前言
说起AI换脸,你可能会想到roop, 然而这个在github上一度大火的项目,已经有一段时间没有更新了。就在一周前,项目有了更新,结果却是停止维护的声明。仔细一看,里面还有瓜:作者大佬说有一个共同开发者利用这个项目制作并发布了一个有问题的视频,大佬实在不能忍受自己的心血被用在这种龌龊的事情上,于是怒而停之。
与此同时,如果你在github搜索face swap,会发现又有一个新项目冒了出来,就是这个FaceFusion,短短几天斩获5千个星的同时,这个项目的介绍也非常的霸气:下一代的换脸和脸部增强工具!好奇之下,我点开了这个项目,发现项目作者怎么这么眼熟,没错,其实就是之前roop的作者大佬。原来,不是项目大佬不干了,而是想把换脸技术带向更加健康的发展方向,要在项目中加入对于制作内容的控制。是另起炉灶继续革命。
所以本期内容我们就一起来看看下一代换脸技术:Facefusion。
Facefusion
需要说明的是,好的模型自然需要好一些的显卡才跑得动,Facefusion这个项目,正常运行大概需要5GB的显存,所以我建议你至少具备一台有6GB以上显存N卡的电脑,再做后续的尝试。首先,Facefusion的安装不算复杂,你只需要进入项目页面复制路径,再在你的电脑上找一个路径克隆项目,之后,创建一个用于本项目的虚拟环境,在这里我用的是anaconda. 注意,这个项目要求Python版本是3.10,不要安装成其他版本了。激活虚拟环境后,就可以安装项目的依赖requirement了,这个过程有点久,并且最好是在魔法环境进行。
如果你在安装过程中碰到其他问题,也可以深入到项目的文档中寻找解决方法,文档中不仅针对不同系统环境给出了能够加速推理的操作步骤,还把常见使用问题列了出来。
在安装完成后,就可以使用python run.py命令启动项目了。首次启动的时候,会需要下载模型文件,需要耐心等待一会,同样,最好是在魔法环境进行。
FaceFusion项目提供了类似于stable diffusion的UI, 你只需要复制链接并在你的浏览器中打开就可以了。
页面启动后,可以看到两个给你的输入区域,source代表换脸的脸要来自哪个照片,target标识要把前面的这张脸换到哪个照片或者视频中。和其他换脸项目一样,Facefusion也提供了图片换脸和视频换脸两种模式,也就是在target这里,你可以上传图片,也可以上传视频。
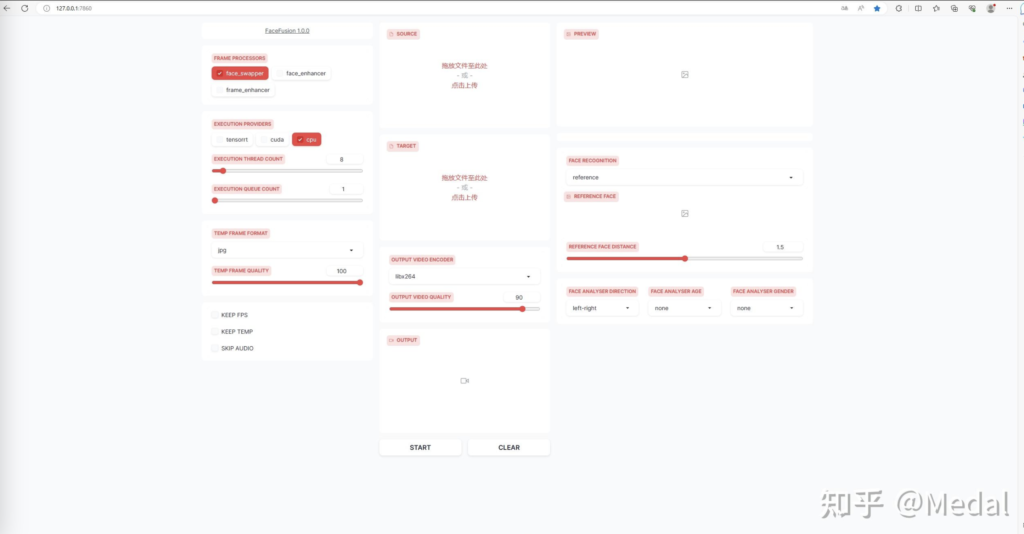
其实只要你上传了source和target,不需要操作任何地方,稍微等待一会,换脸结果就会在右侧显示出来了.如果你想对换脸效果进行精准控制,就需要了解一下页面中其他的这些选项了。
我们先来看左半边的这些参数,首先,我们仅上传一张target照片,并且这张照片是比较糊的,processor里面的frame enhance和face enhance就是对质量较差的照片做增强处理的。比如我们先点击face enhancer,会发现人物的脸部细节变的清楚了,取消face enhancer的勾选,再选择frame enhancer,会发现整个图片的细节变得多了一些,但是脸部没有刚才清楚。而当我们把两个都勾选上时,会发现从脸部到其他地方,都会变得清楚了起来。这里的功能如果是首次使用,也需要下载对应的模型,等待时间会长一些,但是这种增强模型都不是很大,一般就是几十兆。
这时,让我们把source图片也上传上来,并将这三个选项都勾选上,就会发现不仅实现了图片换脸,并且图片的细节也相对比较清楚。
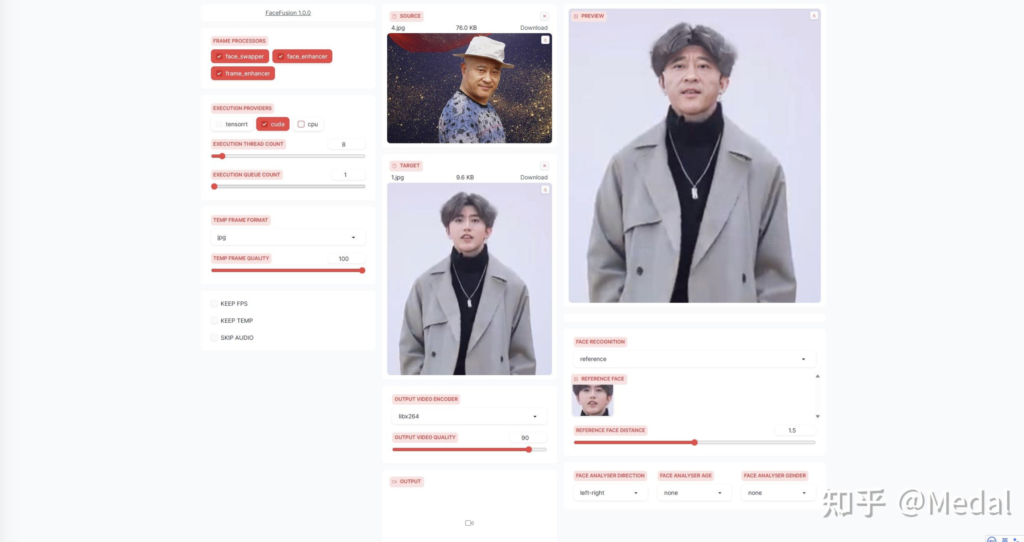
下面的三个选项控制将模型运行在什么设备上,CUDA代表运行在英伟达显卡上,如果你的电脑有N卡,当然选择这个,相比于运行在CPU上,会大大提高模型计算的速度。这里的TensorRT是英伟达推出的在自家显卡上进一步加速模型推理速度的一个工具,简单来说就是在N卡GPU上计算时,通过模型剪枝、模型量化等方式,进一步提高一些模型推理速度,这个可以选择,也可以不选,只选择CUDA影响效果同样可以达到很快。
再下面的两个选项是控制线程使用个数,以及最大查询数量的,也是越大处理越快,如果你的电脑性能好的话,也都可以适当调高一些。下面的临时帧格式,代表帧图片在存储时用到的编码方式,一般选择JPG格式就可以了,相比于PNG格式,会节省一些存储空间,并且计算精度不会受到太大影响,而这个视频帧质量,我们可以选择拉满,这会影响最终换脸的效果。
最左下角的三个选择框,都是和视频换脸相关的参数,第一个代表是否保持原始视频的视频帧率参数,比如你输入的原始视频是60FPS,勾选这个会使得最终的换脸视频保持同样的帧率,视频帧率越大,看起来就会越流畅。第二个参数代表视频换脸是否保存一些中间结果,如果勾选上,会占用更多的存储空间,好处是当你需要对同一个视频的换脸效果进行微调时,可以加快一些计算速度。第三个参数代表是否跳过视频中的声音,如果勾选上,换脸后的视频会不带声音,好处同样是会提高换脸计算的速度,减少等待时间。
现在让我们上传一段韩国小姐姐跳舞的视频,再上传一张泰勒斯威夫特的照片作为source,我们希望把泰勒的脸换到跳舞的韩国小姐姐身上.
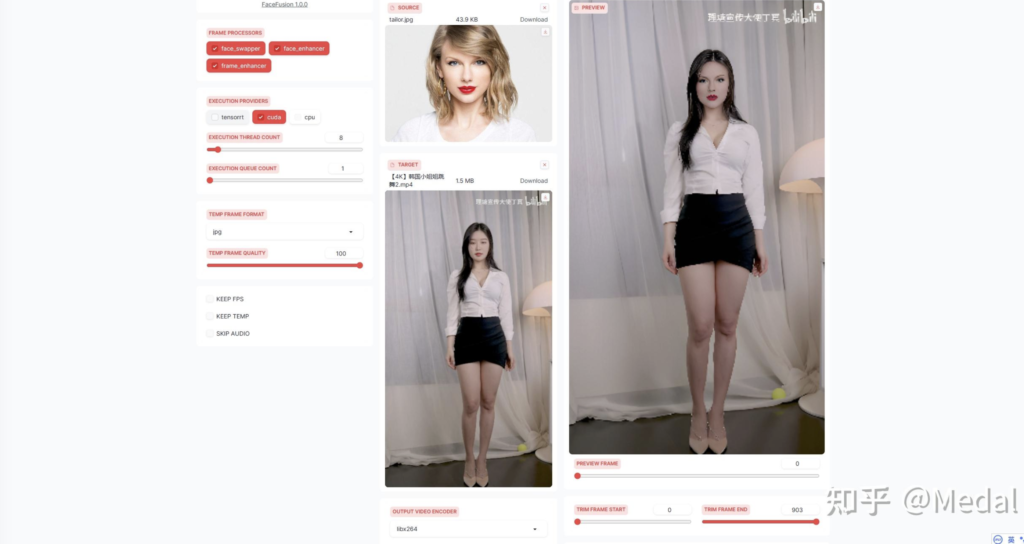
在左边的参数中,我们把CUDA和加速计算都选上,进一步,我们希望保持视频的帧率,并保存一些中间处理结果,便于我们做微调,由于我们希望换脸后的视频仍然有声音,所以略过声音这个选项我们就不选了。输出视频编码器这个参数,如果你没有特殊需求,就选择默认的就好,输出视频质量这里,我们也拉满。再来看下右边的参数,最上面这里是视频帧预览,也就是你可以选择任意帧来提前查看换脸效果,下面的两个参数代表换脸的起始帧和结束帧,默认情况下,会对整个视频进行换脸,也就是起始帧为0,结束帧为视频的最大帧,如果你想看下从视频中间进行换脸的效果,就调整一下换脸起始帧。我们选择对完整视频换脸,所以还是把起始帧拉回到零。再下面的这些参数,我们随后再讲。
好了,一切设置好后,让我们点击这里的开始,模型就开始运算了,这里需要经过漫长的等待,等待的时间和你视频的长短有关系。视频生成好了!让我们来看一下效果(可以看文章最上面的视频查看效果)。
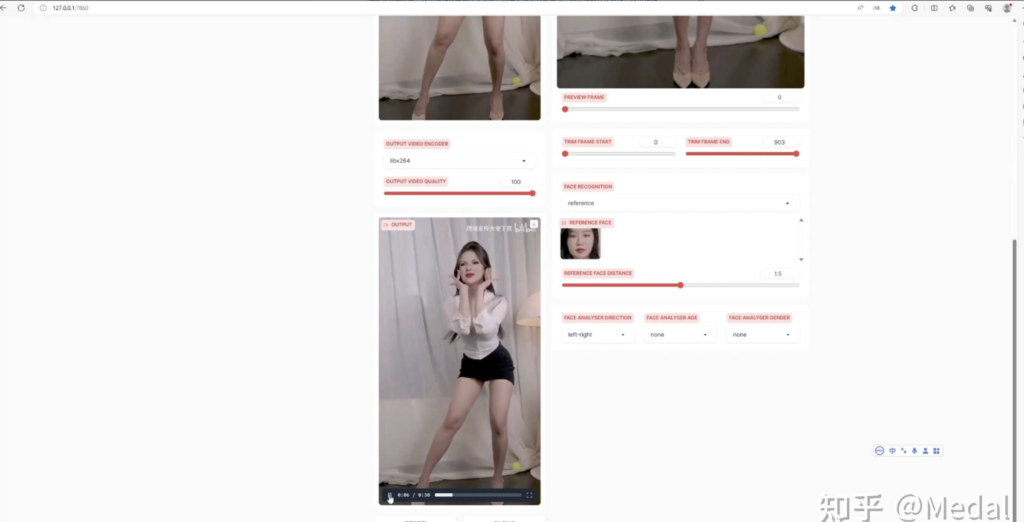
可以看到,虽然跳舞时头部动作很大,但是基本所有帧都能达到比较好的换脸效果。
最后我们来看一看剩下的这些参数的作用,首先我们上传一段新的视频,在这段视频中,有成年人和孩子,性别也是男女都有。
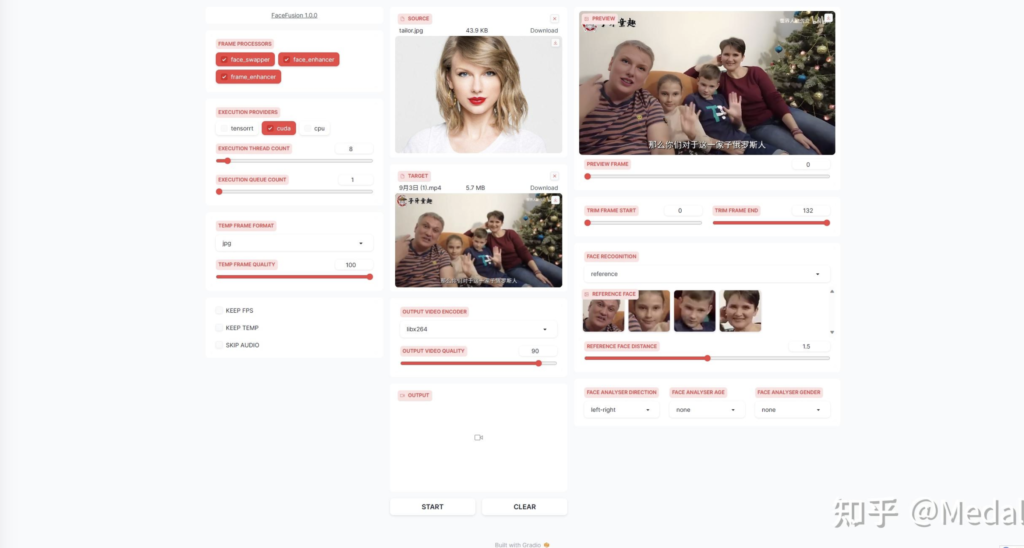
可以看到右边的这个区域显示出了由算法识别出的视频中的全部四张人脸,我们可以通过最下面的选项卡控制人脸识别算法,从而筛选出特定的人,第一个下拉框控制人脸识别的顺序,比如第一个就代表对于视频每一帧,从左到右去检测人脸,第二个下拉框代表需要识别什么年龄段的人脸,第三个下拉框代表需要识别男人还是女人,比如我们选择识别男性,可以看到两个男性的面部被识别了出来,如果选择女性,两个女性的面部就被识别了出来。进一步,我们可以通过点击识别出的照片来控制针对哪个人脸进行替换。现在我们再把泰勒斯威夫特的照片传递上来,可以看到此时会对视频中的这个妈妈进行替换,如果选择这个小女孩,则会对她的人脸记性替换。这个下拉框代表换脸针对的是全部脸还是筛选出的特定脸,如果选择many,就会对所有识别出的人脸进行替换。
让我们试一下效果(可以看文章最上面的视频查看效果)。
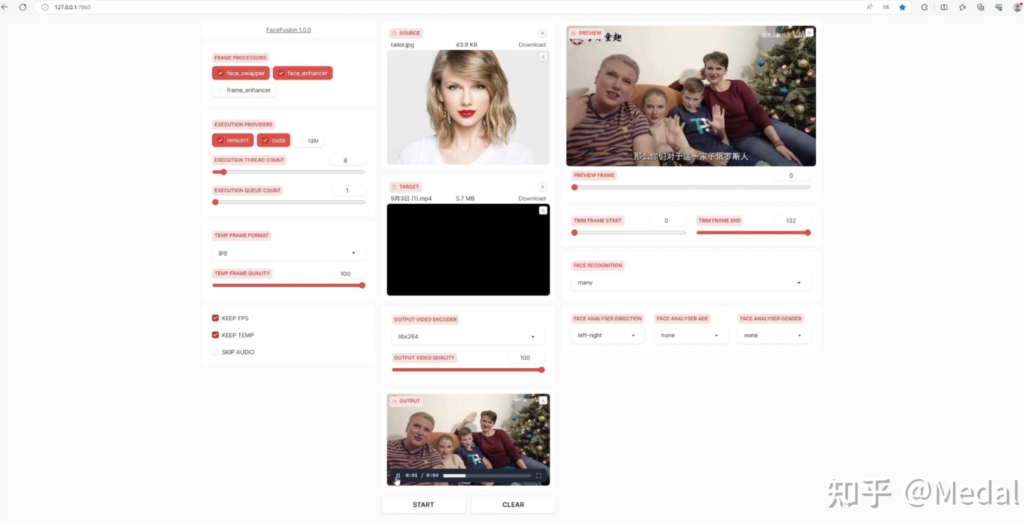
可以看到,全部四张脸都被替换了。进一步,如果你只想替换视频里具体的某一张脸,就可以这样操作。首先,我们把这里从many改成reference,然后按之前介绍的方法筛选出视频中的全部女性,再从中点击妈妈的脸,点击一下这里的clear清除视频,然后让我们重新生成一次。
可以看到,这次只有视频中妈妈的脸被替换了(可以看文章最上面的视频查看效果)。
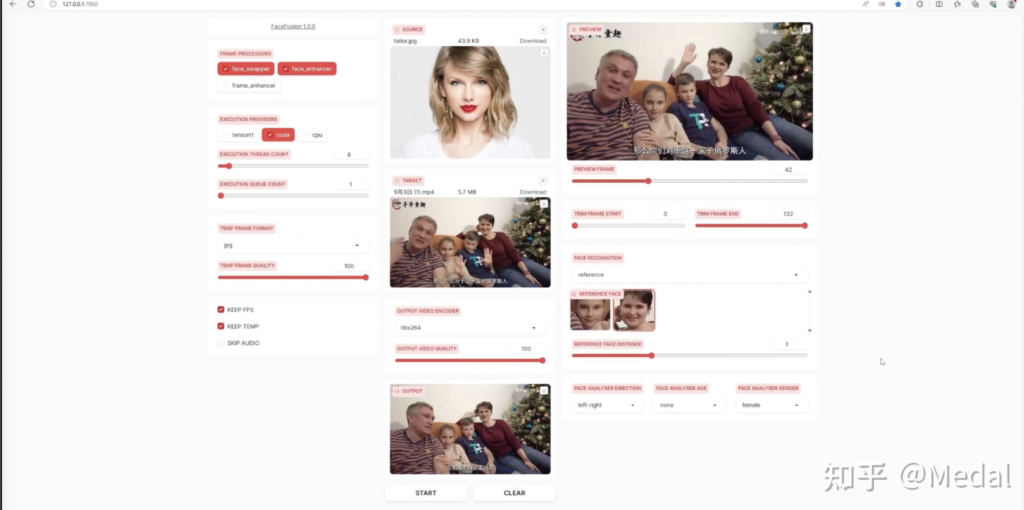
最后,介绍一下face distance这个参数,这是控制目标脸和源头脸相似程度的参数,你可以简单理解为,当换脸的对象和你期望的不相符时,可以通过调节这个参数来改善。比如,把这个参数拉到很小,你会发现视频中所有的脸都不会被替换了,而把这个参数拉大时,视频中的妈妈和女儿都会被换脸,只有将这个参数控制在中间的一个范围,才和我们期望的,只将妈妈进行换脸相符。
以上就是关于FaceFusion的全部内容了,这个项目才刚刚发布,目前看起来还比较简单,但由roop的原班大佬维护和发展,相信未来肯定不会差,目测会成为roop之后的主流换脸项目。值得一提的是,作者选择从roop项目另起炉灶也是为了能让换脸这项AI技术在效果更好的同时,也能更加符合人类伦理,所以在这里也提醒大家,换脸虽好,请莫滥用。