前言
Node.js 的异步特性是其高性能的核心优势,其底层实现融合了 JavaScript 事件循环机制、Libuv 库的线程池管理,以及操作系统的异步 I/O 能力。以下通过具体示例和底层原理解析,深入理解其工作机制。
Node.js 的组成和代码架构
下面先来看一下Node.js 的组成。Node.js 主要是由 V8、Libuv 和一些第三方库组成。
- 1. V8 我们都比较熟悉,它是一个 JS 引擎。但是它不仅实现了 JS 解析和执行,它还是自定义拓展。比如说我们可以通过 V8 提供一些 C++ API 去定义一些全局变量,这样话我们在 JS 里面去使用这个变量了。正是因为 V8 支持这个自定义的拓展,所以才有了 Node.js 等 JS 运行时。
- 2. Libuv 是一个跨平台的异步 IO 库。它主要的功能是它封装了各个操作系统的一些 API, 提供网络还有文件进程的这些功能。我们知道在 JS 里面是没有网络文件这些功能的,在前端时,是由浏览器提供的,而在 Node.js 里,这些功能是由 Libuv 提供的。
- 3. 另外 Node.js 里面还引用了很多第三方库,比如 DNS 解析库,还有 HTTP 解析器等等。
接下来看一下 Node.js 代码整体的架构。
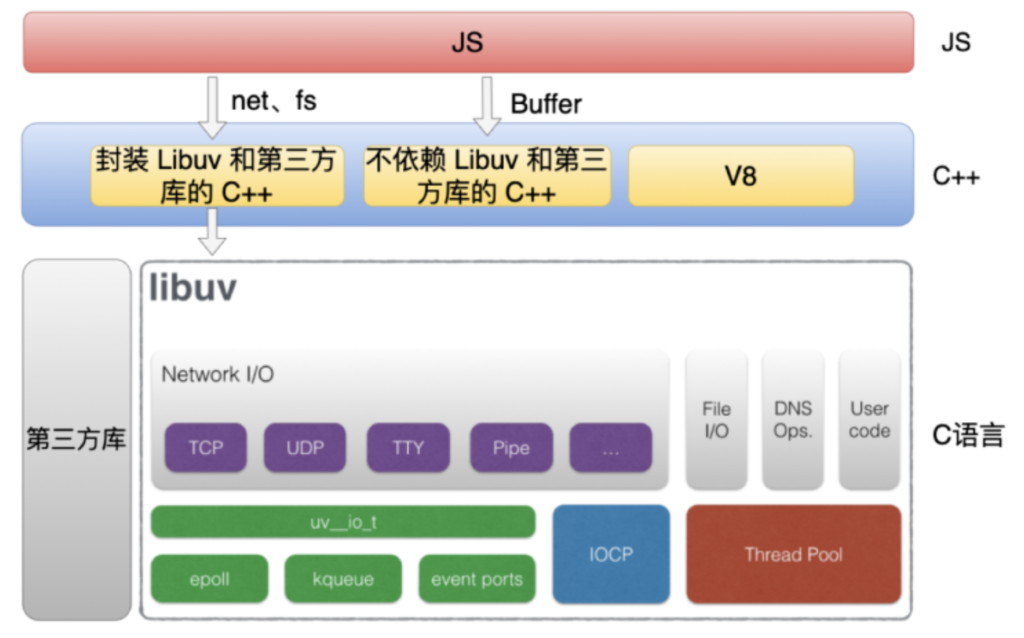
Node.js 代码主要是分为三个部分,分别是C、C++ 和 JS。
- 1. JS 代码就是我们平时在使用的那些 JS 的模块,比方说像 http 和 fs 这些模块。
- 2. C++ 代码主要分为三个部分,第一部分主要是封装 Libuv 和第三方库的 C++ 代码,比如net 和 fs 这些模块都会对应一个 C++ 模块,它主要是对底层的一些封装。第二部分是不依赖 Libuv 和第三方库的 C++ 代码,比方像 Buffer 模块的实现。第三部分 C++ 代码是 V8 本身的代码。
- 3. C 语言代码主要是包括 Libuv 和第三方库的代码,它们都是纯 C 语言实现的代码。
Node.js 中的 Libuv
首先来看一下 Node.js 中的 Libuv,下面从三个方面介绍 Libuv。
- 1. 介绍 Libuv 的模型和限制
- 2. 介绍线程池解决的问题和带来的问题
- 3. 介绍事件循环
