背景
作为在数据行业工作多年,使用过MySQL、Hive、Apache Doris 等多种数据库。如何理解SQL的执行顺序,和书写顺序呢?
很多时候 SQL 查询都是以 SELECT 开始的。不过,最近我跟别人解释什么是窗口函数,我在网上搜索”是否可以对窗口函数返回的结果进行过滤“这个问题,得出的结论是”窗口函数必须在 WHERE 和 GROUP BY 之后,所以不能”。于是我又想到了另一个问题:SQL 查询的执行顺序是怎样的?
好像这个问题应该很好回答,毕竟大部分数据开发者已经写了上万个 SQL 查询了,有一些还很复杂。但事实是,大部分人仍然很难确切地说出它的顺序是怎样的。经过研究后发现SQL执行顺序大概是这样的。SELECT 并不是最先执行的,而是在第五个。
下面我们来通过一下三个方面来展开描述:
1.SQL语句的执行顺序
2.SQL语句的书写顺序
3.SQL语句会做哪些优化
SQL语句执行顺序:
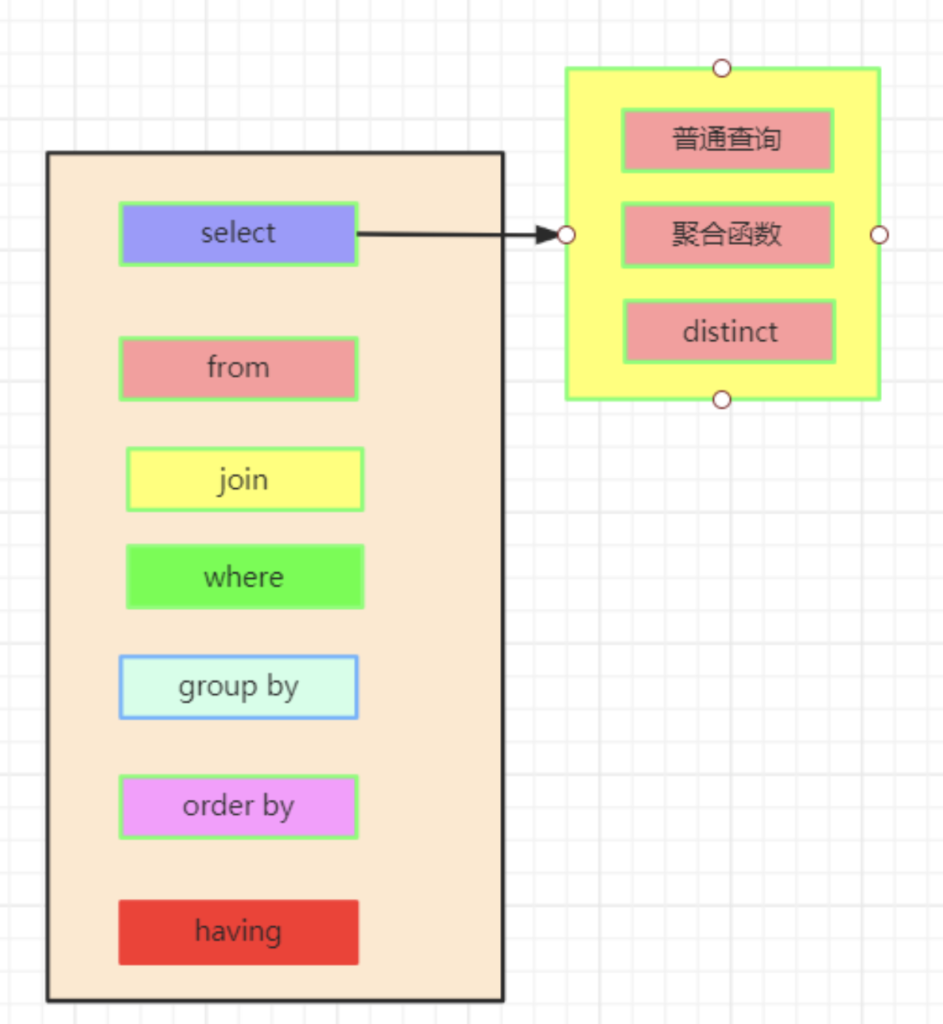
这张图回答了以下这些问题:
这张图与 SQL 查询的语义有关,让你知道一个查询会返回什么,并回答了以下这些问题:
(1)可以在 GRROUP BY 之后使用 WHERE 吗?(不行,WHERE 是在 GROUP BY 之后!) (2)可以对窗口函数返回的结果进行过滤吗?(不行,窗口函数是 SELECT 语句里,而 SELECT 是在 WHERE 和 GROUP BY 之后) (3)可以基于 GROUP BY 里的东西进行 ORDER BY 吗?(可以,ORDER BY 基本上是在最后执行的,所以可以基于任何东西进行 ORDER BY) (4)LIMIT 是在什么时候执行?(在最后!)
