转载:小红书 AI产品赵哥
前言🔖
前几篇笔记我们聊了架构、组件、向量数据库和 RAG。如果你的产品通过了 Demo 阶段,开始准备上线面对真实用户,那么很抱歉的告诉你,你马上要迎来 AI 产品经理最头疼的两个难题:延迟(Latency)和成本(Cost)。
在本地测试时,调用一次 GPT-5 花 0.03 美元,等待 15 秒,你觉得没问题。但当你有 1 万个日活用户时,这 15 秒就是用户的流失率,这 0.03 美元乘以几万次调用,就是月底老板找你谈话的理由。
很多初级团队在这个阶段会陷入恐慌,盲目地去削减功能。其实,LangChain 作为一个成熟的框架,早就为生产环境优化准备了一套完整的工具箱。
今天的笔记,我们不聊新功能,只聊搞钱 —— 如何通过缓存、模型级联和批量处理,把你的 Token 成本打下来,把响应速度提上去。
我们今天的目标是:在不降低回答质量的前提下,将综合成本降低 80%。
缓存(Caching):最被低估的 “降本神器”🔖
在传统 Web 开发中,Redis 缓存是标配。但在 AI 开发中,很多人却忘了用。这是一个巨大的浪费。根据我的经验,在一个成熟的客服或咨询类 AI 产品中,20% ~ 30% 的用户提问是高度重复的。
如果用户问 “怎么修改密码”,你每次都去调用 GPT-5 重新生成一遍 “点击设置……,然后……”,这不仅慢,而且是在哐哐烧钱。
🔹1.1. 内存缓存与持久化缓存
LangChain 提供了极简的开关来启用缓存。
- 内存缓存(InMemoryCache):数据存在服务器 RAM 里。
- 优点:速度最快,微秒级。
- 缺点:重启服务就没了,多实例部署时无法共享。
- 持久化缓存(RedisCache / SQLiteCache):强烈建议生产环境使用 Redis。
- 优点:数据持久保存,多个后端服务可以共享同一个缓存库。
🔹1.2. 核心技术:语义缓存(Semantic Cache)
这是 AI 产品经理必须懂的概念。
传统的缓存是精确匹配(Exact Match)。
- 用户问:“今天天气怎么样?”→→ 缓存命中。
- 用户问:“今日天气如何?”→→ 缓存未命中(因为字符串不一样)。
这对 AI 来说太笨了。我们需要的是语义缓存。
LangChain 通过集成 GPTCache 或类似组件,实现了这一功能:
- 计算用户问题的向量(Embedding)。
- 在缓存库里找有没有 “意思相近” 的问题。
- 如果相似度超过 0.9,直接返回上次的答案。
具象化代码示例:
from langchain.globals import set_llm_cache
from langchain_community.cache import RedisCache
from redis import Redis
# 1. 连接 Redis
redis_client = Redis(host="localhost", port=6379, db=0)
# 2. 一行代码开启 LangChain 全局缓存
# 之后所有的 LLM 调用,都会先查 Redis
set_llm_cache(RedisCache(redis=redis_client))
# --- 测试 ---
# 第一次调用:慢,因为要请求 API
llm.invoke("告诉我万有引力定律是谁提出的")
#第二次调用:极快,直接从 Redis 拿结果,不消耗 Token
llm.invoke ("告诉我万有引力定律是谁提出的")
产品经理 Insight:
在 PRD 里,不要只写 “加缓存”。要定义 缓存策略:
- TTL (过期时间):答案能存多久?汇率查询可能只有 1 小时,公司介绍可能是永久。这个主要取决于不同信息的有效性。
- 相似度阈值:语义缓存多像算命中?建议 0.9 以上,否则容易答非所问。
模型级联与路由器(Model Switching):杀鸡焉用牛刀🔖
