转载:https://blog.csdn.net/m0_48891301/article/details/149194764
转载:https://blog.csdn.net/jbkjhji/article/details/153721303
前言🔖
很多人一学 AI 应用开发,就被三个词反复绕晕:RAG、LangChain、Agent。
但它们并不是“谁更高级”的关系,而是分工不同、协同使用,我用一句工程师能听懂的话讲清楚:
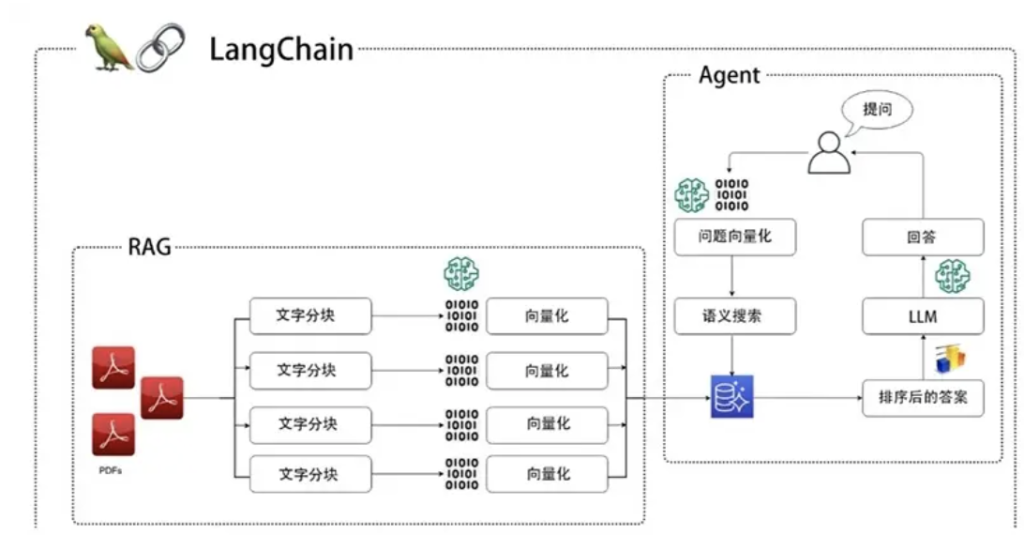
● LangChain:应用框架,负责把流程搭起来;
● RAG:能力组件,负责给模型“外挂知识”;
● Agent:执行角色,负责按目标一步步干活。
真正的AI应用,往往是这三者一起用。
什么是 RAG(检索增强生成)🔖
未来,每个产品经理都是 AI 产品经理,而每个 AI 产品经理都必须懂 RAG。
所谓RAG(Retrieval – Augmented Generation),即信息检索(Retrieval)+内容生成(Generation)。
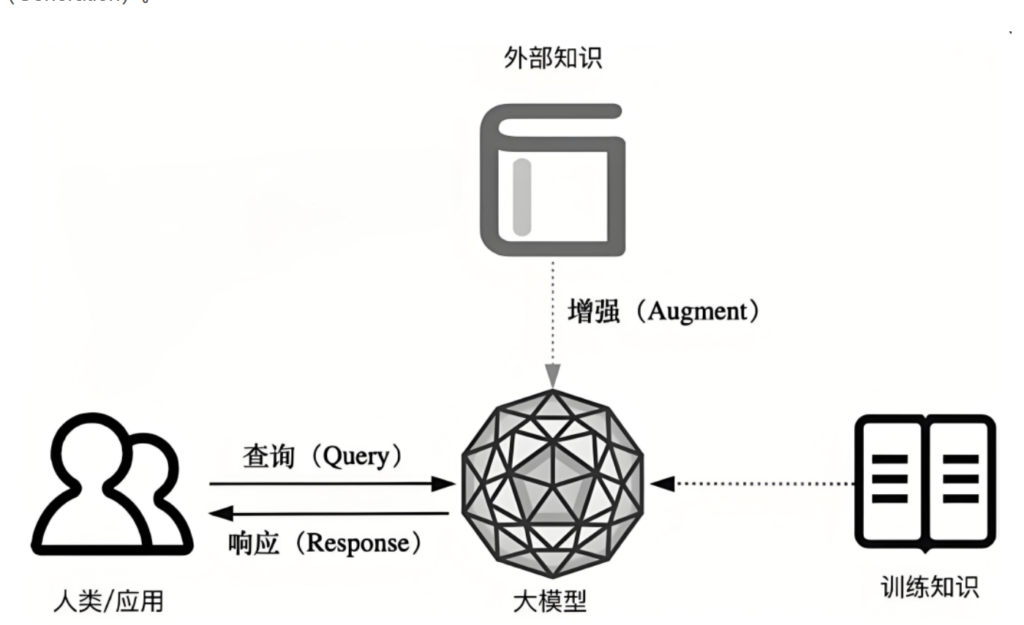
我们平常使用的大模型(比如 ChatGPT)非常聪明,但它有一个问题:
它的“知识”是训练时学到的,不会自动更新。如果我们问它一些很新的问题,或者我们公司的内部资料,它可能就不知道。所以,RAG 技术就是为了解决这个问题而出现的。
RAG 的核心思路🔖
RAG 的全称是 Retrieval-Augmented Generation,中文叫“检索增强生成”。
简单理解就是:
先去找资料,再用AI来写答案。
它分成两个主要步骤:
1. 检索(Retrieval):当用户提问后,系统会先去一个“知识库”里找相关内容,这个知识库可以是。
- 我们公司内部的文档;
- 产品资料;
- 客服问答;
甚至是技术手册等。系统不是靠关键词搜索,而是用“语义搜索”——也就是理解意思后再匹配。
(比如你问“怎么退货?”,它也能找到“退款流程”的内容。)
2.生成(Generation):找到相关资料后,系统会把这些内容交给大模型(比如 GPT)。
模型会结合用户的问题和这些资料,生成一段自然、准确的回答。
这样生成的结果有两个好处:
- 更准确 —— 因为用到了我们提供的最新资料。
- 更及时 —— 知识库一更新,答案也会自动更新。
举个生活化的例子:想象一下你在公司做客服,客户问:
“你们的会员积分可以兑换什么?”
普通AI可能不知道,因为这属于公司的内部政策,但如果我们用了RAG系统:
- 它会先在公司知识库里找到“会员积分兑换规则”;
- 再让AI根据这些资料生成一段自然、清晰的回答。
结果:客户得到准确的信息,AI也不会“乱编”,总结一句话, RAG 就像是:
“AI的大脑 + 公司的知识库 = 会查资料又会说话的AI。”
这样我们既能利用AI的语言能力,又能确保回答内容可靠、实时、贴合业务。
相比于仅依赖大型语言模型的生成,RAG技术可以从外部知识库中检索信息,避免了模型的幻觉问题,并提升了对实时性要求较高问题的处理能力。与传统的知识库问答系统相比,RAG技术更加灵活,可以处理非结构化的自然语言文本。
RAG 的详细工作流程通俗版🔖
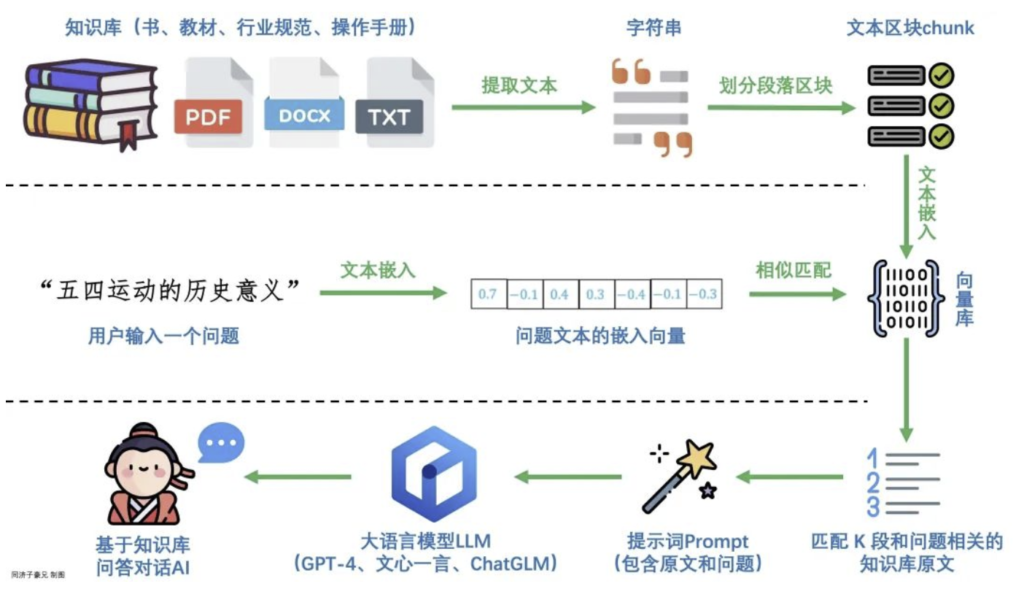
① 向量化(理解问题)
用户输入问题,比如:
“如何报销差旅费?”
系统先把这句话转成“向量”(一种能让电脑理解语义的数字形式),方便后续去匹配相似内容。
② 检索(查找相关内容)
系统去知识库里找“意思最接近”的内容,比如:
找到公司文档里一段:“差旅报销需提交发票和行程单,由财务审核。”
③ 增强(把资料塞给AI)
系统把这些相关文档内容,和用户的问题一起发给AI模型,
告诉它:“这是最新的资料,请参考这些内容来回答。”
④ 生成(写出最终回答)
AI根据知识库内容,用自然语言生成一段完整的回答。
这样生成的结果:
- 更可靠(因为有依据)
- 更及时(知识库更新就能反映)
- 更可控(回答范围限定在业务知识内)
RAG的核心理念是:先查资料,再回答问题。它让AI变成一个: 既能理解人话,又能查资料,还能生成准确答案的助手。
通过 RAG,可以让大模型从指定的内部知识库“检索”准确的内容,再根据准确的内容“生成”回答内容,从而有效避免幻觉。
比如,如果直接让大模型进行医疗诊断,由于大模型的本质是概率模型,因此它会提供大量错误或者不相关的信息。
有了RAG,大模型就可以从海量的医学文献、病例库中直接检索与患者病症相关的知识,再生成诊断建议供医生参考,从而提高内容的准确性。
接下来给大家介绍 RAG 的 7 个核心概念,看完以后,你会对 RAG 有更深入的认识。
向量数据库🔖
向量数据库是 RAG 最重要的基础设施之一。
传统数据库的内容查询主要依赖“关键词匹配”,对查询的精确度要求很高。
比如,如果你查询“如何提高工作效率”,而数据库只有“时间管理技巧”内容,那么就无法搜索出任何内容。
而向量数据库就可以有效解决这个问题,它会把各种知识都转换成一组组数字(向量),这些数字能代表知识的内容和特点,
当你在 RAG 系统中输入查找信息时,它会把输入信息也转换成一组数字(向量),然后在数据库中找出最相关的知识,从而实现“语义检索”。
比如,下面的每个知识都转化为了一个 3 维向量(实际应用中可能把一个知识转化为几十甚至几千维的向量):
- 时间管理:[0.12,0.23,0.46]
- 工作地点:[0.92,0.82,0.65]
- 考勤制度:[0.83,0.93,0.78]
当用户查询“工作效率”,向量数据库就可以把“工作效率”转化为向量: [0.12,0.23,0.53]。
显然它和“时间管理”的向量 [0.12,0.23,0.46] 相似度很高——从业务上来说,是因为“时间管理”是提高“工作效率”的一种有效方法,这就导致两者的语义高度相关。
其实,这就是“语义检索”的过程。
在传统客服系统中,由于依赖“关键词匹配”,在面对复杂咨询时,就很难给出用户想要的答案。
而 AI 客服使用向量数据库,当用户咨询时,可以通过 “语义检索”快速找到最相关的答案,从而提升用户体验和满意度。
混合检索🔖
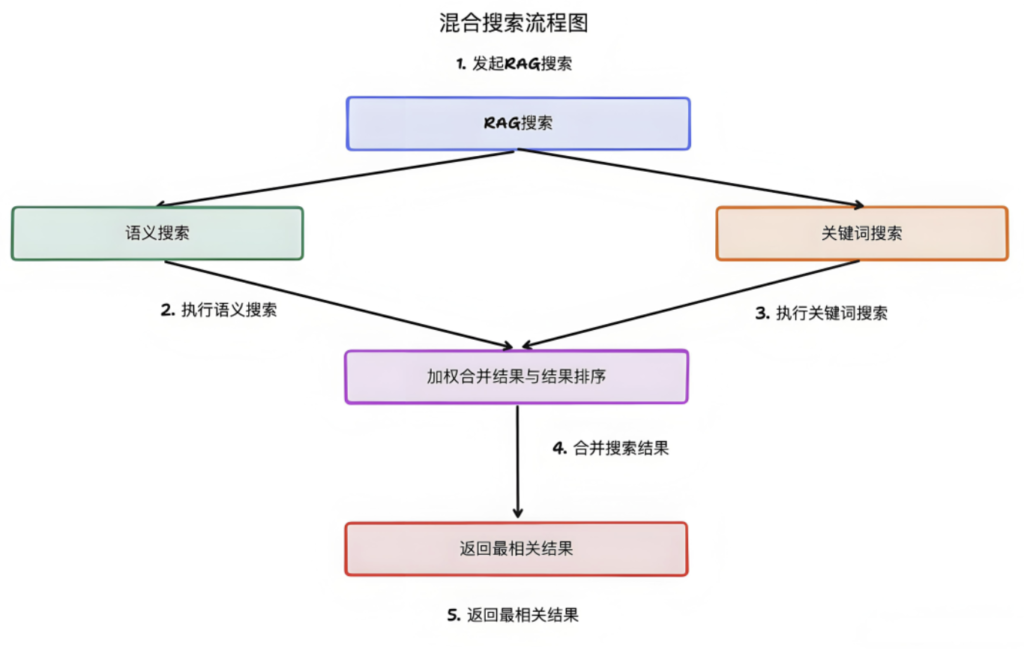
基于向量知识库的语义检索虽然很好,但是也存在 2 个问题:
首先是面对超大数据量,语义检索的速度不如传统的关键词检索。
其次是对于一些需要精确匹配的场景,关键词匹配更有优势。比如在法律文件检索中,法律条文、案例等对措辞的精准要求就很高。
因此,在很多场景下,RAG 会同时使用关键词检索和语义检索,从而尽可能的提升检索体验。
比如,在电商平台上,用户搜索“无线蓝牙耳机”。纯语义检索可能会推荐一些带有“无线”或“蓝牙”字样的普通耳机,但混合检索除了语义匹配,还会根据关键词“无线蓝牙”进行精确匹配,确保优先推荐符合“无线蓝牙耳机”这一完整要求的产品。
分块、嵌入与索引🔖
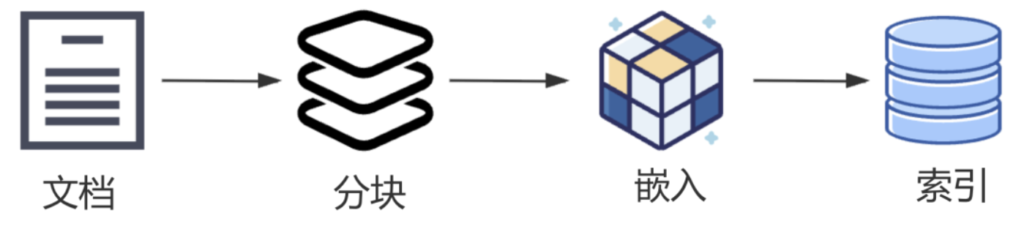
RAG在存储知识时,为了更高效地管理和检索,通常会将原始文档按照一定的规则(如固定长度、语义单元等)分块。
就如同一本很长的小说,如果把它切成一个个章节或者更小的段落块,那么在查找某个故事情节时就更方便快捷。
分块以后,还需要把每一个块转化为向量,从而存储到向量数据库,这就是嵌入。
嵌入以后,还可以把向量存储到一个高效的检索结构中,以便快速进行相似性计算和检索,这就是索引。
比如,某法律咨询平台为用户提供在线法律咨询服务。
由于法律领域的知识库通常非常庞大且复杂,包含大量的文本信息,如法律条文、司法解释、案例判决书等。
在构建知识库时,就可以将法律条文、案例等长文本分割成多个小块,同时,利用索引结构记录每个小块的向量位置,以便快速检索。
这样,当用户输入法律问题,如“合同违约的赔偿标准是什么”,RAG 就可以从数据库中快速找到最相关的多个小块,并通过上下文融合来生成更为准确和完整的答案。
重排序(re-rank)🔖
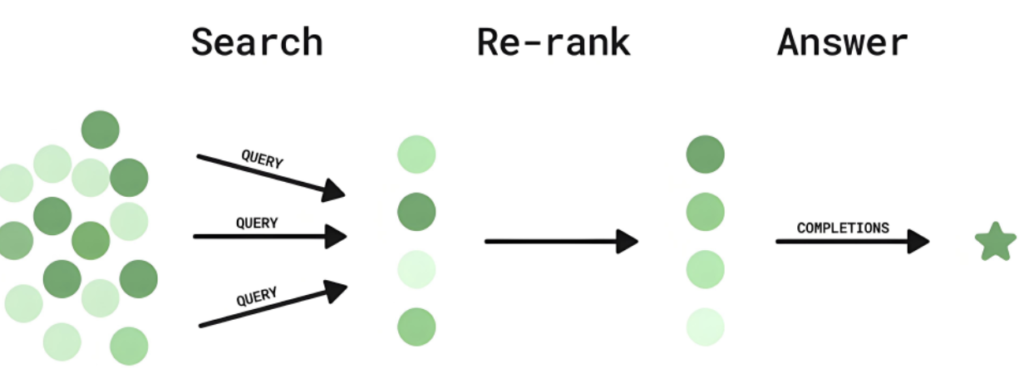
当 RAG 从数据库中检索出多个内容时,需要选取相关性最大的内容喂给大模型,从而提高大模型的回答质量。
所谓重排序,是指 RAG 将初步检索出来的内容进行重新排序,其目的是将最相关的信息排在前面,从而选取出相对更为准确的内容。
打个比方,你想让 AI 搜索一批书籍,RAG 会先大致找出一批可能你想要的书籍,然后仔细评估每一本书和你需求的契合程度,把最符合你心意的书排在最前面,方便你优先查看。
重排序的应用非常广泛,比如电商平台根据用户需求初步筛选出一批商品后,就会通过“重排序”,根据用户的实时行为、偏好历史等,对推荐商品进行重新排序,把更符合用户当下需求的商品排在前面,提高推荐的准确性和实用性。
上下文融合🔖
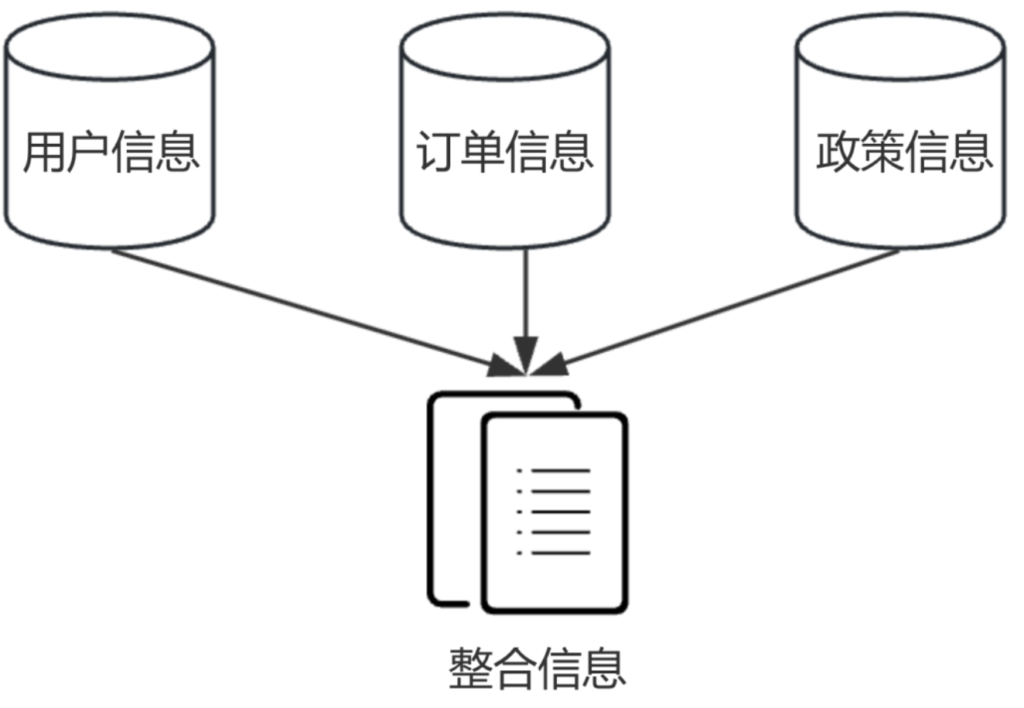
上下文融合是指 RAG 将从多个来源检索到的知识进行整合,以便为大模型提供更全面、连贯的输入内容,这样大模型的回答才能条理清晰、内容完整。
比如,在智能客服场景中,用户咨询:“我刚收到的商品有点瑕疵,我可以申请退货吗?”
要回答好这个问题,RAG 就需要从多个来源检索信息,比如用户的订单信息、退货政策等,再把这些内容整理成统一的内容,以便大模型能够基于内容生成高质量的回答。
准确率和召回率🔖
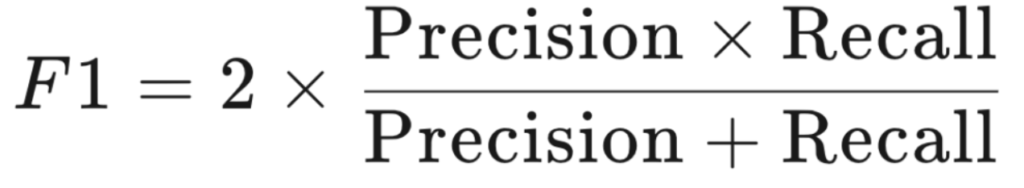
准确率(Precision)是指在 RAG 检索到的内容中,与用户问题真正相关的内容的比例。
例如,在一个问答系统中,检索到 10 条知识,其中有 8 条与用户问题高度相关,那么准确率就是 80%。
准确率是衡量检索质量最重要的指标之一。
比如,智能客服在回答用户问题时,如果准确率不高,就会提供大量不相关或错误的答案,影响用户体验。
但是,只有高的准确率还不够,还必须有高的召回率。
所谓召回率(Recall),是指与用户问题相关的所有知识中,被成功检索到的比例。
例如,知识库中有 20 条与用户问题相关的知识,检索到 12 条,那么召回率就是 60%。
在实际应用场景中,召回率和准确率往往会成为跷跷板。比如如果过度追求高召回率,可能会导致检索结果中包含大量不相关的信息,影响准确率。反之亦然。
比如,在一个电商商品检索系统中,为了尽可能多地召回相关商品,降低了检索阈值,结果导致很多边缘相关甚至不相关的商品也出现在结果中。
在这种情况下,我们可以引入 F1 值进行综合评估,从而找到召回率和准确率之间的平衡点。
F1 值的计算公式是:F1= 2(准确率召回率)/(准确率+召回率)。
在这个公式中,当准确率或者召回率中的任何一个非常低时,F1 值也会相应的降低。
知识图谱🔖
知识图谱就像是一个巨大的知识网络,把各种知识当作一个个节点,并且把有关系的节点进行连接。
比如,通过知识图谱可以对菜谱知识进行管理,把各个菜谱、原材料、烹饪方法连接起来,这样,当用户询问“用鸡蛋可以做哪些菜”时,RAG 就可以通过“菜谱-原材料”的连接关系,准确找到使用“鸡蛋”的菜谱。
通过知识图谱,RAG 能够捕捉到实体间的复杂关系,还能够基于已有的实体关系进行推理和扩展,发现更多潜在的相关信息,从而大大提升准确率和召回率。
比如,一年级有 5 个班,RAG 数据库中记录了 5 个班各自的期末成绩,但是并没有存储“一年级所有同学的平均成绩”。
这就导致,当用户询问“一年级期末平均成绩是多少”时,RAG 找不到相关内容,最后给出一个错误的答案。
但是,如果我们通过知识图谱建立了“一年级”和“5 个班级”之间的实体关系,RAG 就能根据根据这个关系找到“5 个班级的期末成绩”,再通过计算给到用户一个准确的回答。
最后,一个 RAG 系统的运行可能包含以下步骤:
- 1、向量数据库提供知识存储的基础设施
- 2、对内容进行分块、嵌入和索引,以方便检索
- 3、再通过知识图谱建立相关实体的关系,从而提高检索和生成的准确度
- 4、当用户查询时,通过混合检索、知识图谱等方式检索内容
- 5、然后把检索出来的内容进行重排序,选出最相关的内容
- 6、把选出的内容进行上下文融合,提供给大模型生成回答内容
- 7、最后,通过 F1 值对 RAG 系统的准确率和召回率进行综合评估