架构设计及概念
几个系统项目大多是Spring架构,我却一直对Spring鲜有研究,实在惭愧。公司一个有年代的系统,因为应用各模块捆得太深,后台批处理时间分布太宽,每次不论更新哪个模块功能发布都得卡着批任务的时间间隙全停全起。打算用Spring Batch重构一下,正好学习一下Spring体系。
Spring Batch基本设计框架是个样子:
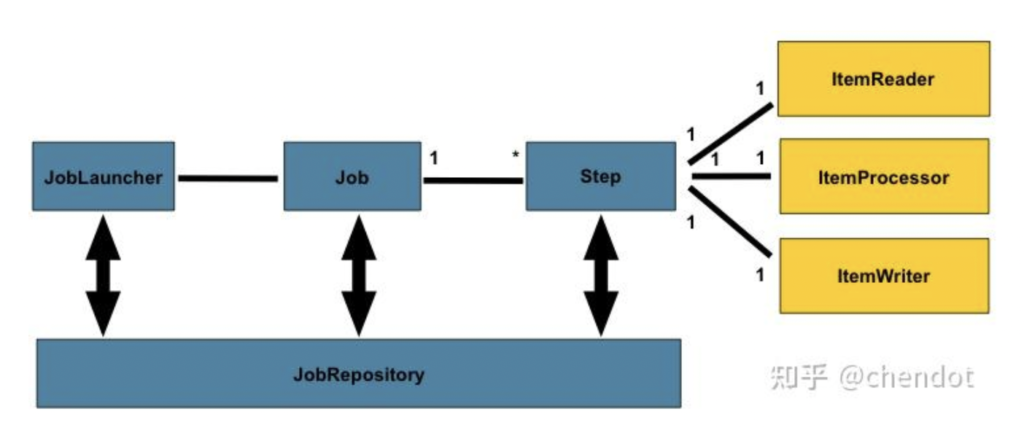
obLauncher根据JobParameters设置来启动Job,Job作为Step的容器,Job需要定义名称、Step顺序和是否支持重跑标识。
JobInstance,顾名思义,是Job的逻辑实例,由JobParameters来控制启用(JobInstance=Job+特定的JobParameters)。所谓逻辑就要对应真实“物理”执行,JobExecution是对应的执行实例。一个JobInstance每次执行都对应一个JobExecution,即如果多次重复执行会有多个JobExecution。
每个Job下可能会有一个或多个的Step,Step通过StepExecution启动执行步骤,StepExecution与各自的JobExecution相对应。Batch框架还需要在数据库中创建一些表(默认BATCH_*打头)用于记录批任务执行中的状态信息,JobRepository则负责管理这些表数据持久化。好像是有点绕,个人理解举个不恰当的栗子:
- Job:做一碗精致的红烧牛肉面
- Step_1:先加水加面;Step_2:再照方加料盛面
- JobParameters:客人A下单啦,微辣、少葱
- JobLauncher:传话小二,告诉后厨Parameters来啦,开始干活
- JobInstance:给后厨的清单——给客户A做一碗精致的,微辣、少葱的牛肉面
- JobExecution_1:后厨真的给客户A做一碗精致的,微辣、少葱的牛肉面
- StepExecution_1-1:大厨加水加面,挥汗如雨;
- StepExecution_1-2:帮厨小师傅加料撒盐,取碗盛面
- JobExecution_2:客户投诉葱放多了,重做一份!对应单子还是之前的JobInstance
- StepExecution_2-1:大厨加水加面,挥汗如雨;
- StepExecution_2-2:帮厨小师傅加料撒盐,取碗盛面
- JobRepository:把上面的菜单、客户点单流水、投诉建议巴拉巴拉都记到账簿里
@EnableBatchProcessing 作用
Spring里面有好些@Enable*类的注解,作用大致都是自动注册所提供模块功能需要的Bean,开箱即用。对于Spring Batch而言,相关依赖包引入后,配置@EnableBatchProcessiong会自动注册下述Bean:
- JobRepository、JobLaunch,作用如上述
- JobRegistry,用于追踪上下文job信息,包括ApplicationContextFactory和JobLoader
- PlatformTransactionManager,Spring基础不好,研究了下,这个继承自TransactionManager接口,用于Spring数据事务管理。
- JobBuilderFactory、StepBuilderFactory,这个比较好理解,用于生产Job和Step
由此,可以开始愉快的装配上述Bean编写自己的批任务逻辑了。
Job的启动
1.使用CommandLineJobRunner通过命令行启动
bash$ java CommandLineJobRunner io.spring.EndOfDayJobConfiguration endOfDay schedule.date(date)=2007/05/05
需要传入参数:jobPath,jobName。CommandLineJobRunner类中包含了main入口函数
2. Web容器启动
准备采用这类方式。通过HttpRequest控制启动,前台可通过@RestController提供访问接口控制JobLauncher,通过@Scheduled(cron = “5 * * * * ?”)设置传入定时参数
这里一般会用到了JobLauncher.run()方法将JobParameters和Job绑定。
JobParameters通过JobParametersBuilder来生成并设置参数。
Job执行情况管理
- JobExplorer查看job状态,即从JobRepository进行读取操作
- JobOperator用于停止、重跑等操作,即对JobRepository写操作
注意事项&问题
mark下写案例时遇到的问题
常规配置
启动时找不到BATCH数据表问题,因为初始化时需要创建一些BATCH_*打头的数据表用于JobRepository保留元数据,解决也很简单,只需在properties文件中加入下述配置即可
程序启动时不希望自动执行任务,需要把相关配置置false
# batch spring.batch.jdbc.initialize-schema=always spring.batch.job.enabled=false
使用PostgreSQL数据库时没有public schema
我自己生成失败的原因。
一个很弱智的原因。
没有创建public schema。导致元数据表生成时不知道在哪个schema自动生成。
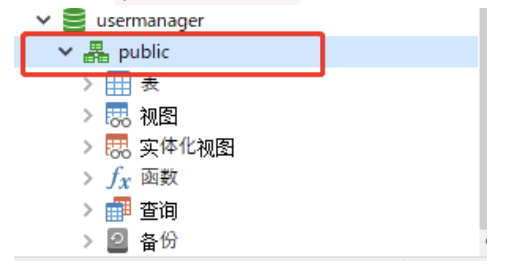
如果暂时没有找到生成失败的原因,可以自行使用sql脚本来创建数据表。
该脚本存在于org.springframework.batch:spring-batch-core依赖的spring-batch-core包中
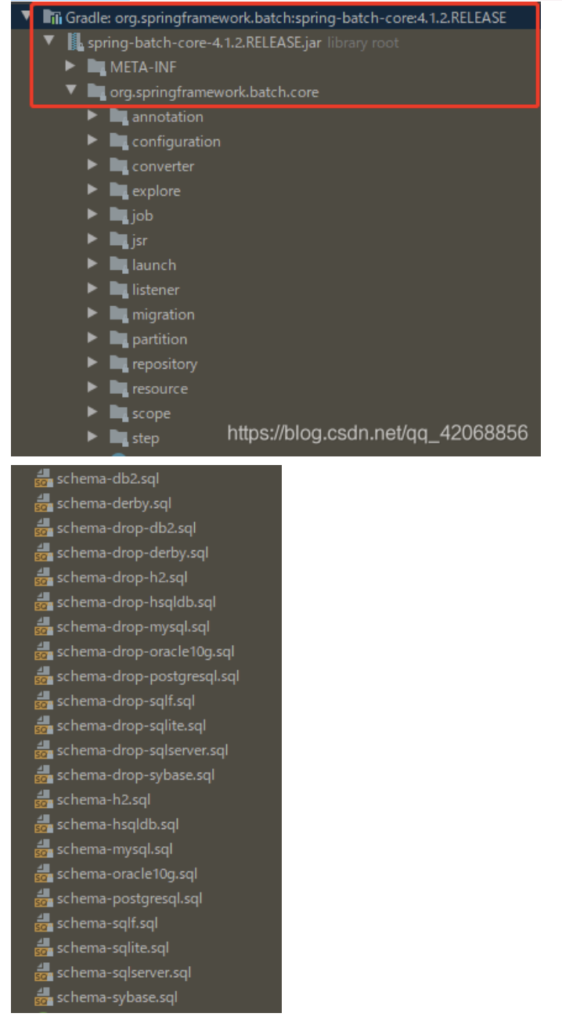
有多种不同数据库的元数据表生成脚本。且包含删除脚本。各位亲自行选择吧。
ORA-08177 无法连续访问此事务处理问题
这个问题搞了比较久,自己电脑上建案例用MySql数据库时启动很顺利没有问题。而后在公司环境重构测试时,使用Oracle数据库会报ORA-08177 无法连续访问此事务处理问题错误。
这里涉及到数据库事务管理的设置,数据库事务管理一般又区分为传播属性(propagation)和事务隔离(isolation)级别的设置。查了下此问题按官方文档解释:
The default isolation level for that method isSERIALIZABLE, which is quite aggressive.READ_COMMITTEDwould work just as well.READ_UNCOMMITTEDwould be fine if two processes are not likely to collide in this way.
大概意思是默认隔离级别定为SERIALIZABLE太保守了,设置为READ_COMMITTED就够用了。然后列出了两种调整方式:
- 重新生成JobRepository实例,并设置隔离级别,覆盖默认的Bean 。
- 通过动态代理类实现对JobRepository的事务级别相关属性设置,所谓的AOP
有点困惑,不知道为啥不能直接在已注册JobRepository Bean中set相关属性?要绕这么一圈。AOP方式参考代码如下,官方参考文档里只设置了传播级别,Oracle11下测试不行,还是要加上隔离级别调整。
@Bean
public TransactionProxyFactoryBean baseProxy() {
TransactionProxyFactoryBean transactionProxyFactoryBean = new TransactionProxyFactoryBean();
Properties transactionAttributes = new Properties();
transactionAttributes.setProperty("*", "PROPAGATION_REQUIRED"); // 设置传播级别
transactionAttributes.setProperty("*", "ISOLATION_READ_COMMITTED"); // 设置隔离级别
transactionProxyFactoryBean.setTransactionAttributes(transactionAttributes);
transactionProxyFactoryBean.setTarget(jobRepository);
// TransactionProxyFactoryBean创建事务代理时,需要了解当前事务所处的环境,该环境属性通过PlatformTransactionManager实例(其实现类的实例)传入
transactionProxyFactoryBean.setTransactionManager(transactionManager);
return transactionProxyFactoryBean;
}
参数传入时机问题
这是因为Job Bean在工程启动时就创建注册到spring容器,而JobParameter的值还没有产生无法获取。
这里涉及到Spring又一个重要内容——作用域注解eg. @Scope(value="prototype"。对应在Spring Batch中有专用注解@StepScop。 它提供一种后绑定效果,就是在生成Step的时候才去创建bean,而不是在加载配置信息的时候就创建。
具体要配合@Value("#{jobParameters[‘contractInfoDat’]}") 注解使用,从job的启动参数中获取所需参数.
Job重复执行问题
正常执行任务情况下,如果用了incrementer(new RunIdIncrementer()),会更新run.id参数传入,对应写入数据表中BATCH_JOBEXECUTION.JOB_INSTANCE_ID字段。
Job: [FlowJob: [name=importUserJob]] launched with the following parameters: [{run.id=23}]
如果定义了一个空的JobParameter,job_instance_id不增长从而导致Job可能无法重复执行,简单的做法是将已完成任务设置可重复执行,通过在step执行中调用allowStartIfComplete(true)方法
Job: [FlowJob: [name=importUserJob]] launched with the following parameters: [{}]
Step already complete or not restartable, so no action to execute: