什么是 SSR
SSR 顾名思义就是 Server-Side Render, 即服务端渲染。原理很简单,就是服务端直接渲染出 HTML 字符串模板,浏览器可以直接解析该字符串模版显示页面,因此首屏的内容不再依赖 Javascript 的渲染(CSR – 客户端渲染)。
Server-side rendering (SSR)是应用程序通过在服务器上显示网页而不是在浏览器中渲染的能力。服务器端向客户端发送一个完全渲染的页面(准确来说是仅仅是 HTML 页面)。
与 SSR 相对的,还有一种 Client-side rendering(CSR)。CSR 和 SSR 的最大区别只是提供 rendering 的是客户端还是服务端,其本质还是一种东西。
服务器渲染就是向后端服务器请求数据,然后在后端生成完整的首屏html页面返回给浏览器。
服务器渲染返回给浏览器的是已经获取了异步数据并执行js脚本的最终html页面,网络爬虫可以抓取到完整的页面信息,SSR另一个很大的作用是加速首屏渲染,因为无需等待所有的js脚本下载并执行,所以用户会很快看到渲染完成的首屏页面。
SSR 的核心优势
- 首屏加载时间:因为是 HTML 直出,浏览器可以直接解析该字符串模版显示页面。
- SEO 友好:正是因为服务端渲染输出到浏览器的是完备的 html 字符串,使得搜索引擎 能抓取到真实的内容,利于 SEO。
为什么要 SSR
得益于 React 等前端框架的发展,前后端分离,webpack 等编译工具的流行,以及 ajax 实现页面的局部刷新,使得我们现在的应用程序不再像曾经的应用程序一般需要从服务端获取页面,可以动态的修改局部的页面数据,避免页面频繁跳转影响用户体验等问题。也就是 SPA 越来越成为主流应用程序模型。
但是 SPA 的使用,除了以上提到的优势以外,必然会带来劣势。譬如:
- 由于需要在页面加载之前就加载所有页面需要的 JavaScript 库,这使得首次打开页面所需要的时间比较久;
- 需要研发专门针对于 SPA 的 Web 框架(各种具备 SSR 能力的框架,包括
Next.js等) - 搜索引擎爬虫
- 浏览器历史记录的问题(基于
pushState的各种router)
为了解决上述提到的 1. 和 3. 的问题,SSR 开始登上历史的舞台。
SSR 怎么做
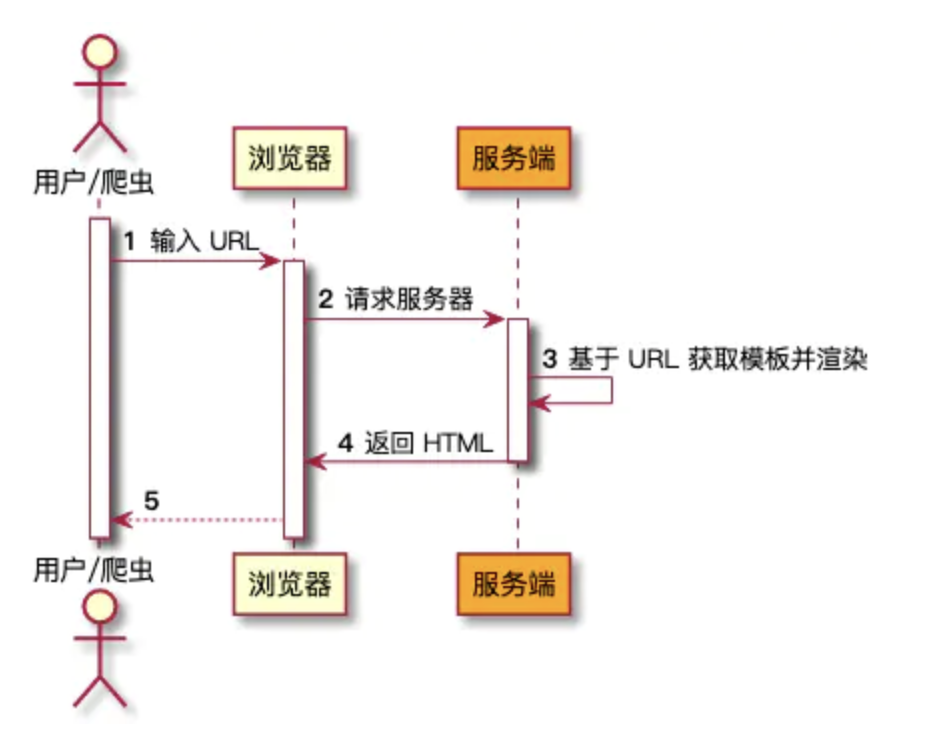
基于上述的理论,我们可以设计一个具有 SSR 功能的 React 框架。
首先,我们通过 create-react-app 命令初始化一个 React 项目,可以把初始化完成后的项目理解为具有最简单功能的项目。我们将基于该项目去实现一个 SSR 的功能。
# Yarn $ yarn create react-app ssr-demo
生成项目的目录如下:
./ ├── README.md ├── build ├── node_modules ├── package.json ├── public ├── src └── yarn.lock
已经自动安装完依赖,启动项目我们可以在「本地环境」看到一个最简单的页面。
接下来,我们去实现一个 SSR 功能。首先,我们需要安装 express(如果是 CSR 的话就不需要这一步)
yarn add express
安装完成后,我们需要在 server/index.js文件中编写如下代码
import express from "express";
import serverRenderer from "./serverRenderer.js";
const PORT = 3000;
const path = require("path");
const app = express();
const router = express.Router();
// 当爬虫的请求进来的时候,把所有请求导向 serverRenderer 路由
router.use("*", serverRenderer);
app.use(router);
app.listen(PORT, () => console.log(`listening on: ${PORT}`));
其中serverRenderer该文件内容如下:
import React from "react";
import ReactDOMServer from "react-dom/server";
import App from "../src/App";
