LangChain 是啥?🔖
🔹想象你有一个超级智能的助手(比如 ChatGPT),但它只能回答简单问题。如果你想让它帮你:
- 查资料(比如最新的新闻)
- 处理长文档(比如总结一份 100 页的PDF)
- 连接其他工具(比如发邮件、算数学题)
- 记住之前的对话(比如聊了 10分钟还能接上话)
这时候就需要 LangChain, 它像一根”链条”,把 ChatGPT 和这些功能连在一起,让 Al 变得更强大、更自动化。
🔹LangChain 是一个为构建大型语言模型(LLMs)驱动的应用程序而设计的框架。它的核心目标是简化从开发到生产的整个应用程序生命周期。
- 模块化构建:LangChain 提供了一套模块化的构建块和组件,这些组件可以集成到第三方服务中,帮助开发者构建应用程序。
- 生命周期支持:LangChain 支持整个应用程序的生命周期,从开发到生产化再到部署。
- 开源与集成:它提供了开源的库和工具,以及与第三方服务的集成。
- 生产化工具:LangSmith 是一个开发平台,用于调试、测试、评估和监控基于LLM的应用程序。
- 部署:LangServe 允许将LangChain链作为REST API部署,从而方便应用程序的访问和使用。
LangChain 的核心功能(用生活例子比喻)🔖
🔹连接各种工具 (Chains)
例子:你想让 Al 帮你查天气,然后根据天气推荐穿搭。
- 普通 Al:只能回答”今天天气如何”,但不会主动推荐衣服。
- LangChain:自动先查天气一再告诉 Al一 Al 根据结果推荐”穿羽绒服”。
- 这就是”链” (Chain):把多个步骤串起来。
🔹长期记忆 (Memory)
例子:你和 Al聊天,上次你说”我喜欢吃辣”,下次它还能记得。
- 普通 Al:聊完就忘。
- LangChain:能自动保存聊天记录,下次说”推荐餐厅”时,Al 会说”你去川菜馆吧!”
🔹处理长文本 (Documents)
例子:你丢给 Al 一本 200 页的书,让它总结。
- 普通 Al:一次只能处理几段文字。
- LangChain:能把书拆成小块,分批处理,最后拼成一个完整总结。
🔹连接外部数据 (Retrieval)
例子:你想问 Al “公司去年销售额多少?
- 普通 Al:不知道你公司的数据。
- LangChain:能先帮你从公司数据库里查数据,再让 AI回答。
LangChain 怎么用?(举个真实场景) 🔖
场景:你想白动回复客户的邮件,内容要根据客户的历史订单生成。
- 步骤1:用 LangChain 连接你的邮箱(工具)。
- 步骤2:从数据库查客户过去的订单(外部数据)。
- 生骤3:让 Al根据订单写回复(比如“您上次买的鞋有新品!”)。
- 步骤4:自动发邮件(工具)。
全程不用人插手!这就是 LangChain 的威力。
为什么需要 LangChain? 🔖
- 普通 Al:像是一个只会回答问题的”学霸”,但不会动手干活。
- LangChain:像是给学霸配了一个秘书团队,能查资料、记笔记、跑腿办事。
LangChain RAG🔖
为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程,轻松地构建如下所示的 RAG 应用
检索增强生成(RAG, Retrieval-Augmented Generation)。该架构巧妙地整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。
🔹目前 LLM 面临的主要问题有:
- 信息偏差/幻觉: LLM 有时会产生与客观事实不符的信息,导致用户接收到的信息不准确。RAG 通过检索数据源,辅助模型生成过程,确保输出内容的精确性和可信度,减少信息偏差。
- 知识更新滞后性: LLM 基于静态的数据集训练,这可能导致模型的知识更新滞后,无法及时反映最新的信息动态。RAG 通过实时检索最新数据,保持内容的时效性,确保信息的持续更新和准确性。
- 内容不可追溯: LLM 生成的内容往往缺乏明确的信息来源,影响内容的可信度。RAG 将生成内容与检索到的原始资料建立链接,增强了内容的可追溯性,从而提升了用户对生成内容的信任度。
- 领域专业知识能力欠缺: LLM 在处理特定领域的专业知识时,效果可能不太理想,这可能会影响到其在相关领域的回答质量。RAG 通过检索特定领域的相关文档,为模型提供丰富的上下文信息,从而提升了在专业领域内的问题回答质量和深度。
- 推理能力限制: 面对复杂问题时,LLM 可能缺乏必要的推理能力,这影响了其对问题的理解和回答。RAG 结合检索到的信息和模型的生成能力,通过提供额外的背景知识和数据支持,增强了模型的推理和理解能力。
- 应用场景适应性受限: LLM 需在多样化的应用场景中保持高效和准确,但单一模型可能难以全面适应所有场景。RAG 使得 LLM 能够通过检索对应应用场景数据的方式,灵活适应问答系统、推荐系统等多种应用场景。
- 长文本处理能力较弱: LLM 在理解和生成长篇内容时受限于有限的上下文窗口,且必须按顺序处理内容,输入越长,速度越慢。RAG 通过检索和整合长文本信息,强化了模型对长上下文的理解和生成,有效突破了输入长度的限制,同时降低了调用成本,并提升了整体的处理效率。
