转载小红书:AI产品赵哥
前言 🔖
作为一个 AI 产品经理过来人,我很能理解大家面对 LangChain 这个家伙时,懵了个圈的状态。
听说这东西很火?听说它是开发 AI 应用的必修课?但去 Github 一看,全是代码;去读官方文档,又是各种抽象概念。
作为产品经理,到底要不要学?学到什么程度?以后能用得上吗?
别慌,今天咱们就把这个家伙拆开、揉碎、炖烂、煮熟,让你吃得下去,消化进去。
为了方便大家阅读,我把这个系列分成了几个大模块,你可以把它当成一本迷你的 “LangChain 实战手册”。
一、先搞清楚:LangChain 到底是个啥?🔖
咱们先别急着看代码,先搞清楚定位。你肯定用过 ChatGPT,对吧?它很强,上知天文下知地理。但是,你有没有发现它在协助我们完成任务的时候,有三个巨大的软肋:
- 它是个 “脑子”,但没有 “手脚”:它没法直接帮你去 Google 搜最新的新闻,也没法直接打开你的 Excel 表修改数据(除非用特定插件,但那不是你自己开发的)。
- 它是个 “金鱼记忆”:你要是跟它聊得太久,或者换个对话框,它就把你之前说啥给忘了。
- 它不懂你的 “家务事”:你问它 “我公司上个月的销售额是多少”,它肯定不知道,因为它没看过你的私有数据。
这时候,LangChain 就闪亮登场了。
如果说 LLM(大语言模型,比如 GPT-4、文心一言)是那个智商爆表的大脑,那么 LangChain 就是链接这个大脑和外部世界的 “神经系统”。它负责帮大模型:
- 连上网(搜索工具);
- 读文件(加载 PDF、Excel);
- 记事情(长短期记忆);
- 做决策(该先干嘛后干嘛)。
用个最俗的比喻:大模型是五星级大厨(脑子好,会做菜)。
但是大厨不能光着身子做菜吧?他需要厨房(环境),需要帮厨(工具)去买菜、洗菜,需要菜谱(Prompt),还需要记性(Memory)记住客人的忌口。
LangChain 就是那个帮你把厨房建好、把帮厨招好、把菜谱写好,最后把大厨请进来干活的餐厅经理。
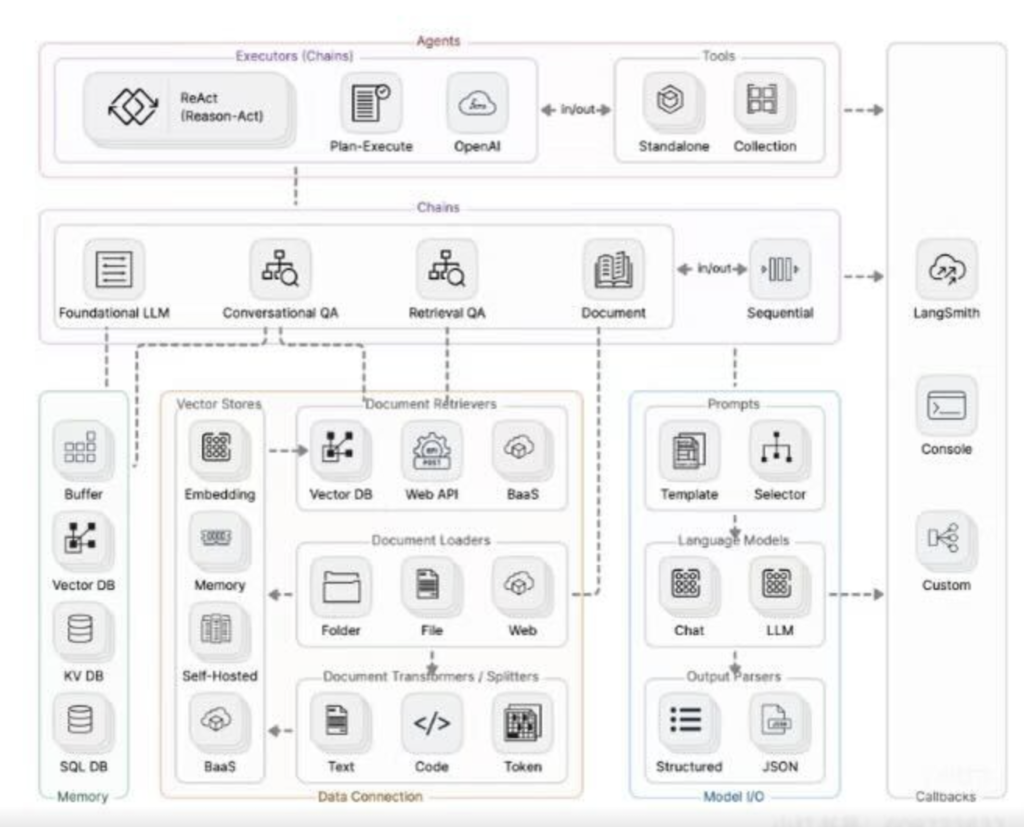
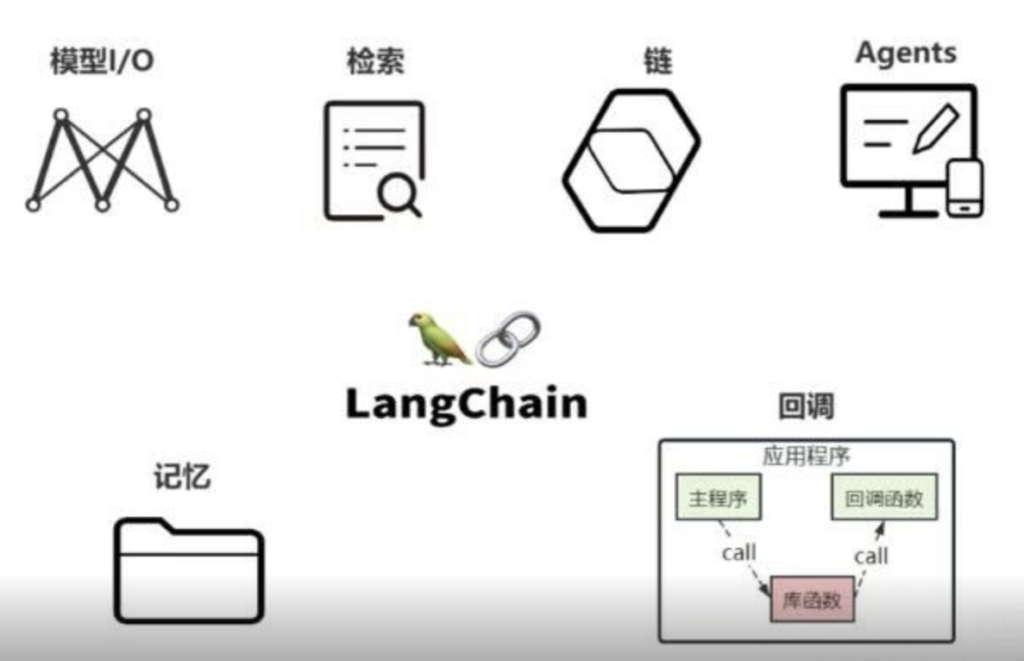
二、构成:LangChain 的六大模块🔖
