数据流的基本概念
几乎所有的程序都离不开信息的输入和输出,比如从键盘读取数据,从文件中获取或者向文件中存入数据,在显示器上显示数据。这些情况下都会涉及有关输入/输出的处理。
在Java中,把这些不同类型的输入、输出源抽象为流(Stream),其中输入或输出的数据称为数据流(Data Stream),用统一的接口来表示。
IO 流的分类
数据流是指一组有顺序的、有起点和终点的字节集合。
- 按照流的流向分,可以分为输入流和输出流。注意:这里的输入、输出是针对程序来说的。
输出:把程序(内存)中的内容输出到磁盘、光盘等存储设备中。
输入:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。
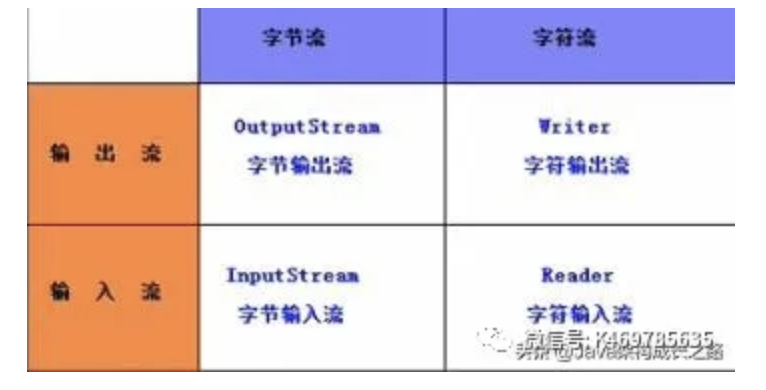
- 按处理数据单位不同分为字节流和字符流。
字节流:每次读取(写出)一个字节,当传输的资源文件有中文时,就会出现乱码。
字符流:每次读取(写出)两个字节,有中文时,使用该流就可以正确传输显示中文。
处理流(包装流):是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如BufferedReader。处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
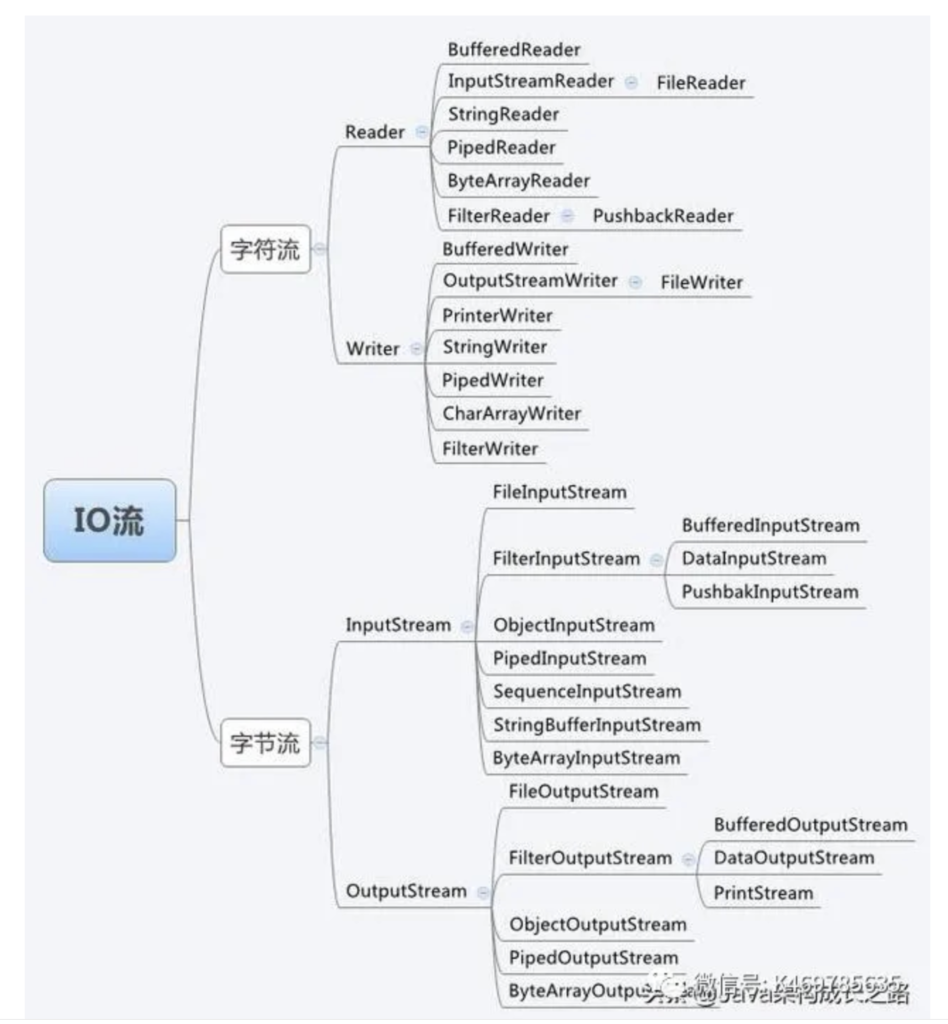
Java IO 流的类图
Java IO 流有4个抽象基类:
其他流都是继承于这四大基类的。下图是Java IO 流的整体架构图:
IO 流的选择
知道了 IO 流有这么多分类,那我们在使用的时候应该怎么选择呢?比如什么时候用输出流?什么时候用字节流?可以根据下面三步选择适合自己的流:
- 首先自己要知道是选择输入流还是输出流。这就要根据自己的情况决定,如果想从程序写东西到别的地方,那么就选择输入流,反之就选输出流;
- 然后考虑你传输数据时,是每次传一个字节还是两个字节,每次传输一个字节就选字节流,如果存在中文,那肯定就要选字符流了。
- 通过前面两步就可以选出一个合适的节点流了,比如字节输入流 InputStream,如果要在此基础上增强功能,那么就在处理流中选择一个合适的即可。
Java乱码的根本原因
乱码的核心原因:编码与解码不匹配
乱码的根本原因是:
写入时使用的编码方式 ≠ 读取时使用的解码方式
例如:
- 写入时用 UTF-8 编码
"你好",读取时用 GBK 解码 → 乱码。 - 写入时用 GBK 编码,读取时用 UTF-8 解码 → 乱码。
乱码可能发生在写入阶段吗?
- 严格来说,写入阶段本身不会直接产生乱码,因为数据是以字节形式写入文件的,而乱码是「字节转字符」时的解码错误。
- 但错误的编码方式会为后续读取埋下乱码隐患。
乱码更常发生在读取阶段
读取阶段乱码的典型场景
- 场景 1:文件编码与读取编码不匹配
例:文件是 UTF-8 编码,但用 GBK 解码:
// 错误:用GBK解码UTF-8文件
BufferedReader reader = new BufferedReader(new FileReader("file.txt", StandardCharsets.GBK));
结果:"你好"可能显示为"浣犲ソ"。
场景 2:未显式指定编码,依赖系统默认编码
例:在 Windows(默认 GBK)中读取 UTF-8 文件,且未指定编码:
// 隐式使用系统默认编码(GBK)解码UTF-8文件
BufferedReader reader = new BufferedReader(new FileReader("file.txt"));
结果:必然乱码,因为解码规则与文件实际编码不匹配。
案例:乱码的完整流程演示
/ 写入阶段(UTF-8编码)
try (FileOutputStream fos = new FileOutputStream("test.txt")) {
fos.write("你好".getBytes(StandardCharsets.UTF_8));
}
// 读取阶段(错误使用GBK解码)
try (FileInputStream fis = new FileInputStream("test.txt")) {
byte[] bytes = fis.readAllBytes();
String text = new String(bytes, StandardCharsets.GBK); // 乱码!
System.out.println(text); // 输出:浣犲ソ
}
如何避免乱码?核心原则
- 写入时显式指定编码:
- 字节流:
getBytes("UTF-8") - 字符流:
new FileWriter("file.txt", StandardCharsets.UTF_8)
- 字节流:
- 读取时使用与写入相同的编码:
- 字节流:
new String(bytes, "UTF-8") - 字符流:
new FileReader("file.txt", StandardCharsets.UTF_8)
- 字节流:
- 跨平台场景强制指定 UTF-8 编码:
- 避免依赖系统默认编码(如 Windows 的 GBK、Mac 的 UTF-8),统一使用 UTF-8 保证兼容性。
总结:乱码的发生阶段
- 乱码的直接表现:发生在读取阶段(解码时)。
- 乱码的根本原因:写入时的编码与读取时的解码不匹配,因此写入阶段的编码选择是乱码的「源头」,读取阶段的解码错误是乱码的「表现」。
核心结论:乱码是编码和解码不匹配的结果,需要在写入和读取阶段同时保证编码一致,才能彻底避免。
在 Java 中,使用字节流写文件时是否需要指定编码?
