基础知识:电商订单支付核心流程
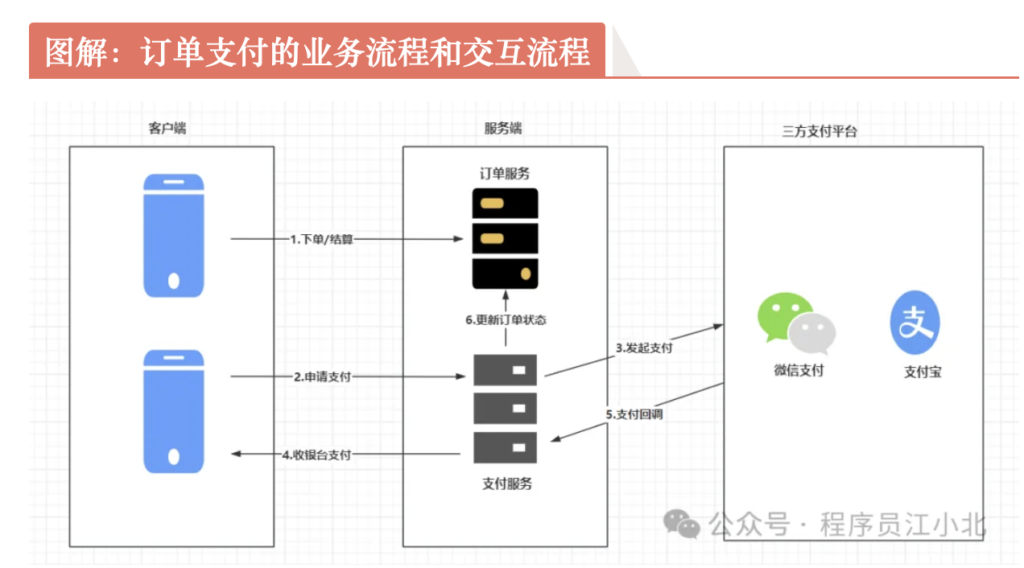
订单支付,大致分为8个步骤流程:
业务流程
- 用户下单:用户在电商平台选择商品,添加到购物车,并提交订单。
- 订单确认:系统生成订单号,并确认订单信息,包括商品、数量、价格等。用户确认订单详情无误。
- 选择支付方式:用户选择支付方式,如信用卡、支付宝、微信支付等。
- 支付提交:用户点击支付按钮,提交支付请求。
- 支付处理:系统将支付请求发送至支付网关或第三方支付平台。
- 支付结果返回:支付平台处理支付请求,返回支付结果(成功或失败)。
- 订单状态更新:系统根据支付结果更新订单状态。如果支付成功,订单状态更新为“已支付”。如果支付失败,通知用户重新尝试支付。
- 通知用户:系统将支付结果通知用户,并显示相关信息。
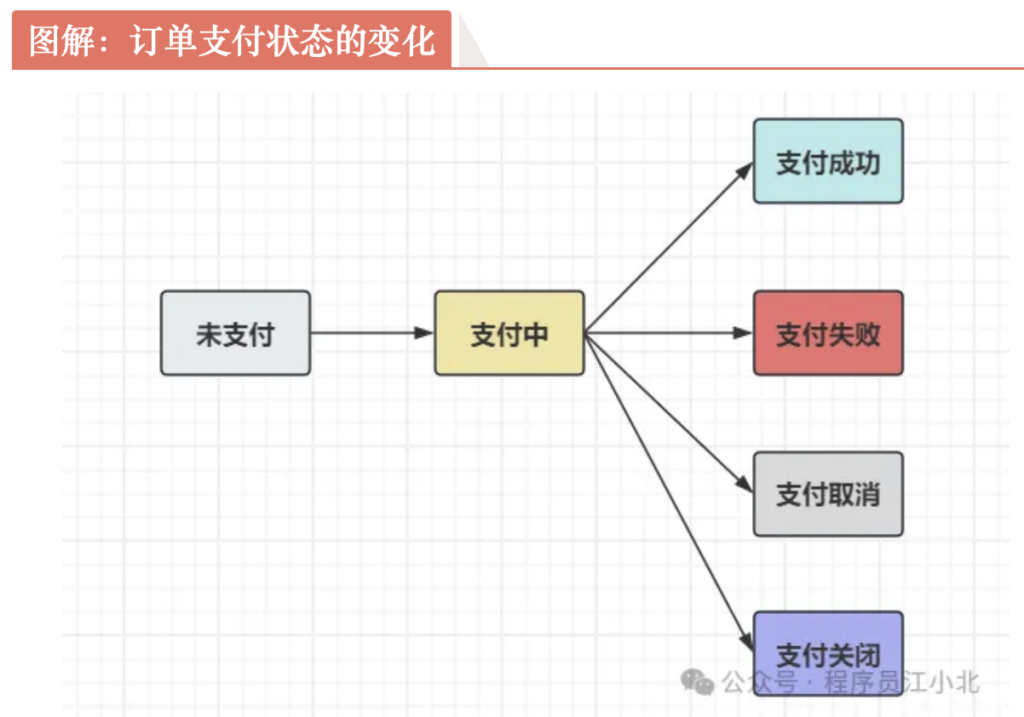
咱们来看看这个支付状态的变化,特别是从支付流水的角度来瞧。
首先,一个订单最开始是“从未支付”的状态,它不会一下子跳到“支付成功”或者“支付失败”的终态。在这中间,它还有一个“中转站”,那就是“支付中”。
那什么时候订单会进入“支付中”这个状态呢?
