问题: BuildConfig (bc)是什么?
BuildConfig 是 OpenShift 特有的资源,用于定义和管理构建过程。它描述了如何从源代码生成容器镜像。BuildConfig 是 OpenShift 用于描述应用程序构建过程的资源。它定义了从源代码生成容器镜像的各种参数和步骤。BuildConfig 包括构建源、构建策略、输出目标以及触发器等信息。
主要组成部分:
- 源代码 (Source):
- 定义构建的源代码位置,可以是 Git 仓库、本地文件路径等。
- 构建策略 (Build Strategy):
- 定义使用哪种构建策略,例如 Source-to-Image (S2I)、Dockerfile、Custom 等。
- 输出 (Output):
- 定义构建完成后,生成的镜像应该推送到哪个镜像仓库。
- 触发器 (Triggers):
- 定义何时触发构建,例如在源代码变化时、在镜像变化时等。
特点:
- 定义构建策略:可以使用不同的构建策略,如源代码构建(Source-to-Image, S2I)、Dockerfile 构建、二进制构建等。
- 触发器:支持基于 Git 变化、ImageStream 变化、定时等触发构建。
- 构建过程:在构建过程中会启动一个或多个 Pod 来执行构建任务。
示例:
apiVersion: build.openshift.io/v1
kind: BuildConfig
metadata:
name: example-buildconfig
spec:
source:
type: Git
git:
uri: 'https://github.com/openshift/nodejs-ex.git'
strategy:
type: Source
output:
to:
kind: ImageStreamTag
name: 'example-image:latest'
triggers:
- type: GitHub
github:
secret: 'mysecret'
- type: ImageChange
- type: ConfigChange
配置文件的作用:
- 定义构建流程:
BuildConfig定义了如何从源代码生成容器镜像,包括所需的所有步骤和参数。 - 触发构建: 根据配置中的触发器,当满足条件时,会自动启动构建任务。例如,代码仓库有新的提交时,
BuildConfig会自动触发新的构建。 - 管理构建过程: OpenShift 的构建控制器会根据
BuildConfig的定义启动构建 Pod,执行构建任务,然后将生成的镜像推送到指定的镜像仓库。
BuildConfig 定义了构建过程,当触发构建时,会启动一个构建 Pod 来执行构建任务。
构建完成后,构建 Pod 会被删除。
构建过程:
- 创建 BuildConfig: 通过
oc create -f buildconfig.yaml命令创建BuildConfig。 - 触发构建: 根据定义的触发器,构建任务会在合适的时机启动,例如代码更新、手动触发等。
- 创建构建 Pod: 构建控制器会启动一个临时的构建 Pod,执行从源代码生成镜像的任务。
- 输出镜像: 构建 Pod 完成任务后,将生成的镜像推送到指定的镜像仓库。
- 管理和监控: 可以使用
oc get builds和oc logs build/<build-name>命令查看构建状态和日志。
用oc get pod,可以看到 临时的构建 Pod

问题: oc new-app 命令可以自动生成 BuildConfig 吗?
oc new-app 命令用于创建一个新的应用程序。这包括创建相应的 Kubernetes 和 OpenShift 资源,如 DeploymentConfig、Service、Route,以及在某些情况下,BuildConfig。
自动生成 BuildConfig 的情况
当你使用 oc new-app 命令并指定源代码仓库(例如 Git 仓库)时,OpenShift 会自动创建一个 BuildConfig 以从源代码构建容器镜像。这个 BuildConfig 将定义如何从源代码生成镜像,然后将该镜像部署到集群中。
oc new-app https://github.com/sclorg/nodejs-ex -l name=myapp
在这个例子中,OpenShift 会:
- 创建一个
BuildConfig,定义如何从https://github.com/sclorg/nodejs-ex仓库中的源代码生成镜像。 - 创建一个
ImageStream来存储构建的镜像。 - 创建一个
DeploymentConfig,用于管理应用的部署。 - 创建一个
Service,用于暴露应用。 - 创建一个
Route(如果适用),用于外部访问应用。
不自动生成 BuildConfig 的情况
oc new-app nodejs:latest -l name=myapp
在这个例子中,OpenShift 直接使用 nodejs:latest 镜像,不需要从源代码构建镜像,因此不会生成 BuildConfig。它会创建以下资源:
- 一个
DeploymentConfig。 - 一个
Service。 - 一个
Route(如果适用)。
总结:
oc new-app会自动生成BuildConfig:如果你指定了源代码仓库,OpenShift 会自动创建一个BuildConfig,从源代码构建容器镜像。- 不会生成
BuildConfig的情况:如果你直接指定了容器镜像,OpenShift 不需要从源代码构建镜像,因此不会生成BuildConfig。
问题: service 和 route 有什么关系
Service提供了一个通往后端Pod集群的稳定入口,但是Service的IP地址只是集群内部节点及容器可见。对于外部的应用或者用户来说,这个地址是不可达的。
那么外面的用户想要访问Service指向的服务该怎么办?
OpenShift提供了Router(路由器)来解决这个问题。
Service
Service 是 Kubernetes 和 OpenShift 中的基本概念,用于定义一组 Pod 的网络服务。它提供了一种抽象层,使客户端能够通过统一的 IP 地址和端口访问 Pod,而不需要知道 Pod 的具体实例。
主要功能:
- 负载均衡:在多个 Pod 之间分发流量,实现负载均衡。
- 服务发现:通过 DNS 或环境变量,使其他服务能够发现并访问它。
- 网络抽象:提供统一的访问入口,不管 Pod 实例如何变化,Service IP 地址和端口保持不变。
apiVersion: v1
kind: Service
metadata:
name: example-service
spec:
selector:
app: example
ports:
- protocol: TCP
port: 80
targetPort: 8080
Route
Route 是 OpenShift 特有的资源,用于将外部流量路由到集群内的服务。它为外部客户端(例如 Web 浏览器)提供了一个可以访问应用程序的 URL。
主要功能:
- 外部访问:为应用程序提供一个外部可访问的 URL。
- TLS 终止:可以配置 TLS 终止,以提供 HTTPS 访问。
- 路由规则:可以基于路径或主机名等定义复杂的路由规则。
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: example-route
spec:
host: example.com
to:
kind: Service
name: example-service
port:
targetPort: 8080
Service 和 Route 的关系:
- Service 作为 Route 的目标:
Route需要一个目标Service来将外部请求路由到集群内的 Pod。Service提供了负载均衡和服务发现功能,将流量分发到后端的 Pod。 - 服务暴露链:
Route通过Service将外部流量导向具体的 Pod。这样,Route提供了从外部世界到集群内部的入口,而Service管理集群内部的流量分发。
工作流程示例:
创建 Service:首先创建一个 Service,定义如何访问一组 Pod。
apiVersion: v1
kind: Service
metadata:
name: example-service
spec:
selector:
app: example
ports:
- protocol: TCP
port: 80
targetPort: 8080
创建 Route:然后创建一个 Route,将外部请求路由到该 Service。
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: example-route
spec:
host: example.com
to:
kind: Service
name: example-service
port:
targetPort: 8080
访问应用:外部用户通过 http://example.com 访问应用,Route 将请求转发到 example-service,Service 再将请求负载均衡到相应的 Pod。
总结:
在 OpenShift 中,Service 和 Route 共同构成了应用程序网络访问的核心机制。Service 用于在集群内部提供稳定的网络访问和负载均衡,而 Route 用于将外部流量引入集群并路由到相应的 Service。通过这两个资源的配合,OpenShift 实现了灵活而强大的网络流量管理和暴露机制。
问题: 如何绑定 service 和 pod?
在 Kubernetes 和 OpenShift 中,Service 是通过标签选择器(label selector)来绑定到 Pod 的。这个过程涉及以下步骤:
- 为 Pod 设置标签。
- 创建一个 Service,并定义标签选择器以匹配 Pod 的标签。
1. 为 Pod 设置标签
首先,确保你的 Pod 有合适的标签。你可以在 Pod 的 YAML 配置文件中定义标签,或者使用 oc label 命令给现有的 Pod 添加标签。
在 Pod 配置文件中定义标签
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
app: my-app
spec:
containers:
- name: my-container
image: my-image:latest
使用 oc label 命令添加标签
oc label pod my-pod app=my-app
2. 创建 Service 并定义标签选择器
创建一个 Service,并在其配置文件中定义标签选择器,使其选择具有相应标签的 Pod。
Service 配置文件示例
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
在这个例子中,Service 使用标签选择器 app: my-app 来选择所有具有该标签的 Pod,并将流量路由到这些 Pod 的 8080 端口。
使用 oc create 命令创建 Service
将上面的 Service 配置文件保存为 service.yaml,然后使用以下命令创建 Service:
oc create -f service.yaml
验证绑定
创建 Service 后,你可以通过以下命令查看 Service 的详细信息,确认它是否正确绑定到 Pod。
oc get service my-service -o yaml
并查看 Endpoints:
oc get endpoints my-service
输出示例:
NAME ENDPOINTS AGE my-service 10.1.1.1:8080,10.1.1.2:8080 5m
总结
通过以下步骤可以将 Service 绑定到 Pod:
- 设置 Pod 标签:在 Pod 配置文件中定义标签或使用
oc label命令添加标签。 - 创建 Service:在 Service 配置文件中定义标签选择器,使其匹配相应的 Pod 标签。
- 验证绑定:使用
oc get service和oc get endpoints命令验证 Service 是否正确绑定到 Pod。
这样,Service 就可以通过标签选择器将流量路由到相应的 Pod。
问题: service yaml 中 port: 80 targetPort: 8080 是什么?
在 Kubernetes 和 OpenShift 中,Service 的 port 和 targetPort 是用来定义网络流量的路由规则的。它们在 Service 的配置中指定了外部访问端口和目标容器端口之间的映射关系。让我们详细解释一下这两个字段的作用:
port 和 targetPort 的作用
port:这是 Service 暴露给外部的端口。外部客户端(如其他 Pod 或用户)通过这个端口访问 Service。targetPort:这是 Service 将流量路由到后端 Pod 的端口。也就是说,Service 将接收到的流量转发到指定的 Pod 上的这个端口。
示例
假设有一个 Service 配置如下:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
在这个示例中:
port: 80:客户端将通过端口80访问这个 Service。targetPort: 8080:Service 将流量路由到匹配标签app: my-app的 Pod 上的8080端口。
工作流程
- 客户端请求:客户端发送一个请求到
my-service的 IP 地址(ClusterIP)上的80端口。 - Service 路由:Service 接收到请求后,将流量转发到后端 Pod 的
8080端口。 - Pod 响应:运行在 Pod 上的应用监听
8080端口,接收请求并进行处理,然后返回响应。
port:Service 的暴露端口,可以是任意未被占用的端口号。
targetPort:通常是容器内应用程序正在监听的端口。
问题:访问service 是通过名字 还是ip?
在 Kubernetes 和 OpenShift 中,访问 Service 可以通过名字或 IP 地址来实现。两种方式各有其适用场景和特点。
通过 Service 名称访问
集群内部 DNS 解析
Kubernetes 内部提供了 DNS 服务,可以通过 Service 的名称在集群内进行服务发现。默认情况下,Service 名称会被解析成该 Service 的 Cluster IP 地址。这种方式更为常用,因为它避免了硬编码 IP 地址,增加了灵活性和可移植性。
- 同一命名空间内: 在同一命名空间内,直接使用 Service 名称即可。例如,如果 Service 名称是
my-service,则可以通过my-service访问。
curl http://my-service
- 跨命名空间: 如果需要跨命名空间访问 Service,需要使用完整的 DNS 名称:
<service-name>.<namespace>.svc.cluster.local。
curl http://my-service.my-namespace.svc.cluster.local
示例
假设有一个 Service 配置如下:
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: my-namespace
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
在同一命名空间内的 Pod 可以通过 my-service 访问,而在其他命名空间内的 Pod 则需要通过 my-service.my-namespace.svc.cluster.local 访问。
通过 IP 地址访问
ClusterIP
每个 Service 都有一个 ClusterIP,这是集群内部可访问的 IP 地址。可以直接使用这个 IP 地址来访问 Service,但这种方式不如通过名称访问灵活,因为 IP 地址是固定的,代码中硬编码 IP 地址会降低可移植性。
获取 ClusterIP:
oc get service my-service -o wide
输出示例:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE my-service ClusterIP 10.217.5.54 <none> 80/TCP 1d
在这个例子中,10.217.5.54 是 my-service 的 ClusterIP。
通过 ClusterIP 访问:
curl http://10.217.5.54
问题:oc new-app 命令创建一个新应用时,如果不指定 --name 参数,生成名称是什么?
在 OpenShift 中,使用 oc new-app 命令创建一个新应用时,如果不指定 --name 参数,OpenShift 将自动生成应用的名称。这个名称通常基于你提供的源代码、镜像或者模板的名称,但也可能在必要时添加一些随机字符以确保名称的唯一性。
示例:不指定 --name 的情况
假设你使用以下命令创建一个新应用:
oc new-app https://github.com/openshift/nodejs-ex
OpenShift 将根据提供的 Git 仓库名称生成应用名称。在这个例子中,应用名称将可能是 nodejs-ex。
自动生成名称的规则
- 基于源代码仓库:如果你提供一个 Git 仓库 URL,应用的名称通常基于仓库名称。例如,
https://github.com/openshift/nodejs-ex将生成nodejs-ex作为应用名称。 - 基于镜像:如果你使用镜像创建应用,应用的名称通常基于镜像名称。例如,使用
oc new-app openshift/nodejs,应用名称可能是nodejs。 - 基于模板:如果你使用模板创建应用,应用名称通常基于模板中定义的名称。
如何查看生成的名称
你可以通过以下命令查看新应用的资源名称:
oc get all
这将列出当前命名空间中的所有资源,包括新创建的应用相关资源。
示例操作
1.创建一个新应用,但不指定 --name:
oc new-app https://github.com/openshift/nodejs-ex
2.查看生成的资源名称:
oc get all
示例输出:
NAME READY STATUS RESTARTS AGE pod/nodejs-ex-1-build 0/1 Completed 0 2m pod/nodejs-ex-1-xxxxx 1/1 Running 0 1m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/nodejs-ex ClusterIP 172.30.0.1 <none> 8080/TCP 2m NAME READY UP-TO-DATE AVAILABLE AGE deployment/nodejs-ex 1/1 1 1 2m NAME DESIRED CURRENT READY AGE replicaset.apps/nodejs-ex-1 1 1 1 2m NAME REVISION DESIRED CURRENT TRIGGERED BY deploymentconfig.apps/nodejs-ex 1 1 1 config,image(nodejs-ex:latest)
在这个例子中,生成的应用名称是 nodejs-ex,所有相关资源(如 DeploymentConfig、Service、Pod 等)都以这个名称命名。
总结
当你使用 oc new-app 命令创建应用而不指定 --name 参数时,OpenShift 将根据输入的源代码、镜像或模板自动生成应用名称。你可以通过 oc get all 命令查看生成的资源名称及其状态。这种自动命名机制简化了应用创建过程,特别是对于快速开发和测试场景。
问题:上面例子 pod name 为什么是 nodejs-ex-1-xxxxx?
