转载:Dense vs MoE:大语言模型架构之争,谁是未来AI的“特种兵”?
前言🔖
在人工智能飞速发展的今天,大语言模型(LLM)已经成为推动技术革新的核心引擎。但你是否知道,在这些“聪明”的大模型背后,其实存在两种截然不同的架构路线?它们分别是 Dense(稠密)模型 和 MoE(Mixture of Experts,混合专家)模型。
这两种架构不仅决定了模型的性能表现,更深刻影响着训练成本、推理效率和实际部署方式。今天,我们就来深入浅出地聊聊它们之间的区别与取舍。
随着大模型技术迎来颠覆性突破,新兴AI应用大量涌现,不断重塑着人类、机器与智能的关系。
MoE混合专家大模型最近究竟有多火?
举个例子,在此前的GTC 2024上,英伟达PPT上的一行小字,吸引了整个硅谷的目光。
“GPT-MoE 1.8T”
这行小字一出来,X(推特)上直接炸锅了。
“GPT-4采用了MoE架构”,这条整个AI圈疯传已久的传言,竟然被英伟达给“无意中”坐实了。消息一出,大量AI开发者们在社交平台上发帖讨论,有的看戏吐槽、有的认真分析、有的开展技术对比,一时好不热闹。MoE大模型的火热,可见一斑。
近半年多以来,各类MoE大模型更是层出不穷。在海外,OpenAI推出GPT-4、谷歌推出Gemini、Mistral AI推出Mistral、连马斯克xAI的最新大模型Grok-1用的也是MoE架构。
MoE究竟是什么?它有哪些技术原理?它的优势和缺点是什么?它又凭什么能成为当前最火的大模型技术?
Dense模型:全栈工程师团队🔖
在深入部署之前,我们必须先搞懂这两个核心架构的区别。你可以把它们想象成两种不同的“公司组织架构”。
Dense模型:全栈工程师团队
Dense模型,也叫稠密模型,是传统且经典的架构。它的工作方式很简单:
- 全员参与:模型里的每一个“神经元”(参数)在每次处理任务时都会被激活和使用。
- 结构统一:就像一个由全栈工程师组成的团队,每个人都要懂前端、后端、数据库,任何任务来了,整个团队都得上。
Dense模型是最传统、最直观的大模型架构。它的核心特点是:每次前向传播时,所有参数都会被激活并参与计算。
举个例子,像早期的GPT-3、LLaMA-1/2、ChatGLM等,都是典型的Dense模型。假设一个模型有70亿参数(7B),那么无论你输入什么问题——哪怕只是一个简单的“你好”——这70亿个参数都会被调用一遍。
- 优点:
- 稳定可靠:结构简单,训练和推理的行为可预测。
- 兼容性好:几乎所有推理框架和硬件都对其有成熟优化。
- 精度有保障:参数虽少,但每个参数都经过充分训练。
- 缺点:
- 效率瓶颈:无论任务简单还是复杂,都要动用全部算力,有点“杀鸡用牛刀”。
- 规模受限:想要提升能力,就得增加参数,模型体积和计算成本会线性增长。
Qwen3-4B就是典型的Dense模型。它的40亿参数在每次推理时都会参与计算。
MoE模型:专家顾问委员会🔖
为了解决Dense模型的效率瓶颈,研究人员提出了 MoE(Mixture of Experts) 架构。其核心思想源自“分而治之”:将模型拆分成多个“专家子网络”,每次只激活其中一部分,根据输入内容动态选择最合适的专家组合。
MoE(Mixture of Experts,混合专家)模型则是一种更“聪明”的架构:
- 专家分工:模型由许多个“子网络”(专家)组成,每个专家只擅长处理某一类任务。
- 动态路由:每来一个任务,一个特殊的“路由网络”会判断这个任务属于哪一类,然后只调用相关的1个或几个专家来处理,其他专家“休息”。
- 稀疏激活:虽然模型总参数可能很大(比如上千亿),但每次实际参与计算的只是其中一小部分。
MoE是大模型架构的一种,其核心工作设计思路是“术业有专攻”,即将任务分门别类,然后分给多个“专家”进行解决。
与MoE相对应的概念是稠密(Dense)模型,可以理解为它是一个“通才”模型。
一个通才能够处理多个不同的任务,但一群专家能够更高效、更专业地解决多个问题。
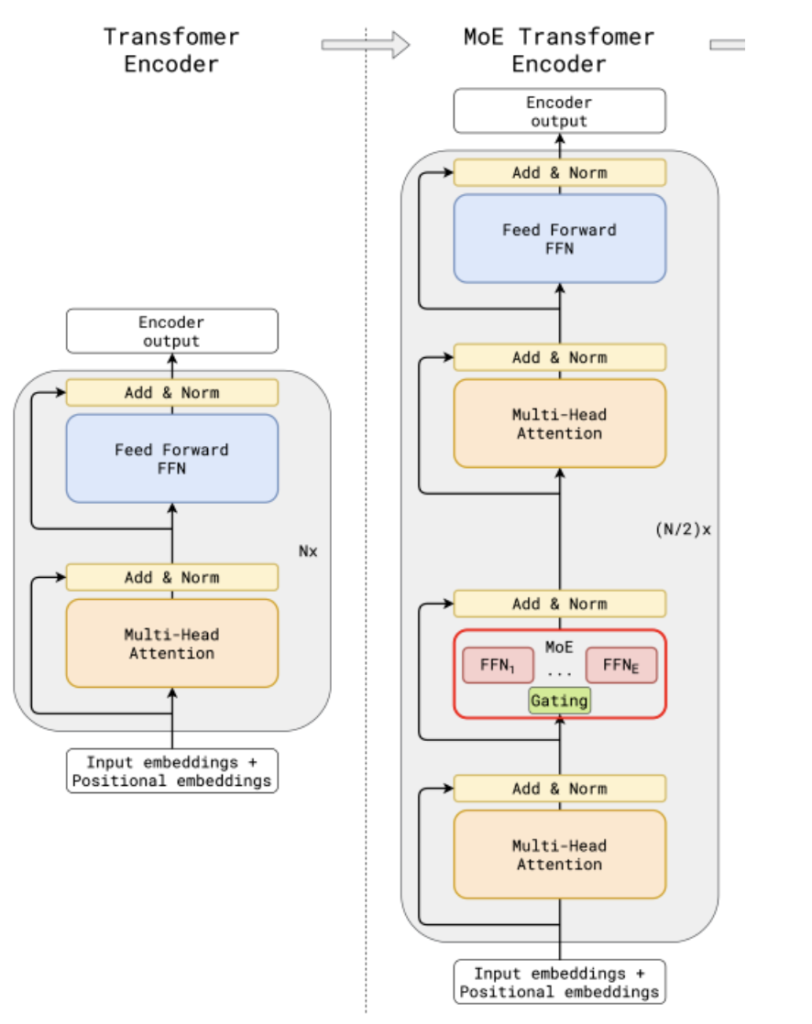
上图中,左侧图为传统大模型架构,右图为MoE大模型架构。
两图对比可以看到,与传统大模型架构相比,MoE架构在数据流转过程中集成了一个专家网络层(红框部分)。
下图为红框内容的放大展示:
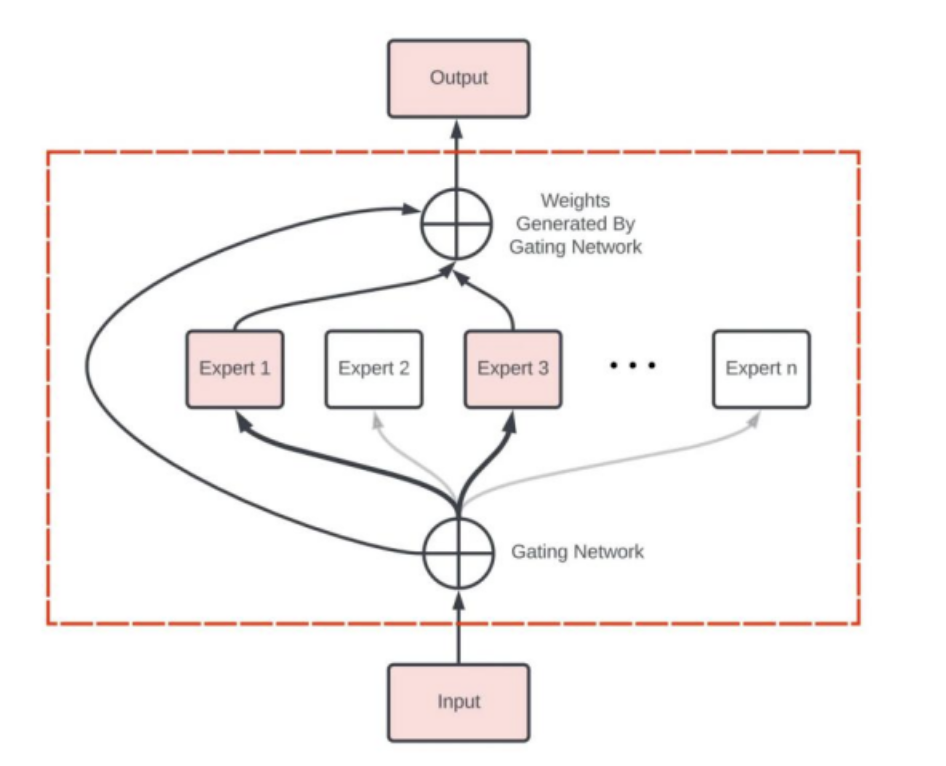
专家网络层的核心由门控网络(Gating Network)和一组专家模型(Experts)构成,其工作流程大致如下:
- 1 数据首先会被分割多个区块(Token),每组数据进入专家网络层时,首先会进入门控网络;
- 2 门控网络将每组数据分配给一个或多个专家,每个专家模型可以专注于处理该部分数据,“让专业的人做专业的事”;
- 3 最终,所有专家的输出结果汇总,系统进行加权融合,得到最终输出。
当然,以上只是一个概括性描述,关于门控网络的位置、模型、专家数量、以及MoE与Transformer架构的具体结合方案,各家方案都略有差别,但核心思路是一致的。
与一个“通才网络”相比,一组术业有专攻的“专家网络”能够提供更好的模型性能、更好地完成复杂的多种任务;同时,也能够在不显著增加计算成本的情况下大幅增加模型容量,让万亿参数级别的大模型成为可能。
- 优点:
- 高效节能:只调用部分参数,显著降低计算开销;
- 易于扩展:增加专家数量可提升模型容量,而不大幅增加单次计算量;
- 潜力巨大:在保持推理成本可控的前提下,逼近更大规模模型的能力。
- 缺点:
- 训练复杂度高:需设计路由机制(Router)决定激活哪些专家;
- 负载不均衡风险:某些专家可能被过度使用,而其他专家“躺平”;
- 工程挑战大:对分布式训练、内存管理要求更高。
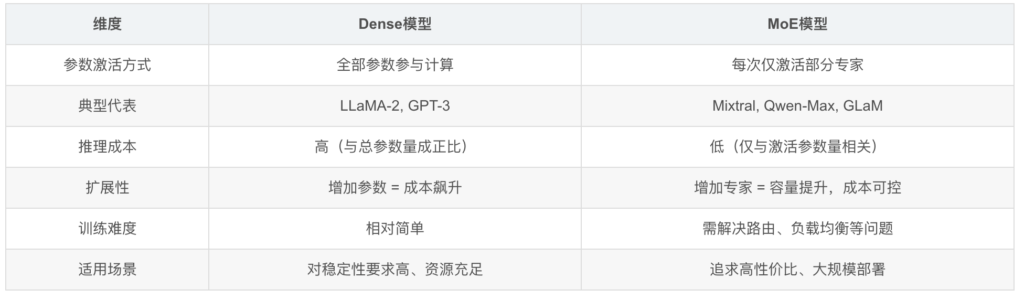
一张表看懂差异
未来趋势:MoE正在成为新主流?🔖
随着模型规模突破万亿参数,Dense模型的边际效益逐渐递减,而MoE凭借其“大容量、低开销”的优势,正被越来越多头部厂商采用:
- 阿里通义千问:Qwen-Max 即基于MoE架构,兼顾性能与成本;
- Meta:在Llama 3系列中探索MoE变体;
- Mistral AI:Mixtral 8x7B 开源即引爆社区,证明MoE的实用价值;
- Google & Anthropic:在其超大模型中广泛使用MoE技术。
不过,Dense模型并未过时。在中小规模场景(如7B~13B参数)、边缘设备部署或对确定性要求极高的任务中,Dense仍是更可靠的选择。
结语:没有最好,只有最合适🔖
Dense与MoE,不是“谁取代谁”的关系,而是不同目标下的技术权衡。
如果你追求极致稳定与简单部署,Dense模型值得信赖;
如果你希望在有限算力下获得更强能力,MoE则是未来方向。
正如一位AI工程师所说:“Dense是稳扎稳打的老将,MoE是灵活高效的特种兵。” 在大模型的军备竞赛中,两者或将长期共存,共同推动AI走向更智能、更普惠的未来。