在上一篇博客中我们简单了解了一下IBM Cloud Code Engine,是一个完全托管的、无服务器的平台,它运行您的容器化工作负载,包括web应用程序、微服务、事件驱动的函数,以及具有“运行到完成”特性的批处理作业。在这篇博文中将介绍代码引擎中的一些使用场景以及自动扩展和服务绑定。
第一部分我们将学习应用程序的并发性设置,以及如何使用该设置来优化延迟和吞吐量。并发性决定了应用程序的每个实例在任何给定时间可以处理的同时请求的数量,要控制每个应用程序的并发性修订,用户可以在应用程序详细信息页面的运行时部分设置并发性值。在CLI中,当使用IBM Code Engine CLI创建/更新应用程序时,用户可以使用–concurrency标志配置并发性。API规范允许您在修订模板上设置containerConcurrency。设置容器并发性(cc)配置将强制在应用程序实例中处理请求的上限。如果并发性达到这个限制,后续请求将被缓冲,并且必须等待有足够的容量来执行请求,通过完成请求或扩展其他应用程序实例,可以释放额外的容量。
接下来我们了解下应用程序的伸缩是如何工作的。自动伸缩器,由Knative提供支持,它观察系统中的请求数量,并向上或向下伸缩应用程序实例,以满足用户的并发性设置。特别是,当没有请求到达应用程序时,自动伸缩器可以将应用程序扩展到零。在这种情况下,不会运行任何实例,也不会产生任何成本。如果扩展到零,并将请求路由到应用程序,自动伸缩器将从零扩展应用程序,并将请求路由到新创建的应用程序实例。因此,系统有一个内部缓冲区来排队请求,直到应用程序实例准备好为请求服务为止。
在内部,自动伸缩器引入了一个60秒的滑动窗口,并扩展应用程序以满足滑动窗口上的平均并发性。由于请求率可以是动态的,并且可以发生显著的变化(例如,请求的突发),当观察到70%的容器并发性(内部配置)时,自动伸缩器就已经扩展了,反之亦然。换句话说,如果用户指定的容器并发性为10,当在60秒的稳定窗口期间平均观察到7个请求时,自动伸缩器将添加一个额外的应用程序实例。在请求率显著增加的情况下,自动伸缩器将进入应急模式。在应急模式中,自动缩放器的反馈循环更短(6s滑动窗口),缩放策略更激进(即,它将更快速地扩大,以满足70%的容器并发在6s应急窗口)。当观察到200%的容器并发性(内部配置)时,自动伸缩器进入应急模式。换句话说,如果用户配置的容器并发性为10,那么当系统中观察到20个请求时,将进入应急模式。
使用命令ic ce app create/update创建或更新应用程序时,可以通过添加以下两个注释:–min-scale 和 –max-scale来为自动缩放器配置缩放边界。
autoscaling.knative.dev/minScale (--min-scale): 要继续运行的最小应用程序实例数。当设置为0(默认)时,自动伸缩器将在没有流量到达应用程序时删除所有实例。 autoscaling.knative.dev/maxScale (--max-scale): 将运行的应用程序实例的最大数量。自动伸缩器不会超出这个值。
接下来如何优化延迟和吞吐量,以下部分将解释一些配置容器并发性(cc)的示例和最佳实践:
Single-concurrency, cc=1: 当应用程序服务于内存或CPU密集型工作负载时,开发人员应该选择单并发模型,因为每次只有一个请求将进入应用程序实例,因此将获得为实例配置的全部CPU和内存,请求不会在同一时间点上竞争资源。单并发模型的一个缺点是应用程序向外扩展更快,向外扩展可能会引入额外的延迟和更低的吞吐量,因为创建新的应用程序实例比重用现有应用程序实例的成本更高。因此,如果请求可以并发处理并且延迟是应用程序的一个关键方面,那么开发人员不应该选择这种模型。
High-concurrency, cc=100 (default) or higher: 当应用程序服务于大量http请求/响应工作负载时,开发人员应该选择这种配置,其中请求不是CPU或内存密集型的,并且请求等待I/O。例如,将CRUD操作上的数据读写到远程数据库的API后端,当一些请求等待I/O时,其他请求可以在不影响总体延迟和吞吐量的情况下进行处理。当并发请求在CPU、内存或I/O上发生竞争时,此设置不是最佳的,因为这会延迟执行并对延迟和吞吐量产生负面影响。
Optimal-concurrency, cc=N: 一些应用程序开发人员非常了解其应用程序的资源需求,因此知道满足应用程序所需响应时间的单个请求所需的资源数量。一个典型的例子是自然语言翻译应用程序,其中语言翻译的机器学习模型为32gb,单个翻译计算每个请求大约需要0.7 vCPU。开发人员可以选择9个vcpu和每个实例32GB内存的配置。最佳的容器并发性大约是13 (9 vCPU/0.7vCPU)。
当行为不完全知道和理解时,要小心设置任意值,错误的容器并发性可能导致过于激进或过于懒惰的伸缩性,这可能会影响应用程序的延迟、错误率和成本。使用以下步骤确定最佳容器并发性值。
Infinite-concurrency, cc=0 (disabled): 只是为了完整性起见,因为Knative支持此设置,并且用户可能希望IBM Cloud Code Engine也支持它,但事实并非如此。该设置将尝试将尽可能多的请求转发到单个应用程序实例,这将延迟扩展其他应用程序实例。在各种测试和分析中,我们看到了更高的错误率和更高的延迟。因此,我们在IBM Cloud Code Engine中禁用了此设置,以保护用户免受意外行为的影响。
最后我们了解如何确定容器的并发性。容器并发性(cc)直接影响应用程序的成功率、延迟和吞吐量。当容器并发性值太高,应用程序无法处理时,客户端将看到对延迟和吞吐量的负面影响,甚至可能临时观察到502和503错误响应。当容器并发性值对应用程序来说太低时也会发生同样的情况,因为这将导致系统更快地向外扩展应用程序,并将请求分散到许多应用程序实例中,这也可能带来额外的成本和延迟开销。在负载突发期间,当系统的内部缓冲区运行时,这也可能导致临时的502响应。最佳容器并发性值由应用程序在可接受的请求延迟下可以处理的最大并发请求数决定。
下面的过程可以用来为应用程序近似一个好的容器并发性值:
- 创建一个应用程序,并将其cc=1000 (max), minScale和maxScale都设置为1。
ibmcloud ce application create -name APPNAME --image APPIMAGE --min-scale=1 --max-scale=1 --concurrency=1000
. 使用像vegeta或wrk这样的负载生成工具来生成针对应用程序的负载。首先,以较高的速率发送请求。如果有502个错误,那么降低成功率,直到结果显示100%的成功率。
- 现在,考虑步骤2输出的请求延迟。如果请求延迟不可接受,则进一步降低请求率,直到请求延迟看起来可以接受为止。注意,请求持续时间扮演着重要的角色(也就是说,如果请求的计算需要2秒或100毫秒,则会产生很大的不同)。
- 要计算应用程序的容器并发值,请从步骤2(以req/s为单位)取RATE,然后除以步骤3(以s为单位)的LATENCY: CC = RATE/LATENCY。例如,如果速率为80req /s,延迟为2s,则并发数为CC = 80req /s / 2s = 40。
- 现在更新应用程序,将容器并发性设置为我们从上一步(40)中获得的值,并重新运行工作负载以检查成功率和延迟是否可以接受。
- 通过将容器并发性设置为稍大一些的值来试验应用程序,看看它是否仍然能够获得可接受的成功率和延迟。
- 最后,我们得到了最佳的容器并发值,并可以删除minScale和maxScale边界,以允许应用程序自动伸缩。
我们看一个使用CLI扩展应用的例子,可以使用cloud shell来完成。通过使用application create或application update命令改变–min-scale和–max-scale选项的值来控制应用程序运行实例的最大值和最小值。
第一步:使用Create命令创建一个应用程序。
ibmcloud ce application create -name myapp --image docker.io/ibmcom/helloworld
第二步:调用应用程序。可以从app create命令的输出中获取应用程序的URL,也可以运行ibmcloud ce app get –name myapp –output URL。
curl https://myapp.4svg40kna19.us-south.codeengine.appdomain.cloud
第三步:运行application get命令显示应用程序的状态。查找Running实例的值。在这个例子中,应用程序有一个正在运行的实例。例如:
ibmcloud ce application get -name myapp
输出:
OK Name: myapp [...] URL: https://myapp.4svg40kna19.us-south.codeengine.appdomain.cloud Console URL: https://cloud.ibm.com/codeengine/project/us-south/01234567-abcd-abcd-abcd-abcdabcd1111/application/myapp/configuration Status Summary: Application deployed successfully Image: docker.io/ibmcom/helloworld Resource Allocation: CPU: 1 Ephemeral Storage: 500Mi Memory: 4G Revisions: myapp-ds8fn-1: Age: 6m25s Traffic: 100% Image: docker.io/ibmcom/helloworld (pinned to fe0446) Running Instances: 1 Runtime: Concurrency: 100 Maximum Scale: 10 Minimum Scale: 0 Timeout: 300 Conditions: Type OK Age Reason ConfigurationsReady true 6m10s