在 OpenShift 中,当你创建一个应用时,Pod 的名称通常由以下几个部分组成:
- 应用名称:例如
nodejs-ex,这是你创建应用时指定的名称或 OpenShift 自动生成的名称。 - 版本号:例如
1,表示 DeploymentConfig 的当前版本号。 - 随机后缀:例如
xxxxx,是一个随机生成的字符串,用于确保 Pod 名称的唯一性。
具体名称构成
让我们详细解释这个名称 nodejs-ex-1-xxxxx:
nodejs-ex:应用名称。这是你在创建应用时由oc new-app命令生成的名称。1:版本号。表示这是 DeploymentConfig 的第一个版本。当你对 DeploymentConfig 进行修改(例如更新镜像、修改环境变量等),版本号会递增。xxxxx:随机后缀。这是一个随机生成的字符串,用于确保 Pod 名称的唯一性。这样可以避免命名冲突,特别是在滚动更新或扩展 Pod 的时候。
假设你使用以下命令创建一个应用:
oc new-app https://github.com/openshift/nodejs-ex
OpenShift 将创建相关资源,并生成 DeploymentConfig 名称为 nodejs-ex。第一次创建时,版本号为 1。生成的 Pod 名称可能类似于 nodejs-ex-1-xxxxx,其中 xxxxx 是随机生成的字符串。
DeploymentConfig 和 Pod 名称
每次你对 DeploymentConfig 进行修改时,例如通过以下命令设置环境变量:
oc set env dc/nodejs-ex MY_VAR=my_value
DeploymentConfig 的版本号将递增。例如,从 1 递增到 2。新创建的 Pod 名称将变为 nodejs-ex-2-yyyyy,其中 yyyyy 是另一个随机生成的字符串。
示例
1.初始创建:
oc new-app https://github.com/openshift/nodejs-ex
创建的资源和 Pod:
NAME READY STATUS RESTARTS AGE pod/nodejs-ex-1-abcde 1/1 Running 0 1m
2.修改 DeploymentConfig:
oc set env dc/nodejs-ex MY_VAR=my_value
新版本的 Pod:
NAME READY STATUS RESTARTS AGE pod/nodejs-ex-2-fghij 1/1 Running 0 1m
