一、 版本控制工具
1.1. 什么是版本控制系统?
版本控制系统(Version Control System):是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。版本控制系统不仅可以应用于软件源代码的文本文件,而且可以对任何类型的文件进行版本控制。
常见的版本控制系统有:cvs、svn、git
1.2. 为什么要有版本控制系统?
在开发过程中,经常需要对一个文件进行修改甚至删除,但是我们又希望能够保存这个文件的历史记录,如果通过备份,那么管理起来会非常的复杂。
在多人开发时,如果需要多人合作开发一个页面,那么修改以及合并也会非常的棘手。容易出现冲突。
当你在工作中面对的是一些经常变化的文档、代码等交付物的时候,考虑如何去追踪和记录这些changes就变得非常重要,原因可能是:
- 对于频繁改动和改进的交付物,非常有必要去记录下每次变更的内容,每次记录的内容汇成了一段修改的历史,有了历史我们才知道我们曾经做了什么
- 记录的历史中必须要包含一些重要的信息,这样追溯才变得有意义,比如:
- Who: 是谁执行的变更?
- When:什么时候做出的变更?
- What:这次变更做了什么事情?
- 最好可以支持撤销变更,不让某一个提交的严重问题,去污染整个提交历史。
版本控制系统(VCS: Version Control System),正会为你提供这种记录和追溯变更的能力。
大多数的VCS支持在多个使用者之间共享变更的提交历史,这从实质上让团队协同变为了可能,简单说来就是:
- 你可以看到我的变更提交。
- 我也可以看到你的变更提交。
- 如果双方都进行了变更提交,也可以以某种方式方法进行比对和合并,最终作出统一的变更版本。
VCS历经多年的发展,目前业界中有许多VCS工具可供我们选择。在本文中,我们将会针对目前最流行的 git 来介绍。
1.3. 版本控制系统分类
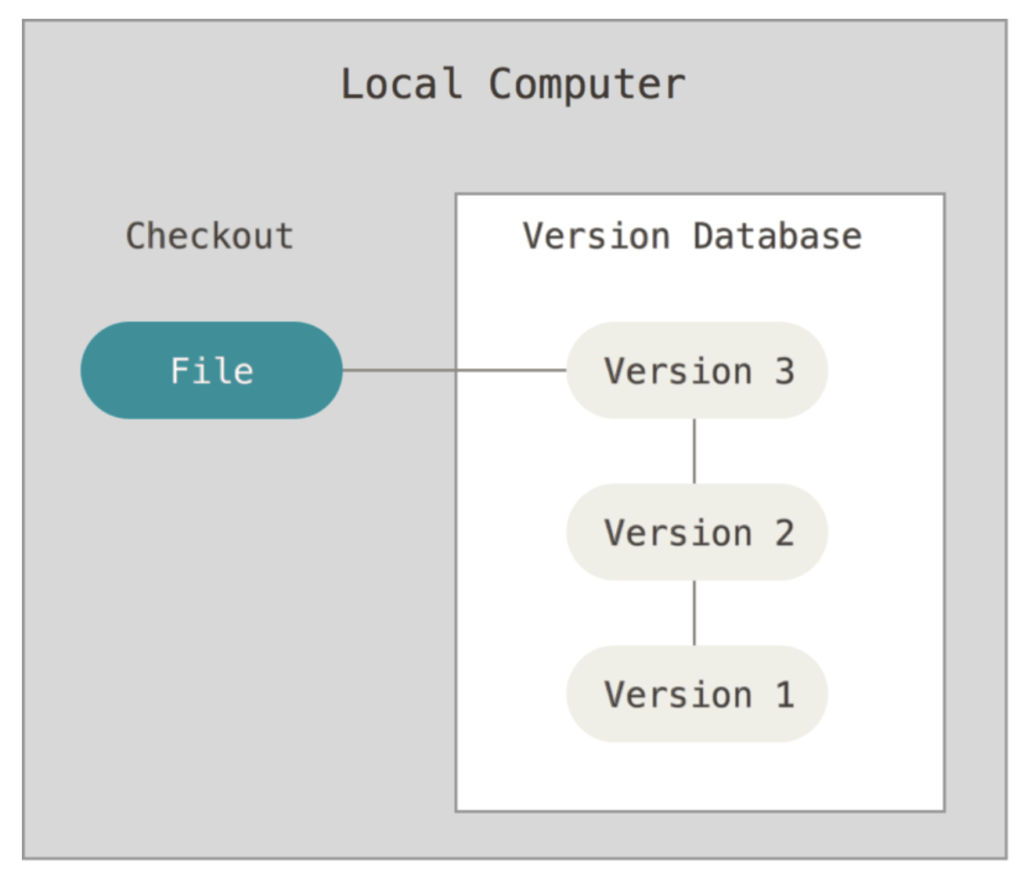
- 本地版本控制系统
本地版本控制系统就是在一台机器上,记录版本的不同变化,保证内容不会丢失
缺点:如果多人开发,每个人都在不同的系统和电脑上开发,没办法协同工作。
- 集中式版本控制系統
svn/cvs都是集中式的版本控制系统
需要一个中央服务器来管理代码的的版本和备份
所有的用户电脑都是从中央服务器获取代码或者是将本地的代码提交到中央服务器
依赖于网络环境,如果连不上中央服务器,就无法提交和获取代码。
如果中央服务器宕机,所有人都无法工作。
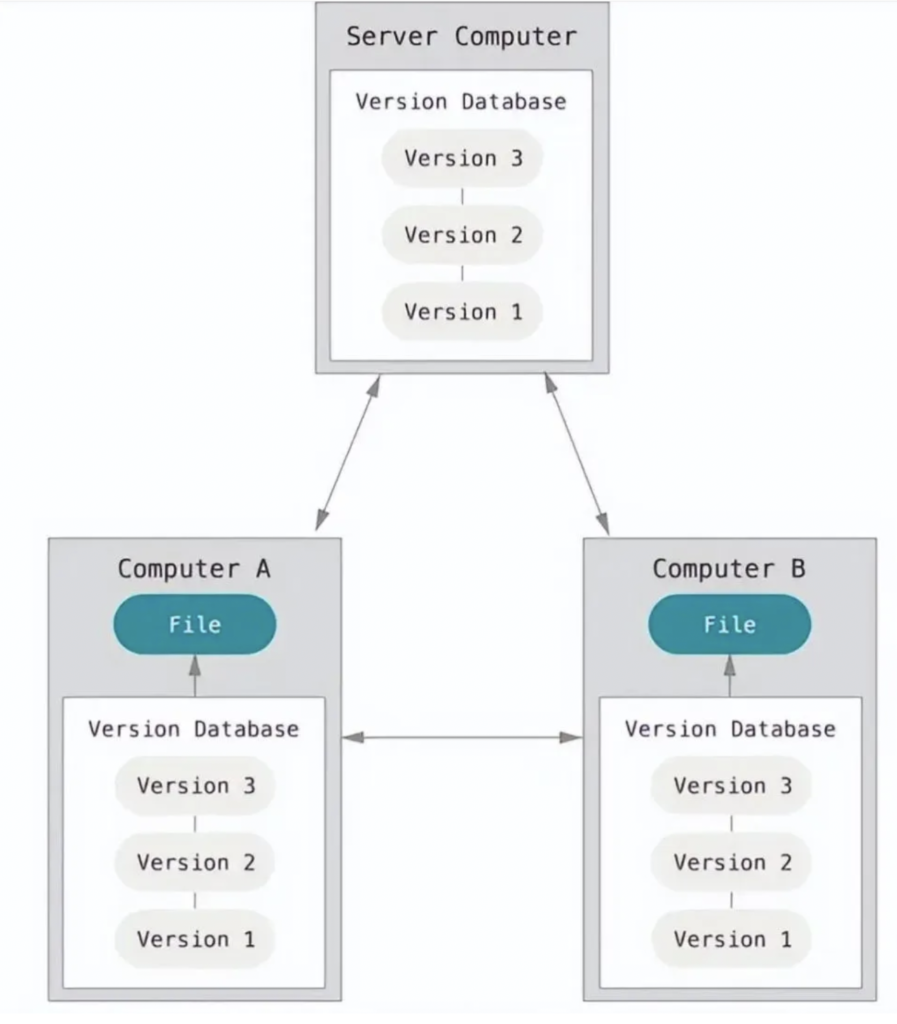
- 分布式版本控制系统
git是分布式的版本控制系统,需要一台中央服务器作为代码仓库。
每个用户电脑都是一个服务器(代码仓库),并且和中央服务器的代码仓库是镜像的,用户修改和获取代码都是提交到自己的服务器当中。
不需要网络就可以进行工作。
当连接网络时,用户可以选择将自己的服务器与中央服务器的代码仓库进行同步。
二、 git是黑魔法么?
刚接触git时,git确实有让人觉得有点像黑魔法一样神秘,但是又有哪个技术不是这样呢?当我们了解其基本的数据结构结构后,会发现git从使用角度来讲其实并不复杂,我们甚至可以更进一步的学习git的一些优良的软件设计理论,从中获益。首先,让我们先从commit说起。
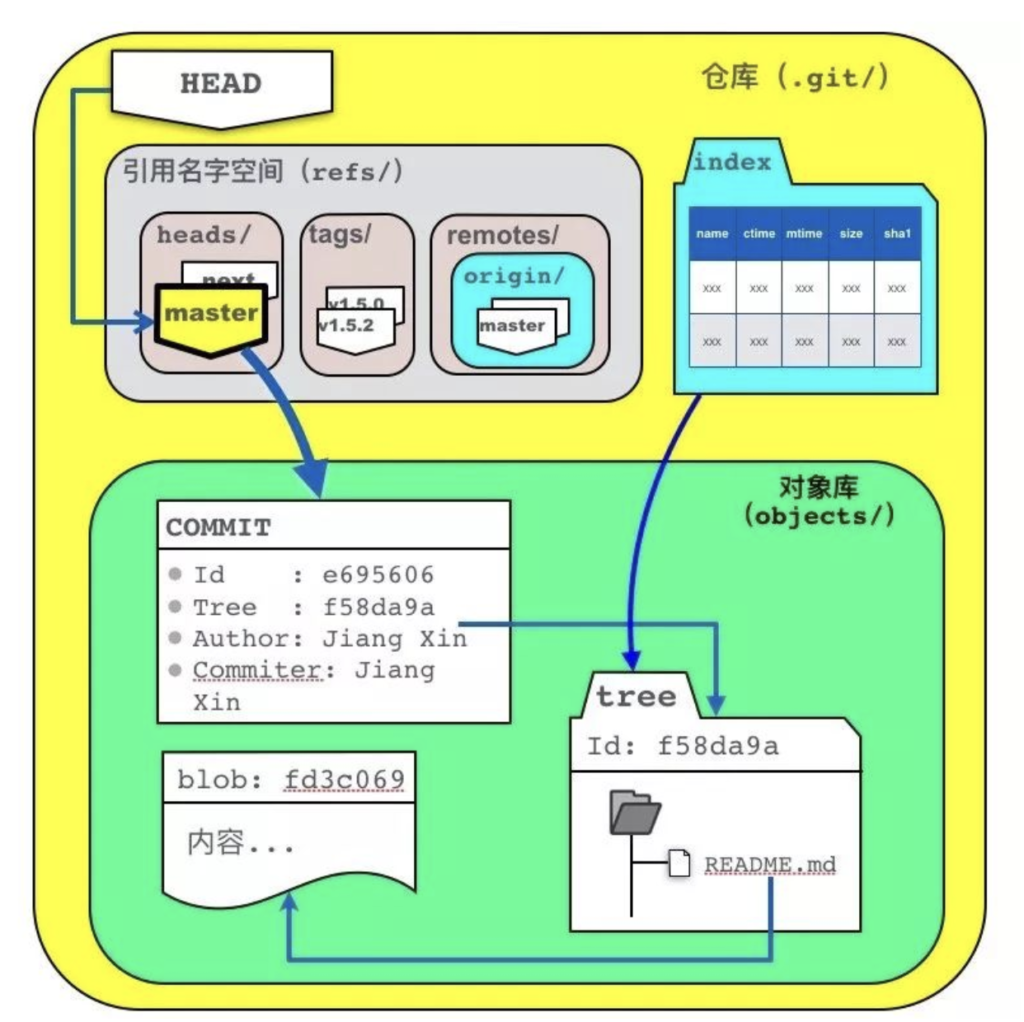
git object commit
- 提交对象(git commit object): 每一个提交在git中都通过git commit object存储,对象具有一个全局唯一的名称,叫做 revision hash。它的名字是由 SHA-1 算法生成,形如”998622294a6c520db718867354bf98348ae3c7e2″,我们通常会取其缩写方便使用,如”9986222″。
- 对象构成: commit对象包含了author + commit message 的基本信息。
- 对象存储:git commit object保存一次变更提交内的所有变更内容,而不是增量变化的数据delta(很多人都理解错了这一点),所以git对于每次改动存储的都是全部状态的数据。
- 大对象存储:因对于大文件的修改和存储,同样也是存储全部状态的数据,所以可能会影响git使用时的性能(glfs可以改进这一点)。
- 提交树: 多个commit对象会组成一个提交树,它让我们可以轻松的追溯commit的历史,也能对比树上commit与commit之间的变更差异。
git commit 练习
让我们通过实战来帮助理解,第一步我们来初始化一个repository(git仓库),默认初始化之后仓库是空的,其中既没有保存任何文本内容也没有附带任何提交:
$ git init hackers $ cd hackers $ git status
第二步,让我们来看下执行过后git给出的输出内容,它会指引我们进行进一步的了解:
➜ hackers git:(master) git status On branch master No commits yet nothing to commit (create/copy files anduse "git add" to track)