LangChain 之所以强大,是因为它把开发 AI 应用的过程拆成了几个标准化的模块。哪怕你代码基础一般,像搭积木一样拼拼凑凑,也能弄出个像模像样的东西来。
这六大金刚分别是:Models(模型)、Memory(记忆)、Retrieval(索引 / 数据检索)、Chains(链)、Agents(代理)、Callback(回调)。
咱们一个个把它们 “扒光” 了看。
🔹2.1.Models(模型):换个 “脑子” 就像换灯泡
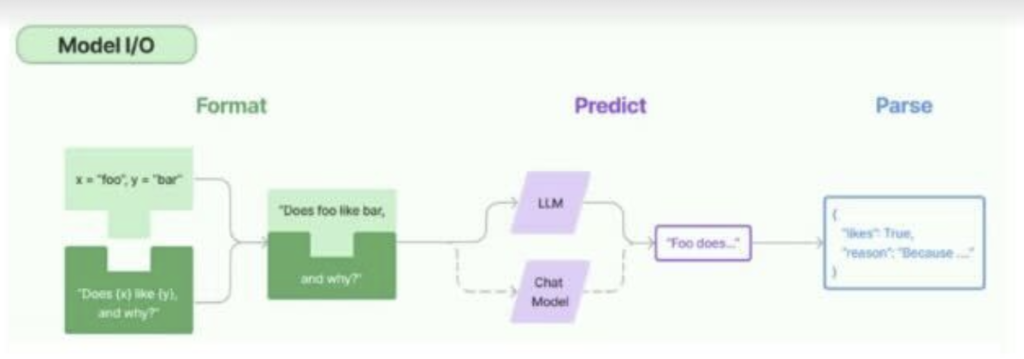
以前我们要换个模型,比如从 GPT-3.5 换到 Claude,那代码得改一堆,接口都不一样。
LangChain 做了一件大好事,它把市面上主流的模型都封装成了统一的接口。
不管你是用 OpenAI,还是用 HuggingFace 上的开源模型,在 LangChain 里,也就是改一行参数的事儿。这叫标准化。
- LLMs(大语言模型):这种主要就是为了 “补全”,你给它半句话,它给你补全剩下的。
- Chat Models(聊天模型):这种更像我们现在的 ChatGPT,有明确的 “系统角色”、“用户角色”、“AI 角色”,它是为了对话设计的。
干货细节:这里有个小坑。很多新手在用的时候,分不清 text-davinci-003(老 LLM)和 gpt-3.5-turbo(Chat Model)的区别。虽然 LangChain 能帮你屏蔽一部分差异,但输入格式是不一样的。LLM 吃的是一串字符串,Chat Model 吃的是一个列表(List of Messages)。这一点要是搞混了,报错能报到你怀疑人生。
Prompts(提示词):把 “说话” 变成 “填空题”
你肯定听说过,提示词工程很重要。但如果你每次写程序都要手敲一段:”你是一个有用的助手,请回答……” 那太累了。
LangChain 引入了 Prompt Template(提示词模板)。
想象一下你要做一个 “翻译机器人”。你不用每次都写:“请把这句话翻译成英语:你好”。你可以做一个模板:
“请把这句话翻译成 {target_language}:{text}”
