转载:https://blog.csdn.net/2401_84204207/article/details/150614914
前言🔖
在大型语言模型(LLM)日益普及的今天,检索增强生成(Retrieval-Augmented Generation,RAG)已成为提升 LLM 知识准确性和时效性的关键技术。它通过将 LLM 与外部知识库相结合,有效解决了 LLM 知识滞后和“幻觉”等问题。
然而,RAG 技术本身也在不断演进。从最初的传统 RAG 结构,到如今备受关注的 Agentic RAG(智能体式 RAG),RAG 系统正变得越来越智能、灵活和强大。本文将深入对比这两种 RAG 范式,揭示 Agentic RAG 如何通过引入“智能体”的概念,将 RAG 系统推向一个全新的高度。
传统 RAG🔖
🔹传统 RAG 结构:简洁与效率
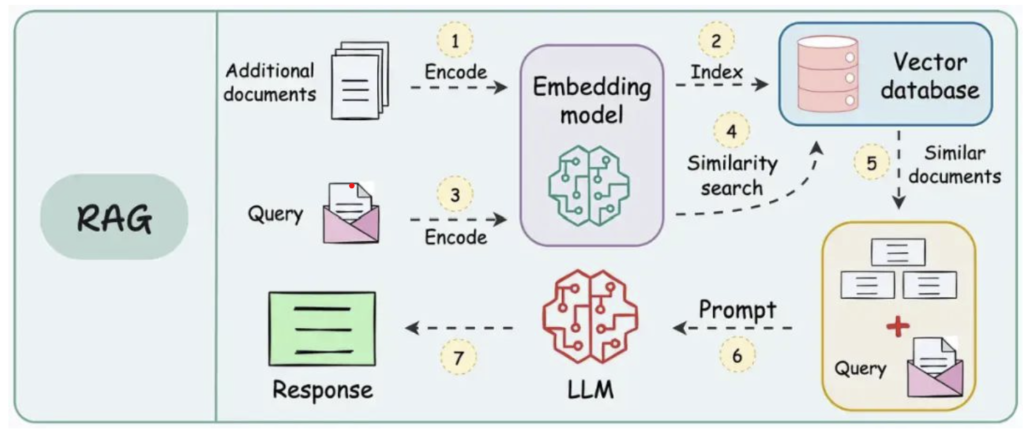
让我们首先回顾一下传统的 RAG 结构。如图所示,传统 RAG 的核心在于其线性、高效的 “检索-生成”流程。
🔹传统 RAG 的工作流程:
- 知识库编码与索引(步骤 1 & 2):
- 额外文档(Additional documents)首先通过嵌入模型(Embedding model)进行编码(Encode),将其内容转化为高维向量。这些向量随后被索引(Index)并存储到向量数据库(Vector database)中。这个过程通常是离线完成的,为后续的检索做好准备。
- 查询编码(步骤 3):
- 当用户输入一个查询(Query)时,这个查询也会通过相同的嵌入模型进行编码(Encode),生成其对应的查询向量。
- 相似性搜索(步骤 4 & 5):
- 查询向量被用来在向量数据库中进行相似性搜索(Similarity search),以找到与查询语义最接近的相似文档(Similar documents)。
- 提示构建与生成(步骤 6 & 7):
- 检索到的相似文档作为上下文(Context),与原始查询一起,被整合为一个提示(Prompt)。
- 这个提示被发送给大型语言模型(LLM)。
- LLM 基于提供的上下文和查询生成最终的响应(Response)。
🔹传统 RAG 的特点:
- 优点: 结构简单、流程清晰、易于实现,在处理直接、单跳的问答任务时效率高。