在 OpenShift 中,Pod 的名称由应用名称、版本号和随机后缀组成。应用名称是你在创建应用时指定的,版本号表示 DeploymentConfig 的当前版本,每次修改 DeploymentConfig 时会递增,随机后缀确保 Pod 名称的唯一性。通过这种命名机制,可以有效地管理和区分同一个应用的不同版本及其对应的 Pod。
问题:为什么修改完探针,会多一个pod?
下面的nodejs代码,通过oc命令创建app
const express = require('express');
const app = express();
const port = 3000;
app.get('/test', (req, res) => {
return res.status(200).send('hello world');
});
// 启动服务器
app.listen(port, () => {
console.log(`服务器运行在 http://localhost:${port}`);
});
oc new-app --name demo http://xxxxxx/demo
我们可以通过控制台,修改deployment添加探针probe
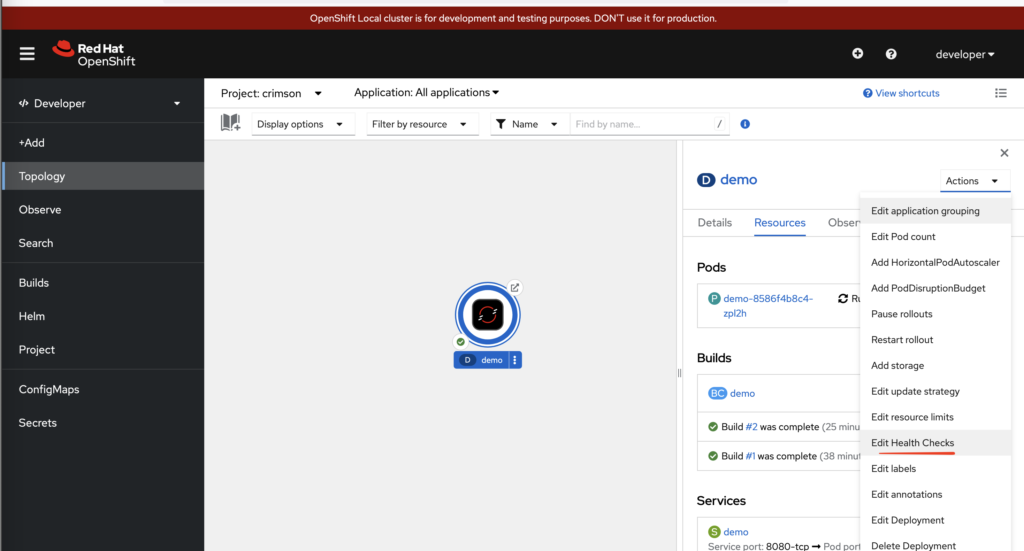
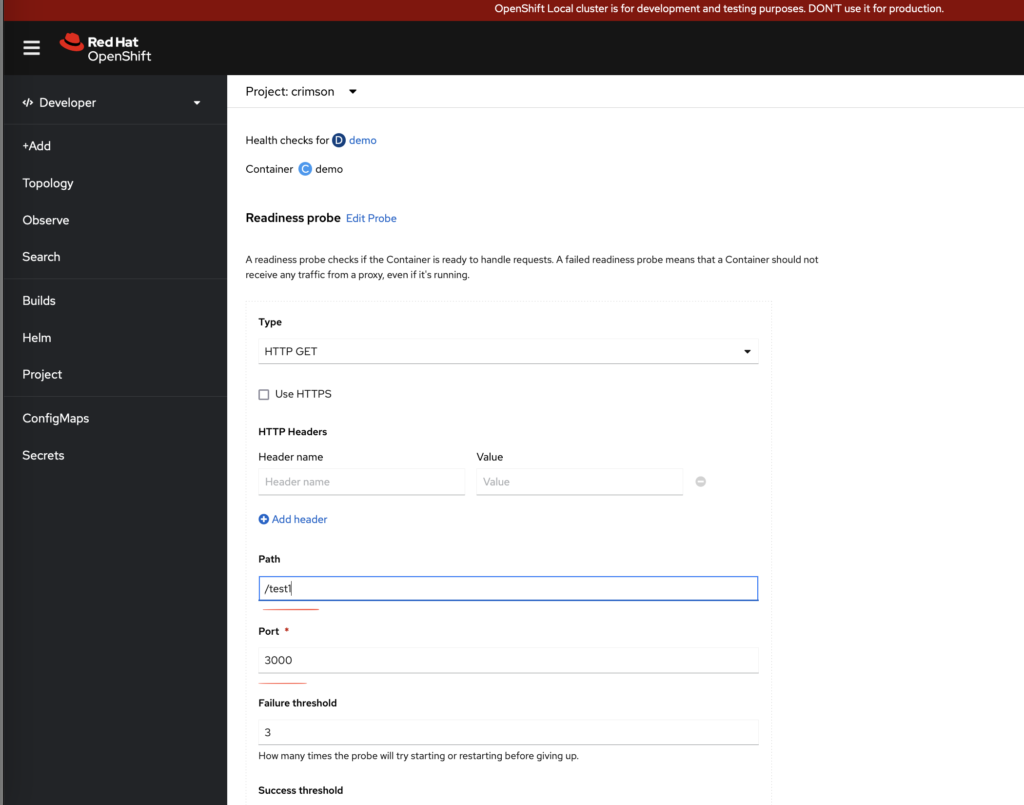
添加一个readiness 探针,故意把url写错成test1(正确应该是test)
保存探针以后,会发现多了一个pod
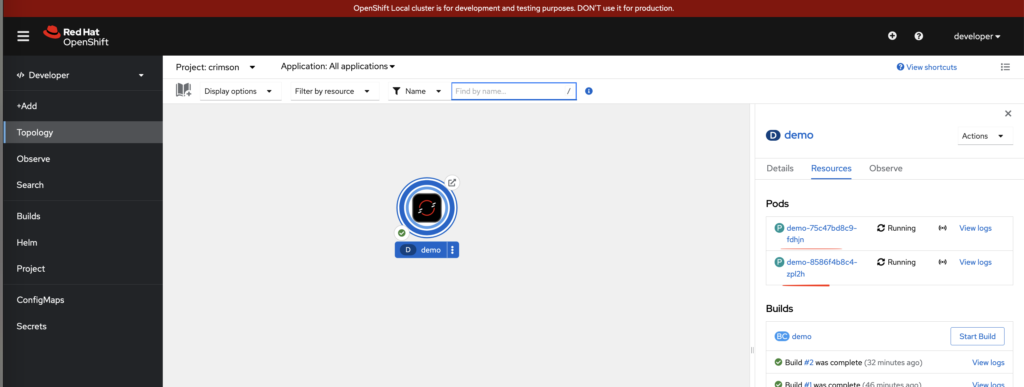
这是因为,当你修改与 deployment 相关的配置(例如探针配置)时,控制器会触发滚动更新过程。这种机制会创建新的 Pod 来应用新的配置,并逐步替换旧的 Pod。
如果新 Pod 的探针配置不正确,可能导致新 Pod 不能进入 Running 状态,从而阻止旧 Pod 的终止。
我们可以通过命令查看一下新pod状态
oc describe pod demo-75c47bd8c9-fdhjn
可以看到在pod events里面,探针检测是失败的,导致新pod没有就绪,旧pod没有被删除
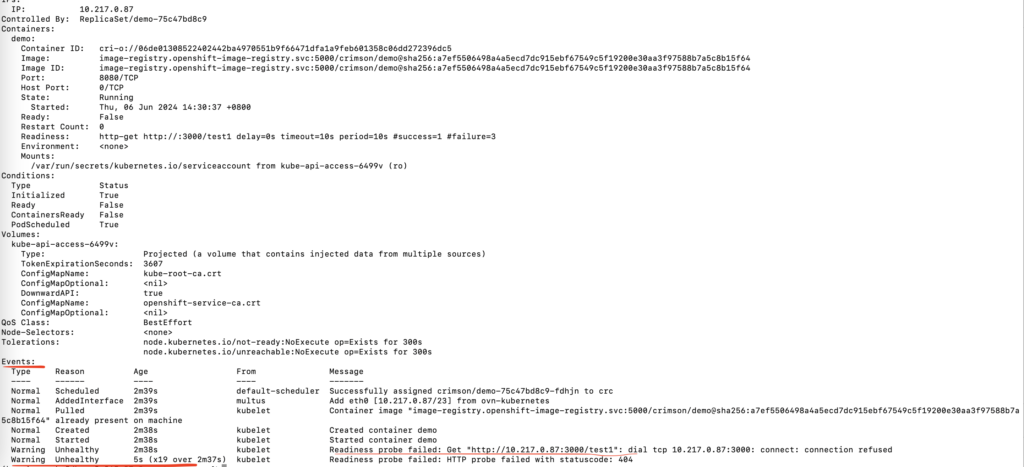
把探针path改成正确的,并且保存。
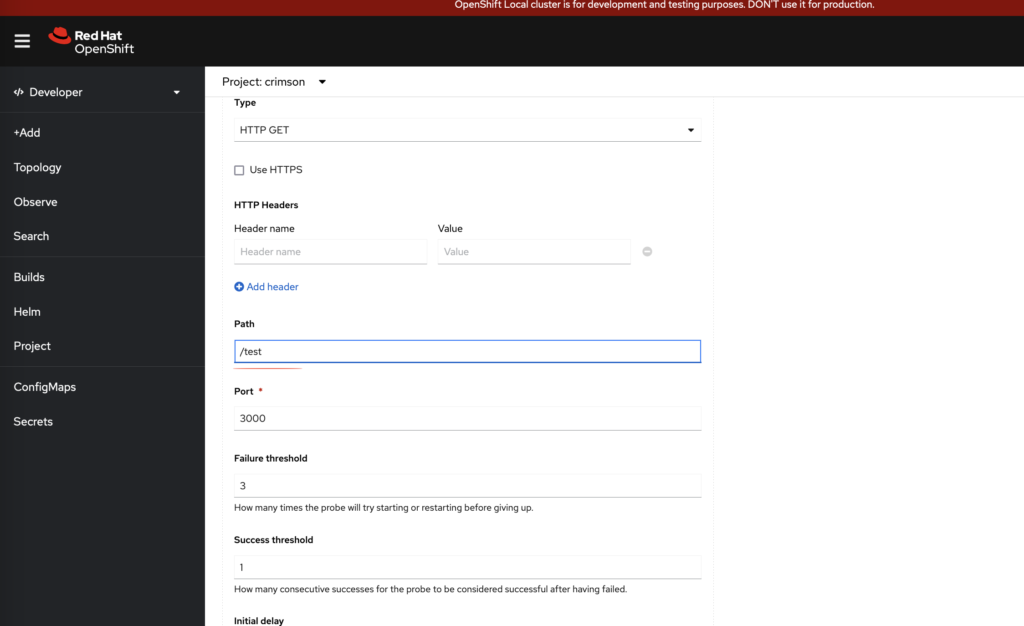
就剩一个新pod了,旧pod被删除掉了。
问题:openshift 可以只创建pod吗? 也就是不创建Deployment 或者 DeploymentConfig 等等?
