转载:分布式系统最全详解
分布式系统
分布式系统:是通过网络连接的多台独立计算机(比如:物理服务器、虚拟机、或容器)协同工作,共同完成特定任务的计算系统。

一般,具体典型的4大特点:
- 可扩展性(Scalability):通过增加更多的节点,可以提高系统的处理能力、和存储容量;
- 高可用性(High Availability):系统能够在部分节点出现故障时继续提供服务,通常通过数据冗余、和故障切换实现;
- 容错性(Fault Tolerance):系统能够检测、和处理节点故障,保证服务的连续性、和数据的完整性;
- 并发性(Concurrency):多个节点:可以并行处理不同的请求,提高系统的吞吐量、和响应速度。
分布式系统关键技术,会涉及到:负载均衡、数据分片、一致性协议、分布式锁、分布式缓存……….等等,下面我就分别来详解
负载均衡
负载均衡是一种在多个计算资源(如:服务器、节点)之间分配工作负载的技术,以确保没有单个资源过载,从而提高系统的可用性、和响应速度。
如下图所示:
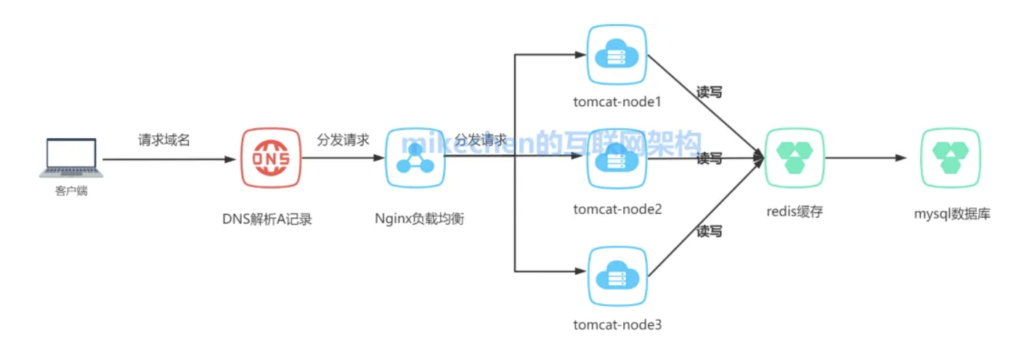
可以动态添加/或移除服务器,以应对流量变化,实现系统的弹性扩展。
而且,通过在多个服务器之间分配流量,即使部分服务器发生故障,系统仍然可以继续运行。
负载分配策略,常见的有:
- 轮询(Round Robin):按顺序将请求依次分配给每个服务器。
- 最少连接(Least Connections):将请求分配给当前处理请求最少的服务器。
- 源地址哈希(Source IP Hash):根据客户端 IP 地址计算哈希值,并将请求分配到固定的服务器。
- 权重轮询(Weighted Round Robin):根据服务器的权重,按比例分配请求。
数据分片
数据分片(Sharding)是一种将大数据集分割成更小的数据块,并分布存储在多个数据库、或存储节点上的技术。
典型的就是,大家现在熟知的“分库分表”:
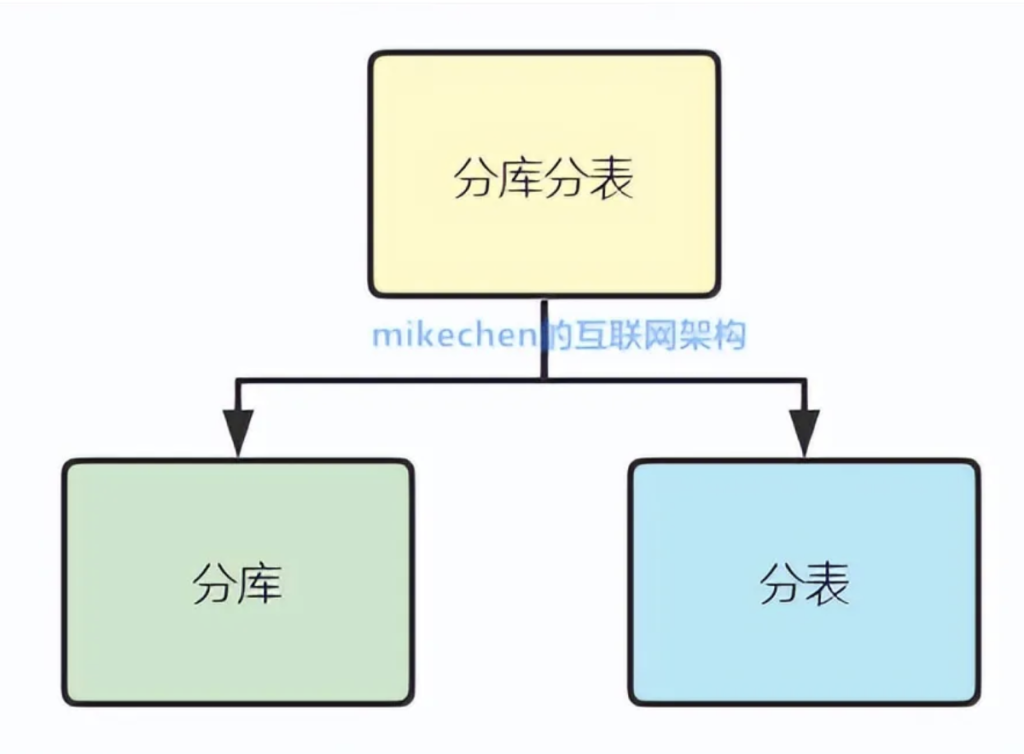
比如:按业务分库,根据不同的业务模块,将数据分配到不同的数据库中。
如下图所示:
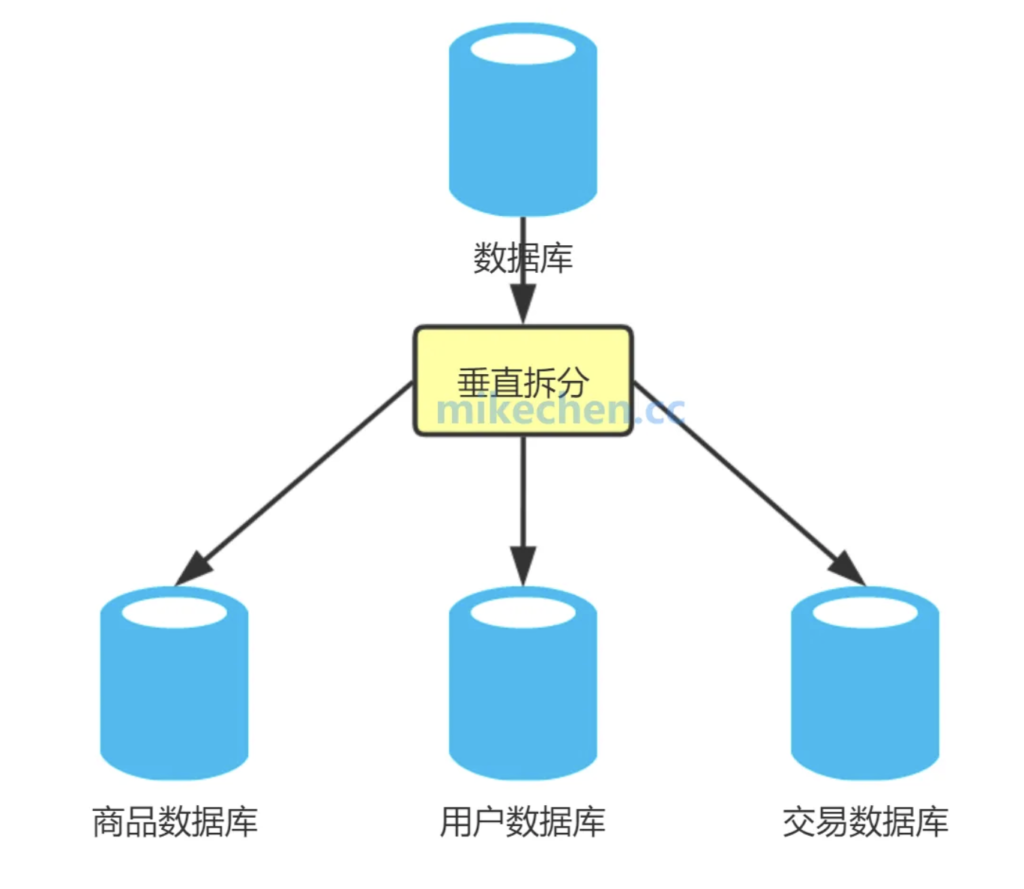
将用户数据、订单数据、和商品数据,分别存储在不同的数据库中,这就是典型的“垂直分库”,这些都是典型的“数据分片策略”。
除此之外,还有“水平分库”,比如:将一个表的数据按某个字段(如用户 ID)分割成多个子表。
例如:将用户表分成 user_0001、user_0002 …….user_000N等多个子表,这就会涉及到具体的分片策略:
- 范围分片(Range Sharding):根据分片键的值范围进行分片,如将数据按字母顺序或数值范围进行分片;
- 哈希分片(Hash Sharding):通过对分片键进行哈希计算,将数据均匀地分布到不同的分片中;
- 列表分片(List Sharding):根据预定义的列表进行分片,如按地理区域进行分片。
通过这些分片策略,可以极大的降低数据量,从而,提升数据查询效率。
分布式事务
分库分表是解决数据库性能/和扩展性问题的有效手段,但同时也会带来一些挑战、和问题,比如:分布式事务。
跨多个数据库实例的事务管理复杂度增加,会引入分布式事务问题,如:一致性、和隔离性的保障…等等。
在分布式系统中,由于存在多个独立的数据库实例、或服务,跨越这些实例进行事务,就会涉及到“分布式事务”。
如下图所示:
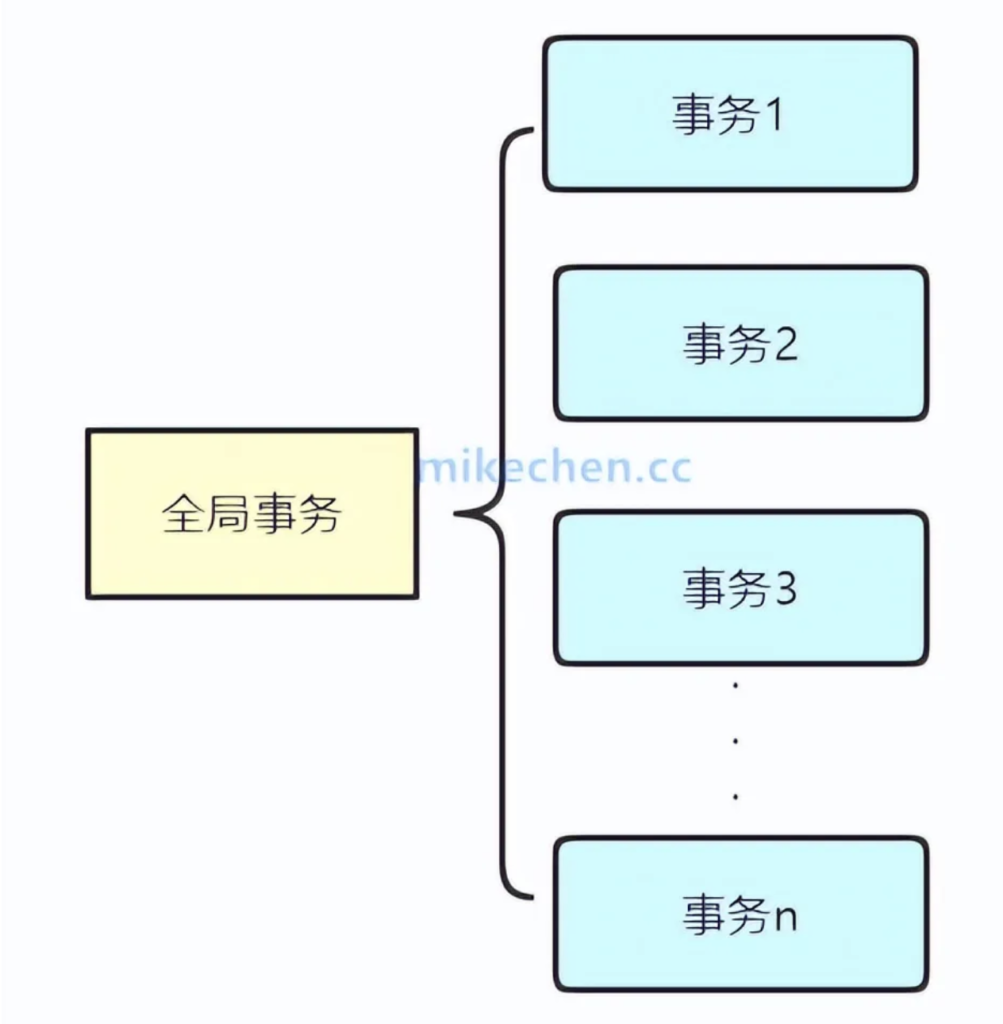
这里就会涉及到具体的“分布式事务解决方案“,比如:
- 两阶段提交(2PC):是最经典的分布式事务协议之一,它分为准备阶段和提交阶段,通过协调器和各个参与者的交互,保证事务的原子性;
- 三阶段提交(3PC):在2PC的基础上增加了一个CanCommit阶段,用于减少潜在的阻塞风险;
- 补偿事务(Compensating Transaction):事务分为Try、Confirm和Cancel三个阶段,通过预留资源、确认执行和取消操作来实现分布式事务。
分布式ID
同样,分库分表还会带来的分布式 ID 问题,比如:如何生成全局唯一的 ID。
传统的自增长 ID ,在分库分表后无法满足全局唯一性的要求,因为每个数据库实例的自增长 ID 只能保证在当前实例中的唯一性。
因此,需要全局唯一的分布式 ID,来解决这个问题。
分布式ID的方案有很多,但目前使用比较主流,依然还是”雪花算法“,如下图所示:
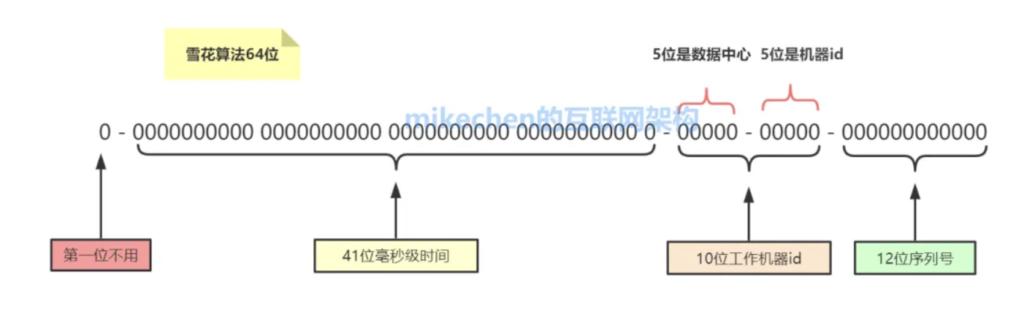
雪花算法:结合了时间戳、机器标识、和序列号的方式,生成全局唯一的64位整数。
包含:
- 符号位(1位):最高位固定为0,表示生成的是正数;
- 时间戳(41位):时间戳部分记录的是当前时间与一个固定的起始时间点之间的毫秒数差值,可以表示约 69 年的时间跨度;
- 机器标识(10位):机器标识部分用来标识不同的机器或节点,可以支持多达 1024 个节点;
- 序列号(12位):序列号部分:用来保证在同一毫秒内生成的 ID 的唯一性。
