早期的SSR
一般说前后端不分离,指的是早期的开发模式,即前端代码写完后嵌入到后端的JSP/PHP中。由后端服务渲染完数据后直接返回一个完整的HTML页面,里面的数据都已经渲染好了。
例如,如下是一个JSP文件,它的内容是:
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@ page import="java.text.*" %>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>Hello</title>
</head>
<body>
<% out.println("你好"); %>
<br>
<%!
SimpleDateFormat sdf = new SimpleDateFormat("yyyy年mm月dd日");
String s = sdf.format(new Date());
%>
今天是:<%=s %>
</body>
</html>
当客户端尝试向服务端请求这个页面的时候,服务端会对这个模版先进行计算处理,返回给客户端的页面可能是这样的:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>Hello</title>
</head>
<body>
你好
<br>
今天是:2022年05月04日
</body>
</html>
可以直接从这个HTML页面中提取它的关键内容。如果这个客户端指的是爬虫之类的脚本,那么这个爬虫可以分析HTML的结构,然后提取出关键内容。
上面的这种方式称为SSR,即Server Side Rendering。翻译过来的意思就是服务端渲染,很好理解,我们上面页面就是通过服务端渲染出来的,内容都直接包含在HTML中。
与SSR相对的叫做CSR,即Client Side Rendering。翻译过来的意思就是客户端渲染,现在的开发模式,大多数都是CSR
为什么要有CSR
我们先来看看早期的SSR有什么问题。
乘坐时光机,回到十多年前,我们看看腾讯的官方网站是什么样子:
上面的页面十分的简单,几乎都是静态内容,即不用编写太多的JavaScript,仅用HTML+CSS编写页面,然后扔给后端开发人员就可以。
而现在的腾讯官网,上面的网页有着大量的交互效果,它们都需要编写JavaScript来完成,而且整个前端项目也比以前要复杂的多,文件量和代码量都远远超过了早期。
所以我们需要把开发这些页面的工作单独提出来,交由其他的工程师来完成。也明确出现了一个新的工种 – 前端工程师,随着这些年的发展,前端的概念越来越火热,前端工程师的角色也越来越重要,不再局限于开发页面
那CSR和SSR各有哪些不同和优缺点呢?
在回答此问题之前,我们先来看下CSR模式下,前端工程师的开发流程是怎样的
CSR的运行模式
CSR典型的代表是SPA,即单页应用Single Page Application。如今Vue/React都是这种类型的框架。
客户端通过访问域名,向前端服务器请求静态资源(HTML/CSS/JS),向后端服务器请求数据
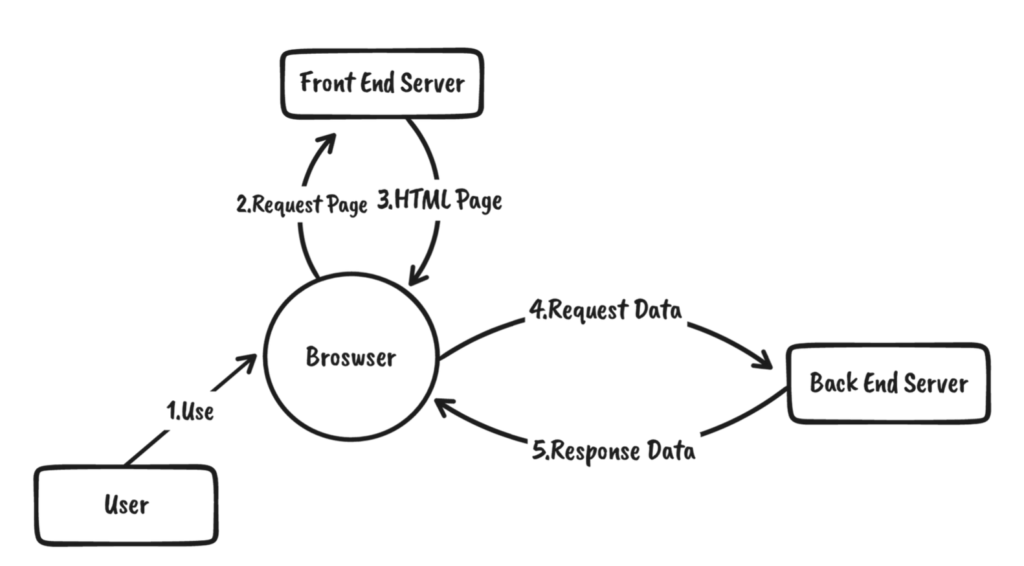
可以看到,CSR模式下,因为前后端的分离,多了一个数据交互的步骤,前端需要通过Ajax/fetch向后端发送请求才能得到数据,然后再将数据渲染到页面上。
既然是这样,那么我们在上面图片的步骤3得到的HTML就很有可能没有完全“渲染”出来。
例如,可能在步骤3得到这样的HTML页面:
<!-- 原始页面 -->
<html>
<head>
<title>Hello</title>
</head>
<body>
<div id="app"></h1>
</body>
<script> const div = document.getElementById('app')
fetch('/api/data').then(res => res.json()).then(data => {
div.innerHTML = data.name
}) </script>
</html>
经过步骤5之后,才可能得到完整的渲染好的页面,例如:
<!-- 执行JS后的页面 -->
<html>
<head>
<title>Hello</title>
</head>
<body>
<div id="app">Hello World</h1>
</body>
<script> const div = document.getElementById('app')
fetch('/api/data').then(res => res.json()).then(data => {
div.innerHTML = data.name //假设data.name是Hello World
}) </script>
</html>
可以看到,CSR模式下,浏览器请求某个域名后得到的HTML页面,里面可能没有有效的内容。必须执行JS代码,才能得到完整的HTMl。
这样的缺点是明显的,不利于爬虫抓取或者SEO,首屏加载速度也更慢。
当然,CSR模式并不是一无是处。一个最大的好处就是前后端分离,可以让前端和后端的代码解耦合,更加方便管理。
除此之外,还有很多优点:
- 因为前端的静态资源与后端是分开的,可以对静态资源进行
CDN缓存,提高页面的加载速度。 - 将渲染的资源消耗由服务端转为客户端的浏览器承担,
减轻服务端的压力,后端可以专注于业务逻辑的处理。
- 局部刷新,这也是
Ajax/fetch带来的好处,通过异步获取数据,修改HTML可以实现页面的局部刷新。
现在的SSR
如今,虽然我们几乎抛弃了传统的SSR模式,但是由于SSR的首屏加载速度等优点。我们仍然需要它,因为直接返回渲染好的HTML在某些场景下很有用。
但是我们又不想回到过去那种古老的方式,于是,专属于前端的SSR诞生了。是的,前端也可以单独做SSR
你可能听过Nuxt.js/Next.js等框架,它们都专注于基于流行的前端框架(Vue/React)做SSR。
原理示意图如下:
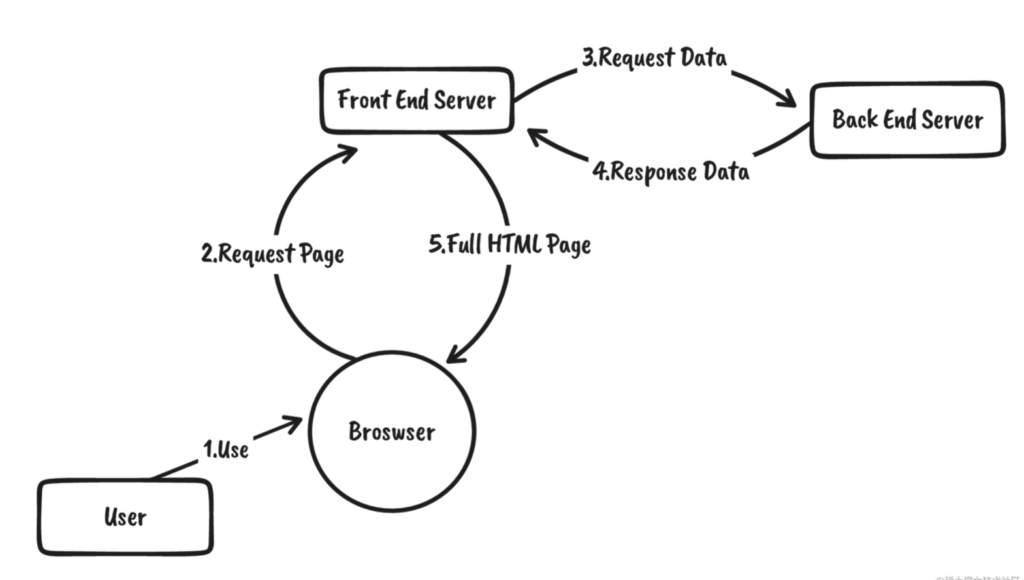
可以看到,Front End Server接管了浏览器的初始渲染工作,所以浏览器可以直接得到渲染好的HTML。
这种方式,结合了早期的SSR的优点,又保留了SPA的优点。
目前还不够?
前端的SSR还存在一些缺点。
似乎我们都忘记了一点,前端的SSR需要在服务区上跑NodeJs,所以,我们需要一个NodeJs的服务器。
这就意味着如果你想要使用SSR,你需要自己搭建一个NodeJs服务器。不能使用一些第三方的CDN服务托管你的前端资源(维护服务器是一件恼火的事情)。
我们再来想一下:
- 为什么我们需要从后端获取数据?
- 因为数据是动态的
- 那假如我们的数据是不变的呢?(个人博客等)
- 是不是就不需要从后端获取数据了?是不是可以把数据直接写入到
HTML中?
- 是不是就不需要从后端获取数据了?是不是可以把数据直接写入到
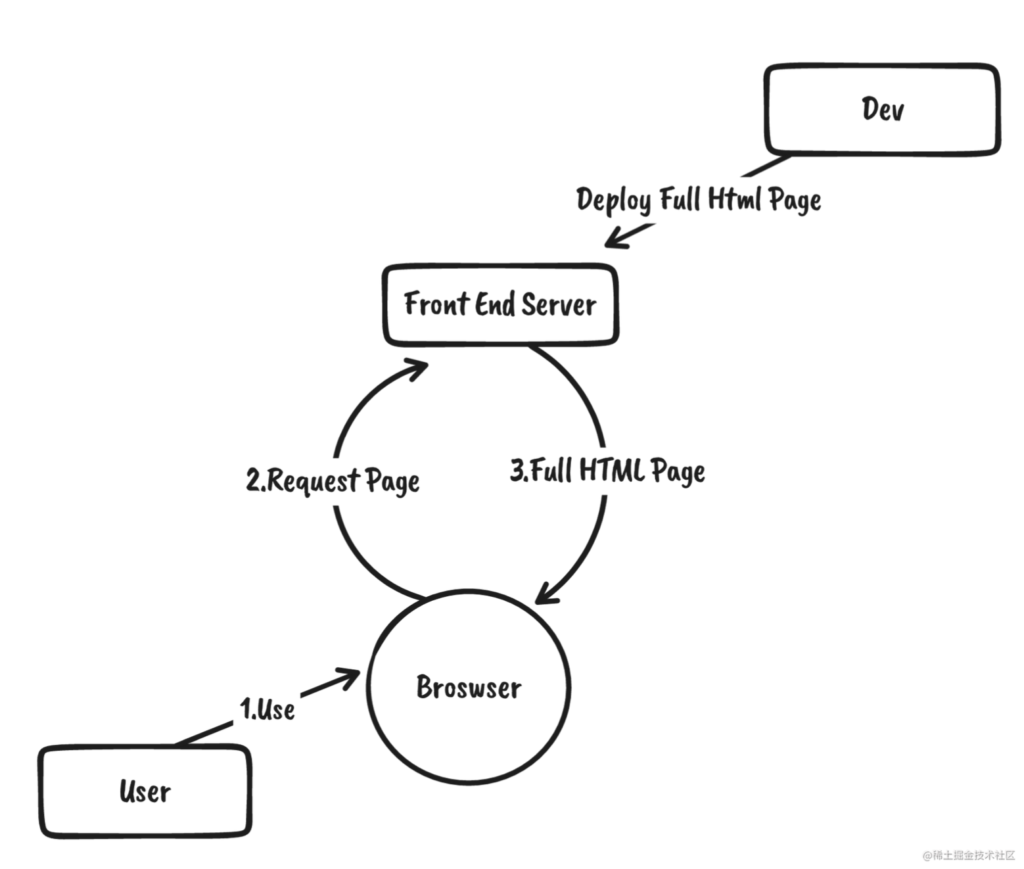
是的,SSG就这么诞生了,根据已有的SPA,在本地打包的时候,计算生成HTML页面,然后可以直接部署。使用方式可以参考某个大佬写的vite-ssg
原理如下:
总结
越来越多的名词出现在前端领域,像SSR, SPA, CSR, SSG,不管是哪一门技术,都给前端开发者带来了很多帮助。或许日后,我们将会看到前端的更多可能。