const path = require("path");
const fs = require("fs");
export default (req, res, next) => {
// 获取当前项目的 HTML 模板文件路径
const filePath = path.resolve(__dirname, "..", "build", "index.html");
// 读取该文件
fs.readFile(filePath, "utf8", (err, htmlData) => {
if (err) {
console.error("err", err);
return res.status(404).end();
}
// 借助 react-dom 依赖下的方法将 JSX 渲染成 HTML string
const html = ReactDOMServer.renderToString(<App />);
// 将 HTML string 替换到 root 中
return res.send(
htmlData.replace('<div id="root"></div>', `<div id="root">${html}</div>`)
);
});
};
如上,我们完成了一个非常简单的具有 SSR 功能的服务端。
但是仅仅如此是不够的,我们还需要在根目录下,新建parser.js将ESM 转成 CommonJS 运行起来,代码如下:
require("ignore-styles");
require("@babel/register")({
ignore: [/(node_modules)/],
presets: ["@babel/preset-env", "@babel/preset-react"],
});
require("./server");
解释一下上面引入的包的作用:
@babel/register:该依赖会将 node 后续运行时所需要 require 进来的扩展名为.es6、.es、.jsx、.mjs和.js的文件将由 Babel 自动转换。ignore-styles:该依赖也是一个 Babel 的钩子,主要用于在 Babel 编译的过程中忽略样式文件的导入。
在经过上述的操作之后,我们先 yarn build出我们的产物,然后通过node parser.js来启动 SSR 服务。
SSR性能
与 CSR(Client-side rendering)模式相比,SSR 的性能优势体现在两方面:
- 网络链路
- 省去了客户端二次请求数据的网络传输开销
- 服务端的网络环境要优于客户端,内部服务器之间通信路径也更短
- 内容呈现
- 首屏加载时间(FCP)更快
- 浏览器内容解析优化机制能够发挥作用
网络链路上,由服务端发出接口请求,将返回数据随 HTML 响应内容一次性传递到客户端,比 CSR 二次请求更快。并且服务端网络传输速度更快(可以有更大带宽)、通信路径更短(可以同机房部署)、通信效率也更高(可以走 RPC)
内容呈现方面,CSR 的 HTML 大多是个空壳儿:
<!DOCTYPE html>
<html>
<head>
<title>My Awesome Web App</title>
<meta charset="utf-8">
</head>
<body>
<div id="app"></div>
<script src="bundle.js"></script>
</body>
</html>
客户端拿到这种 HTML 只能立即渲染出一页空白,二次请求的数据回来之后才能呈现出有意义的内容,而 SSR 返回的 HTML 是有内容(数据)的,客户端能够立刻渲染出有意义的首屏内容(First Contentful Paint)。同时,静态的 HTML 文档让流式文档解析(streaming document parsing)等浏览器优化机制也能发挥其作用
关键区别是 SSR 不依赖客户端环境,包括网络环境和设备性能,即使用户的网络情况很糟(弱网)、设备性能很差(廉价、老旧设备),服务端渲染同样能够保障与最优用户环境(Wi-Fi 网络、高端设备)下相近的内容加载体验
可访问性
可访问性(accessibility)从两方面理解:
- 对人:古老、特殊的用户设备,比如禁用了 JavaScript
- 对机器人:爬虫程序等,典型的,搜索引擎爬虫
前者一般不必太过在意,后者要关注两大“客户”:
- 搜索引擎:SEO
- 社交媒体:抓取页面内容展示缩略信息(比如 Twitter 卡片等)
对 PC 站点而言,保证搜索引擎能够正确索引、准确理解页面内容,有重要的商业价值(搜索结果靠前,曝光量更大)。移动端虽不必考虑搜索引擎爬取,但也有类似的社交分享需求,社交媒体会抓取目标页面中的图片等作为缩略信息。
P.S.诚然,有些搜索引擎能够正确爬取重 CSR 的 SPA,但不是全部,并且一大批社交媒体大都只从响应 HTML 中提取部分内容作为缩略信息,动态渲染 HTML(部分)内容的需求真切存在。
虽具有这些优势,但 SSR 却远不如 CSR 应用广泛,是因为 SSR 面临着 6 大难题。
SSR的6 个难题
难题1:如何利用存量 CSR 代码实现同构
为了降级、复用、降低迁移成本等目的,通常会采用一套 JavaScript 代码跨客户端、服务端运行的同构方式来实现 SSR,然而,要让现有的 CSR 代码在服务端跑起来,先要解决诸多问题,例如:
- 客户端依赖:分为 API 依赖和数据依赖两种,比如
window/document之类的 JS API、设备相关数据信息(屏幕宽高、字体大小等)。 - 生命周期差异:例如 React 中,
componentDidMount在服务端不执行。 - 异步操作不执行:服务端组件渲染过程是同步的,
setTimeout、Promise之类的都等不了。 - 依赖库的适配:React、Redux、Dva 等等,甚至还有第三方库等不确定能否跑在 universal 环境,是否需要跨环境共享状态,以状态管理层为例,SSR 要求其 store 必须是可序列化的。
- 两边共享状态:每一份需要共享的状态都要考虑(服务端)如何传递、(客户端)如何接收。
难题2:服务的稳定性和性能要求
与客户端程序相比,服务端程序对稳定性和性能的要求严苛得多,例如:
- 稳定性:异常崩溃、死循环
- 性能:内存/CPU 资源占用、响应速度(网络传输距离等都要考虑在内)
因此面临后端专业性问题,Demo 级的 SSR 可能并不难,但高可用的 SSR 服务却绝非易事,如何应对大流量/高并发,如何识别故障,如何降级/快速恢复,哪些环节需要加缓存,缓存如何更新等等。
难题3:配套设施的建设
SSR 最核心的部分是渲染服务,但除此之外还要考虑:
- 本地开发套件(校验 + 构建 + 预览/HMR + 调试)
- 发布流程(版本管理)
一整套的工程设施,在 SSR 模式下都需要重新考虑
难题4:钱的问题
引入 SSR 渲染服务,实际上实在网络结构上加了一层节点,而大流量所过之处,每一层都是钱。
将组件渲染逻辑从客户端改到服务器执行,计算资源的成本必须考虑在内。
难题5:hydration 的性能损耗
客户端接到 SSR 响应之后,为了支持(基于 JavaScript 的)交互功能,仍然需要创建出组件树,与 SSR 渲染的 HTML 关联起来,并绑定相关的 DOM 事件,让页面变得可交互,这个过程称为 hydration。
hydration 所需加载、执行的 JavaScript 代码不见得比 CSR 模式少多少,这部分工作在客户端执行,受限于用户设备的性能,在较差的设备下可能会造成可感知的不可交互时间。
- CSR:可交互但是没有数据(还在异步请求数据,可能会持续很长)
- SSR:有数据但是不可交互(拉到 JS 后开始 hydrate 的过程,能看到内容但是不可交互,一般不会持续很长)
富交互的场景下,后者不一定比前者用户体验更好。
难题6:数据请求
服务端同步渲染要求先发请求,拿到数据后才开始渲染组件,那么面临 3 个问题:
- 数据依赖要从业务组件中剥离出来
- 缺失客户端公参(包括 cookie 等客户端会默认带上的 header 信息)
- 两边数据协议不同:服务端可能有更高效的通信方式,比如 RPC
目前主流的 CSR 模式下,数据依赖与业务组件存在紧耦合,要由服务端发起的数据请求全都掺杂在组件生命周期函数中,剥离数据依赖意味着需要同时改造 CSR 代码。公参、数据协议等差异对代码复用、可维护性也提出了一些新的挑战。
应用场景
无论首屏加载性能还是可访问性,都是对内容密集型页面才有意义,而对于交互密集型的页面,SSR 所能提前渲染的内容不多,对用户意义不大,SEO 的必要性也值得商榷。因此,SSR 适用于偏静态的内容展示场景,典型的,商品详情、攻略、文章等图文混排的场景。
另一方面,不一定非要 100% SSR,渲染特定页面,甚至只渲染个页面框架也是不错的应用。