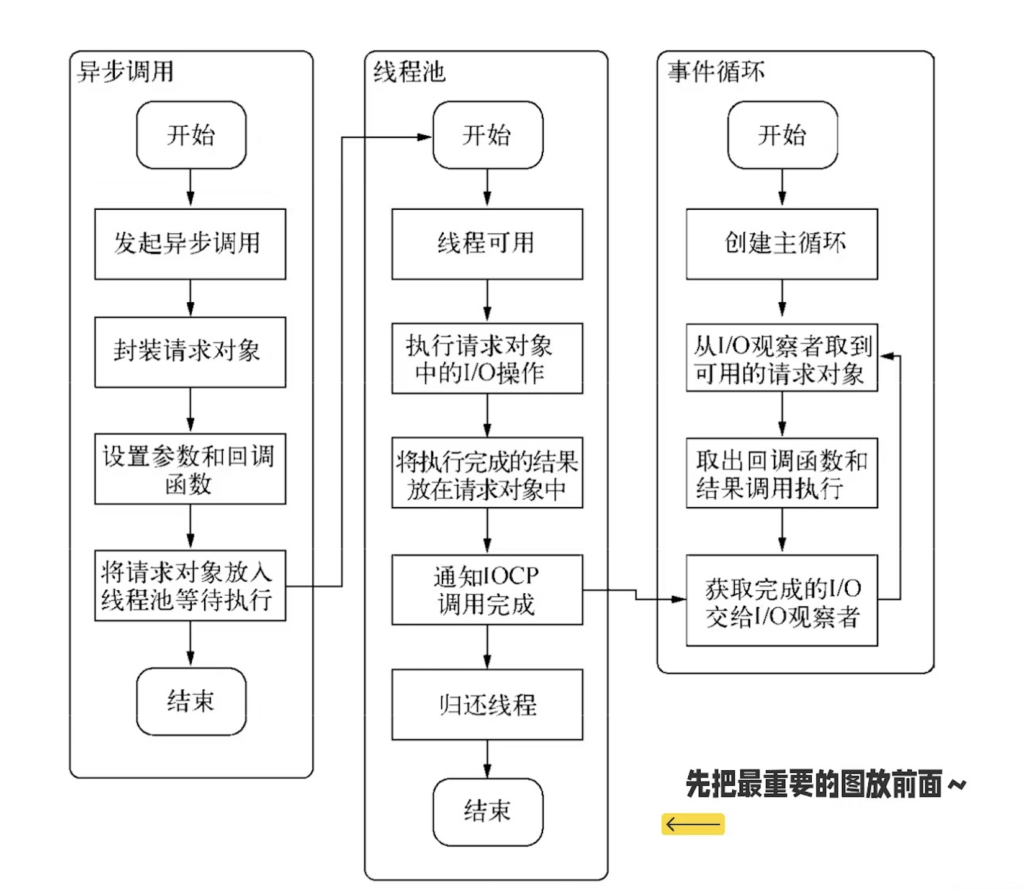
Libuv 本质上是一个生产者消费者的模型。
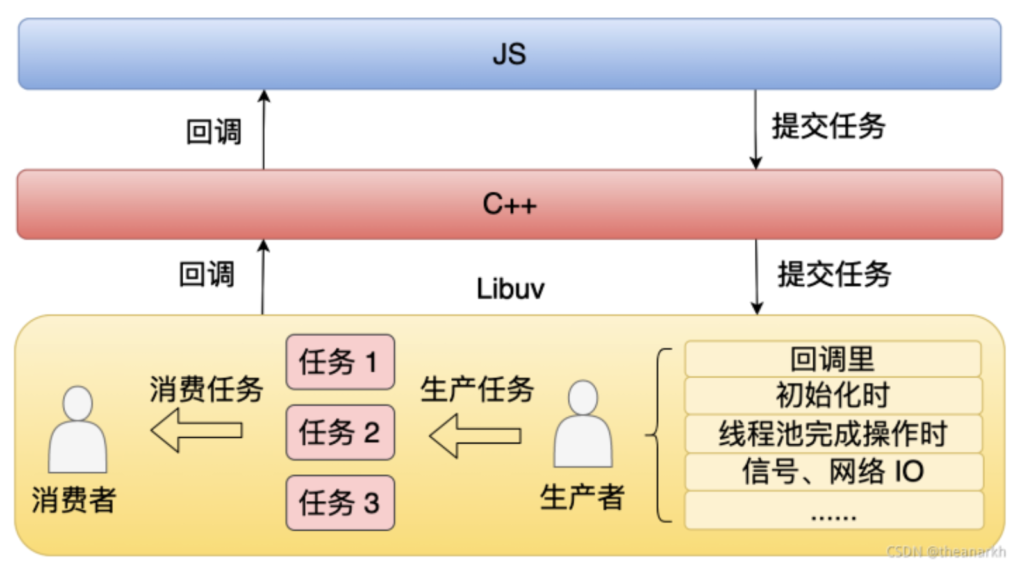
从上面这个图中,我们可以看到在 Libuv 中有很多种生产任务的方式,比如说在一个回调里,在 Node.js 初始化的时候,或者在线程池完成一些操作的时候,这些方式都可以生产任务。然后 Libuv 会不断的去消费这些任务,从而驱动着整个进程的运行,这就是我们一直说的事件循环。
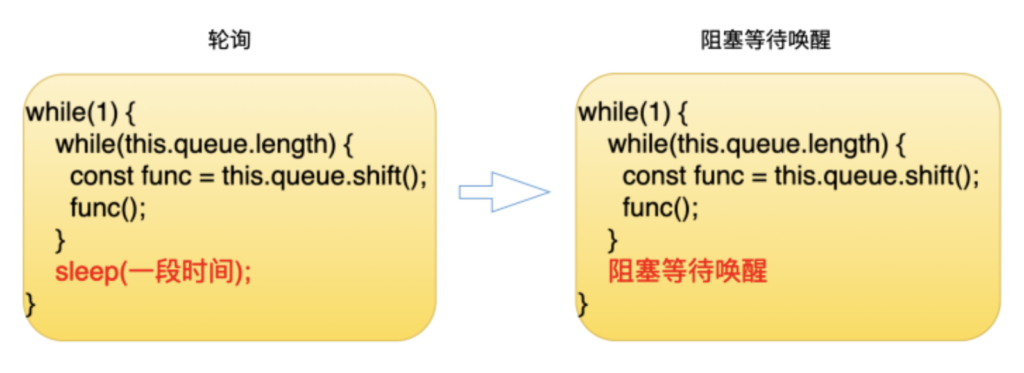
但是生产者的消费者模型存在一个问题,就是消费者和生产者之间,怎么去同步?比如说在没有任务消费的时候,这个消费者他应该在干嘛?第一种方式是消费者可以睡眠一段时间,睡醒之后,他会去判断有没有任务需要消费,如果有的话就继续消费,如果没有的话他就继续睡眠。很显然这种方式其实是比较低效的。第二种方式是消费者会把自己挂起,也就是说这个消费所在的进程会被挂起,然后等到有任务的时候,操作系统就会唤醒它,相对来说,这种方式是更高效的,Libuv 里也正是使用这种方式。
这个逻辑主要是由事件驱动模块实现的,下面看一下事件驱动的大致的流程。
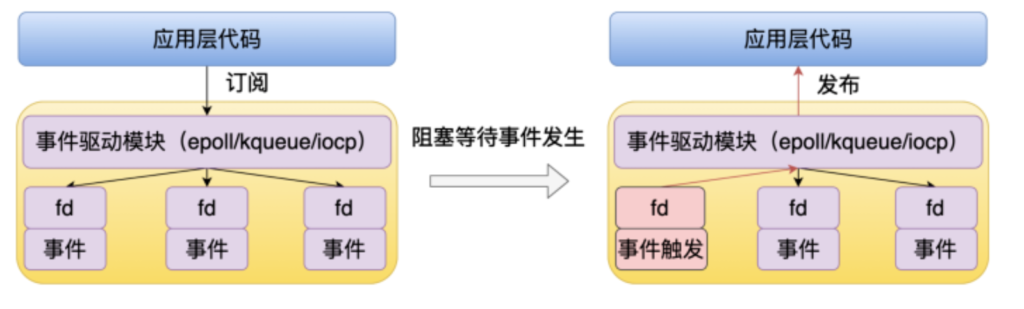
应用层代码可以通过事件驱动模块订阅 fd 的事件,如果这个事件还没有准备好的话,那么这个进程就会被挂起。然后等到这个 fd 所对应的事件触发了之后,就会通过事件驱动模块回调应用层的代码。
下面以 Linux 的 事件驱动模块 epoll 为例,来看一下使用流程。
- 1. 首先通过 epoll_create 去创建一个epoll 实例。
- 2. 然后通过 epoll_ctl 这个函数订阅、修改或者取消订阅一个 fd 的一些事件。
- 3. 最后通过 epoll_wait 去判断当前订阅的事件有没有发生,如果有事情要发生的话,那么就直接执行上层回调,如果没有事件发生的话,这种时候可以选择不阻塞,定时阻塞或者一直阻塞,直到有事件发生。要不要阻塞或者说阻塞多久,是根据当前系统的情况。比如 Node.js 里面如果有定时器的节点的话,那么 Node.js 就会定时阻塞,这样就可以保证定时器可以按时执行。
