在生产环境中,慢SQL就像是系统性能的隐形杀手,一条糟糕的查询可能拖垮整个数据库!本文将从慢SQL的识别、分析到优化,为你提供一套完整的解决方案。
什么是慢SQL?
慢SQL(Slow Query)是指执行时间超过预设阈值的SQL查询语句。通常来说:
- • 在线业务:执行时间超过100ms的查询
- • 报表系统:执行时间超过5秒的查询
- • 数据分析:执行时间超过30秒的查询
简单来说:慢SQL = 执行时间长 + 影响系统性能
慢SQL的危害
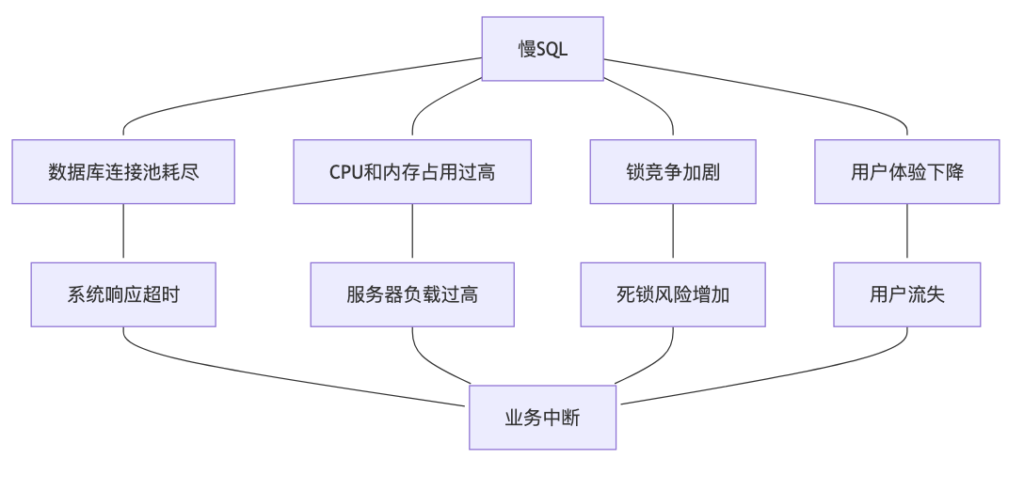
慢SQL识别方法
1. MySQL慢查询日志
开启慢查询日志:
-- 查看慢查询配置 SHOW VARIABLES LIKE '%slow_query%'; SHOW VARIABLES LIKE 'long_query_time'; -- 开启慢查询日志 SET GLOBAL slow_query_log = 'ON'; SET GLOBAL long_query_time = 0.1; -- 设置阈值为0.1秒 SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';
分析慢查询日志:
# 使用mysqldumpslow分析 mysqldumpslow -s c -t 10 /var/log/mysql/slow.log # 参数说明: # -s c: 按查询次数排序 # -s t: 按查询时间排序 # -s l: 按锁定时间排序 # -t 10: 显示前10条
2. Performance Schema监控
-- 开启Performance Schema
UPDATE performance_schema.setup_instruments
SET ENABLED ='YES', TIMED ='YES'
WHERE NAME LIKE'%statement/%';
-- 查询最慢的SQL
SELECT
SCHEMA_NAME,
DIGEST_TEXT,
COUNT_STAR,
AVG_TIMER_WAIT/1000000000AS avg_time_seconds,
MAX_TIMER_WAIT/1000000000AS max_time_seconds
FROM performance_schema.events_statements_summary_by_digest
ORDERBY AVG_TIMER_WAIT DESC
LIMIT 10;
3. 实时监控工具
// Spring Boot集成慢SQL监控
@Component
@Slf4j
publicclassSlowSqlInterceptorimplementsInterceptor {
privatestaticfinallongSLOW_SQL_THRESHOLD=100; // 100ms
@Override
public Object intercept(Invocation invocation)throws Throwable {
longstartTime= System.currentTimeMillis();
try {
return invocation.proceed();
} finally {
longendTime= System.currentTimeMillis();
longexecuteTime= endTime - startTime;
if (executeTime > SLOW_SQL_THRESHOLD) {
// 记录慢SQL
logSlowSql(invocation, executeTime);
// 发送告警
sendSlowSqlAlert(invocation, executeTime);
}
}
}
privatevoidlogSlowSql(Invocation invocation, long executeTime) {
MappedStatementms= (MappedStatement) invocation.getArgs()[0];
BoundSqlboundSql= ms.getBoundSql(invocation.getArgs()[1]);
log.warn("慢SQL检测 - 执行时间: {}ms, SQL: {}",
executeTime, boundSql.getSql());
}
privatevoidsendSlowSqlAlert(Invocation invocation, long executeTime) {
// 发送钉钉/邮件告警
SlowSqlAlertalert= SlowSqlAlert.builder()
.executeTime(executeTime)
.sql(getSqlFromInvocation(invocation))
.timestamp(newDate())
.build();
alertService.sendSlowSqlAlert(alert);
}
}
慢SQL分析工具
1. EXPLAIN执行计划分析
-- 基本EXPLAIN分析 EXPLAIN SELECT*FROM orders o LEFTJOIN order_items oi ON o.id = oi.order_id WHERE o.create_time >='2024-01-01'; -- 详细的执行计划 EXPLAIN FORMAT=JSON SELECT*FROM orders o LEFTJOIN order_items oi ON o.id = oi.order_id WHERE o.create_time >='2024-01-01';
EXPLAIN结果解读:
| 字段 | 含义 | 关键值 |
| id | 查询序列号 | 数字越大越先执行 |
| select_type | 查询类型 | SIMPLE、UNION、SUBQUERY |
| table | 表名 | 当前操作的表 |
| type | 访问类型 | system > const > eq_ref > ref > range > index > ALL |
| key | 使用的索引 | NULL表示未使用索引 |
| rows | 扫描行数 | 越少越好 |
| Extra | 额外信息 | Using filesort、Using temporary需要关注 |
2. 自定义分析工具
// SQL性能分析器
@Component
publicclassSqlPerformanceAnalyzer {
public SqlAnalysisResult analyzeSql(String sql, Object... params) {
SqlAnalysisResultresult=newSqlAnalysisResult();
try {
// 1. 执行EXPLAIN
ExplainResultexplainResult= executeExplain(sql, params);
result.setExplainResult(explainResult);
// 2. 分析执行计划
List<OptimizationSuggestion> suggestions = analyzeExplainResult(explainResult);
result.setSuggestions(suggestions);
// 3. 检查索引使用情况
IndexUsageAnalysisindexAnalysis= analyzeIndexUsage(explainResult);
result.setIndexAnalysis(indexAnalysis);
// 4. 评估查询复杂度
ComplexityScorecomplexityScore= calculateComplexity(sql);
result.setComplexityScore(complexityScore);
} catch (Exception e) {
log.error("SQL分析失败", e);
}
return result;
}
private List<OptimizationSuggestion> analyzeExplainResult(ExplainResult explainResult) {
List<OptimizationSuggestion> suggestions = newArrayList<>();
for (ExplainRow row : explainResult.getRows()) {
// 检查是否全表扫描
if ("ALL".equals(row.getType())) {
suggestions.add(OptimizationSuggestion.builder()
.type(SuggestionType.ADD_INDEX)
.description("表 " + row.getTable() + " 存在全表扫描,建议添加索引")
.priority(Priority.HIGH)
.build());
}
// 检查是否使用了临时表
if (row.getExtra().contains("Using temporary")) {
suggestions.add(OptimizationSuggestion.builder()
.type(SuggestionType.OPTIMIZE_GROUP_BY)
.description("查询使用了临时表,考虑优化GROUP BY或ORDER BY")
.priority(Priority.MEDIUM)
.build());
}
// 检查扫描行数
if (row.getRows() > 10000) {
suggestions.add(OptimizationSuggestion.builder()
.type(SuggestionType.ADD_WHERE_CONDITION)
.description("扫描行数过多(" + row.getRows() + "),建议添加WHERE条件")
.priority(Priority.HIGH)
.build());
}
}
return suggestions;
}
}
慢SQL优化策略
1. 索引优化
创建合适的索引:
-- 单列索引 CREATE INDEX idx_order_create_time ON orders(create_time); -- 复合索引(注意顺序) CREATE INDEX idx_order_status_time ON orders(status, create_time); -- 覆盖索引 CREATE INDEX idx_order_cover ON orders(user_id, status, create_time, amount); -- 函数索引(MySQL 8.0+) CREATE INDEX idx_order_year ON orders((YEAR(create_time)));
索引设计原则:
| 原则 | 说明 | 示例 |
| 最左前缀原则 | 复合索引只能从最左边的列开始使用 | 索引(a,b,c)可匹配:a, a+b, a+b+c 不能匹配:b, c, b+c |
| 区分度高的列在前 | 选择性高的列放在复合索引前面 | user_id(百万个值) + gender(2个值) 应该是:(user_id, gender) |
| 范围查询列放最后 | 范围条件会停止索引的后续匹配 | WHERE user_id=? AND status=? AND create_time>? 索引:(user_id, status, create_time) |
| 考虑覆盖索引 | 索引包含查询所需的所有列,避免回表 | SELECT id,name FROM user WHERE age=? 索引:(age, id, name) |
| 避免冗余索引 | 不要创建功能重复的索引 | 有了(a,b,c)就不要再创建(a,b) |
