转载:小红书 AI产品赵哥
前言🔖
这两年 AI 爆火,大家应该听得最多的一个词就是 token 了吧?token 到底是什么?好像懂了,又好像没全懂,比如说:
- 为什么你的年度报告 PDF 没法直接扔给 ChatGPT 让它总结?
- 为什么你只是让 AI 帮你润色一段文字,API 账单却意外地高?
- 为什么有时候 AI 的回答像个高材生,有时候又像个记忆只有 7 秒的金鱼?
所有这些问题的根源、所有大语言模型(LLM)的秘密,都起始于 “Token” 这个小小的单位。今天,咱们一起来看看这个小玩意儿到底是个啥?
准备好了吗?咱们发车了!!
一、AI 为什么需要 Token?(它不认识字啊!)🔖
在聊 Token 之前,咱必须先明白一个事实:计算机只能看懂二进制(0 和 1)。它不理解 “爱” 的温暖,不理解 “悲伤” 的沉重,它甚至连 “你”、“我”、“他” 这三个最简单的汉字都看不懂。在它眼里,所有非数字的东西,都是天书。
所以,当我们要让 AI 处理人类的语言时,摆在所有科学家面前的一个挑战就是:如何把我们丰富多彩、充满感性的文字,翻译成计算机能理解的数字?
这个翻译过程,在 AI 领域被称为文本表示(Text Representation)。
早期的笨办法:独热编码(One-Hot Encoding)
在 AI 的石器时代,科学家们想出了一个简单粗暴的办法,叫独热编码(One-Hot Encoding)。
想象我们有一个小词典,里面只有五个词:【猫,狗,追,跑,叫】。
独热编码会给每个词一个独一无二的身份证(id):
猫: [1, 0, 0, 0, 0] 狗: [0, 1, 0, 0, 0] 追: [0, 0, 1, 0, 0] …… 以此类推。
这个方法有两个问题:
- 太占地方:真实世界的词汇有几十万个,那表示一个词就需要一个几十万长度、但只有一个 1 的列表!这在存储和计算上是个灾难。
- 毫无意义:在这种表示下,“猫” 和 “狗” 的数学关系,跟 “猫” 和 “追” 的关系,是完全一样的。它无法表达出 “猫” 和 “狗” 都是动物,而 “追” 是一个动作。
独热编码就像是给每个人一个房间号,但我们从房间号上看不出这个人是男是女、是高是矮。我们需要一种更聪明的 “身份证”,这个 “身份证” 本身就要包含持有者的信息。
于是,词嵌入(Word Embedding) 一声炸雷,诞生了。它用一个稠密的、低维的向量(比如一个 300 长度的浮点数列表)来表示一个词。而 Token,则是这个更先进世界里的基本操作单位。
所以,Token 存在的根本原因,就是为了充当人类语言和计算机数字世界之间的翻译官和通用接口。
二、Token 是咋被 “切” 出来的?🔖
我们现在知道,AI 拿到一句话,第一步是把它切成一堆 Tokens。这个过程叫分词(Tokenization)。
一个核心的误解需要再次强调:Token ≠ 一个单词(Word)。那它到底是怎么切的呢?为什么不直接按单词切?