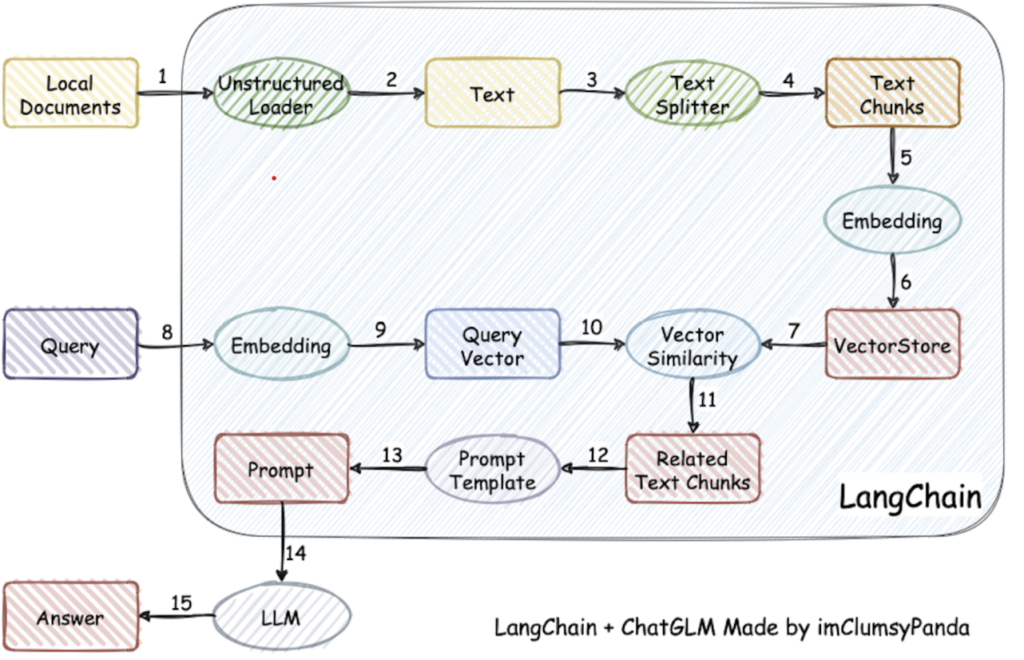
🔹RAG 是一个完整的系统,其工作流程可以简单地分为数据处理、检索、增强和生成四个阶段:
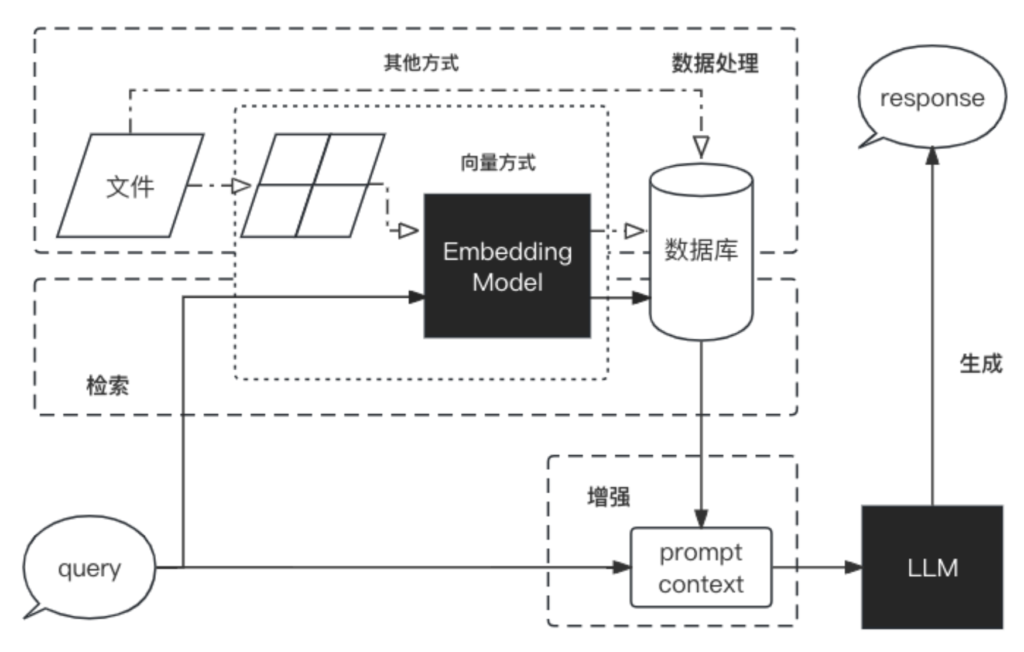
- 数据处理阶段
- 对原始数据进行清洗和处理。
- 将处理后的数据转化为检索模型可以使用的格式。
- 将处理后的数据存储在对应的数据库中。
- 检索阶段
- 将用户的问题输入到检索系统中,从数据库中检索相关信息。
- 增强阶段
- 对检索到的信息进行处理和增强,以便生成模型可以更好地理解和使用。
- 生成阶段
- 将增强后的信息输入到生成模型中,生成模型根据这些信息生成答案。
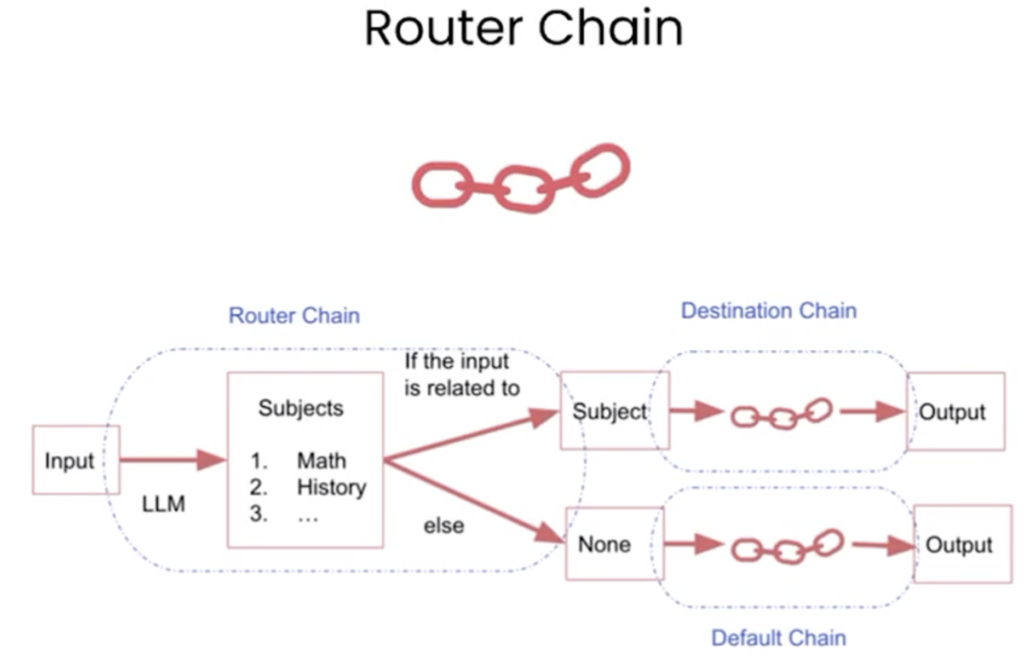
理解什么是agent,什么是chain🔖
- Chain:在LangChain中,Chain 是指一系列按顺序执行的任务或操作,这些任务通常涉及与语言模型的交互。Chain 可以被看作是处理输入、执行一系列决策和操作,最终产生输出的流程。Chain 可以是非常简单的,比如只有一个提示(prompt)和一个语言模型的调用;也可以是非常复杂的,涉及多个步骤和决策点。
- Agent:Agent 在LangChain中是一个更为高级和自主的实体,它负责管理和执行Chain。Agent 可以决定何时、如何以及以何种顺序执行Chain中的各个步骤。Agent 通常基于一组规则或策略来模拟决策过程,它们可以观察执行的结果,并根据这些结果来调整后续的行动。Agent 使得LangChain能够构建更为复杂和动态的应用程序,如自动化的聊天机器人或个性化的问答系统。
Agent:基于某模型实现的一个问答系统,就可以看做是一个Agent
Chain:问答系统需要根据一个prompt给出一个回答,这样的任务可以看做是一个Chain,当然,实际的回答过程一般是多个任务(Chain)一个接一个执行得到的。
🔹一个简单顺序链:

🔹一个更复杂一些的路由链:
RAG 和 微调(Finetune)🔖
在提升大语言模型效果中,RAG 和 微调(Finetune)是两种主流的方法
微调: 通过在特定数据集上进一步训练大语言模型,来提升模型在特定任务上的表现。
RAG 和 微调的对比可以参考下表:
| 特征比较 | RAG | 微调 |
|---|---|---|
| 知识更新 | 直接更新检索知识库,无需重新训练。信息更新成本低,适合动态变化的数据。 | 通常需要重新训练来保持知识和数据的更新。更新成本高,适合静态数据。 |
| 外部知识 | 擅长利用外部资源,特别适合处理文档或其他结构化/非结构化数据库。 | 将外部知识学习到 LLM 内部。 |
| 数据处理 | 对数据的处理和操作要求极低。 | 依赖于构建高质量的数据集,有限的数据集可能无法显著提高性能。 |
| 模型定制 | 侧重于信息检索和融合外部知识,但可能无法充分定制模型行为或写作风格。 | 可以根据特定风格或术语调整 LLM 行为、写作风格或特定领域知识。 |
| 可解释性 | 可以追溯到具体的数据来源,有较好的可解释性和可追踪性。 | 黑盒子,可解释性相对较低。 |
| 计算资源 | 需要额外的资源来支持检索机制和数据库的维护。 | 依赖高质量的训练数据集和微调目标,对计算资源的要求较高。 |
| 推理延迟 | 增加了检索步骤的耗时 | 单纯 LLM 生成的耗时 |
| 降低幻觉 | 通过检索到的真实信息生成回答,降低了产生幻觉的概率。 | 模型学习特定领域的数据有助于减少幻觉,但面对未见过的输入时仍可能出现幻觉。 |
| 伦理隐私 | 检索和使用外部数据可能引发伦理和隐私方面的问题。 | 训练数据中的敏感信息需要妥善处理,以防泄露。 |
LangChain核心组件 🔖
LangChian 作为一个大语言模型开发框架,可以将 LLM 模型(对话模型、embedding 模型等)、向量数据库、交互层 Prompt、外部知识、外部代理工具整合到一起,进而可以自由构建 LLM 应用。 LangChain 主要由以下 6 个核心组件组成:
- 模型输入/输出(Model I/O):与语言模型交互的接口
- 数据连接(Data connection):与特定应用程序的数据进行交互的接口
- 链(Chains):将组件组合实现端到端应用。比如像
检索问答链来完成检索问答。 - 记忆(Memory):用于链的多次运行之间持久化应用程序状态;
- 代理(Agents):扩展模型的推理能力。用于复杂的应用的调用序列,执行复杂任务和流程的关键组件,代理集成,以扩展其功能,连接到用户自己的信息源或API;
- 回调(Callbacks):扩展模型的推理能力。用于复杂的应用的调用序列;
在开发过程中,我们可以根据自身需求灵活地进行组合。
总结 🔖
- LangChain 二 Al 的“外挂”:让AI 能调用其他工具、记住
历史、处理复杂任务。 - 核心用途:自动化、 个性化、处理长文本/数据。
- 小白理解:已就是一套”乐高积木”,把 Al和其他功能拼在一起,搭出更牛的东西。