就是用户打开他的钱包,开始操作支付,然后直到支付完成并且收到支付回调的这段时间。
这段时间里,支付流水就会显示“支付中”。
简单说,就是用户正在付钱,但还没付完,也没收到付款结果的那段时间。
重复下单的定义、危害、应对策略
什么是重复下单
想象一下啊,你正在网上买东西,在点那个“下单”按钮的时候,可能因为手滑啊,或者网络不太给力,你就多点了几次。
再或者呢,有些系统它会自动帮你重试下单,就是因为这些原因,订单服务那边就收到了两次一模一样的下单请求。
这种情况,咱们就管它叫“重复下单”。
简单来说,就是你买了一个东西,但订单系统以为你买了两次。

重复下单带来的危害
- 库存管理问题:
重复下单会导致库存系统中出现虚假需求,影响库存管理的准确性。可能导致实际库存不足或库存积压,增加仓储成本。
- 订单处理负担:
增加了订单处理的复杂性,需要额外的人力和时间来核查和取消重复订单。系统需要处理更多的订单请求,增加了服务器和网络的负载。
- 财务成本增加:
处理重复订单和退款会产生额外的财务成本,如支付手续费、人工处理费用、营销成本等。平台需要承担由于重复订单引发的物流和配送费用。
- 客户服务压力:
客服团队需要处理更多的消费者投诉和问题,增加了客服的工作量和压力。可能需要增加客服人员来应对增加的咨询量,导致运营成本上升。
- 品牌形象受损:
频繁的重复下单问题会影响平台的品牌形象,消费者会质疑平台的专业性和可靠性。不良的购物体验会导致消费者流失,影响平台的长期发展。
什么场景下会发生重复下单
- 场景1:网络卡顿或出错
有时候我们在网上购物时,遇到网络卡顿或者系统出错,点了“提交订单”按钮,但页面没反应。于是,我们就会再点一次。这样可能就导致重复下单了。特别是当页面卡住或者显示错误信息时,用户很容易以为订单没成功,就会反复提交。
- 场景2:超时重试 Nginx或Spring Cloud Gateway 网关层、RPC通信重试或业务层重试,进行超时重试导致的。用户的设备与服务器之间,可能是不稳定的网路。这样一个下单请求过去,服务器不一定及时返回结果。
- 场景3:用户误操作
这类情况也不少见。有些用户在不太熟悉操作流程的时候,可能会因为紧张或者不小心多次点击“提交订单”按钮,导致重复下单。特别是一些老年用户或者不太熟悉网络购物流程的人,更容易出现这种问题。
- 场景4:秒杀活动
在一些特定情况下,比如秒杀活动或者抢购限量商品时,用户为了确保买到商品,可能会在不同设备上同时下单,或者在短时间内反复提交订单。这种情况下,很容易出现重复下单的现象。
重复下单与幂等性问题
重复下单问题,本质上,就是下单操作的幂等性问题
说到底,“下单防重”的问题其实就是属于“接口幂等性”的问题范畴。
什么是幂等性问题?
幂等性,简单来说,就是你做一个操作,无论是做一次还是做很多次,最后得到的结果都是一样的。
就像你点了一份披萨,点一次和点十次,最后送来的披萨数量还是一份,不会变成十份。
幂等性在计算机里也是个很重要的概念。
有些函数或方法,你不管重复执行多少次,只要参数一样,得到的结果都是相同的。
这样的函数或方法,我们就叫它幂等函数或幂等方法。
幂等性,用数学语言表达就是:
f(x)=f(f(x))
这些幂等函数有个好处,就是不会影响系统状态。就算你不小心重复执行了,也不用担心系统会乱套或者数据会出错。
举个例子吧,比如有个“setTrue()”的函数,它的作用就是把某个东西设置为真。
不管你调用这个函数多少次,只要参数不变,最后的结果都是那个东西被设置为真,不会有其他变化。
更复杂的操作要实现幂等性,可能会用到一些技巧,比如给每个操作分配一个唯一的交易号或流水号。这样就算重复执行了,系统也能根据这个唯一的号来识别,确保结果不变。
如何解决接口幂等问题
说起接口幂等性问题,只需记住一句口诀,那就是“一锁、二判、三更新”。
你按照这个步骤来,幂等问题基本就搞定了。
下面我来详细解释一下这个口诀:
- 一锁:首先,你得给接口加个锁,这样别人就不能在你操作的时候来插一脚了。
这锁可以是分布式锁,也可以是悲观锁,但关键是要确保它是互斥的,也就是说同一时间只能有一个人用。
- 二判:接下来,就是判断操作的幂等性了。怎么判断呢?你可以基于状态机、业务流水表或者数据库的唯一索引来做。
简单来说,就是看看这个操作是不是已经做过了,如果做过了,那就别再做了。
- 三更新:最后一步,就是更新数据了。你得把操作的结果保存到数据库里,这样下次再来查的时候就能看到这个结果了。
如何解决重复下单问题
方案一:提交订单按钮置灰
想要避免用户重复提交,最常规的办法就是,当用户点击下单后,还没等到服务器回应之前,就把那个按钮变成灰色,让它不能再点。
虽然前端页面可以尽量防止用户重复提交表单,但有时候网络不给力,导致请求没发出去,或者发出去没得到回应,这时候也可能出现重传的情况。而且啊,很多RPC框架和网关都有自动重试的功能,所以只靠前端来防止重复请求,那是不太可能的。
当然,这种方案也不是真的没有价值。在访问量特别大的时候,这个方法可以从浏览器这边先拦住一部分请求,让后端服务器轻松一点,起到过滤流量的作用。
这个方案的好处就是简单,基本上可以防止因为用户不小心多次点击提交按钮而造成的重复提交问题。
但它也有个不足,那就是对于用户的前进后退操作,或者按F5刷新页面等情况,它就没辙了。
方案二:请求唯一ID+数据库唯一索引约束
接下来向大家介绍一种最简单的、成本最低的解决方案。
防重最重要的第一步是什么?
那肯定是需要识别出是否是重复请求
所以,需要客户端在请求下单接口的时候,需要生成一个唯一的请求号:requestId,服务端就可以拿这个请求号,判断是否重复请求。
核心流程图:
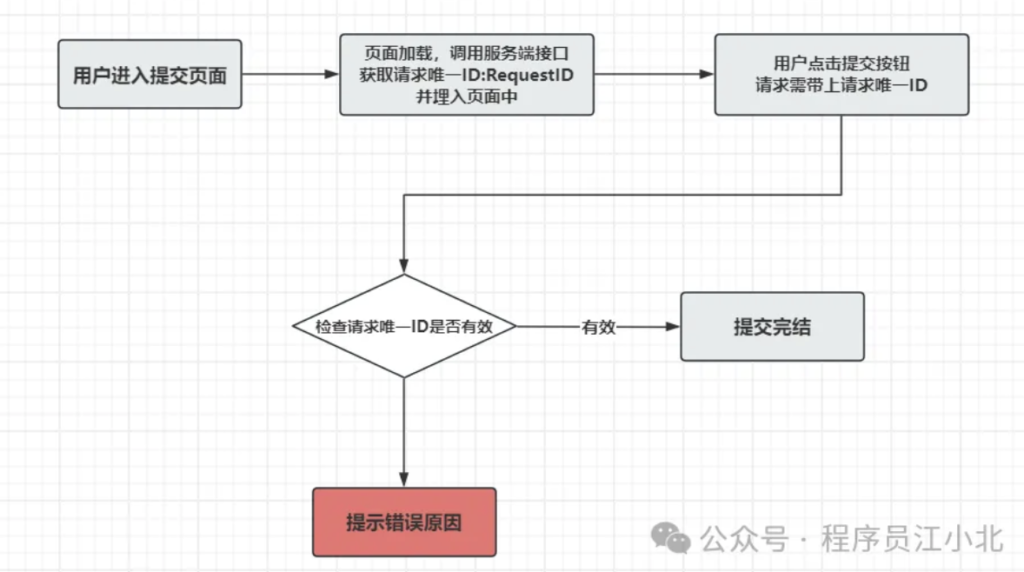
实现的逻辑,流程如下:
- 用户进入订单提交页时,系统会生成一个唯一的请求ID并隐藏在页面里。
- 点击提交时,系统会检查这个ID是否已被使用。若未使用,继续处理;若已使用,则提示重复提交。
- 最关键的是,这个ID会被存入系统的独特名单中,确保每个ID都是唯一的,以此防止重复提交。
但请注意,在高并发情况下(如每秒10万请求),这种方法可能不够用。
方案三:reids分布式锁+请求唯一ID
在上一个方案中我们提到,对于下单流量不多的系统,我们可以用一个叫做“请求唯一ID”再配合给数据表加个“唯一索引”的方法来防止订单重复提交。
但你们知道吗?
随着我们生意越来越好,订单越来越多,可能每秒钟的订单请求就从几十飙升到几百、几千,甚至几万!
这时候,数据库就累得不行了,成了我们下单流程里的“大瓶颈”。
这时候就需要以引入一个叫redis的“缓存小助手”来帮数据库分担压力。
下面,我们以引入redis缓存中间件,向大家介绍具体的解决方案。
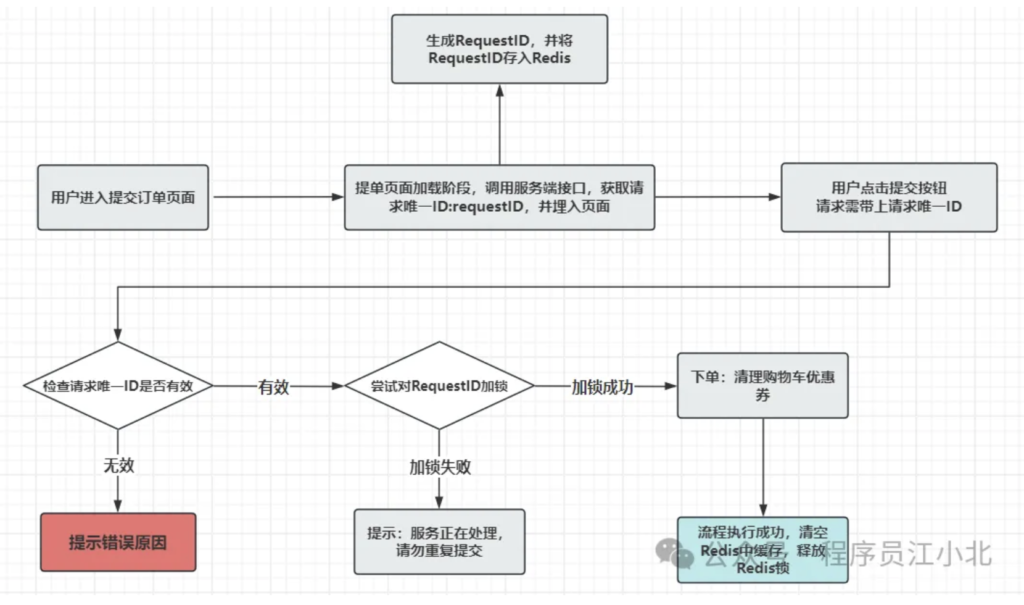
流程如下:
- 用户进入订单提交界面时,系统调用后端API获取并生成请求唯一ID,将其存储至Redis缓存并返回至前端,前端将此ID嵌入页面。
- 用户点击提交按钮时,后端检查Redis中是否存在该请求唯一ID。若不存在,返回错误信息;若存在,继续后续验证流程。
- 利用Redis的分布式锁机制,对请求ID进行短暂锁定。锁定成功则继续处理;锁定失败则返回提示信息:“订单正在处理中,请勿重复提交。”
- 处理完成后,确保释放Redis中的锁,并清理已处理订单的请求唯一ID。
关于数据库唯一索引:虽然理论上可省略,但添加可提高数据一致性和防止潜在的数据冲突。
该方案经过扩展,可高效应对10万QPS(每秒查询率)的高并发场景。
方案四:reids分布式锁+token
在之前的那个方案里,每次下单都得先跑去服务端要个请求的唯一ID,也就是那个requestId,感觉就像是在走个多余的步骤,是吧?那这样不就多了一个专门要ID的请求了吗?
那有没有办法省掉这一步,让我们的下单过程更快更顺畅呢?
答案是肯定的!
我们可以换个思路,不用每次都去服务端要ID了。
我们可以根据用户请求的一些关键信息,按照某种特定的方式,自己生成一个“通行证”,也就是一个token,来代替那个专用的requestId。
这样,我们就不用专门跑去找服务端要ID了,省去了中间那一步,下单过程就更快了。
那么,怎么生成这个token呢?
其实也不难,我们可以把几个重要的信息组合起来,比如
应用名+接口名+方法名+请求参数签名(请求header、body参数,取SHA1值)
把这些信息放在一起,就能生成一个独一无二的token了。
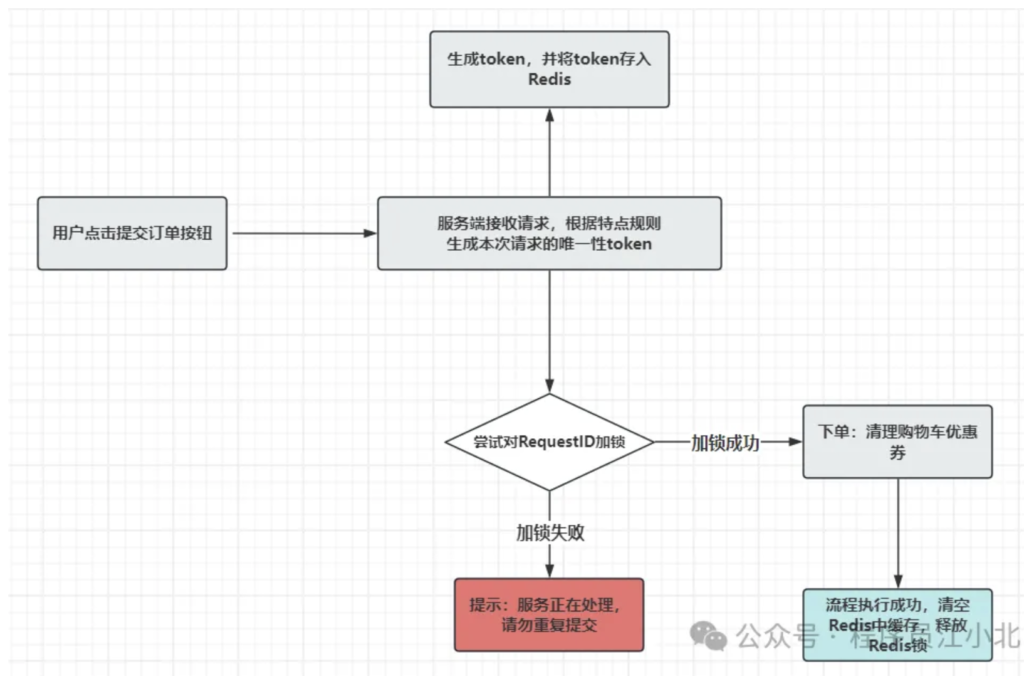
大致流程如下:
- 用户点击提交按钮,然后服务端就会收到这个请求。收到之后,服务端会根据一些规则给这次请求算出一个独一无二的“身份证”,也就是请求ID。
- 服务端会尝试用Redis的“锁匠”给这个“身份证”上个锁,时间有限哦。如果锁上了,那就继续处理订单;如果锁不上,那就说明服务正在忙,别重复提交了。
- 最后一步,如果成功锁上了,别忘了处理完事情后要把锁打开,不然下次别人再来的时候可能会搞错。
现在来说说方案四和方案三的区别。最主要的区别就在于怎么给请求生成这个“身份证”。
方案四是在服务端这边,通过把几个关键信息组合起来,给请求造一个“身份证”。
这样做的好处是,既能防止订单重复提交,又能让接口测试变得更简单。
而且,方案四的性能还比方案三要好一些呢!
方案五:技术+产品+运营支持
虽然我们已经有了很棒的处理方案,但说实话,有时候用户还是可能因为不小心点错了,收到两份相同的商品才发现自己下重复了。
你知道,就算是世界上最顶尖的技术,也做不到100%完美无缺,总会有那么一点点小漏洞。
所以,为了彻底解决这个问题,我们不仅要靠技术,还得靠产品设计和运营团队的支持。
当这种情况真的发生时,就得靠我们的运营和客服团队来帮忙解决了。
其实,就连像淘宝、京东、拼多多这样的大电商平台,也会遇到类似的问题,他们都是通过运营手段来配合处理的。
总结
看到这里,相信认真看完的小伙伴都对如何防止重复下单有一个清晰的认知了。
简单来说,其实就是解决幂等性问题,而解决幂等性问题其实主要就是加锁和唯一性ID校验
而如果要满足10W QPS的并发,就需要优化加锁的性能(比如Redis分布式锁)和生成唯一ID的方式