这就是个填空题。当你程序运行时,只需要把变量填进去,LangChain 自动帮你生成完整的提示词发给模型。这有点类似于我们高考的时候,背的那些作文模板,到考场上去按照作文的要求套模板的过程。
为什么这很重要?因为它让你的程序变 “活” 了。你可以随时动态地改变翻译的目标语言,或者翻译的内容,而不需要去改底层的逻辑。
🔹2.2.Memory(记忆):治好 AI 的 “健忘症”
这是我觉得 LangChain 最性感的功能之一。
原生的 API 接口是无状态的。啥叫无状态?就是你问完第一句,再问第二句,模型压根不知道第一句是啥。为了让对话能继续,你需要把之前的对话记录打包,每次都一股脑地发给模型。
LangChain 帮你自动化了这个过程。它提供了好几种记忆模式:
- ConversationBufferMemory:最简单粗暴,把之前说过的话全记下来,每次全扔给 AI。缺点是贵,Token 消耗巨大。
- ConversationBufferWindowMemory:只记最近的 K 轮对话(比如最近 3 句)。之前的就忘了。这就像鱼的记忆,但省钱。
- ConversationSummaryMemory:这个厉害了。它会用另一个 LLM,帮咱把之前的对话做一个总结,然后只保留总结。这就像我们开会,不记流水账,只记会议纪要。
说实话,现在的 Memory 模块虽然好用,但有时候也挺智障的。特别是那个 “总结记忆”,有时候总结得驴唇不对马嘴,把关键细节给丢了。所以在实际做项目时,我们经常得把好几种记忆方式混合起来用,或者自己写点逻辑去修补。
🔹2.3.Retrieval(检索)与 RAG:给 AI 开小灶
这部分是现在最火的,也就是大家常说的 RAG(检索增强生成)。简单说,就是怎么把你的 PDF、Word、公司文档喂给 AI。
LangChain 把这个过程变成了流水线:
- Document Loaders(文档加载器):不管你是 PDF、TXT、Json 还是网页,LangChain 都有对应的工具把它读进来。
- Text Splitters(文本分割器):大模型一次吃不下一整本书。你需要把书切成一块一块的(Chunk)。这一步非常有讲究!切太大了,Token 不够;切太小了,上下文意思断了。