接下来再深入一点去看一下 epoll 的大致的实现。
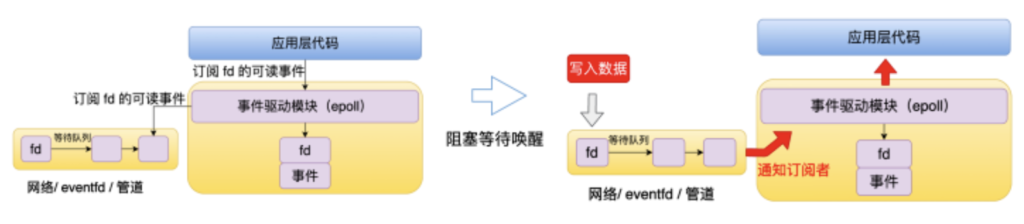
当应用层代码调用事件驱动模块订阅 fd 的事件时,比如说这里是订阅一个可读事件。那么事件驱动模块它就会往这个 fd 的队列里面注册一个回调,如果当前这个事件还没有触发,这个进程它就会被阻塞。等到有一块数据写入了这个 fd 时,也就是说这个 fd 有可读事件了,操作系统就会执行事件驱动模块的回调,事件驱动模块就会相应的执行用层代码的回调。
但是 epoll 存在一些限制。首先第一个是不支持文件操作的,比方说文件读写这些,因为操作系统没有实现。第二个是不适合执行耗时操作,比如大量 CPU 计算、引起进程阻塞的任务,因为 epoll 通常是搭配单线程的,如果在单线程里执行耗时任务,就会导致后面的任务无法执行。
线程池解决的问题和带来的问题
针对这个问题,Libuv 提供的解决方案就是使用线程池。下面来看一下引入了线程池之后, 线程池和主线程的关系。
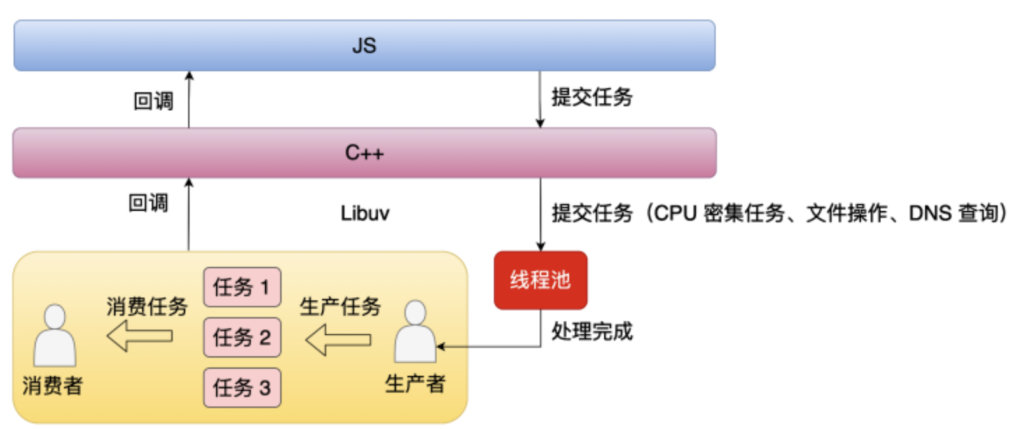
从这个图中我们可以看到,当应用层提交任务时,比方说像 CPU 计算还有文件操作,这种时候不是交给主线程去处理的,而是直接交给线程池处理的。线程池处理完之后它会通知主线程。
但是引入了多线程后会带来一个问题,就是怎么去保证上层代码跑在单个线程里面。因为我们知道 JS 它是单线程的,如果线程池处理完一个任务之后,直接执行上层回调,那么上层代码就会完全乱了。这种时候就需要一个异步通知的机制,也就是说当一个线程它处理完任务的时候,它不是直接去执行上程回调的,而是通过异步机制去通知主线程来执行这个回调。

Libuv 中具体通过 fd 的方式去实现的。当线程池完成任务时,它会以原子的方式去修改这个 fd 为可读的,然后在主线程事件循环的 Poll IO 阶段时,它就会执行这个可读事件的回调,从而执行上层的回调。可以看到,Node.js 虽然是跑在多线程上面的,但是所有的 JS 代码都是跑在单个线程里的,这也是我们经常讨论的 Node.js 是单线程还是多线程的,从不同的角度去看就会得到不同的答案。
一、Node.js 异步的核心组件
Node.js 的异步实现依赖三大核心组件:
- V8 引擎:解析和执行 JavaScript 代码。