在 OpenShift 和 Kubernetes 中,虽然直接创建独立的 Pod 是技术上可行的,但这不是推荐的做法。原因是直接创建的 Pod 没有自我修复能力,即如果 Pod 因某种原因崩溃或被删除,它不会自动重新创建。因此,通常会使用 Deployment 或 DeploymentConfig 来管理 Pod,从而实现自动重启、扩展和滚动更新等功能。
不过,如果你确实需要直接创建一个独立的 Pod,可以使用 oc run 或 oc create 命令来实现。以下是一些例子:
使用 oc run 命令创建 Pod
oc run 是一个快捷方式命令,既可以用来创建 Deployment,也可以用来创建 Pod。
oc run mypod --image=nginx --restart=Never
mypod是 Pod 的名称。--image=nginx指定使用的镜像。--restart=Never表示不使用控制器来管理 Pod,从而创建一个独立的 Pod。
使用 oc create 命令创建 Pod
可以直接通过 YAML 文件定义 Pod 并使用 oc create 命令创建。
示例 YAML 文件 mypod.yaml
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mycontainer
image: nginx
ports:
- containerPort: 80
创建 Pod
oc create -f mypod.yaml
查看和管理 Pod
创建 Pod 后,可以使用以下命令查看 Pod 的状态和日志:
oc get pods oc describe pod mypod oc logs mypod
总结
- 直接创建 Pod:虽然可以通过
oc run和oc create命令直接创建 Pod,但不推荐这种方式用于生产环境,因为它缺乏自我修复和管理能力。 - 推荐方式:使用 Deployment 或 DeploymentConfig 来创建和管理 Pod,提供自动重启、扩展和滚动更新等功能。
直接创建 Pod 适用于测试和实验环境,但在实际生产环境中,使用更高层次的控制器来管理 Pod 是更为安全和可靠的做法。
问题:openshift中,pipeline的 Trigger, TriggerBinding, TriggerTemplate区别?
在 OpenShift Pipelines(基于 Tekton)的上下文中,Trigger, TriggerBinding, 和 TriggerTemplate 是用于自动触发 CI/CD 管道的组件。它们各自有不同的功能,但共同作用以响应某些事件来启动一个 Pipeline。
1. Trigger
Trigger 是用来组合 TriggerBinding 和 TriggerTemplate 的组件。它定义了在触发事件发生时如何使用绑定的参数和模板来创建资源(如 PipelineRun)。
- 功能:决定何时以及如何触发 Pipeline 运行。
- 作用:与
EventListener配合使用,以便在接收到某个事件时触发一个特定的 Pipeline 运行。
例子:
apiVersion: triggers.tekton.dev/v1alpha1
kind: Trigger
metadata:
name: example-trigger
spec:
bindings:
- ref: example-binding
template:
ref: example-template
2. TriggerBinding
TriggerBinding 是用来定义如何从事件负载中提取信息并将其映射到 Pipeline 的参数。它提取事件中的信息,并将这些信息与 TriggerTemplate 中定义的参数相对应。
- 功能:将事件中的数据绑定到模板中的参数。
- 作用:允许从事件中提取值并传递给 Pipeline。
示例:
apiVersion: triggers.tekton.dev/v1alpha1
kind: TriggerBinding
metadata:
name: example-binding
spec:
params:
- name: git-repo-url
value: $(body.repository.url)
- name: git-revision
value: $(body.head_commit.id)
3. TriggerTemplate
TriggerTemplate 定义了在 Pipeline 被触发时应该创建的资源。它通常包括 PipelineRun 的定义,并使用来自 TriggerBinding 的参数来填充字段。
- 功能:定义事件触发时创建的资源,如
PipelineRun。 - 作用:模板化 Pipeline 运行的定义,使用绑定的参数来动态生成。
示例:
apiVersion: triggers.tekton.dev/v1alpha1
kind: TriggerTemplate
metadata:
name: example-template
spec:
params:
- name: git-repo-url
- name: git-revision
resourcetemplates:
- apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
generateName: example-pipeline-run-
spec:
pipelineRef:
name: example-pipeline
params:
- name: git-repo-url
value: $(params.git-repo-url)
- name: git-revision
value: $(params.git-revision)
总结
- Trigger: 定义了事件触发时如何组合
TriggerBinding和TriggerTemplate,以及触发的条件。 - TriggerBinding: 从事件中提取数据,并将其映射到
TriggerTemplate的参数。 - TriggerTemplate: 使用
TriggerBinding中的参数,定义事件触发时需要创建的资源(如PipelineRun)。
它们一起工作,能够动态响应事件并自动触发 CI/CD 管道。
补充:
OpenShift运行环境中EventListener。
EventListener运行在Pod中,其Service对应的Route地址就是Github中使用的Webhook URL地址。
EventListener会将回调参数通过TriggerBinding传给TriggerTemplate,TriggerTemplate再使用自己定义的Pipeline运行CI/CD过程。
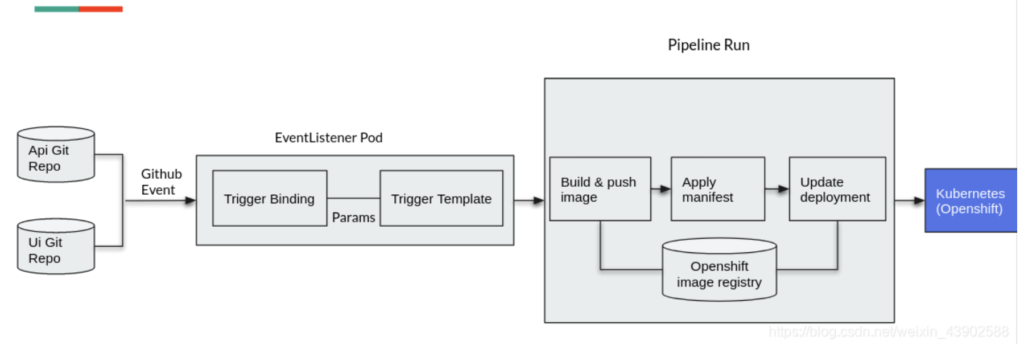
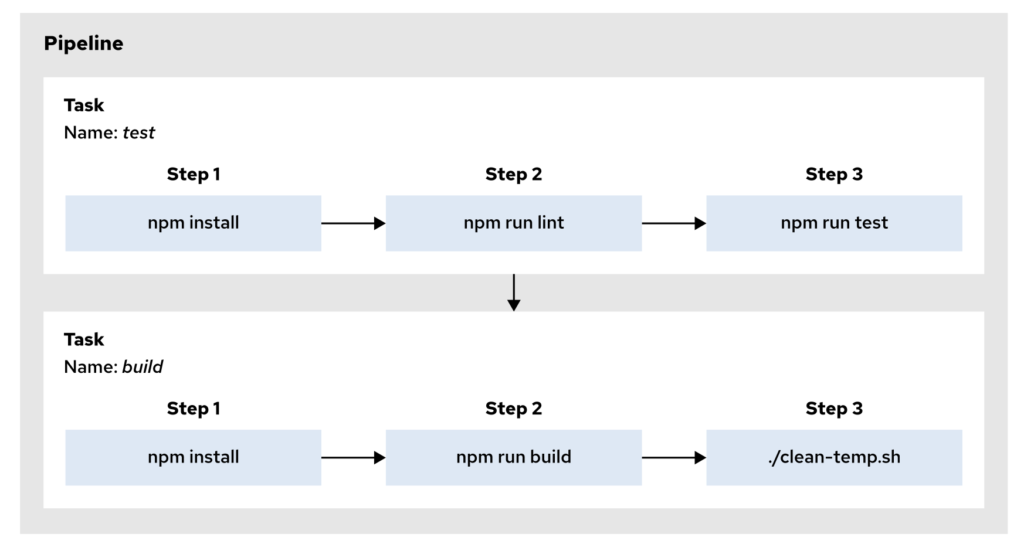
问题:在 OpenShift Pipelines(基于 Tekton)的环境中,Trigger 和 Pipeline 关系?
