作为一名 java 后端程序员,MySQL 应该是接触最多的数据库之一,增删改查(CRUD) 更是对 MySQL 的常规操作。当你在编写一条查询语句时,你有好奇过:这条SQL查询语句是如何执行的吗?哪些环节会影响语句的查询效率?今天我们就来扒一扒 SQL 查询语句的执行流。
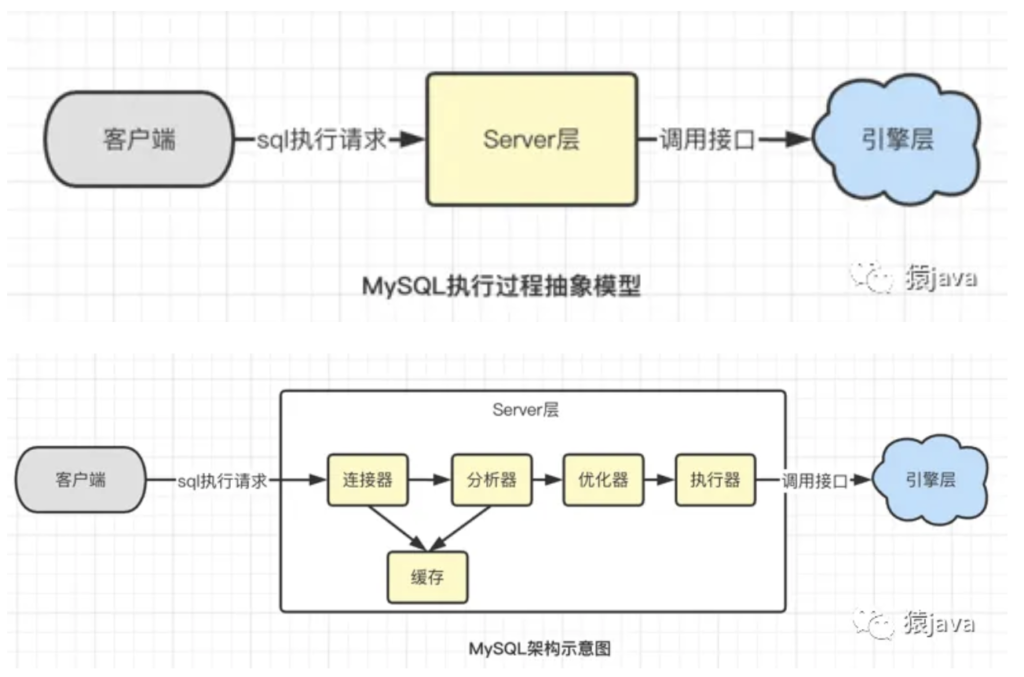
1. MySQL 架构示意图
MySQL 是典型的 C/S 架构,SQL 整个执行流程包括:客户端,Server 层和存储引擎层 三部分。
备注:C/S 架构,C是指Client客户端,S是指Server服务端。
2. 模块分析
2.1 客户端
客户端是指连接使用 MySQL 的终端。常见的 MySQL 客户端有:java 代码,这个是 java 程序员使用最多的,比如 mybatis ORM 框架;navicat 工具,功能强大,能够可视化操作很多种数据库;mysql-cli,这个是 MySQL 官方自带的客户端;还有一些网页版的客户端。
2.2 Server层
Server 层是 MySQL 的核心模块,Server 层包含 连接器、查询缓存、分析器、优化器、执行器等核心组件,涵盖了 MySQL 大多数核心服务以及所有的内置函数,诸如 存储过程、触发器、视图等所有跨存储引擎的功能也都在 Server 层实现。下面将分别讲解几个核心组件。
连接器
连接器的主要功能是连接管理和权限校验。当客户端请求过来时,首先是和 Server 层的连接器交互。
下面通过一个实例来讲解连接层的功能,比如,mysql-cli 客户端连接 MySQL Server 的命令:
mysql> mysql -h 127.0.0.1 -P 3306 -uroot -p
整个过程分解为:
输入指令,点击 Enter键后会完成经典的TCP 3次握手,客户端和MySQL Server建立TCP连接。
连接建立后,连接器开始对请求进行权限校验,如果 Server 层配置需要密码校验,会提醒用户输入密码,密码正确进入下一步,密码错误提醒”Access denied for user”;如果 Server 层配置不需要密码校验,则直接进入下一步
权限验证成功后,连接器会从权限表把当前用户的所有权限查询并缓存起来,权限缓存的生命周期一直到该连接关闭。
连接器会把权限缓存,因此,只要该连接一直存在就会使用缓存中的权限,这就意味着,即便服务器更改了该用户的权限,只要是在权限更改前还存活的连接,新的权限不生效。这也能很好的解释,有时候服务端修改了权限配置,客户端不能及时生效。
查询缓存
缓存是 MySQL 为了加速查询而设置的,当请求鉴权完成之后,就会到执行缓存查询(Server 层开启了缓存),如果命中缓存,则直接返回,否则进入下一步。不过根据小编剧这么多年的工作经验,缓存使用的场景比较少,比如:MySQL 中存放的是一些静态数据或者变更频率特别低,其他的场景这个功能就比较鸡肋了,怎么鸡肋呢?
