转载:抖音 小白debug
前言🔖
Harness Engineering 是什么?和 Prompt Engineering 以及 Context Engineering有什么关系?
2026年Open ai在一篇博客文章中提到了Harness Engineering,驾驭工程,之后它就快速在AI圈里火了起来。很多人根本不知道它到底是什么,就开始各种跟风吹爆。这在三天一重磅,五天一炸裂的AI圈里,虽然离谱,但也合理,那它到底是什么?和这两年很火的提示词工程(Prompt Engineering ),上下文工程(Context Engineering)又是什么关系?全网资料参差不齐,如有差异,以我为准。

今年就把这些概念,串起来讲透,看完你就会知道。

AI Agent开发的本质 🔖
AI Agent开发,本质上是在做什么?为什么同样的模型,换个AI IDE,效果会差这么多?
有了AI,程序员就不写代码,是真的吗?怎么做到的?
Prompt Engineering 🔖
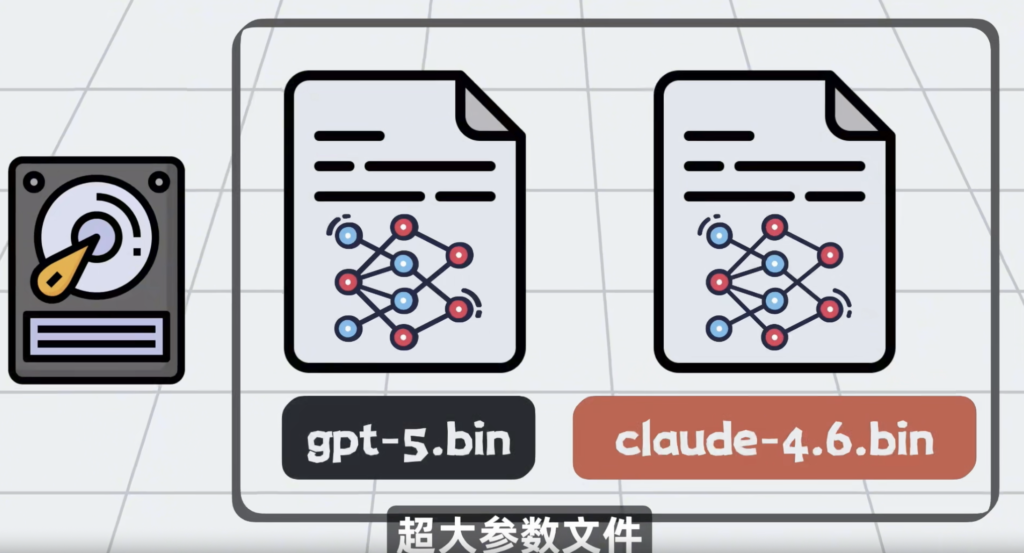
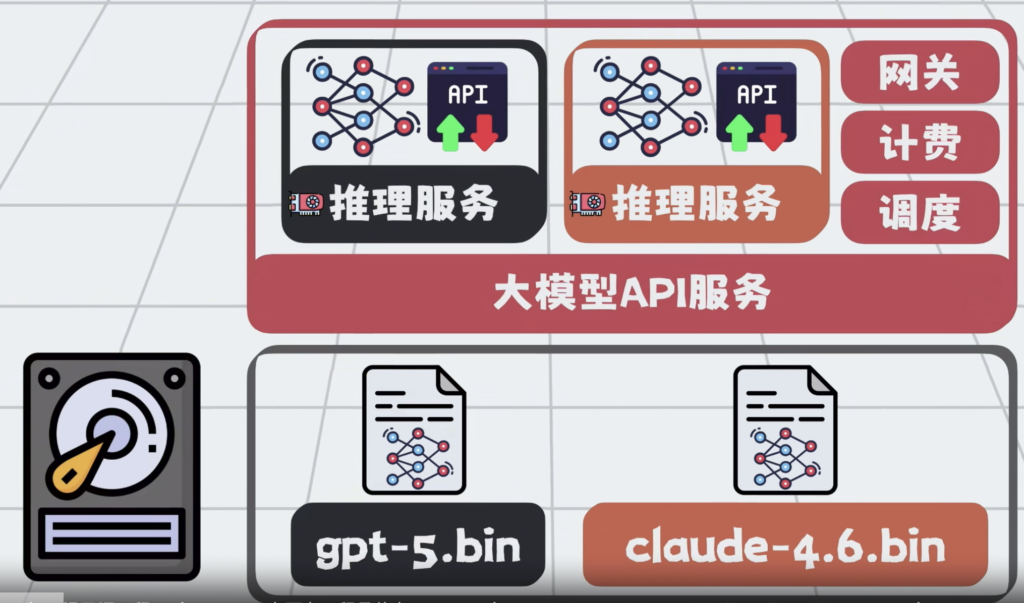
把ChatGpt,Claude的外壳剥开,里面的大模型LLM,本质就是磁盘上超大参数文件。


将它加载到显卡内存里,
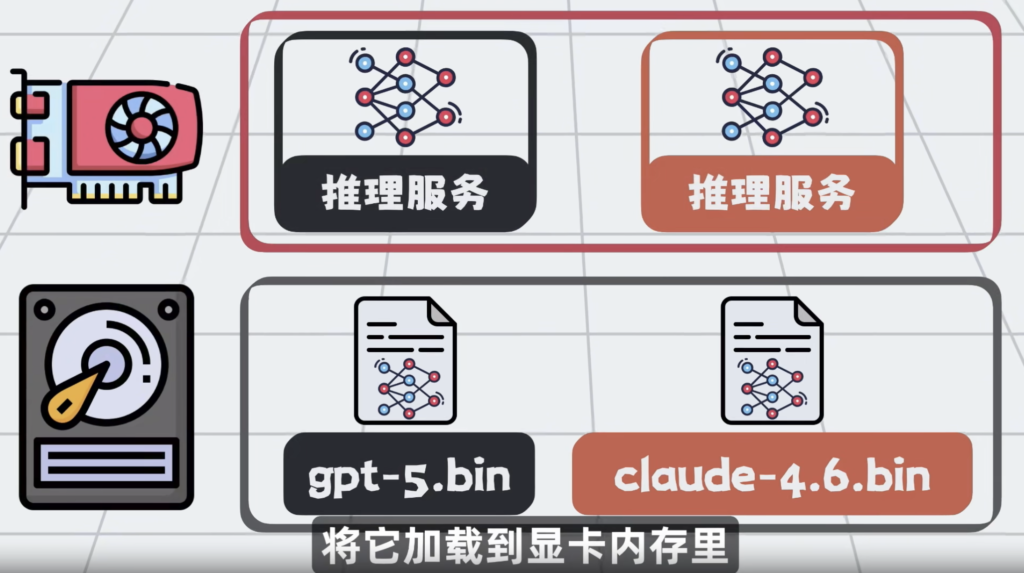
配上HTTP接口,就成了大模型API服务。
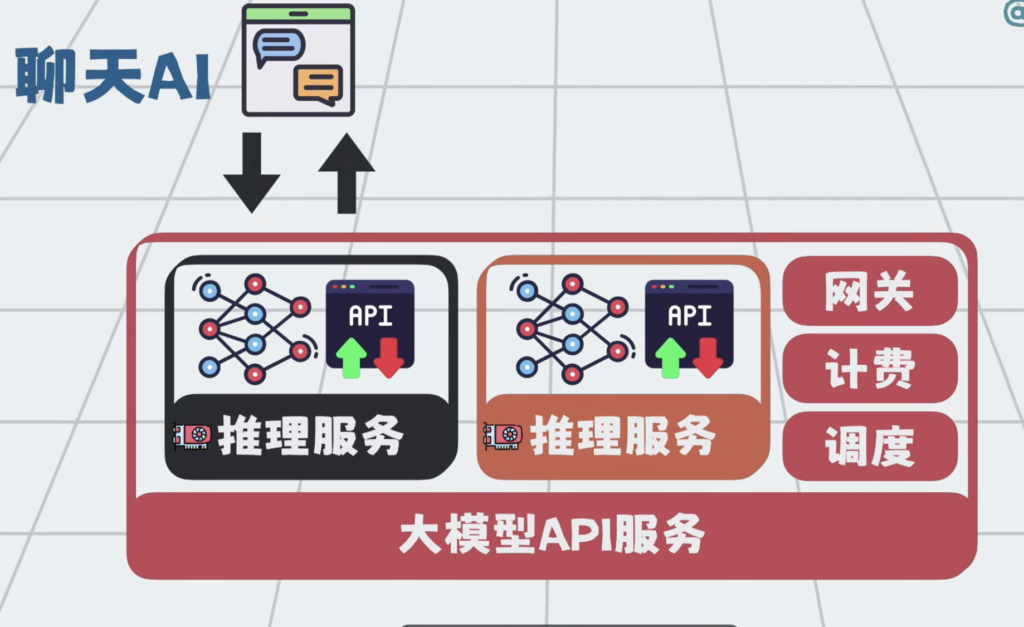
给它加个聊天界面,就变成了聊天AI。
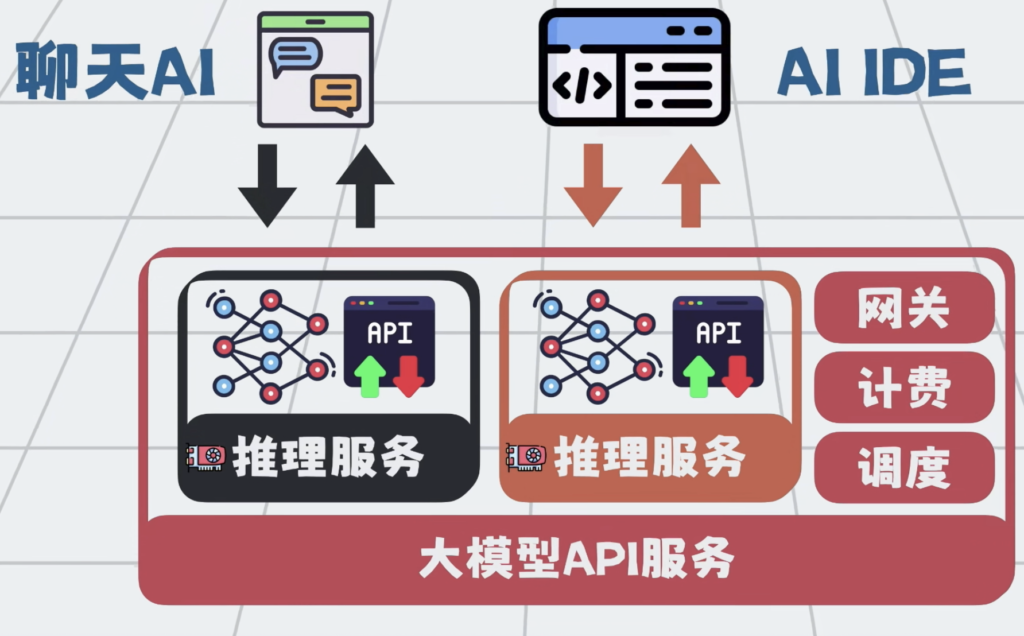
加个代码编辑器,就变成了AI IDE。
AI大模型做的事情很简单,就是基于当前输入到内容,预测下一个字词,大概率会是什么?它本质上只是在猜,你想要什么。
所以你给他输入的指令太宽泛,那它预测的答案就会非常发散。
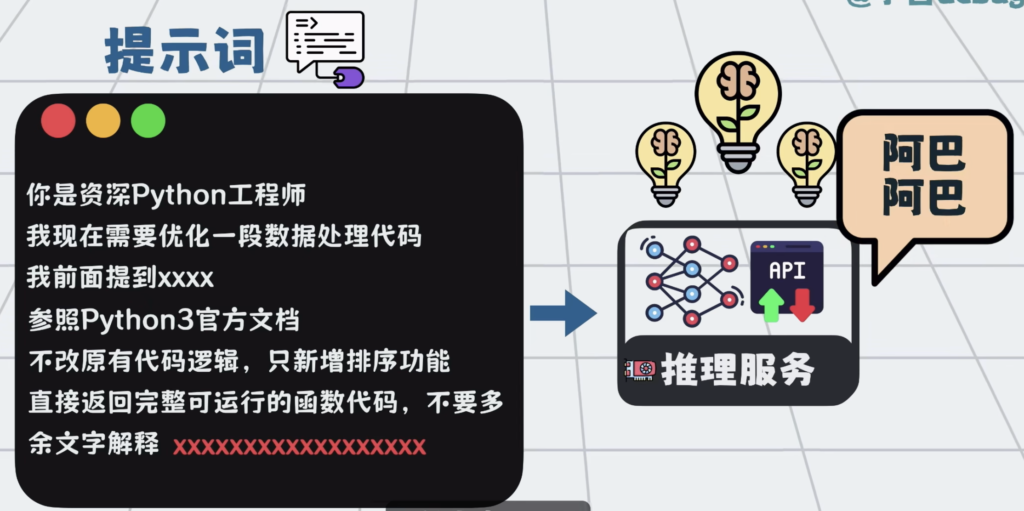
比如你丢给他一段代码,说【加个排序】,它可能只回你排序那部分怎么写。
你得补一句,【给我完整的函数代码】。【不要乱改我的代码】,它给的结果才会更符合要求。
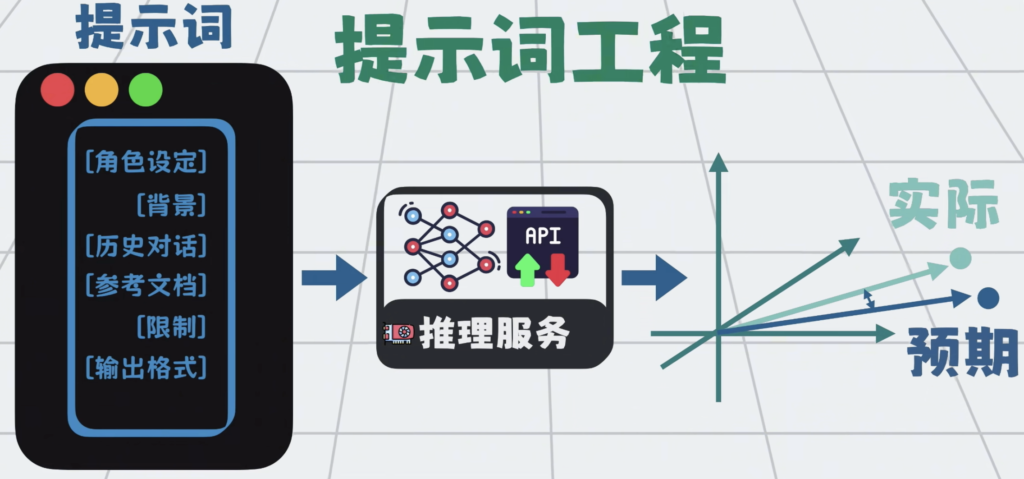
能加的内容有很多,比如:
- 角色设定
- 背景
- 历史对话
- 参考文档
- 限制
- 输出格式
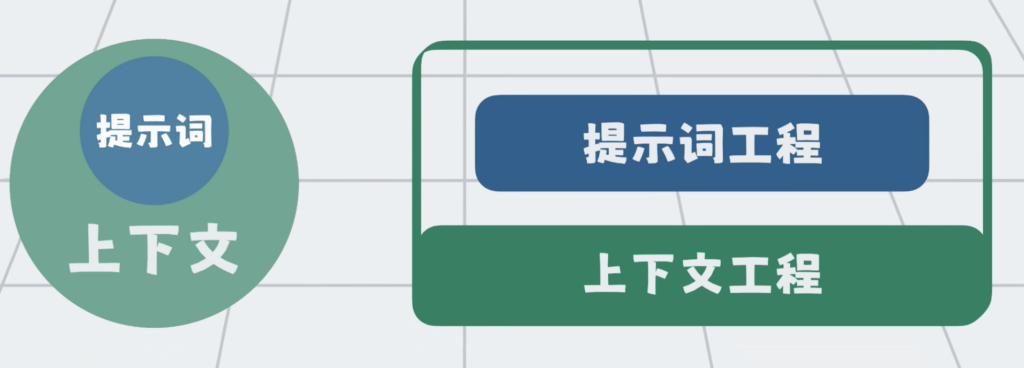
这些约束构成了所谓的提示词。

而这种有意识的调整,和设计提示词,让模型稳定的,朝着你预期的内容和格式,输出的技术手段,就是所谓的提示词工程。
提示词工程解决的是,大模型无引导,乱说话的问题。
Context Engineering🔖
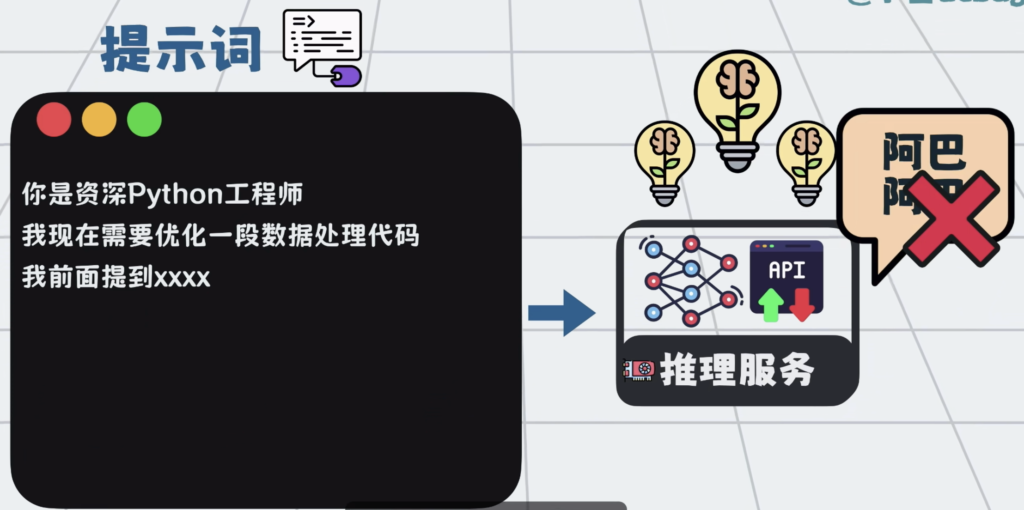
提示词写的越长越仔细,模型就知道的越多,回答就越准,
反过来同理,大模型回答的不准,那大概率是因为,知道的不够多。
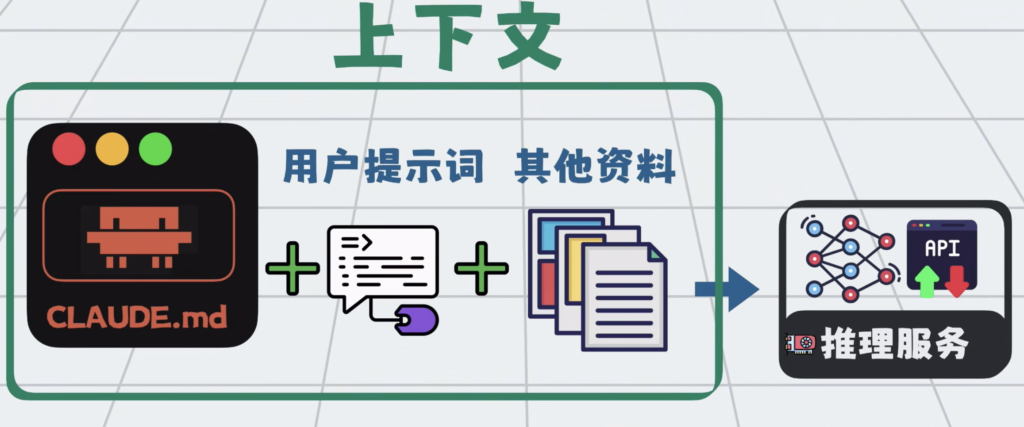
于是大家很自然的,会不断往大模型里,塞各种资料。这些打包到一起,发给大模型的所有信息,就叫上下文。
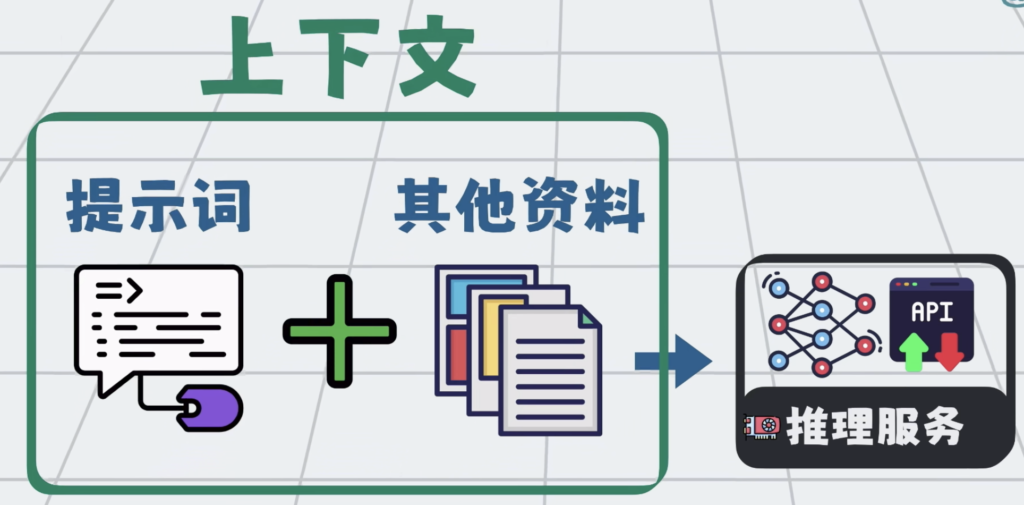
提示词只是上下文的一部分,但大模型再强,一次性能处理的上下文也有最大的限制,这个限制叫上下文窗口。
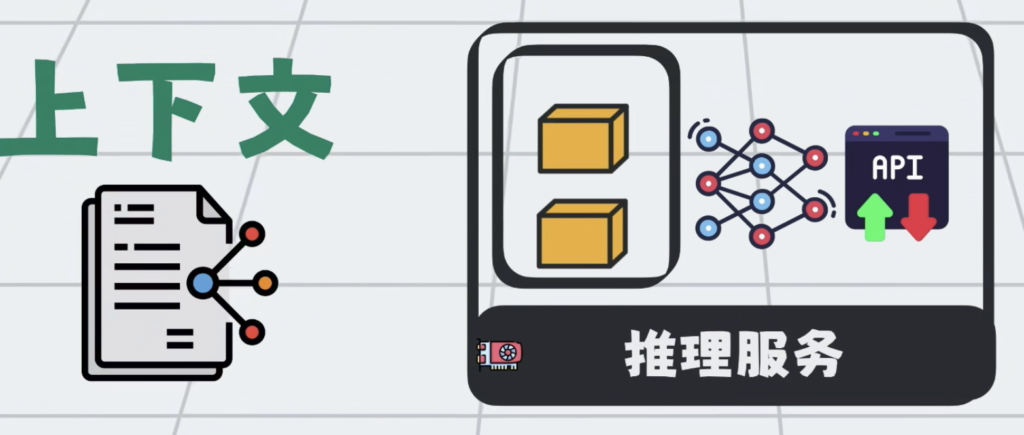
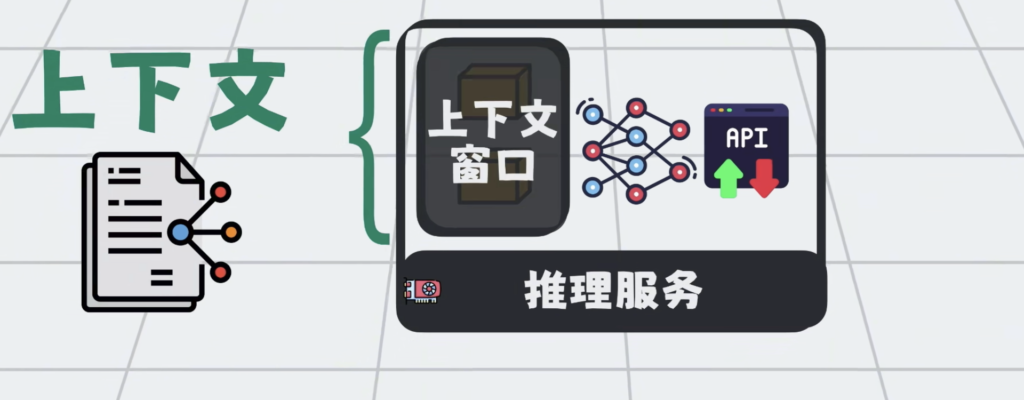
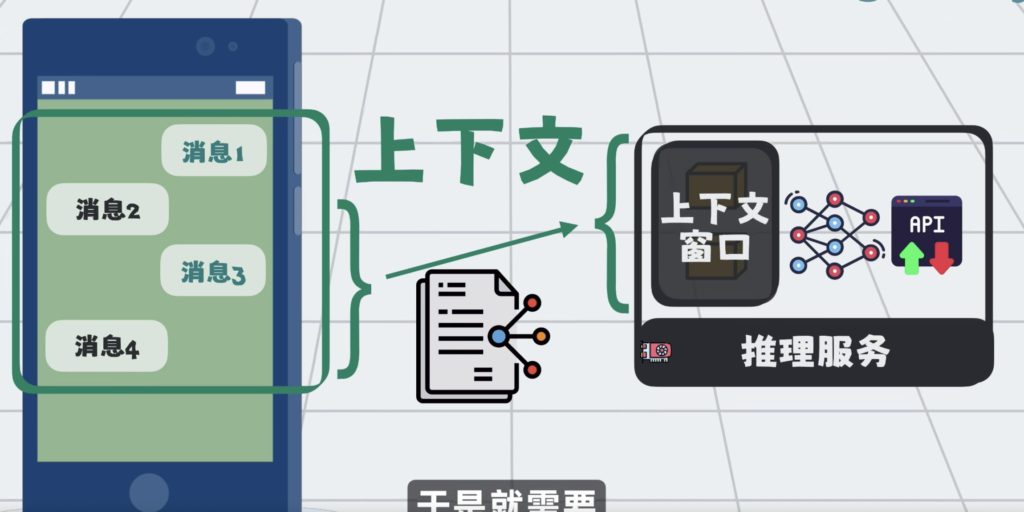
在AI大模型应用里面,多对话几轮,就很容易将上下文窗口打满。
于是就需要一些策略,去压缩或者丢弃部分信息,在这个过程中,不可避免会丢失关键信息,从而破坏上下文的完整性和准确性。这类问题被统称为上下文腐化。
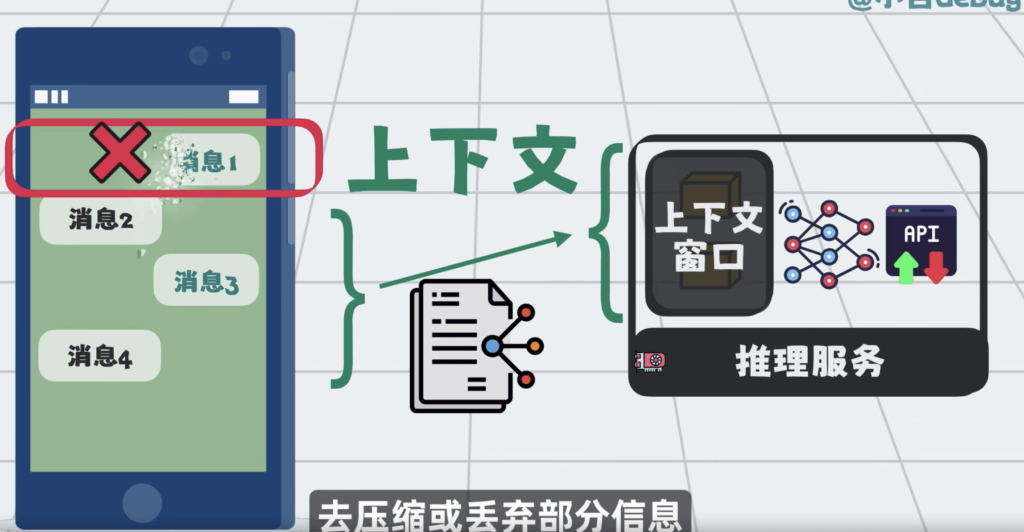
效果上,就是模型开始记不住,回答前后不一致。
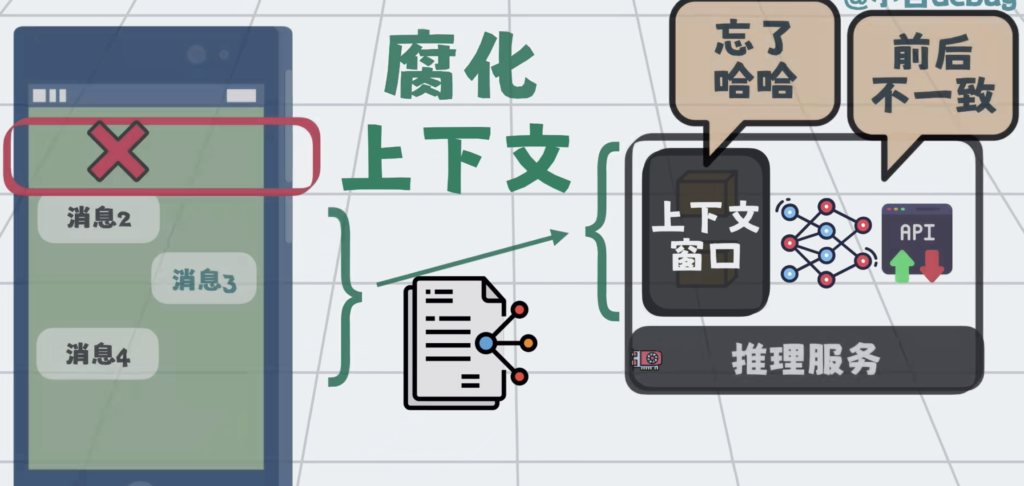
上下文窗口就这么大,于是问题就变成了,怎么才能在合适的时候,将合适的内容塞入到有限的上下文中。
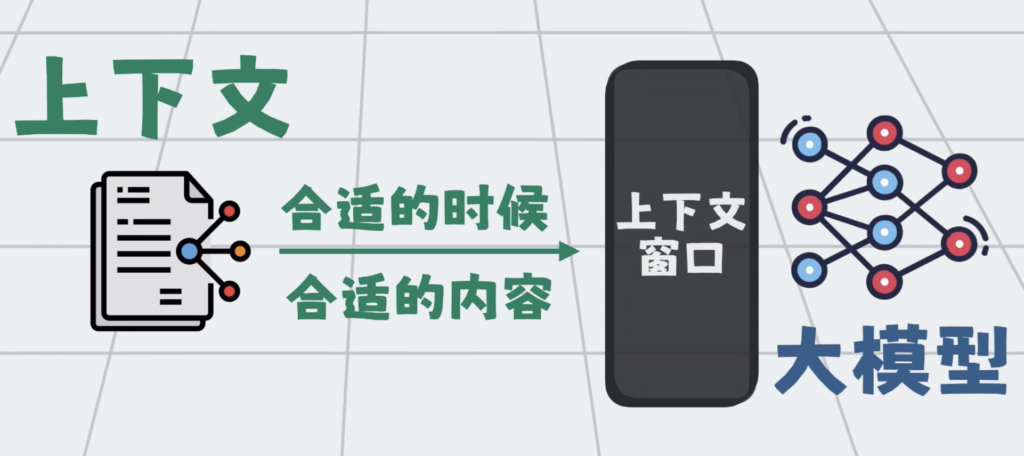
于是衍生了一套负责动态管理大模型上下文的技术,也就是所谓的上下文工程。
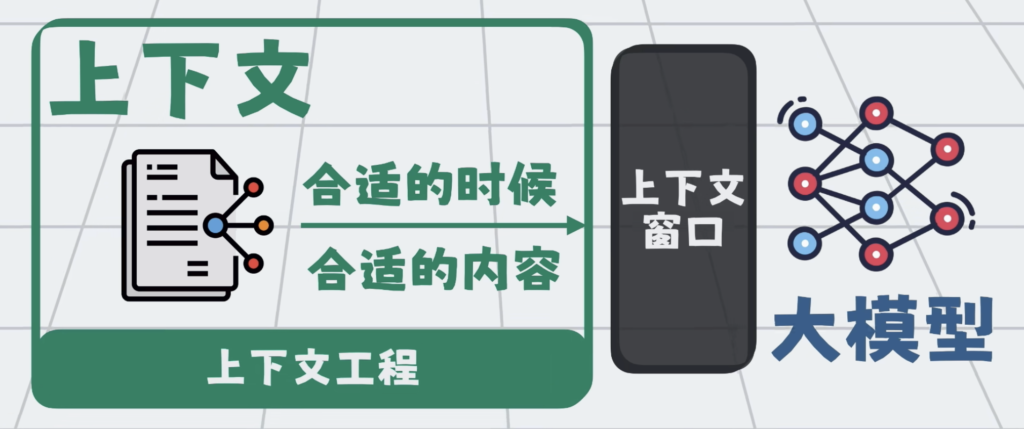
提示词是上下文的一部分,那自然提示词工程,其实也是上下文工程的一部分。
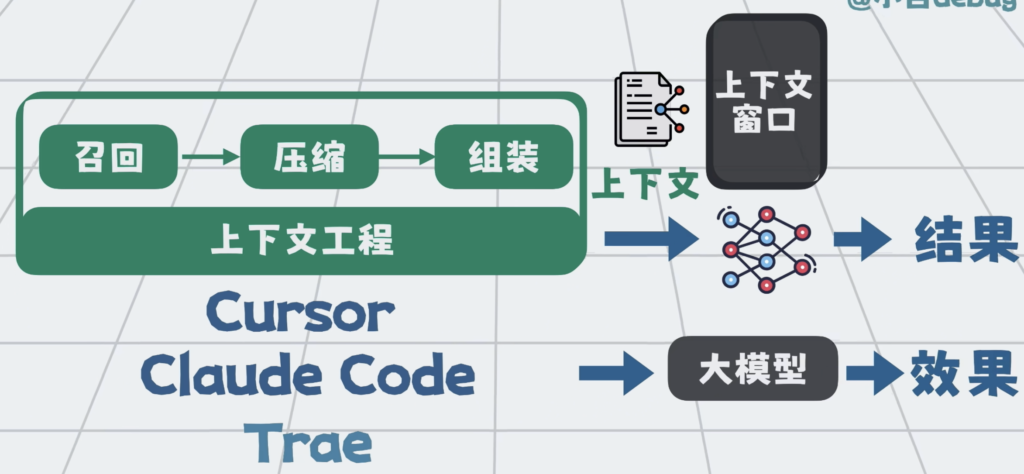
上下文工程一般通过外部程序来实现,比如Cursor,Claude code,Trae。
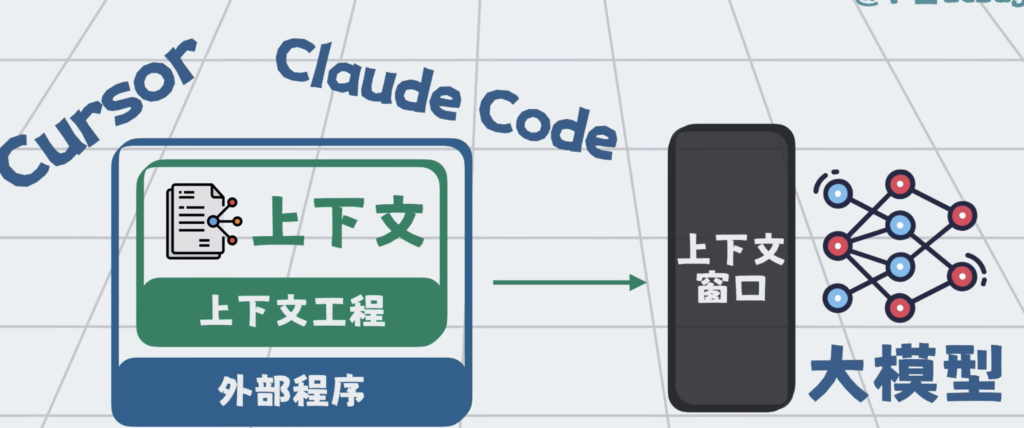
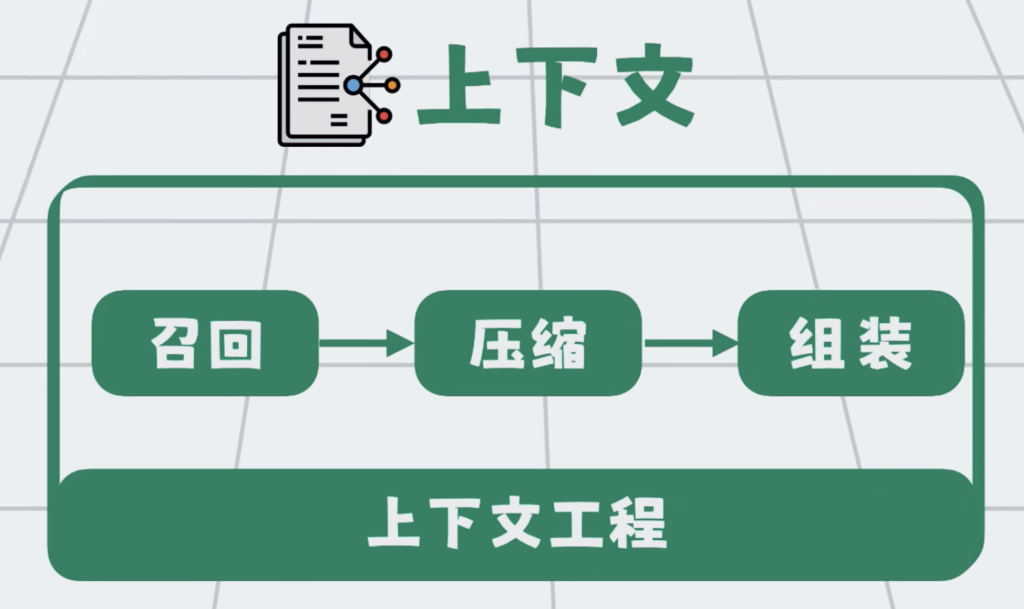
每一家的技术实现都有差异,但总的来说,可以总结为三个步骤:召回,压缩,和组装。
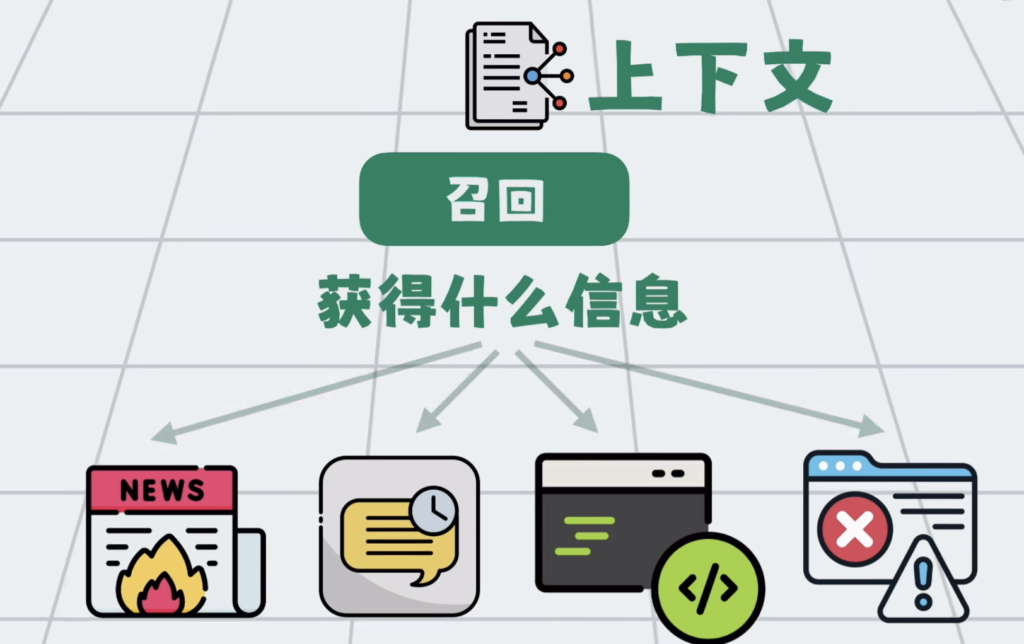
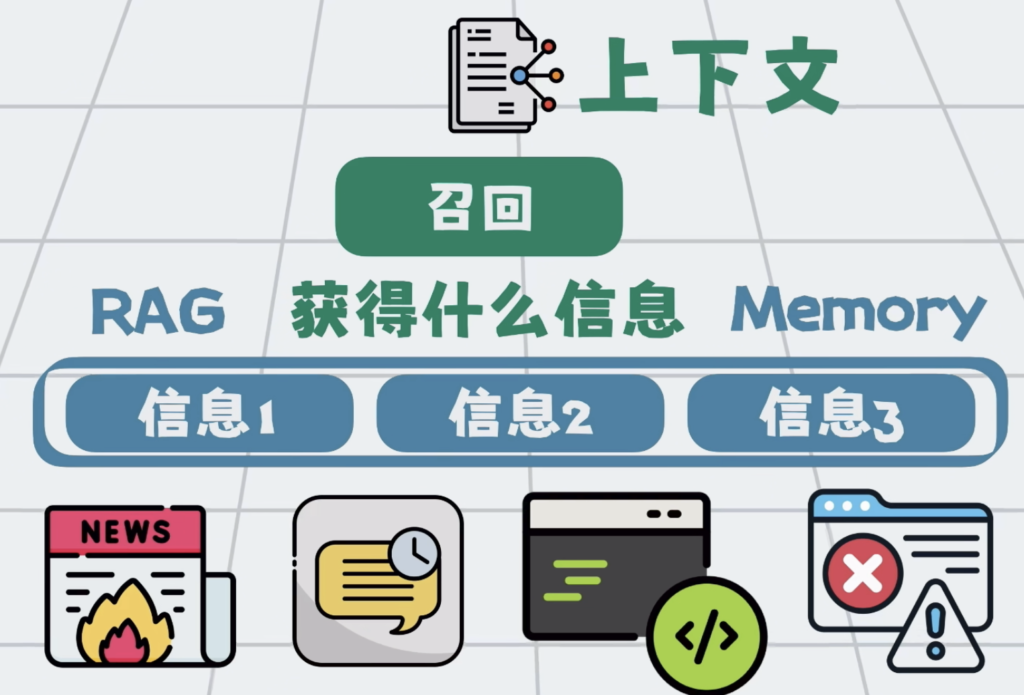
第一步召回,说白了就是找什么信息,这些信息可以来自外部新闻,也可以来自过去聊天记录,当前代码环境,以及程序运行报错等等,总之就是从里面找出最相关的内容。
这里面涉及到一些 RAG,Memory 等技术。随便拿出一个,都能单开一个视频。
信息很多,上下文窗口有限,所以需要将信息变小,于是引入第二步,压缩。
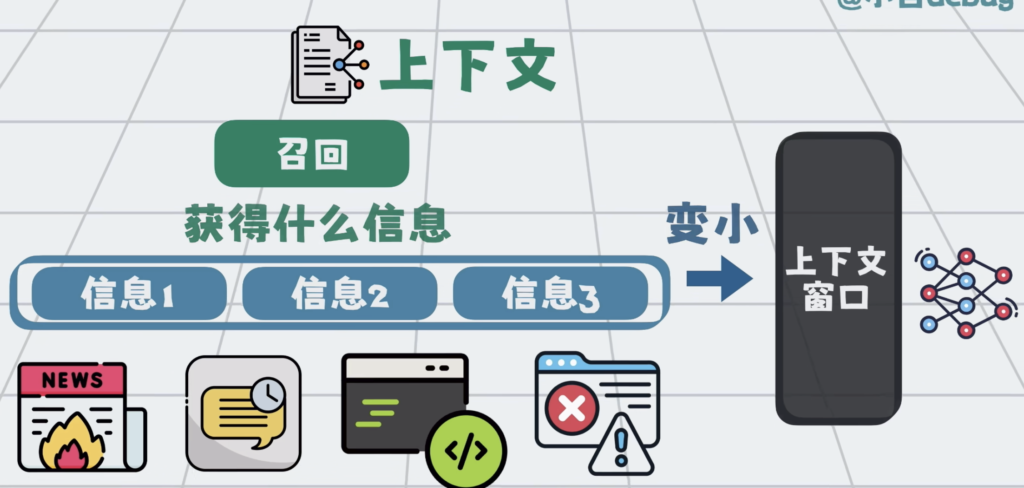
比如将信息分开发给大模型做总结,
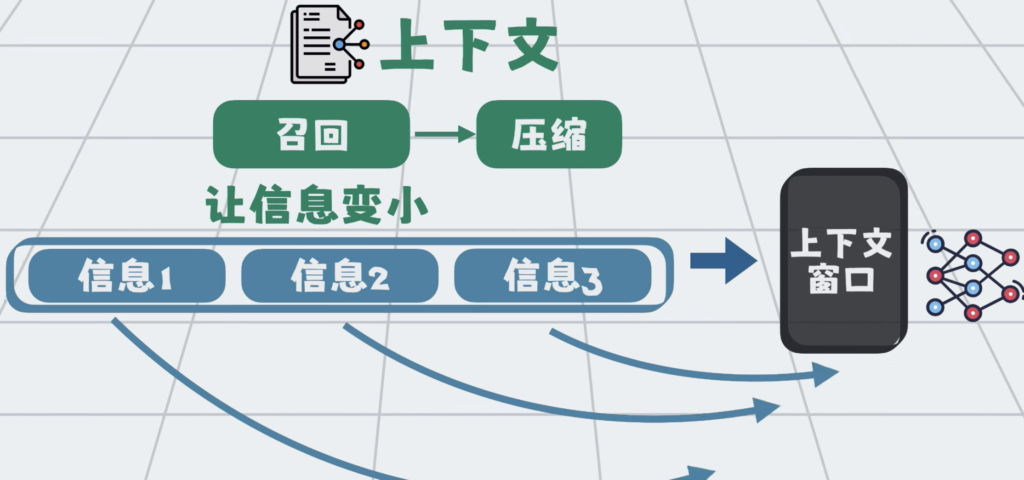
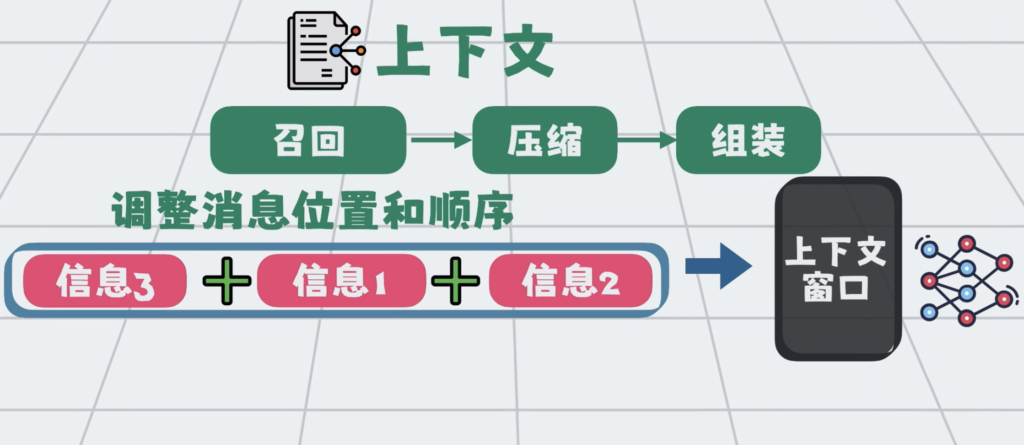
之后就是组装,因为信息放置到位置和顺序,会直接影响模型的理解和输出。比如越靠后,越容易被模型关注。所以我们需要通过一定的结构,重新组装内容。这样进入模型的上下文,更精简,更相关,输出也会更稳定,更准确。
不同AI工具的上下文工程策略不同,所以你会发现,就算用的是同一个模型,不同AI工具的执行效果也会有差异。
Claude Code最近也被开源了,正好可以单开一期,讲下它的上下文工程是怎么做的。

Harness Engineering🔖
提示词工程解决了大模型无引导乱说话的问题。

上下文工程解决的是上下文的组织问题。
模型是更聪明了,但它只能聊天,没法帮我们干活。
于是我们可以给大模型加入bash沙箱,文件系统,MCP这些能力,让它能像人一样操作外部工具,读写代码文件,执行命令做测试。
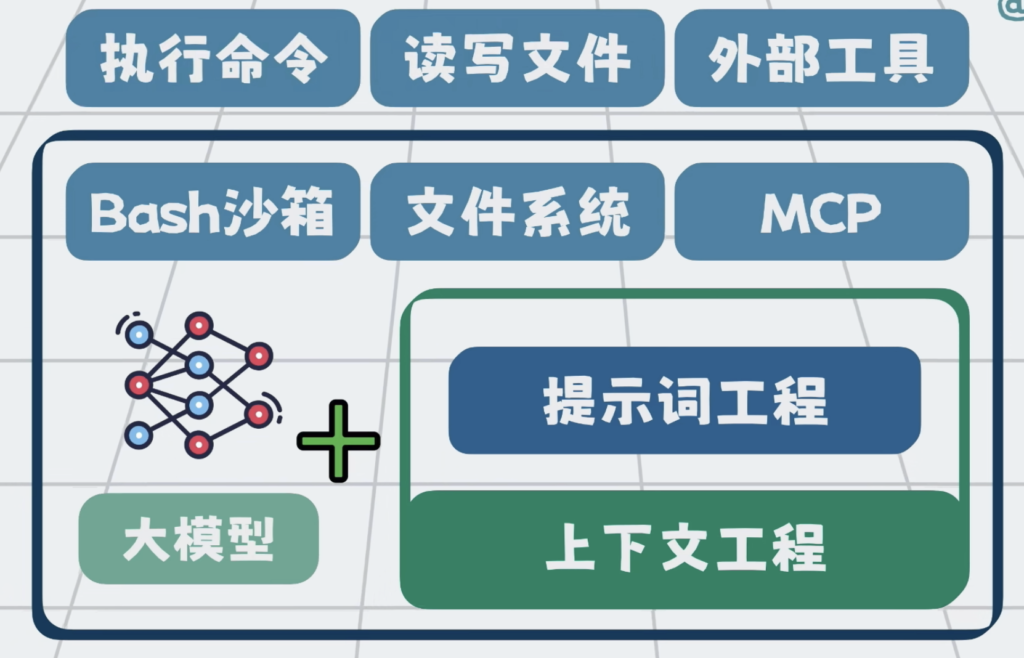
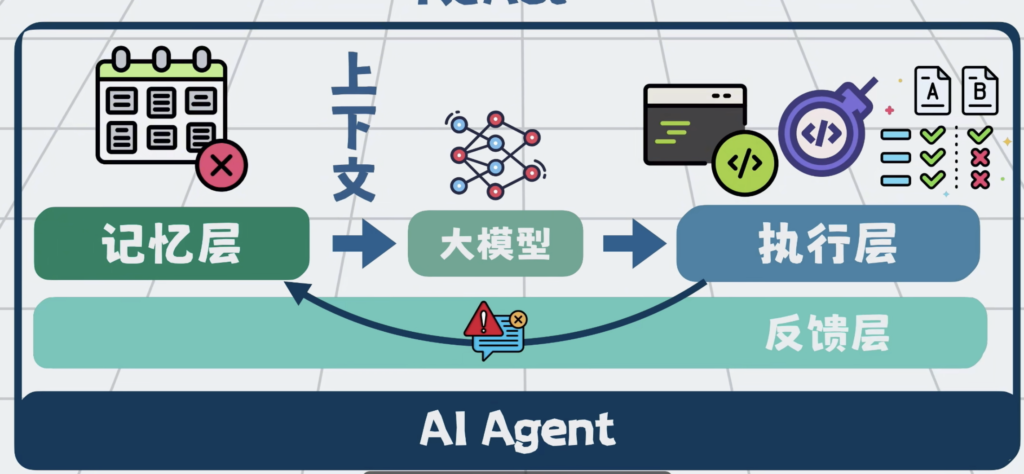
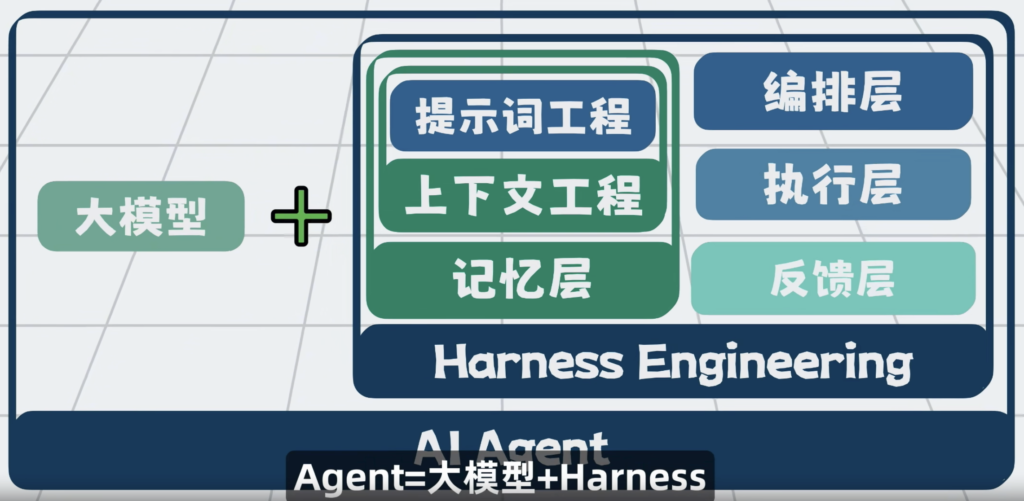
bash沙箱,文件系统,MCP 他们 共同构成了执行层,将他们串成一个流程,在外部套一层循环。于是我们就可以通过提示词工程和上下文工程,组装上下文,发给大模型,大模型负责思考,外部程序负责执行。执行过程中,得到的报错等信息,再加到上下文里,继续推理和执行。这套一边思考,一边行动的循环,就是所谓的ReAct。
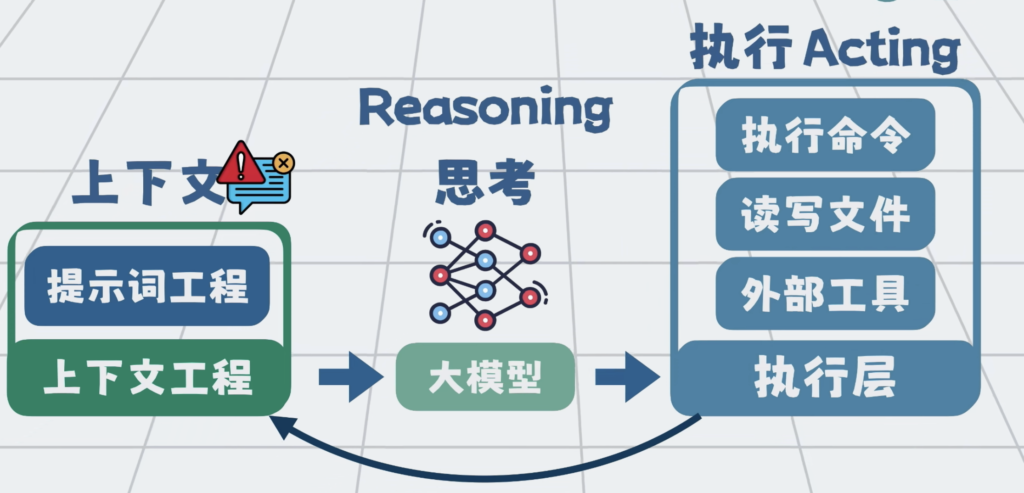
而这个能通过聊天,帮你执行任务的程序,就是所谓的AI Agent。
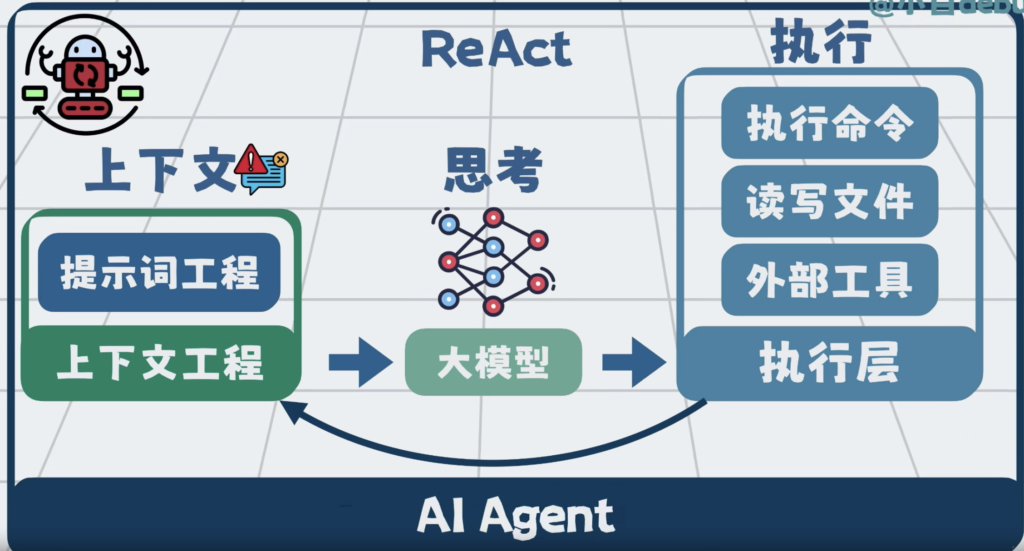
Agent的本质,就是一个for循环,只要这个循环一长,上下文就一定会膨胀,上下文工程做的再好,也可能会腐化。
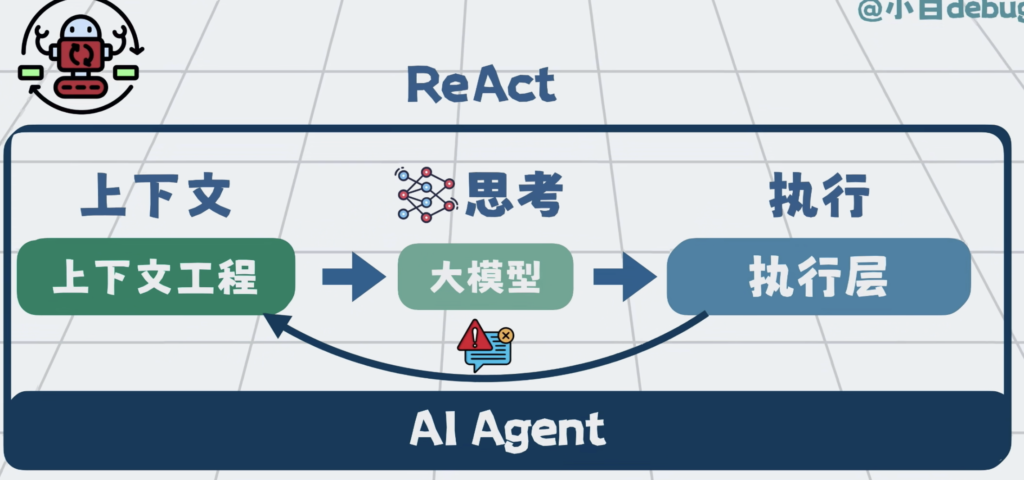
随着它看过的文件越来越多,拿到的信息越来越杂,前面定好的目标和约束,后面可能就被慢慢冲淡了。理解也会越来越偏。
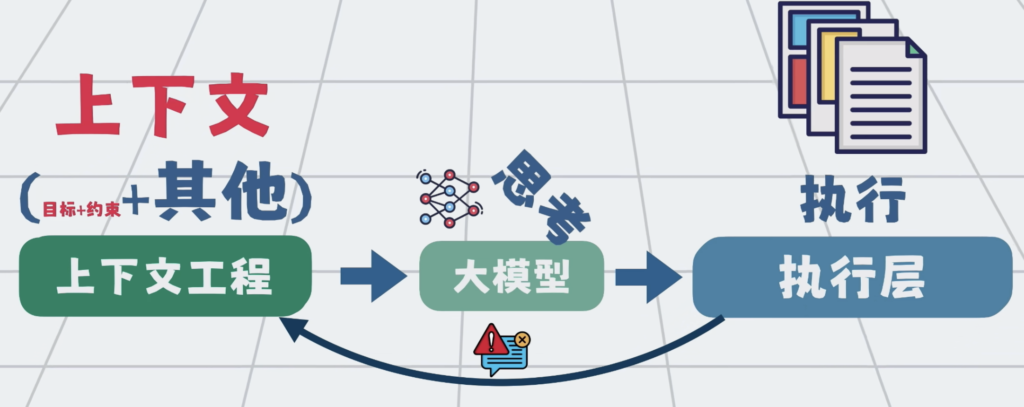
怎么办呢?很简单,只要我们可以保证每次给大模型的上下文中,都包含一些可复用的核心信息,比如项目目标,技术栈,需求背景,代码风格,禁止事项等。只要保证这部分一直在,那大模型就能在大框架约束下,减少理解偏移。
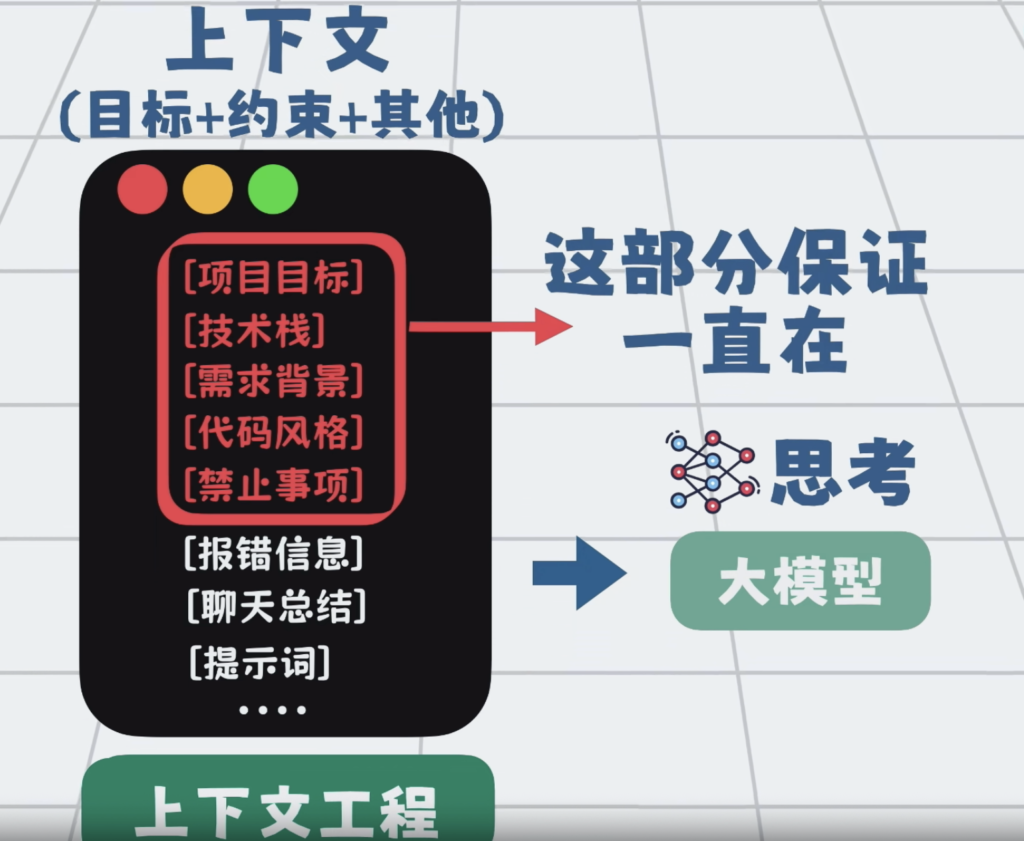
这些核心信息,可以单独写成文件,固定在代码仓库里面。
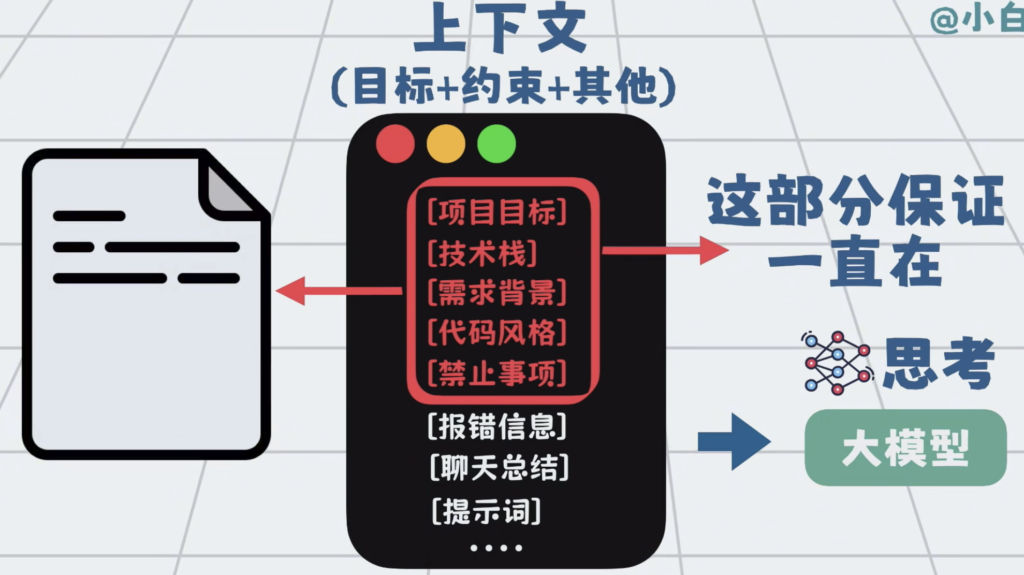
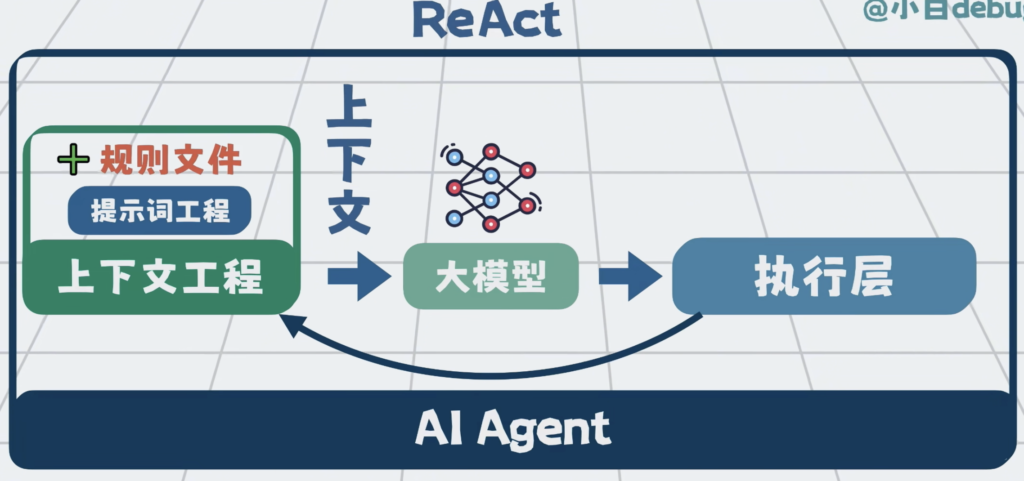
比如 Claude Code用的 Claude.md,Cursor 或 Trae 也会有各自的rules文件,它们暂时没有统一的名字。我暂且称为规则文件,
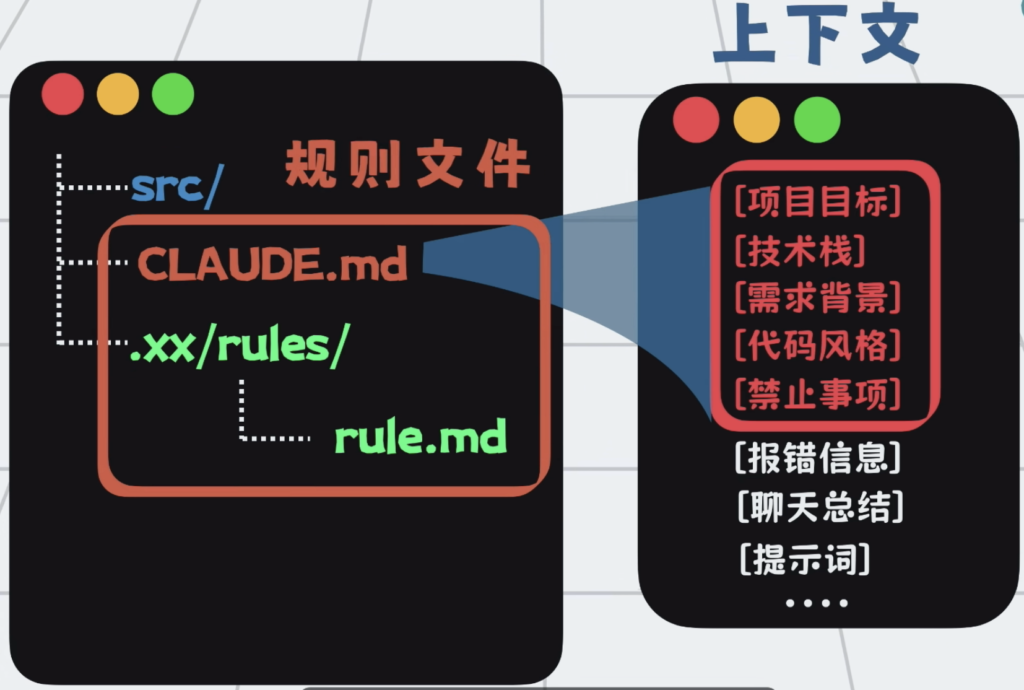
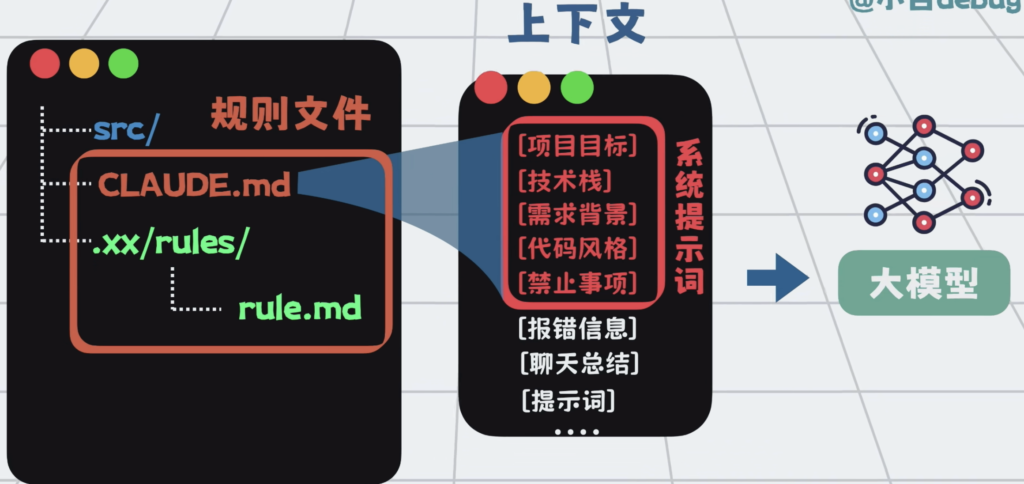
规则文件会在调用大模型的时候,作为系统提示词,自动注入上下文。
规则文件写多了也会变长,所以上下文也会很长,那就拆,把它拆成几份更短的文件,再加一个简单的路由,比如背景就读bg.md,技术栈就看stack.md,一般情况下只需要加载文件的地址路径,真正需要的时候,再加载文件的全部内容。
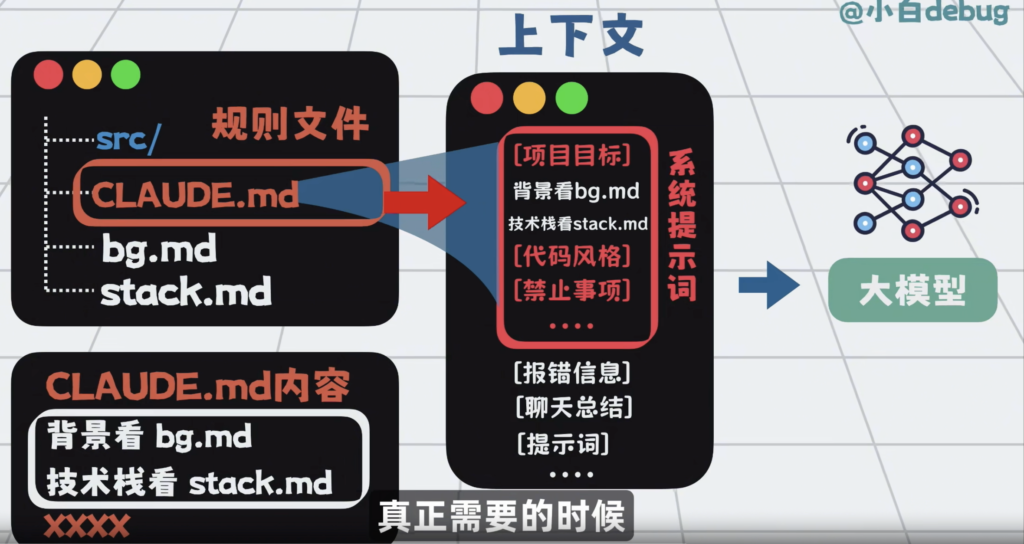
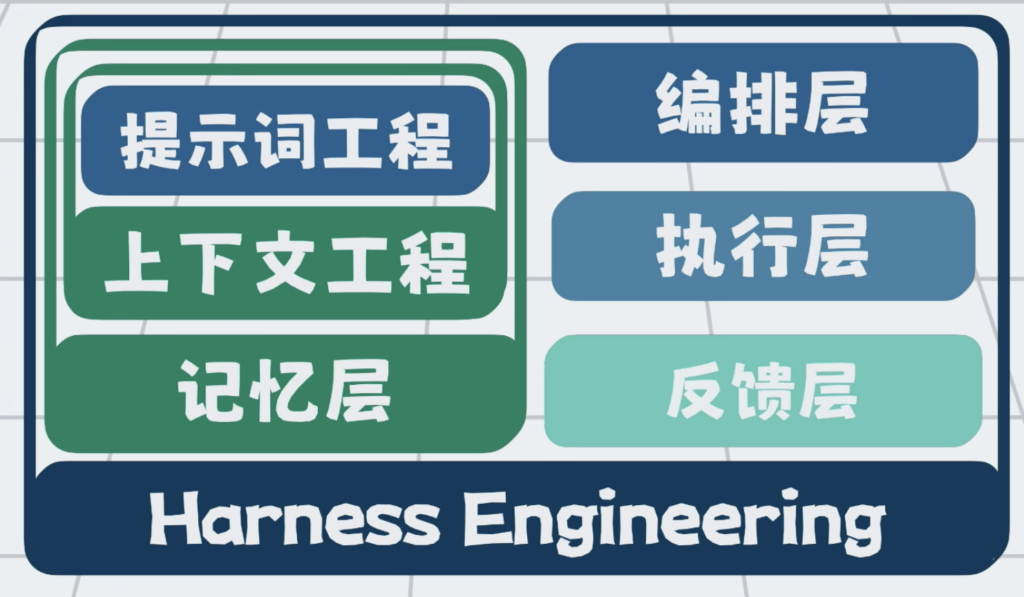
将他们跟提示词工程 和 上下文工程,配合在一起,形成记忆层。
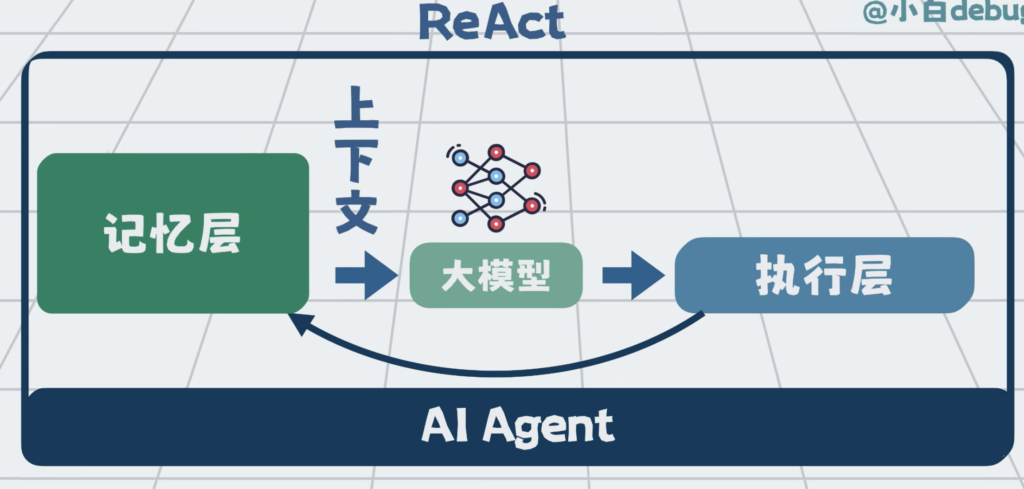
有了记忆层和执行层的配合,Agent就能不停写代码,跑linter和单元测试。
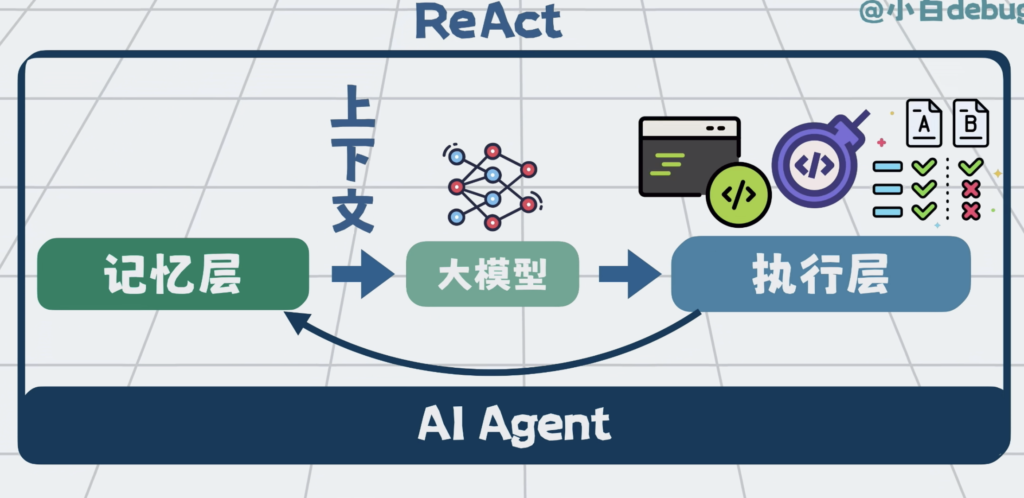
过程中发现执行有问题,还可以将测试输出和报错加入到上下文里,这样就可以驱动Agent,在下一轮循环中,自动做修复。
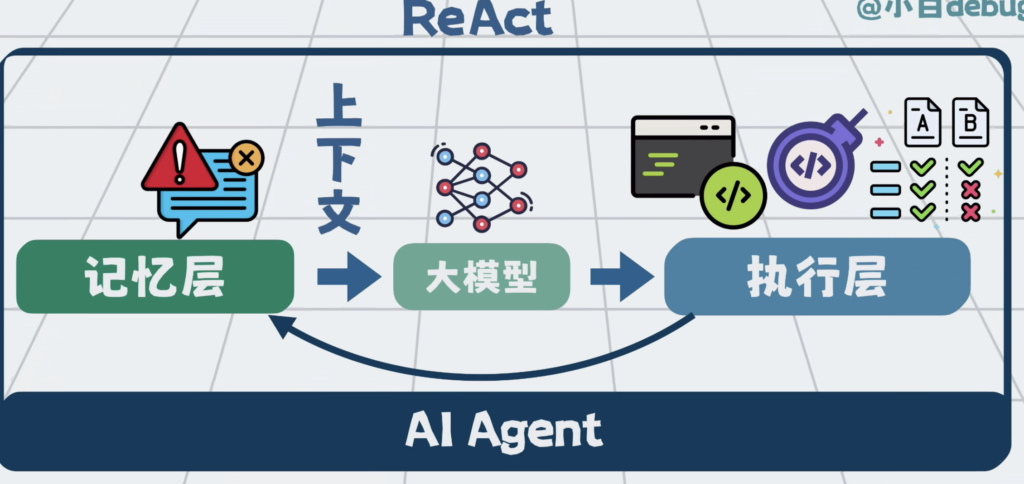
这套通过校验结果,回传错误来实现自动修复问题的能力,形成了反馈层。
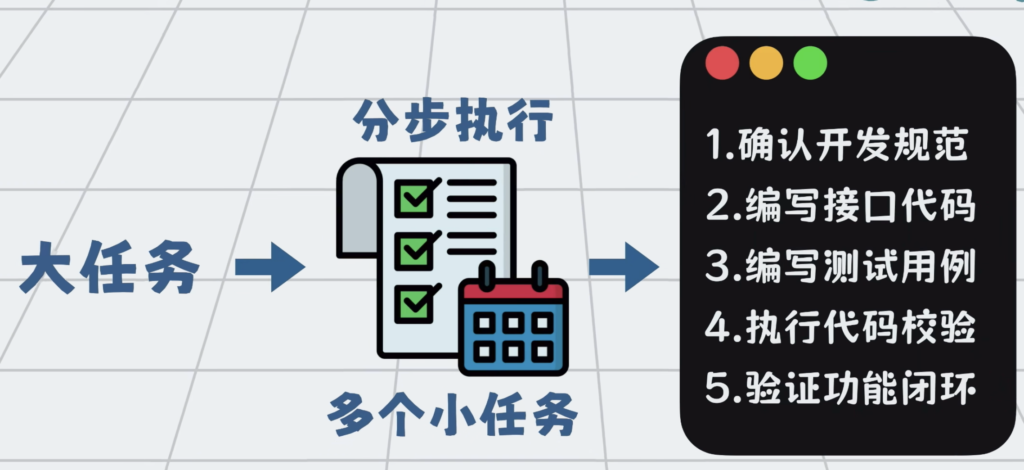
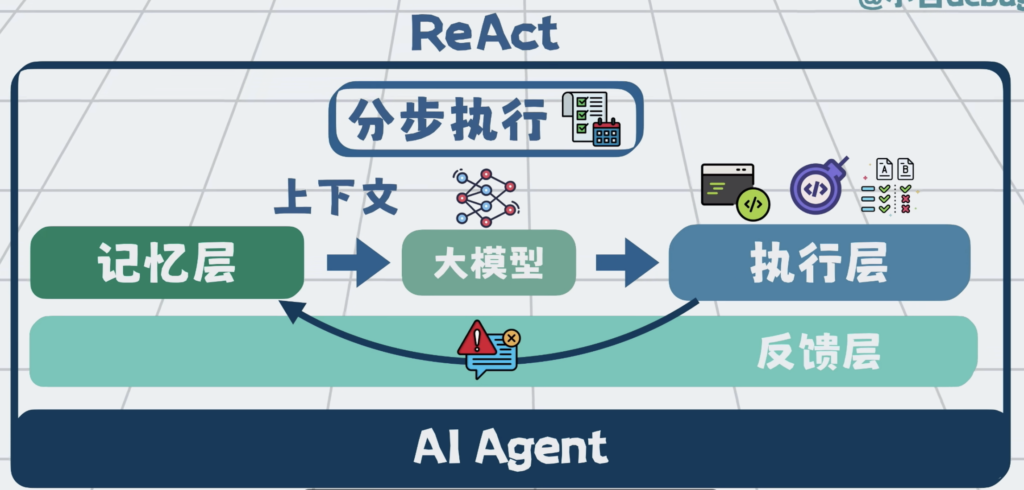
但Agent的循环,如果缺乏全局规划和清晰的结束目标,依然很容易跑偏,甚至陷入无效的死循环。所以我们还可以将大任务拆解为有明确执行标准的多个子任务,就像这样,按规划驱动Agent分步执行。
这种以全局规划为核心的,对任务做拆解与全流程管控的能力,形成了编排层。
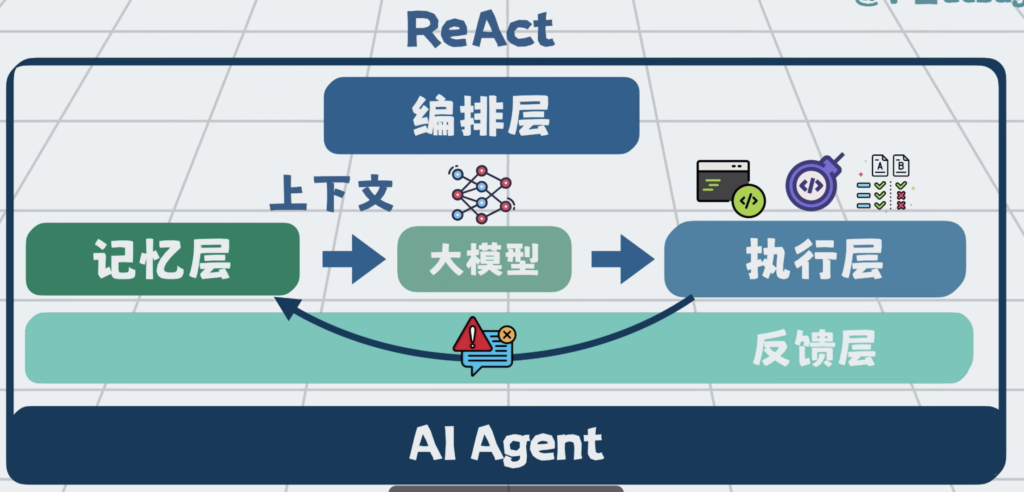
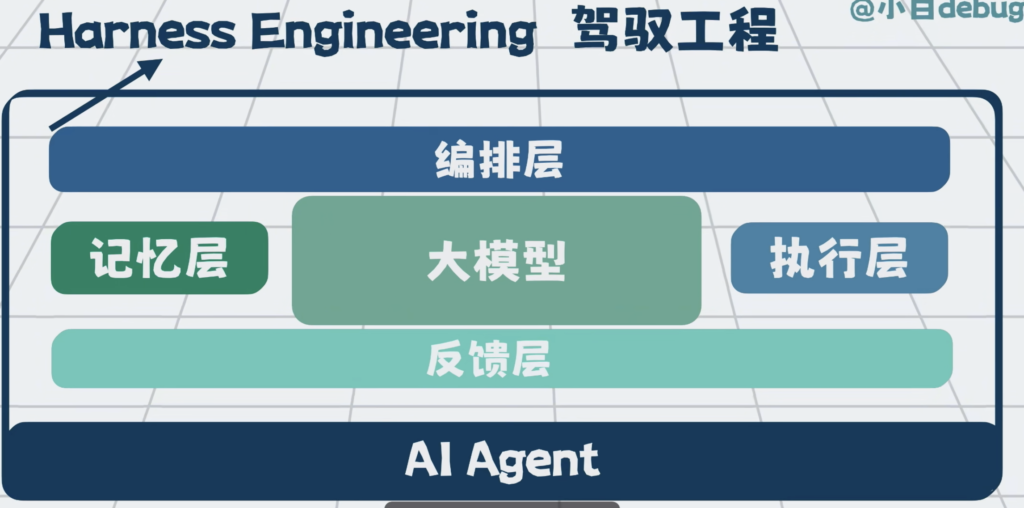
编排层,执行层,反馈层和记忆层,这些能力共同组成了一套,包裹着大模型的工程外壳,它就是Harness Engineering,驾驭工程。
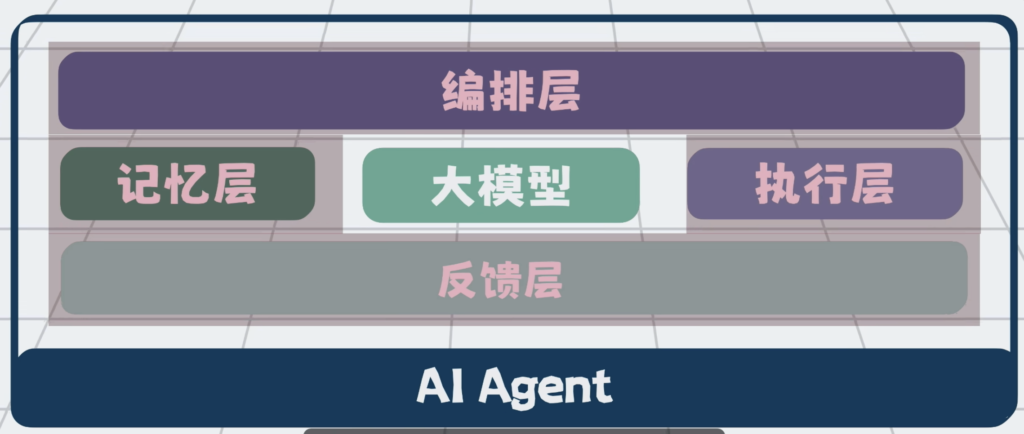
大模型越强,外壳就可以做的越薄,但无论怎么样,这层外壳都得有。
再给个公式,Agent = 大模型 + Harness,只要不是大模型的部分,那都属于Harness Engineering的范畴,存量程序员们好好看好好学,以后它就是我们的主战场了。
Harness Engineering 怎么落地? 🔖
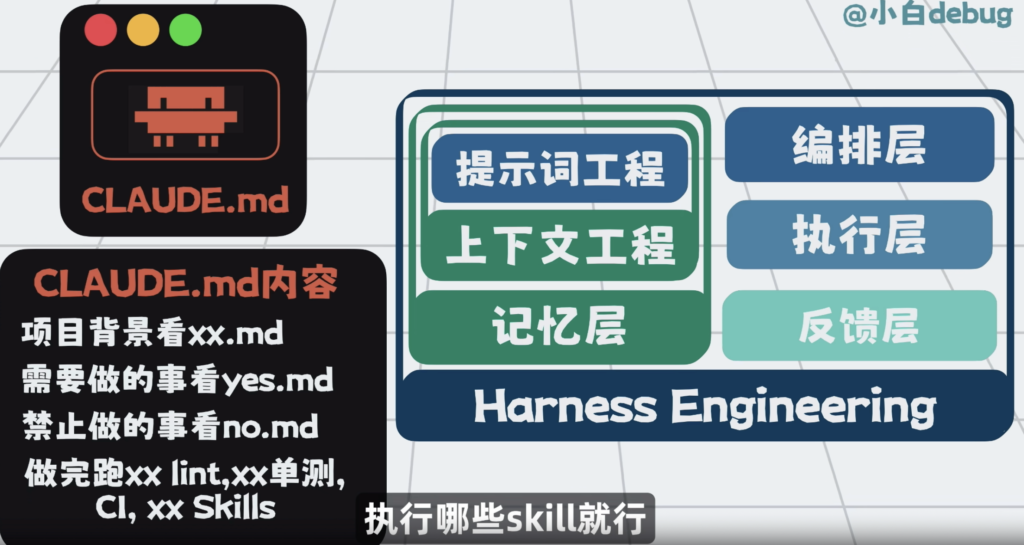
概念理解了,那最重要的问题来了,怎么落地?以Claude Code为例,Claude Code软件本身已经原生支持Harness的四层能力。
所以最轻量的做法,就是在Claude.md文件中,写清楚项目背景是什么?你希望大模型做什么?别做什么,做完之后要跑哪些lint,单测和CI执行哪些skill就行。
如果不想自己写着么累,那就引入一些插件比如spec-kit这类扩展,它会根据项目,将需求拆成多个阶段,做的事情也很简单。就是先生成对应的约束文件,明确需求,再指定具体开发计划,拆解任务,最后才是实际修改加测试。

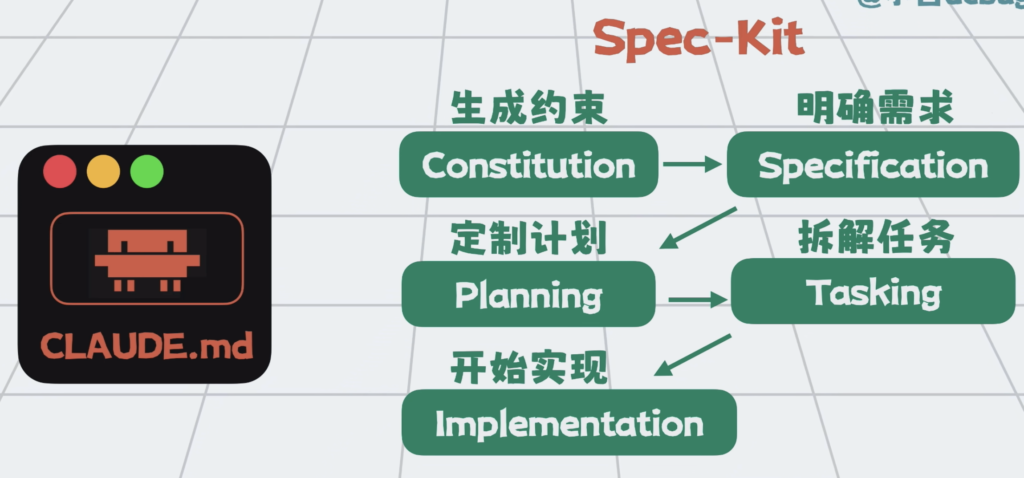
每个阶段都可能更新一次claude.md,这样每一阶段注入上下文的,尽可能都是核心信息。
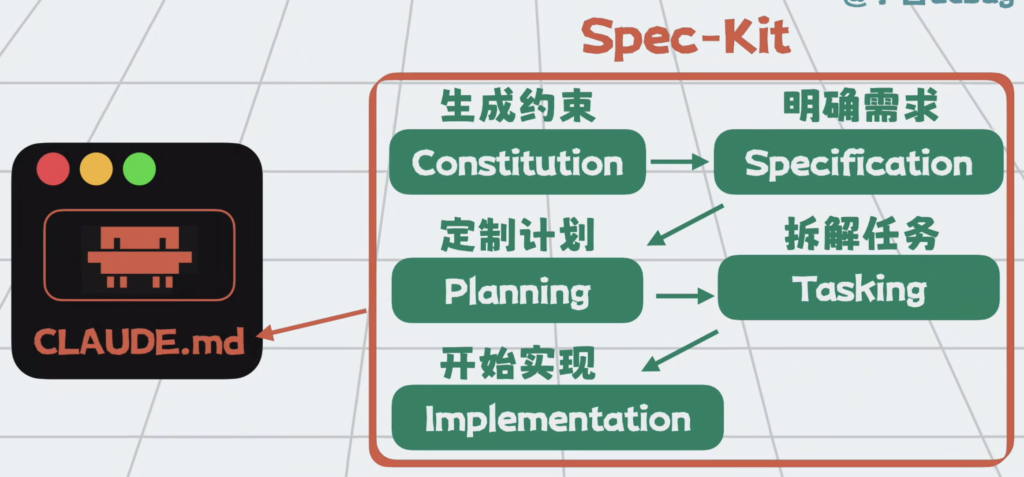
这套开发方式也叫Spec-Driven development,简称SDD。
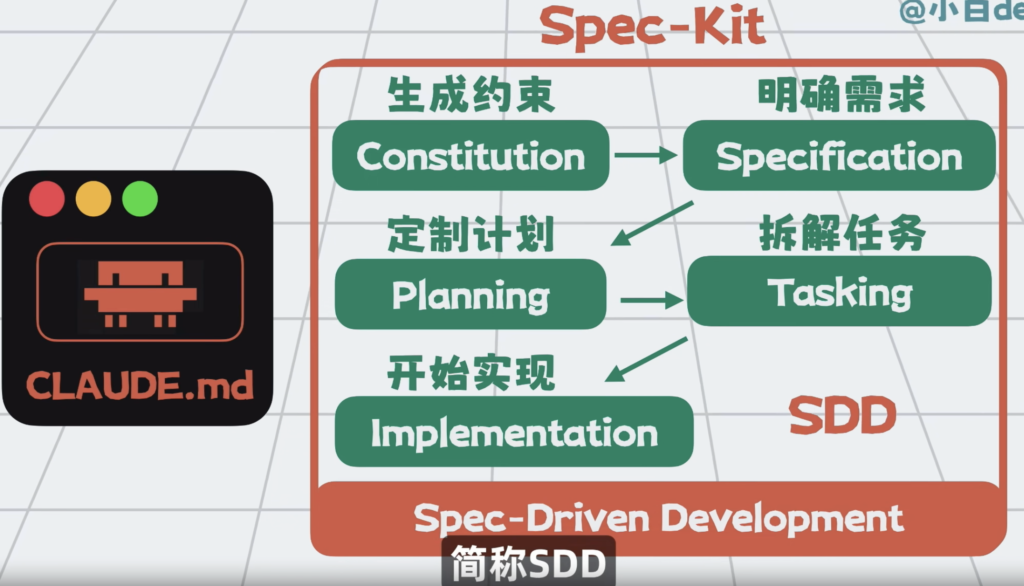
本质上做的事情,就是Harness Engineering 的落地,但是spec-kit整体还是不够强。我相信很快有更加全面的替代方案出现。
有了Harness Engineering之后,程序员的工作内容就从写代码,慢慢改为写规则和skill,所以有句话是这么说的,你那些拿了大礼包的同事,其实从未离开你,他只是变成了skill默默陪伴你。
提示词工程可以让大模型明白你的具体需求和输出标准,上下文工程可以给大模型注入精准有效的上下文。驾驭工程可以让大模型持续按规范执行任务,并最终交付,现在大家通了吗?