在 OpenShift Pipelines(基于 Tekton)的环境中,Trigger 和 Pipeline 是两个核心组件,但它们的作用和用途是不同的。以下是它们的区别和相互关系:
1. Pipeline
Pipeline 是一个定义了一系列任务(Tasks)和步骤(Steps)的组件,用于构建、测试、部署应用程序或执行其他自动化流程。
- 功能:定义了一个 CI/CD 工作流,它由多个任务组成,这些任务可以按顺序或并行执行。
- 作用:
Pipeline是实际执行工作流的主体。每个Task可以执行一项特定的操作,如构建镜像、运行测试、部署应用等。
示例:
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: example-pipeline
spec:
tasks:
- name: build-task
taskRef:
name: build-task
- name: test-task
taskRef:
name: test-task
- name: deploy-task
taskRef:
name: deploy-task
runAfter:
- test-task
在这个例子中,Pipeline 定义了一个包含三个任务的工作流,分别用于构建、测试和部署应用程序。
2. Trigger
Trigger 是一种机制,用于根据外部事件(如 Git 提交、Webhook 触发等)自动启动 Pipeline。它负责监听事件,并决定何时、如何触发 Pipeline 运行。
- 功能:
Trigger通过绑定事件和Pipeline,使得Pipeline可以在满足特定条件时自动运行,而不需要手动触发。 - 作用:
Trigger配合TriggerBinding和TriggerTemplate,监听外部事件并自动触发Pipeline运行。它将事件数据传递给Pipeline作为参数。
工作流程:
- 事件发生:外部事件(如 Git 推送)触发
Trigger。 - 数据绑定:
TriggerBinding从事件中提取相关数据。 - 模板填充:
TriggerTemplate使用这些数据生成PipelineRun的定义。 - 触发 Pipeline:最终,
Trigger创建并运行PipelineRun,启动Pipeline的执行。
总结
- Pipeline 是定义 CI/CD 工作流的组件,包含了具体的构建、测试、部署任务。它是实际执行工作的主体。
- Trigger 是一个触发机制,用于根据外部事件自动启动
Pipeline,从而实现自动化的 CI/CD 流程。
Trigger 通过 TriggerBinding 和 TriggerTemplate 使得 Pipeline 可以在特定事件发生时自动运行,而 Pipeline 则负责定义具体的工作流步骤和任务。
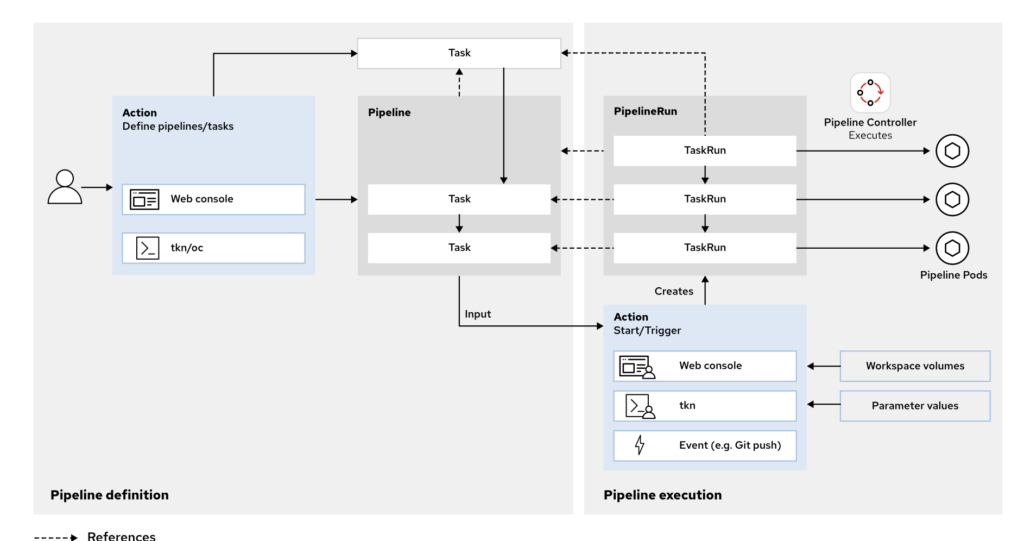
问题:Trigger 和 Pipeline 如何传递参数?
在 OpenShift Pipelines(基于 Tekton)中,Trigger 和 Pipeline 的参数传递是一个关键的机制,用于将来自外部事件(如 Git 提交)中的信息传递给 Pipeline,以便在运行时进行动态配置。以下是参数传递的详细流程和示例:
1. Pipeline 定义参数
首先,在 Pipeline 中定义参数。这些参数可以在 PipelineRun 运行时动态传入。
示例:定义一个 Pipeline 并添加参数
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: example-pipeline
spec:
params:
- name: git-repo-url
type: string
description: The URL of the Git repository
- name: git-revision
type: string
description: The Git revision to build
default: main
tasks:
- name: build
taskRef:
name: build-task
params:
- name: repo-url
value: $(params.git-repo-url)
- name: revision
value: $(params.git-revision)
在这个例子中,Pipeline 定义了两个参数 git-repo-url 和 git-revision,这些参数将用于 Task 中。
2. TriggerBinding 传递参数
TriggerBinding 用于从事件负载(例如 GitHub Webhook 事件)中提取数据,并将其映射到 Pipeline 的参数。
示例:定义一个 TriggerBinding
apiVersion: triggers.tekton.dev/v1alpha1
kind: TriggerBinding
metadata:
name: example-binding
spec:
params:
- name: git-repo-url
value: $(body.repository.url)
- name: git-revision
value: $(body.head_commit.id)
在这个示例中,TriggerBinding 从事件负载中提取 repository.url 和 head_commit.id,并将它们映射到 Pipeline 的参数 git-repo-url 和 git-revision。
3. TriggerTemplate 使用参数
TriggerTemplate 定义了触发事件时创建的资源,并使用 TriggerBinding 提供的参数值。
示例:定义一个 TriggerTemplate
apiVersion: triggers.tekton.dev/v1alpha1
kind: TriggerTemplate
metadata:
name: example-template
spec:
params:
- name: git-repo-url
- name: git-revision
resourcetemplates:
- apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
generateName: example-pipeline-run-
spec:
pipelineRef:
name: example-pipeline
params:
- name: git-repo-url
value: $(params.git-repo-url)
- name: git-revision
value: $(params.git-revision)
在这个 TriggerTemplate 中,TriggerBinding 提供的参数 git-repo-url 和 git-revision 被传递到 PipelineRun 的参数中,从而启动对应的 Pipeline。
4. Trigger 组合所有部分
Trigger 将 TriggerBinding 和 TriggerTemplate 组合在一起,以便在事件发生时自动创建 PipelineRun 并传递参数。
示例:定义一个 Trigger
apiVersion: triggers.tekton.dev/v1alpha1
kind: Trigger
metadata:
name: example-trigger
spec:
bindings:
- ref: example-binding
template:
ref: example-template
interceptors:
- ref:
name: github
在这个 Trigger 中,当 GitHub 事件发生时,TriggerBinding 提取的数据将通过 TriggerTemplate 传递给 PipelineRun,从而启动 Pipeline。
总结
- Pipeline 定义参数,这些参数将在运行时接收值。
- TriggerBinding 从事件负载中提取值,并将其映射到
Pipeline的参数。 - TriggerTemplate 使用
TriggerBinding的参数值来创建PipelineRun。 - Trigger 组合
TriggerBinding和TriggerTemplate,并在事件发生时自动传递参数和触发Pipeline。
问题:pipeline.yaml 和 pipelinerun.yaml 关系?