雪花算法也是万能,也会面临,比如:如果系统时钟发生回拨,有可能导致生成的 ID 出现重复。
分布式缓存
分布式缓存的主要作用就是:加速数据访问,减轻数据库等后端存储的压力,提高系统的性能和吞吐量。
分布式缓存还将缓存数据存储在多个节点上,利用多台机器的内存资源,不仅可以提供更大的缓存容量、和更快的访问速度。
而且,分布式缓存可以水平扩展,即通过增加缓存节点来增加缓存容量和处理能力,从而应对系统的增长需求。
如下图所示:
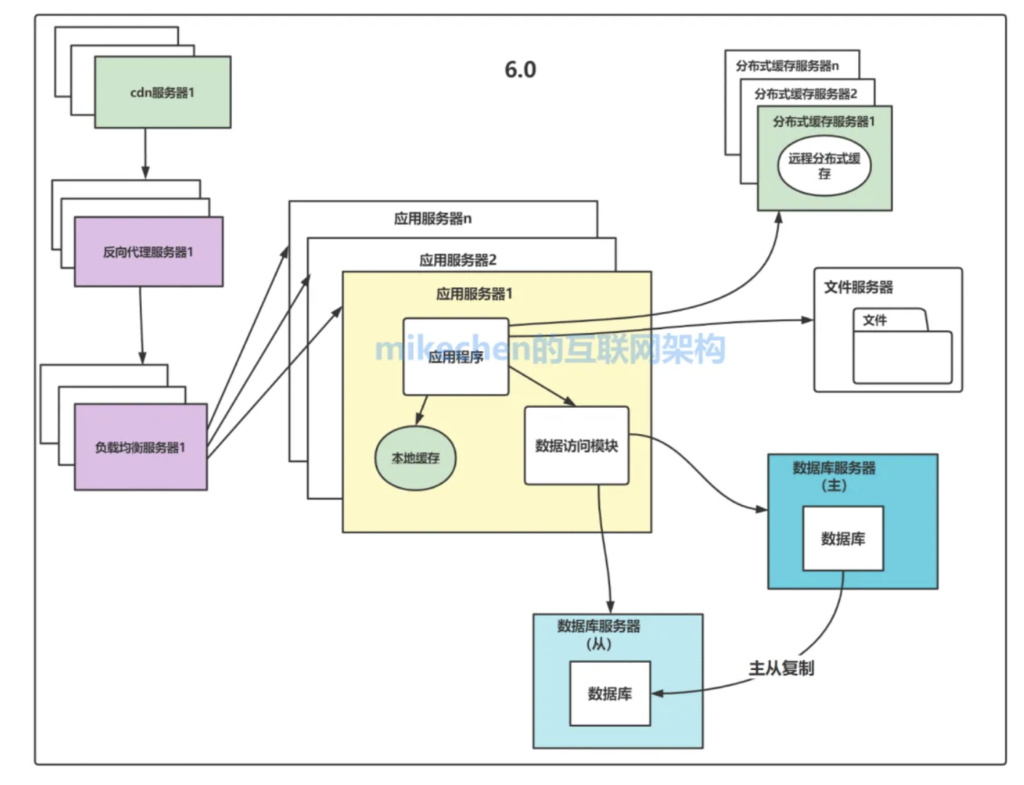
所以,目前大型架构都会广泛使用分布式缓存,典型的就是:”Redis集群“。
分布式锁
一旦开始分布式的时候,很多”单机锁“比如:”Synchronized”的实现方式,就失灵了。
原因很简单,锁的是一个实例,现在变成多个”服务器实例“,当然,就失灵了。
所以,需要分布式锁,来保证资源。
常见的解决方案,如下图所示:
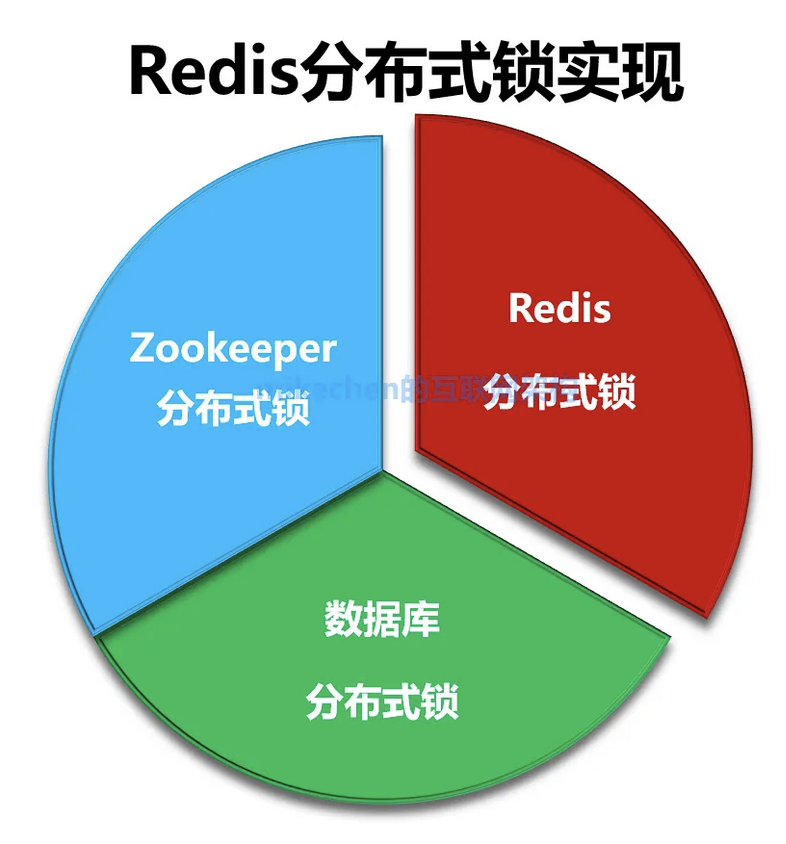
比如:有基于数据库的乐观锁、基于 ZooKeeper 的临时顺序节点、以及基于 Redis 的 方式来实现。。。等。
一般,主要都是使用Redis来实现:
1、获取锁
使用 Redis 的 SETNX 命令(Set if Not Exists)来尝试获取锁,该命令只有在键不存在时才会设置键的值。
2、设置过期时间
为了防止死锁问题,通常会在获取锁的同时设置一个过期时间,可以使用 SET key value EX seconds NX 命令来实现。
3、释放锁
只有持有锁的客户端才能释放锁。,使用 Lua 脚本来确保原子性,即检查锁的持有者并删除锁。
分布式一致性
一致性协议是用于保证分布式系统中数据一致性的协议或算法,确保不同节点之间的数据能够达到一致的状态。

一致性协议的实现,通常会涉及到:
- 选举算法:如在 Paxos 和 Raft 协议中,通过选举一个 Leader 节点来协调和管理数据的写入操作。
- 日志复制:Leader 节点将写入操作日志复制到所有 Follower 节点,确保所有节点接收到相同的操作日志。
- 提交操作:Leader 节点等待大多数节点确认接收到日志后,提交操作并通知所有节点应用该操作。
- 故障恢复:在 Leader 节点故障时,通过选举机制选出新的 Leader,确保系统的连续性和一致性。
总之,分布式系统是大型架构的必经之路,也是处理大规模数据、和高并发请求的必备解决方案。