转载:小红书 AI产品赵哥
前言🔖
有没有觉得,我们生活在一个信息爆炸的时代?手机里 APP 上千个,衣柜里衣服几百件,想找个东西得翻半天。
其实,AI 也面临着同样的烦恼!在训练 AI 模型的时候,我们喂给它的数据,特征(也就是描述一个东西的属性)可能有成百上千个,这在术语里就叫高维数据。
数据维度太多,就像一个堆满杂物的房间,不仅乱,还找不着重点,甚至会让 AI 很懵逼!
这个时候,AI 语料的数据骚操作来了 ——降维(Dimensionality Reduction),就是教 AI 如何做一次彻底的数据断舍离,扔掉无用的信息,留下真正需要的。这不仅能让 AI 跑得更快,而且更聪明!
具体怎么做断舍离?大家准备好,咱们就发车了!!!
一、到底啥是 “维”?为啥要 “降”?🔖
在聊降维之前,我们得先搞懂两个基本问题。
🔹1. 维度(Dimension)到底是个啥?
别被吓到。在机器学习里,一个维度就是一个特征(Feature)。
举个栗子🪶:
我们想预测一套房子的价格。我们会收集哪些信息呢?
特征 1:面积(平方米) 特征 2:房间数(个) 特征 3:楼层 特征 4:离地铁站距离(米) 特征 5:房龄(年) …… 特征 100:小区绿化率(%)
这里,每一个特征(面积、房龄……)就是一个维度。如果我们收集了 100 个特征,那我们的数据就是 100 维的。是不是瞬间就理解了?
💡 维度就是描述一个事物的不同角度。
🔹2. 为啥非要降维?维度高不好吗?(维度灾难)
你可能会想,描述一个东西的特征越多,信息不就越全吗?AI 不就学得越好吗?
在一定程度上是这样。但当维度高到一定程度后,就会引发一场维度灾难(Curse of Dimensionality)。
这又是个听起来很可怕的词,但我们可以用一个比喻来理解它:
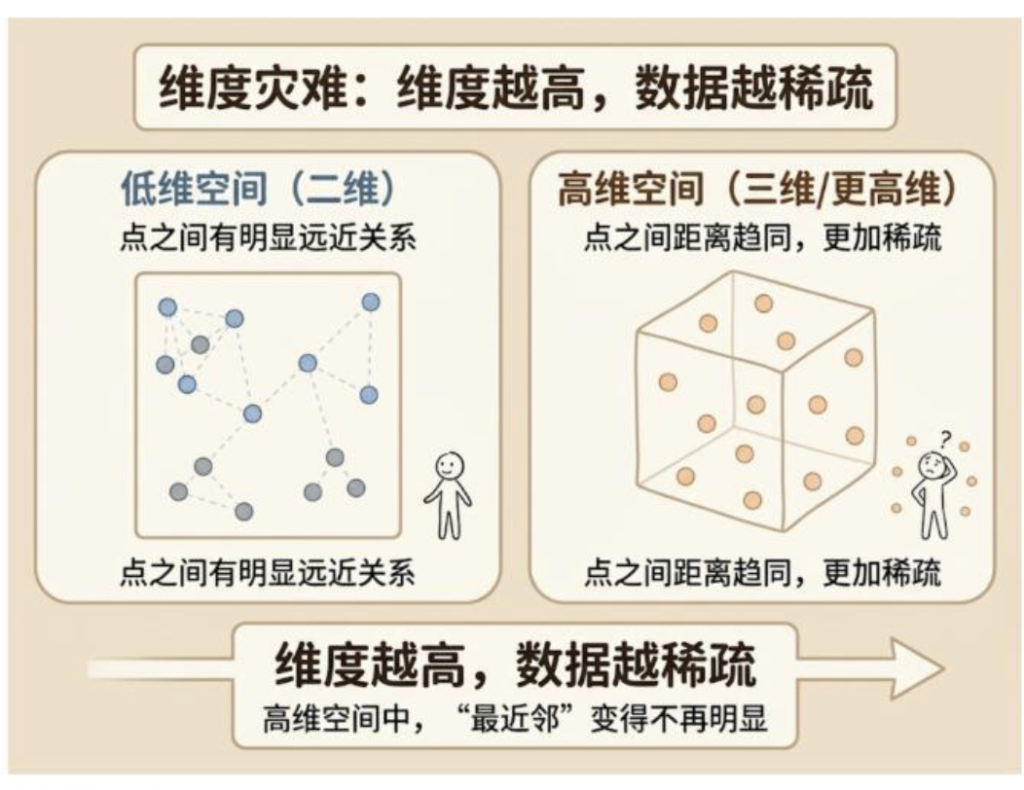
想象一下,你在一条一维的线上找朋友,很简单,就在你前后。
现在,你在一个二维的广场上找朋友,范围变大了,难度增加了点。
然后,你在一个三维的大楼里找朋友,你不仅要考虑前后左右,还要考虑楼上楼下,难度剧增。
再想象一下,在一个 1000 维的超空间里呢?