- Vector Stores(向量数据库):这是核心。我们要把切好的文字,转化成向量(一串数字)存起来。就像去图书馆找书。以前是按书名找,现在是按 “意思” 找。你问 “怎么做红烧肉”,系统会把所有跟 “猪肉”、“酱油”、“炖” 相关的片段找出来。
- Retrievers(检索器):当你提问时,先去数据库里把相关的片段捞出来,拼在 Prompt 里,再扔给 LLM。
RAG 是目前企业落地 AI 应用的最主流方式,没有之一。
LangChain 在这里的生态是最完善的。你如果想做个 “法律顾问 AI” 或者 “客服机器人”,这一块必须吃透。
🔹2.4.Chains(链):把动作串起来
这就是 LangChain 名字的由来(LangChain = Language Chain)。一个复杂的任务,往往不是一步就能搞定的。比如我要写一篇股评:
- 第一步:去搜集今天的股市数据。
- 第二步:让 AI 分析数据。
- 第三步:让 AI 根据分析写成文章。
- 第四步:把文章翻译成英文。
这四个步骤,就是四环链条。LangChain 提供了 SequentialChain(顺序链),能把这些步骤像串糖葫芦一样串起来。前一个步骤的输出,自动变成下一个步骤的输入。
这就有点像工业流水线了。没有 LangChain 之前,你得自己写一大堆 if-else 和胶水代码来传递数据,现在只需要定义好链条结构就行。
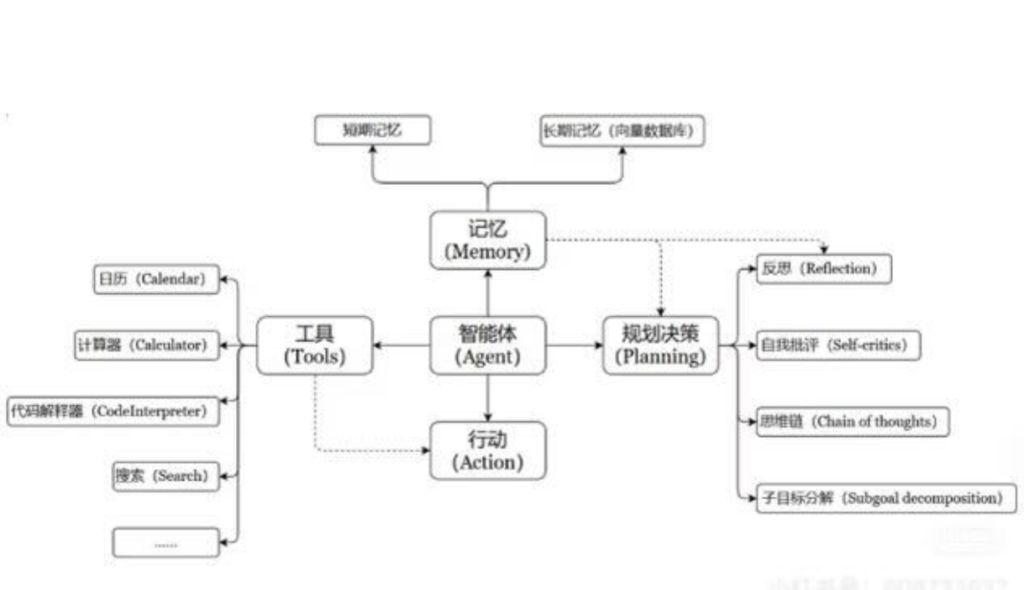
🔹2.5.Agents(智能体 / 代理):AI 有了 “自主意识”
这是 LangChain 出现后,最让人兴奋的点,但也最容易翻车的部分。如果说 Chains 是按部就班的流水线,那 Agents 就是拥有自主决策权的员工。
你给 Agent 一个目标:”帮我策划一次去日本的旅行,并预定机票。”Agent 会自己思考:
- “我得先去搜搜日本哪里好玩。”→ 调用搜索工具。
- “我想去京都,我得查查去京都的机票。”→ 调用机票查询工具。
- “这个航班太贵了,我再查查别的。”→ 再次调用工具。
- “定好了。”→ 返回结果。
在 Agent 模式下,LLM 变成了大脑,它根据当下的情况,自己决定该用什么工具(Tool),该干什么事。这就是通往 AGI(通用人工智能)的雏形啊!
