转载:https://www.zhihu.com/question/575861004/answer/3076951659
在分布式系统中,随着各种中间件的引入,让原本就非常复杂的业务逻辑更加复杂,调用链路也越来越深。
用户在WEB页面点击一个按钮请求一个服务,可能会经过后端几次、十几次、甚至几十上百次的服务节点,最终将响应返回给前端。
举个例子。
我们在电商平台下单买一台笔记本电脑,结果WEB页面显示「系统内部错误,请稍后重试」,此时,作为用户的你会怎么想?

大概是先骂娘,然后找客服吧。
客户接到你的诉求,将问题抛给了开发,开发一脸不情愿,但又不得不排查问题,但是怎么排查呢?在这么复杂的调用链路中,就算他掐指一算,也算不出问题到底出在哪里。
没有任何头绪,只能从头开始排查,如果调用链路足够深、复杂的话,光定位问题可能就要半个小时。
如果是单体应用,那就好办了。
我们把错误信息在代码里搜索基本上就能定位到问题发生的地方了,即使是比较通用的错误信息,如上面所说的「系统内部错误,请稍后重试」,我们只需要从服务器来拉下来日志,就可以很快的定位问题。
最多三五分钟也就能确定问题在哪里。
但是,电商平台是分布式系统,前端的一个按钮可能涉及到后端的很多服务,可能每个服务都有「系统内部错误,请稍后重试」类的通用错误信息。
而且,很多服务调用涉及不同的组件、不同的JVM进程、不同的应用等,如果按照调用链路从头到尾一个个的拉日志,就显得非常繁琐,且效率太低。
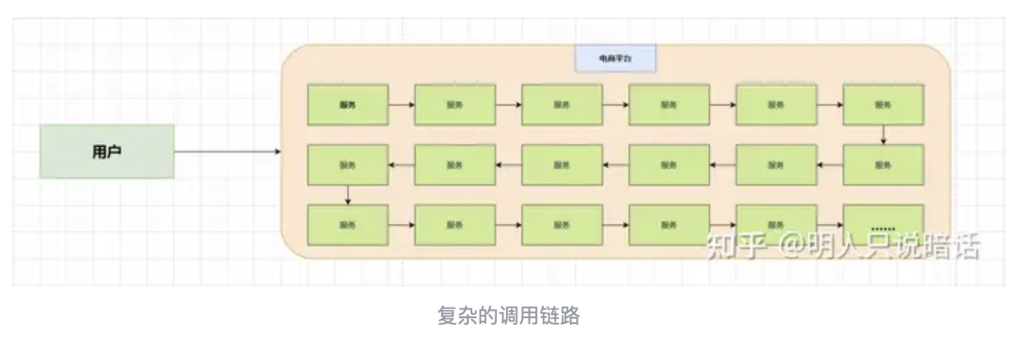
为了能够在分布式系统中,精确定位问题的案发现场,分布式链路追踪技术应运而生。
分布式链路追踪技术可以将请求流程经过的各个服务节点以日志的方式记录下,然后还原成调用链路,最终进行可视化展示,便于问题的定位和分析。
展示的内容,包括但不限于:各个服务的耗时、请求具体到达哪台机器上(IP地址或者容器地址等)、每个服务节点的请求状态(成功、失败)、各个服务之间的依赖关系等等。
分布式链路追踪技术已经非常成熟,国内外也有很多这样的产品,如Spring Cloud Sleuth + Twitter Zipkin,Skaywalking,CAT等等。
当然,分布式链路追踪系统不仅可以用来快速定位问题,还可以通过查看调用链路中各个服务的耗时、服务之间的依赖关系等,也可以通过对调用链路进行分析,得到用户的行为路径,为营销、广告推荐等场景提供数据支撑。
分布式链路追踪技术的核心概念
俗话说,无规矩不成方圆。
为了让分布式链路追踪技术有一个行业标准,CNCF(云原生计算基金会
)推出了 OpenTracing 项目。
OpenTracing 项目是与平台厂商无关的链路解决方案,它不提供具体的实现代码,只制定规范,让接入它的系统能有个一致的协议。
Jaeger、Skywalking等分布式链路追踪产品都是根据这个标准实现的。
下面介绍分布式链路追踪技术涉及的核心概念。
Trace
顾名思义,Trace表示对一次请求完整调用链的追踪,可以用树状图表示。
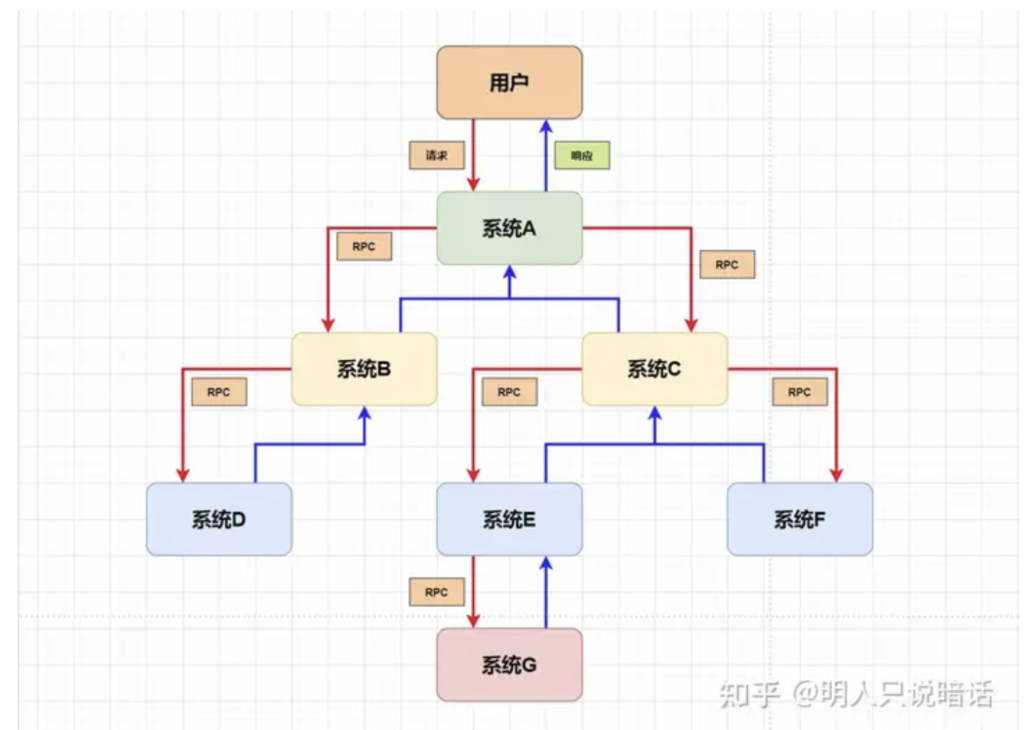
如上图所示。
A、B、C、D、E、F、G表示各个系统的服务。
当用户发起一次请求到系统A,系统A分别发送RPC请求到系统B和系统C。
而系统B发送RPC请求到系统D,系统C则发送RPC请求到系统E和系统F,系统E还要调用以RPC的方式调用系统G的服务,处理完所有请求后,系统A将结果响应给用户。
整个链路有一个唯一的ID标识,称之为traceId。
Span
Span表示两个服务的请求/响应的过程,例如上面的系统A和系统B之间RPC请求。
每个Span除了有一个标识自己属于哪个Trace的traceId(同一个Trace下的各个Span的traceId是一样的),还有一个用于标识自己的spanId(同一层级parentSpanId相同,spanId不同,spanId从小到大表示请求的顺序),一个parentSpanId用于标识上一级的Span,没有parentSpanId就无法形成一个调用链路关系。
除此之外,Span中还会记录自己调用其他服务的时间等信息。
Span结构如下图。

了解了Trace和Span之后,我们就可以画出上图调用关系的Trace调用链路图了。
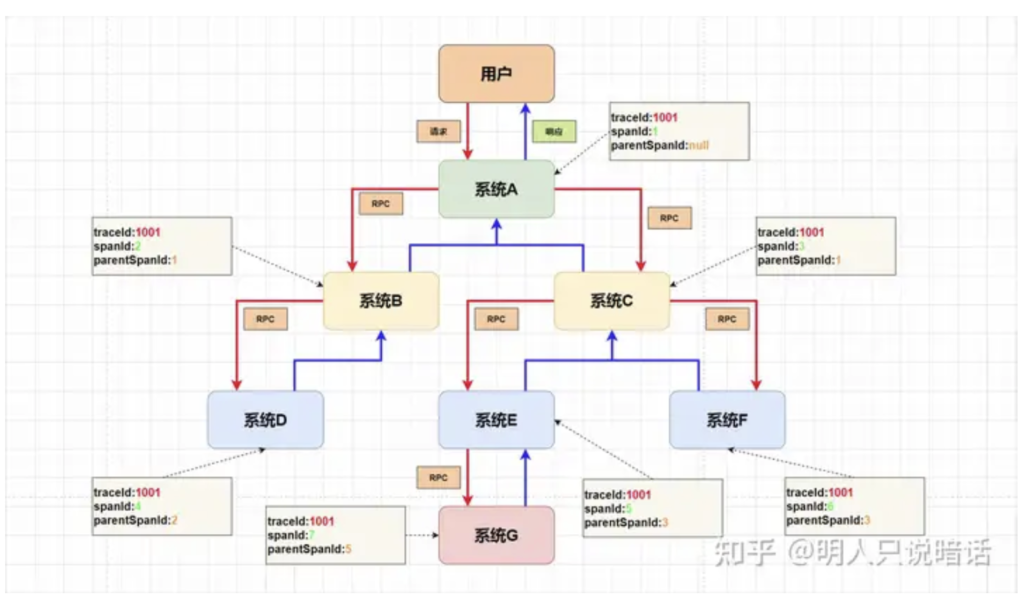
只需要找出相同traceId的日志,就可以找出某个Trace调用链路关系,再根据spanId和parentSpanId就可以将一条完整的请求调用链串成一颗调用链路树。
Annotation
除了Trace和Span之外,Dapper中还定义了Annotation的概念,用于用户自定义事件,可以辅助定位问题。
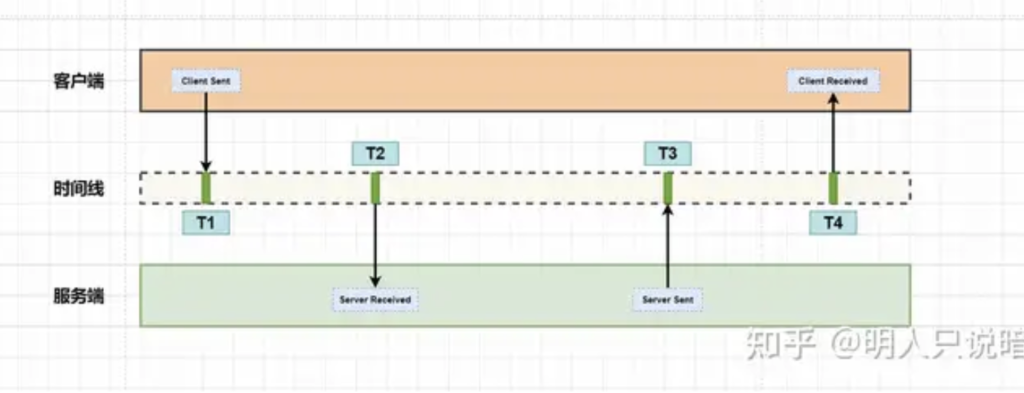
Annotation一般包括如下四个信息:
- cs(Client Sent)表示客户端发起请求。
- sr(Server Received)表示服务端收到请求。
- ss(Server Sent)表示服务端完成处理,并将结果发送给客户端。
- cr(Client Received)表示客户端获取到服务端返回信息。
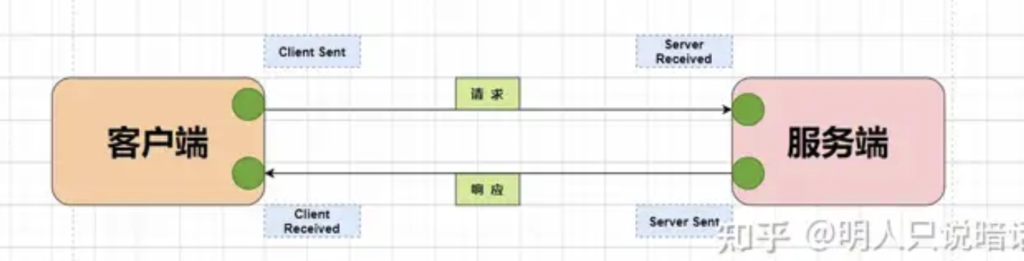
上图中的四个圆点代表Annotation的四个事件。
如果我们将上述四个事件在时间线上表示出来,结果如下图所示。

采样率
即使我们在应用中接入了分布式链路追踪系统,但也不是每个请求都会采集的,一个是避免大量的采集对应用造成性能损失,一个是节省存储资源。
举个例子。
我们将采样率设置为每秒采集请求总数的10%。
那么,如果每秒有10000个请求访问系统,那么分布式链路追踪系统每秒只会采集1000个请求到存储端(ElasticSearch、HBase等)。