在 OpenShift Pipelines(基于 Tekton)中,pipeline.yaml 和 pipelinerun.yaml 是两种不同的 YAML 文件,分别用于定义和执行 CI/CD 流程。以下是它们的区别和用途:
1. Pipeline (pipeline.yaml)
Pipeline 是一个定义 CI/CD 工作流的 YAML 文件。它描述了一个工作流的结构,包括需要执行的任务、任务之间的顺序以及所需的参数。
- 功能:定义一系列按顺序或并行执行的任务(Tasks),这些任务共同构成了一个 CI/CD 流程。
- 作用:
Pipeline文件主要用于描述管道的整体结构,并不会自动执行,而是作为一种模板,等待触发。
示例:pipeline.yaml
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: example-pipeline
spec:
params:
- name: git-repo-url
type: string
description: The URL of the Git repository
- name: git-revision
type: string
description: The Git revision to build
default: main
tasks:
- name: build-task
taskRef:
name: build
params:
- name: repo-url
value: $(params.git-repo-url)
- name: revision
value: $(params.git-revision)
- name: deploy-task
taskRef:
name: deploy
runAfter:
- build-task
在这个例子中,Pipeline 定义了一个包含构建和部署任务的 CI/CD 工作流。它不会直接运行,而是需要通过 PipelineRun 来启动。
2. PipelineRun (pipelinerun.yaml)
PipelineRun 是一个用于执行 Pipeline 的 YAML 文件。它引用了一个特定的 Pipeline,并为其提供运行时所需的参数。每次运行 Pipeline 都会创建一个 PipelineRun 实例。
- 功能:启动并执行一个
Pipeline,将参数传递给Pipeline并创建一个具体的运行实例。 - 作用:
PipelineRun文件用于实际触发和执行管道中的任务,并在每次执行时创建一个新的运行实例。
示例:pipelinerun.yaml
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
name: example-pipelinerun
spec:
pipelineRef:
name: example-pipeline
params:
- name: git-repo-url
value: https://github.com/example/repo.git
- name: git-revision
value: main
在这个例子中,PipelineRun 引用了 example-pipeline,并为它提供了运行时的参数 git-repo-url 和 git-revision。运行这个 PipelineRun 会实际执行 example-pipeline 中定义的工作流。
总结
- Pipeline (
pipeline.yaml): 定义了一个 CI/CD 流程的结构,包括任务、顺序、参数等。它是一个模板,不会自动执行。 - PipelineRun (
pipelinerun.yaml): 用于启动和执行Pipeline。每次运行Pipeline时,都需要通过PipelineRun来启动,传递必要的参数,并生成一个运行实例。
PipelineRun 是实际执行 Pipeline 的触发器,而 Pipeline 则是定义了工作流的蓝图。
问题:PipelineRun 和 Trigger的关系,Trigger不是也能触发Pipeline 并且传递参数吗?
是的,Trigger 和 PipelineRun 都能触发 Pipeline 并传递参数,但它们的用途和使用场景略有不同。以下是两者的关系和区别:
PipelineRun 是直接执行 Pipeline 的实体,它包含了 Pipeline 的引用和参数,并且每次运行 Pipeline 时都会生成一个新的 PipelineRun 实例。PipelineRun 通常是手动创建的,或者由某种自动化工具触发,用于执行定义好的 CI/CD 流程。
1.PipelineRun
- 手动触发: 通常是直接通过命令行或 YAML 文件来手动触发
Pipeline。 - 参数传递: 可以在
PipelineRun中指定参数值,以便在运行时传递给Pipeline。 - 使用场景: 适用于在特定时间或条件下手动触发
Pipeline。
示例:
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
name: example-pipelinerun
spec:
pipelineRef:
name: example-pipeline
params:
- name: git-repo-url
value: https://github.com/example/repo.git
- name: git-revision
value: main
在这个例子中,PipelineRun 手动触发了 example-pipeline,并传递了 git-repo-url 和 git-revision 参数。
2. Trigger
Trigger 是一种机制,用于自动化 Pipeline 的执行。它基于外部事件(如 Webhook)来动态创建和触发 PipelineRun。通过 Trigger,可以实现事件驱动的 CI/CD 流程。
- 自动触发: 由外部事件(如 GitHub 提交、Webhook)触发
Pipeline。当事件发生时,Trigger会自动创建一个PipelineRun实例并执行。 - 参数传递: 通过
TriggerBinding从事件负载中提取参数,并通过TriggerTemplate将这些参数传递给PipelineRun。 - 使用场景: 适用于事件驱动的自动化 CI/CD 流程,如在每次代码提交时自动构建和部署。
工作流程:
- 事件发生: 外部事件(如 Git 提交)触发
Trigger。 - 数据提取:
TriggerBinding从事件负载中提取数据(如 Git 仓库 URL、提交 ID)。 - 创建 PipelineRun:
TriggerTemplate使用提取的数据创建一个新的PipelineRun实例。 - 自动执行: 生成的
PipelineRun自动执行Pipeline。
示例:
apiVersion: triggers.tekton.dev/v1alpha1
kind: Trigger
metadata:
name: example-trigger
spec:
bindings:
- ref: example-binding
template:
ref: example-template
interceptors:
- ref:
name: github
在这个例子中,Trigger 监听 GitHub 的 Webhook 事件,并自动创建一个 PipelineRun 来执行 example-pipeline,无需人工干预。
3. Trigger 和 PipelineRun 的关系
Trigger自动创建PipelineRun:Trigger是一种自动化机制,当某个事件发生时,它会自动创建并执行一个PipelineRun,从而触发Pipeline。Trigger是PipelineRun的一种自动生成器,帮助实现事件驱动的 CI/CD 流程。PipelineRun是触发的具体实例: 无论是手动创建还是通过Trigger自动创建,PipelineRun都是实际执行Pipeline的实例。
总结
PipelineRun: 直接用于手动或编程方式触发Pipeline,适合需要明确控制何时运行Pipeline的场景。Trigger: 用于自动化Pipeline的触发,基于外部事件动态创建PipelineRun,适合事件驱动的 CI/CD 流程。
Trigger 是通过事件自动创建和执行 PipelineRun 的机制,从而使得 Pipeline 可以在事件发生时自动启动和运行。