在高维空间里,所有的数据点都像是宇宙里孤独的星星,彼此之间的距离都变得非常遥远,而且都差不多远。
二、降维的两大流派🔖
知道了为什么要降维,那具体怎么操作呢?主要有两种思路,就像整理房间的两种方法。
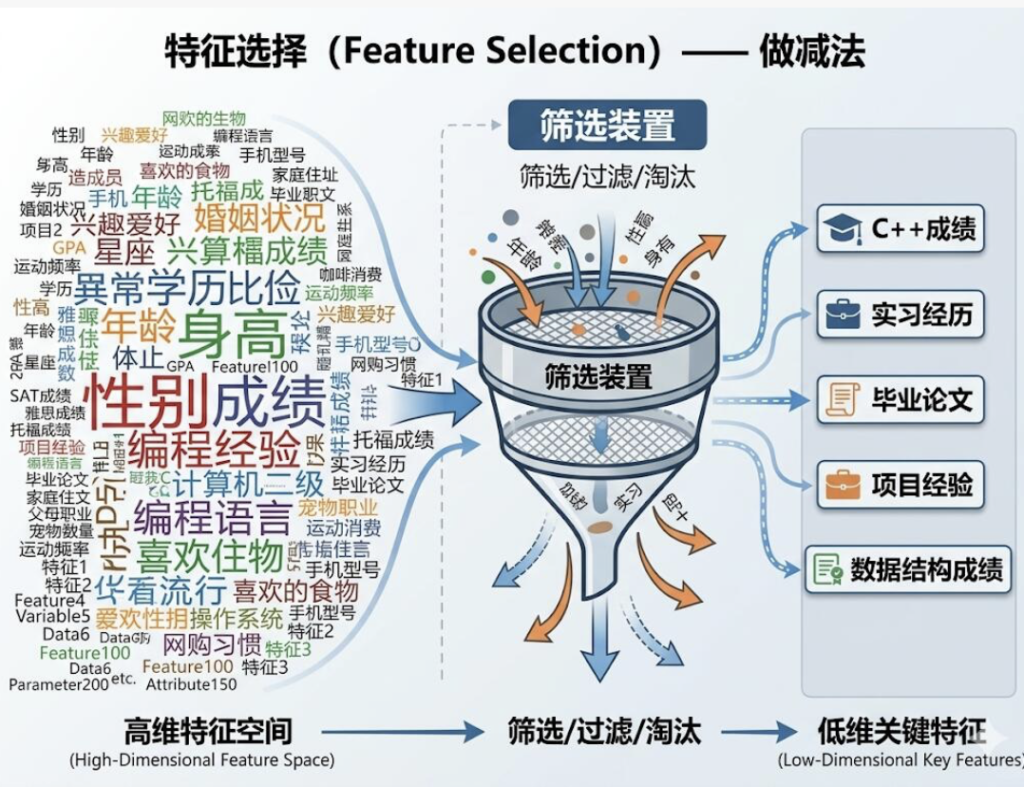
🔹流派一:特征选择(Feature Selection)—— 做减法
这是最直观的方法。就像你整理衣柜,发现有 200 件衣服,但常穿的就那 20 件。特征选择就是直接从原来的 200 个特征里,挑出最重要的 20 个,剩下的 180 个直接扔掉。
优点: 简单粗暴,保留了原始特征的物理意义。比如你最后留下了 “面积” 和 “房龄”,你很清楚它们代表什么。
缺点: 可能会扔掉一些看似无用但组合起来有用的信息,有点一刀切。
怎么扔呢?也有几种策略:
- 过滤法(Filter):先用统计学方法给每个特征打分(比如看它和房价的相关性),然后设定一个分数线,低于分数线的全部淘汰。就像海选,不合格的直接 pass。
- 包裹法(Wrapper):把特征选择的过程和模型训练包裹在一起。不断地尝试不同的特征组合,看哪种组合能让模型效果最好。这很有效,但计算量巨大,有点像是在搞题海战术。
- 嵌入法(Embedded):让模型在训练的时候,自己学会哪些特征重要,哪些不重要,顺便就把特征给选了。比如一些高级算法(Lasso 回归、决策树)天生就带这个功能,非常智能。
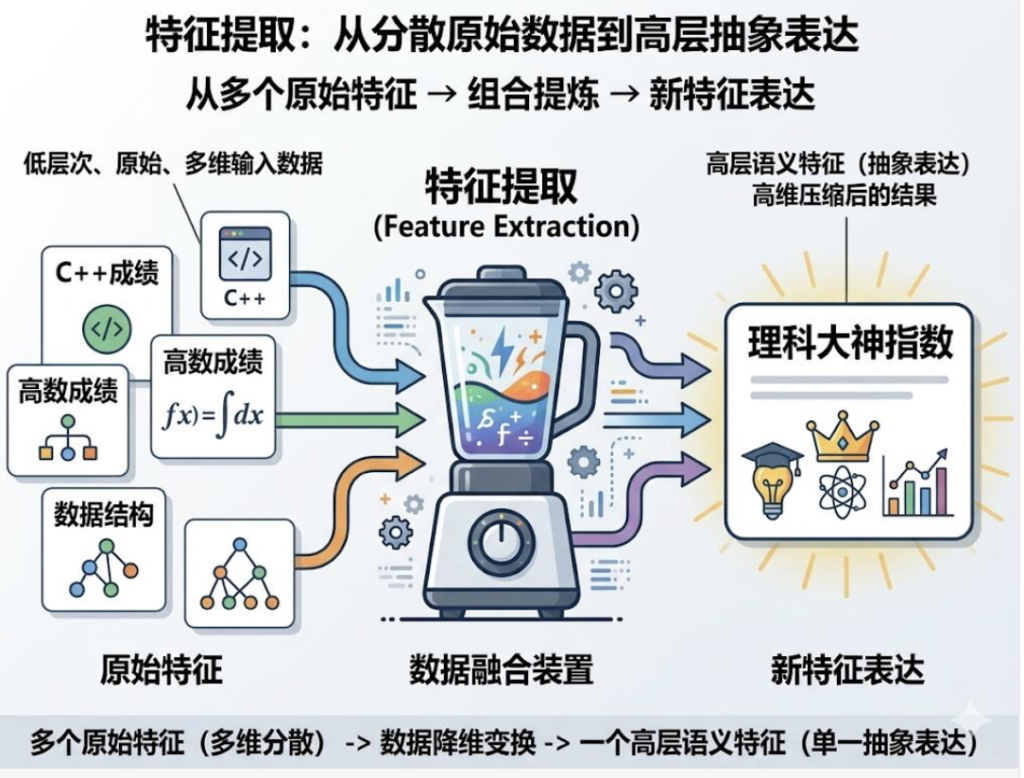
🔹流派二:特征提取(Feature Extraction)—— 做归纳
这是更常用也更高级的方法。它不是简单地扔掉特征,而是把原有的多个特征,重新组合、浓缩,创造出全新的、数量更少的特征。
这个过程有点像榨果汁。
- 原来的特征:是一整个橙子,里面有果肉、果皮、经络、水分等等(成百上千个维度)。
- 特征提取:就是用榨汁机(降维算法)把这个橙子进行处理。
- 新的特征:得到的一杯橙汁。这杯橙汁包含了原来橙子的大部分精华(味道、营养),但它已经不再是橙子了,它是一个全新的东西。我们可能只需要 1 杯橙汁(1 个新维度)就能代表原来一个橙子(成百上千个旧维度)的核心信息。
优点: 能够保留大部分原始信息,通常降维效果比特征选择要好。
缺点: 新创造出来的特征,失去了原有的物理意义。那杯橙汁特征,你没法说它具体代表 “面积” 还是 “房龄”,它是一个综合体,解释起来比较困难。
在特征提取这个领域里,有一个名震江湖的武林盟主,它就是 PCA。
三、PCA(主成分分析)🔖
PCA(Principal Component Analysis,主成分分析),是特征提取里最常用、最经典的方法。
PCA 的核心思想: 就像给一个三维物体拍一张二维照片。

这个花瓶是三维的,信息很复杂。我们想用一张二维的照片来最大程度地展示它的样子。你会怎么拍?你肯定不会从花瓶的正上方或者正下方拍,那样只能拍到一个圆形或一个环形,丢失了太多信息。你一定会找一个最能体现花瓶轮廓、纹理和形状的角度去拍。
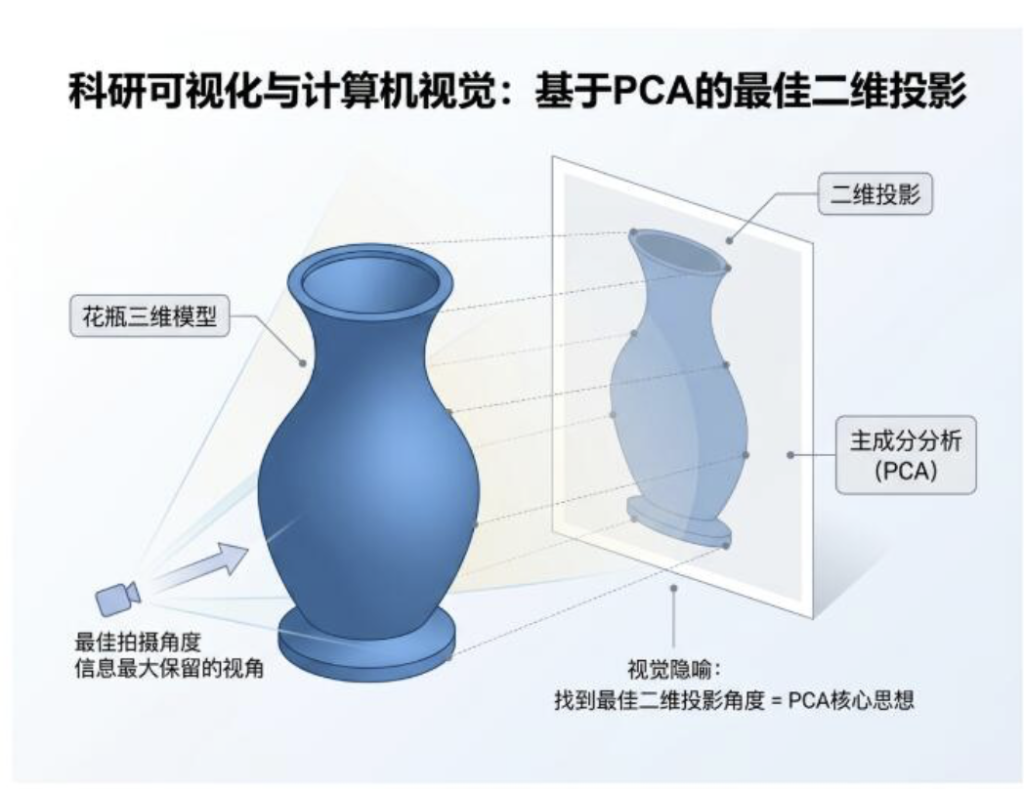
PCA 干的就是这个事!它要为你的高维数据,找到那个最佳拍摄角度。这个最佳角度,在 PCA 里被称为主成分(Principal Component)。
PCA 的工作逻辑(大白话版):
假设我们有一堆二维数据点,像散落在一张纸上的芝麻。我们想把它降到一维。
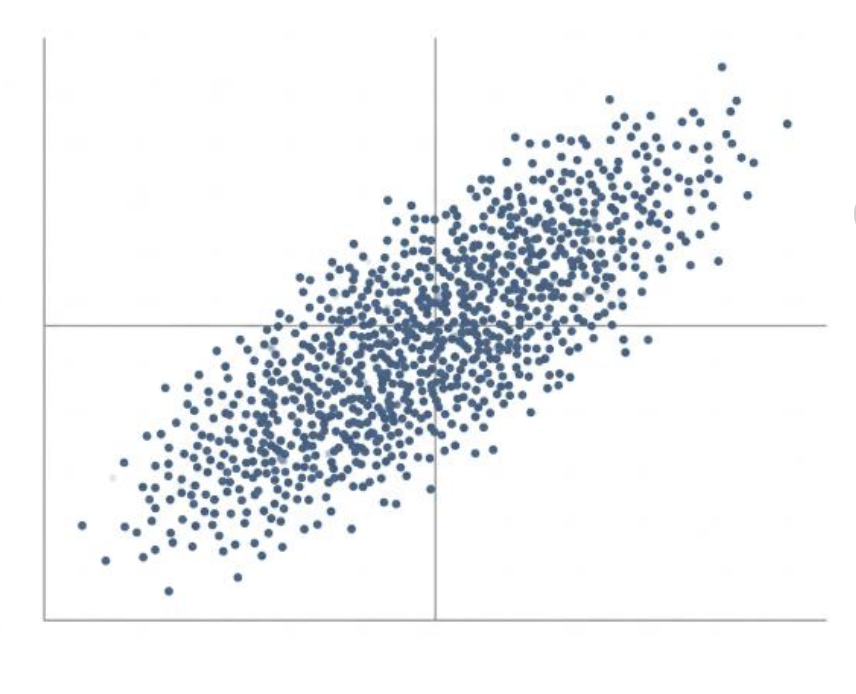
1.第一步:找到最主要的矛盾 —— 第一主成分(PC1)
- PCA 会扫视这堆数据,然后问自己:“哪个方向上,这些数据点分布得最开、最散?”,也就是方差最大的方向。
- 为什么找方差最大的方向?因为方差越大,代表这个方向上包含的信息量越丰富。如果所有数据点在一个方向上都挤在一起,说明这个方向没啥区分度,信息量很小。
- PCA 找到的这个能让数据 “伸展” 得最开的方向,就是第一主成分(PC1)。它就像是故事的主线剧情,包含了最多的信息。
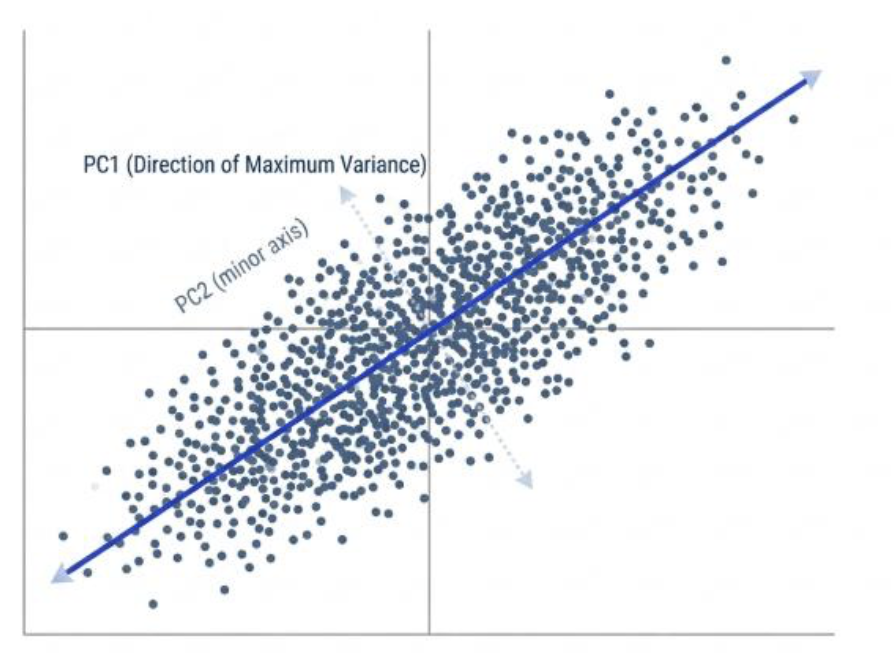
2.第二步:找到次要的矛盾 —— 第二主成分(PC2)
- 找到了主线剧情还不够,我们还想找点支线剧情。
- PCA 会接着寻找下一个方向。这个方向有两个要求:
- 必须和刚才的 PC1 互相垂直(数学上叫正交)。为啥要垂直?因为这样才能保证新的信息和旧的信息不重复、不相关。
- 在所有与 PC1 垂直的方向里,找到那个能让数据次一级 “伸展” 的方向,也就是方差第二大的方向。
- 这个方向,就是第二主成分(PC2)。
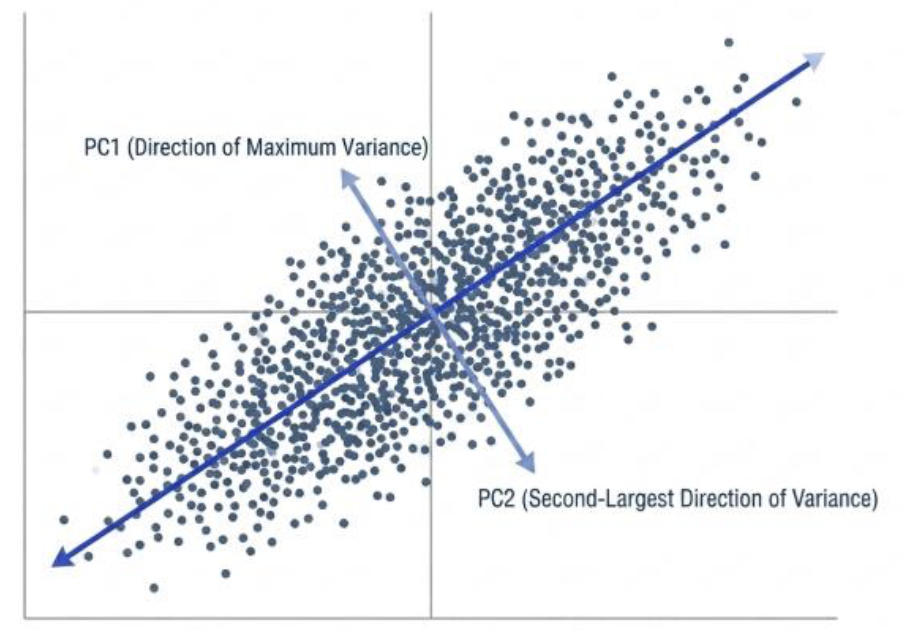
3.第三步:以此类推,直到找到所有主成分。
- 如果数据是 N 维的,PCA 就能找到 N 个互相垂直的主成分(PC1, PC2, …, PCN),它们的方差是依次递减的。
4.第四步:做出选择,完成降维。
- 现在,我们有了一套全新的坐标系(由 PC1, PC2…… 组成)。
- 我们会发现,绝大部分信息(比如 95% 的方差)都集中在前几个主成分上(比如 PC1 和 PC2)。后面的那些主成分(PC3, PC4……)包含的方差很小,基本就是噪音了。
- 于是,我们就可以保留前 K 个最重要的主成分,扔掉后面的。
- 最后,把原始数据投影到这 K 个主成分构成的 “新坐标系” 上,就得到了降维后的新数据!
比如,把 100 维的数据用 PCA 降到 2 维,我们就是保留了信息量最大的 PC1 和 PC2,然后把所有数据点都 “拍” 到这个由 PC1 和 PC2 构成的二维平面上,得到一套全新的二维坐标。
💡 整个过程,就像把一个立体的物体,拍成了一张信息量最大的二维照片。虽然维度降低了,但物体的核心样貌被保留了下来。
四、来来来,总结一下吧!🔖
1.“维” 是什么? 在 AI 里,维度 = 特征。100 个特征就是 100 维。
2.为什么要 “降维”? 因为高维数据会导致维度灾难,让 AI 计算慢、容易笨(过拟合)。降维是为了提速、增效、防变笨。
3.降维两大流派:
- 特征选择:像整理衣柜,直接扔掉不重要的特征。优点是简单、可解释。
- 特征提取:像榨果汁,把旧特征融合成信息量大的新特征。优点是效果好,但新特征不可解释。
4.PCA(主成分分析)是什么?
- 是特征提取最常用的算法;
- 核心思想是找到数据方差最大的方向(主成分),因为方差大 = 信息量大。
- 通过保留前几个最重要的主成分,扔掉次要的,从而实现降维。就像给一个 3D 物体,找到最好的角度,拍一张信息量最足的 2D 照片。