字节流(如FileOutputStream)的核心作用是直接操作二进制字节,它不关心数据的「字符含义」,只负责按字节序列写入文件。
- 例如:写入
int a = 65,字节流会直接写入0x41(ASCII 中 ‘A’ 的字节值)。 - 关键:字节流本身不涉及编码转换,编码是「字符→字节」转换时的规则。
为什么处理字符数据时需要指定编码?
当你需要写入「字符数据」(如String)时,必须先将字符转换为字节序列,而这个转换过程必须指定编码,否则会使用系统默认编码,可能导致问题:
1. 字符→字节的转换必须依赖编码规则
- 例:字符
"你"在不同编码下的字节表示不同:- UTF-8:
0xE4 0xBD 0xA0(3 字节) - GBK:
0xC4 0xE3(2 字节)
- UTF-8:
- 若不指定编码,
String.getBytes()会使用系统默认编码(如 Windows 默认 GBK,Linux 默认 UTF-8),可能导致:- 跨平台时文件编码不一致,读取时乱码。
- 无法预知文件的实际编码,增加维护成本。
2. 示例:不指定编码的风险
try (FileOutputStream fos = new FileOutputStream("test.txt")) {
String text = "你好";
fos.write(text.getBytes()); // 隐式使用系统默认编码
}
问题:若在 Windows(GBK)写入,在 Linux(UTF-8)中用 UTF-8 读取,必然乱码。
什么情况下可以不指定编码?
当你操作的是非字符数据(如图片、音频、二进制文件)时,不需要考虑编码,因为:
- 这些数据本身就是字节序列,无需「字符→字节」的转换。
- 例:复制图片文件时,直接读取字节并写入即可:
try (FileInputStream fis = new FileInputStream("image.jpg");
FileOutputStream fos = new FileOutputStream("image_copy.jpg")) {
byte[] buffer = new byte[1024];
int len;
while ((len = fis.read(buffer)) != -1) {
fos.write(buffer, 0, len);
}
}
注意:此时操作的是原始字节,与编码无关。
总结:是否需要指定编码的核心逻辑
| 场景 | 是否需要指定编码 | 原因 |
|---|---|---|
| 写入字符数据(String) | 必须显式指定编码 | 字符→字节的转换需要明确规则,避免依赖系统默认编码导致乱码或兼容性问题。 |
| 写入原始字节数据 | 无需指定编码 | 直接操作字节序列,不涉及字符转换。 |
最佳实践:显式指定编码,避免隐患
即使是处理字符数据,也建议始终显式指定编码,例如:
try (FileOutputStream fos = new FileOutputStream("test.txt")) {
String text = "你好";
fos.write(text.getBytes(StandardCharsets.UTF_8)); // 显式指定UTF-8编码
}
这样做的好处:
- 明确文件的编码格式,便于后续读取时使用相同编码,避免乱码。
- 跨平台场景下保证编码一致性(UTF-8 是通用编码)。
关键结论
- 字节流本身不处理编码,编码是「字符→字节」转换时的规则。
- 当写入字符数据时,必须指定编码,否则会使用系统默认编码,可能导致后续读取时乱码或兼容性问题。
- 当写入原始字节数据(非字符)时,无需考虑编码,直接操作字节即可。
为什么不能只用字节流?
字节流确实可以写任何文件(包括文本),但处理文本时存在两大致命问题:
编码复杂性(手动处理编码易出错)
- 示例:用字节流写入中文
try (FileOutputStream fos = new FileOutputStream("test.txt")) {
String text = "你好";
// 必须手动指定编码,否则默认用系统编码(如Windows的GBK)
fos.write(text.getBytes("UTF-8"));
}
问题:若不指定编码(如getBytes()),在不同系统上可能使用不同默认编码(如 Windows 的 GBK、Linux 的 UTF-8),导致跨平台乱码。
操作低效(需频繁处理字节细节)
示例:用字节流逐行写入文本
try (FileOutputStream fos = new FileOutputStream("test.txt")) {
String line1 = "第一行";
String line2 = "第二行";
// 写入第一行 + 换行符(需手动处理字节)
fos.write(line1.getBytes("UTF-8"));
fos.write("\n".getBytes("UTF-8")); // 手动添加换行符的字节
fos.write(line2.getBytes("UTF-8"));
}
问题:需频繁将字符串转字节数组,手动处理换行符(\n),代码冗余且易出错。
字符流的 “救赎”:自动处理编码和文本操作
自动编码转换(无需手动处理字节)
示例:用字符流写入中文
try (FileWriter writer = new FileWriter("test.txt")) {
writer.write("你好"); // 自动按UTF-8编码写入,无需手动转字节
}
高层文本操作(简化代码)
示例:用字符流逐行写入文本
try (BufferedWriter writer = new BufferedWriter(new FileWriter("test.txt"))) {
writer.write("第一行");
writer.newLine(); // 自动添加系统无关的换行符(Windows是\r\n,Linux是\n)
writer.write("第二行");
}
优势:直接使用newLine()方法添加换行符,无需关心底层字节细节,代码更简洁。
生活化类比
- 场景:你要写一篇散文,有两种方式:
- 字节流方式:
- 先用笔把每个汉字拆解成笔画(如 “你” 拆成丿丨丿乛丨ノ丶)。
- 再按特定顺序(如 UTF-8 编码规则)排列这些笔画。
- 最后逐笔写在纸上。
- 结果:能完成,但效率极低,且容易写错(比如把 “你” 写成 “尔”)。
- 字符流方式:
- 直接用键盘敲入汉字(如 “你”)。
- 电脑自动按 UTF-8 编码转换为二进制存储。
- 结果:高效且不易出错。
- 字节流方式:
- 结论:
处理文本时,字符流的抽象层级更高,屏蔽了底层编码细节,就像用高级语言编程一样,让你专注于内容而非实现细节。
IO缓冲流

缓冲流(Buffered Stream)是 Java IO 中用于提高读写效率的装饰器流,它通过在内存中创建缓冲区(Buffer),减少与底层数据源(如磁盘、网络)的直接交互次数,从而显著提升性能。
缓冲流的核心作用:减少 IO 次数
传统 IO 的痛点:频繁访问底层资源
- 普通流(如
FileInputStream)每次读写操作都会直接调用操作系统的 IO 接口,例如:
try (FileInputStream fis = new FileInputStream("data.txt")) {
int data;
while ((data = fis.read()) != -1) { // 每次读取1个字节,调用1次系统IO
// 处理数据
}
}
问题:若文件有 1000 字节,需调用 1000 次系统 IO,开销极大。
缓冲流的解决方案:批量读写
- 缓冲流(如
BufferedInputStream)在内存中维护一个缓冲区(默认 8KB),每次从数据源读取一大块数据到缓冲区,后续的读操作直接从缓冲区获取:
try (BufferedInputStream bis = new BufferedInputStream(
new FileInputStream("data.txt"))) {
int data;
while ((data = bis.read()) != -1) { // 实际从缓冲区读取,减少系统IO调用
// 处理数据
}
}
优势:若文件有 1000 字节,只需 1 次系统 IO 将数据读入缓冲区,后续 999 次读操作直接从内存缓冲区获取,大幅提升效率。
缓冲流的工作原理:以BufferedOutputStream为例
写入流程
try (BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("output.txt"))) {
bos.write("Hello".getBytes()); // 先写入缓冲区,而非直接写入文件
bos.write("World".getBytes()); // 继续写入缓冲区
// 缓冲区满或调用flush()/close()时,才将数据批量写入文件
}
- 关键点:
- 数据先写入内存缓冲区,而非直接写入文件。
- 当缓冲区满(默认 8KB)或手动调用
flush()时,才将数据一次性写入文件。
缓冲区的优势
- 减少磁盘 IO 次数:从每次写 1 字节 → 每次写 8KB。
- 类比:
- 普通流:像用勺子舀水,每次舀一勺倒入桶中(效率低)。
- 缓冲流:像用大桶接水,装满一桶后再倒入水缸(效率高)。
Java 中的缓冲流类
Java 提供了 4 种缓冲流,分别对应字节流和字符流:
| 类型 | 输入流 | 输出流 | 适用场景 |
|---|---|---|---|
| 字节缓冲流 | BufferedInputStream | BufferedOutputStream | 处理二进制数据(图片、视频) |
| 字符缓冲流 | BufferedReader | BufferedWriter | 处理文本数据(.txt、.json) |
缓冲流的额外功能
字符缓冲流的高效文本操作
BufferedReader提供readLine()方法,直接读取一行文本:
try (BufferedReader br = new BufferedReader(
new FileReader("data.txt"))) {
String line;
while ((line = br.readLine()) != null) { // 高效读取整行
System.out.println(line);
}
}
BufferedWriter提供newLine()方法,自动添加系统无关的换行符:
try (BufferedWriter bw = new BufferedWriter(
new FileWriter("output.txt"))) {
bw.write("第一行");
bw.newLine(); // 自动添加换行符(Windows是\r\n,Linux是\n)
bw.write("第二行");
}
自定义缓冲区大小
可通过构造函数指定缓冲区大小(默认 8KB):
// 指定缓冲区为16KB
BufferedInputStream bis = new BufferedInputStream(
new FileInputStream("data.txt"), 16384);
何时使用缓冲流?
建议在任何 IO 操作中都使用缓冲流,尤其是:
- 频繁读写小数据(如逐行读取文本)。
- 操作大文件(如复制 GB 级视频)。
- 网络 IO(如 Socket 通信)。
示例:复制大文件时缓冲流的性能提升
// 无缓冲(慢)
try (FileInputStream fis = new FileInputStream("input.zip");
FileOutputStream fos = new FileOutputStream("output.zip")) {
byte[] buffer = new byte[1024];
int len;
while ((len = fis.read(buffer)) != -1) {
fos.write(buffer, 0, len);
}
}
// 有缓冲(快)
try (BufferedInputStream bis = new BufferedInputStream(
new FileInputStream("input.zip"));
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("output.zip"))) {
byte[] buffer = new byte[1024];
int len;
while ((len = bis.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
}
缓冲流是 IO 的性能加速器,它通过批量读写减少与底层资源的交互次数,就像快递员一次送多个包裹而非逐个派送,显著提升效率。无论是处理大文件还是小数据,都建议优先使用缓冲流!
Java I O流一定要关闭吗?
在 Java 中,IO 流必须关闭,否则会导致严重的资源泄漏问题。这就像你用完水龙头后必须关掉,否则会浪费水资源并可能引发水灾。以下是详细解释:
为什么必须关闭 IO 流?
1. 资源占用
- IO 流(如
FileInputStream、Socket)通常会占用操作系统的文件描述符、网络连接、内存缓冲区等资源。 - 若不关闭,这些资源不会被自动释放,长期积累会导致系统资源耗尽,程序崩溃。
2. 数据完整性风险
- 输出流(如
FileOutputStream)通常有缓冲区,数据先写入缓冲区,而非直接写入文件。 - 若不关闭流,缓冲区的数据可能不会被刷新到磁盘,导致数据丢失。例如:
FileOutputStream fos = new FileOutputStream("test.txt");
fos.write("Hello".getBytes());
// 未调用close()或flush(),"Hello"可能不会写入文件
3. 系统限制
- 操作系统对每个进程的文件描述符数量有限制(如 Linux 默认 1024 个)。
- 若频繁打开 IO 流而不关闭,会迅速耗尽限制,导致后续无法打开新文件。
关闭 IO 流的正确方式
传统方式:try-finally
FileInputStream fis = null;
try {
fis = new FileInputStream("data.txt");
// 读取数据
} catch (IOException e) {
e.printStackTrace();
} finally {
// 确保流在finally块中关闭
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
问题:代码繁琐,易遗漏关闭操作。
现代方式:try-with-resources(JDK7+)
try (FileInputStream fis = new FileInputStream("data.txt")) {
// 读取数据,流会自动关闭
} catch (IOException e) {
e.printStackTrace();
}
原理:实现了AutoCloseable接口的类(如FileInputStream),会在try块结束时自动调用close()。
缓冲流的特殊注意事项
缓冲流必须关闭
- 缓冲流(如
BufferedOutputStream)的close()会自动调用flush(),确保缓冲区数据写入文件。 - 若只调用
flush()而不关闭流,虽然数据会写入,但流仍占用资源。
装饰器流只需关闭最外层
当使用装饰器流(如BufferedOutputStream包装FileOutputStream)时,只需关闭最外层流:
try (BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("output.txt"))) {
bos.write("Hello".getBytes());
// 只需关闭bos,内部的FileOutputStream会被自动关闭
}
常见误区
误区 1:JVM 会自动回收 IO 流
- 真相:IO 流占用的是操作系统资源,而非 Java 堆内存。JVM 的垃圾回收(GC)只能回收 Java 对象,无法直接释放操作系统资源。
误区 2:使用小文件时可以不关闭流
- 真相:即使是小文件,若不关闭流,每次运行程序都会积累资源占用,长期可能导致问题。
误区 3:只关闭输出流,不关闭输入流
- 真相:输入流(如
FileInputStream)也占用文件描述符,必须关闭。
扩展:哪些类需要关闭?
实现了AutoCloseable接口的类都需要关闭,常见的包括:
- IO 流:
FileInputStream、FileOutputStream、BufferedReader等。 - 网络连接:
Socket、ServerSocket。 - 数据库连接:
Connection、Statement、ResultSet。 - 其他资源:
Process(执行外部程序)、ZipFile等。
关闭 IO 流就像用完水龙头要关掉,是编程的基本要求。使用try-with-resources语法,既能保证资源正确关闭,又能让代码更简洁!编辑分享
理解 IO 流占用的系统资源
文件描述符(File Descriptor):操作系统的 “文件通行证”
1. 本质
- 文件描述符是操作系统内核为每个打开的文件分配的唯一整数标识(如 Linux 中是一个非负整数,如 0、1、2…)。
- 类比:图书馆给每本借出的书分配一个 “借阅证编号”,操作系统通过文件描述符追踪哪些文件被哪些程序打开。
2. 文件描述符的限制
- 每个进程(如 Java 程序)能打开的文件描述符数量有限(Linux 默认 1024 个)。
- 示例:
// 错误示例:循环打开文件但不关闭
for (int i = 0; i < 2000; i++) {
FileInputStream fis = new FileInputStream("data.txt");
// 未关闭fis,文件描述符持续占用
}
结果:循环到第 1025 次时,程序会抛出Too many open files异常,因为超过了系统限制。
3. 关闭流的意义
- 调用
close()相当于归还 “借阅证”,让操作系统回收文件描述符,供其他程序使用。
网络连接(Socket):占用网卡和端口资源
网络连接的建立过程
- 当创建
Socket连接时,操作系统会:- 分配本地端口(如 8080、9000)。
- 占用网卡资源(用于数据收发)。
- 在内核中维护连接状态表(记录连接的源 IP、目标 IP、端口等信息)。
不关闭连接的后果
- 端口耗尽:每个连接占用一个端口,而端口数量有限(0~65535)。若不关闭,会导致无法创建新连接。
- 资源浪费:即使连接不再使用,操作系统仍会为其分配缓冲区和 CPU 时间。
生活化类比
- 网络连接就像打电话:
- 建立连接(
new Socket())→ 拿起电话拨号。 - 数据传输 → 通话中。
- 关闭连接(
socket.close())→ 挂掉电话。 - 若不挂电话,别人无法拨打该号码(端口被占用),且电话公司持续为你分配线路资源。
- 建立连接(
内存缓冲区(Buffer):数据的 “临时仓库”
缓冲区的作用
- 为提高 IO 效率,Java IO 流通常使用内存缓冲区:
- 输入流(如
BufferedInputStream)会预读数据到缓冲区,减少磁盘 IO 次数。 - 输出流(如
BufferedOutputStream)会先将数据写入缓冲区,满后再批量写入磁盘。
- 输入流(如
不关闭流导致的问题
- 数据丢失:若缓冲区未满且未调用
flush()/close(),数据会停留在缓冲区,不会写入文件。- 示例:
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("test.txt"));
bos.write("Hello".getBytes());
// 未调用bos.close()或bos.flush(),"Hello"可能丢失
内存泄漏:缓冲区占用的内存不会被 GC 回收,直到流被关闭。
数据库连接:占用数据库服务器资源
数据库连接的特殊性
- 数据库连接(如
java.sql.Connection)不仅占用本地资源,还会在数据库服务器端创建会话(Session)。 - 每个会话会占用:
- 服务器内存(用于存储会话状态、查询缓存等)。
- 数据库连接池中的一个槽位(若使用连接池)。
不关闭连接的后果
- 服务器资源耗尽:大量未关闭的会话会导致数据库服务器内存溢出,性能下降。
- 连接池耗尽:若连接池中的连接被占满,新的数据库请求会被阻塞。
类比
- 数据库连接就像去银行办理业务:
- 建立连接 → 取号排队。
- 执行 SQL → 办理业务。
- 关闭连接 → 业务完成,释放窗口资源。
- 若不释放窗口,后面的客户无法办理业务。
Java 中可以使用 ASCII 编码写入汉字?
在 Java 中使用 ASCII 编码写入汉字无法正确读取,因为 ASCII 编码不支持汉字。以下是详细解释和示例:
ASCII 编码的局限性
- ASCII(American Standard Code for Information Interchange) 是美国信息交换标准代码,仅包含128 个字符:
- 英文字母(大写 A-Z,小写 a-z)、数字(0-9)、标点符号。
- 不包含任何中文汉字。
- 编码范围:0-127(用 7 位二进制表示)。
用 ASCII 写入中文的结果
当你尝试用 ASCII 编码写入中文时,Java 会将无法编码的字符替换为?。
try (FileOutputStream fos = new FileOutputStream("test.txt")) {
String text = "你好,世界!";
byte[] bytes = text.getBytes("ASCII"); // 使用ASCII编码
fos.write(bytes);
} catch (IOException e) {
e.printStackTrace();
}
文件内容
打开test.txt会看到:
??????
原因分析
- 汉字(如
你、好)的 Unicode 码点超出了 ASCII 范围(0-127)。 - Java 在编码时会将这些字符替换为
?(ASCII 中的 63)。
二进制内容
文件test.txt的实际二进制内容是:
0x3F 0x3F (即两个连续的`?`字符)
读取 ASCII 编码的中文文件
即使你知道文件是用 ASCII 编码写入的,读取时也无法恢复原始中文内容,因为信息已永久丢失。
try (FileInputStream fis = new FileInputStream("test.txt")) {
byte[] bytes = fis.readAllBytes();
String text = new String(bytes, "ASCII");
System.out.println(text); // 输出:??????
} catch (IOException e) {
e.printStackTrace();
}
详细过程解析
字符串 → 字节数组(编码过程)
- 字符
你:- Unicode 码点:
U+4F60(十进制 20304)。 - ASCII 范围:0-127。
- 结果:超出 ASCII 范围,被替换为
?(ASCII 码 63,即0x3F)。
- Unicode 码点:
- 字符
好:- Unicode 码点:
U+597D(十进制 22909)。 - 同样超出 ASCII 范围,被替换为
?(0x3F)。
- Unicode 码点:
字节数组 → 文件(写入过程)
FileOutputStream直接将字节数组[0x3F, 0x3F]写入文件。- 文件内容在文本编辑器中显示为
??
验证方法
使用以下代码查看实际字节值:
String text = "你好";
byte[] bytes = text.getBytes("ASCII");
for (byte b : bytes) {
System.out.printf("0x%02X ", b); // 输出:0x3F 0x3F
}
为什么会这样?
- ASCII 的局限性:仅包含 128 个字符,无法表示中文、日文等非英语字符。
- Java 的处理逻辑:当遇到无法编码的字符时,默认使用替换模式(
REPLACE),即用?替代无法编码的字符。
如何正确存储中文?
使用支持中文的编码(如 UTF-8):
ry (FileOutputStream fos = new FileOutputStream("test.txt")) {
String text = "你好";
byte[] bytes = text.getBytes("UTF-8"); // UTF-8编码
fos.write(bytes);
}
二进制结果:
0xE4 0xBD 0xA0 0xE5 0xA5 0xBD (对应"你好"的UTF-8编码)