SwiftUI之声音识别
配合MachineLearning功能,判断说话的人是男性还是女性。需要实现这个功能,首先需要有MachineLearning模块,即已经训练过的数据。
苹果自带了CreateML工具,可以自己训练图片,文字,声音,甚至图表,关键在于收集格式合适以及数量可观的数据。
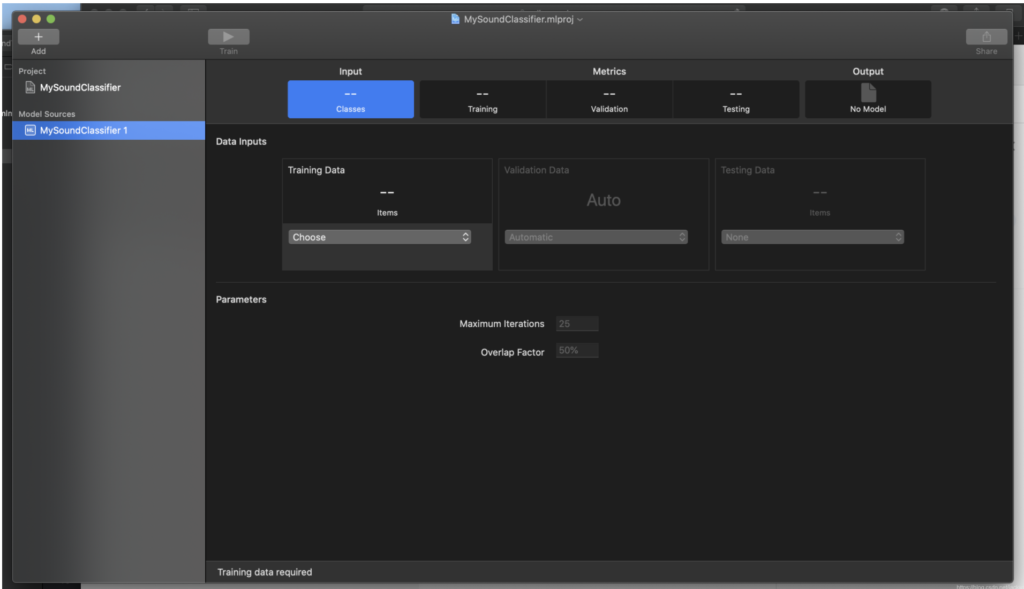
上图是训练音频的软件,使用方法很简单,类似于文本训练,通过文件夹区分男女声,然后在文件夹下放置搜集的男女声音频文件,为了准确性,可以将文件分类为训练用,校验用,以及测试用。即分成各种文件夹,而音频文件越多越好。
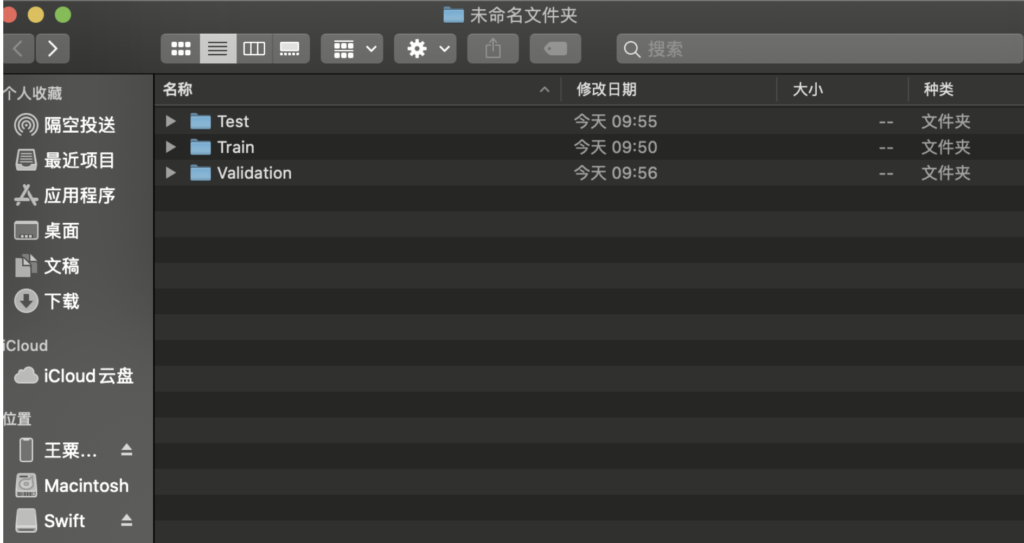
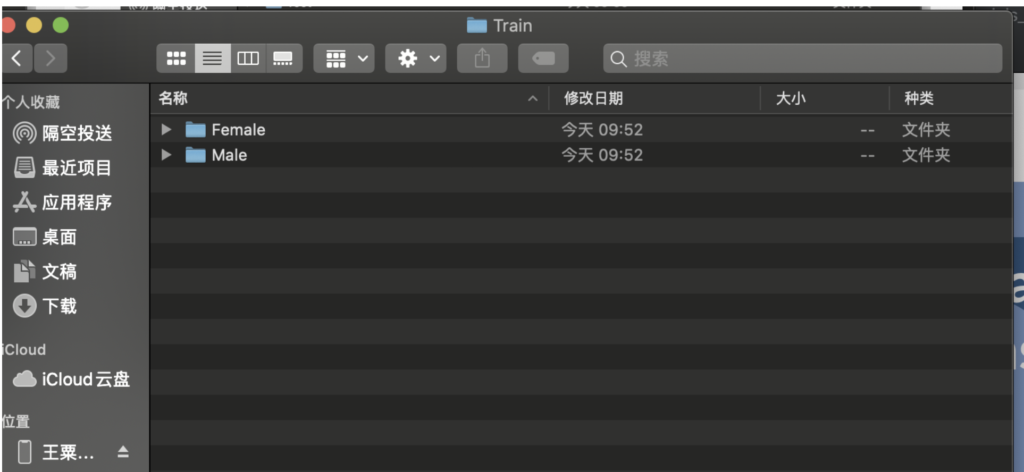
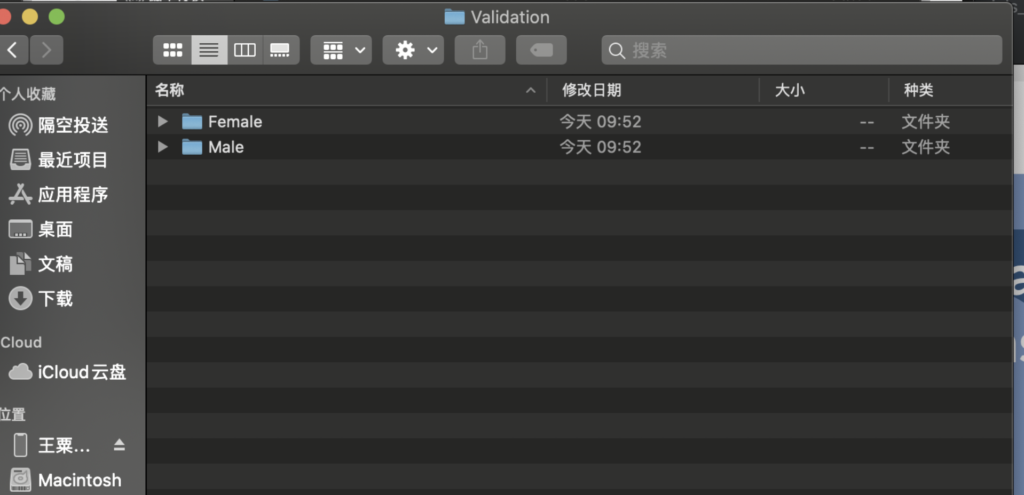
然后将文件路径放到训练工具CreateML中
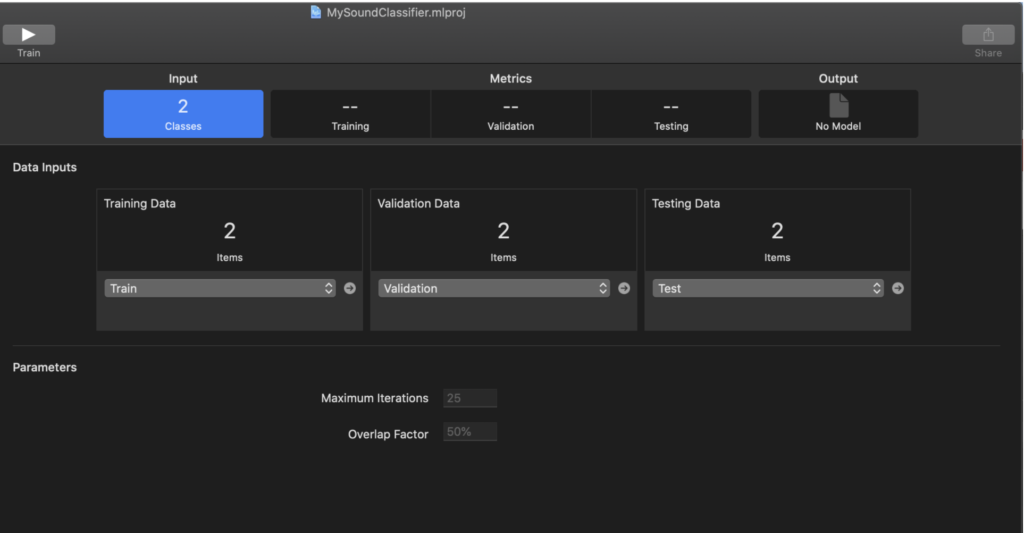
点击▶️,训练即可。训练后的模块准确性跟很多东西有关,用于训练的文件越多自然越好。

从Output中直接拖出训练好的模块,即可放入工程中。
以上只是简单介绍制作方法。
当模块拖到工程后,如图
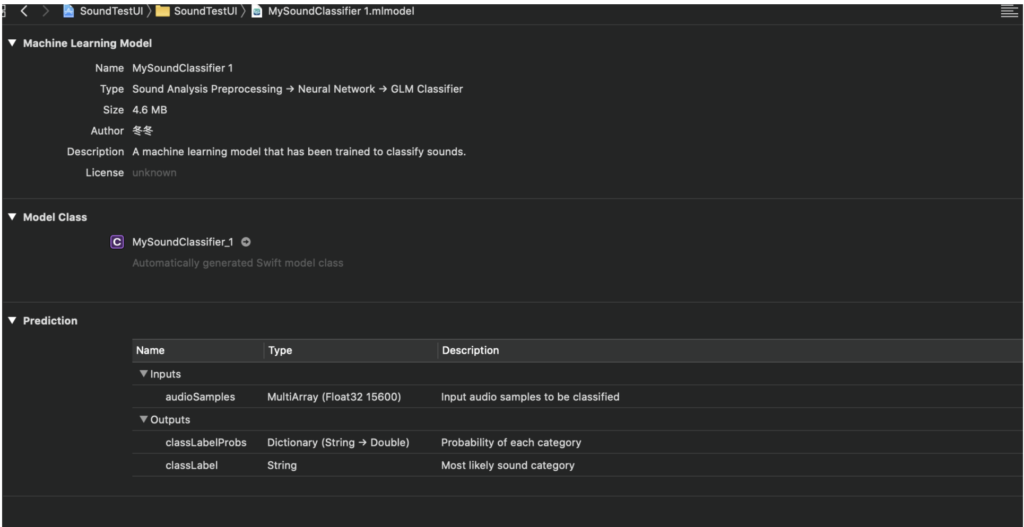
Inputs为我们需要输入模块的内容,即音频样本(audioSamples),而模块会输出该样本最可能的分类及可能性比例。
因为需要用到音频获取以及声音分析,所以首先
定义一个ObservableObject类型变量
class testMessage: ObservableObject{
@Published var message = "Nothing"
}
因为需要在不同的视图内传递数据,使用了protocol以及notification两种方式传递数据
在contentView中添加以下变量
//另一种数据传递方式测试用
@State var message = "Nothing"
@ObservedObject var myMessage = testMessage()
//AVEngine
private let audioEngine = AVAudioEngine()
//声音识别模块
private var soundClassifier = MySoundClassifier 1()
var inputFormat: AVAudioFormat!
var analyzer: SNAudioStreamAnalyzer!
var resultsObserver = ResultsObserver()
let analysisQueue = DispatchQueue(label: "dongdong")
初始化函数
init(){
resultsObserver.delegate = self
inputFormat = audioEngine.inputNode.inputFormat(forBus: 0)
analyzer = SNAudioStreamAnalyzer(format: inputFormat)
}
启动audio函数
func startAudioEngine() {
do {
let request = try SNClassifySoundRequest(mlModel: soundClassifier.model)
try analyzer.add(request, withObserver: resultsObserver)
} catch {
print("Unable to prepare request: \(error.localizedDescription)")
return
}
audioEngine.inputNode.installTap(onBus: 0, bufferSize: 8192, format: inputFormat) { buffer, time in
self.analysisQueue.async {
self.analyzer.analyze(buffer, atAudioFramePosition: time.sampleTime)
}
}
do{
try audioEngine.start()
}catch( _){
print("error in starting the Audio Engin")
}
}
定义procotol函数内容
数据传递
func displayPredictionResult(identifier: String, confidence: Double) {
DispatchQueue.main.async {
//self.myMessage.message = ("Recognition: \(identifier)\nConfidence \(confidence)")
self.myMessage.message = self.translateString(identifier: identifier)
//print(self.myMessage.message)
}
}
因为模块输出的内容比较单一且训练的时候是英文分类,所以做个简单的处理
func translateString(identifier: String) -> String{
switch identifier{
case "male":
return "男生⛹️👱🏼♂️"
default:
return "女生👩🏻🦳💄"
}
}
在ContentView的所有定义之外,定义类,参考苹果官网对于sound介绍

class ResultsObserver: NSObject, SNResultsObserving {
var delegate: GenderClassifierDelegate?
func request(_ request: SNRequest, didProduce result: SNResult) {
guard let result = result as? SNClassificationResult,
let classification = result.classifications.first else { return }
class ResultsObserver: NSObject, SNResultsObserving {
var delegate: GenderClassifierDelegate?
func request(_ request: SNRequest, didProduce result: SNResult) {
guard let result = result as? SNClassificationResult,
let classification = result.classifications.first else { return }
// Determine the time of this result.
let formattedTime = String(format: "%.2f", result.timeRange.start.seconds)
print("Analysis result for audio at time: \(formattedTime)")
let confidence = classification.confidence * 100.0
delegate?.displayPredictionResult(identifier: classification.identifier, confidence: confidence)
//使用通知传递数据,但是数据只能为[Hasable:Any?]格式
//必须Dispathcqueue
DispatchQueue.main.async {
NotificationCenter.default.post(name: NSNotification.Name("ForMyTest"), object: nil,userInfo: ["性别": classification.identifier,"概率":String(confidence)])
}
}
}
以上代码基本和苹果官网一致,不同之处有协议方式传递数据
delegate?.displayPredictionResult(identifier: classification.identifier, confidence: confidence)
然后测试通过同志传递数据用于测试内容
DispatchQueue.main.async {
NotificationCenter.default.post(name: NSNotification.Name("ForMyTest"), object: nil,userInfo: ["性别": classification.identifier,"概率":String(confidence)])
}
然后加入协议,所有内容之外面
protocol GenderClassifierDelegate {
func displayPredictionResult(identifier: String, confidence: Double)
}
终于进入body部分
简单的代码,见注释
var body: some View {
Text(myMessage.message)
.onAppear{
self.startAudioEngine()
}
.onTapGesture {
self.message = "what"
}
//此处接受通知,处理数据,此时@state message也能更改了
//当有通知内容传递过来后,处理类容,打印出结果.
.onReceive(NotificationCenter.default.publisher(for: Notification.Name("ForMyTest"))){
label in
//print(label)
if let new = label.userInfo as? [String:String]
{
self.message = new["性别"]!
print(self.message)
}
}
}
通知传递数据方式相对步骤少一些,此处没有现实出来,只是打印了一下,与protocol方式结果完全一致,无问题,可参考备用.
然后运行程序,然后程序就挂了
因为还没有开麦克风权限,如图,info.list中

然后再运行
识别出声音类型

非常简单的使用到了ML的小程序,苹果自带的CreateML功能还是很强大的,支持很多类型,如
但是在训练模块时,真正深入ML时,CreateML则感觉功能有些不够了,这时候还是的用Python了。