一个数学公式来表示:Agent = LLM + Memory + Tools + Planning + Action
真心话:虽然 Agents 听起来很屌,但在实际生产环境中,它非常不可控。有时候它会陷入死循环(一直在思考,不干活),有时候会乱调用工具。目前我们在做严肃的商业项目时,对 Agent 的使用还是比较谨慎的,更多时候还是倾向于用确定的 Chains。
🔹2.6.Callbacks(回调)—— 战甲的 “日志与监控系统”
这是一个面向开发者的 “调试” 和 “监控” 系统。
- 功能:允许你在 LangChain 运行的任何一个环节(比如 LLM 调用前、工具使用后),“挂载” 一些自定义的函数,用于日志记录、性能监控、成本计算等。
- 战甲比喻:这是钢铁侠战甲的 **“系统日志和诊断面板”**。托尼・斯塔克可以实时看到战甲每个部件的能耗、温度、API 调用次数、花费了多少钱等,方便他进行优化和故障排查。
三、具体实操:手把手带你搞定一个知识库助手🔖
光说不练假把式。咱们现在脑补一下,怎么用 LangChain 做一个 “个人知识库助手”。
假设你电脑里有一堆 PDF 格式的行业报告,你想问 AI 关于这些报告的内容。
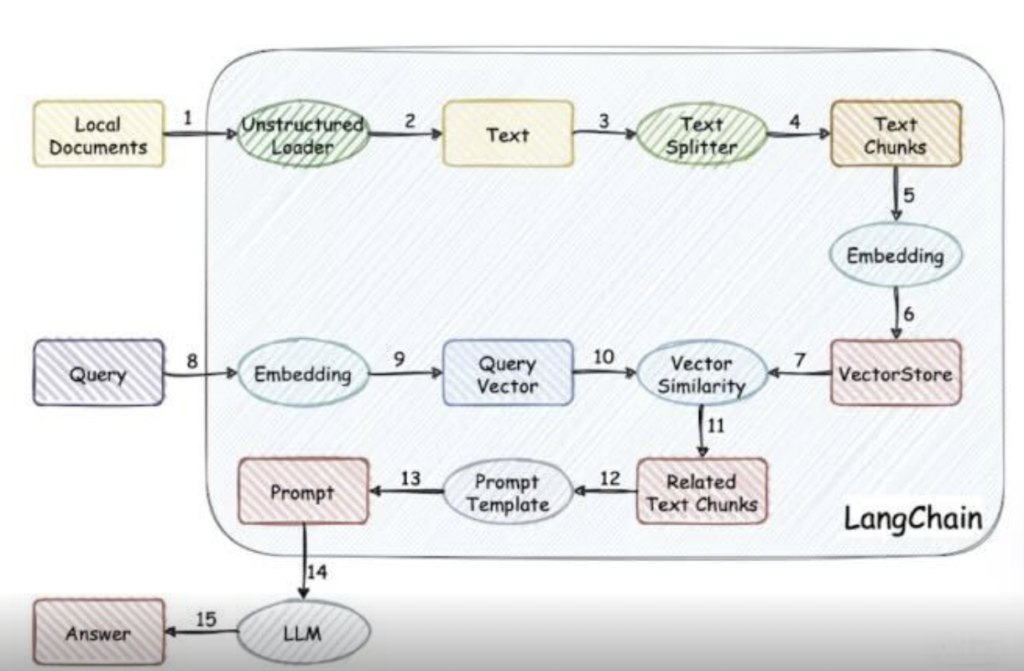
🔹第一阶段:备菜(数据处理)
首先,我们需要用到 LangChain 的 PyPDFLoader。这玩意儿就像个扫描仪,把你文件夹里的 PDF 全部读成文本。
然后,用到 RecursiveCharacterTextSplitter。名字很长,别怕。它的作用就是拿把剪刀,把长篇大论剪成一段一段的,比如每段 500 个字,而且为了防止剪断了句子的意思,段与段之间还会留一点重叠个字,而且为了防止剪断了句子的意思,段与段之间还会留一点重叠(Overlap)。
🔹第二阶段:腌制(向量化)
切好的肉(文本块)是生的,模型吃不下。我们需要调用 OpenAI 的 Embeddings 接口,把这些文字变成向量。
这时候,你需要一个容器来装这些向量。对于新手,推荐用 FAISS 或者 Chroma。它俩就像个轻量级的本地数据库,不需要你装复杂的服务器软件,直接在你的 Python 环境里就能跑。
🔹第三阶段:开火(构建检索链)
现在,你有了数据库,有了 API Key。我们要构建一个 RetrievalQA 链。这个链条的工作原理是这样的:
- 1.用户提问:”报告里关于新能源汽车的预测是啥?”