在SQL实际执行过程中,每个步骤都会为下一个步骤生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入。
SQL执行顺序
这是一条标准的查询语句:
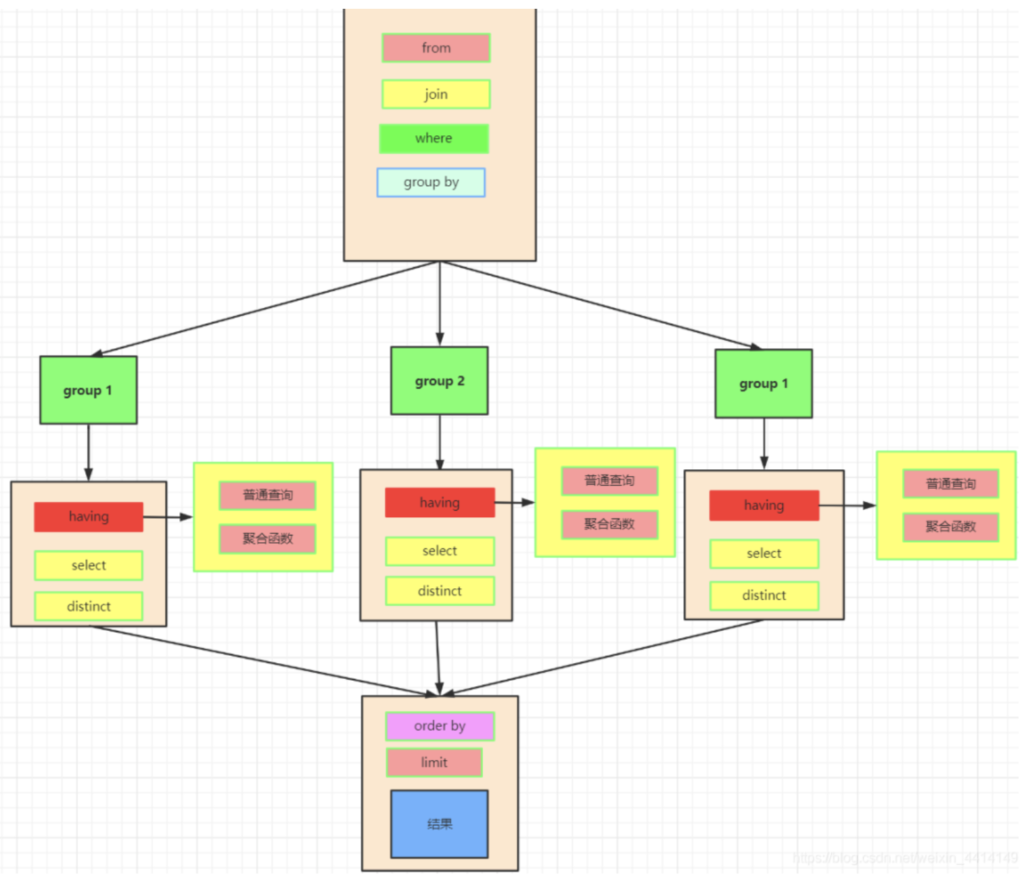
这时我们实际上SQL执行顺序:
- 我们先执行from,join来确定表之间的连接关系,得到初步的数据
- where对数据进行普通的初步的筛选
- group by 分组
- 各组分别执行having中的普通筛选或者聚合函数筛选。
- 然后把再根据我们要的数据进行select,可以是普通字段查询也可以是获取聚合函数的查询结果,如果是集合函数,select的查询结果会新增一条字段
- 将查询结果去重distinct
- 最后合并各组的查询结果,按照order by的条件进行排序
我们在理解SELECT语法的时候,还需要了解SELECT执行时的底层原理。只有这样,才能让我们对SQL有更深刻的认识。
其中你需要记住SELECT查询时的两个顺序:
1.关键字的顺序是不能颠倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...
2.SELECT语句的执行顺序(在MySQL和Oracle中,SELECT执行顺序基本相同):
FROM > WHERE > GROUP BY > HAVING > SELECT的字段 > DISTINCT > ORDER BY > LIMIT
比如你写了一个SQL语句,那么它的关键字顺序和执行顺序是下面这样的:
SELECT DISTINCT player_id, player_name, count(*) as num #顺序5 FROM player JOIN team ON player.team_id = team.team_id #顺序1 WHERE height > 1.80 #顺序2 GROUP BY player.team_id #顺序3 HAVING num > 2 #顺序4 ORDER BY num DESC #顺序6 LIMIT 2 #顺序7
在SELECT语句执行这些步骤的时候,每个步骤都会产生一个虚拟表,然后将这个虚拟表传入下一个步骤中作为输入。需要注意的是,这些步骤隐含在SQL的执行过程中,对于我们来说是不可见的。
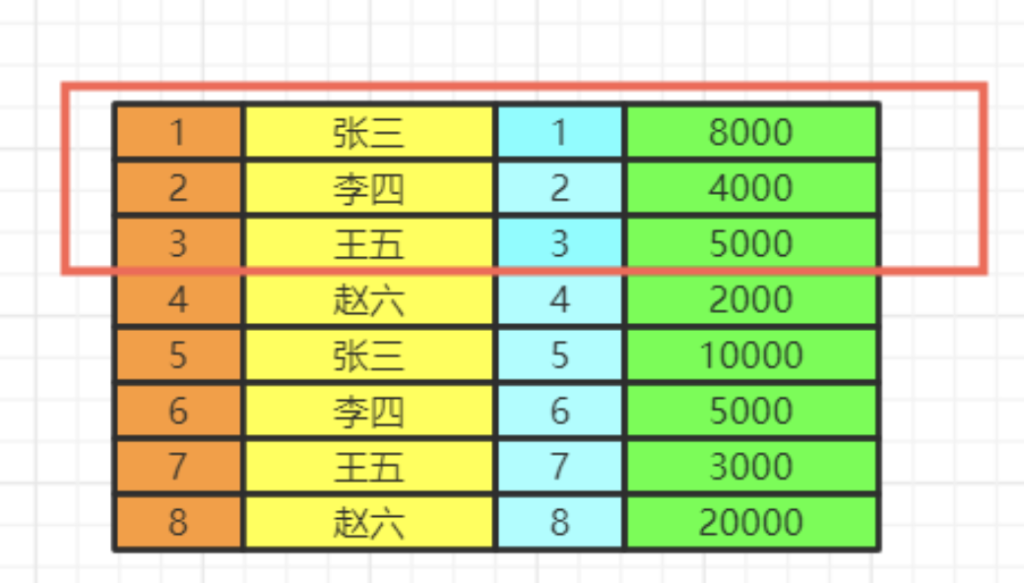
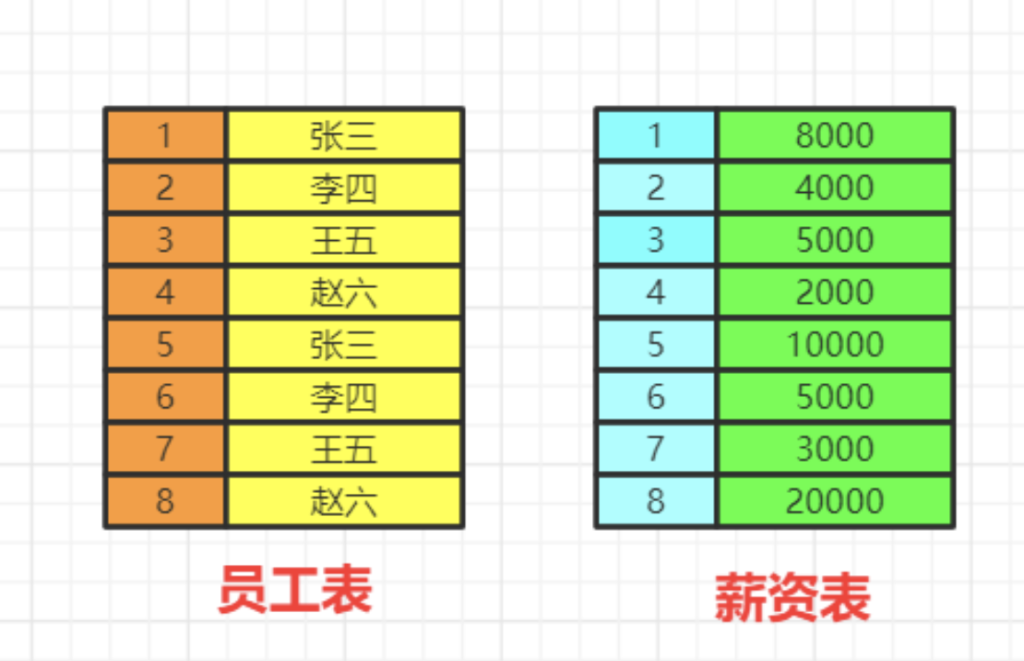
数据的关联过程
数据库中的两张表
- from & join & where
用于确定我们要查询的表的范围,涉及哪些表。
选择一张表,然后用join连接
from table1 join table2 on table1.id=table2.id
选择多张表,用where做关联条件
from table1,table2 where table1.id=table2.id
我们会得到满足关联条件的两张表的数据,不加关联条件会出现笛卡尔积。
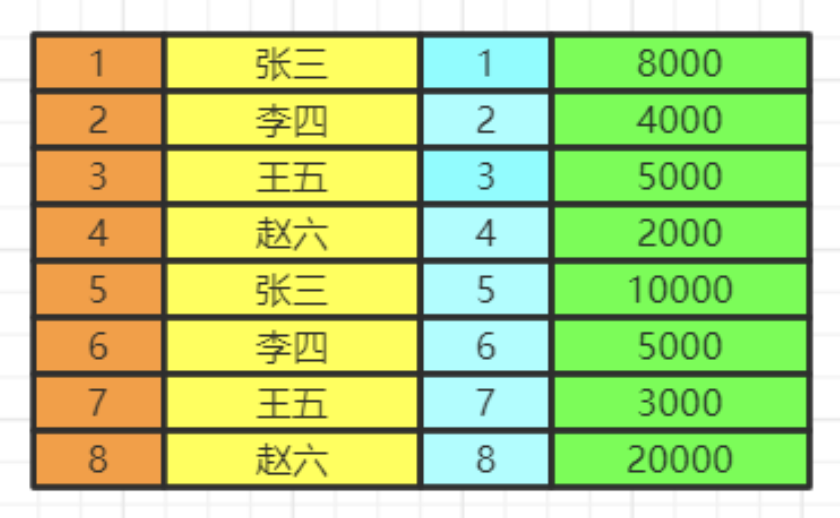
- group by
按照我们的分组条件,将数据进行分组,但是不会筛选数据。
比如我们按照即id的奇偶分组
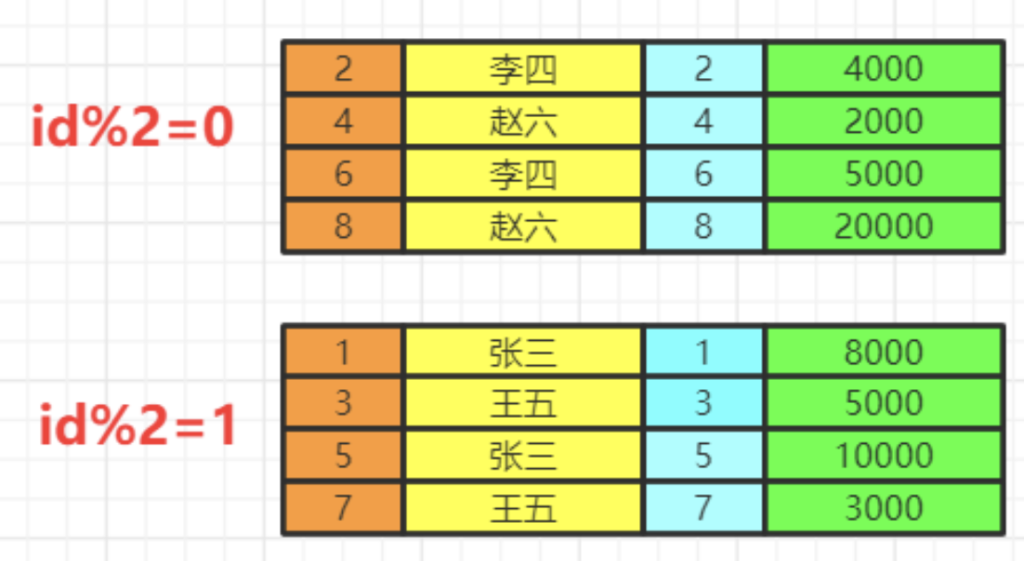
- having & where
having中可以是普通条件的筛选,也能是聚合函数。而where只能是普通函数,一般情况下,有having可以不写where,把where的筛选放在having里,SQL语句看上去更丝滑。
1.使用where再group by
先把不满足where条件的数据删除,再去分组
2.使用group by再having
先分组再删除不满足having条件的数据,这两种方法有区别吗,几乎没有!
举个例子:
100/2=50,此时我们把100拆分(10+10+10+10+10…)/2=5+5+5+…+5=50,只要筛选条件没变,即便是分组了也得满足筛选条件,所以where后group by 和group by再having是不影响结果的!
不同的是,having语法支持聚合函数,其实having的意思就是针对每组的条件进行筛选。我们之前看到了普通的筛选条件是不影响的,但是having还支持聚合函数,这是where无法实现的。
当前数据分组情况
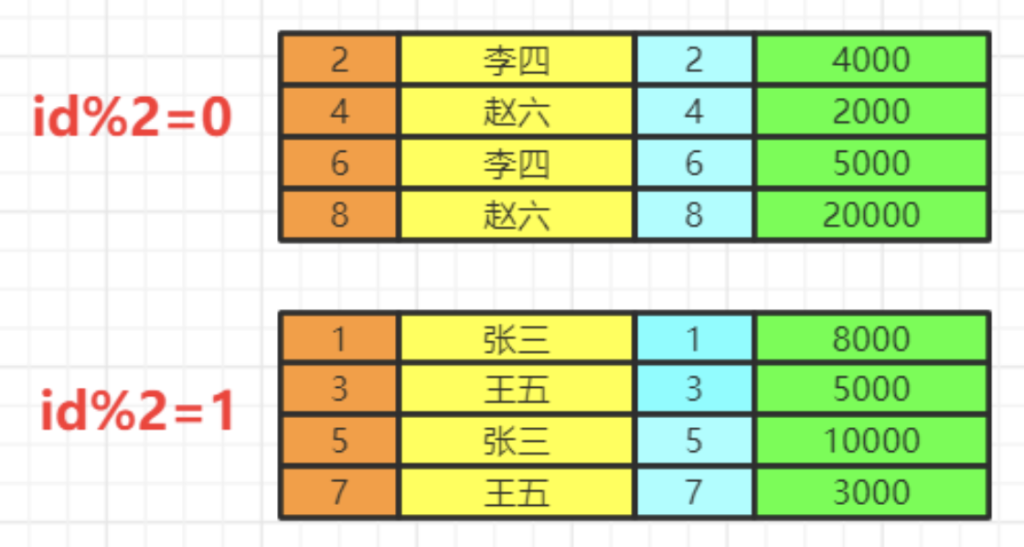
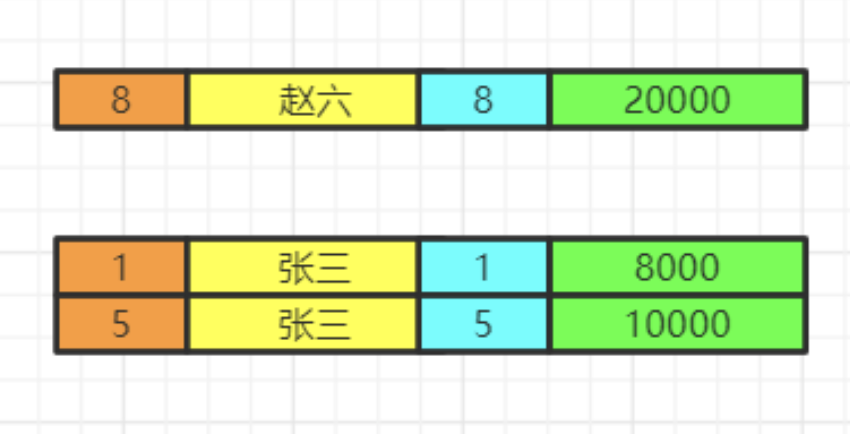
执行having的筛选条件,可以使用聚合函数。筛选掉工资小于各组平均工资的having salary<avg(salary)
- select
分组结束之后,我们再执行select语句,因为聚合函数是依赖于分组的,聚合函数会单独新增一个查询出来的字段,这里用紫色表示,这里我们两个id重复了,我们就保留一个id,重复字段名需要指向来自哪张表,否则会出现唯一性问题。最后按照用户名去重。
select employee.id,distinct name,salary, avg(salary)
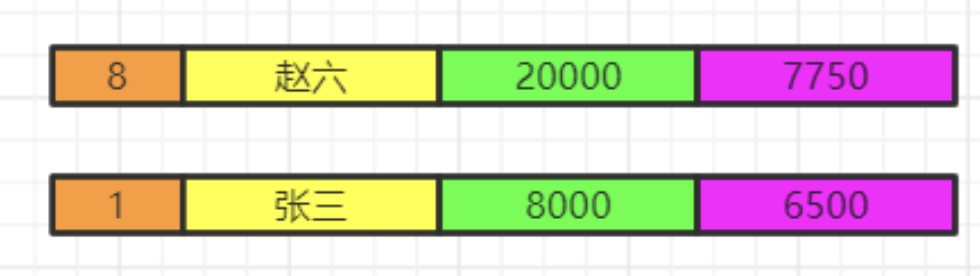
将各组having之后的数据再合并数据。

- order by
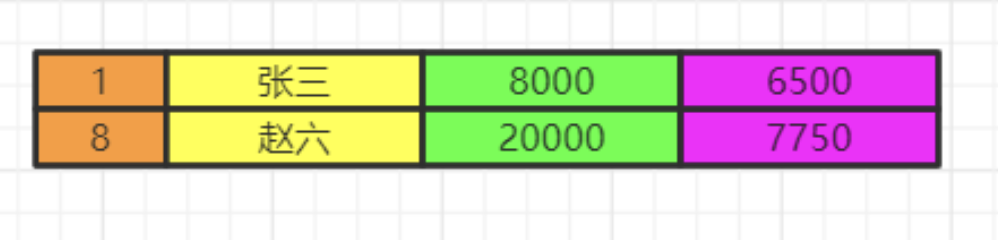
最后我们执行order by 将数据按照一定顺序排序,比如这里按照id排序。如果此时有limit那么查询到相应的我们需要的记录数时,就不继续往下查了。
- limit
记住limit是最后查询的,为什么呢?假如我们要查询年级最小的三个数据,如果在排序之前就截取到3个数据。实际上查询出来的不是最小的三个数据而是前三个数据了,记住这一点。
我们如果limit 0,3窃取前三个数据再排序,实际上最少工资的是2000,3000,4000。你这里只能是4000,5000,8000了。