- Libuv 库:跨平台的异步 I/O 引擎,负责事件循环、线程池管理等。
- 操作系统内核:提供底层系统调用(如文件读写、网络请求)。
二、底层实现示例:文件读取的异步过程
以读取文件为例,看 Node.js 如何实现异步操作:
const fs = require('fs');
console.log('1. 开始执行');
fs.readFile('/path/to/file.txt', 'utf8', (err, data) => {
console.log('3. 文件内容:', data);
});
console.log('2. 继续执行其他任务');
底层执行流程解析
- JavaScript 层的调用
- 调用
fs.readFile时,Node.js 不会阻塞主线程,而是将文件读取任务交给底层处理。 - 回调函数
(err, data)被暂存,等待文件读取完成后执行。
- 调用
- Libuv 库的任务分发
- Libuv 的核心模块:
- 事件循环(Event Loop):管理任务执行顺序。
- 线程池(Thread Pool):处理 CPU 密集型异步任务(如文件读写、加密计算)。
- 文件读取的底层处理:
- 由于文件读写属于阻塞操作,Libuv 会将任务分配给线程池中的一个工作线程。
- 主线程继续执行后续代码(输出
2. 继续执行其他任务),不被阻塞。
- Libuv 的核心模块:
- 操作系统的异步 I/O 机制
- 工作线程通过系统调用(如 Linux 的
pread)向内核发起文件读取请求。 - 内核处理 I/O 操作时,工作线程不会阻塞,而是进入等待状态,直到内核完成数据读取并通知线程。
- 工作线程通过系统调用(如 Linux 的
- 结果回调的处理
- 当文件数据读取完成后,内核通知 Libuv 的事件循环。
- 事件循环将回调函数放入 微任务队列 或 宏任务队列(取决于任务类型),等待主线程空闲时执行(输出
3. 文件内容:)。
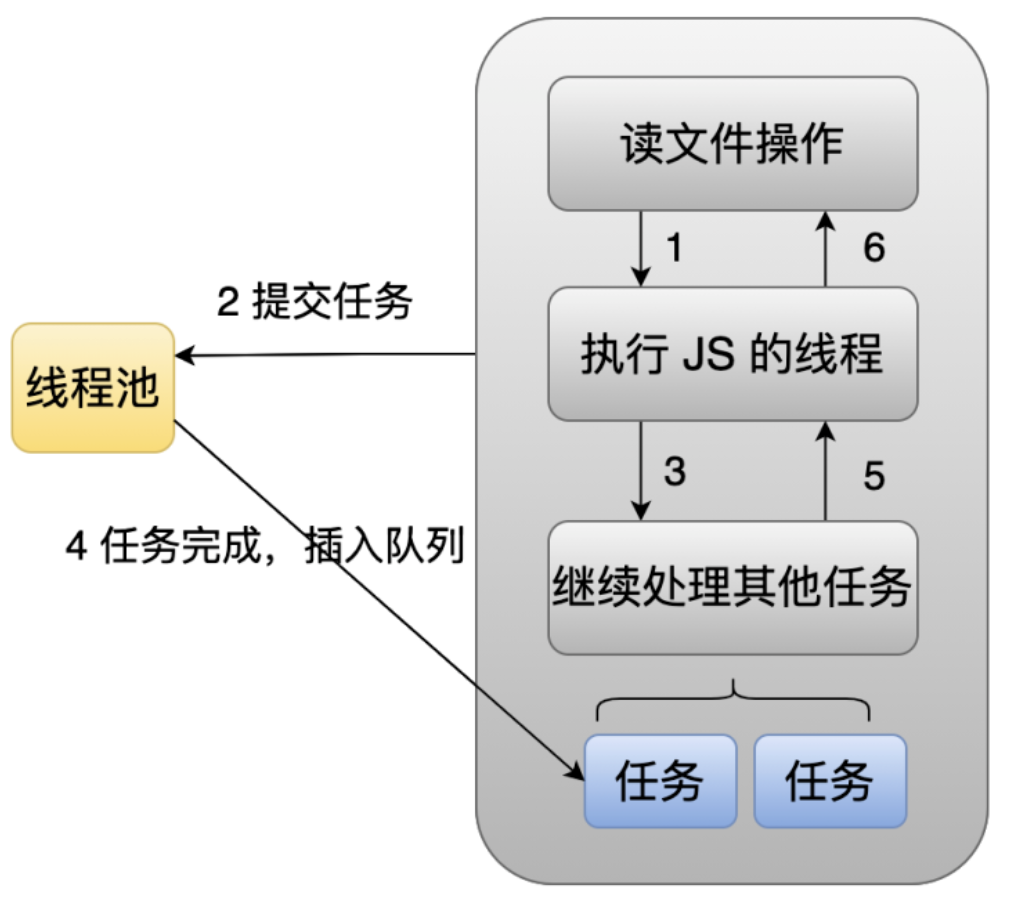
下面的图就是异步任务处理的一个大致过程。
比如我们想读一个文件的时候,这时候主线程会把这个任务直接提交到线程池里面去处理,然后主线程就可以继续去做自己的事情了。当在线程池里面的线程完成这个任务之后,它就会往这个主线程的队列里面插入一个节点,然后主线程在 Poll IO 阶段时,它就会去执行这个节点里面的回调。
