🔥 开篇:一个让人困惑的问题
你写的SQL语句为什么这么慢?为什么有时候加了索引还是不走?为什么GROUP BY要放在WHERE后面?这些问题的答案都藏在SQL的执行顺序里!
作为程序员,你是否遇到过这样的困惑:
-- 这个查询为什么报错? SELECT name, age, COUNT(*) as cnt FROM users WHERE age > 18 AND cnt > 5 GROUP BY name;
明明逻辑很清楚:查找年龄大于18岁,且统计数量大于5的用户,为什么MySQL却告诉你 cnt 字段不存在?
答案就在SQL的执行顺序里!今天我们就来揭开这个神秘的面纱。
📋 SQL执行顺序全景图
让我们先看一个完整的SQL查询语句:
SELECT DISTINCT column_name, COUNT(*) FROM table_name t1 JOIN table_name2 t2 ON t1.id = t2.user_id WHERE condition GROUP BY column_name HAVING COUNT(*) > 1 ORDER BY column_name LIMIT 10 OFFSET 20;
你以为MySQL是按照你写的顺序执行的吗?大错特错!
MySQL的真实执行顺序是这样的:
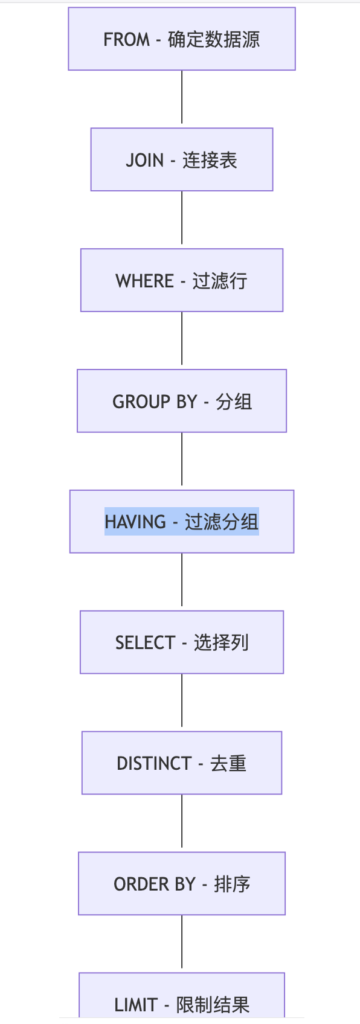
🎯 详解每个执行步骤
- 第1步:FROM – 找到数据源
FROM users u
MySQL首先要知道数据从哪里来,所以第一步是确定表和给表起别名。
这一步做了什么?
- • 找到指定的表
- • 为表创建别名(如果有的话)
- • 准备读取数据
- 第2步:JOIN – 连接多张表
FROM users u JOIN orders o ON u.id = o.user_id
如果查询涉及多张表,MySQL会根据JOIN条件将它们连接起来。
常见的JOIN类型:
- •
INNER JOIN:只返回两表都有的数据 - •
LEFT JOIN:返回左表所有数据,右表没有则为NULL - •
RIGHT JOIN:返回右表所有数据,左表没有则为NULL
-- 示例:查询用户及其订单信息 SELECT u.name, o.order_date FROM users u LEFT JOIN orders o ON u.id = o.user_id;
- 第3步:WHERE – 过滤不需要的行
WHERE u.age > 18 AND u.status = 'active'
在分组之前,MySQL会根据WHERE条件过滤掉不符合条件的行。
注意:WHERE不能使用聚合函数!
-- ❌ 错误写法 SELECT name, COUNT(*) as cnt FROM users WHERE COUNT(*) > 5; -- 报错! -- ✅ 正确写法 SELECT name, COUNT(*) as cnt FROM users GROUP BY name HAVING COUNT(*) > 5; -- 用HAVING
- 第4步:GROUP BY – 数据分组
GROUP BY u.department, u.position
将数据按照指定的列进行分组,为聚合函数做准备。
分组示例:
-- 按部门统计员工数量 SELECT department, COUNT(*) as employee_count FROM users WHERE status = 'active' GROUP BY department;
- 第5步:HAVING – 过滤分组
HAVING COUNT(*) > 10
HAVING是对分组后的结果进行过滤,可以使用聚合函数。
WHERE vs HAVING 对比:
| 条件 | WHERE | HAVING |
| 执行时机 | 分组前 | 分组后 |
| 过滤对象 | 行 | 分组 |
| 能否使用聚合函数 | ❌ | ✅ |
-- 找出订单数量超过10的用户 SELECT user_id, COUNT(*) as order_count FROM orders WHERE order_status = 'completed' -- 先过滤已完成的订单 GROUP BY user_id HAVING COUNT(*) > 10; -- 再过滤订单数量超过10的用户
- 第6步:SELECT – 选择要显示的列
SELECT u.name, u.age, COUNT(o.id) as order_count
到了这一步,MySQL才开始处理SELECT子句,选择要显示的列。
这就是为什么WHERE不能使用SELECT中定义的别名!
-- ❌ 错误:WHERE执行在SELECT之前 SELECT name, age * 2 as double_age FROM users WHERE double_age > 50; -- double_age还不存在! -- ✅ 正确写法 SELECT name, age * 2 as double_age FROM users WHERE age * 2 > 50;
- 第7步:DISTINCT – 去除重复
SELECT DISTINCT department FROM users;
如果使用了DISTINCT,MySQL会去除重复的行。
- 第8步:ORDER BY – 排序
ORDER BY u.age DESC, u.name ASC
对最终结果进行排序。
ORDER BY可以使用SELECT中的别名:
-- ✅ 正确:ORDER BY执行在SELECT之后 SELECT name, age * 2 as double_age FROM users ORDER BY double_age DESC; -- 可以使用别名
- 第9步:LIMIT – 限制结果数量
LIMIT 10 OFFSET 20
最后一步,限制返回的结果数量。
💡 实战案例:执行顺序的应用
让我们通过一个实际案例来理解执行顺序:
-- 需求:查询每个部门中年龄大于25岁的员工数量,
-- 只显示员工数量超过5人的部门,按员工数量降序排列
SELECT
department,
COUNT(*) as employee_count
FROM users
WHERE age > 25
GROUP BY department
HAVING COUNT(*) > 5
ORDER BY employee_count DESC;
执行过程分析:
- 1. FROM users – 确定数据源
- 2. WHERE age > 25 – 过滤年龄大于25的员工
- 3. GROUP BY department – 按部门分组
- 4. HAVING COUNT(*) > 5 – 过滤员工数量超过5的部门
- 5. SELECT department, COUNT(*) – 选择要显示的列
- 6. ORDER BY employee_count DESC – 按员工数量降序排列
🚀 性能优化技巧
了解执行顺序后,我们可以进行一些性能优化:
1. WHERE条件优化
-- ❌ 低效:先JOIN再过滤 SELECT u.name, o.order_date FROM users u JOIN orders o ON u.id = o.user_id WHERE u.status = 'active'; -- ✅ 高效:先过滤再JOIN SELECT u.name, o.order_date FROM (SELECT * FROM users WHERE status = 'active') u JOIN orders o ON u.id = o.user_id;
2. 索引利用
-- 为WHERE条件创建索引 CREATE INDEX idx_user_status_age ON users(status, age); -- 查询会自动使用索引 SELECT * FROM users WHERE status = 'active' AND age > 25;
3. 避免不必要的排序
-- 如果不需要排序,不要使用ORDER BY SELECT department, COUNT(*) FROM users GROUP BY department; -- 而不是 SELECT department, COUNT(*) FROM users GROUP BY department ORDER BY department; -- 不必要的排序
🔧 常见错误及解决方案
错误1:在WHERE中使用聚合函数
-- ❌ 错误 SELECT department, COUNT(*) as cnt FROM users WHERE COUNT(*) > 5; -- ✅ 正确 SELECT department, COUNT(*) as cnt FROM users GROUP BY department HAVING COUNT(*) > 5;
错误2:在WHERE中使用SELECT别名
-- ❌ 错误 SELECT name, salary * 12 as annual_salary FROM employees WHERE annual_salary > 100000; -- ✅ 正确 SELECT name, salary * 12 as annual_salary FROM employees WHERE salary * 12 > 100000;
错误3:GROUP BY与SELECT不匹配
-- ❌ 错误:SELECT中的列必须在GROUP BY中,或者是聚合函数 SELECT department, name, COUNT(*) FROM users GROUP BY department; -- ✅ 正确 SELECT department, COUNT(*) FROM users GROUP BY department;
📊 执行顺序速记口诀
为了帮助大家记忆,我总结了一个口诀:
"从哪连什么,分组再筛选,选择去重排,最后限数量"
- • 从哪 – FROM
- • 连什么 – JOIN
- • 什么 – WHERE
- • 分组 – GROUP BY
- • 再筛选 – HAVING
- • 选择 – SELECT
- • 去重 – DISTINCT
- • 排 – ORDER BY
- • 最后限数量 – LIMIT
🏆 实战练习
现在让我们做一个小练习,看看你是否真的理解了执行顺序:
-- 题目:下面这个查询的执行顺序是什么?
SELECT
DISTINCT u.department,
AVG(u.salary) as avg_salary
FROM users u
JOIN departments d ON u.dept_id = d.id
WHERE u.status = 'active' AND d.budget > 100000
GROUP BY u.department
HAVING AVG(u.salary) > 50000
ORDER BY avg_salary DESC
LIMIT 5;
答案:
- 1. FROM users u – 确定主表
- 2. JOIN departments d ON u.dept_id = d.id – 连接部门表
- 3. WHERE u.status = ‘active’ AND d.budget > 100000 – 过滤活跃用户和预算充足的部门
- 4. GROUP BY u.department – 按部门分组
- 5. HAVING AVG(u.salary) > 50000 – 过滤平均工资超过5万的部门
- 6. SELECT DISTINCT u.department, AVG(u.salary) – 选择部门和平均工资
- 7. DISTINCT – 去重(虽然这里GROUP BY已经保证唯一性)
- 8. ORDER BY avg_salary DESC – 按平均工资降序排列
- 9. LIMIT 5 – 只取前5条记录