大白话:Token 是 AI 语言世界里的乐高积木。而分词的过程,就像一个聪明的工人,把一整块木头(一句话)分解成一堆标准化的、可复用的乐高零件。
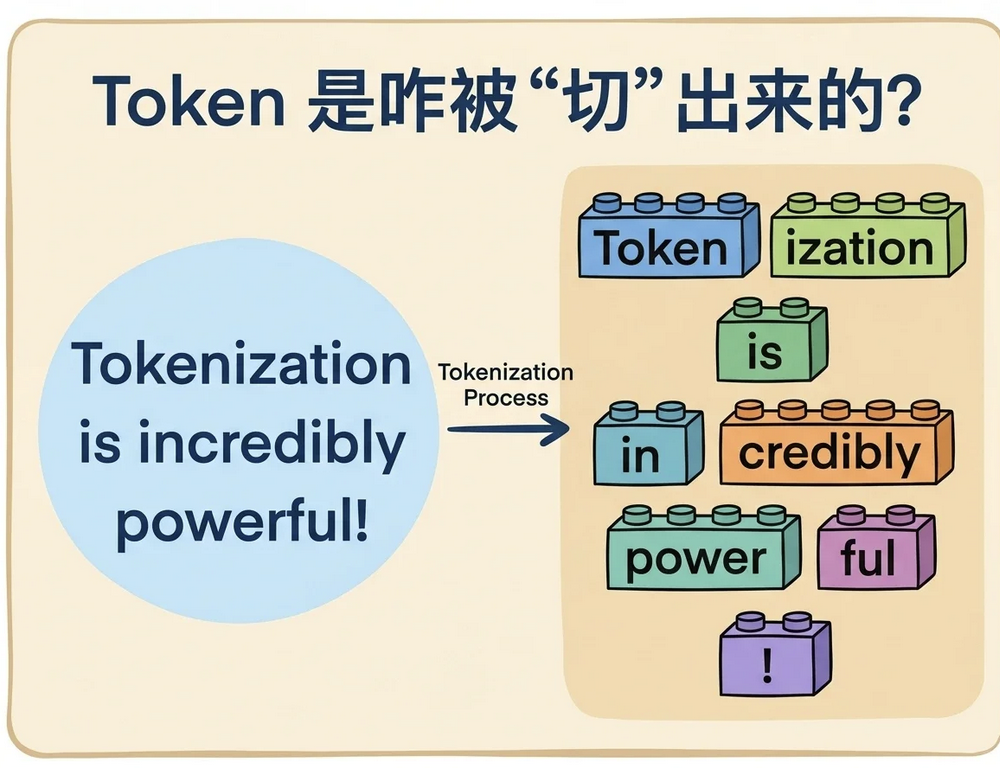
AI 之所以不直接用单词,而是用这种更小的 子词(Subword) 作为积木,是为了解决两个大难题:
- 词汇表爆炸问题:
- 问题:语言中有无数的词形变化,比如
love,loves,loving,lovely,beloved。如果都当成新词,AI 的词典(Vocabulary)会大到无法管理。 - Token 的解决方案:它会把这些词拆成更基础的 “积木”,比如
love、s、ing、ly、be、d。这样,它的词典里只需要存这些基本零件,就能拼凑出整个 “love” 家族。这就像乐高不需要为每一种汽车都开一个模具,只需要生产轮子、底盘、砖块等通用零件就够了。
- 问题:语言中有无数的词形变化,比如
- 未登录词(OOV – Out-of-Vocabulary)问题:
- 问题:语言是活的,每天都有新词(如 “AIGC”)、网络梗(如 “emo 了”)、品牌名、甚至是拼写错误。如果按单词来,AI 一看到不认识的词就彻底歇菜了。
- Token 的解决方案:它可以把不认识的词,尽可能拆成它认识的更小的部分。比如,它可以把
AIGC拆成A、I、G、C四个字母积木。虽然它可能不懂AIGC的整体含义,但至少它能处理它,而不会卡住。这让 AI 面对未知世界时,拥有了 “降级处理” 的能力,大大增强了模型的鲁棒性。
🔹分词器(Tokenizer)的小秘密 —— BPE 算法简介
这个 “切词” 的过程不是乱切的。它背后有一套非常聪明的算法,最经典的一种叫 BPE(Byte-Pair Encoding)。
你可以把 BPE 的训练过程想象成一个找朋友游戏:
- 开始:把所有文本都拆成最最基础的单元,比如单个字母。
- 第一轮:在文本里扫一遍,看看哪两个相邻的字母组合出现得最频繁。比如发现
e和r总是黏在一起出现。 - 合并:好,那我们就把
er合并成一个新的、更长的 “积木”er,把它加入我们的 “乐高零件库”。 - 第二轮:再扫一遍,又发现
er和s经常一起出现,组成ers。 - 再合并:把
ers也加入零件库。……这个过程不断重复,直到零件库的大小达到我们设定的阈值(比如 5 万个)。
最终,这个零件库里,既有单个的字母,也有高频的音节,还有非常常见的短词。当分词器拿到一个新词时,它就会用这个零件库里的积木,以最长的优先的原则,来搭建这个词。
三、Token 的双重身份 —— “货币” 与 “记忆” 🔖
理解了 Token 是乐高积木,这只是第一步。在实际应用中,它更重要的两个身份,直接关系到你的成本和 AI 的能力。
🔹身份一:Token 是 AI 世界的硬通货
当你在 ChatGPT 官网免费聊天时,你感受不到这点。但一旦你踏入更专业的领域,使用 API 接口来开发应用,或者使用那些背后调用了 GPT 模型的工具时,你会发现,你的每一次呼吸(和 AI 的互动),都是在烧钱!!!
而计费的唯一单位,就是 Token。
这个计费是双向的,而且有一个巨大的陷阱:
- 输入 Token(Input/Prompt Tokens):你发给 AI 的每一句话、每一个字符,都会被切成 Tokens,然后按量计费。你说话,要花钱。
- 输出 Token(Output/Completion Tokens):AI 为你生成的每一个字、每一个标点,也是按 Token 计费的。AI 说话,你买单。
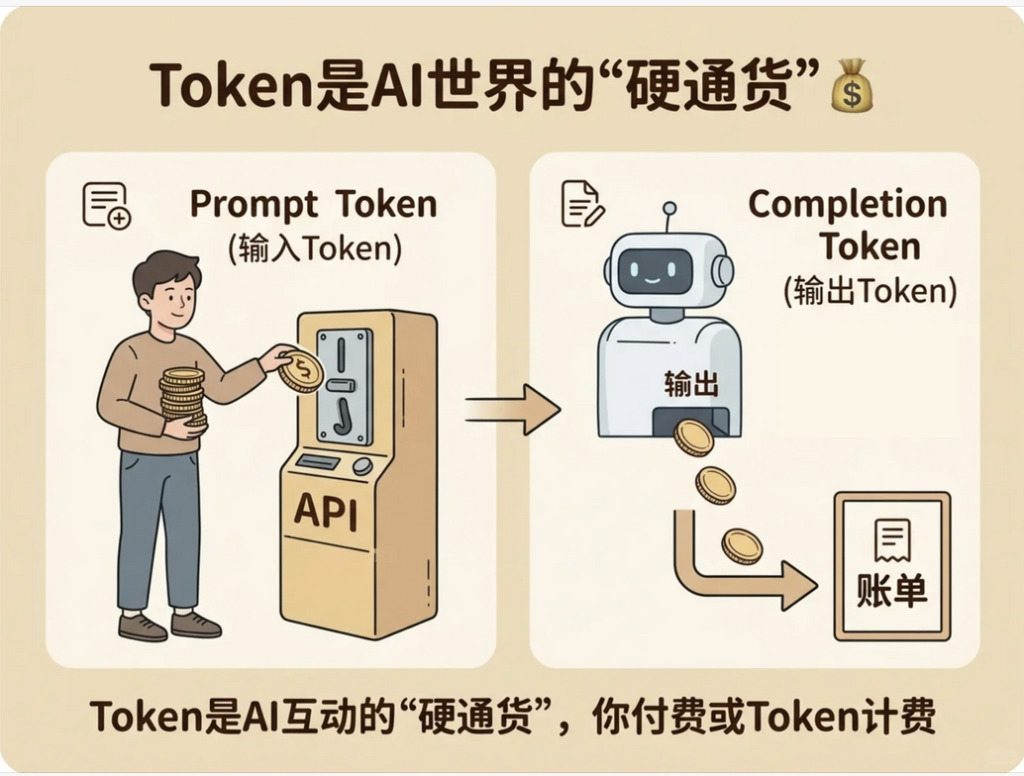
让我们看一个真实的商业场景:
假设你用 GPT-4 的 API 做了一个电商客服机器人。一个顾客发来一段 500 字的长篇抱怨(比如包含订单号、商品问题、情绪发泄),这可能就是 800 个输入 Tokens。
你的机器人为了安抚他,生成了一段 1000 字的、包含道歉、解决方案、后续步骤的回复,这可能就是 1500 个输出 Tokens。
仅仅这一次交互,你就消耗了 800 + 1500 = 2300 个 Tokens。如果 GPT-4 的价格是每 1000 个输入 Token 0.03 美元,每 1000 个输出 Token 0.06 美元,那么这次服务的成本就是 (800/1000)*0.03 + (1500/1000)*0.06 = 0.024 + 0.09 = 0.114 美元。
看起来不多,但如果你的应用每天有 1 万次这样的交互呢?成本会迅速累积到一个惊人的数字。
因此,学会像吝啬鬼一样计算和优化 Token,是每一个 AI 应用开发者的必修课。
🔹身份二:Token 是 AI 大脑的内存条
这是 Token 另一个决定 AI 能力上限的核心身份。它解释了 AI 为什么会健忘。
所有的大语言模型,都有一个叫做 上下文窗口(Context Window) 的东西。这个窗口的容量,就是用 Token 来衡量的。
- GPT-3.5-turbo:有 4k 或 16k Tokens 的版本。
- GPT-4:有 8k、32k 甚至 128k 的版本。
- Gemini 1.5 Pro:达到了惊人的 1M(100 万)Tokens。
你可以把上下文窗口想象成 AI 大脑里一块用于短期思考的草稿纸。AI 是 ** 无状态(Stateless)** 的。这意味着它本身没有任何记忆。你和它的每一次对话,背后都发生了这样的事:
1.你:“你好,我叫小明。”(这句话被切成 Tokens,发给 AI) 2.AI:“你好小明,很高兴认识你。” 3.你:“我喜欢蓝色。” (为了让 AI 知道 “我” 是谁,你的程序会把 **【你的第一句话 + AI 的第一句回答 + 你的第二句话】** 打包成一个更长的 Token 序列,再次发给 AI) 4.AI:“蓝色是个很棒的颜色。” 5.……
看到了吗?为了维持对话的连贯性,每一次交互,都需要把到目前为止的整个草稿纸上的内容全部重新发送一遍!
当草稿纸写满了(比如超过了 4096 个 Tokens),AI 为了能写下新的内容,就必须把最开始写下的内容给擦掉。这就是它忘记你叫小明的原因。不是它笨,是它的草稿纸不够大了!
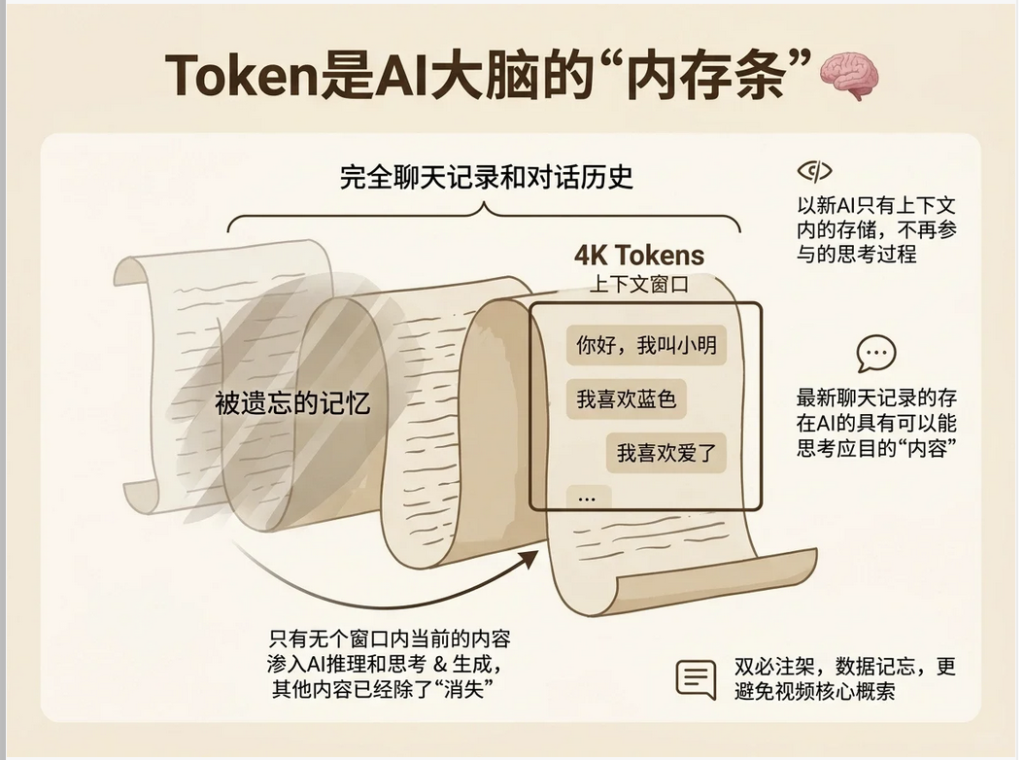
这个机制解释了很多现象:
- 为什么长对话后 AI 会变傻? 因为关键的初始设定和信息已经被挤出窗口了。
- 为什么 GPT-4 的 32k 版本能分析长篇报告? 因为它的草稿纸足够大,可以一次性把整篇报告(的大部分)都铺在上面进行思考。
- 为什么大窗口模型是未来的趋势? 因为更大的草稿纸意味着更强的长程记忆、更复杂的推理能力和更少的遗忘尴尬。
四、成为 “Token 管理大师” 的实用技巧🔖
理论的最终目的是为了实践。了解了 Token 的本质,我们就能从 “被动接受者” 变成 “主动操控者”。
🔹技巧一:精简的艺术 —— 如何节省你的 “Token 币”?
- 用 Markdown 写提示词:练习用最少的文字表达最清晰的意图。与其说 “我想让你帮我写一个关于…… 的介绍,要…… 风格,大概…… 字”,不如用结构化的格式:
1 # 角色: 资深营销文案 2 # 任务: 为XX产品写一篇小红书种草笔记 3 # 要求: 4 - 风格: 活泼、有网感 5 - 篇幅: 约500字 6 - 核心卖点: [要点1], [要点2] 7 - 格式: 包含emoji和hashtags
这种方式不仅清晰,而且通常比大段的自然语言描述更节省 Token。
- 上下文的断舍离:如果你要开始一个全新的话题,果断地新开一个聊天窗口。这相当于换一张干净的草稿纸,避免为之前无关的数千个 Token 对话记录支付历史债务。
- 为输出立规矩:明确告诉 AI 你想要的长度和格式。“请在 200 字以内回答”、“请用三点式总结”。这就像给一个话痨朋友说:“长话短说”,能有效控制输出成本。
🔹技巧二:记忆的魔法 —— 如何扩展 AI 的 “Token 内存”?
- 滚动总结(Rolling Summary):这是对抗小窗口遗忘症的利器。当你和 AI 进行长对话时,可以阶段性地让它总结:“请基于我们之前的对话,以 bullet points 的形式,总结一下我们已经确定的关键信息和下一步行动计划。” 然后,你可以把这个总结作为下一段长对话的前情提要,手动刷新 AI 的记忆。
- RAG(检索增强生成)—— AI 的外接硬盘:这是目前解决超长文本处理主流且强大的技术。当你需要 AI 基于一本几百页的书来回答问题时:
- 你做的不是把书塞给 AI,而是先把书的内容存入一个智能的外部数据库(向量数据库)。
- 当用户提问时,一个检索程序会先去数据库里找到和问题最相关的几个段落。
- 最后,把 “你的问题”+“这几个相关段落” 一起打包,作为上下文喂给 AI。
AI 需要处理的 Token 数量大大减少,但它却拥有了整个数据库的 “知识”,能力和记忆力都得到了无限扩展。
- 明智的投资 —— 选择合适的模型:不要用 “杀鸡用牛刀”。如果你的任务(如法律合同分析、长篇代码审查)天然需要长上下文,那么直接付费使用拥有更大窗口(如 GPT-4-128k)的模型,虽然单次成本高,但其带来的准确性和效率提升,可能远超你费尽心机去优化小窗口模型的总成本。
五、Token 的未来 —— 从文本到万物🔖
Token 的概念,并不仅限于文本。随着多模态 AI 的发展,万物皆可 Token 化的时代正在到来。
- 图像 Token:像 ViT(Vision Transformer)这样的模型,会把一张图片切成一个个固定大小的小方块(Patches),每个小方块就像一个视觉 Token。我们在之前的笔记里详细聊过 ViT。
- 语音 Token:语音信号可以被切分成一个个极短的音频片段,编码成声音 Token。
未来,AI 处理一个包含文字、图片和声音的复杂场景时,它的大脑里流淌的,将是一个由不同类型的 Token 组成的、统一的信息流。理解文本 Token,是你理解多模态未来的起点。
六、来来来,总结一下吧!🔖
- 身份一:建筑材料(乐高积木) 🧱
- 它是 AI 阅读的基本单位,通过子词分词解决了词汇爆炸和新词难题,是连接人类语言和机器数字的桥梁。
- 身份二:货币(硬通货) 💰
- 使用 API 的成本由双向 Token 决定。学会优化 Token,就是学会为你的 AI 应用降本增效。
- 身份三:内存(短期记忆草稿纸) 🧠
- 上下文窗口的容量由 Token 决定,这是 AI 会健忘的根本原因。学会管理上下文,就是学会如何驾驭 AI 进行长期、复杂的思考。