- 2.检索:LangChain 把你的问题也变成向量,去数据库里 “搜” 最相似的几段原文。
- 3.组装:LangChain 悄悄地把搜到的原文和你的问题拼在一起,变成一个新的 Prompt:”请根据以下参考资料回答问题:[资料片段…] 问题是:新能源汽车的预测是啥?”
- 4.生成:大模型看完资料,假装自己全都知道,给你吐出了答案。
看懂了吗?其实 AI 根本没记住你的文件,它只是在你提问的那一瞬间,临时抱佛脚看了小抄,然后回答了你。这就是 LangChain 干的最核心的事儿!
四、不禁反问:LangChain 是完美的吗?🔖
反转来了,我要给你泼点冷水。
虽然 LangChain 现在是业界的扛把子,但它的糟心事也真的不少。
- 文档写得乱:这是公认的。LangChain 更新太快了,大概两三天就是一个新版本。官方文档经常跟不上代码的更新速度,你在文档里看到的方法,可能在最新版代码里已经被改名或者删除了。这对新手极其不友好。
- 抽象过度:为了兼容所有的模型和数据库,LangChain 封装了一层又一层。有时候你只想做一个简单的功能,结果发现要调用的类藏在很深的地方。这也导致了所谓的 “LangChain 很慢” 的说法 —— 不是运行慢,是调试代码的时候脑子转得慢,因为调用栈太深了。
- 版本不兼容:你今天写的代码,下个月升级了 LangChain 可能就跑不通了。
那为什么还要学它?因为它生态太强了。
- 你想用的任何工具(Google Search, Wikipedia, Notion, Gmail…),LangChain 里都有现成的组件。
- 你想用的任何技术(RAG, ReAct, MapReduce…),LangChain 里都有现成的模板。
- 它就像 AI 届的 Spring 框架或者 React 框架,虽然臃肿,虽然有坑,但它是目前最快上手、资源最多的选择。
- 对于初学者,我的建议是:不要试图去学完 LangChain 的所有 API,那是不可能的。你只需要搞懂它的核心逻辑(就是上面说的六大核心模块),然后用到什么再去查什么。把它当成一个工具箱,而不是一本教科书。
五、未来什么样:LangChain 1.0 与 AI 原生的未来🔖
现在还有一个趋势,叫 LangSmith 和 LangServe。
- LangSmith 是帮你看清这一堆乱七八糟的链条里到底发生了啥的平台(监控与调试)。
- LangServe 是帮你一键把写好的链条变成 API 接口,直接能给前端调用的神器。
这说明啥?说明 LangChain 正在从一个 “代码库” 进化成一套完整的 “AI 开发操作系统”。而且,随着大模型本身的能力越来越强(比如 GPT-4 的 Context 窗口越来越大,能一次性读完一本书),也许未来简单的 RAG 不需要那么复杂的切片逻辑了。但 Agent(智能体)的逻辑会越来越重要。
未来的 AI 应用,一定不是简单的 “一问一答”,而是 “一句话解决复杂任务”。比如:“帮我写个游戏,然后发布到 App Store”。这中间涉及到写代码、画图、测试、填表单、上传等几十个步骤。LangChain 就是在为这种未来打地基。
六、总结🔖
本来写了一些总结,但是感觉都不够完美,就放下面这张图吧: