前言
Ai绘画有一个很现实的问题,要保证每次画出的都是同一个人物的话,很费劲。
Midjourney就不必说了,人物的高度一致性一直得不到很好的解决。而在Stable Diffusion(SD)中,常用办法是通过同一个Seed值(种子值),或者通过训练同一个人物的高质量Lora去控制。
Seed值控制虽然可大体达到目的,但是画出的人物姿态也高度趋同,而且稍微改变描述就会画出另外一个人来,而训练「高质量」模型则更费时费力。
一张稳定的人脸,配合不同的场景和动作,意味着角色人设可以得到继承和发挥。如应用到连贯的绘画场景中,例如漫画、虚拟角色设计等领域,意味着提高产能的可行性。
一、Controlnet(图像精准控制)是什么?
ControlNet 是一个用于控制 AI 图像生成的插件。它使用了一种称为”Conditional Generative Adversarial Networks”(条件生成对抗网络)的技术来生成图像。与传统的生成对抗网络不同,ControlNet 允许用户对生成的图像进行精细的控制。这使得 ControlNet 在许多应用场景中非常有用,例如计算机视觉、艺术设计、虚拟现实等等。总之,ControlNet 可以帮助用户精准控制 AI 图像的生成,以获得更好的视觉效果。
看着有点复杂是不是,没关系,我给你们总结一下:
在 ControlNet 出现之前,我们在生成图片之前,永远的不知道 AI 能给我们生成什么,就像抽卡一样难受。
ControlNet 出现之后,我们就能通过模型精准的控制图像生成,比如:上传线稿让 AI 帮我们填色渲染,控制人物的姿态、图片生成线稿等等。
这下看懂了吗,就很哇塞,大家可能网上看到一些线稿生成的图片,就是用到的这个 ControlNet,Stable Diffusion 必装的插件之一。

二、Controlnet 插件安装
进入 Stable Diffusion 界面,点击扩展标签,选择从 URL 安装,然后输入 ControlNet 网址(https://github.com/Mikubill/sd-webui-controlnet),粘贴到对应的地方,然后点击安装。
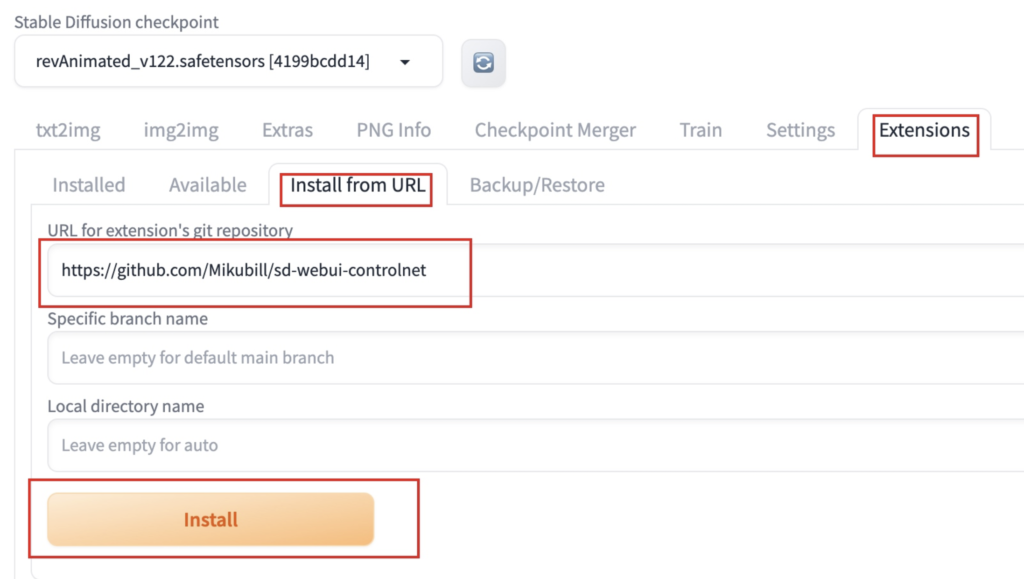
完成之后,点击已安装标签,将刚刚安装的扩展选项打钩,随后点应用并重启UI按钮。
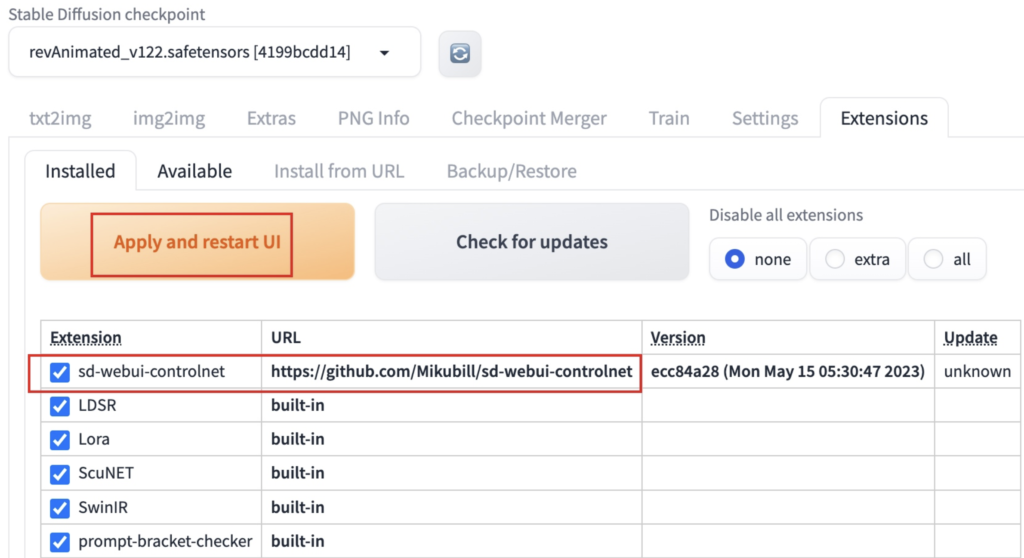
重启UI之后,text2img和img2img标签界面下方就会多出一个ControlNet选项。
如果安装出现下面的错误:AssertionError: extension access disabled because of command line flags,请问怎么解决?
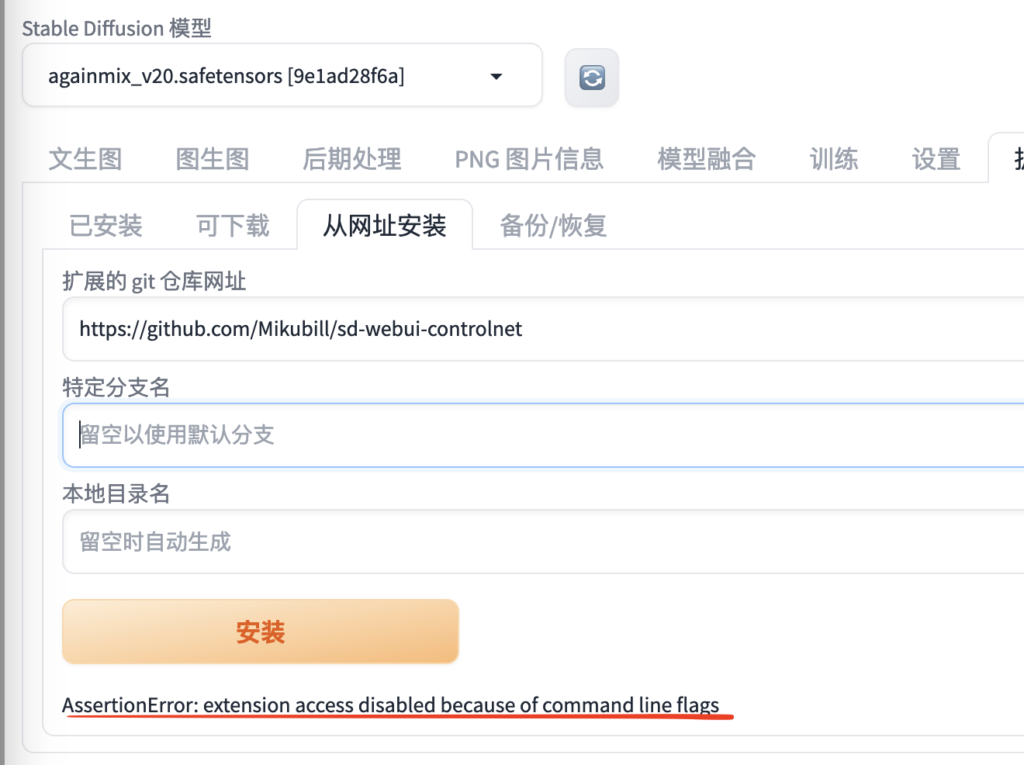
要解决Stable Diffusion从网址安装插件时出现的AssertionError: extension access disabled because of command line flags错误,您可以通过修改启动脚本中的命令行参数来允许不安全的扩展访问。具体操作步骤如下:
1.编辑启动脚本:找到并编辑webui-user.sh(Linux环境下)或webui-user.bat(Windows环境下)文件。
2.添加命令行参数:在export COMMANDLINE_ARGS参数中增加--enable-insecure-extension-access参数。
3.保存并重启:保存更改后的脚本文件,然后重新启动Stable Diffusion WebUI。
此外,如果您是在云主机上部署的Stable Diffusion,并且需要远程访问,可以添加--listen和--gradio-auth参数,后面跟上用户名和密码,以提高安全性。
总的来说,在进行上述操作时,请确保您了解这些参数可能带来的安全风险,尤其是在使用--enable-insecure-extension-access参数时,因为这可能会降低系统的安全性。如果您对操作不太熟悉,建议在进行更改前备份相关文件,以便出现问题时能够恢复到原始状态。
二、ControlNet 模型下载安装
已经安装了 sd-webui-controlnet 扩展后,您可以从 ControlNet 的 HuggingFace 页面上下载所需的文件(https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main)。
Right now all the 14 models of ControlNet 1.1 are in the beta test. Download the models from ControlNet 1.1: https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main You need to download model files ending with ".pth" . Put models in your "stable-diffusion-webui\extensions\sd-webui-controlnet\models". You only need to download "pth" files. Do not right-click the filenames in HuggingFace website to download. Some users right-clicked those HuggingFace HTML websites and saved those HTML pages as PTH/YAML files. They are not downloading correct files. Instead, please click the small download arrow “↓” icon in HuggingFace to download.
三、模型说明及案例演示
介绍几个常用的 controlnet 模型教程,注意看哦。跟着我一步步的操作就没什么问题的,加油!
3.1 骨骼姿势识别
姿势识别,用于人物动作,提取人体姿势的骨架特征(posture skeleton)。
姿势提取的效果图很像小时候 flash 上的小游戏“火柴人打斗”,有了这个就不用去网上寻找各种英语姿势tag,而是可以直接输入一张姿势图。下面是相关步骤:
- 随便网上找一张相对少见点的姿势,然后稍微裁剪一下,让人物更大一点。
- 把图片放进 ControlNet,Enable 打开,预处理器选择 openpose。
- 然后点击 Preview annotator result 按钮(星星按钮),生成预处理预览图。
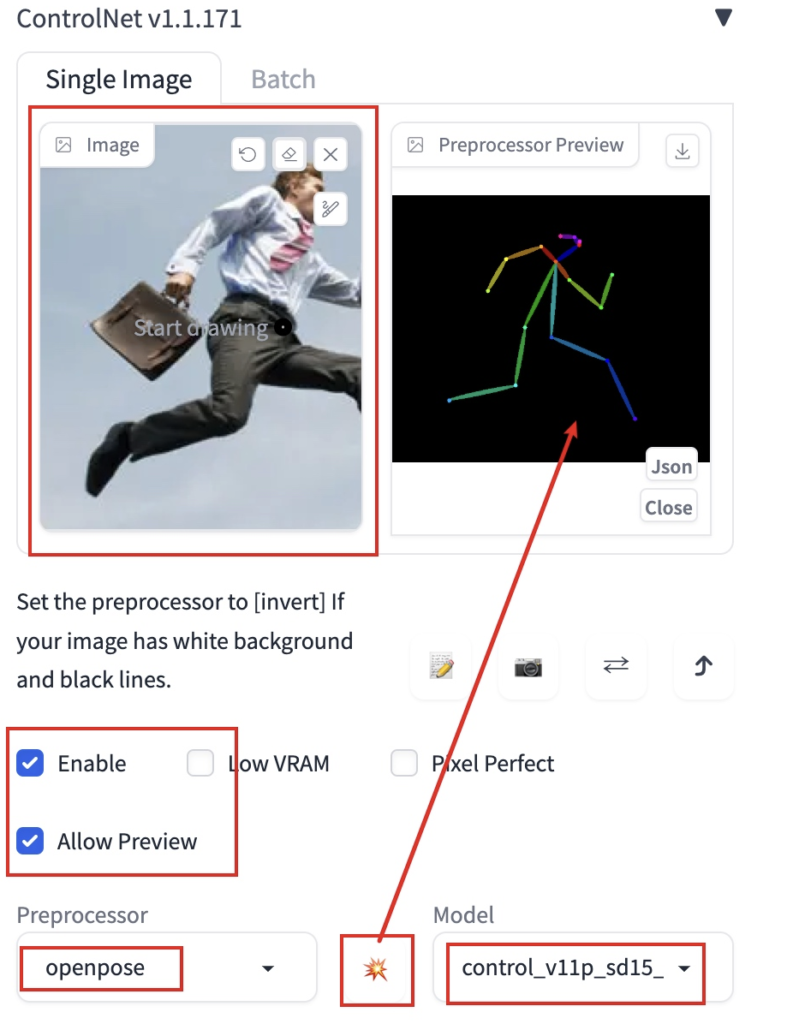
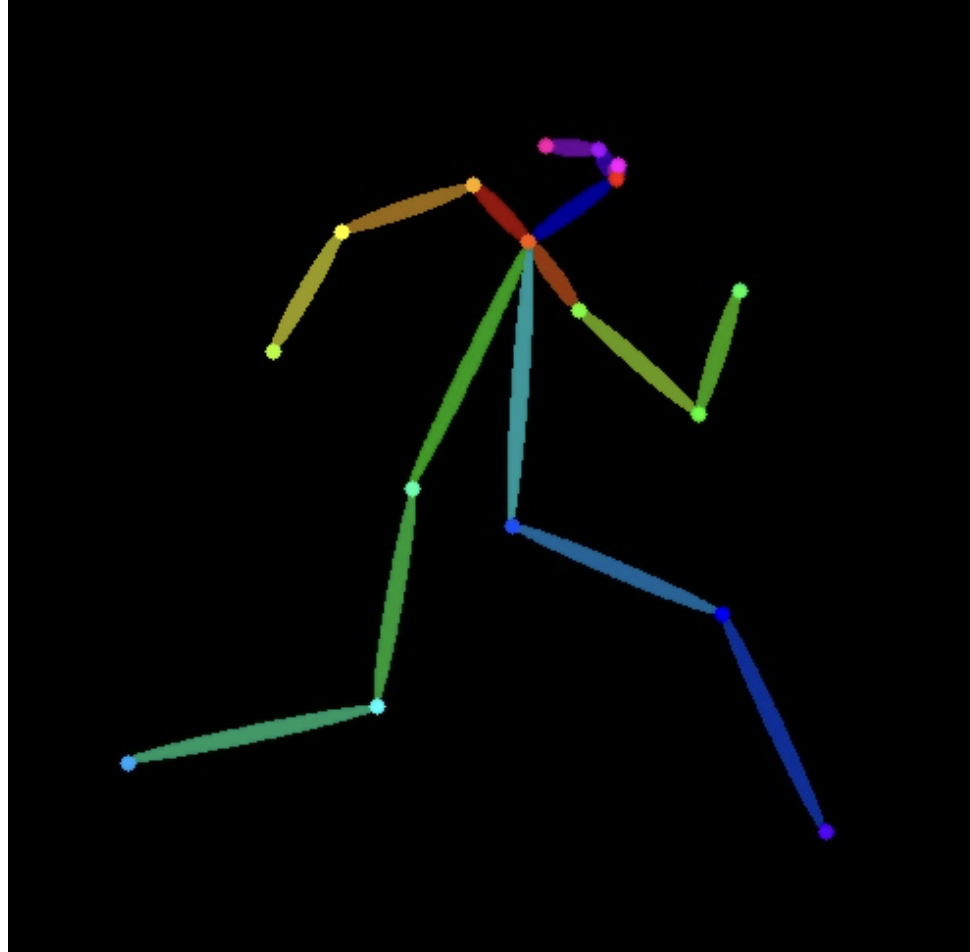
- 看预览的骨架图,识别还算精确。(找的图最好是真人,识别会准一点)。
- Prompt提示词就写“girl”(女孩),然后点击generate生成按钮。

girl Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 1529353483, Size: 512x512, Model hash: 4199bcdd14, Model: revAnimated_v122, Version: v1.2.1, ControlNet: "preprocessor: openpose, model: control_v11p_sd15_openpose [cab727d4], weight: 1, starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (512, 64, 64)"
其中使用的骨骼姿势:
3.2 Canny 边缘检测 (Canny edge detection)
Canny 用于识别输入图像的边缘信息。从上传的图片中生成线稿,然后根据关键词来生成与上传图片同样构图的画面。
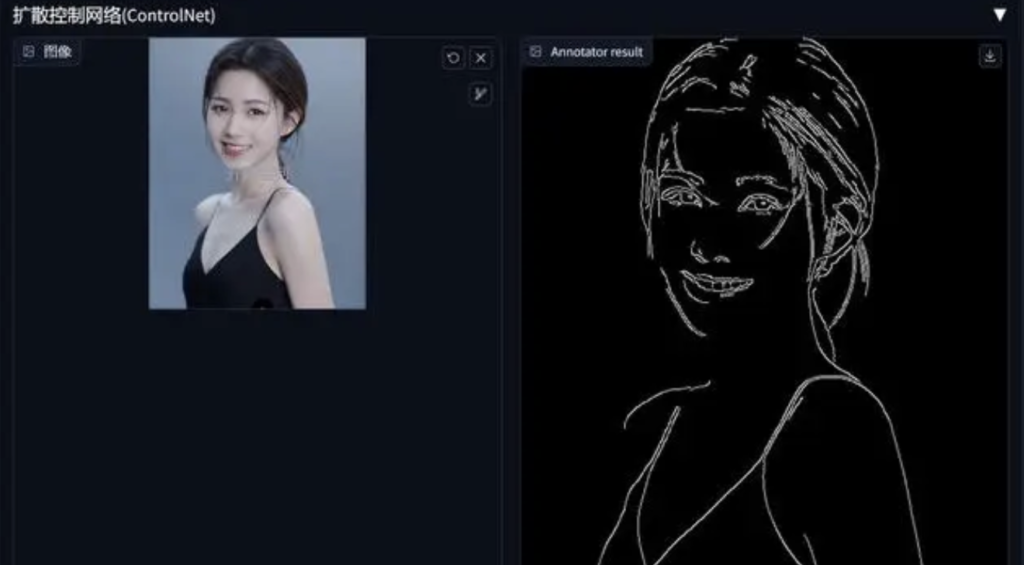
来跟着我的操作来一遍。
首先我们把模型和 lora 选择好,因为我这里上传的是一个真实的模特,所以像最大程度的还原,模型一定要对。这里我用到的是这两个模型。

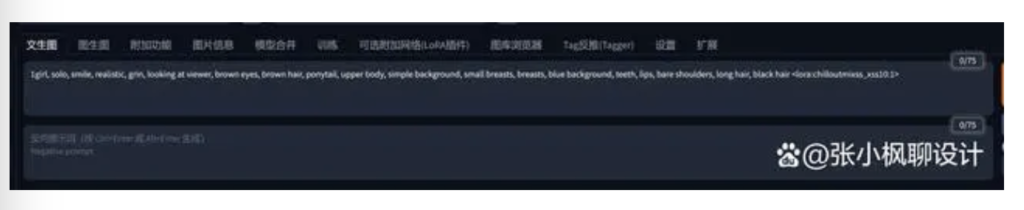
然后输入关键词:
1girl, solo, smile, realistic, grin, looking at viewer, brown eyes, brown hair, ponytail, upper body, simple background, small breasts, breasts, blue background, teeth, lips, bare shoulders, long hair, black hair 女孩,独奏,微笑,现实,咧嘴笑,看着观众,棕色的眼睛,棕色的头发,马尾辫,上身,简单的背景,xxx,xx,蓝色的背景,牙齿,嘴唇,裸露的肩膀,长发,黑发
打开 Controlnet,选择 Canny 边缘检测,模型选择对应的 canny 模型。
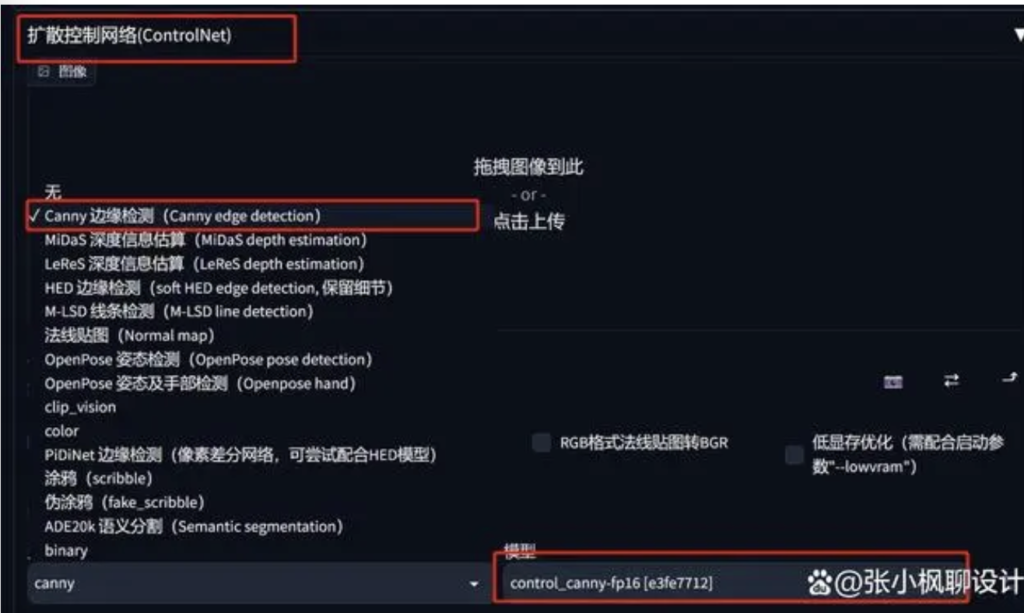
上传图片,并勾选启用。

点击下方的“预览预处理结果”这一步是生成线稿。然后就会出现上面那张线稿图。

最后我们勾选下“DPM++SDE Karras”,开始生图

来看下原图和生成图片的对比,姿态构图基本一致。如果你想换头发颜色、面部细节、服装等等,就可以通过关键词来控制。这个功能学会了吧,那咱们讲下一个。

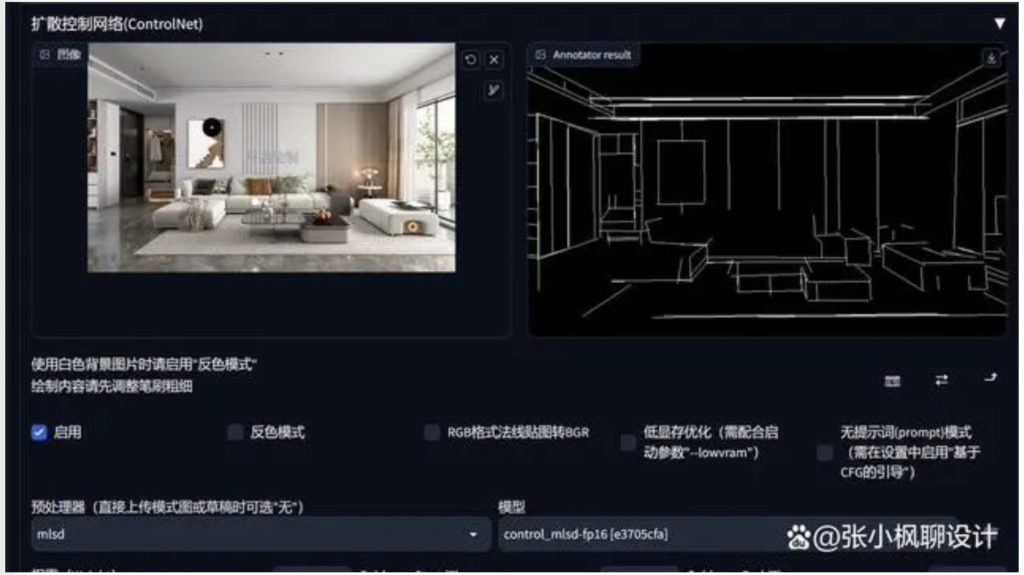
3.3 M-LSD (建筑物绘制)
通过分析图片中的线条结构和几何形状,可以构建建筑物的外框,适合建筑、室内设计的朋友使用。
切换预处理器和相应模型。

上传一张室内设计的图片,然后点击“预处理结果”,(第一次用这个,控制台会更新一段时间)。
输入关键词
pearl white walls, windsor gray floors, bedroom, Natural lighting, earthly tones, simple and clean, trending on interior design, digital artwork by Audrey kawasaki, Smooth, Detailed, Artstation, Neutral colors, elegant 珍珠白的墙壁,温莎灰色的地板,卧室,自然光,朴实的色调,简单干净,室内设计的趋势,由 Audrey kawasaki 设计的数字艺术品,光滑,细节,艺术站,中性色,优雅

可以看到,图片生成的效果还是不错的,跟原图的构图基本一致,当然还有更多的细节需要调整,大家可以调整这块的参数即可。
3.4 Reference only
SD的Controlnet插件推出了Reference only功能,这个问题才得到较好的改善。
一张稳定的人脸,配合不同的场景和动作,意味着角色人设可以得到继承和发挥。如应用到连贯的绘画场景中,例如漫画、虚拟角色设计等领域,意味着提高产能的可行性。
下图是SD画的参考图:

修改描述词后,通过Reference Only生成新的图片例:

我们通过Reference Only功能,基于参考图去生成新的图片,大致效果如下(点击可看大图):
可以看到,在改变了姿势、场景、构图之后,人物的脸部特征,包括发型,仍然得到很好的保留,维持了高度统一的形象。
同时也留意到,人物服装只是部分相同。这个时候,如果要保持一致性,应该通过更详细的Tag描述去控制,具体指定服装的颜色、样式和风格等。
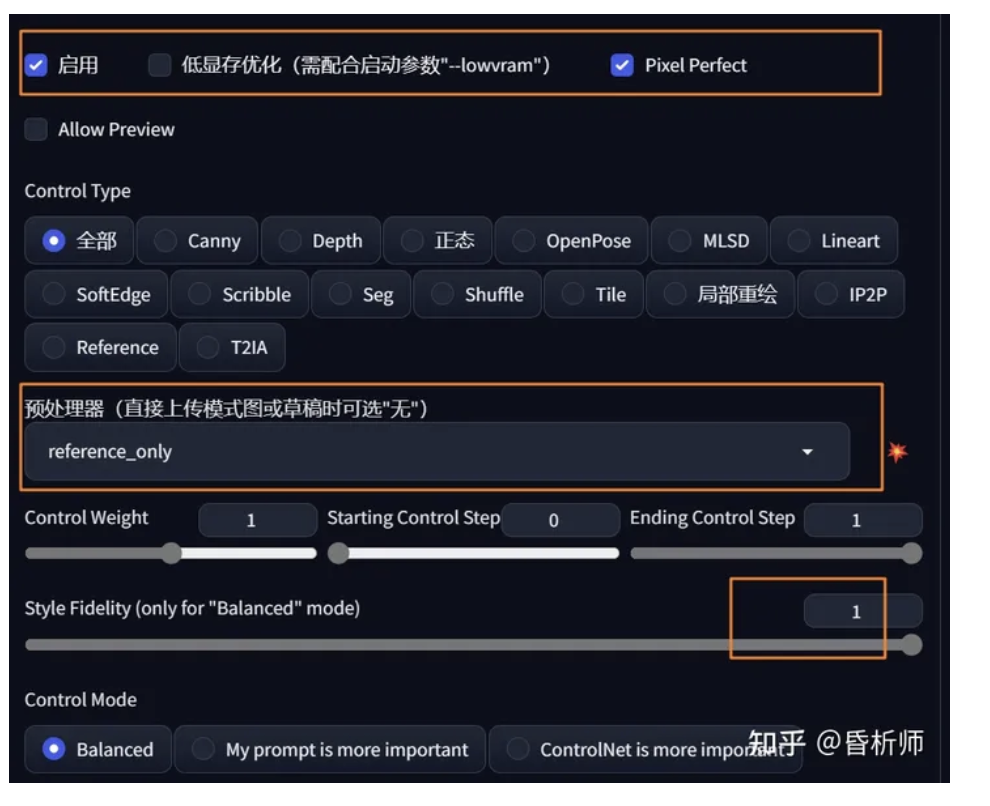
建议在SD中生成参考图,并将参考图上传到Controlnet的图片作业区域,如下图界面:

勾选启用Controlnet,选择Reference only三个预处理器中的一个,并将Style Fidelity值设置为1,如下:
基于参考图的描述词生成图片即可,如需变换场景或细节例如发型等,可在正面提示词中调整,不会影响人脸继承。
- 1.并不是所有底模,都可以跟Reference only契合得很好,个别模型在成像过程中,有时候会出现色彩走样。
- 2.一些底模结合Reference only绘图时,并不总是支持多动作、多场景、多视角变换,个别场景很难被画出,例如,要把背景换成“大海”,即使“大海”的权重再高,也是无法实现,不知是何原因。
无论如何,Reference only可免去训练高质量模型即可保持人物一致,算是一个较大进步,如果下个版本可以解决上述2个问题,相信可以更好地赋能内容生产领域。
Reference only目前一共有3个预处理器可用,分别为:
- Reference only:绘制与参考图类似的风格和脸部;
- Reference adain:自适应规范,会更偏向于使用的模型,结果可能偏离参考图;
- Reference adain+attn:结合了上述两种。
3.5 Semantic Segmentation(语义分割绘制)
Semantic Segmentation 语义分割是一种深度学习算法,重点关注 语义 一词,这种算法将一个标签或类别与图像联系起来,被用来识别形成不同类别的像素集合。具体还是看我的操作:
切换预处理器和模型
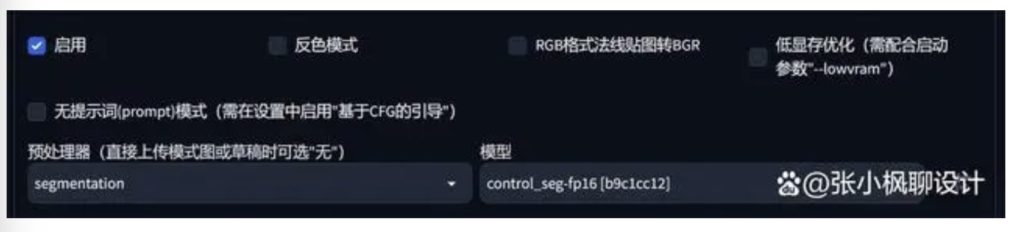
上传图片,然后点击“预览预处理器结果”。
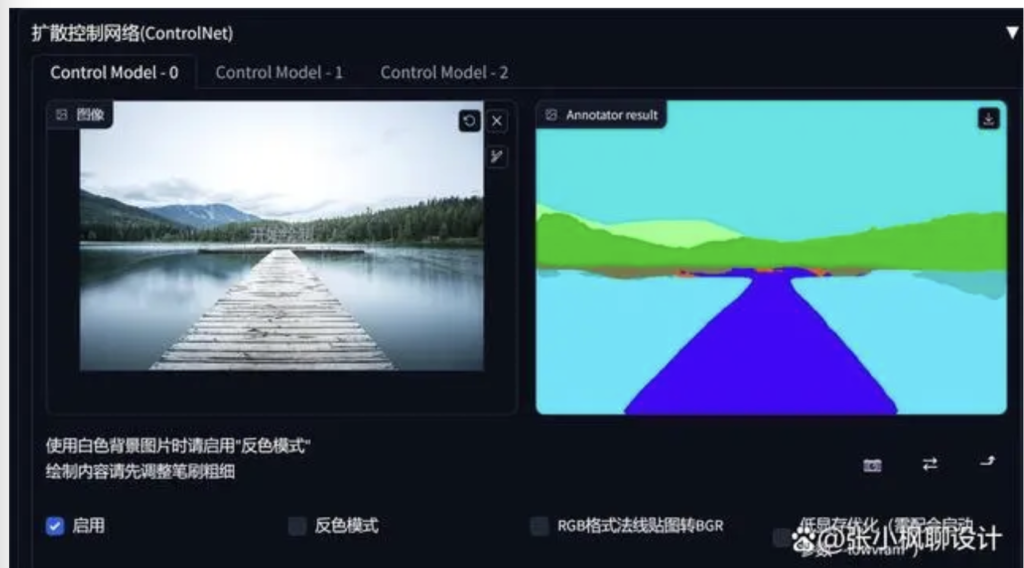
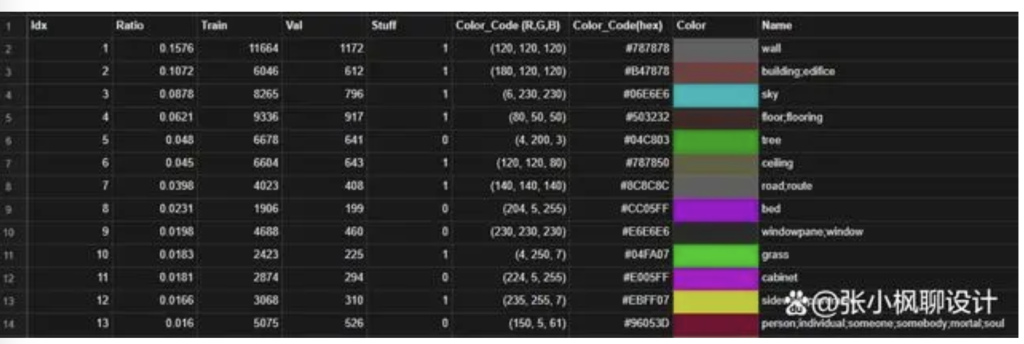
可以看到,预处理阶段生成了一张五颜六色的图片,这就是语义分割图,这图中的每一种颜色都代表了一类物品,比如紫色(#cc05ff)代表床(bed),橙黄色(#ffc207)代表垫子(cushion),金黄色(#e0ff08)代表台灯(lamp)。
这是一份色值表格,大家自取!
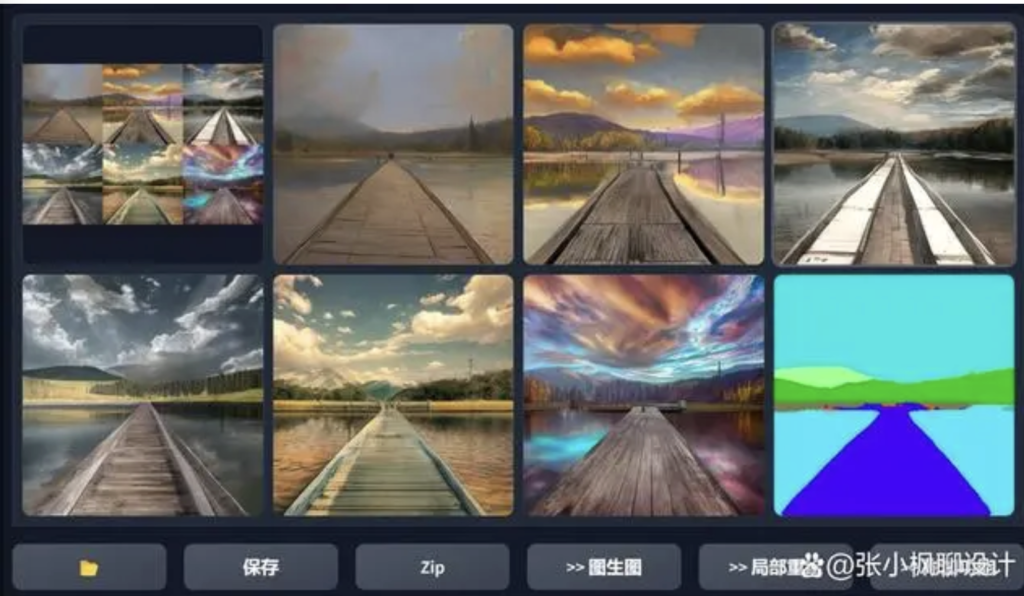
里我就不输入关键词了,让 sd 自由发挥
3.6 Scribble (涂鸦)
使用 Scribbles 模型,可以根据草图(涂鸦)绘制出精美的图片,对于那些没有接受过美术训练或缺乏绘画天赋的人来说,这是非常棒的。
切换预处理器和模型。(第一次用这个,控制台会更新一段时间)

点击“创建空白画布”。
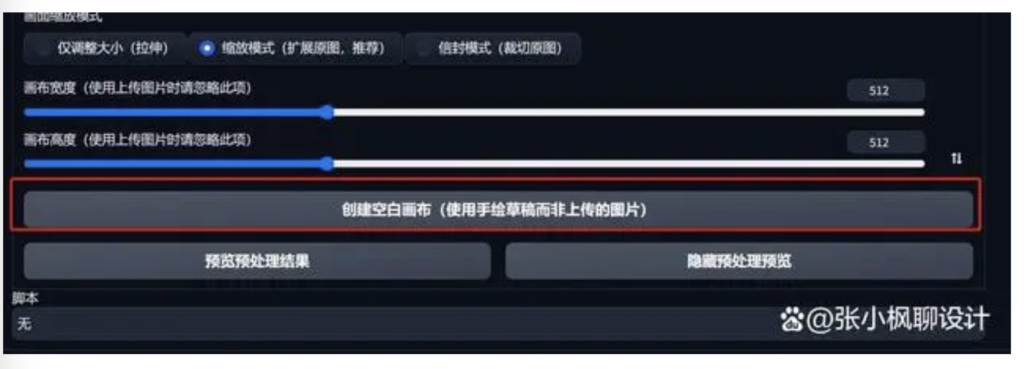
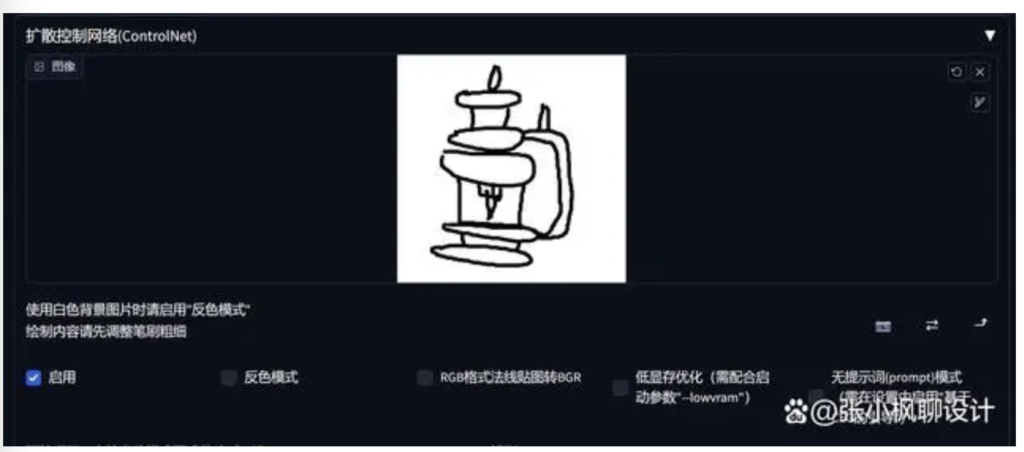
然后在这里画线稿,这里我画一盏煤油灯,我是用的鼠标绘制的,画的不好,做个演示。有手绘板的同学可以用手绘板绘制一下。
输入关键词:
old electronic kerosene lamp in anthracite blue metal, warm orange metal reflections, Intricate, Highly detailed, Warm lighting, Sharp focus, Digital painting, Artstation, Concept art, trending, inspired by art by Zdenek Burian and frederick catherwood 旧电子煤油灯在无烟煤蓝色金属,温暖的橙色金属反射,错综复杂,高度详细,温暖的照明,锐利的焦点,数字绘画,艺术站,概念艺术,趋势,灵感来自艺术 zdenek burian 和 frederick catherwood

我画的不标准哈,做个演示,这个模型是根据你绘画的线稿精准控制物体的构图、构造。细节根据关键词来控制。
3.7 法线贴图 (Normal map)
从原图中提取 3D 物体的法线向量,绘制的新图与原图的光影效果完全相同。
切换预处理器和模型
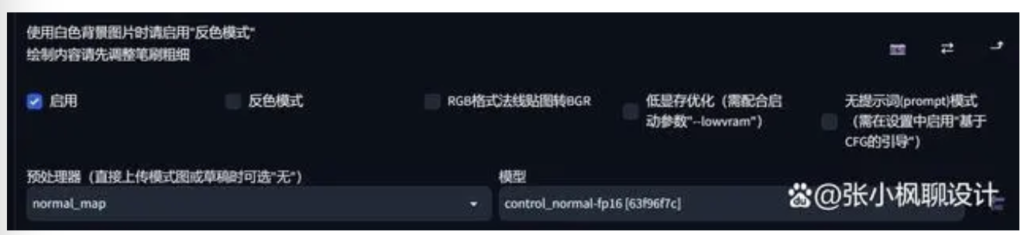
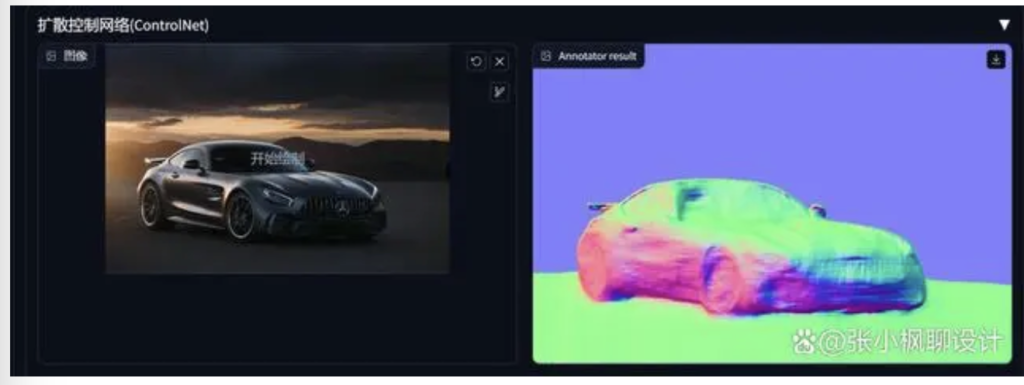
上传一张图片,然后点击“预览预处理结果”,然后就会给你生成一张法线图(懂 3 维的小伙伴应该都知道这个)
继续输入关键词,等待生图….
Mercedes-Benz AMG GT, staring out of the window with regal air, Moody lighting, High detail, realistic fur texture, Digital painting, trending on artstation 梅赛德斯-奔驰 AMG GT,凝视窗外的皇家空气,穆迪照明,高细节,逼真的皮毛纹理,数字绘画,艺术站的趋势

怎么说呢,就是牛!!!背景细节等都可以通过关键词来控制,其他调整参数与上面一样。
言川小知识:这个模型主要是通过 RGB 颜色通道来标记表示凹凸,生成的图片立体感很强。
可以看到,图片生成的效果还是不错的,跟原图的构图基本一致,当然还有更多的细节需要调整,大家可以调整这块的参数即可。
3.8 OpenPose 姿态检测
通过姿势识别实现对人体动作的精准控制,不仅可以生成单人的姿势,还可以生成多人的姿势。
此外,由于 AI 生成的手部有问题,OpenPose 还有一个手部检测模型,大大改善了奇奇怪怪的手。
切换预处理器和模型。
上传一张图片,然后点击“预览预处理结果”,注意,第一次选中这个模型开始预处理的时候,会更新一段时间,可以在“控制台”查看更新进度,更新完成之后再次点击“预处理”就可以看到 AI 识别的图了。
看看预处理结果:

输入关键词,等待生图….
1girl, solo, dress, braid, hairband, earrings, smile, brown eyes, white dress, realistic, jewelry, long hair, black hair, looking at viewer, bare shoulders, lips, blue hairband, single braid, brown hair, simple background 女孩,独奏,连衣裙,辫子,发带,耳环,微笑,棕色眼睛,白色连衣裙,现实主义,珠宝,长发,黑发,看着观众,裸露的肩膀,嘴唇,蓝色发带,单发带,棕色头发,简单的背景