- 局限性: 线性流程使其在处理复杂、模糊或需要多步推理的查询时显得力不从心。它缺乏自我评估和主动规划的能力,容易受到检索结果质量的直接影响,可能导致“幻觉”或不准确的回答。
🔹传统RAG的缺点
RAG虽然是最简单的AI框架,但是没有人可以A领域调试后在B领域大范围推广应用,100多个参数没有多少人说的清楚怎怎么用。除此之外它还有很多缺点:
- 1)检索一次,生成一次。
- 这意味着如果检索到的上下文不够或不正确,LLM 就无法动态搜索更多信息。
- 2)无法通过复杂的查询进行推理。
- 如果查询需要多个检索步骤或 CoT(思路链),传统的 RAG 就不够了。
- 3)适应性有限
- 系统无法根据当前问题修改其策略。例如,是否进行向量搜索、网页搜索或调用 API。
Agentic RAG 🔖
智能体驱动的未来:循环、决策和工具使用的特性
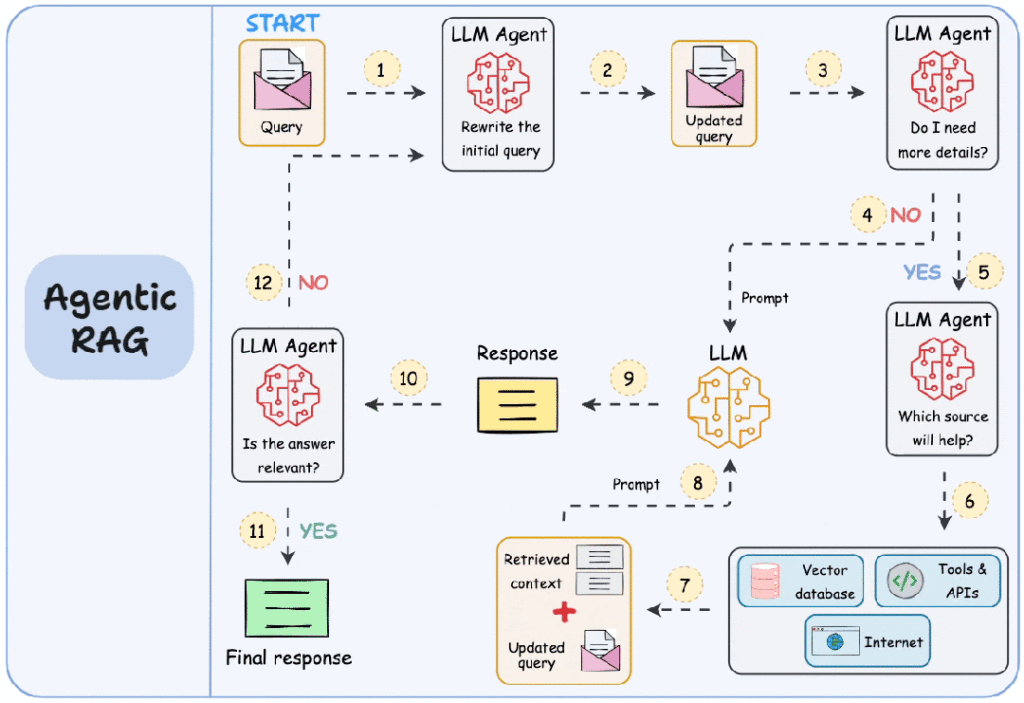
相较于传统 RAG 的线性流程,Agentic RAG 引入了“智能体”(Agent)的概念,赋予 LLM 更高的自主性和决策能力。如图所示,Agentic RAG 的核心在于其循环、决策和工具使用的特性。
Agentic RAG 解决了这些问题。 核心思想是在RAG的每个阶段引入代理行为。 代理可以积极思考任务——规划、调整和迭代以找到最佳解决方案,而不仅仅是遵循一组指令,而 LLM 可以实现这一点。
- 步骤1-2)用户输入查询,代理对其进行细化(纠正拼写、简化嵌入等)
- 步骤3)另一个代理决定是否需要更多详细信息。
- 步骤 4)如果不是,则将细化查询发送到 LLM。
- 步骤5-8)如果是,代理选择相关来源(矢量数据库、工具/API、互联网),检索上下文,并将其发送给 LLM。
- 步骤9)生成响应。
- 步骤 10)最后一个代理检查答案是否相关。
- 步骤 11)如果是,则返回响应。
- 步骤 12)如果没有,则从步骤 1 重新开始。
此过程重复,直到系统提供可接受的答案或承认它无法响应。 这使得 RAG 更加动态和稳健。 然而,值得注意的是,构建 RAG 系统通常取决于设计偏好和选择。 用户可以动态调整,使用具体领域case。
🔹Agentic RAG 的工作流程:
- 智能体主导的查询处理(步骤 1-3):
- 查询重写与思考: 初始查询不再直接进入检索,而是首先由 LLM 智能体(LLM Agent)进行重写,将其转化为更精确的查询。随后,智能体进行自我评估,判断是否需要更多信息。这是智能体主动思考的体现。
- 主动规划与工具选择(步骤 4-6):
- 如果智能体判断需要更多信息,它会进一步思考“哪一个源头能帮我?”,并主动选择并调用不同的工具(Tools & APIs)。这些工具不再局限于向量数据库,还可以包括互联网搜索、结构化数据库或其他自定义 API。这种工具使用能力是 Agentic RAG 的重要特征。
- 检索与生成(步骤 7-9):
- 检索与上下文构建(步骤 7): 系统会利用智能体选择的工具进行检索,并得到相关的检索到的上下文(Retrieved context)。这个上下文会与更新后的查询一起,为生成答案做准备。
- 生成初步响应(步骤 8 & 9): 系统将检索到的上下文和更新后的查询打包成一个提示(Prompt),发送给一个大型语言模型(LLM)。LLM 基于这个提示生成一个初步响应(Response)。
- 循环迭代与自我评估(步骤 10-12):
- 自我评估: 拿到初步响应后,LLM 智能体不会直接返回答案,而是会进行自我评估:“这个答案相关吗?”。
- 反馈循环: 如果智能体判断答案不相关,它可以循环回到初始查询或之前的步骤,重新规划、重新检索,直到找到满意的答案。这种反馈循环和自我修正能力是 Agentic RAG 解决复杂问题的关键。
🔹Agentic RAG 的特点:
- 优点:
- 更强的推理能力: 能够处理多跳查询和复杂逻辑推理。
- 更高的准确性: 通过自我评估和迭代,减少“幻觉”和不准确的回答。
- 更强的适应性: 能够根据任务需求,灵活选择和使用不同的外部工具。
- 更好的可解释性: 智能体的“思考”过程(如查询重写、工具选择)可以被记录和追踪。
- 局限性:
- 更高的复杂性: 引入了更多的决策和循环,系统设计和调试难度增加。
- 潜在的延迟: 多次迭代和工具调用可能导致更高的响应延迟。
当然缺点也很明显,每个阶段都调用大模型(也许是很小的模型,但是得专门训练),耗时资源部署可能存在风险。的历史都是曲折前进的,先解决有无,在提高效率。
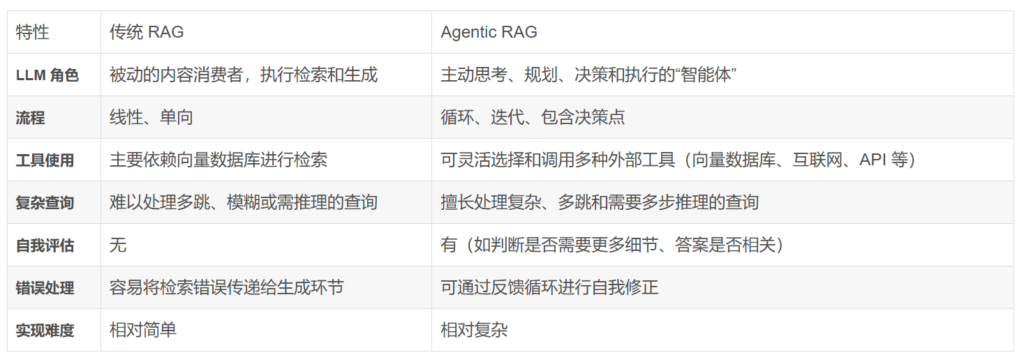
🔹汇总分析
传统 RAG 和 Agentic RAG 之间的主要区别: