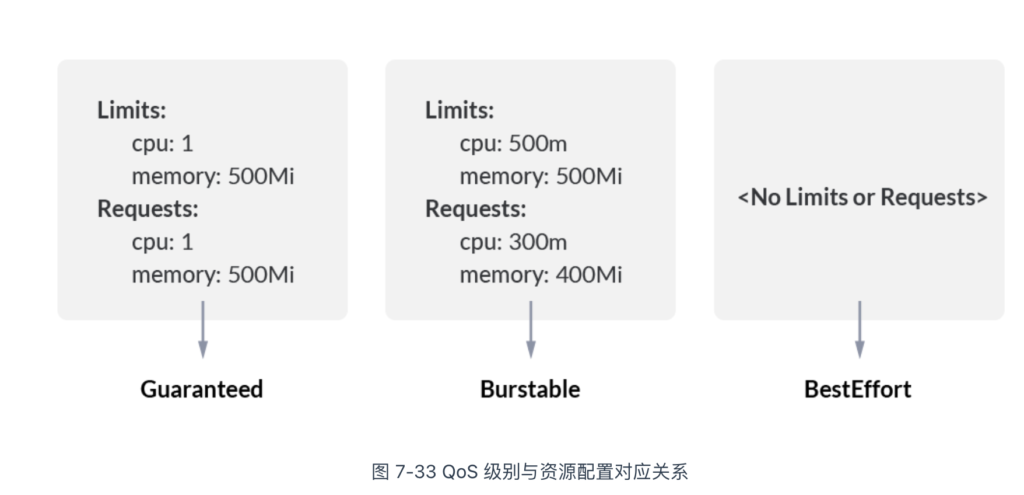
从上述描述可见,未配置 requests 和 limits 时,Pod 的 QoS 等级最低,在节点资源紧张时最容易受到影响。因此,合理配置 requests 和 limits 参数,能够提高调度精确度,并增强服务的稳定性。
节点资源管理
在 Kubernetes 系统中,每个节点都运行着容器运行时(如 Docker、containerd)以及负责管理容器的组件 kubelet。这些基础服务在节点上运行时,会占用一定的资源。因此,当 Kubernetes 进行资源管理时,必须为这些基础服务预先分配一部分资源。
Kubelet 通过下面两个参数,控制节点上基础服务的资源预留额度:
- –kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi]:预留给 Kubernetes 组件 CPU、内存和存储资源。
- –system-reserved=[cpu=100mi][,][memory=100Mi][,][ephemeral-storage=1Gi]:预留给操作系统的 CPU、内存和存储资源。
需要注意的是,考虑 Kubernetes 驱逐机制,kubelet 会确保节点上的资源使用率不会达到 100%。因此,Pod 实际可用的资源会更少一些。最终,一个节点的资源分配如图 7-34 所示。
Node Allocatable Resource(节点可分配资源)= Node Capacity(节点所有资源) – Kube Reserved(Kubernetes 组件预留资源)- System Reserved(系统预留资源)- Eviction Threshold(为驱逐预留的资源)。
图 Node 资源分配
驱逐机制
当不可压缩类型的资源(如可用内存 memory.available、宿主机磁盘空间 nodefs.available、镜像存储空间 imagefs.available)不足时,保证节点稳定的手段是驱逐(Eviction)那些不太重要的 Pod,使其能够重新调度到其他节点。
承担上述职责的组件为 kubelet。kubelet 运行在节点上,能够轻松感知节点的资源耗用情况。当 kubelet 发现不可压缩类型的资源即将耗尽时,触发两类驱逐策略。
kubelet 的第一种驱逐策略是软驱逐(soft eviction)。
由于节点资源耗用可能是临时性波动,通常会在几十秒内恢复。因此,当资源耗用达到设定阈值时,应先观察一段时间再决定是否触发驱逐操作。与软驱逐相关的 kubelet 配置参数如下:
- –eviction-soft:软驱逐触发条件。例如,可用内存(memory.available)< 500Mi,可用磁盘空间(nodefs.available)< 10% 等等。
- –eviction-soft-grace-period:软驱逐宽限期。例如,memory.available=2m30s,即可用内存 < 500Mi,并持续 2m30s 后,才真正开始驱逐 Pod。
- –eviction-max-pod-grace-period:Pod 优雅终止宽限期,该参数决定给 Pod 多少时间来优雅地关闭(graceful shutdown)。
kubelet 的第二种驱逐策略是硬驱逐(hard eviction)。
硬驱逐主要关注节点稳定性,防止资源耗尽导致节点不可用。硬驱逐相当直接,当 kubelet 发现节点资源耗用达到硬驱逐阈值时,会立即杀死相应的 Pod。与硬驱逐相关的 kubelet 配置参数仅有 –eviction-hard,其配置方式与 –eviction-soft 一致,笔者就不再赘述了。
需要注意的是,当 kubelet 驱逐部分 Pod 后,节点的资源使用可能在一段时间后再次达到阈值,进而触发新的驱逐,形成循环,这种现象称为“驱逐波动”。为了预防这种情况,kubelet 预留了以下参数:
- –eviction-minimum-reclaim:决定每次驱逐时至少要回收的资源量,以停止驱逐操作;
- –eviction-pressure-transition-period:决定 kubelet 上报节点状态的时间间隔。较短的上报周期可能导致频繁更改节点状态,从而引发驱逐波动。
最后,以下是与驱逐相关的 kubelet 配置示例:
$ kubelet --eviction-soft=memory.available<500Mi,nodefs.available < 10%,nodefs.inodesFree < 5%,imagefs.available < 15% \ --eviction-soft-grace-period=memory.available=1m30s,nodefs.available=1m30s \ --eviction-max-pod-grace-period=120 \ --eviction-hard=memory.available<500Mi,nodefs.available < 5% \ --eviction-pressure-transition-period=30s \ --eviction-minimum-reclaim="memory.available=500Mi,nodefs.available=500Mi,imagefs.available=1Gi"
扩展资源与设备插件
在 Kubernetes 中,节点的标准资源(如 CPU、内存和存储)由 Kubelet 自动报告,但节点内的异构硬件资源(如 GPU、FPGA、RDMA 或硬件加速器),Kubernetes 并未识别和管理。
扩展资源
作为通用的容器编排平台,Kubernetes 需要集成各种异构硬件资源,以满足更广泛的计算需求。为此,Kubernetes 提供了“扩展资源”(Extended Resource)机制,允许用户像使用标准资源一样声明和调度特殊硬件资源。
为了让调度器了解节点的异构资源,节点需向 API Server 报告资源情况。报告方式是通过向 Kubernetes API Server 发送 HTTP PATCH 请求。例如,某节点拥有 4 个 GPU 资源,以下是相应的 PATCH 请求示例:
PATCH /api/v1/nodes/<your-node-name>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "add",
"path": "/status/capacity/nvidia.com~1gpu",
"value": "4"
}
]
需要注意的是,上述 PATCH 请求仅告知 Kubernetes,节点 <your-node-name> 拥有 4 个名为 GPU 的资源,但 Kubernetes 并不理解 GPU 资源的具体含义和用途。
接着,运行 kubectl describe node 命令,查看节点资源情况。从输出结果中可以看到,之前扩展的 nvidia.com/gpu 资源容量为 4。
$ kubectl describe node <your-node-name> ... Status Capacity: cpu: 2 memory: 2049008Ki nvidia.com/gpu: 4
在完成上述操作后,配置 Pod 的 YAML 文件时,就可以像配置标准资源(如 CPU 和内存)一样,为自定义资源(例如 nvidia.com/gpu)设置 request 和 limits。以下是包含 nvidia.com/gpu 资源申请的 Pod 配置示例:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: cuda-container
image: nvidia/cuda:10.0-base
resources:
request:
nvidia.com/gpu: 1
在上述 Pod 资源配置中,GPU 的资源名称为 nvidia.com/gpu,并且为其分配了 1 个该资源的配额。这表明 Kubernetes 调度器会将该 Pod 调度到具有足够 nvidia.com/gpu 资源的节点上。
一旦 Pod 成功调度到目标节点,系统将自动执行一系列配置操作,例如设置环境变量、挂载 GPU 设备驱动等。这些操作完成后,容器内的程序便可使用 GPU 资源了。
设备插件
除非特殊情况,通常不需用手动的方式扩展异构资源。
在 Kubernetes 中,管理异构资源主要通过一种称为设备插件(Device Plugin)的机制负责。该机制的原理是,通过定义一系列标准化的 gRPC 接口,使 kubelet 能够与设备插件进行交互,从而实现设备发现、状态更新以及资源上报等功能。
具体来说,设备插件定义了如下 gRPC 接口,硬件设备插件按照这些规范实现接口后,即可与 kubelet 进行交互。
service DevicePlugin {
// 返回设备插件的配置选项。
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// 实时监控设备资源的状态变化,并将设备资源信息上报至 Etcd 中。
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// 执行特定设备的初始化操作,并告知 kubelet 如何使设备在容器中可用。
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// 从一组可用的设备中返回一些优选的设备用来分配。
rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
// 在容器启动之前调用,用于特定于设备的初始化操作。确保容器能够正确地访问和使用特定的硬件资源。
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
目前,Kubernetes 社区已有多个专用设备插件,涵盖 NVIDIA GPU、Intel GPU、AMD GPU、FPGA 和 RDMA 等硬件。以 GPU 设备插件为例,其工作原理如下:
- 设备发现与注册:设备插件在节点上运行,自动检测并将 GPU 资源注册到 Kubernetes API,例如,NVIDIA GPU 设备插件将 GPU 注册为 nvidia.com/gpu;
- 资源暴露与分配:设备插件通过 Kubernetes API 将 GPU 资源暴露给 Pod,Pod 可通过 request 和 limit 字段声明所需的 GPU 资源,例如,Pod 可以在 limits 中指定 nvidia.com/gpu: 1 来请求一个 NVIDIA GPU;
- 调度与使用:当 Pod 请求特殊硬件资源时,Kubernetes 调度器根据节点的资源状态和 Pod 的需求进行调度。一旦 Pod 被调度并分配了资源,kubelet 调用设备插件的 Allocate 接口获取设备配置信息(如设备路径、驱动目录),并将这些信息添加到容器创建请求中。最终,容器运行时(如 Docker、Containerd)会将硬件驱动目录挂载到容器内,容器中的应用程序即可直接访问这些设备了。
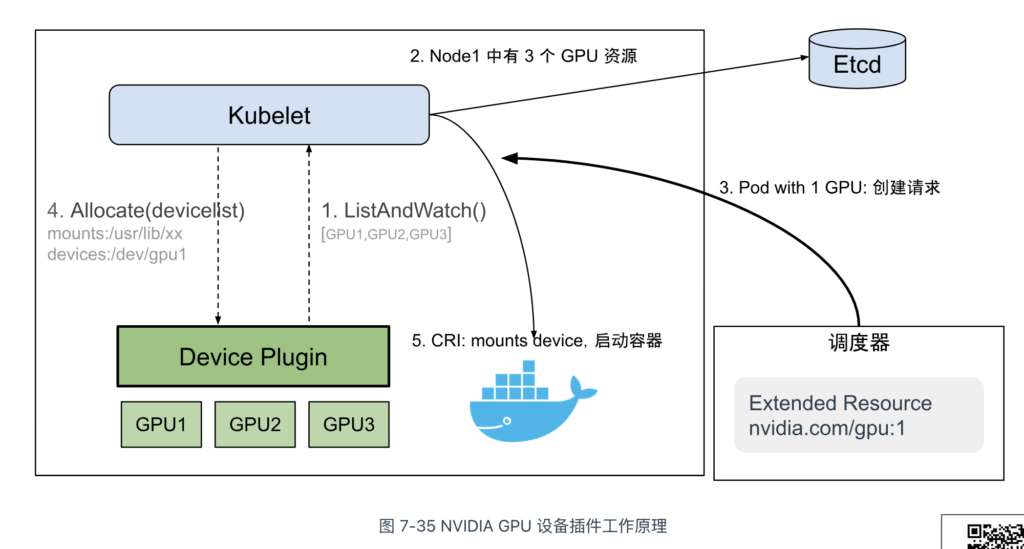
最后,再来看扩展资源和设备插件的问题。Pod 只能通过类似“nvidia.com/gpu:2”的计数方式申请 2 个 GPU,但这些 GPU 的具体型号、拓扑结构、是否共享等属性并不明确。也就是说,设备插件仅实现了基本的入门级功能,能用,但不好用。
在“成本要省”、“资源利用率要高”背景推动下,Nvidia、Intel 等头部厂商联合推出了“动态资源分配”(Dynamic Resource Allocation,DRA)机制,允许用户以更复杂的方式描述异构资源,而不仅仅是简单的计数形式。DRA 属于较新的机制,具体的接口规范因硬件供应商和 Kubernetes 版本不同而有所变化。限于篇幅,笔者就不再扩展讨论了,有兴趣的读者请查阅其他资料。
默认调度器及扩展设计
如果节点只有几十个,为新建的 Pod 找到合适的节点并不困难。但当节点的数量扩大到几千台甚至更多时,情况就复杂了:
- 首先,节点资源无时无刻不在变化,如果每次调度都需要数千次远程请求获取信息,势必因耗时过长,增加调度失败的风险。
- 其次,调度器频繁发起网络请求,极容易成为集群的性能瓶颈,影响整个集群的运行。
为了充分利用硬件资源,通常会将各种类型(CPU 密集、IO 密集、批量处理、低延迟作业)的 workloads 运行在同一台机器上,这种方式减少了硬件上的投入,但也使调度问题更加复杂。
随着集群规模的增大,需要调度的任务的规模也线性增大,由于调度器的工作负载与集群大小大致成比例,调度器有成为可伸缩性瓶颈的风险。
Omega 论文中提出了一种基于“共享状态”(Scheduler Cache)的双循环调度机制,用来解决大规模集群的调度效率问题。双循环的调度机制不仅应用在 Google 的 Omega 系统中,也被 Kubernetes 继承下来。
Kubernetes 默认调度器(kube-scheduler)双循环调度机制如图 7-36 所示。
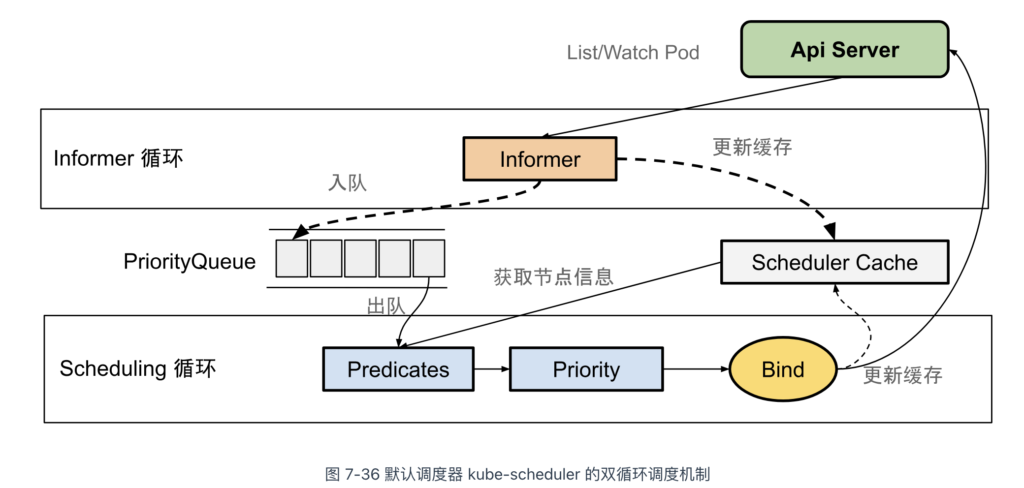
根据图 7-36 可以看出,Kubernetes 调度的核心在于两个互相独立的控制循环。
第一个控制循环被称为“Informer 循环”。其主要逻辑是启动多个 Informer 来监听 API 资源(主要是 Pod 和 Node)状态的变化。一旦资源发生变化,Informer 会触发回调函数进行进一步处理。例如,当一个待调度的 Pod 被创建时,Pod Informer 会触发回调,将 Pod 入队到调度队列(PriorityQueue),以便在下一阶段处理。
当 API 资源发生变化时,Informer 的回调函数还负责更新调度器缓存(Scheduler Cache),以便将 Pod 和 Node 信息尽可能缓存,从而提高后续调度算法的执行效率。
第二个控制循环是“Scheduling 循环”。其主要逻辑是从调度队列(PriorityQueue)中不断出队一个 Pod,并触发两个核心的调度阶段:预选阶段(图 7-36 中的 Predicates)和优选阶段(图 7-36 中的 Priority)。
Kubernetes 从 v1.15 版本起,为默认调度器(kube-scheduler)设计了可扩展的机制 —— Scheduling Framework。其主要目的是在调度器生命周期的关键点(如图7-37中的绿色矩形箭头框所示)暴露可扩展接口,允许实现自定义的调度逻辑。这套机制基于标准 Go 语言插件机制,需要按照规范编写 Go 代码并进行静态编译集成,其通用性相较于 CNI、CSI 和 CRI 等较为有限。
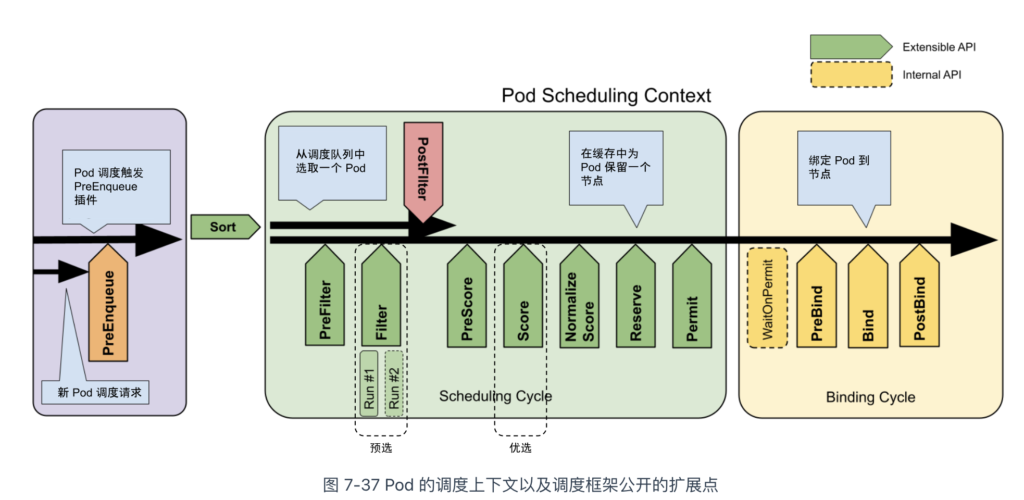
接下来,我们回到调度处理逻辑,首先来看预选阶段的处理。
预选阶段的主要逻辑是在调度器生命周期的 PreFilter 和 Filter 阶段,调用相关的过滤插件,筛选出符合 Pod 要求的节点集合。以下是 Kubernetes 默认调度器内置的一些筛选插件:
// k8s.io/kubernetes/pkg/scheduler/algorithmprovider/registry.go
func getDefaultConfig() *schedulerapi.Plugins {
...
Filter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: nodeunschedulable.Name},
{Name: noderesources.FitName},
{Name: nodename.Name},
{Name: nodeports.Name},
{Name: nodeaffinity.Name},
{Name: volumerestrictions.Name},
{Name: tainttoleration.Name},
{Name: nodevolumelimits.EBSName},
{Name: nodevolumelimits.GCEPDName},
{Name: nodevolumelimits.CSIName},
{Name: nodevolumelimits.AzureDiskName},
{Name: volumebinding.Name},
{Name: volumezone.Name},
{Name: interpodaffinity.Name},
},
},
}
上述插件本质上是按照 Scheduling Framework 规范实现 Filter 方法,根据一系列预设的策略筛选节点。它们的筛选策略可以总结为以下三类:
- 通用过滤策略:负责基础的筛选操作,例如检查节点是否有足够的可用资源满足 Pod 请求,或检查 Pod 请求的宿主机端口是否与节点中的端口冲突。相关插件包括 noderesources、nodeports 等。。
- 节点相关的过滤策略:与节点特性相关的筛选策略。例如,检查 Pod 的污点容忍度(tolerations)是否匹配节点的污点(taints),检查 Pod 的节点亲和性(nodeAffinity)是否与节点匹配,或检查 Pod 与节点中已有 Pod 之间的亲和性(Affinity)和反亲和性(Anti-Affinity)。相关插件包括 tainttoleration、interpodaffinity、nodeunschedulable 等。
- Volume 相关的过滤策略:与存储卷相关的筛选策略。例如,检查 Pod 挂载的 PV 是否冲突(如 AWS EBS 类型的 Volume 不允许多个 Pod 同时使用),或者检查节点上某类型 PV 的数量是否超限。相关插件包括 nodevolumelimits、volumerestrictions 等。
预选阶段执行完毕后,会得到一个可供 Pod 调度的节点列表。如果该列表为空,表示 Pod 无法调度。至此,预选阶段宣告结束,接着进入优选阶段。
优选阶段的设计与预选阶段类似,主要通过调用相关的打分插件,对预选阶段得到的节点进行排序,选择出评分最高的节点来运行 Pod。
Kubernetes 默认调度器内置的打分插件如下所示。与筛选插件不同,打分插件额外包含一个权重属性。
// k8s.io/kubernetes/pkg/scheduler/algorithmprovider/registry.go
func getDefaultConfig() *schedulerapi.Plugins {
...
Score: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: noderesources.BalancedAllocationName, Weight: 1},
{Name: imagelocality.Name, Weight: 1},
{Name: interpodaffinity.Name, Weight: 1},
{Name: noderesources.LeastAllocatedName, Weight: 1},
{Name: nodeaffinity.Name, Weight: 1},
{Name: nodepreferavoidpods.Name, Weight: 10000},
{Name: defaultpodtopologyspread.Name, Weight: 1},
{Name: tainttoleration.Name, Weight: 1},
},
}
...
}
优选阶段最重要的策略是 NodeResources.LeastAllocated,它的计算公式如下:
score=(capacitycpu−∑podsrequestedcpu)×10capacitycpu+(capacitymemeory−∑pods(requestedmemeory))×10capacitymemeory2score=2capacitycpu(capacitycpu−∑podsrequestedcpu)×10+capacitymemeory(capacitymemeory−∑pods(requestedmemeory))×10
上述公式实际上是根据节点中 CPU 和内存资源的剩余量进行打分,从而使 Pod 更倾向于调度到资源使用较少的节点,避免某些节点资源过载而其他节点资源闲置。
与 NodeResources.LeastAllocated 策略配合使用的,还有 NodeResources.BalancedAllocation 策略,它的计算公式如下:
score=10−variance(cpuFraction,memoryFraction,volumeFraction)×10score=10−variance(cpuFraction,memoryFraction,volumeFraction)×10
这里的 Fraction 指的是资源利用比例。笔者以 cpuFraction 为例,它的计算公式如下:
cpuFraction= Pod 的 CPU 请求节点中 CPU 总量cpuFraction=节点中 CPU 总量 Pod 的 CPU 请求
memoryFraction 和 volumeFraction 也是类似的概念。Fraction 算法的主要作用是计算资源利用比例的方差,以评估节点的资源(CPU、内存、volume)分配是否均衡,避免出现 CPU 被过度分配而内存浪费的情况。方差越小,说明资源分配越均衡,得分也就越高。
除了上述两种优选策略外,还有 InterPodAffinity(根据 Pod 之间的亲和性、反亲和性规则来打分)、Nodeaffinity(根据节点的亲和性规则来打分)、ImageLocality(根据节点中是否缓存容器镜像打分)、NodePreferAvoidPods(基于节点的注解信息打分)等等,笔者就不再一一解释了。
值得注意的是,打分插件的权重可以在调度器配置文件中进行设置,以调整它们在调度决策中的影响力。例如,如果希望更重视 NodePreferAvoidPods 插件的打分结果,可以为该插件分配更高的权重,如下所示:
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
plugins:
score:
enabled:
- name: NodePreferAvoidPods
weight: 10000
- name: InterPodAffinity
weight: 1
...
经过优选阶段之后,调度器根据预定的打分策略为每个节点分配一个分数,最终选择出分数最高的节点来运行 Pod。如果存在多个节点分数相同,调度器则随机选择其中一个。
选择出最终目标节点后,接下来就是通知目标节点内的 kubelet 创建 Pod 了。
在这一阶段,调度器不会直接与 kubelet 通信,而是将 Pod 对象的 nodeName 修改为选定节点的名称。kubelet 会持续监控 Etcd 中 Pod 信息的变化,发现变动后执行一个名为“Admin”的本地操作,确认资源可用性和端口是否冲突。这相当于执行一遍通用的过滤策略,对 Pod 是否能在该节点运行进行二次确认。
不过,从调度器更新 Etcd 中的 nodeName 到 kubelet 检测到变化,再到二次确认是否可调度,这一过程可能会持续一段不等的时间。如果等到所有操作完成才宣布调度结束,势必会影响整体调度效率。
调度器采用了“乐观绑定”(Optimistic Binding)策略来解决上述问题。首先,调度器更新 Scheduler Cache 里的 Pod 的 nodeName 的信息,并发起异步请求 更新 Etcd 中的远程信息,该操作在调度生命周期中称 Bind。如果调度成功了,Scheduler Cache 和 Etcd 中的信息势必一致。如果调度失败了(也就是异步更新失败),也没有太大关系。因为 Informer 会持续监控 Pod 变化,只要将调度成功、但没有创建成功的 Pod nodeName 字段清空,然后同步至调度队列,待下一次调度解决即可。
资源弹性伸缩
为了平衡资源预估和实际使用之间的差距,Kubernetes 提供了 HPA、VPA 和 CA 三种自动扩缩(autoscaling)机制。
Pod 水平自动伸缩
HPA(Horizontal Pod Autoscaler,Pod 水平自动扩缩)是根据工作负载(如 Deployment)的资源使用情况调整 Pod 副本数量的机制。
HPA 的工作原理简单明了:
- 当负荷较高时,增加 Pod 副本数量;
- 当负荷较低时,减少 Pod 副本数量。
因此,自动伸缩的关键在于准确监控资源使用情况。为此,Kubernetes 提供了 Metrics API,用于获取节点和 Pod 的资源信息。以下是 Metrics API 的响应示例,展示了 CPU 和内存的使用情况。
$ kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes/minikube" | jq '.'
{
"kind": "NodeMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "minikube",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/minikube",
"creationTimestamp": "2022-01-27T18:48:43Z"
},
"timestamp": "2022-01-27T18:48:33Z",
"window": "30s",
"usage": {
"cpu": "487558164n",
"memory": "732212Ki"
}
}
最初,Metrics API 仅支持 CPU 和内存指标。随着需求的增加,Metrics API 扩展了对用户自定义指标(Custom Metrics)的支持。用户可以开发 Custom Metrics Server,并通过调用其他服务(如 Prometheus)来监控应用程序、系统资源、服务性能及外部系统的繁忙程度。
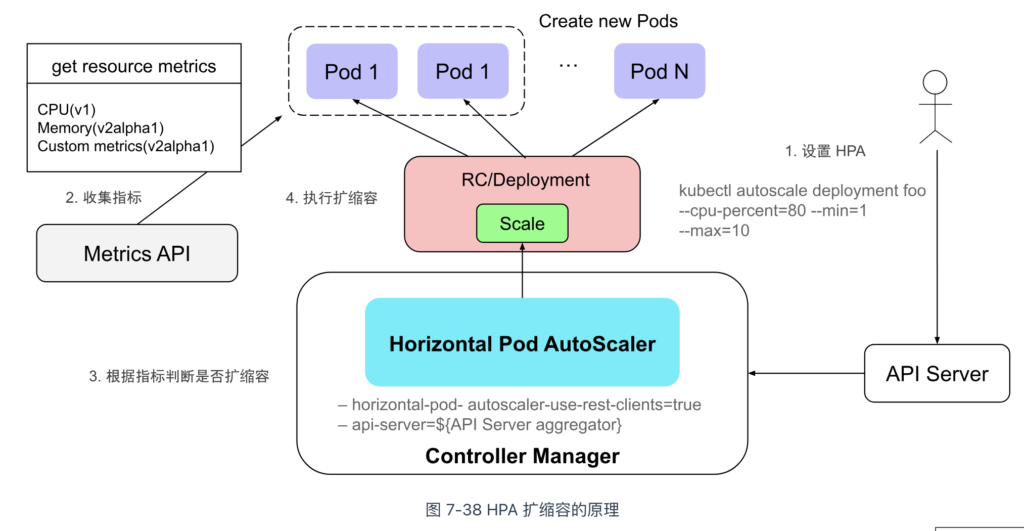
接下来介绍 HPA 的使用方式。如图 7-38 所示,使用 kubectl autoscale 命令创建 HPA,设置监控指标类型(如 cpu-percent)、目标值(如 70%)以及 Pod 副本数量的范围(最少 1 个,最多 10 个)。
$ kubectl autoscale deployment foo --cpu-percent=70 --min=1 --max=10
随后,HPA 定期获取 Metrics 数据,与设定的目标值比较,决定是否进行扩缩。如果需要扩缩,HPA 调用 Deployment 的 Scale 接口调整副本数量,将每个 Pod 的负荷维持在用户期望的水平。
Pod 垂直自动伸缩
VPA(Vertical Pod Autoscaler)是 Pod 的垂直自动伸缩组件。其工作原理与 HPA 类似,两者都是通过 Metrics API 获取指标并进行评估调整。不同之处在于,VPA 调整的是工作负载的资源配额,例如 Pod 的 CPU 和内存的 request 和 limit。
需要注意的是,VPA 是 Kubernetes 的附加组件,必须安装并配置后,才能为工作负载(如 Deployment)定义资源调整策略。以下是一个 VPA 配置示例,供参考:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: example-app-vpa
namespace: default
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: example-app
updatePolicy:
updateMode: Auto # 决定 VPA 如何应用推荐的资源调整,也可以设置为 "Off" 或 "Initial" 来控制更新策略
将上述 YAML 文件提交到 Kubernetes 集群后,可以通过 kubectl describe vpa 命令查看 VPA 推荐的资源策略:
$ kubectl describe vpa example-app-vpa
...
Recommendation:
Container Recommendations:
Container Name: nginx
Lower Bound:
Cpu: 25m
Memory: 262144k
Target:
Cpu: 25m
Memory: 262144k
Uncapped Target:
Cpu: 25m
Memory: 262144k
Upper Bound:
Cpu: 11601m
Memory: 12128573170
...
可以看出,VPA 更适用于负载变化较大、资源需求不确定的场景,尤其在无法精确预估应用资源需求时。
基于事件驱动的伸缩
虽然 HPA 基于 Metrics API 实现了弹性伸缩,但其指标范围有限且粒度较粗。为了支持基于外部事件的更细粒度扩缩容,微软与红帽联合开发了 KEDA(Kubernetes Event-driven Autoscaling)。
KEDA 的出现并非为了取代 HPA,而是与其互补。其工作原理如图 7-39 所示:用户通过配置 ScaledObject(缩放对象)来定义 Scaler(KEDA 内部组件)的行为,Scaler 持续从外部系统获取状态数据,并与扩缩条件进行比较。当条件满足时,Scaler 触发扩缩操作,调用 Kubernetes 的 HPA 组件调整工作负载的 Pod 副本数。
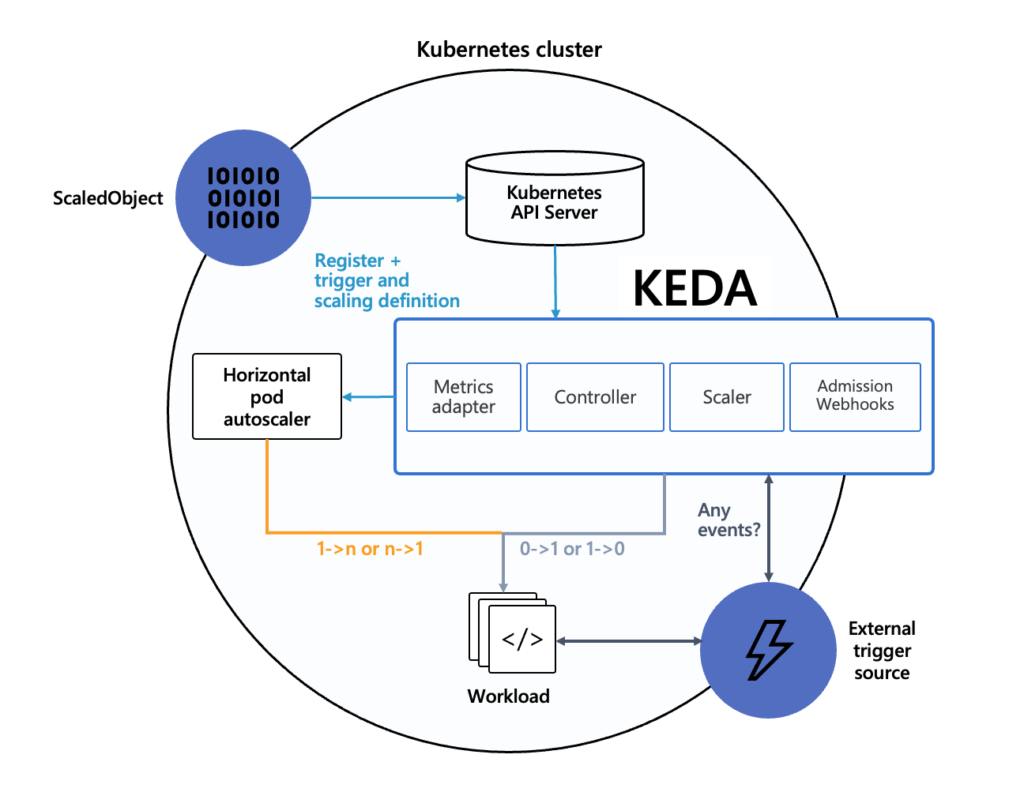
KEDA 内置了多种常见的 Scaler,用于处理特定的事件源或指标源。以下是部分 Scaler 示例,供参考:
- 消息队列 Scaler:获取 Kafka、RabbitMQ、Azure Queue、AWS SQS 等消息队列的消息数量。
- 数据库 Scaler:获取 SQL 数据库的连接数、查询延迟等。
- HTTP 请求 Scaler:获取 HTTP 请求数量或响应时间。
- Prometheus Scaler:通过 Prometheus 获取自定义指标来触发扩缩操作,如队列长度、CPU 使用率等业务特定指标。
- 时间 Scaler:根据特定时间段触发扩缩逻辑,如每日的高峰期或夜间低峰期。
以下是 Kafka Scaler 的配置示例,它监控某个 Kafka 主题中的消息数量:
- 当消息队列超过设定阈值时,触发扩容操作,增加 Pod 副本数量,以提高消息处理吞吐量;
- 当消息队列为空时,触发缩减操作,减少 Pod 副本数量,降低资源成本( Pod 数可缩减至 0,minReplicaCount)。
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kafka-scaledobject
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: brm-index-basic
pollingInterval: 10
minReplicaCount: 0
maxReplicaCount: 20
triggers:
- type: kafka
metadata:
bootstrapServers: kafka-server:9092
consumerGroup: basic
topic: basic
lagThreshold: "100"
offsetResetPolicy: latest
节点自动伸缩
业务增长(或萎缩)可能导致集群资源不足或过度冗余。如果能够根据集群资源情况自动调整节点数量,不仅能保证集群的可用性,还能最大程度地降低资源成本。
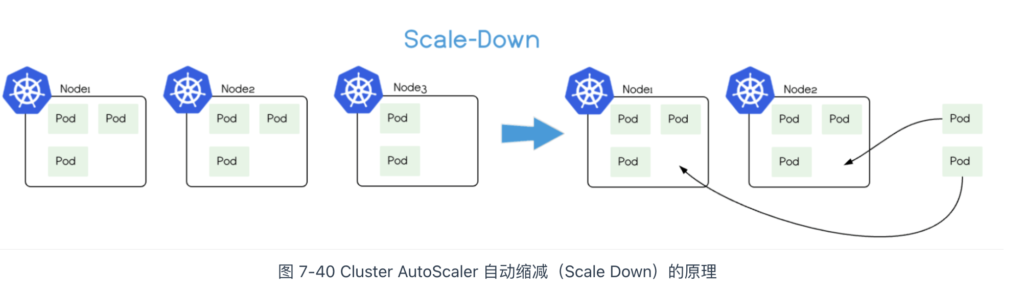
CA(Cluster AutoScaler)是专门用于调整节点的组件,其功能如下:
- 自动扩展(Scale Up):当节点资源不能满足 Pod 需求时,Cluster AutoScaler 向云服务提供商(如 GCE、GKE、Azure、AKS、AWS 等)请求创建新的节点,扩展集群容量,确保业务能够获得所需的资源。
- 自动缩减(Scale Down):当节点资源利用率长期处于低水平(如低于 50%),Cluster AutoScaler 将该节点上的 Pod 调度到其他节点,然后将节点从集群中移除,避免资源浪费。
最后,Cluster Autoscaler 是 Kubernetes 官方提供的组件,但它深度依赖于公有云厂商。因此,具体的使用方法、功能和限制取决于云厂商的实现,笔者就不再过多介绍了。
小结
本章,笔者从 Google 内部容器系统演进作为开篇,从网络、计算、存储、调度等方面展开,深入分析了 Kubernetes 的设计原理和应用。希望能让你在学习 Kubernetes 这个复杂而庞大的项目时,抓住其核心主线,理解其设计理念。
在笔者看来,Kubernetes 作为基础设施,它的设计理念有两个核心:
- 其一,从 API 到容器运行时的每一层,都为开发者暴露可供扩展的插件机制。通过 CNI 插件把网络功能解耦,让外部的开发社区、厂商参与容器网络的实现;通过 CSI 插件建立了一套庞大的存储生态;通过设备插件机制把物理资源的支持扩展到 GPU、FPGA、DPDK、RDMA 等各类异构设备。凭借这种开放性设计,Kubernetes 社区涌现出成千上万的插件,帮助运维工程师轻松构建强大的基础设施平台。从这一点讲,这也是 CNCF 基于 Kubernetes 能构建出一个庞大生态的原因。所以说,Kubernetes 并不是一个简单的容器编排平台,而是一个分量十足的“接入层”,是云原生时代真真正正的“操作系统”。
- 其二,在这一开放性底层之上,Kubernetes 将各类资源统一抽象为“资源”,并通过 YAML 文件描述。这种设计使得一个 YAML 文件即可表达复杂基础设施的最终状态,并自动管理应用程序的运维。Kubernetes 隐藏了底层实现细节,屏蔽了不同平台的差异,以一致、友好、跨平台的方式将底层基础设施能力“输送”给业务工程师,正是它的设计理念的精髓所在。
接下来,笔者将介绍基于“容器设计模式”的二次创新,也就是近几年热度极高的“服务网格”(ServiceMesh)技术。