日常开发中,我们经常听到系统的可用性是几个 9这样的描述,因此,这篇文章,我们将探讨什么是可用性、如何计算可用性以及提高可用性的一些常用策略。
什么是系统可用性?
系统的可用性(Availability)是衡量一个系统在特定时间段内能够正常运行并提供服务的能力。
可用性计算方式:
Availability = Uptime / (Uptime + Downtime)
- Uptime:运行时间,系统正常运行且可访问的时间段。
- Downtime:停机时间,由于故障、维护或其他问题而导致系统不可用的时期。
举个例子,假如一年 365天,停机总时间 2天,那么可用性的计算为:
Availability = (365-2) / 365
= 363 / 365
= 0.99452
转换成百分比 = 99.452 %
可用性等级
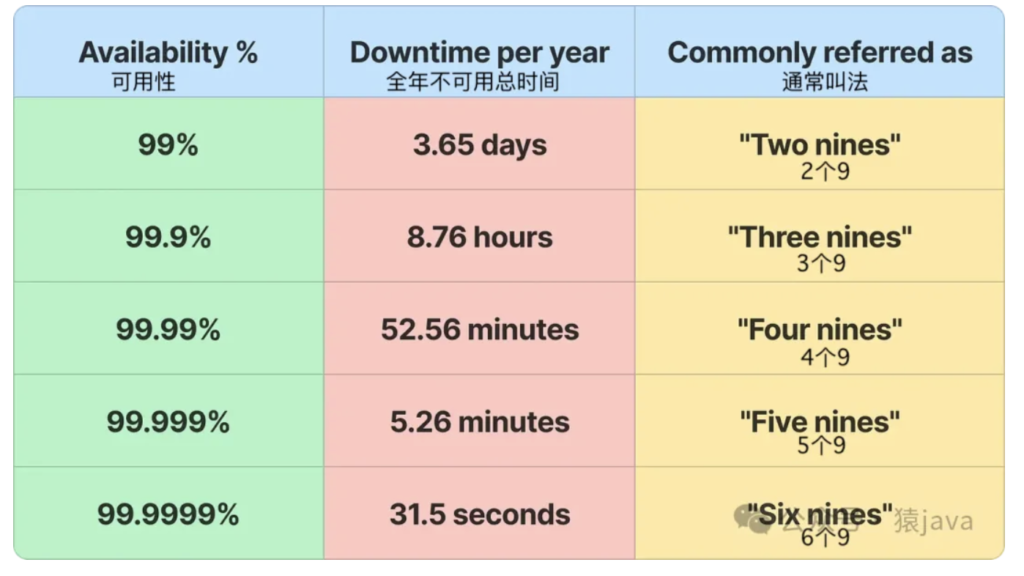
系统可用性,可用性通常用“9”表示,可用性越高,停机时间就越少。如下图所示:
如何提升系统可用性?
提升系统可用性的方法包括但不限于以下几种:
冗余设计
冗余设计是提升系统可用性常用的方式,比如,分布式部署,异地多活等,冗余设计常见的技术策略主要有以下 3种:
- 服务器冗余:部署多个服务器来处理请求,确保如果一个服务器出现故障,其他服务器可以继续提供服务。
- 数据库冗余:创建一个副本数据库,如果主数据库发生故障,该数据库可以接管。
- 地理冗余:将资源分布在多个地理位置,以减轻区域故障的影响。
故障检测与自动恢复
当检测到故障时,故障切换机制会自动切换到冗余系统。常用的技术策略有:
- 监控系统:使用监控工具(如Nagios、Zabbix)实时监控系统状态,及时发现问题。
- 自动化恢复:配置自动化脚本或服务(如AWS Auto Scaling)在检测到故障时自动重启或替换故障组件。
数据备份与恢复
在实际开发中,绝大部署业务都是对数据进行处理,因此数据的重要性不言而喻,对于数据可用性常用的技术点有:
- 定期备份:定期备份重要数据,确保在数据丢失或损坏时能够快速恢复。
- 灾难恢复计划:制定并测试灾难恢复计划,以确保在重大故障或灾难发生时能够迅速恢复系统运营。
负载均衡
负载均衡在多个服务器之间分配传入的网络流量,以确保没有单个服务器成为瓶颈,从而提高性能和可用性。
- 负载均衡器:使用负载均衡器(如Nginx、HAProxy)将请求分发到多个服务器,避免单个服务器过载。
- 分布式系统:设计分布式系统架构,将工作负载分布到多个节点。
容错设计
容错设计(Fault Tolerance Design),旨在使系统能够在某些组件发生故障时仍然继续正常运行,它的核心理念是通过冗余和其他技术手段,避免单点故障导致系统整体失效。
以下是容错设计的一些具体方法和技术:
- 无状态服务:设计无状态服务,使得服务实例可以随时被替换而不影响整体系统。
- 数据复制:使用数据复制技术(如数据库的主从复制)保证数据的高可用性。
定期维护与更新
在现实生活中,不管是人的健康还是机器或者其他的健康,都需要定期维护,对于系统来说也是一样的道理,通过定期的维护和更新,可以及时发现和解决潜在问题,防止系统故障,提升系统的整体可用性。
以下是定期维护与更新的主要策略:
- 补丁管理:及时应用安全补丁和系统更新,防止已知漏洞被利用。
- 健康检查:定期进行系统健康检查,发现潜在问题并及时修复。
使用高可用性云服务
- 云服务提供商的HA解决方案:利用云服务提供商提供的高可用性解决方案,如多区域部署、自动故障转移等。
网络优化
- 冗余网络连接:配置冗余的网络连接,避免单点网络故障。
- 优化网络配置:使用CDN(内容分发网络)加速内容交付,减少网络延迟。