具体应用示例:
-- 案例1:最左前缀原则 CREATE INDEX idx_user_status_time ON orders(user_id, status, create_time); -- ✅ 以下查询能使用索引 SELECT*FROM orders WHERE user_id =123; SELECT*FROM orders WHERE user_id =123AND status ='PAID'; SELECT*FROM orders WHERE user_id =123AND status ='PAID'AND create_time >'2024-01-01'; -- ❌ 以下查询不能使用索引 SELECT*FROM orders WHERE status ='PAID'; SELECT*FROM orders WHERE create_time >'2024-01-01'; SELECT*FROM orders WHERE status ='PAID'AND create_time >'2024-01-01'; -- 案例2:区分度原则 -- 假设用户表有100万条记录,其中性别只有2个值,城市有1000个值 -- ❌ 错误的索引顺序 CREATE INDEX idx_wrong ON users(gender, city, user_id); -- ✅ 正确的索引顺序 CREATE INDEX idx_correct ON users(user_id, city, gender); -- 案例3:覆盖索引 -- 查询:SELECT user_id, amount, create_time FROM orders WHERE status = 'PAID'; -- ✅ 覆盖索引,避免回表 CREATE INDEX idx_status_cover ON orders(status, user_id, amount, create_time); -- 案例4:范围查询优化 -- 查询:WHERE user_id = ? AND status = ? AND create_time BETWEEN ? AND ? -- ✅ 正确的索引设计 CREATE INDEX idx_user_status_time ON orders(user_id, status, create_time); -- 等值条件在前,范围条件在后
2. SQL语句优化
常见优化技巧:
-- 1. 避免SELECT * -- ❌ 不推荐 SELECT*FROM orders WHERE user_id =12345; -- ✅ 推荐 SELECT id, user_id, amount, status, create_time FROM orders WHERE user_id =12345; -- 2. 使用LIMIT限制返回结果 -- ❌ 不推荐 SELECT*FROM orders WHERE status ='PENDING'; -- ✅ 推荐 SELECT id, amount FROM orders WHERE status ='PENDING' LIMIT 100; -- 3. 优化分页查询 -- ❌ 深分页效率低 SELECT*FROM orders ORDERBY id LIMIT 100000, 20; -- ✅ 使用游标分页 SELECT*FROM orders WHERE id >100000ORDERBY id LIMIT 20; -- 4. 避免在WHERE子句中使用函数 -- ❌ 不推荐 SELECT*FROM orders WHEREYEAR(create_time) =2024; -- ✅ 推荐 SELECT*FROM orders WHERE create_time >='2024-01-01'AND create_time <'2025-01-01'; -- 5. 使用EXISTS替代IN(大数据集) -- ❌ 子查询返回大量数据时效率低 SELECT*FROM users u WHERE u.id IN (SELECT user_id FROM orders WHERE amount >1000); -- ✅ 推荐 SELECT*FROM users u WHEREEXISTS (SELECT1FROM orders o WHERE o.user_id = u.id AND o.amount >1000);
3. JOIN优化
-- JOIN优化策略 -- 1. 小表驱动大表 -- ❌ 大表在前 SELECT*FROM big_table b JOIN small_table s ON b.id = s.big_id; -- ✅ 小表在前(MySQL会自动优化,但明确更好) SELECT*FROM small_table s JOIN big_table b ON s.big_id = b.id; -- 2. 确保JOIN条件有索引 -- 确保both tables的JOIN字段都有索引 CREATE INDEX idx_orders_user_id ON orders(user_id); CREATE INDEX idx_users_id ON users(id); -- 主键自动有索引 -- 3. 避免笛卡尔积 -- ❌ 缺少JOIN条件 SELECT*FROM orders o, order_items oi WHERE o.status ='PENDING'; -- ✅ 正确的JOIN SELECT*FROM orders o JOIN order_items oi ON o.id = oi.order_id WHERE o.status ='PENDING'; -- 4. 使用适当的JOIN类型 -- INNER JOIN vs LEFT JOIN vs RIGHT JOIN -- 只获取需要的数据
实战优化案例
案例1:慢查询优化
问题SQL:
-- 执行时间:2.5秒 SELECT u.name, u.email, COUNT(o.id) as order_count, SUM(o.amount) as total_amount FROM users u LEFT JOIN orders o ON u.id = o.user_id WHERE u.register_time >= '2024-01-01' AND o.create_time >= '2023-01-01' GROUP BY u.id, u.name, u.email ORDER BY total_amount DESC LIMIT 100;
分析过程:
-- 1. 查看执行计划 EXPLAIN SELECT u.name, u.email, COUNT(o.id) as order_count, SUM(o.amount) as total_amount FROM users u LEFTJOIN orders o ON u.id = o.user_id WHERE u.register_time >='2024-01-01' AND o.create_time >='2023-01-01' GROUPBY u.id, u.name, u.email ORDERBY total_amount DESC LIMIT 100; -- 执行计划显示: -- 1. users表全表扫描 (type: ALL) -- 2. orders表全表扫描 (type: ALL) -- 3. 使用了临时表和文件排序 (Extra: Using temporary; Using filesort)
优化步骤:
-- 1. 添加必要的索引
CREATE INDEX idx_users_register_time ON users(register_time);
CREATE INDEX idx_orders_user_create ON orders(user_id, create_time);
-- 2. 优化后的SQL
SELECT u.name, u.email,
COUNT(o.id) as order_count,
SUM(o.amount) as total_amount
FROM users u
LEFTJOIN orders o ON u.id = o.user_id
AND o.create_time >='2023-01-01'-- 将条件移到JOIN中
WHERE u.register_time >='2024-01-01'
GROUPBY u.id, u.name, u.email
ORDERBY total_amount DESC
LIMIT 100;
-- 3. 进一步优化 - 使用子查询预先过滤
SELECT u.name, u.email,
COALESCE(order_stats.order_count, 0) as order_count,
COALESCE(order_stats.total_amount, 0) as total_amount
FROM users u
LEFTJOIN (
SELECT user_id,
COUNT(*) as order_count,
SUM(amount) as total_amount
FROM orders
WHERE create_time >='2023-01-01'
GROUPBY user_id
) order_stats ON u.id = order_stats.user_id
WHERE u.register_time >='2024-01-01'
ORDERBY total_amount DESC
LIMIT 100;
优化结果:
- • 执行时间:2.5秒 → 0.08秒
- • 性能提升:31倍
案例2:分页查询优化
// 深分页优化
@Service
publicclassOrderQueryService {
/**
* 传统分页 - 性能差
*/
public PageResult<Order> getOrdersByTraditionalPaging(int page, int size) {
intoffset= (page - 1) * size;
// 深分页时,MySQL需要扫描很多不需要的数据
Stringsql="SELECT * FROM orders ORDER BY id LIMIT ?, ?";
return queryWithPaging(sql, offset, size);
}
/**
* 游标分页 - 性能好
*/
public PageResult<Order> getOrdersByCursorPaging(Long lastId, int size) {
Stringsql="SELECT * FROM orders WHERE id > ? ORDER BY id LIMIT ?";
List<Order> orders = jdbcTemplate.query(sql,
newObject[]{lastId, size},
newOrderRowMapper());
LongnextCursor= orders.isEmpty() ? null :
orders.get(orders.size() - 1).getId();
return PageResult.<Order>builder()
.data(orders)
.nextCursor(nextCursor)
.hasNext(orders.size() == size)
.build();
}
/**
* 延迟关联优化深分页
*/
public PageResult<Order> getOrdersByDeferredJoin(int page, int size) {
intoffset= (page - 1) * size;
// 先查询ID,再关联查询详细信息
Stringsql="""
SELECT o.* FROM orders o
INNER JOIN (
SELECT id FROM orders ORDER BY id LIMIT ?, ?
) temp ON o.id = temp.id
""";
return queryWithPaging(sql, offset, size);
}
}
案例3:复杂统计查询优化
-- 原始慢查询:统计每月销售数据
-- 执行时间:8.2秒
SELECT
DATE_FORMAT(create_time, '%Y-%m') asmonth,
COUNT(*) as order_count,
SUM(amount) as total_amount,
AVG(amount) as avg_amount,
COUNT(DISTINCT user_id) as unique_users
FROM orders
WHERE create_time >='2023-01-01'AND create_time <'2024-01-01'
AND status ='COMPLETED'
GROUPBY DATE_FORMAT(create_time, '%Y-%m')
ORDERBYmonth;
-- 优化方案1:添加合适的索引
CREATE INDEX idx_orders_status_time ON orders(status, create_time);
-- 优化方案2:使用汇总表(推荐)
-- 创建月度汇总表
CREATE TABLE order_monthly_stats (
monthDATE,
order_count INT,
total_amount DECIMAL(15,2),
avg_amount DECIMAL(10,2),
unique_users INT,
PRIMARY KEY (month)
);
-- 定时任务更新汇总表
INSERT INTO order_monthly_stats
SELECT
DATE_FORMAT(create_time, '%Y-%m-01') asmonth,
COUNT(*) as order_count,
SUM(amount) as total_amount,
AVG(amount) as avg_amount,
COUNT(DISTINCT user_id) as unique_users
FROM orders
WHERE create_time >='2024-01-01'AND create_time <'2024-02-01'
AND status ='COMPLETED'
GROUPBY DATE_FORMAT(create_time, '%Y-%m-01')
ON DUPLICATE KEY UPDATE
order_count =VALUES(order_count),
total_amount =VALUES(total_amount),
avg_amount =VALUES(avg_amount),
unique_users =VALUES(unique_users);
-- 查询汇总表(毫秒级响应)
SELECT*FROM order_monthly_stats
WHEREmonth>='2023-01-01'ANDmonth<'2024-01-01'
ORDERBYmonth;
📈 监控和预防
1. 慢SQL监控系统
// 慢SQL监控配置
@Configuration
@EnableConfigurationProperties(SlowSqlProperties.class)
publicclassSlowSqlMonitorConfig {
@Bean
public SlowSqlMonitor slowSqlMonitor(SlowSqlProperties properties) {
return SlowSqlMonitor.builder()
.threshold(properties.getThreshold())
.alertEnabled(properties.isAlertEnabled())
.alertWebhook(properties.getAlertWebhook())
.build();
}
@Bean
public SqlMetricsCollector sqlMetricsCollector() {
returnnewSqlMetricsCollector();
}
}
@Component
@Slf4j
publicclassSqlMetricsCollector {
privatefinal MeterRegistry meterRegistry;
privatefinal Counter slowSqlCounter;
privatefinal Timer sqlExecutionTimer;
publicSqlMetricsCollector(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
this.slowSqlCounter = Counter.builder("slow_sql_total")
.description("Total number of slow SQL queries")
.register(meterRegistry);
this.sqlExecutionTimer = Timer.builder("sql_execution_time")
.description("SQL execution time")
.register(meterRegistry);
}
publicvoidrecordSlowSql(String sql, long executionTime) {
slowSqlCounter.increment(
Tags.of(
"sql_hash", DigestUtils.md5Hex(sql),
"execution_time_range", getTimeRange(executionTime)
)
);
sqlExecutionTimer.record(executionTime, TimeUnit.MILLISECONDS);
log.warn("慢SQL告警 - 执行时间: {}ms, SQL: {}", executionTime, sql);
}
private String getTimeRange(long executionTime) {
if (executionTime < 1000) return"0-1s";
if (executionTime < 5000) return"1-5s";
if (executionTime < 10000) return"5-10s";
return"10s+";
}
}
2. 数据库连接池监控
// HikariCP连接池监控
@Component
publicclassConnectionPoolMonitor {
@Autowired
private HikariDataSource dataSource;
@Scheduled(fixedRate = 30000)// 每30秒检查一次
publicvoidmonitorConnectionPool() {
HikariPoolMXBeanpoolMXBean= dataSource.getHikariPoolMXBean();
intactiveConnections= poolMXBean.getActiveConnections();
intidleConnections= poolMXBean.getIdleConnections();
inttotalConnections= poolMXBean.getTotalConnections();
intthreadsAwaitingConnection= poolMXBean.getThreadsAwaitingConnection();
// 记录指标
Metrics.gauge("hikari.active_connections", activeConnections);
Metrics.gauge("hikari.idle_connections", idleConnections);
Metrics.gauge("hikari.total_connections", totalConnections);
Metrics.gauge("hikari.threads_awaiting_connection", threadsAwaitingConnection);
// 告警检查
if (activeConnections > totalConnections * 0.8) {
log.warn("连接池使用率过高: {}/{}", activeConnections, totalConnections);
}
if (threadsAwaitingConnection > 0) {
log.error("有{}个线程等待数据库连接", threadsAwaitingConnection);
}
}
}
3. 自动化SQL审核
// SQL审核规则引擎
@Component
publicclassSqlAuditEngine {
privatefinal List<SqlAuditRule> auditRules;
publicSqlAuditEngine() {
this.auditRules = Arrays.asList(
newSelectStarRule(),
newMissingWhereRule(),
newLargeOffsetRule(),
newFunctionInWhereRule(),
newTooManyJoinRule()
);
}
public SqlAuditResult audit(String sql) {
SqlAuditResultresult=newSqlAuditResult();
for (SqlAuditRule rule : auditRules) {
RuleViolationviolation= rule.check(sql);
if (violation != null) {
result.addViolation(violation);
}
}
return result;
}
}
// 具体的审核规则
publicclassSelectStarRuleimplementsSqlAuditRule {
@Override
public RuleViolation check(String sql) {
if (sql.toUpperCase().contains("SELECT *")) {
return RuleViolation.builder()
.ruleId("SELECT_STAR")
.severity(Severity.MEDIUM)
.message("避免使用SELECT *,明确指定需要的列")
.suggestion("将SELECT *改为具体的列名")
.build();
}
returnnull;
}
}
publicclassMissingWhereRuleimplementsSqlAuditRule {
@Override
public RuleViolation check(String sql) {
StringupperSql= sql.toUpperCase();
if ((upperSql.contains("UPDATE") || upperSql.contains("DELETE"))
&& !upperSql.contains("WHERE")) {
return RuleViolation.builder()
.ruleId("MISSING_WHERE")
.severity(Severity.HIGH)
.message("UPDATE/DELETE语句缺少WHERE条件,可能导致全表操作")
.suggestion("添加WHERE条件限制操作范围")
.build();
}
returnnull;
}
}
💡 优化最佳实践
1. 索引设计最佳实践
-- 索引设计检查清单
-- ✅ 良好的索引设计
CREATE TABLE orders (
id BIGINTPRIMARY KEY AUTO_INCREMENT,
user_id BIGINTNOT NULL,
status VARCHAR(20) NOT NULL,
amount DECIMAL(10,2) NOT NULL,
create_time DATETIME NOT NULL,
update_time DATETIME NOT NULL,
-- 基础索引
INDEX idx_user_id (user_id),
INDEX idx_status (status),
INDEX idx_create_time (create_time),
-- 复合索引(常用查询组合)
INDEX idx_user_status (user_id, status),
INDEX idx_status_time (status, create_time),
-- 覆盖索引(避免回表)
INDEX idx_user_cover (user_id, status, amount, create_time)
);
-- 索引命名规范
-- idx_{table}_{columns} 或 idx_{purpose}
2. 查询编写规范
// SQL编写最佳实践
@Repository
publicclassOrderRepository {
/**
* ✅ 好的查询示例
*/
public List<Order> findUserOrdersGood(Long userId, String status,
LocalDateTime startTime, int limit) {
Stringsql="""
SELECT id, user_id, status, amount, create_time
FROM orders
WHERE user_id = ?
AND status = ?
AND create_time >= ?
ORDER BY create_time DESC
LIMIT ?
""";
return jdbcTemplate.query(sql,
newObject[]{userId, status, startTime, limit},
newOrderRowMapper());
}
/**
* ❌ 不好的查询示例
*/
public List<Order> findUserOrdersBad(Long userId, String status,
LocalDateTime startTime) {
// 问题1:SELECT *
// 问题2:没有LIMIT
// 问题3:可能返回大量数据
Stringsql="""
SELECT * FROM orders
WHERE user_id = ?
AND status = ?
AND YEAR(create_time) = YEAR(?)
ORDER BY create_time DESC
""";
return jdbcTemplate.query(sql,
newObject[]{userId, status, startTime},
newOrderRowMapper());
}
/**
* 分页查询最佳实践
*/
public PageResult<Order> findOrdersWithPaging(OrderQuery query) {
// 使用游标分页避免深分页问题
if (query.getLastId() != null) {
return findOrdersByCursor(query);
} else {
return findOrdersByOffset(query);
}
}
}
3. 数据库设计规范
-- 数据库设计最佳实践
-- 1. 表结构设计
CREATE TABLE user_orders (
id BIGINTPRIMARY KEY AUTO_INCREMENT,
user_id BIGINTNOT NULL COMMENT '用户ID',
order_no VARCHAR(32) NOT NULL COMMENT '订单号',
status TINYINT NOT NULLDEFAULT0 COMMENT '状态:0待付款,1已付款,2已发货,3已完成',
amount DECIMAL(10,2) NOT NULL COMMENT '订单金额',
create_time DATETIME NOT NULLDEFAULTCURRENT_TIMESTAMP COMMENT '创建时间',
update_time DATETIME NOT NULLDEFAULTCURRENT_TIMESTAMPONUPDATECURRENT_TIMESTAMP,
-- 索引设计
UNIQUE KEY uk_order_no (order_no),
KEY idx_user_id (user_id),
KEY idx_status (status),
KEY idx_create_time (create_time),
KEY idx_user_status_time (user_id, status, create_time)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户订单表';
-- 2. 分区表(大数据量)
CREATE TABLE orders_partitioned (
id BIGINTPRIMARY KEY AUTO_INCREMENT,
user_id BIGINTNOT NULL,
amount DECIMAL(10,2) NOT NULL,
create_time DATETIME NOT NULL,
KEY idx_user_id (user_id),
KEY idx_create_time (create_time)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
PARTITIONBYRANGE (TO_DAYS(create_time)) (
PARTITION p202401 VALUES LESS THAN (TO_DAYS('2024-02-01')),
PARTITION p202402 VALUES LESS THAN (TO_DAYS('2024-03-01')),
PARTITION p202403 VALUES LESS THAN (TO_DAYS('2024-04-01')),
PARTITION p_future VALUES LESS THAN MAXVALUE
);
🔧 工具和技巧
1. 性能测试工具
# 1. sysbench - 数据库压力测试 sysbench oltp_read_write \ --mysql-host=localhost \ --mysql-user=root \ --mysql-password=password \ --mysql-db=testdb \ --tables=10 \ --table-size=100000 \ --threads=16 \ --time=60 \ run # 2. pt-query-digest - 慢查询分析 pt-query-digest /var/log/mysql/slow.log # 3. mytop - 实时监控 mytop -u root -p password -d testdb
2. SQL优化辅助脚本
-- 查找未使用的索引
SELECT
OBJECT_SCHEMA,
OBJECT_NAME,
INDEX_NAME,
COUNT_FETCH,
COUNT_INSERT,
COUNT_UPDATE,
COUNT_DELETE
FROM performance_schema.table_io_waits_summary_by_index_usage
WHERE INDEX_NAME ISNOT NULL
AND COUNT_STAR =0
AND OBJECT_SCHEMA ='your_database'
ORDERBY OBJECT_SCHEMA, OBJECT_NAME;
-- 查找重复索引
SELECT
a.TABLE_SCHEMA,
a.TABLE_NAME,
a.INDEX_NAME as index1,
b.INDEX_NAME as index2,
a.COLUMN_NAME
FROM information_schema.STATISTICS a
JOIN information_schema.STATISTICS b
ON a.TABLE_SCHEMA = b.TABLE_SCHEMA
AND a.TABLE_NAME = b.TABLE_NAME
AND a.COLUMN_NAME = b.COLUMN_NAME
AND a.INDEX_NAME != b.INDEX_NAME
WHERE a.TABLE_SCHEMA ='your_database'
ORDERBY a.TABLE_NAME, a.COLUMN_NAME;
-- 查看表大小和行数
SELECT
TABLE_NAME,
TABLE_ROWS,
ROUND(DATA_LENGTH/1024/1024, 2) AS'Data Size (MB)',
ROUND(INDEX_LENGTH/1024/1024, 2) AS'Index Size (MB)',
ROUND((DATA_LENGTH + INDEX_LENGTH)/1024/1024, 2) AS'Total Size (MB)'
FROM information_schema.TABLES
WHERE TABLE_SCHEMA ='your_database'
ORDERBY (DATA_LENGTH + INDEX_LENGTH) DESC;
🎯 常见问题解答
Q1:什么时候需要添加索引?
要添加索引的情况:
- • WHERE子句中经常出现的列
- • JOIN条件中的列
- • ORDER BY中的列
- • GROUP BY中的列
- • 外键列
不需要添加索引的情况:
- • 数据量很小的表(几千行)
- • 频繁更新的列
- • 区分度很低的列(如性别)
Q2:如何选择合适的数据类型?
-- 数据类型选择建议
-- ✅ 推荐的数据类型
CREATE TABLE user_profile (
id BIGINTPRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL, -- 不要过长
age TINYINT UNSIGNED, -- 年龄用TINYINT够了
balance DECIMAL(10,2), -- 金额用DECIMAL精确计算
is_active BOOLEANDEFAULTTRUE, -- 布尔值用BOOLEAN
create_time DATETIME NOT NULL, -- 时间用DATETIME
-- ❌ 不推荐
-- username VARCHAR(255), -- 过长的VARCHAR
-- age INT, -- 年龄不需要INT
-- balance DOUBLE, -- 金额不要用浮点数
-- is_active CHAR(1), -- 布尔值不要用CHAR
-- create_time TIMESTAMP -- 有时区问题
);
Q3:如何处理大表查询?
// 大表查询策略
@Service
publicclassBigTableQueryService {
/**
* 策略1:分页 + 索引
*/
public List<Order> queryWithPaging(Long lastId, int size) {
Stringsql="""
SELECT * FROM big_orders
WHERE id > ?
ORDER BY id LIMIT ?
""";
return jdbcTemplate.query(sql, newObject[]{lastId, size}, rowMapper);
}
/**
* 策略2:异步处理
*/
@Async
public CompletableFuture<List<Order>> queryAsync(OrderQuery query) {
return CompletableFuture.supplyAsync(() -> {
// 执行查询
return executeQuery(query);
});
}
/**
* 策略3:读写分离
*/
@ReadOnlyDataSource
public List<Order> queryFromSlave(OrderQuery query) {
// 从只读库查询,减轻主库压力
return orderMapper.selectByQuery(query);
}
/**
* 策略4:缓存热点数据
*/
@Cacheable(value = "orders", key = "#userId + '_' + #status")
public List<Order> getUserOrdersWithCache(Long userId, String status) {
return orderMapper.selectByUserAndStatus(userId, status);
}
}
总结
慢SQL优化是一个系统性工程,需要从多个维度来解决:
核心要点:
- • 及时发现:建立完善的监控体系,第一时间发现慢SQL
- • 准确分析:使用EXPLAIN等工具深入分析查询执行计划
- • 针对优化:根据分析结果选择合适的优化策略
- • 持续监控:优化后持续监控效果,防止性能回退
优化策略优先级:
- 1. 索引优化:最直接、最有效的优化手段
- 2. SQL重写:改写查询逻辑,避免性能陷阱
- 3. 架构优化:读写分离、分库分表、缓存等
- 4. 硬件升级:最后的选择
记住优化原则:测量 → 分析 → 优化 → 验证
掌握了这套慢SQL优化方法论,你就能够系统性地解决数据库性能问题,让系统运行如飞!在实际项目中,性能优化往往能带来数倍甚至数十倍的性能提升。