转载:如何设计高并发系统
在短时间内同时有大量的用户请求打到业务系统中,业务系统如何实现能够快速且稳定的给用户响应,这样的系统就是高并发系统。高性能和高可用是高并发系统所必备的条件,那么如何设计高并发系统呢,今天我们从业务的角度和技术的角度来讨论这个问题。
1、技术角度
(1)系统的拆分
把一个系统拆分成多个子系统,也就是将一个单体的应用根据它不同的模块拆分成不同的微服务,如下图所示单体应用:
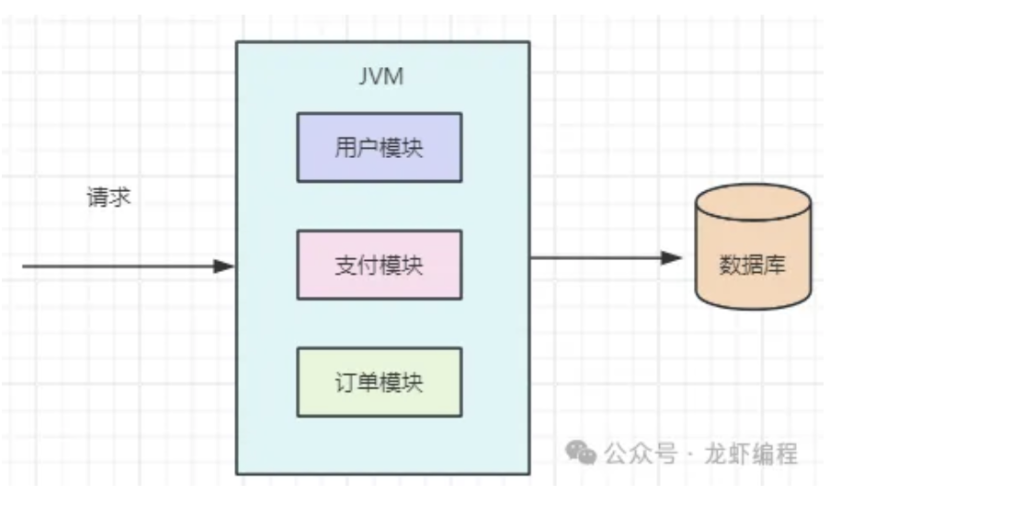
我们将上面的单体应用拆分成不同的服务模块,这个服务模块单独的部署成一个独立的服务,如下图所示:
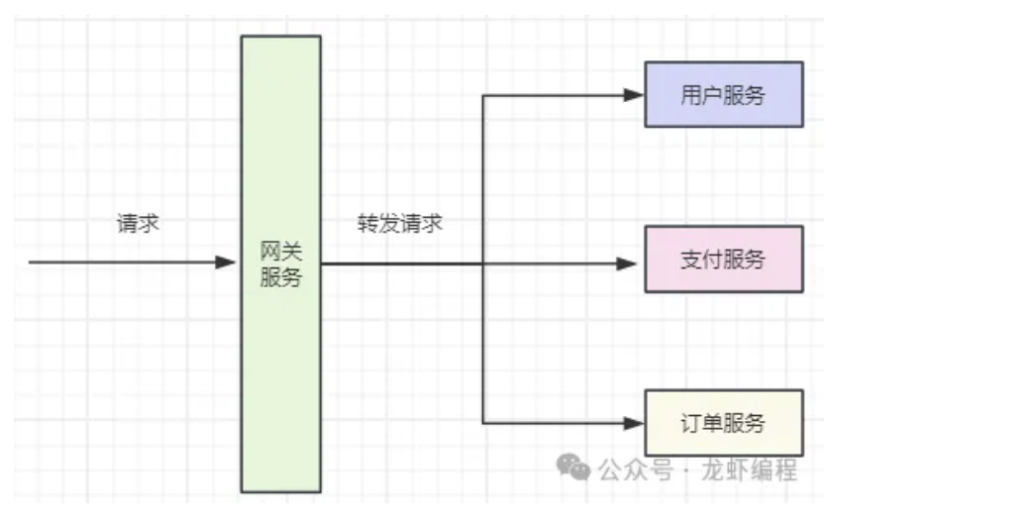
经过拆分之后,由原来单体应用对应一个数据库,变成多个微服务对应不同的数据库,这样可以承受更多的流量,如果某个某块的流量过大,我们可以针对这个模块采取一些措施,如集群部署服务。
(2)使用缓存
在高并发系统中,大部分的请求都是读取请求,如果想要提高数据的读取速度就需要考虑增加缓存(如redis),如下如所示:
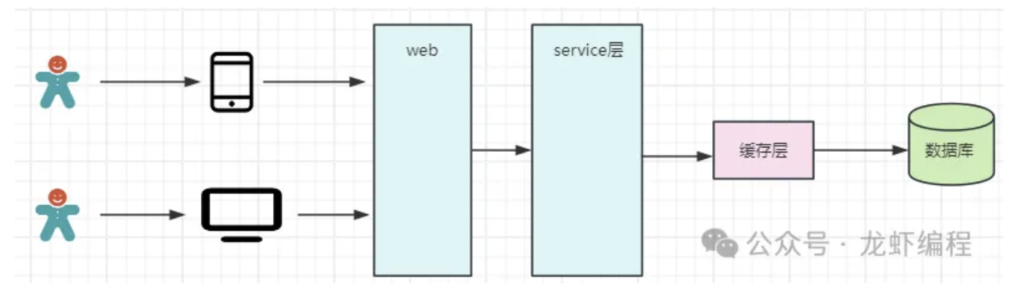
如果没有缓存层,那么在高并发下会有许多的重复请求,如A用户查询商品X的详情,B用户也查询商品X的详情,由于针对A用户和B用户商品X的信息是一样的,这样重复请求每次都要从数据库加载,会对数据产生压力,所以我们希望第一次查询之后,后面就不需要再次从数据库拿了,而是直接从缓存中拿商品X的数据,这样降低数据库访问的次数,提升了整体大的性能。
虽然缓存可以给我们带来性能上的提升,但是缓存(如redis)也带来一些问题,如缓存与数据库的数据一致性问题、缓存雪崩、缓存穿透、缓存击穿等,我们需要解决这些问题。前面龙虾针对缓存一致性的问题也整理了一些常见的解决方案,如下链接所示:
(3)使用MQ削峰
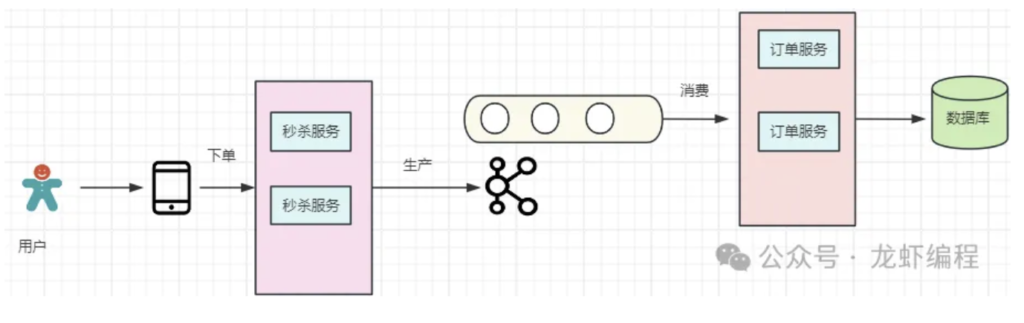
高并发场景下有时无法绕开写并发的问题,针对一个业务处理需要频繁的操作数据库,可能会导致业务系统的崩溃,因为数据库存在磁盘的IO性能瓶颈,因此是不能让Mysql在同一时刻承担大量的写请求。此时使用MQ来将写请求放入队列中,如上图的下单业务由原来的同步变为异步处理,这样的目的是让数据库的写请求保持在一个合理的范围内,不会让数据库被高并发冲垮。
(4)业务数据库的分离
数据库的磁盘IO性能存在上限的,如果数据库没有做处理的话是不能支持更多的并发量。如果业务发展迅速的话,就需要针对业务数据做分离,如下如图所示:
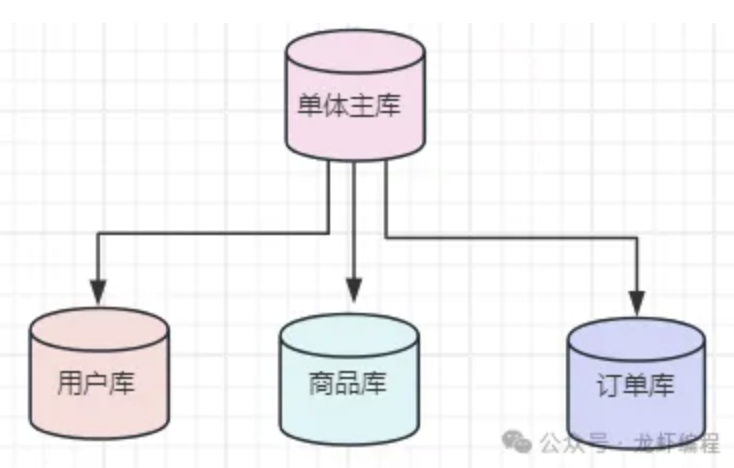
我们将单体的主库针对不同业务场景拆分成不同的业务库,这样将原先的单体主体拆分成不同业务数据库之后,假设原本主库支持1500的连接,按照业务分离后可以支持4500(1500*3)的连接,通过这种拆分的方式可以提高数据库抗并发能力。
随着业务发展,业务数据量也会激增,就会造成单表的数据量非常大了,此时就需要水平拆分了。将一张大表按照一定的规则拆分成若干的小表来存储数据。
通过垂直拆分和水平拆分的两种方式将数据分散到不同的库和不同的表中,大大的缓解了数据库可能成为性能瓶颈的问题。
(5)读写分离
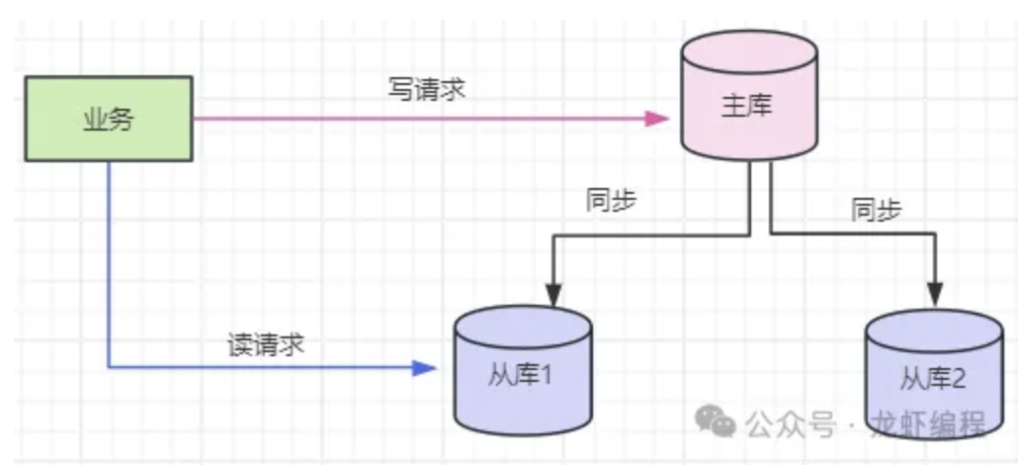
系统中大多数读多写少的场景可以做读写分离方案,原理是利用Mysql的主从架构将数据库中的读、写操作分别分配到不同的库上,这样可以提高系统的并发处理能力。
读、写操作具备不同的特点,读操作比较频繁、写操作比较耗时,因此将读、写操作进行分离之后可以有效的提高系统的并发能力.同时这样的架构设计中如果主库宕机了,可以将从库晋升为主库继续为整个系统提供服务,从而保证了高可用。
2、业务角度
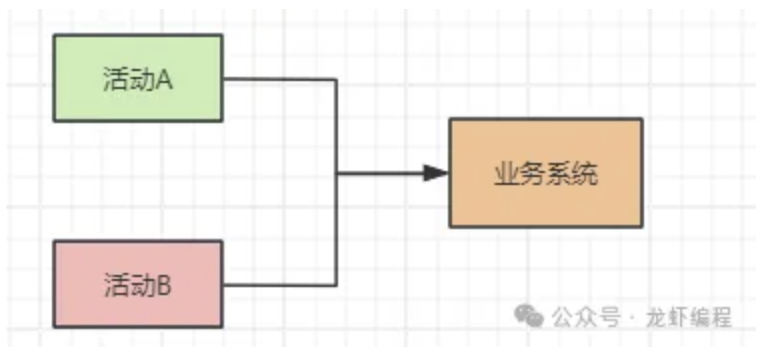
有些实际的业务场景中,我们通过业务设计来降低流量请求到我们系统中,如双十一的活动,原先是所有的活动都集中在一起开展,如下图所示:
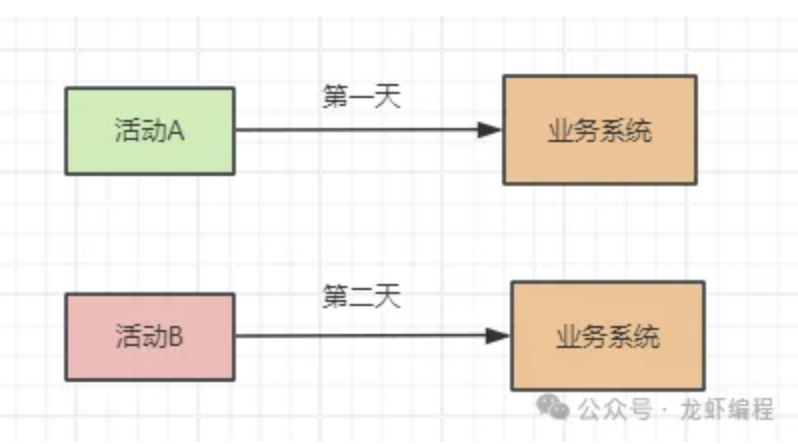
现在设计是将各种活动错开,如第一天是母婴商品活动、第二天做电子产品活动,这样可以通过业务的设计将流量分开,如下图所示:
总结:
(1)可以从业务角度来辅助降低服务的请求流量,从技术角度提高服务的抗并发能力。
(2)高并发下,也需要做好服务的限流,保证服务的稳定性和可用性。
(3)高并发场景下,我们需要对服务做监控,这样可以及时发现问题和解决问题。