三、Node.js 事件循环的底层结构
Node.js 的事件循环在 Libuv 中分为 6 个阶段,每个阶段处理特定类型的任务:
┌───────────────────────────┐ │ timers │ (处理 setTimeout/setInterval 回调) ├───────────────────────────┘ └───────────────────────────┐ │ I/O callbacks │ (处理已完成的 I/O 操作回调) ├───────────────────────────┘ └───────────────────────────┐ │ idle, prepare │ (内部使用) ├───────────────────────────┘ └───────────────────────────┐ │ poll │ (等待新的 I/O 事件) ├───────────────────────────┘ └───────────────────────────┐ │ check │ (处理 setImmediate 回调) ├───────────────────────────┘ └───────────────────────────┐ │ close callbacks │ (处理 close 事件回调)
关键阶段示例:poll 阶段的工作机制
- 当主线程无同步任务时,进入
poll阶段,等待新的 I/O 事件。 - 若有已完成的 I/O 任务(如文件读取结果),事件循环会执行这些任务的回调。
- 若
poll阶段空闲且存在setImmediate任务,则进入check阶段执行该任务。
四、线程池与异步操作类型
Node.js 的线程池(默认大小为 4 个线程)用于处理两类异步任务:
- 必须由线程池处理的任务
- 文件系统操作(如
fs.readFile)、加密计算(crypto模块)、zlib 压缩等。 - 示例场景:当调用
fs.readFile时,Libuv 从线程池取出一个线程,执行文件读取,避免阻塞主线程。
- 文件系统操作(如
- 可由系统直接处理的异步任务
- 网络请求(
net模块)、DNS 查询等,这些操作依赖操作系统的异步 I/O 能力(如 Linux 的epoll、Windows 的IOCP),无需线程池参与。 - 示例场景:
http.get发起网络请求时,Libuv 通过操作系统的异步接口直接监听数据返回,不占用线程池资源。
- 网络请求(
五、异步操作的性能优化示例
当处理大量文件读取时,线程池可能成为瓶颈(默认仅 4 个线程),可通过 worker_threads 模块创建更多工作线程:
const fs = require('fs');
const { Worker } = require('worker_threads');
// 主进程
console.log('主进程开始');
// 创建工作线程处理文件读取
const worker = new Worker('./file-worker.js');
worker.on('message', (data) => {
console.log('文件内容:', data);
});
console.log('主进程继续执行');
// file-worker.js(工作线程代码)
const fs = require('fs');
// 工作线程中执行文件读取,不占用主线程池资源
const data = fs.readFileSync('/path/to/large-file.txt', 'utf8');
process.send(data);
底层优化原理
- 工作线程拥有独立的 V8 实例和线程池,可并行处理多个文件读取任务,避免主线程池过载。
- 主线程与工作线程通过 IPC(进程间通信)机制交换数据,确保主线程不被阻塞。
总结:Node.js 异步的三层实现模型
- 应用层:JavaScript 代码通过回调函数、Promise、Async/Await 处理异步逻辑。
- 引擎层:Libuv 库管理事件循环、线程池,将异步任务分发到系统底层。
- 系统层:操作系统通过异步 I/O 接口(如 epoll、IOCP)处理实际的硬件操作。
Node.js 异步 = 快递站的「前台 + 仓库」模式
假设你去快递站取包裹:
- 主线程:像快递站的前台小姐姐,负责接待顾客、查单号、打包,但不负责去仓库找包裹(否则会被堵在仓库,没法接待其他人)。
- 异步任务:像 “找某一个包裹”,比如你报出单号:“我要取 1024 号包裹!”