因为只要对表有更新操作,查询缓存就会失效,如果表的更新和查询操作比较频繁,那么缓存就会一直处于建立和失效的频繁交替中,最终导致查询性能不但没有提升还无形中多维护了缓存。
因此实际生产中,Server 层都会设置 query_cache_type=DEMAND,这样 SQL 默认不会使用查询缓存。如果有特殊需求一定要使用查询缓存,可以显示指定 SQL_CACHE,比如下面的 SQL 语句:
mysql> select SQL_CACHE * from user where id = ?;
分析器
优化器目的是对 SQL 语句进行优化处理。因为 SQL 语句的编写者能力不一样,编写出来的 SQL 语句性能也不一样。Server 层如果完全按照 SQL 语句顺序执行,可能会造成性能问题, 所以需要优化,判断语句能否使用索引等。比如下面的场景:
假如:5000 万数据的 user 表中原存在一个组合索引是 index_name_age(name,age),某工程师在没有查看现有索引的情况编写了如下的 SQL 语句:
mysql> select * from user where age = 30 and name like '张%';
假如 MySQL server 层完全按照 SQl 语句的顺序执行,则该 SQL 语句不会使用索引,必定会成为慢 sql。而有了优化器,语句就可以优化成下面的形式,完全使用上现有的 index_name_age(name,age)索引。这下是不是看出了优化器的好处。
mysql> select * from user where name like '张%' and age = 30;
执行器
执行器就是运行 SQL 语句。不过,此处执行器不会在 Server 层直接执行 SQL 语句,而是根据数据表中执行引擎类型调用对应的存储引擎提的接口。至于,为什么执行引擎不亲自执行 SQL 语句,我们会后期进行分享。不过 MySQL 此处的设计符合了 SOLID 软件设计原则 ( https://www.yuanjava.cn/tags/solid/ ) 的依赖倒置原则。
执行引擎不亲自执行 SQL 语句原因
Server 层(执行引擎相关部分)
- SQL 语句输入:应用程序将 SQL 语句发送到数据库系统,这是整个流程的起点。比如应用程序要查询用户表中年龄大于 30 岁的用户信息,会发送类似
SELECT * FROM users WHERE age > 30;这样的 SQL 语句到数据库。 - SQL 解析与优化模块
- 语法分析:对输入的 SQL 语句进行语法检查,判断其是否符合 SQL 语言规范。例如检查语句中的关键字拼写是否正确、括号是否匹配、语句结构是否完整等。如果输入
SELEC * FROM users WHERE age > 30;(SELECT拼写错误 ),该模块会检测出语法错误并返回错误信息。 - 语义检查:检查 SQL 语句的语义是否正确。比如确认语句中引用的表和列在数据库中是否存在,以及数据类型是否匹配等。若数据库中不存在
users表,执行语义检查时就会报错。 - 查询优化:这是关键环节,会根据数据库元数据(如表结构、索引信息等 )生成多种可能的执行方案,并通过成本估算等方式选择最优的执行计划。例如对于上述查询,如果
age列上有索引,优化器可能会选择使用索引扫描来获取数据,而不是全表扫描,以提高查询效率。
- 语法分析:对输入的 SQL 语句进行语法检查,判断其是否符合 SQL 语言规范。例如检查语句中的关键字拼写是否正确、括号是否匹配、语句结构是否完整等。如果输入
- 执行计划生成模块:根据 SQL 解析与优化模块的结果,生成具体的执行步骤。例如确定先从索引中获取满足
age > 30条件的记录指针,再根据指针读取对应的数据行等操作顺序。 - 调用存储引擎接口模块:执行引擎不直接操作数据,而是通过这个模块向存储引擎发送指令。它根据执行计划,将操作转化为对存储引擎接口的调用请求,比如调用存储引擎的 “读取数据页”“写入数据” 等接口。
存储引擎层
- 不同存储引擎:数据库支持多种存储引擎,如 InnoDB、MyISAM 等。
- InnoDB:是一种事务安全型存储引擎,支持行级锁和外键约束等。在处理事务时,它会严格遵循 ACID 特性(原子性、一致性、隔离性、持久性 )。例如在银行转账业务中,涉及多个账户金额变动的操作会被视为一个事务,InnoDB 能保证要么所有账户金额变动都成功提交,要么都回滚,确保数据一致性。它在处理数据存储时,会将数据和索引组织在聚簇索引结构中,以提高数据读取和写入效率。
- MyISAM:不支持事务,采用表级锁。对于一些读操作频繁、对事务要求不高的场景比较适用,如简单的日志记录系统。它的优势在于数据读取速度较快,在一些以查询为主的应用中表现良好。其数据和索引是分开存储的。
- 存储引擎功能实现:每个存储引擎都有自己独特的底层数据存储和管理机制。它们负责实际的数据存储、读取以及相关的事务控制、并发控制等操作。比如 InnoDB 在接收到执行引擎的读取数据请求后,会根据自身的数据页管理机制,从磁盘中读取对应的数据页到内存中,再返回给执行引擎。
交互部分
- 指令传递:执行引擎通过调用存储引擎接口,将执行计划中的操作指令传递给存储引擎。例如执行引擎要求存储引擎从某个表中读取满足特定条件的数据,存储引擎会根据自身的数据结构和索引情况进行相应操作。
- 数据返回与结果反馈:存储引擎执行完操作后,将数据返回给执行引擎,并反馈操作结果(如是否成功读取数据、写入数据时是否遇到错误等 )。执行引擎再根据这些结果进行后续处理,比如将数据整理后返回给数据库客户端展示,或者根据错误结果进行异常处理。
整体优势体现
- 职责分离优势
- 专业化分工:执行引擎专注于 SQL 语句的逻辑处理和优化,不断提升 SQL 解析、查询优化等方面的能力;存储引擎专注于数据的物理存储和底层操作,针对不同存储需求进行优化。两者相互协作,提高数据库整体性能。例如执行引擎可以不断改进查询优化算法,存储引擎可以针对新型存储介质优化 I/O 操作。
- 降低复杂度:将复杂的数据库操作拆分为不同模块,每个模块功能相对单一,便于开发、维护和调试。开发人员可以分别对执行引擎和存储引擎进行代码优化和功能扩展,而不会相互干扰。
- 灵活性与扩展性优势
- 适配多种存储引擎:执行引擎通过统一的接口方式调用不同存储引擎,用户可以根据业务需求灵活选择存储引擎。比如电商应用中,订单处理模块对事务要求高,可选用 InnoDB 存储引擎;商品展示模块读操作多,对事务要求低,可选用 MyISAM 存储引擎。
- 便于功能扩展:随着技术发展,新的存储引擎或存储技术可以方便地集成到数据库系统中。只要新存储引擎实现了执行引擎调用所需的接口,就能被执行引擎调用,无需对执行引擎核心代码进行大规模修改。
- 性能优化优势
- 优化执行路径:执行引擎通过查询优化生成高效执行计划,指导存储引擎进行数据操作,减少不必要的数据读取和处理。例如通过索引使用策略,避免全表扫描,提高查询速度。
- 减少资源占用:存储引擎根据自身对数据存储结构的了解,更合理地管理 I/O 操作和内存资源。比如利用缓存机制减少磁盘 I/O 次数,执行引擎无需关心这些底层细节,专注于 SQL 逻辑处理,从而降低系统整体资源消耗。
2.3 存储引擎层
存储引擎层负责数据的存储和提取。采用插件式的架构模式,常见的存储引擎有 InnoDB、MyISAM、Memory 等。其中 MyISAM 是 MySQL 官方自带的引擎,但是因为该引擎不支持事务,使得能够支持事务的 InnoDB 存储引擎得以快速发展,并在 MySQL 5.5.5 版本夺嫡成功,成为了默认存储引擎。
因此,作为开发人员,在进入新公司后,最好是要弄清楚公司的 MySQL 版本以及默认引擎,这样可以避免很多不必要的坑。查看指令如下:
# 查看数据库版本 mysql> status; # 查看默认引擎 mysql> SHOW VARIABLES LIKE 'default_storage_engine%';
3. 总结
- SQL 执行会经历客户端、Server 层、存储引擎层 3 个部分。
- Server 层包含 连接器、查询缓存、分析器、优化器、执行器等核心组件。
- 连接器主要职责是管理连接,权限校验
- 查询缓存主要职责是为查询提供缓存
- 分析器主要职责是词法分析和语法分析,目的是识别 SQL 是做什么,有没有语法错误。
- 优化器主要职责是关注 SQL 的性能,优化 SQL 语句怎么更好的去执行,比如:匹配索引,优化 join 查询的连接顺序。
- 执行器主要职责是调用存储引擎接口和返回结果。
- 存储引擎主要职责是数据的存储和提取,给执行器提供接口。