output 1: On branch master
- 对于刚刚创建空仓库来说,master是我们的默认分支,一个git仓库下可以有很多分支(branches),具体某一个分支的命名可以完全由你自己决定,通常会起便于理解的名字,如果用hash号的话肯定不是一个好主意。
- branches是一种引用(ref),他们指向了一个确定的commit hash号,这样我们就可以明确我们的分支当前的内容
- 除了branches引用以外,还有一种引用叫做tags,相信大家也不会陌生。
- master通常被我们更加熟知,因为大多数的分支开发模式都是用master来指向“最新”的commit。
- On branch master代表着我们当前是在master分支下操作,所以每次当我们在提交新的commit时,git会自动将master指向我们新的commit,当工作在其他分支上时,同理。
- 有一个很特殊的ref名称叫做”HEAD”,它指向我们当前正在操作的branches或tags(正常工作时),其命名上非常容易理解,表示当前的引用状态。
output 2: No commits yet
- 对于空仓库来说,目前我们还没有进行任意的提交
nothing to commit (create/copy files anduse "git add" to track)
output中提示我们需要使用 gitadd 命令,说到这里就必须要提到暂存或索引(stage),那么如何去理解暂存呢?
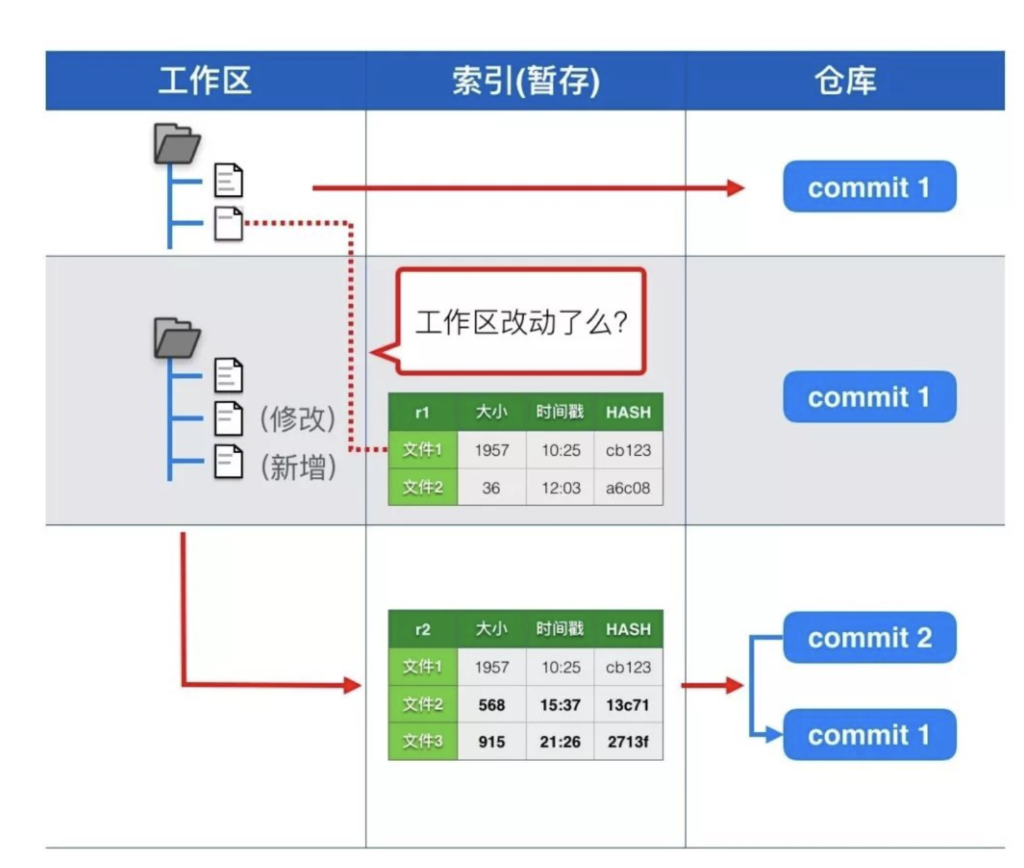
一个文件从改动到提交到git仓库,需要经历三个状态:
- 工作区:工作区指的是我们本地工作的目录,比如我们可以在刚才创建的hackers目录下新增一个readme文件,readme文件这时只是本地文件系统上的修改,还未存储到git。
- 暂存(索引)区: 暂存实际上是将我们本地文件系统的改动转化为git的对象存储的过程
- 仓库:git commit后将提交对象存储到git仓库
对git暂存有一定了解后,其相关操作的使用其实也非常简单,简要的说明如下:
1、暂存区操作
- 通过 git add 命令将改动暂存
- 可以使用 git add -p 来依次暂存每一个文件改动,过程中我们可以灵活选择文件中的变更内容,从而决定哪些改动暂存
- 如果 git add 不会暂存被ignore 的文件改动
- 通过 git rm 命令,我们可以删除文件的同时将其从暂存区中剔除
2、暂存区修正
- 通过 git reset 命令进行修正,可以先将暂存区的内容清空,在使用 git add -p 命令对改动review和暂存
- 这个过程不会对你的文件进行任何修改操作,只是git会认为目前没有改动需要被提交
- 如果我们想分阶段(or 分文件)进行reset,可以使用 git reset FILE or git reset -p 命令
3、暂存区状态
- 可以用 git diff –staged 依次检查暂存区内每一个文件的修改
- 用 git diff 查看剩余的还未暂存内容的修改
4、Just Commit
- 当你对需要修改的内容和范围满意时,你就可以将暂存区的内容进行commit了,命令为: git commit
- 如果你觉得需要把所有当前工作空间的修改全部commit,可以执行 git commit -a ,这相当于先执行 git add后执行 git commit,将暂存和提交的指令合二为一,这对于一些开发者来说是很高效的,但是如果提交过大这样做通常不合适。
- 我们建议一个提交中只做一件事,这在符合单一职责的同时,也可以让我们明确的知道每一个commit中做了一件什么事情而不是多个事情。所以通常我们的使用习惯都是执行 git add -p 来review我们将要暂存内容是否合理?是否需要更细的拆分提交?这些优秀的工程实践,将会让代码库中的commits更加优雅☕️
我们已经在不知不觉中了解了很多内容,我们来回顾下,它们包括了:
- commit包含的信息?
- commit是如何表示的?
- 暂存区是什么?如何全部添加、一次添加、删除、查询和修正?
- 如何将暂存区的改动内容commit?
- 不要做大提交,一个提交只做一件事
附带的,在了解commit过程中我们知道了从本地改动到提交到git仓库,经历的几个关键的状态:
- 工作区(Working Directory)
- 暂存区(Index)
- Git仓库(Git Repo)
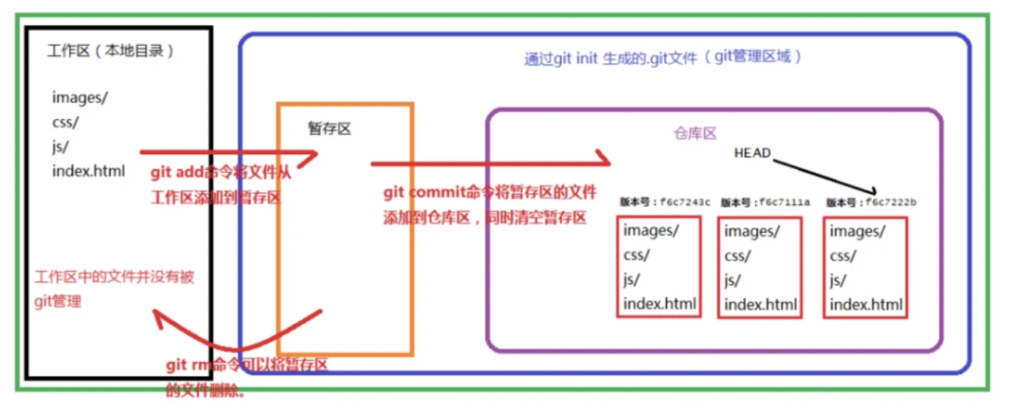
下图为上述过程中各个状态的转换过程:
- 本地改动文件时,此时还仅仅是工作区内的改动
- 当执行 git add 之后,工作区内的改动被索引在暂存区
- 当执行 git commit 之后,暂存区的内容对象将会存储在git仓库中,并执行更新HEAD指向等后续操作,这样就完成了引用与提交、提交与改动快照的一一对应了。
- 正是因为git本身对于这几个区域(状态)的设计,为git在本地开发过程带来了灵活的管理空间。我们可以根据自己的情况,自由的选择哪些改动暂存、哪些暂存的改动可以commit、commit可以关联到那个引用,从而进一步与其他人进行协同。
正是因为git本身对于这几个区域(状态)的设计,为git在本地开发过程带来了灵活的管理空间。我们可以根据自己的情况,自由的选择哪些改动暂存、哪些暂存的改动可以commit、commit可以关联到那个引用,从而进一步与其他人进行协同。
三、关于git
版本控制的一个常见功能是允许多个人对一组文件进行更改,而不会互相影响。或者更确切地说,为了确保如果他们不会踩到彼此的脚趾,不会在提交代码到服务端时偷偷的覆盖彼此的变化。
在git中我们如何保证这一点呢?
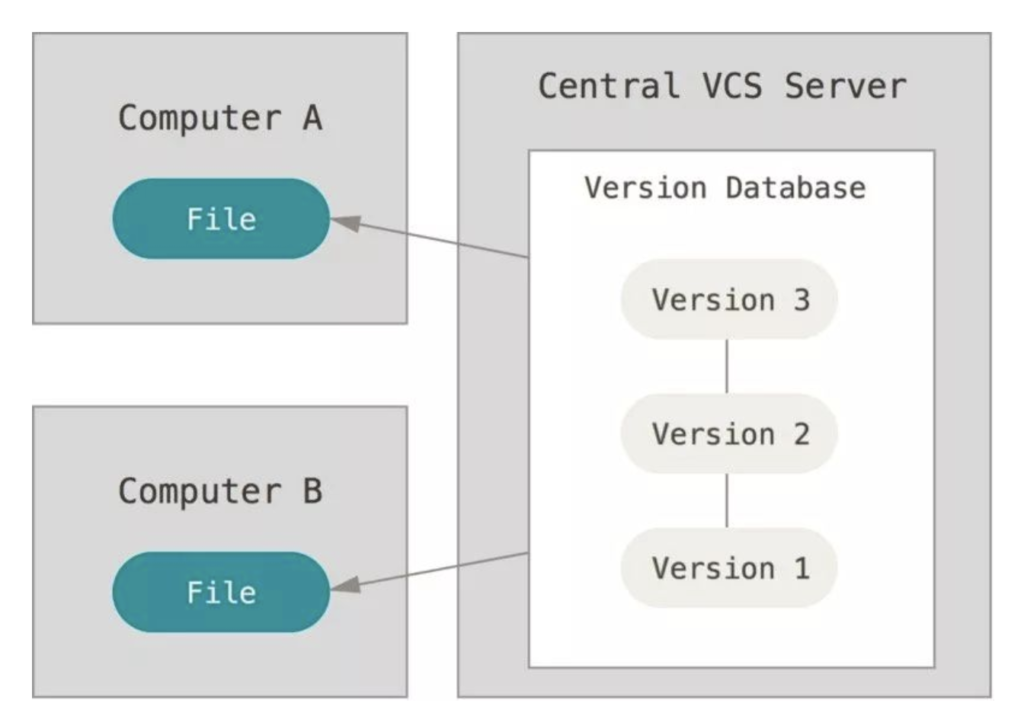
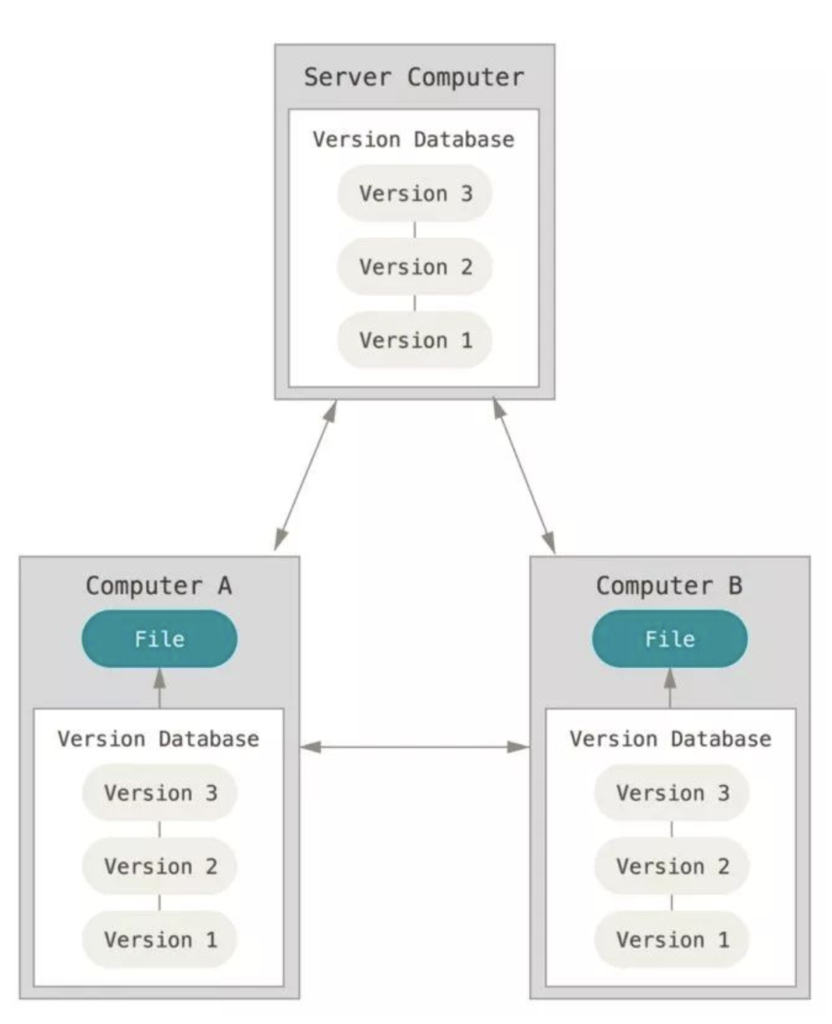
git与svn不同,git不存在本地文件存在lock的情况,这是一种避免出现写作问题的方式,但是并不方便,而git与svn最大的不同在于它是一个分布式VCS,这意味着:
- 每个人都有整个存储库的本地副本(其中不仅包含了自己的,也包含了其他人的提交到仓库的所有内容)。
- 一些VCS是集中式的(例如,svn):服务器具有所有提交,而客户端只有他们“已检出”的文件。所以基本上在本地我们只有当前文件,每次涉及本地不存在的文件操作时,都需要访问服务端进行进一步交互。
- 每一个本地副本都可以当作服务端对外提供git服务
- 我们可以用git push推送本地内容到任意我们有权限的git远端仓库
- 不管是集团的force、github、gitlab等工具,其实本质上都是提供的git仓库存储的相关服务,在这一点上其实并没有特别之处,针对git本身和其协议上是透明的。
四、git分支操作
分支就是科幻电影里面的平行宇宙,当你正在电脑前努力学习Git的时候,另一个你正在另一个平行宇宙里努力学习SVN。
如果两个平行宇宙互不干扰,那对现在的你也没啥影响。不过,在某个时间点,两个平行宇宙合并了,结果,你既学会了Git又学会了SVN!
为什么要有分支?
如果你要开发一个新的功能,需要2周时间,第一周你只能写50%代码,如果此时立即提交,代码没写完,不完整的代码会影响到别人无法工作。如果等代码写完再提交,代码很容易丢失,风险很大。
有了分支,你就可以创建一个属于自己的分支,别人看不到,也不影响别人,你在自己的分支上工作,提交到自己的分支上,等到功能开发完毕,一次性的合并到原来的分支。这样既安全,又不影响他人工作。
在工作过程中,经常会碰到多任务并行开发 的情况,使用分支就能很好的避免任务之间的影响。
其他版本工具比如svn,cvs中也有分支这个概念,但是这些工具中的分支操作非常的慢,形同摆设。
五、git冲突解决
冲突的产生几乎是不可避免的,当冲突产生时你需要将一个分支中的更改与另一个分支中的更改合并,对应git的命令为 git merge NAME ,一般过程如下:
- 找到HEAD和NAME的一个共同祖先(common base)
- 尝试将这些NAME到共同祖先之间的修改合并到HEAD上
- 新创建一个merge commit对象,包含所有的这些变更内容
- HEAD指向这个新的mergecommit
git将会保证这个过程改动不会丢失,另外一个命令你可能会比较熟悉,那就是 git pull 命令,git pull 命令实际上包含了 git merge 的过程,具体过程为:
- git fetch REMOTE
- git merge REMOTE/BRANCH
- 和 git push一样,有的时候需要先设置 “tracking”(-u) ,这样可以将本地和远程的分支一一对应。
如果每次merge都如此顺利,那肯定是非常完美的,但有时候你会发现在合并时产生了冲突文件,这时候也不用担心,如何处理冲突的简要介绍如下:
- 冲突只是因为git不清楚你最终要合并后的文本是什么样子,这是很正常的情况
- 产生冲突时,git会中断合并操作,并指导你解决好所有的冲突文件
- 打开你的冲突文件,找到 <<<<<<< ,这是你需要开始处理冲突的地方,然后找到=======,等号上面的内容是HEAD到共同祖先之间的改动,等号下面是NAME到共同祖先之间的改动。用 git mergetool 通常是比较好的选择,当然现在大多数IDE都集成了不错的冲突解决工具
- 当你把冲突全部解决完毕,请用 git add . 来暂存这些改动吧
- 最后进行git commit,如果你想放弃当前修改重新解决可以使用 git merge –abort ,非常方便
- 当你完成了以上这些艰巨的任务,最后 git push 吧!
六、push失败的处理
排除掉远端的git服务存在问题以外,我们push失败的大多数原因都是因为我们在工作的内容其他人也在工作的关系。
Git是这样判断的:
- 1、会判断REMOTE的当前commit是不是你当前正在pushing commit的祖先。
- 2、如果是的话,代表你的提交是相对比较新的,push是可以成功的(fast-forwarding)
- 3、否则push失败并提示你其他人已经在你push之前执行更新(push is rejected)。
当发生push is rejected 后我们的几个处理方法如下:
- 使用git pull合并远程的最新更改(git pull相当于 git fetch + git merge)
- 使用 –force 强制推送本地变化到远端饮用进行覆盖,需要注意的是 这种覆盖操作可能会丢失其他人的提交内容
- 可以使用 –force-with-lease 参数,这样只有远端的ref自上次从fetch后没有改变时才会强制进行更改,否则reject the push,这样的操作更安全,是一种非常推荐使用的方式。
- 如果rebase操作了本地的一些提交,而这些提交之前已经push过了的话,你可能需要进行force push了,可以想象看为什么?
七、git忽视文件
在仓库中,有些文件是不想被git管理的,比如数据的配置密码、写代码的一些思路等。git可以通过配置从而达到忽视掉一些文件,这样这些文件就可以不用提交了。
在仓库的根目录创建一个.gitignore的文件,文件名是固定的。
将不需要被git管理的文件路径添加到.gitignore中