- Libuv 仓库工人:像仓库里的分拣员,专门负责找包裹(处理耗时任务)。
- 事件循环:像前台的 “待办小本本”,记录哪些包裹找到了需要通知顾客。
取包裹的全过程:从报单号到拿到包裹
场景:你报出单号,让前台找包裹(对应代码里的文件读取)
- 你对前台说:“我要 1024 号包裹!”
- 前台小姐姐不会自己冲进仓库翻包裹(否则没人接待后面的顾客),而是对仓库工人喊:“帮我找 1024 号!”,然后继续给下一个顾客查单号(主线程继续执行后续代码)。
- 仓库工人找包裹(耗时操作)
- 仓库有多个工人(线程),其中一个工人接到任务后,钻进仓库找包裹。找包裹需要时间(比如在货架间跑来跑去),但工人不能闲着玩手机,必须一直找直到找到(因为找包裹是 “体力活”,需要亲自翻找)。不过这时前台还在外面正常接待,没人被卡住。
- 工人找到包裹,告诉前台
- 找到包裹后,工人喊:“前台!1024 号包裹找到了!”,前台听到后,把这件事记在 “待办小本本” 上:“等有空了把 1024 号给顾客”。
- 前台按小本本顺序叫号(事件循环执行回调)
- 前台小姐姐手里的 “待办小本本” 有顺序:
- 先处理 “马上要超时的快递”(比如
setTimeout像快递滞留 24 小时要提醒); - 再处理 “已经找到的包裹”(比如你的 1024 号);
- 最后看看有没有 “加急件”(比如
setImmediate像生鲜快递要优先送)。
- 先处理 “马上要超时的快递”(比如
- 等前台忙完当前顾客,就会按小本本的顺序喊你:“1024 号顾客,你的包裹好了!”(执行回调函数,把包裹给你)。
- 前台小姐姐手里的 “待办小本本” 有顺序:
如果仓库工人不够用?比如突然来了 100 个取件人
快递站默认只有 4 个仓库工人(Node.js 线程池大小默认 4),如果同时有 100 个人要找包裹,后面的人只能排队等。这时候可以:
- 多开一个仓库(worker_threads):像快递站开分店,每个分店有独立的工人,同时处理不同的取件任务,前台小姐姐不用等某一个仓库忙完。
- 让机器人送包裹(系统异步 I/O):比如寄快递(网络请求)不需要工人找包裹,机器人直接扫码出库,不占用工人的时间,前台更高效。
和浏览器的区别:快递站 vs 小区便利店
- Node.js(快递站):有专业仓库团队(线程池)处理重活(找包裹),前台专注接待(主线程处理业务),适合大量顾客同时来取件(高并发请求)。
- 浏览器(小区便利店):没有仓库团队,老板一个人既要看店又要找货(单线程),除非喊邻居来帮忙(Web Worker),否则来太多顾客就会手忙脚乱(页面卡顿)。
Node.js 异步就像:前台小姐姐不自己找包裹,把麻烦事丢给仓库工人,自己继续接待顾客,等工人找到包裹后,按小本本顺序叫号。这样快递站就能同时服务很多人,不会因为某个人的包裹难找而排队堵车。