现在大家都在卷 GPT-5,但 80% 的用户请求其实根本不需要 GPT-5 的智商。
- 用户发:“你好”→→ 用 GPT-5 回复是极大的浪费。
- 用户发:“把这段话翻译成英文”→→ GPT-3.5 或 Haiku 足够了。
- 用户发:“分析这份财报的潜在风险”→→ 这才需要 GPT-5。
LangChain 允许我们构建模型级联(Model Cascading) 或路由器(Router),根据任务难度动态切换模型。
🔹方案 A:Fallbacks(失败回退)
这是最简单的容错策略。优先用便宜的模型,如果它搞不定(比如格式错了、报错了),再由昂贵的模型接手。
from langchain_openai import ChatOpenAI # 定义两个模型 gpt_35 = ChatOpenAI(model="gpt-3.5-turbo") gpt_4 = ChatOpenAI(model="GPT-5") # 构建带有回退机制的链 # 优先跑 gpt_35,如果报错,自动切 gpt_4 llm_with_fallback = gpt_35.with_fallbacks([gpt_4]) # 这种场景通常用于 JSON 格式化解析失败时自动救场
🔹方案 B:智能路由(Smart Routing)
这是高级玩法。利用一个小模型(如 Claude Haiku 或微调过的 Llama 3)作为分拣员。
逻辑如下:
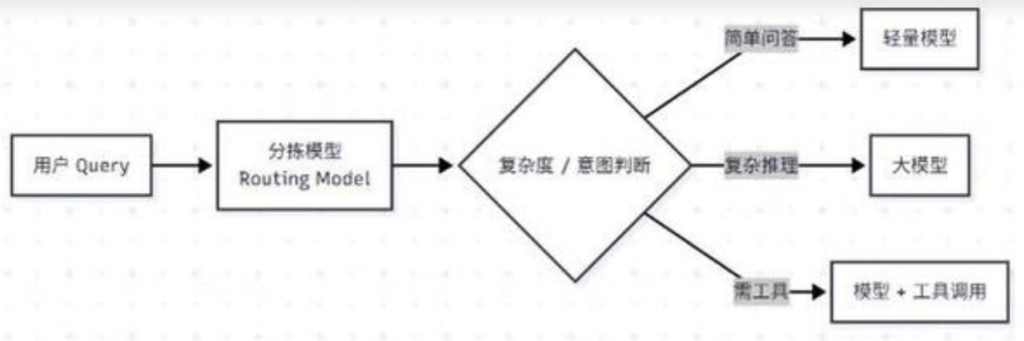
成本账:
- gpt-5.2 Input:$1.75 / 1M tokens
- gpt-3.5-turbo Input:$0.5 / 1M tokens
- Claude 3 Haiku Input:$0.25 / 1M tokens
如果你的分拣员能把 70% 的简单流量分给 Haiku,你的总 Token 成本将直接下降 10 倍。
产品经理 Insight:
不要迷信 “最好的模型”。在垂直场景下,经过 Prompt 优化的 3.5 版本往往性价比无敌。你需要建立一个测试集,去评估小模型在基础任务上的表现,如果通过率达标,果断降级。
批量处理(Batching):吞吐量提升神器🔖
如果你在做离线任务,比如 “给数据库里的 10,000 条用户评论打标签”,千万不要用 for 循环一条条调。串行处理不仅慢,而且容易触发 API 的并发限制报错。
LangChain 的核心组件(Runnables)都原生支持 .batch () 方法。它会自动利用 Python 的 asyncio 库进行并行处理,大幅提升吞吐量(Throughput)。
🔹并行与并发控制
这里有一个坑:虽然 .batch () 可以并行发 100 个请求,但 OpenAI 的接口通常有 Rate Limit(比如每分钟最多 5000 次)。如果瞬间并发太高,会直接被 429 错误打回来。
LangChain 允许配置 max_concurrency(最大并发数)。
伪代码
# 假设 chain 是我们要执行的处理链
inputs = [{"text": "评论1..."}, {"text": "评论2..."}, ...] # 1000条数据
# 自动批量处理,同时最多跑 5 个请求
# config 参数是控制并发的关键
results = chain.batch(inputs, config={"max_concurrency": 5})
产品经理 Insight:
对于非实时(即:User-facing)的功能,比如每天凌晨生成的日报、批量文档分析,Batching 是必须的要求。它能让原本跑一整晚的任务缩短到半小时。
上下文压缩(Context Compression):只给模型看它该看的🔖
在 RAG 场景中,成本的大头往往不是用户的几句提问,而是我们塞进 Prompt 里的那几千字参考文档。
朴素做法:检索出前 5 个文档块,原封不动塞给 LLM。
问题:文档块里可能只有一句话是有用的,其他 90% 都是废话。但你却为这些废话付了费。
LangChain 提供了 ContextualCompressionRetriever(上下文压缩检索器)。
🔹原理
在文档检索出来之后,在发给 LLM 之前,加一个压缩层。这个压缩层可以是另一个极小的 LLM,它的任务是:只保留与问题相关的句子,删掉无关的废话。
流程对比:
- 优化前:检索 3000 Tokens → 发送 LLM → 成本高
- 优化后:检索 3000 Tokens → 压缩层过滤 → 剩余 500 Tokens → 发送 LLM → 节省 80% 成本
虽然多了一次压缩的计算,但因为压缩可以用极小的模型(甚至是非 LLM 的算法),且主模型处理的 Token 大幅减少,整体延迟通常反而是降低的。
咱来算笔账:优化前 vs 优化后🔖
为了让你更有体感,咱来复盘一个真实的企业知识库问答项目的优化路径。
场景:每天 10,000 次问答,平均每次 Prompt 长度 2000 Tokens(含检索到的文档)。
🔹阶段 1:裸奔版(Naive RAG)
- 模型:全部使用 GPT-5。
- 策略:无缓存,无压缩。
- 日成本:10,000 * 2000 / 1000 * $0.03 (假设混合均价) ≈ $600 / 天
- 平均延迟:12 秒
🔹阶段 2:引入语义缓存(Redis + Embedding)
- 策略:命中率 30%(常见问题)。
- 日成本:剩余 7000 次调用 ≈ $420 / 天
- 平均延迟:命中时 0.5 秒,未命中 12 秒。
🔹阶段 3:模型级联(Router)
- 策略:使用 Router,将 50% 的简单问题(如打招呼、简单事实查询)分流给 GPT-3.5-turbo。
- GPT-5 调用量降至 3500 次。
- GPT-3.5 调用量 3500 次(成本极低,几乎可忽略)。
- 日成本:$220 / 天
🔹阶段 4:上下文压缩
- 策略:对 GPT-5 处理的那 3500 次复杂问题,进行 Context 压缩,Token 减少 60%。
- 日成本:$100 / 天
🔹最终结果
从 $600 降到 $100,成本降低了 83%。同时,由于缓存和简单模型分流的存在,平均响应速度从 12 秒提升到了 4 秒左右。
这样下来,你猜猜,你的老板会不会天天请你喝咖啡?🥺🥺🥺
产品经理的避坑清单🔖
在推动这些优化时,有几个点咱们得特别留意,不要被开发忽悠,也不要给开发挖坑:
- 缓存的负面效应:缓存可能导致 “数据更新不及时”。如果你修改了知识库文档,记得同步清空 Redis 里的相关缓存。这叫缓存失效机制(Cache Invalidation),PRD 里要提。
- 压缩的风险:上下文压缩如果压得太狠,可能会把关键信息丢掉。需要设置一个 min_tokens 或者压缩比的下限。
- Trace(链路追踪)的重要性:当你引入了 Router、Cache、Fallbacks 之后,系统链路会变得很复杂。出现 Bad Case 时,你需要知道到底是 Router 分错了,还是 Cache 里的旧数据,还是模型本身的问题。必须接入 LangSmith 进行全链路监控。
总结🔖
AI 应用开发,跑通 Demo 只是完成了 10% 的工作。剩下的 90% 都在做一件事:权衡。
在质量、速度、成本这个不可能三角中,LangChain 提供了丰富的调节旋钮:
- 想省钱?上 Cache 和 Model Switching。
- 想提速?上 Batching 和 Streaming。
- 想精简?上 Compression。
作为 AI 产品经理,你的价值就体现在如何根据业务形态,拧动这些旋钮,找到那个完美的平衡点。如果你已经把这些都掌握了,那你的 AI 应用已经具备了商业化的基础。