Ready true 5m56s RoutesReady true 5m56s Events: Type Reason Age Source Messages Normal Created 6m28s service-controller Created Configuration "myapp" Normal Created 6m28s service-controller Created Route "myapp" Instances: Name Revision Running Status Restarts Age myapp-ds8fn-1-deployment-79bdd76749-khtmw myapp-ds8fn-1 2/2 Running 0 32s
第四步:再次运行应用程序get命令,注意Running实例的值已缩放为零。当应用程序结束运行时,如果–min-scale选项设置为0(这是默认值),则运行实例的数量将自动扩展到零。
ibmcloud ce application get -n myapp
输出:
OK Name: myapp [...] URL: https://myapp.4svg40kna19.us-south.codeengine.appdomain.cloud Console URL: https://cloud.ibm.com/codeengine/project/us-south/01234567-abcd-abcd-abcd-abcdabcd1111/application/myapp/configuration Image: docker.io/ibmcom/helloworld Resource Allocation: CPU: 1 Ephemeral Storage: 500Mi Memory: 4G Revisions: myapp-ds8fn-1: Age: 12m Traffic: 100% Image: ibmcom/hello (pinned to 548d5c) Running Instances: 0 Runtime: Concurrency: 100 Maximum Scale: 10 Minimum Scale: 0 Timeout: 300 Conditions: Type OK Age Reason ConfigurationsReady true 3m7s Ready true 2m54s RoutesReady true 2m54s Events: Type Reason Age Source Messages Normal Created 3m21s service-controller Created Configuration "myapp" Normal Created 3m20s service-controller Created Route "myapp"
第五步:再次调用应用程序,使其从零扩展。
curl https://myapp.4svg40kna19.us-south.codeengine.appdomain.cloud
第六步:再次运行应用程序get命令,注意Running实例的值从零增加。例如:
ibmcloud ce application get -n myapp
输出:
OK Name: myapp [...] URL: https://myapp.4svg40kna19.us-south.codeengine.appdomain.cloud Console URL: https://cloud.ibm.com/codeengine/project/us-south/01234567-abcd-abcd-abcd-abcdabcd1111/application/myapp/configuration Status Summary: Application deployed successfully Image: docker.io/ibmcom/helloworld Resource Allocation: CPU: 1 Ephemeral Storage: 500Mi Memory: 4G Revisions: myapp-ds8fn-1: Age: 13m Traffic: 100% Image: docker.io/ibmcom/helloworld (pinned to fe0446) Running Instances: 1 Runtime: Concurrency: 100 Maximum Scale: 10 Minimum Scale: 0 Timeout: 300 Conditions: Type OK Age Reason ConfigurationsReady true 16m Ready true 16m RoutesReady true 16m Events: Type Reason Age Source Messages Normal Created 17m service-controller Created Configuration "myapp" Normal Created 17m service-controller Created Route "myapp" Instances: Name Revision Running Status Restarts Age myapp-ds8fn-1-deployment-79bdd76749-76l4w myapp-ds8fn-1 1/2 Running 0 16s
第二部分,我们看一下服务绑定。在开发应用程序时,您经常需要将其连接到一个服务,以扩展应用程序的功能,比如用于持久化数据的数据库,我们可以称之为服务绑定。在IBM Cloud Code Engine中开发应用程序和批处理作业时,可以绑定IBM Cloud目录中提供的各种服务,比如数据库、AI或机器学习和分析服务,后续所有支持IAM的IBM云服务都能提供给代码引擎绑定和调用。 想想如何在“vanilla Kubernetes”中部署应用程序和批处理作业。
如果想将你的应用绑定到公共云中的服务,通常你必须做以下事情:
1. 提供服务实例并获取服务凭证,如URL、用户名和密码。 2. 复制服务凭据。 3. 在Kubernetes中创建一个ConfigMap和Secret来持久化服务凭证。 4. 在部署应用程序时挂载Config文件和Secret。
可以想象,如果有多个应用程序和服务,那么配置和维护应用程序和服务之间的绑定关系可能是一个冗长而低效的过程。手动复制和编辑YAML文件来定义绑定信息是容易出错的,并且可能导致难以调试的失败。IBM Cloud Code Engine中的服务绑定的目的是使您更容易将应用程序绑定到IBM Cloud Catalog中的服务。IBM Cloud Code Engine中的服务绑定提供了以下功能:
检索IBM Cloud中的现有服务实例,如果服务凭证不存在,则创建服务凭证。
检索服务凭证,并将其作为机密直接保存在IBM Cloud Code Engine项目中。
将秘钥自动注入选定的应用程序中。
提供两种服务凭据格式:JSON字符串和普通环境变量。
IBM云代码引擎服务绑定是建立在开源技术之上的,包括IBM Cloud Operator和Red Hat OpenShift Service Binding Operator。
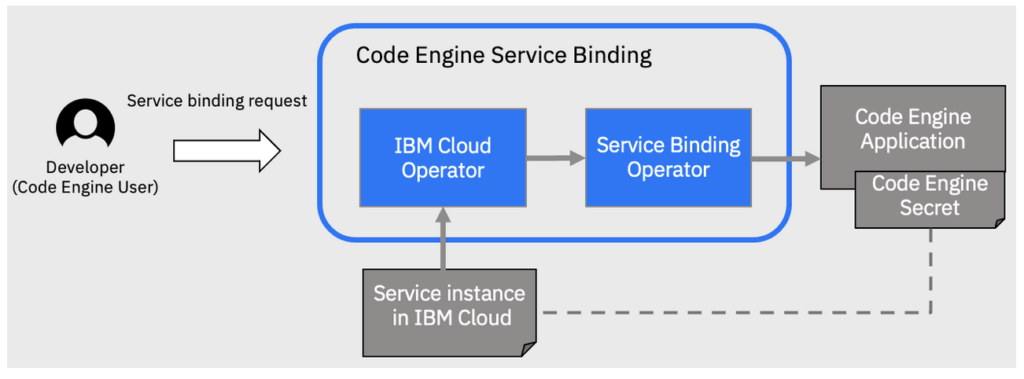
如上图所示,IBM Cloud Operator帮助连接到IBM Cloud中的服务实例,创建和接收服务实例凭据,并作为机密保存在IBM Cloud Code Engine项目中。OpenShift服务绑定操作符将秘钥注入到用户的应用程序中,并持久化服务实例与应用程序之间的关系。
接下来我们来看一下如何在IBM Cloud引擎代码中使用服务绑定。引擎代码服务绑定为开发人员提供了简单的CLI体验,在创建服务实例和应用时,可以使用一个CLI命令将服务实例和应用绑定在一起。代码引擎服务绑定还提供CLI命令来查询哪些服务实例绑定到应用程序,以及解除服务实例的绑定,用户拥有服务绑定的完整生命周期控制。例如,CLI命令
ibmcloud code-engine application bind --name servicebinding-helloworld --service-instance language-translator
在IBM Cloud Code Engine中将IBM Cloud语言翻译服务实例与servicebinding-helloworld应用程序绑定,环境变量被注入到应用程序中,其中包括服务凭证。说起服务凭证,很多人不了解,其实就是IBM Cloud上一套应用和服务直接连接的认证和授权机制,显示为一个JSON对象,绑定后将添加到应用程序或作业环境中,下面就是一个对象存储服务的凭证示例:
{
"apikey": "xxxxxxx",
"endpoints": "https://control.cloud-object-storage.cloud.ibm.com/v2/endpoints",
"iam_apikey_description": "Auto-generated for key 1d3eb853-4ef1-4d8c-78cf-d2630d872a82",
"iam_apikey_name": "my-object-storage-codeengine-credential",
"iam_role_crn": "crn:v1:bluemix:public:iam::::serviceRole:Writer",
"iam_serviceid_crn": "crn:v1:bluemix:public:iam-identity::a/1176a104ad4241e6b0aa82ed0b60c15c::serviceid:ServiceId-c3081ceb-7ae8-4769-a219-49403c474cc7",
"resource_instance_id": "crn:v1:bluemix:public:cloud-object-storage:global:a/1176a104ac4241e6b0cb82ed0b60c15c:11179bc4-3736-4777-9c8e-d330a450c85b::"
}