作为一名 Java后端程序员,MySQL应该是接触最多的数据库之一,增删改查更 MySQL数据库的常规操作。 那么,一条 SQL语句在执行的过程中经历了哪些流程呢?它是如何被 MySQL执行的?这篇文章,我们将详细地分析。
为了更好地理解,我们先来看一下 MySQL的架构。
MySQL架构示意图
MySQL是典型的C/S架构,SQL整个执行流程包括:客户端,Server层和存储引擎层三部分。
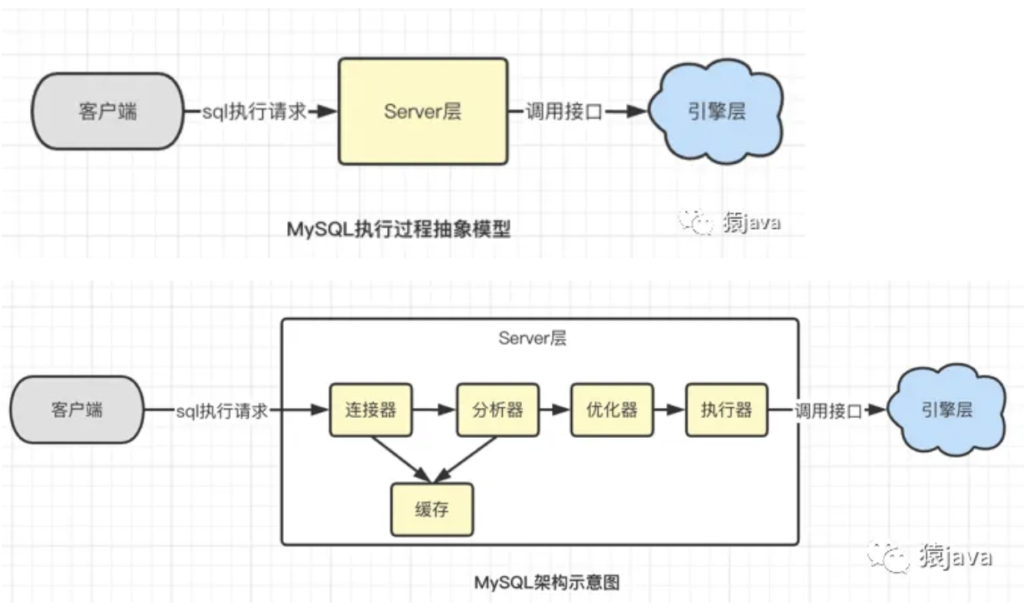
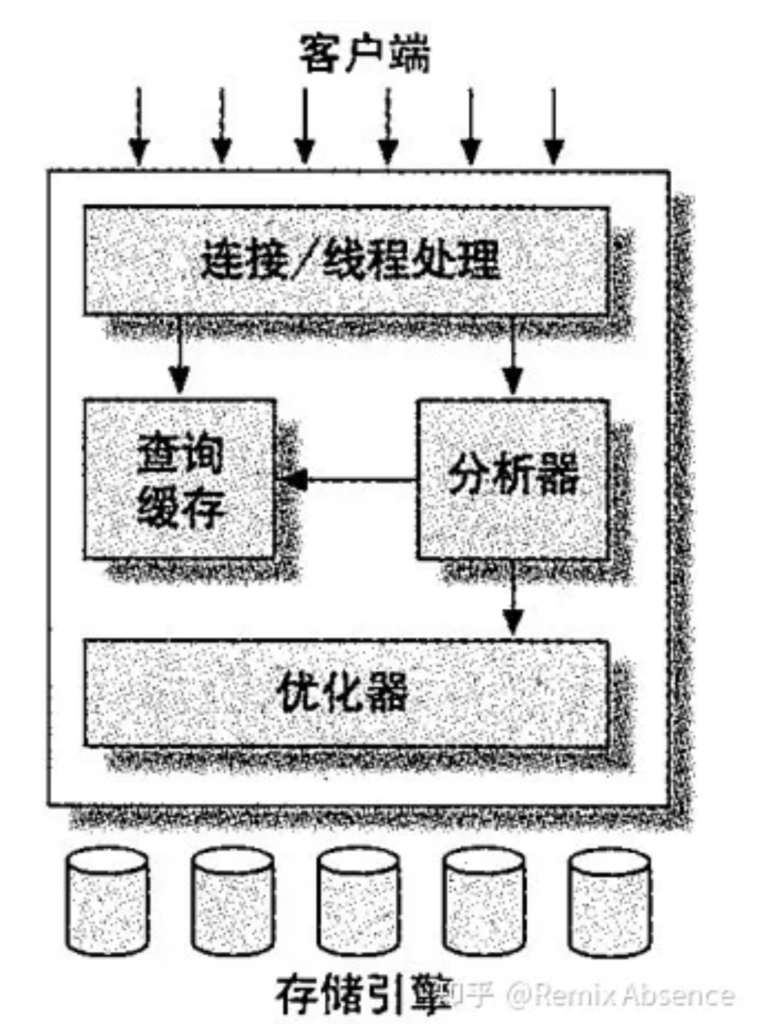
C/S架构,C是指 Client 客户端,S是指 Server 服务端。
流程图
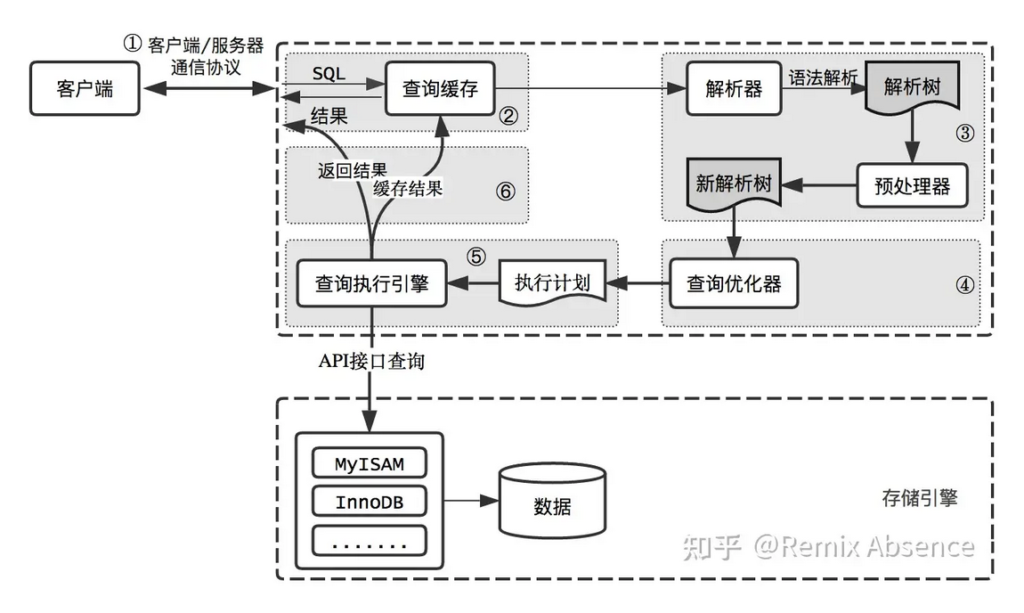
MySQL 整个查询执行过程,分为 6 个大步骤,如上图:连接建立、查询缓存、SQL解析、优化SQL查询、调用引擎,返回结果
- 连接建立:客户端向 MySQL 服务器发送一条查询请求,与 Connectors 交互,进行身份认证、连接分配等操作。如验证通过,会暂时存放在连接池中并由Management Serveices & Utilities 管理。当该请求从等待队列进入到处理队列,管理器会将该请求传递给 SQL Interface
- 查询缓存:SQL Interface 接收到请求后,首先对请求进行 hash 处理并检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果,否则进入后续流程,传递给 Parser
- SQL 解析:Parser 对 SQL 进行解析(词法、语法、语义),将 SQL 转化为语法树,并传递给预处理器
- SQL 预处理:预处理器会进行表/字段存在性验证、权限验证等操作,完成后传递给 Optimizer
- SQL 优化:Optimizer 结合语法树的语义和目标数据库统计信息生成 MySQL 认为的最佳执行计划
- SQL 执行:MySQL 根据执行计划,调用存储引擎的 API 来执行查询
- 返回结果:将结果返回给客户端,同时如为 select 请求则缓存查询结果
模块分析
1. 客户端
客户端是指连接使用MySQL的终端。常见的MySQL客户端有:java代码,这个是java程序员使用最多的,比如mybatis ORM框架;navicat工具,功能强大,能够可视化操作很多种数据库;mysql-cli,这个是MySQL官方自带的客户端;还有一些网页版的客户端。
2. Server层
Server层是MySQL的核心模块,Server层包含 连接器、查询缓存、分析器、优化器、执行器等核心组件, 涵盖了MySQL大多数核心服务以及所有的内置函数,诸如 存储过程、触发器、视图等所有跨存储引擎的功能也都在Server层实现。下面将分别讲解几个核心组件。
连接器
连接器的主要功能是连接管理和权限校验。当客户端请求过来时,首先是和Server层的连接器交互。
下面通过一个实例来讲解连接层的功能,比如:mysql-cli客户端连接MySQL Server的命令
mysql> mysql -h 127.0.0.1 -P 3306 -uroot -p
整个过程分解为:
输入指令,点击 Enter键后会完成经典的TCP 3次握手,客户端和MySQL Server建立TCP连接。
连接建立后,连接器开始对请求进行权限校验,如果Server层配置需要密码校验,会提醒用户输入密码,密码正确进入下一步,密码错误提醒"Access denied for user"; 如果Server层配置不需要密码校验,则直接进入下一步
权限验证成功后,连接器会从权限表把当前用户的所有权限查询并缓存起来,权限缓存的生命周期一直到该连接关闭。
连接器会把权限缓存,因此,只要该连接一直存在就会使用缓存中的权限,这就意味着,即便服务器更改了该用户的权限,只要是在权限更改前还存活的连接,新的权限不生效。这也能很好地解释, 有时候服务端修改了权限配置,客户端不能及时生效。
查询缓存
缓存是 MySQL为了加速查询而设置的,当请求鉴权完成之后,就会到执行缓存查询(Server层开启了缓存),如果命中缓存,则直接返回,否则进入下一步。不过根据小编剧这么多年的工作经验, 缓存使用的场景比较少,比如:MySQL中存放的是一些静态数据或者变更频率特别低,其他的场景这个功能就比较鸡肋了,怎么鸡肋呢?
因为只要对表有更新操作,查询缓存就会失效,如果表的更新和查询操作比较频繁,那么缓存就会一直处于建立和失效的频繁交替中,最终导致查询性能不但没有提升还无形中多维护了缓存。
因此实际生产中,Server层都会设置 query_cache_type=DEMAND,这样SQL默认不会使用查询缓存。如果有特殊需求一定要使用查询缓存,可以显示指定SQL_CACHE,比如下面的SQL语句:
mysql> select SQL_CACHE * from user where id = ?;
分析器
分析器,顾名思义就是SQL语句进行分析,那么,分析器对SQL会做哪些分析呢?通常来说有:词法分析 和 语法分析 两种。
词法分析 是判断SQL里面的字符串进行拆解,识别当前SQL是什么操作,SQL里面包含多少字符串,空格等等,比如:下面的sql语句, 词法分析器可以根据 select来判断当前SQL是查询操作,id 为需要查询的结果,where 后面的条件等等;
mysql> select id from user where name = 'zhangsan';
语法分析就是检查SQL的语法是否正确,比如下面的SQL语句,把update 错误的写成了 updater,因此语法分析器就能识别该SQL有语法错误,抛出语法错误相关的异常。
mysql> updater user set update_time = now() where id = 10;
优化器
优化器目的是对SQL语句进行优化处理。因为SQL语句的编写者能力不一样,编写出来的SQL语句性能也不一样。Server层如果完全按照SQL语句顺序执行,可能会造成性能问题, 所以需要优化,判断语句能否使用索引等。比如下面的场景:
假如:5000万数据的user表中原存在一个组合索引是index_name_age(name,age),某工程师在没有查看现有索引的情况下编写了如下的SQL语句:
mysql> select * from user where age = 30 and name like '张%';
假如 MySQL server层完全按照SQl语句的顺序执行,则该SQL语句不会使用索引,必定会成为慢sql。而有了优化器,语句就可以优化成下面的形式,完全使用上现有的index_name_age(name,age)索引。这下可以是不是看出了优化器的好处。
mysql> select * from user where name like '张%' and age = 30;
执行器
执行器就是运行SQL语句。不过,此处执行器不会在Server层直接执行SQL语句,而是根据数据表中执行引擎类型调用对应的存储引擎提的接口。至于,为什么执行引擎不亲自执行SQL语句,我们会后期进行分享。不过MySQL此处的设计符合了SOLID软件设计原则 的依赖倒置原则。
3. 存储引擎层
存储引擎层负责数据的存储和提取。采用插件式的架构模式,常见的存储引擎有 InnoDB、MyISAM、Memory等。其中MyISAM是MySQL官方自带的引擎, 但是因为该引擎不支持事务,使得能够支持事务的InnoDB存储引擎得以快速发展,并在MySQL 5.5.5版本夺嫡成功,成为了默认存储引擎
因此,作为开发,在进入新公司后,最好是要弄清楚公司的MySQL版本以及默认引擎,这样可以避免很多不必要的坑。查看指令如下:
# 查看数据库版本 mysql> status; # 查看默认引擎 mysql> SHOW VARIABLES LIKE 'default_storage_engine%';
总结
本文,我们详细分析了一条 SQL查询语句在 MySQL中的全部执行流程。通过了解这些流程,可以帮助我们更好的理解 MySQL的内部结构和原理,以及 vvvMySQL的优化原理。:
- SQL执行会经历客户端、Server层、存储引擎层 3个部分。
- Server层包含 连接器、查询缓存、分析器、优化器、执行器等核心组件。
- 连接器主要职责是管理连接,权限校验
- 查询缓存主要职责是为查询提供缓存
- 分析器主要职责是词法分析和语法分析,目的是识别SQL是做什么,有没有语法错误。
- 优化器主要职责是关注SQL的性能,优化SQL语句怎么更好的去执行,比如:匹配索引,优化join查询的连接顺序。
- 执行器主要职责是调用存储引擎调的接口和返回结果。
- 存储引擎主要职责是数据的存储和提取,给执行器提供接口。