问题:EventListener 是什么,和Trigger 和pipeline有什么关系吗
EventListener 是 OpenShift Pipelines(基于 Tekton)的一个重要组件,用于处理外部事件并触发相应的 CI/CD 流程。它在整个 Pipeline 触发机制中扮演着关键角色,和 Trigger 以及 Pipeline 关系密切。以下是它们之间的关系和具体功能解释:
1. Pipeline
Pipeline 是一个 CI/CD 工作流的定义。它由一系列按顺序或并行执行的任务(Tasks)组成,这些任务共同完成构建、测试、部署等操作。Pipeline 定义了工作流的结构和逻辑,但不会自动运行,通常需要通过 PipelineRun 来执行。
2. Trigger
Trigger 是一组资源的集合,用于响应外部事件并自动触发 Pipeline。它包括以下主要组件:
- TriggerBinding:定义从外部事件负载中提取数据的规则。它决定了哪些信息(如 Git 仓库 URL、提交 SHA 等)将从事件中提取出来。
- TriggerTemplate:定义了如何使用从事件中提取的数据来创建
PipelineRun或其他 Kubernetes 资源。它基本上是一个模板,描述了触发后的PipelineRun或资源应该是什么样子。 - Trigger:将
TriggerBinding和TriggerTemplate组合在一起,定义了在某个事件发生时应如何处理。
3. EventListener
EventListener 是一个接收外部事件(如 Webhook 请求)的组件。它监听来自外部的 HTTP 请求,并将这些请求映射到一个或多个 Trigger 上。EventListener 是 Trigger 的入口点,是将外部事件与内部 Tekton 触发机制连接起来的桥梁。
工作流程:
- 外部事件:如 GitHub 提交或拉取请求触发一个 Webhook。
- EventListener:接收这个 Webhook 请求,解析其中的数据。
- Trigger:
EventListener将请求的数据传递给关联的Trigger。TriggerBinding提取有用的数据,TriggerTemplate生成一个PipelineRun。 - PipelineRun:生成的
PipelineRun实例启动并执行Pipeline中定义的工作流。
总结
EventListener:负责接收外部事件,并将这些事件传递给Trigger,从而触发Pipeline的执行。Trigger:处理从EventListener传递的数据,并根据需要生成PipelineRun。Pipeline:是实际执行的 CI/CD 流程,由PipelineRun来启动和运行。
EventListener、Trigger 和 Pipeline 共同组成了一个自动化的 CI/CD 触发系统,允许外部事件(如代码提交、拉取请求等)自动触发构建、测试和部署流程。
问题:EventListener 如何关联Trigger?
EventListener 通过引用一个或多个 Trigger 来与它们建立关联。当 EventListener 接收到外部事件(如 Webhook 请求)时,它会根据配置将事件传递给关联的 Trigger,从而触发相应的操作,如创建 PipelineRun 并执行 Pipeline。
关联 Trigger 的方式
EventListener 通过其 spec.triggers 字段来引用一个或多个 Trigger。每个 Trigger 可以指定要使用的 TriggerBinding 和 TriggerTemplate,从而决定如何处理事件数据以及如何生成和执行 PipelineRun。
示例配置
以下是一个 EventListener 关联 Trigger 的示例:
apiVersion: triggers.tekton.dev/v1alpha1
kind: EventListener
metadata:
name: example-listener
spec:
serviceAccountName: pipeline
triggers:
- name: example-trigger
bindings:
- ref: example-triggerbinding
template:
ref: example-triggertemplate
详细说明
EventListener:- 定义了一个名称为
example-listener的EventListener,用于监听外部事件。
- 定义了一个名称为
triggers字段:triggers是一个列表,每个元素都是一个Trigger配置。在这个示例中,EventListener关联了一个名为example-trigger的Trigger。
bindings字段:bindings指定了与这个Trigger关联的TriggerBinding,例如example-triggerbinding。TriggerBinding用于从事件负载中提取数据。
template字段:template指定了一个TriggerTemplate,例如example-triggertemplate,它定义了如何使用提取的数据生成PipelineRun或其他资源。
如何工作
- 事件接收:当
EventListener接收到一个外部事件(如 Webhook)时,它会将该事件传递给它所关联的所有Trigger。 - 数据提取:每个
Trigger会使用它的TriggerBinding从事件中提取有用的数据(如 Git 仓库 URL、提交 SHA 等)。 - 资源生成:提取的数据会被传递给
TriggerTemplate,TriggerTemplate根据这些数据生成一个新的资源(通常是PipelineRun)。 - 执行
Pipeline:最终生成的PipelineRun会启动并执行Pipeline中定义的任务。
总结
EventListener 通过 triggers 字段来关联一个或多个 Trigger。当事件发生时,EventListener 会将事件数据传递给这些 Trigger,从而触发相应的操作(如启动 PipelineRun)。这一机制使得 OpenShift Pipelines 可以根据外部事件动态触发 CI/CD 流程。
问题:为 EventListener 创建 Edge 路由
1.确保 EventListener 已经部署: 您需要先确保 EventListener 已经在您的 OpenShift 集群中部署并运行。
2.为 EventListener 创建 Service: 通常,EventListener 会自动创建一个对应的 Service,您可以使用该 Service 名称来创建路由。如果没有,您需要手动创建一个 Service 来暴露 EventListener。
示例:
apiVersion: v1
kind: Service
metadata:
name: eventlistener-service
spec:
selector:
app: my-eventlistener
ports:
- protocol: TCP
port: 8080
targetPort: 8080
3.使用 oc create route edge 创建路由: 一旦有了 Service,您可以使用以下命令为该 EventListener 创建一个边缘终止的 TLS 路由。
命令:
oc create route edge --service=eventlistener-service
这会创建一个基于 HTTPS 的路由,外部请求将通过该路由进入,并最终被转发到 EventListener 关联的 Service。
4.获取路由的 URL: 创建路由后,您可以使用以下命令查看路由的外部 URL:
oc get route
- 您会看到一个生成的 URL,您可以将其用作 Webhook URL,将外部请求(如 GitHub Webhook)发送到这个 URL。
总结
通过使用 oc create route edge --service=<EventListener的Service名称>,您可以为 EventListener 创建一个外部路由,使其能够接收来自外部系统(如 GitHub、GitLab 等)的 Webhook 请求。这种方式使您的 CI/CD 流程能够响应外部事件并自动触发 Pipeline。